






默认的数值型变量的长度为8
字符函数的默认长度可达到200
LIBNAME STATEMENT:
LIBNAME LIBREF 'SAS-DATA-LIBRARY';LIBREF长度为1到8字节,以字母或下划线开头,并且只包括字母,数字或下划线
# 清除LIBREF引用
LIBNAME LIBREF CLEAR;LIBNAME STATEMENT FOR FILES IN OTHER FORMATS:
LIBNAME LIBREF ENGINE 'SAS-DATA-LIBRARY';LIBRARY ENGINES:
ENGINE | DESCRIPTION |
BMDP | ALLOWS READ-ONLY ACCESS TO BMDP FILES |
OSIRIS | ALLOWS READ-ONLY ACCESS TO OSIRIS FILES |
SPSS | ALLOWS READ-ONLY ACCESS TO SPSS FILES |
PROC CONTENTS STEP:
PROC CONTENTS DATA=LIBREF._ALL_ NODETAILS;
RUN;_ALL_请求一个库中所有文件的列表
当指定_ALL_时,NODETAILS(NODS)会禁止打印有关每个文件的详细信息。只有在指定_ALL_时,才能指定NODS。
PROC DATASETS STEP WITH CONTENTS STATEMENT:
PROC DATASETS;
CONTENTS DATA=LIBREF._ALL_ NODETAILS <VARNUM>;
QUIT;默认情况下,PROC CONTENTS和PROC DATASETS会按照字母顺序列出变量。要按照数据集中的逻辑书序列出变量,可以在PROC CONTENTS或在PROC DATASETS语句中指定VARNUM选项。
OPTIONS STATEMENT:
OPTIONS OPTIONS;一般选项
CENTER|NOCENTER | 输出居中,左对齐。默认居中 |
DATE|NODATE | 今天的日期是否出现在顶部。默认出现 |
LINESIZE=N | 控制输出行的最大长度,N可能的值为64到256 |
NUMBER|NONUMBER | 输出的页面页码是否需要。默认需要 |
ORIENTATION=PORTRAIT; ORIENTATION=LANDSCAPE; | 指定打印输出的方法。默认竖向(portrait) |
PAGENO=N | 输出页开始的页面,默认为1 |
PAGESIZE=N | 每个页面输出的最大行数,可能的值为15到32767 |
RIGHTMARGIN=N LEFTMARGIN=N TOPMARGIN=N BOTTOMMARGIN=N | 指定打印输出的边缘大小,默认0.00英寸 |
YEARCUTOFF=yyyy | 设定起始年份 |
默认情况下,页码和日期将在输出中显示。以下选项语句禁止在列表输出中打印页码和日期和时间。
OPTIONS NONUMBER NODATE;PAGENO=选项指定报表打印的起始页码。默认输出从第1页开始。
PAGESIZE=N选项将指定每页输出包含多少行,其中N为行数。(包括标题,日期及其他一系列占用行)
LINESIZE=选项指定输出和日志的行宽度(行包含字符数量),不符合行大小的观察结果僵在不同的行上继续打印。
YEARCUTOFF=选项只对两位数的年值(TWO-DIGIT YEAR)有效,此选项指定使用哪个100年的跨度来解释两位数的年值,其默认值为1920,即1920到2019年这100年跨度。
SAS可以正确显示从1582 A.D. 到20,000 A.D.的日期(闰年,世纪和四世纪的调整是自动进行的,闰秒和夏令时被忽略)。
OBS=确定系统需要处理的最后一行观测
FIRSTOBS=确定系统需要处理的第一行观测
FIRSTOBS= AND OBS= OPTIONS IN AN OPTIONS STATEMENT:
OPTIONS FIRSTOBS=N;
OPTIONS OBS=N;N为正整数,默认情况下FIRSTOBS=1, OBS=MAX, MAX最大课代表在操作环境下克表示的最大的有符号的四字节整数。
只对最后一个观测进行处理时,可以指定OBS=MAX。
DATA PERM.UPDATE;
INFILE INVENT OBS=10;
INPUT ITEM $ 1-13 IDNUM $ 15-19
INSTOCK 21-22 BACKORD 24-25;
TOTAL=INSTOCK+BACKORD;
RUN;OPTIONS PROCEDURE:
PROC OPTIONS <OPTION(S)>;
RUN;提交以下代码,可以列出所有SAS系统选项及其设置和说明:
PROC OPTIONS;
RUN;要列出某个特定系统选项的设置和说明,可在PROC OPTIONS语句中使用OPTION=选项:
(EXAMPLE)
PROC OPTIONS OPTION=YEARCUTOFF;
RUN;ADDDITIONAL SYSTEM OPTIONS:
OPTION | DESCRIPTION |
FORMCHAR='FORMATTING-CHARACTERS' | 确定输出设备的格式化字符。格式化字符用于构造表的轮廓,以及各种过程的分隔符,如FREQ过程和TABULATE过程。如果在输出过程中没有指定格式化字符,则将使用FORMCHAR=的系统默认规范。 |
FORMDLIM='DELIMITING-CHARACTER' | 指定一个在SAS系统输出中用于分页的字符。通常,分页符为空。 |
LABEL | NOLABEL | 允许SAS程序临时使用描述性标签替换变量名。在使用任何过程的LABEL选项之前,LABEL系统选项必须生效。如果制定了NOLABEL,则忽略过程中的LABEL选项,默认设置为LABEL |
SOURCE | NOSOURCE | 控制是否将SAS源语句写入SAS日志。NOSOURCE指定不将SAS源语句写入SAS日志。默认设置为SOURCE。 |
ERRORS=N | 指定打印完整数据错误消息的最大观测数。 |
FMTERR | NOFMTERR | 当找不到变量的格式时,该选项控制SAS是否生成错误消息。NOFMTERR错误会导致警告而不是错误。默认为FMTERR。 |
SAS ERROR:
SYNTAX ERRORS | 程序语句不符合SAS语言规则 |
DATA ERRORS | 某些数据值不符合程序中指定的SAS语句时发生。此时SAS为适当的变量分配了一个缺失的值,然后继续执行。 |
与语法错误不同,无效的数据错误不会导致SAS停止处理程序。SAS通过将缺失的值分配给适当的变量并向SAS日志写入消息来处理无效的数据错误。
PROC PRINT STEP:
PROC PRINT <DATA=SAS-DATA-SET> <NOOBS> <LABEL>;
RUN;
# NOOBS选项取消SAS默认打印的观测值数
# LABEL选项可以指定打印的变量标签PROC PRINT DATA=RESULTS.OUTPUT04 (OBS=16 FIRSTOBS=16);
VAR VAR3 VAR20;
RUN; #只打印第十六行VAR3和VAR20的值PROC PRINT DATA=RESULTS.OUTPUT27A (FIRSTOBS=100 OBS=100);
VAR EMPLOYEE_ID;
RUN;
# 只打印第100行的变量EMPLOYEE_ID的值VAR STATEMENT:
VAR VARIABLE(S);ID STATEMENT:
ID VARIABLE(S);WHERE STATEMENT:
WHERE WHERE-EXPRESSION;COMPARISON OPERATORS:
SYMBOL | MEANING | EXAMPLE |
= OR EQ | EQUAL TO | WHERE NAME='JONES, C.'; |
^= OR NE | NOT EQUAL TO | WHERE TEMP NE 212; |
> OR GT | GREATER THAN | WHERE INCOME > 2000; |
< OR IT | LESS THAN | WHERE PARTNO LE "BG05"; |
>= OR GE | GREATER THAN OR EQUAL TO | WHERE ID >='1543'; |
<= OR LE | LESS THAN OR EQUAL TO | WHERE PULSE LE 85; |
IN | EQUAL TO ONE OF A LIST |
PROC SORT STEP:
PROC SORT DATA=SAS-DATA-SET <OUT=SAS-DATA-SET> <NODUPKEY>;
BY <DESCENDING> BY-VARIABLE(S);
RUN;
# 选项NODUPKEY告诉SAS排序时删除重复值PROC SORT DATA=CERT.INPUT27 OUT=RESULTS.OUTPUT27A(WHERE=(UPCASE(COUNTRY)='US'));
BY STATE DESCENDING POSTAL_CODE EMPLOYEE_ID;
RUN;
# 基于数据集CERT.INPUT27创造输出数据集RESULTS.OUTPUT27A,其中仅保留变量COUNTRY的值为‘US’或‘us’的观测
# SUM STATEMENT:
SUM VARIABLE(S);BY STATEMENT IN THE PRINT PROCEDURE:
BY <DESCENDING> BY-VARIABLE-1
<...<DESCENDING><BY-VARIABLE-N>>
<NOTSORTED>;PAGEBY STATEMENT:
PAGEBY BY-VARIABLE;TITLE AND FOOTNOTE STATEMENTS:
TITLE <N> 'TEXT';
FOOTNOTE <N> 'TEXT';N是1到10的数字,指定标题或脚注行
'TEXT'是实际的标题或脚注
TITLE OPTIONS 'TEXT-STRING-1' OPTIONS 'TEXT-STRING-2'...OPTIONS 'TEXT-STRING-N';
FOOTNOTE OPTIONS 'TEXT-STRING-1' OPTIONS 'TEXT-STRING-2'...OPTIONS 'TEXT-STRING-N';可以将一段文字分成不同的部分,每个部分应用不同的样式
COLOR= 为文本指定一种颜色
BCOLOR= 为背景指定一种颜色
HEIGHT= 为文本指定高度
JUSTIFY= 要求对齐
FONT= 为文本指定字体
BOLD 粗体
ITALIC 斜体
LABEL STATEMENT:
LABEL VARIABLE1='LABEL1'
VARIABLE2='LABEL2'
...;标签长度最多可达256个字符。引号被用来括住标签。
FORMAT STATEMENT:
FORMAT VARIABLE(S) FORMAT-NAME;Format 可以用在数据步和过程步中,前者将把格式永久储存,后者只是临时储存
THIS FORMAT STATEMENT | ASSOCIATES | TO DISPLAY VALUES AS |
FORMAT DATE MMDDYY8.; | 变量DATE使用格式MMDDYY8. | 06/05/03 |
FORMAT NET COMMA5.0 GROSS COMMA8.2; | 变量NET使用格式COMMA5.0,变量GROSS使用格式COMMA8.2 | 1,234 5,678.90 |
FORMAT NET GROSS DOLLAR9.2; | 变量NET和GROSS都使用格式DOLLAR9.2 | $1,234.00 $5,678.90 |
SAS FORMATS:
FORMAT | SPECIFIES THESE VALUE | EXAMPLE |
COMMAw.d | 包含逗号和小数点占位 | COMMA8.2 |
DOLLARw.d | 包含美元符号,逗号和小数点占位 | DOLLAR6.2 |
MMDDYYw. | 以09/12/97(MMDDYY8.)或09/12/1997(MMDDYY10.)作为日期形式 | MMDDYY10. |
w. | 四舍五入到w位最接近的一个整数 | 7. |
w.d | 四舍五入到w位的第d个小数位 | 8.2 |
$w. | w位的字符值 | $12. |
DATEw. | 以16OCT99(DATE7.)或16OCT1999(DATE9.)作为日期形式 | DATE9. |
BASIC STATEMENTS TO CONSTRUCT PROGRAMS:
TO DO THIS | USE THIS SAS STATEMENT | EXAMPLE |
引入SAS数据库 | LIBNAME STATEMENT | LIBNAME LIBREF 'SAS-DATA-LIBRARY'; |
引入外部文件 | FILENAME STATEMENT | FILENAME TESTS 'SAS-DATA-FILE'; |
命名SAS数据集 | DATA STATEMENT | DATA WORK.TEST; |
标识外部文件 | INFILE STATEMENT | INFILE TEST OBS=10; |
输入数据 | INPUT STATEMENT | INPUT ID 1-4 AGE 6-7...; |
执行DATA/PROC步 | RUN STATEMENT | RUN; |
列出数据 | PROC PRINT STATEMENT | PROC PRINT DATA=WORK.SHOP; |
FILENAME FUNCTION:
FILENAME FILEREF 'FILENAME';FILEREF是一个与外部文件关联的名称。名称必须为1到8个字符长,以字母或下划线开头,并且只包含字母、数字或下划线。
DATA STATEMENT:
DATA SAS-DATA-SET-1 <...SAS-DATA-SET-N>;INFILE STATEMENT:
INFILE FILE-SPECIFICATION <OPTIONS>;最大记录长度的默认值由操作环境决定。如果在读取许多变量时出现意外的结果,则可能需要通过在INFILE语句中指定LRECL=选项来更改最大记录长度。
INFILE '/home/data.dat';INFILE 'FILE-SPECIFICATION' PAD;PAD 选项允许SAS读取含有空格的可变长度的记录
INFILE 'FILE-SPECIFICATION' DSD;DSD选项允许SAS正确地读取使用逗号作为分隔符和使用两个连续逗号以表示缺失的数据
如果数据中有缺失值,则要在 INFILE 中加入DSD 和 MISSOVER 选项,前者将两个连续的分隔符视为缺失值,后者告诉 SAS 如果此行读完,不要进入下一行给未赋值的变量赋值
INFILE 'FILE-SPECIFICATION' MISSOVER;MISSOVER选项防止SAS在读取自由格式数据(FREE FORMATTED DATA)时读取超过行末尾。
在 input 语句中输入的几个变量,SAS 在观测值中就读取几个变量,如果一行未读完,则进入下一行直到输入的变量都读取了变量值。missover 可以让 SAS 不进入下一行读取,未赋值的变量就使其成为缺失值。
Truncover :使用 column input 或 formatted input 输入时可能会需要这个选项,因为这时有
的数据行比其他的短。
INFILE 'FILE-SPECIFICATION' DLM=',';DLM=选项将逗号指定为分隔符;但是,默认情况下,将连续分隔符视为一个分隔符。
Standard and Nonstandard Numeric Data
Standard Numeric data values contains only
numbers
decimal points
numbers in scientific or E-notation(2.3E4, for example)
plus or minus signs
Nonstandard numeric data includes
values that contain special characters, such as percent signs (%), dollar signs ($), and commas (,)
date and time values
data in fraction, integer binary, real binary, and hexadecimal forms
INPUT STATEMENT USING COLUMN INPUT:
INPUT VARIABLE ;<$> STARTCOL-ENDCOL...美元符号($)将变量类型标识为字符(如果变量是数字的,则这里不显示任何内容)
变量命名:
长度为1-32个字符
以字符(A-Z)或下划线(_)起始
可以继续使用数字、字母或下划线的任何组合
INPUT RANK CITY & $12. POP86 : COMMA.;修饰符(&)用于读取包含嵌入空格的字符值。
冒号(:)修饰符用于读取长度超过8个字符,但不包含嵌入式空格的非标准数据值和字符值。冒号(:)表示读取值,直到遇到空白(或其他分隔符),然后应用信息处理程序。如果指定了读取字符值的信息,则w值指定变量的长度,覆盖默认长度。
如果指定一系列字符变量,变量列表和$符号都必须用括号括起来。
DATA SURVEY.STORES;
INFILE STORDATA;
INPUT AGE (STORE1-STORE3) ($)
RUN;还可以使用格式化的输入来指定一系列变量。如果使用格式化输入指定一系列变量,则变量列表和格式都必须包含在括号中,而不包含在变量的类型中。
DATA TEST.SCORES;
INFILE GROUP3;
INPUT AGE (SCORE1-SCORE4) (6.);
RUN;INPUT BANDNAME :$30 GIGDATE :MMDDYY10.;
# 冒号修改器告诉 SAS 读取信息的长度(BandName 为 30,GigDate 为 10)。如果不加冒号修改器,将会默认每个变量的长度为该变量取值最长的那个值的长度PROC IMPORT:
PROC IMPORT DATAFILE='ONIONS.XLS'
DBMS=XLSX;
OUT=SALES;
SHEET=SHEETA;
GETNAMES=YES;
# 常被用来读取EXCEL文件ASSIGNMENT STATEMENT:
VARIABLE=EXPRESSION;算术运算符(ARITHMETIC OPERATORS):
OPERATOR | ACTION | EXAMPLE | PRIORITY |
- | NEGATIVE PREFIX | NEGATIVE=-X; | I |
** | EXPONENTIATION | RAISE=X**Y; | I |
* | MULTIPLICATION | MULT=X*Y; | II |
/ | DIVISION | DIVIDE=X/Y; | II |
+ | ADDITION | SUM=X+Y; | III |
- | SUBTRACTION | DIFF=X-Y; | III |
逻辑运算符:
OPERATOR | MEANING | |
AND or & | AND | WHERE RAINFALL>20 AND TEMP<90; |
OR or | ! | OR | WHERE RAINFALL>20 OR TEMP<90; |
^= OR ~= | NOT | WHERE REGION ~='SPAIN'; |
IS NOT MISSING | WHERE REGION IS NOT MISSING; | |
BETWEEN AND | WHERE REGION BETWEEN 'PLAIN' AND 'SPAIN'; | |
CONTAINS | WHERE REGION CONTAINS 'AIN'; | |
IN(LIST) | WHERE REGION IN ('RAIN','SPAIN','PLAIN'); | |
DATE CONSTANT:
'DDMMM<YY>YY'D
OR
"DDMMM<YY>YY"DDD以一位或两位表示日期
MMM是月份的三个字母的缩写(JAN, FEB, and so on)
YY或YYYY分别是两位和四位的年份表示
SUBSETTING IF STATEMENT:
IF EXPRESSION;DATALINES STATEMENT:
DATALINES;还可以使用CARDS;作为DATA步骤中的最后一条语句(RUN语句除外),并且紧跟在数据行的前面。CARDS语句是DATALINES语句的别名。
USING THE _NULL_ KEYWORD:
使用关键字_NULL_,它能够使用DATA步骤,而不实际创建SAS数据集。
DATA _NULL_;
SET CLINIC.STRESS;
RUN;FILE STATEMENT:
FILE FILE-SPECIFICATION;将观察数据写入原始数据文件时,使用FILE语句来指定输出文件
DATA _NULL_;
SET WORK.SHOP;
FILE 'D:\WORKSHOP.DAT';
RUN;PUT STATEMENT USING COLUMN OUTPUT:
PUT VARIABLE STARTCOL-ENDCOL...;FILE语句指定输出文件,而PUT语句则指定要写入原始数据文件的内容。
DATA _NULL_;
SET WORK.SHOP;
PUT ID 1-4 NAME 6-25 RESTHR 27-29 MAXHR 31-33 RECHR 35-37 TIMEMIN 39-40 TIMESEC 42-43
TOLERANCE 45 TOTALTIME 47-49;当程序错误的来源不明显时,可以使用PUT语句来检查变量值,并在日志中打印自己的消息。出于诊断目的,可以使用IF-THEN/ELSE语句来有条件地检查值。
SIMPLE PUT STATEMENT:
PUT SPECIFICATION(S);示例:
DATA WORK.TEST;
INFILE LOAN;
INPUT CODE $ 1 AMOUNT 3-10 RATE 12-16
ACCOUNT $ 18-25 MONTHS 27-28;
IF CODE='1' THEN TYPE='VARIABLE';
ELSE IF CODE='2' THEN TYPE='FIXED';
ELSE PUT 'MY NOTE: INVALID VALUE:'
CODE=;
RUN;在本例中,如果CODE的期望值不是1或2,PUT语句将写入消息:
SAS LOG
MY NOTE: INVALID VALUE: CODE=V
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 6 VARIABLES.带有条件处理的PUT语句(即使用IF-THEN/ELSE语句)可被用来标记程序错误或超出范围的数据。在下面的示例中,PUT语句用于标记变量RATE的任何缺失值或零值。
DATA FINANCE.NEWCALC;
INFILE NEWLOANS;
INPUT LOANID $ 1-4 RATE 5-8 AMOUNT 9-19;
IF RATE>0 THEN
INTEREST=AMOUNT*(RATE/12);
ELSE PUT 'DATA ERROR' RATE=_N_=;
RUN;_N_计算DATA步骤执行的次数,并且_ERROR_表示错误的发生。检查DATA步骤语句是否存在语法错误,如无效选项或拼写错误。
关键点:
每个SAS语句都以一个分号结尾
在SAS输出中,缺失的数值用句点表示,缺失的字符值保留为空。
在DATA步骤中定义变量的顺序决定了变量在数据集中存储的顺序。
标准字符值可以包含数字,但数值不能包含字符。
每个规范都指定了编写内容、编写方式和编写位置。这可以包括:
一个字符串
PUT 'MY NOTE: THE CONDITION WAS MET.';
OUTPUT:
SAS LOG
MY NOTE: THE CONDITION WAS MET.
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 6 VARIABLES.一个或多个数据集变量
PUT 'MY NOTE: INVALID VALUE'
CODE TYPE;
OUTPUT:
SAS LOG
MY NOTE: INVALID VALUE: V FIXED
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 6 VARIABLES.
# 要在日志中写入变量名及其值,请向变量名添加一个等号(=)。
PUT 'MY NOTE: INVALID VALUE'
CODE= TYPE=;
OUTPUT:
SAS LOG
MY NOTE: INVALID VALUE: CODE=V TYPE=FIXED
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 6 VARIABLES.自动变量_N_和_ERROR_
PUT 'MY NOTE: INVALID VALUE:'
CODE=_N_=_ERROR_=;
OUTPUT:
SASLOG
MY NOTE: INVALID VALUE: CODE=V N=4 ERROR=0
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 6 VARIABLES.自动变量_ALL_
PUT 'MY NOTE: INVALID VALUE: ACCOUNT=101-3144
AMOUNT=$3,500 RATE=10.50% MONTHS=1
CODE=V TYPE=C ERROR=0 N=4'
NOTE: THE DATA SET WORK.TEST HAS 9 OBSERVATIONS
AND 9 VARIABLES.使用INPUT语句进行列输入,列输入只适用于某些情况,当使用列数据时,数据必须为:
标准字符和数值。如果原始数据文件包含非标准值,则需要使用格式化的输入,即另一种类型的输入。
在固定字段中。也就是说,一个特定变量的值必须在所有记录中的同一位置。如果原始数据文件包含非固定字段中的值,则需要使用列表输入。
其他形式的INPUT语句适用于:
非标准数据值,如十六进制、打包十进制、SAS日期值,以及包含美元符号和逗号的货币值
自由格式的数据(非固定字段中的数据)
隐含的小数点
可变长度数据值
可变长度记录
不同的记录类型
关键点:
LIBNAME和FILENAME语句是全局的。LIBRERS和FILEREFS在更改、取消它们或结束SAS会话之前仍然有效。
对于读入SAS数据集的每个原始数据字段,必须在输入语句中指定以下内容:有效的SAS变量名、类型(字符或数字)、开始列,必要时还需要指定结束列。
使用列输入时,可以从原始数据文件中读取任何或所有字段,按任何顺序读取字段,并且仅为值只占固定列的变量指定起始列。
列输入只适用于在某些情况下。在使用列输入时,数据必须是标准字符和数值,并且这些值必须在固定字段中。也就是说,一个特定变量的值必须在所有记录中的同一位置。
程序数据向量(PROGRAM DATA VECTOR):
程序数据向量包含两个自动变量,它们可以用于处理,但它们不会作为观察的一部分写入数据集。
_N_计数数据步骤开始执行的次数。
_ERROR_显示在执行期间出现由数据引起的错误。默认值为0,这表示没有错误。当发生一个或多个错误时,该值将设置为1。
语法错误(SYNTAX ERRORS):
缺少或拼写错误的关键字
无效的变量名
标点符号缺失或无效
无效的选项。
PROC FORMAT STATEMENT:
PROC FORMAT <OPTIONS>;其中选项包括:
LIBRARY=LIBREFS指定SAS数据库的LIBREF,其中包含存储用户定义格式的永久目录
FMTLIB打印格式目录的内容。
每当使用PROC格式创建格式时,该格式都将存储在一个格式目录中。如果SAS数据库尚未包含格式目录,则SAS将自动创建一个格式目录。如果没有指定LIBRARY=选项,则这些格式将存储在名为WORK.FORMAT的默认格式目录中。
正如LIBREF WORK所暗示的,存储在WORK.FORMAT中的任何格式是一种仅存在于当前SAS会话的临时格式。在当前会话结束时,将删除该目录。
在PROC格式语句中指定LIBRARY=选项时,格式将被存储在一个名为“FORMATS”的永久格式目录中。
PROC FORMAT LIBRARY=LIBREF;LIB=可作为LIBRARY=选项的缩写
PROC FORMAT LIB=LIBREF;可使用LIBRARY=选项中指定一个目录名称,并且可以在任何目录中存储格式。目录库名称必须符合SAS的命名约定。
PROC FORMAT LIB=LIBRARY.CATALOG;VALUE STATEMENT:
VALUE FORMAT-NAME
RANGE1='LABEL1'
RANGE2='LABEL2'
...;格式名称命名您正在创建的格式。格式名称
如果该格式适用于字符数据,则必须以美元符号($)开头
不能超过8个字符
不能是现有SAS格式的名称
不能以数字结尾
指定VALUE语句时不会以句点结束
范围指定一个或多个变量值和一个字符串或一个现有的格式
标签是一个用引号括起来的文本字符串
示例语句以关键词VALUE开始,并在定义了所有标签后以分号结束。下面的VALUE语句创建JOBFMT格式来指定稍后将分配给变量JOBTITLE的描述性标签:
PROC FORMAT LIB=LIBRARY;
VALUE JOBFMT;
103='MANAGER'
105='TEXT PROCESSOR'
111='ASSOC. TECHNICAL WRITER'
112='TECHNICAL WRITER'
113='SENIOR TECHNICAL WRITER';
RUN;VALUE范围确定:
一个单一的值,如24或“S”
一系列的数值,如0-1500
用引号括的一系列字符值,如'A'-'M'
用逗号分隔的唯一值的列表,如90、180、270或'B'、'D'、'F'。这些值可以是字符值或数值,但不是字符和数值的组合(因为格式本身是字符或数值)。
当指定的值是字符值时,它们必须用引号括起来,并且必须与变量的值的大小写相匹配。该格式的名称还必须以美元符号($)开头。例如,下面的VALUE语句定义了$GRADE格式,它将字符值显示为文本标签。
PROC FORMAT LIB=LIBRARY;
VALUE $GRADE
'A'='GOD'
'B'-'D'='FAIR'
'F'='POOR'
'I','U'='SEE INSTRUCTOR';
RUN;您可以通过使用小于号(<)来指定一个非包含的数值范围,以避免任何重叠。在本例中,从0到小于13的值的范围被标记为CHILD。下一个范围从13开始,所以标签TEENAGER将被分配到值13到19。
PROC FORMAT LIB=LIBRARY;
VALUE AGEFMT
0-<13='CHILD'
13-<20='TEENAGER'
20-<65='ADULT'
65-<100='SENIOR CITIZEN';
RUN;关键字LOW和HIGH也可被用来指定一个变量的值范围的下限和上限。关键字LOW不包括缺失的数值。关键字OTHER可用于标记缺失的值以及范围内没有专门处理的任何值。
PROC FORMAT LIB=LIBRARY;
VALUE AGEFMT
LOW-<13='CHILD'
13-<20='TEENAGER'
20-<65='ADULT'
65-HIGH='SENIOR CITIZEN'
OTHER='UNKNOWN';
RUN;如果应用于字符格式,则关键字LOW将包含缺失的字符值。
当指定一个用来显示每个范围的标签时:
用引号括起来标签
标签最多为256个字符
如果希望在标签中出现撇号,请使用双引号,如下例所示:
000="EMPLOYEE'S JOBTITLE UNKNOWN";要定义多种格式,可以在单个PROC FORMAT步骤中使用多个值语句。在本示例中,每个值语句都定义了不同的格式。
PROC FORMAT LIB=LIBRARY;
VALUE JOBFMT;
103='MANAGER'
105='TEXT PROCESSOR'
111='ASSOC. TECHNICAL WRITER'
112='TECHNICAL WRITER'
113='SENIOR TECHNICAL WRITER';
VALUE $RESPONSE;
'Y'='YES'
'N'='NO'
'U'='UNDECIDED'
'NOP'='NO OPINION';
RUN;SAS在两个库中搜索格式,以下列顺序:
临时库WORK
被LIBREF指定的永久库LIBRARY
为变量分配FORMAT STATEMENT中的格式:
DATA PERM.EMPINFO;
INFILE EMPDATA;
INPUT @9 FIRSTNAME $5. @1 LASTNAME $7. +7 JOBTITLE 3.
@19 SALARY COMMA9.;
FORMAT SALARY COMMA9.2 JOBTITLE JOBFMT.;PROC REPORT STEP:
PROC REPORT <DATA=SAS-DATA-SET><OPTIONS>;
RUN;WINDOWS或WD,它在窗口模式下调用该过程。您的报告将显示在报告窗口中。这是SAS窗口环境的默认设置。
NOWINDOWS或NOWD,它会在输出窗口中显示报告的列表。
PROC REPORT可以:
创建自定义报告
创建单独的小计和总计
计算列
创建和存储报表定义。
可以以三种方式使用PROC REPORT:
在窗口模式下,使用提示功能,构建报告
在没有提示设施的窗口模式下
在非窗口模式下。在这种情况下,使用PROC REPORT语句提交一系列声明,就如其他SAS过程一样
为您的报表选择列
定义列的用法
指定列的属性、选项和对齐方式
指定列标题的特征,包括分隔字符、下划线和空白行
示例:PROC REPORT使用无窗口模式创建一份报告:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
RUN;默认情况下,PROC REPORT步骤会获得的HTML输出
要选择出现在列表报告中的变量并进行排序,可以使用列语句:
COLUMN STATEMENT:
COLUMN VARIABLE(S);其中,VARIABLE(s)是一个或多个变量名,用空格分隔
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
RUN;要选择观察结果,还可以使用WHERE语句,就像PROC PRINT语句一样
下面的WHERE语句指定只打印变量DEST的值为LON或PAR的观察值
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
WHERE DEST IN ('LON','PAR');
RUN;PROC REPORT显示:
每个数据值其存储在数据集中的方式
变量名称作为报表中的列标题
报告列的默认宽度
字符值左对齐
数值右对齐
按照它们在数据集中存储的顺序进行观察。
DEFINE STATEMENT:
DEFINE VARIABLE / <USAGE> <ATTRIBUTE(S)> <OPTION(S)>
<JUSTIFICATION> <'COLUMN-HEADING'>;其中:
VARIABLE是您要定义的变量的名称。
USAGE指定如何使用该变量。有效的选项包括ACROSS、ANALYSIS、COMPUTED、DISPLAY、GROUP和ORDER
ATTRIBUTE(S)指定变量的属性,包括FORMAT=、WIDTH=和SPACING=
OPTION(S)指定格式化选项,包括DESCENDING、NOPRINT、NOZERO和PAGE
<JUSTIFICATION>指定列对齐(CENTER、LEFT或RIGHT)
“COLUMN-HEADING”指定了列标题的标签。
下列定义语句为变量FLIGHT和ORIG指定属性、用法、选项、对齐方式和列标题。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE FLIGHT/ORDER DECENDING 'FLIGHT NUMBER'
CENTER WIDTH=6 SPACING=5;
DEFINE ORIG/'FLIGHT ORIGIN' CENTER WIDTH=6;
RUN;通过指定变量的属性,您可以轻松地更改PROC REPORT输出的外观。例如,您可以为数据值选择一种格式、指定列的宽度、并指定列之间的间距。
ATTRIBUTE | ACTION |
FORMAT=FORMAT | 为项目指定SAS格式或用户定义的格式。 |
SPACING=HORIZONTAL-POSITIONS | 指定在选定列和左侧的列之间保留多少空白字符。默认值为2。 |
WIDTH=COLUMN-WIDTH | 指定列的宽度。默认的列宽度刚好大到足以处理指定的格式。 |
示例:假设你希望你的收入数字用一个美元符号、逗号和两个小数点后来表示,总宽度为15个位置。为此,您可以将DOLLAR15.2格式分配给“REVENUE”
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FILGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE/FORMAT=DOLLAR15.2;
RUN;如果输入数据集中的变量没有与其关联的格式,则默认的PROC REPORT列宽度为:
字符变量的变量长度
数值变量长度为9
要指定报表中列的宽度,请使用DEFINE语句中的WIDTH=属性。您可以指定从1到LINESIZE=系统选项的值。
要指定适合FLIGHT、ORIG和DEST的列标题的列宽,您可以在PROC REPORT步骤中使用以下定义语句:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6;
DEFINE ORIG / WIDTH=4;
DEFINE DEST / WIDTH=4;
RUN;改善PROC REPORT输出的另一种方法是指定列间距,即所选列和紧邻其左边的列之间的空白字符数。默认的列间距为2。要指定不同的列间距,请使用定义语句中的SPACING=ATTRIBUTE。
SPACING=ATTRIBUTE对HTML输出没有影响.
要在Orig和Dest的列标题前面指定五个空格,您可以使用在PROC REPORT步骤中如下所示的定义语句:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6;
DEFINE ORIG / WIDTH=4 SPACING=5;
DEFINE DEST / WIDTH=4 SPACING=5;
RUN;假设您想将FLIGHT标记为FLIGHT NUMBER,将ORIG标记为FLIGHT ORIGIN,将DEST标记为FLIGHT DESTINATION。将这些列标题添加到定义语句中,以确保与引号相匹配。您还可以更改WIDTH=SPECIFICATIONS,以适应新的标题:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=13 'FLIGHT NUMBER';
DEFINE ORIG / WIDTH=4 SPACING=5 'FLIGHT ORIGIN';
DEFINE DEST / WIDTH=4 SPACING=5 'FLIGHT DESTINATION';
RUN;要控制单词在列标题中分隔的方式,可以在列标签中使用拆分字符。当PROC REPORT在列标题中遇到需要拆分的字符时,它会中断标题并在下一行继续标题。拆分符本身并不会出现在标题中。
若要使用分割字符,您可以执行以下任一操作:
使用默认的斜杠(/)作为分割符。
通过使用PROC REPORT语句中的SPLIT=OPTION来定义拆分字符。
假设您想要修改列标题,以便在一行中只出现一个单词。使用默认斜线作为分割字符,您可以提交此PROC REPORT步骤。请注意,列宽已减小。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6 'FLIGHT/NUMBER';
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN';
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION';
RUN;或者你可以提交这个程序,它使用SPLIT=OPTION,并产生完全相同的输出:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD SPLIT='*';
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6 'FLIGHT*NUMBER';
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT*ORIGIN';
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT*DESTINATION';
RUN;在列表输出的默认情况下,PROC REPORT字符变量向左对齐,数字变量向右对齐。对于您定义的每个变量,您可以在定义语句中指定对齐选项的中心、左或右。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;要完成在列表报告中增强标题的工作,您可以利用PROC REPORT声明中的两个有用的选项:
HEADLINE,它强调了所有的列的标题和它们之间的空格
HEADSKIP,在所有列标题下面输入空行,如果使用HEADLINE选项,则在下划线后面输入空行。
在此PROC报告步骤中,PROC REPORT步骤同时指定HEADLINE和HEADSKIP。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;PROC REPORT以六种方式之一(DISPLAY、ORDER、GROUP、ACROSS、ANALYSIS或COMPUTED)使用每个变量。默认情况下,PROC REPORT使用
字符变量作为DISPLAY VARIABLES
数值变量作为ANALYSIS VARIABLES,用于计算SUM统计量。
字符变量FLIGHT、ORIG和DEST都是DISPLAY VARIABLES。DISPLAY VARIABLES不会影响报表中的行的顺序。包含一个或多个DISPLAY VARIABLES的报告具有针对从数据集读取的每个观察结果的详细信息行。每个详细信息行都包含针对每个显示变量的一个值。
ORDER VARIABLES根据格式化的值对报表中的详细信息行进行排序。例如,假设您希望在按航班号排序的列表报告中的值。要将Flight作为ORDER VARIABLES,请在DEFINE语句中指定ORDER选项,如下所示。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / ORDER WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;OUTPUT:
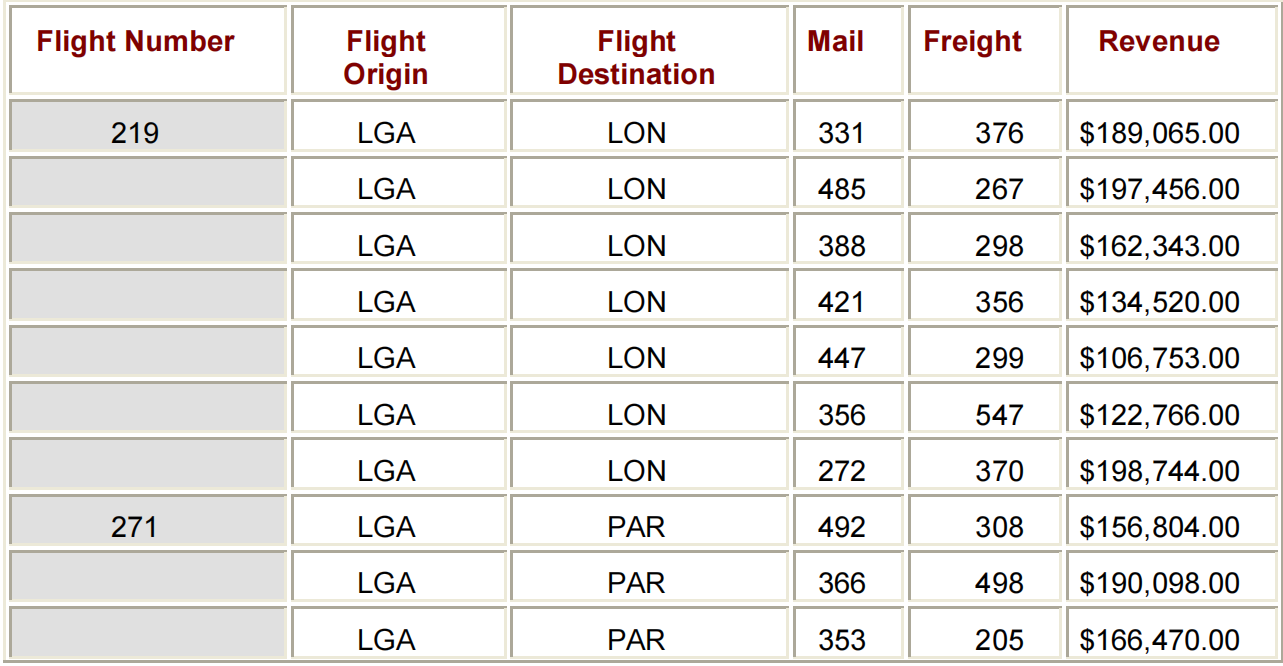
默认是升序,但可以使用DESCENDING改变顺序
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / ORDER DESCENDING WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;摘要报告(SUMMARY REPORT):
若要使用PROC REPORT汇总数据,可以定义一个或多个组变量(GROUP VARIABLES)。组变量根据格式化的值对报表中的详细信息行进行分组。如果一个报告包含一个或多个组变量,那么PROC REPORT会将对所有组变量具有唯一值组合的数据集中的所有观察值合并为一行。
如果您提交以下PROC REPORT步骤,并将FLIGHT定义为一个组变量,将得到如下所示的输出:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / GROUP WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;摘要报告中的所有变量都必须定义为组变量(GROUP)、分析变量(ANALYSIS)、跨变量(ACROSS)或计算(COMPUTED)变量。这是因为PROC REPORT必须能够总结一个观测中的所有变量,以便收缩观测数量。如果PROC REPORT不能创建GROUPS,则它会将组变量显示为顺序变量(ORDER VARIABLES)。
-
下表比较了使用顺序变量和组变量的效果:
EFFECT ON REPORT | ORDER | GROUP |
ROWS ARE ORDERED | YES | YES |
REPETITIOUS PRINTING OF VALUES IS SUPPRESSED | YES | YES |
ROWS THAT HAVE THE SAME VALUES ARE COLLASPED | NO | YES |
TYPE OF REPORT PRODUCED | LIST | SUMMARY |
通过在REVENUE的DEFINE语句中指定MEAN,您可以显示每个航班号的平均收入。可选列标题“AVERAGE REVENUE”声明了将显示MEAN统计信息。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / MEAN FORMAT=DOLLAR15.2 'AVERAGE/REVENUE';
DEFINE FLIGHT / GROUP WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / GROUP WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / GROUP WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;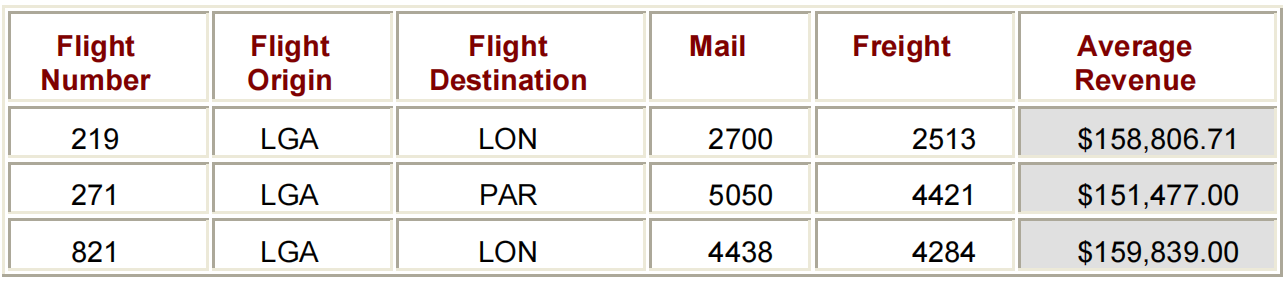
您可以在PROC REPORT中使用以下统计声明:
STATISTIC | DEFINITION |
CSS | CORRECTED SUM OF SQUARES |
USS | UNCORRECTED SUM OF SQUARES |
CV | COEFFICIENT OF VARIATION (变异系数) |
MAX | MAXIMUM VALUE |
MEAN | AVERAGE |
MIN | MINIMUM VALUE |
N | NUMBER OF OBSERVATIONS WITH NONMISSING VALUES |
NMISS | NUMBER OF OBSERVATIONS WITH MISSING VALUES |
RANGE | RANGE |
STD | STANDARD DEVIATION |
STDERR | STANDARD ERROR OF THE MEAN |
SUM | SUM |
SUMWGT | SUM OF THE WEIGHT VARIABLE VALUES |
PCTN | PERCENTAGE OF A CELL OR ROW FREQUENCY TO A TOTAL FREQUENCY |
PCTSUM | PERCENTAGE OF A CELL OR ROW SUM TO A TOTAL SUM |
VAR | VARIANCE |
T | STUDENT'S T FOR TESTING THE HYPOTHESIS THAT THE POPULATION MEAN IS 0 |
PRT | PROBABILITY OF A GREATER ABSOLUTE VALUE OF STUDENT'S T |
ACROSS VARIABLES在功能上与GROUP VARIABLES相似,但是PROC REPORT过程步水平地显示为ACROSS VARIABLES创建的组而不是竖直的。
示例:
下面的程序使用GROUP VARIABLES来生成如图所示的输出。该表显示了GROUP VARIABLES的值的独特组合,以及每个组合的每个分析变量的总和。
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT ORIG DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / GROUP WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE ORIG / GROUP WIDTH=6 SPACING=5 'FLIGHT/ORIGIN' CENTER;
DEFINE DEST / GROUP WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;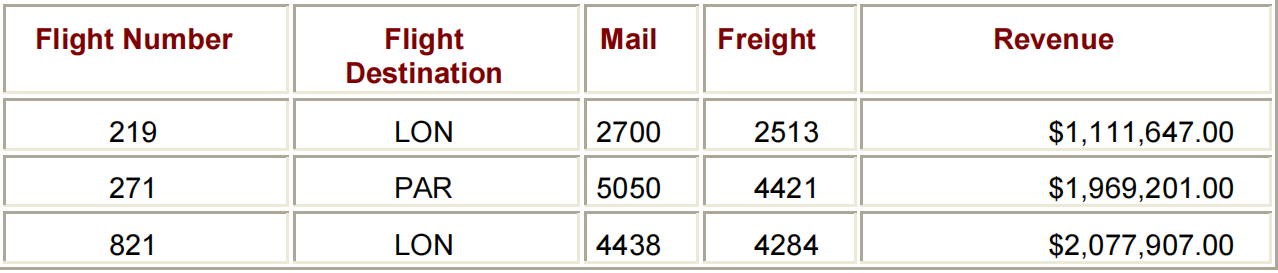
假设将GROUP VARIABLES更改为ACROSS VARIABLES,如在这个程序中:
PROC REPORT DATA=FLIGHTS.EUROPE NOWD HEADLINE HEADSKIP;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT DEST MAIL FREIGHT REVENUE;
DEFINE REVENUE / FORMAT=DOLLAR15.2;
DEFINE FLIGHT / ACROSS WIDTH=6 'FLIGHT/NUMBER' CENTER;
DEFINE DEST / ACROSS WIDTH=11 SPACING=5 'FLIGHT DESTINATION' CENTER;
RUN;
计算变量是为报表定义的数值变量或字符变量。它们不在输入数据集中,而且PROC REPORT也不将它们添加到输入数据集中。您不能更改一个COMPUTED VARIABLE。
在非窗口环境中,可以添加如下计算变量的用法:
在列语句中包含COMPUTED VARIABLE
在DEFINE语句中将变量定义为COMPUTED VARIABLE
计算与该变量相关联的计算块中的变量的值
计算变量的位置很重要。PROC REPORT从左到右为报告行中的列分配值。因此,计算变量的计算不能基于报告中右侧出现的任何变量
使用ENDCOMP语句关闭计算块。
示例:
假设您要确定每个航班的空座位数。为此,可以假设飞机已满,从飞机总座位(CAPCITY)减去下降的乘客数量(DEPLANED)来计算变量EMPTYSEATS
PROC REPORT DATA=FLIGHTS.EUROPE NOWD;
WHERE DEST IN ('LON','PAR');
COLUMN FLIGHT CAPCITY DEPLANED EMPTYSEATS;
DEFINE FLIGHT / WIDTH=6;
DEFINE EMPTYSEATS / COMPUTED 'EMPTY SEATS';
COMPUTE EMPTYSEATS;
EMPTYSEATS=CAPCITY.SUM-DEPLANED.SUM;
ENDCOMP;
RUN;VARIABLE USAGE IN PROC REPORT:
VARIAABLE USAGE IN PROC REPORT | |
DISPLAY VARIABLES | 不影响报表中的行的顺序。包含一个或多个DISPLAY VARIABLES的报告对数据集中的每个观察结果都有一个详细信息行。每个详细信息行都包含每个显示变量的一个值。默认情况下,PROC REPORT将所有字符变量视为DISPLAY VARIABLES。 |
ORDER VARIABLES | 根据格式化的值对报表中的详细信息行进行排序。 |
GROUP VARIABLES | 根据格式化的值对报表中的详细信息行进行排序。如果一个报告包含一个或多个GROUP VARIABLES,则PROC REPORT会尝试将数据集中的所有观测值组合合并为一行。 |
ACROSS VARIABLES | 在功能上与GROUP VARIABLES相似;然而,PROC REPORT显示它为ACROSS VARIABLES水平地而不是垂直地创建的组。 |
ANALYSIS VARIABLES | 用于计算一个统计量。默认情况下,PROC REPORT使用数字变量作为分析变量,用于计算SUM统计量。 |
COMPUTED VARIABLES | 是您为报表定义的变量。它们不在数据集中。您不能更改已计算变量的用法。计算出的变量可以是数字变量或字符变量。 |
关键点:
对于HTML输出,FORMAT=OPTION不能将单元格宽度增加到超过单元格值的宽度。WIDTH=和SPACING=ATTRIBUTES,以及HEADSKIP和HEADLINE,对HTML输出没有影响
您可以使用默认的斜杠(/)作为拆分字符,也可以使用PROC REPORT语句中的SPLIT=OPTION指定拆分字符
如果您想要描述的数据值是连续的数值(例如,人们的年龄),那么您可以使用SUMMARY过程或MEANS过程来计算统计数据,如平均值、总和、最小值和最大值。
如果您想要描述的数据值是离散的(例如,人们的眼睛的颜色),那么您可以使用FREQ过程来显示这些值的分布,如百分比和计数。
平均过程可以包括许多用于指定所需统计信息的语句和选项。为简单起见,让我们考虑一下这个过程的基本形式。
MEANS PROCEDURE:
PROC MEANS <DATA=SAS-DATA-SET>
<STATISTIC-KEYWORD(S)><OPTION(S)>;
RUN;MEAN(X1,X2,X3);
MEAN(OF X1-X3);
MEAN(OF NEWARRAY{*});
MEAN(X1-X3) # 该变量计算的是X1-X3的平均值而不是变量X1,X2,X3的平均值其中:
STATISTIC-KEYWORD(S)指定要计算的统计信息
OPTION(S)控制输出的内容、分析和外观。
在其最简单的形式中,PROC MEANS打印数据集中每个数字变量的N-COUNT(非缺失值的数量)、MEAN、STD DEV、MIN和MAX。
PROC MEANS DATA=PERM.SURVEY;
RUN;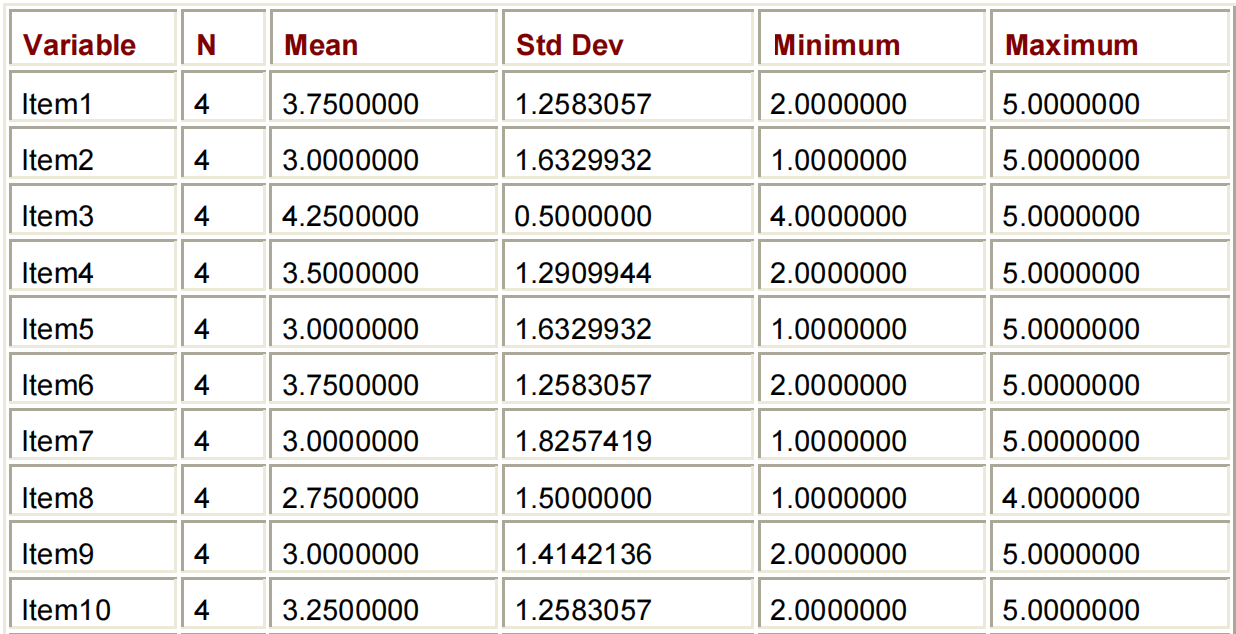
MEANS过程产生的默认统计信息(N-COUNT、MEAN、STANDARD DEVIATION、MINIMUM和MAXIMUM)并不总是您所需要的。您可能只希望将输出这些值的平均值。或者,您可能需要计算一个不同的统计数据,比如值的中值或范围。
为了细化这些统计,请在PROC MEANS语句中指定包含统计信息关键字作为选项。当您在PROC MEANS语句中指定一个统计信息时,将不会生成默认的统计信息。例如,要查看PERM.SURVEY的中位数和范围,可以添加MEDIAN和RANGE关键字作为选项。
PROC MEANS DATA=PERM.SURVEY MEDIAN RANGE;
RUN;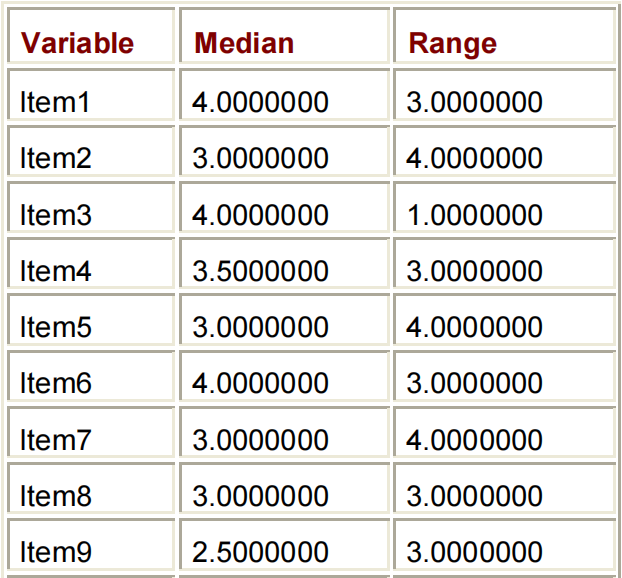
以下关键字可与PROC MEANS一起使用来计算统计数据:
DESCRIPTIVE STATISTICS | |
KEYWORD | DESCRIPTION |
CLM | TWO-SIDED CONFIDENCE LIMIT FOR THE MEAN |
CSS | CORRECTED SUM OF SQUARES |
CV | COEFFICIENT OF VARIATION |
KURTOSIS / KURT | KURTOSIS |
LCLM | ONE-SIDED CONFIDENCE LIMIT BELOW THE MEAN |
MAX | MAXIMUM VALUE |
MEAN | AVERAGE |
MIN | MINIMUM VALUE |
N | NUMBER OF OBSERVATIONS WITH NON-MISSING VALUES |
NMISS | NUMBER OF OBSERVATIONS WITH MISSING VALUES |
RANGE | RANGE |
SKEWNESS / SKEW | SKEWNESS |
STDDEV / STD | STANDARD DEVIATION |
STDERR / STDMEAN | STANDARD ERROR OF THE MEAN |
SUM | SUM |
SUMWGT | SUM OF THE WEIGHT VARIABLE VALUES |
UCLM | ONE-SIDED CONFIDENCE LIMIT ABOVE THE MEAN |
USS | UNCORRECTED SUM OF SQUARES |
VAR | VARIANCE |
-
QUANTILE STATISTIC | |
KEYWORD | DESCRIPTION |
MEDIAN / P50 | MEDIAN OR 50TH PERCENTILE |
P1 | 1ST PERCENTILE |
P5 | 5TH PERCENTILE |
P10 | 10TH PERCENTILE |
Q1 / P25 | LOWER QUARTILE OR 25TH PERCENTILE |
Q3 / P75 | UPPER QUARTILE OR 75TH PERCENTILE |
P90 | 90TH PERCENTILE |
P95 | 95TH PERCENTILE |
P99 | 99TH PERCENTILE |
QRANGE | DIFFERENCE BETWEEN UPPER AND LOWER QUARTILES: Q3 - Q1 |
HYPOTHESIS TESTING | |
KEYWORD | DESCRIPTION |
PROBT | PROBABILITY OF A GREATER ABSOLUTE VALUE FOR THE T VALUE |
T | STUDENT'S T FOR TESTING THE HYPOTHESIS THAT THE POPULATION MEAN IS 0 |
要限制PROC MEANS过程输出的小数点,请使用PROC MEANS语句中的MAXDEC=选项,并将其设置为您喜欢的长度
PROC TRANSPOSE:
PROC TRANSPOSE <DATA=INPUT-DATA-SET> <DELIMITER=DELIMITER> <LABEL=LABEL>
<LET> <NAME=NAME> <OUT=OUTPUT-DATA-SET> <PREFIX=PREFIX> <SUFFIX=SUFFIX>;
BY <DESCENDING> VARIABLE-1
<<DESCENDING> VARIABLE-2>
<NOTSORTED>;
COPY VARIABLE(S);
ID VARIABLE;
IDLABEL VARIABLE;
VAR AVRIABLE(S);
# BY指定转置后的列标题
# ID指定转置后的行标题
# VAR指定输出内容PROC MEANS STATEMENT WITH MAXDEC= OPTION:
PROC MEANS <DATA=SAS-DATA-SET>
<STATISTIC-KEYWORD(S)> MAXDEC=N;其中,N指定小数点后位的最大数目。
要指定PROC MEANS过程分析的变量,请添加VAR语句并列出变量名称。
PROC MEANS DATA=WORK.CLEANDATA36 MEDIAN;
CLASS GROUP;
VAR KILOGRAMS;
RUN;
# 根据不同的GROUP,分别得到变量KILOGRAMS的中位数值VAR STATEMENT:
VAR VARIABLE(S);其中,VARIABLE(S)列出了要为此其计算统计数据的数字变量。
除了单独列出变量外,您还可以使用一个有编号的变量范围。
PROC MEANS DATA=PERM.SURVEY MEAN STDERR MAXDEC=2;
VAR ITEM1-ITEM4;
RUN;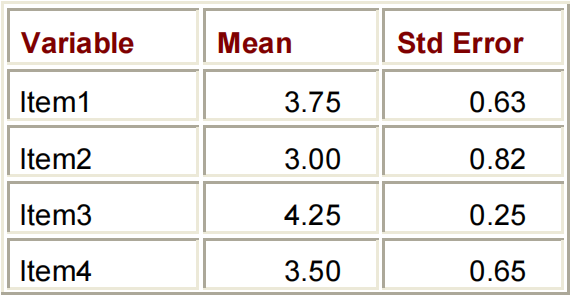
在PROC MEANS过程时,您通常需要分组观测的统计数据,而不是作为整体观测。例如,当按地区分组时,人口普查数字比按全国总数分组时更有用。要对分组的观察结果进行单独的分析,请在MEANS过程中添加一个CLASS语句。
CLASS STATEMENT:
CLASS VARIABLE(S);其中,VARIABLE(S)指定了用于组处理的类别变量。
PROC MEANS不为类变量生成统计信息,因为它们的值仅用于对数据进行分类。CLASS变量可以是字符或数字,但它们应该包含有限数量的离散值,它们表示有意义的分组。
下面所示的程序的输出按变量SURVIVE和SEX的值进行分类。CLASS语句中的变量的顺序决定了它们在输出表中的顺序。
PROC MEANS DATA=CLINIC.HEART MAXDEC=1;
VAR ARTERIAL HEART CARDIAC URINARY;
CLASS SURVIVE SEX;
RUN;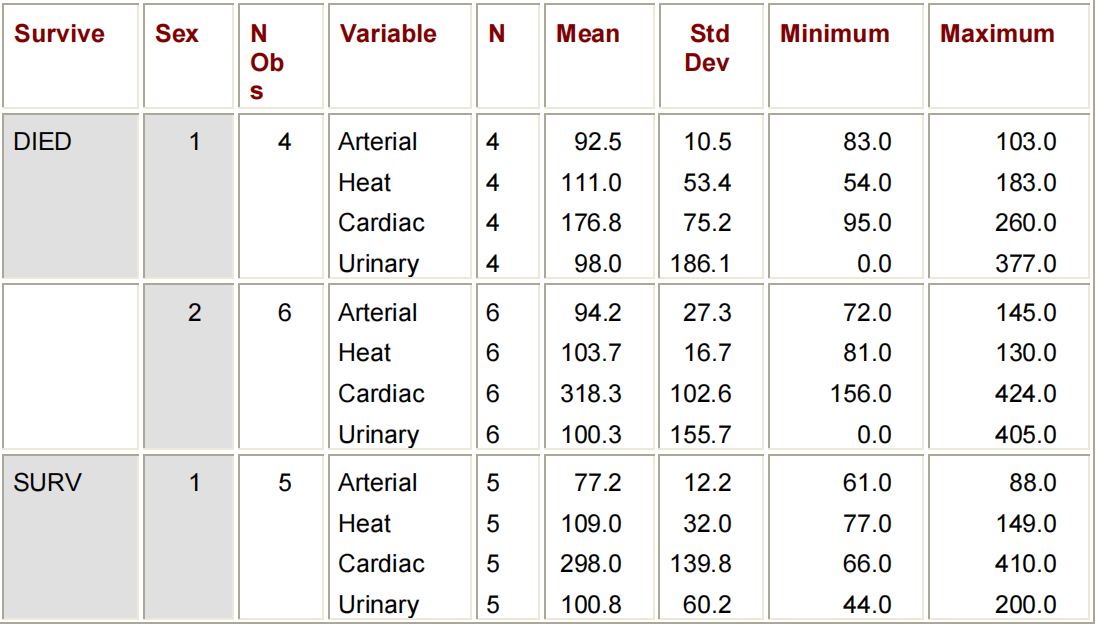
与CLASS语句一样,BY语句也指定了用于对观察结果进行分类的变量:
BY STATEMENT:
BY VARIABLE(S);BY和CLASS语句在两个关键方面有所不同:
与CLASS语句不同,BY语句要求数据已经按照BY变量的顺序进行排序或索引。除非已经对数据集的观察结果进行了排序,否则在对任何BY组使用PROC MEANS之前,将需要运行SORT过程
在排序数据集以启用组处理时要小心。如果没有使用OUT=OPTION来指定输出数据集,那么PROC SORT将用新排序的观察结果覆盖您的初始数据集,将会永久覆盖。
BY组结果的布局不同于CLASS组结果的布局。请注意,下面程序中的BY语句创建了四个小表;CLASS语句将生成一个大表。
PROC SORT DATA=CLINIC.HEART OUT=WORK.HEARTSORT;
BY SURVIVE SEX;
RUN;
PROC MEANS DATA=WORK.HEARTSORT MAXDEC=1;
VAR ARTERIAL HEART CARDIAC URINARY;
BY SURVIVE SEX;
RUN;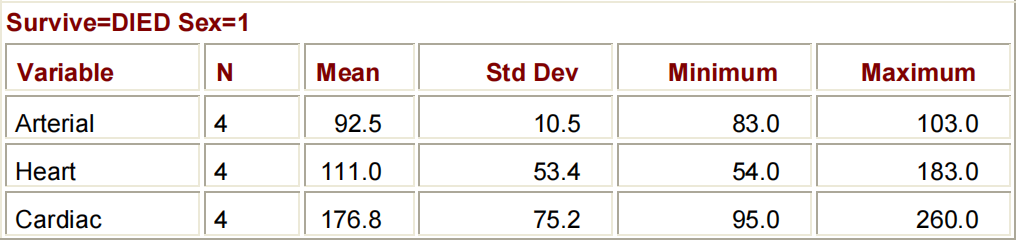
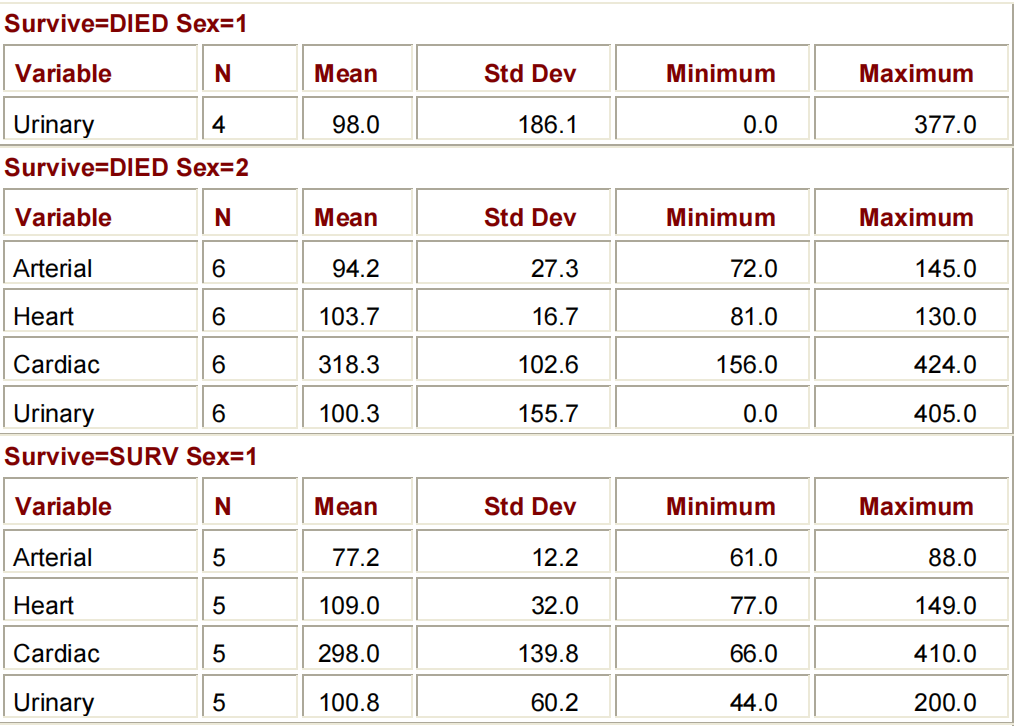
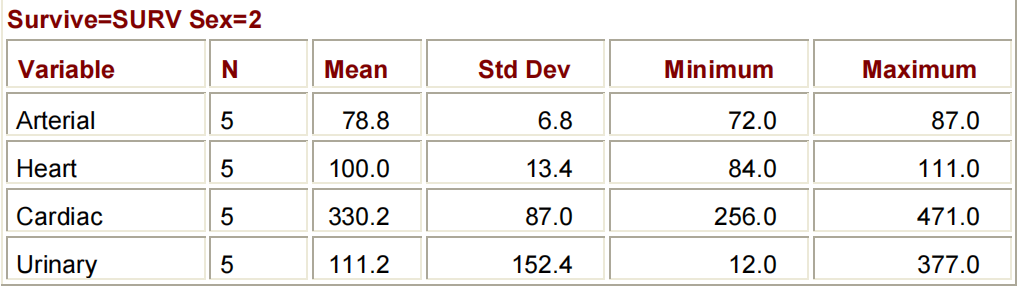
您可能希望创建一个只包含汇总变量的输出SAS数据集。您可以通过使用PROC MEANS中的OUTPUT语句来实现这一点。
OUTPUT STATEMENT:
OUTPUT OUT=SAS-DATA-SET <STATISTIC-KEYWORD=VARIABLE-NAME(S)>;STATISTIC-KEYWORD=指定要写入的汇总统计信息
VARIABLE-NAME(S)指定将创建以包含汇总统计量值的变量的名称。这些变量对应于VAR语句中列出的分析变量
当您使用不指定STATISTIC-KEYWORD=OPTION而使用OUTPUT语句时,将会为所有数字变量或VAR语句中列出的所有变量生成汇总统计信息N、MEAN、STD、MIN和MAX。
下面的程序创建一个典型的PROC MEANS报告,并创建一个只包含MEAN和MIN统计数据的汇总输出数据集:
PROC MEANS DATA=CLINIC.DIABETES;
VAR AGE HEIGHT WEIGHT;
CLASS SEX;
OUTPUT OUT=WWORK.SUM_GENDER;
MEAN=AVGAGE AVGHEIGHT AVGWEIGHT
MIN=MINAGE MINHEIGHT MINWEIGHT;
RUN;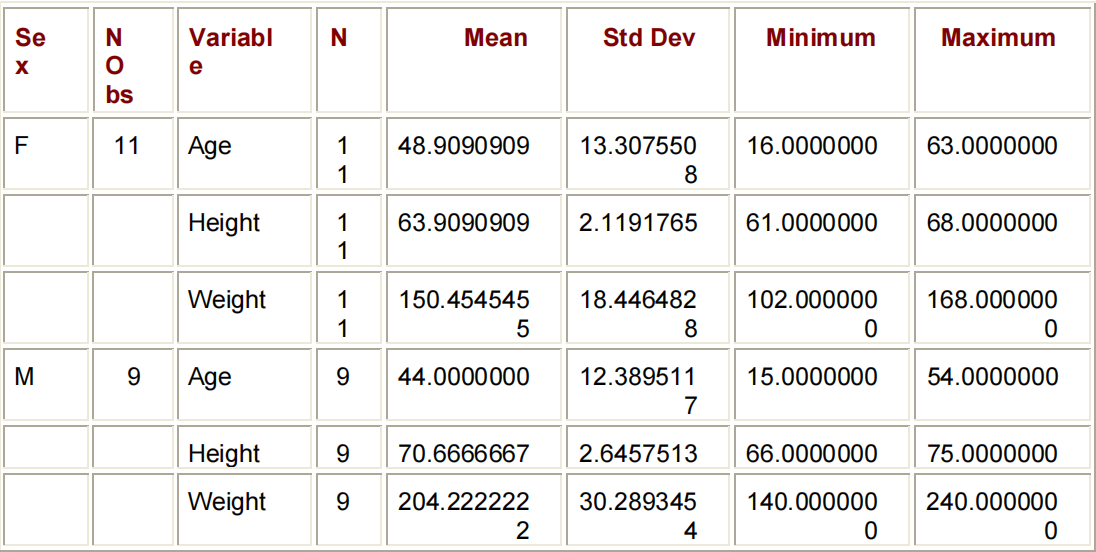
要查看输出数据集的内容,请提交以下PROC PRINT步骤:
PROC PRINT DATA=WORK.SUM_GENDER;
RUN;
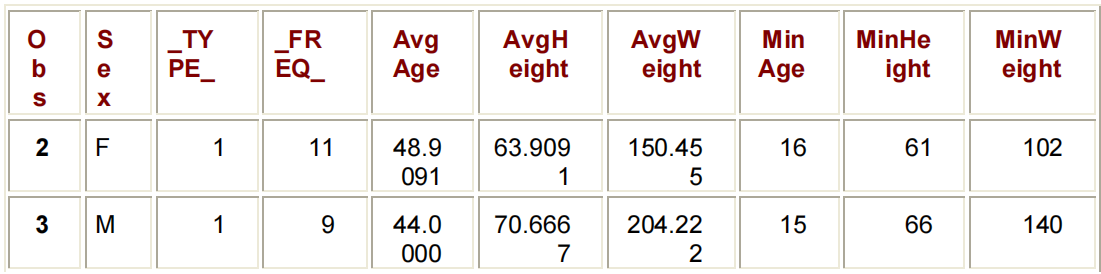
您还可以使用SUMMARY过程创建汇总输出数据集。当您使用PROC SUMMARY时,您将使用相同的代码来生成与PROC方法一起使用的输出数据集
这两个过程的不同之处在于PROC MEANS在默认情况下生成报告(记住,您可以使用NOPRINT选项来抑制默认报告)。相比之下,要在PROC SUMMARY中生成报告,您必须在PROC SUMMARY语句中包含一个PRINT选项
以下示例将创建一个输出数据集,但并不创建一个报告:
PROC SUMMARY DATA=CLINIC.DIABETES;
VAR AGE HEIGHT WEIGHT;
CLASS SEX;
OUTPUT OUT=WORK.SUM_GENDER
MEAN=AVGAGE AVGHEIGHT AVGWEIGHT;
RUN;如果您在上面的PROC SUMMARY语句中放置了一个PRINT选项,这个程序将产生相同的报告,如果您将单词SUMMARY替换为MEANS:
PROC MEANS DATA=CLINIC.DIABETES;
VAR AGE HEIGHT WEIGHT;
CLASS SEX;
OUTPUT OUT=WORK.SUM_GENDER
MEAN=AVGAGE AVGHEIGHT AVGWEIGHT;
RUN;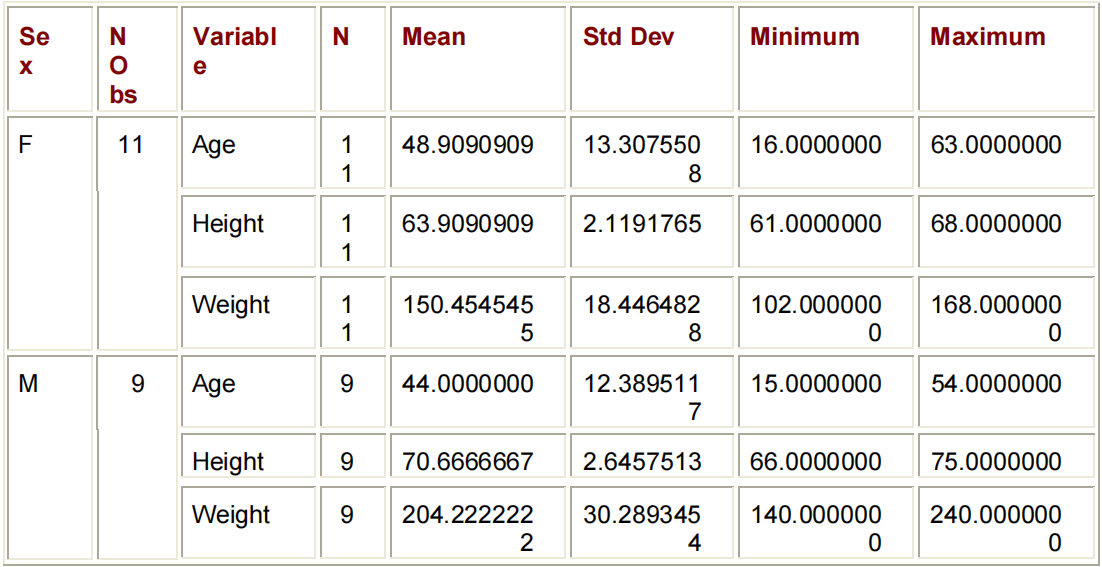
FREQ过程是一个描述性程序和一个统计程序。它生成ONEWAY和N-WAY频率表,并通过报告变量值的分布来简洁地描述数据。您可以使用FREQ过程来创建交叉统计表,通过显示每个变量值组合的观察数来汇总两个或多个分类变量的数据。
FREQ PROCEDURE:
PROC FREQ <DATA=SAS-DATA-SET>;
RUN;默认情况下,PROC FREQ将创建一个单向表(ONE-WAY TABLE),其中包含数据集中所有变量的每个值的频率(FREQUENCY)、百分比(PERCENT)、累积频率(CUMULATIVE FREQUENCY)和累积百分比(CUMULATIVE PERCENT)。
PROC FREQ DATA=CLINIC.DIABETES;
TABLES SEX*WEIGHT*HEIGHT / CROSSLIST;
RUN;
# TABLES语句的CROSSLIST选项以ODS列格式显示交叉统计表。此选项创建一个表定义,可以使用TEMPLATE过程自定义。
PROC FREQ DATA=CLINIC.DIABETES;
TABLES SEX*WEIGHT*HEIGHT / LIST;
RUN;
# 在PROC FREQ步骤中的TABLES语句中添加一个斜杠(/)和LIST选项,可以生成交叉稳定的列表输出。VARIABLE | FREQUENCY | PERCENT | CUMULATIVE FREQUENCY | CUMULATIVE PERCENT |
VALUE | 具有值的观测数量 | 某个值的观测数占总数百分比 | 该值的频数计数和其他值的频数计数 | 该值的累计频率除以观测总数 |
PROC FREQ DATA=PARTS.WIDGETS;
RUN;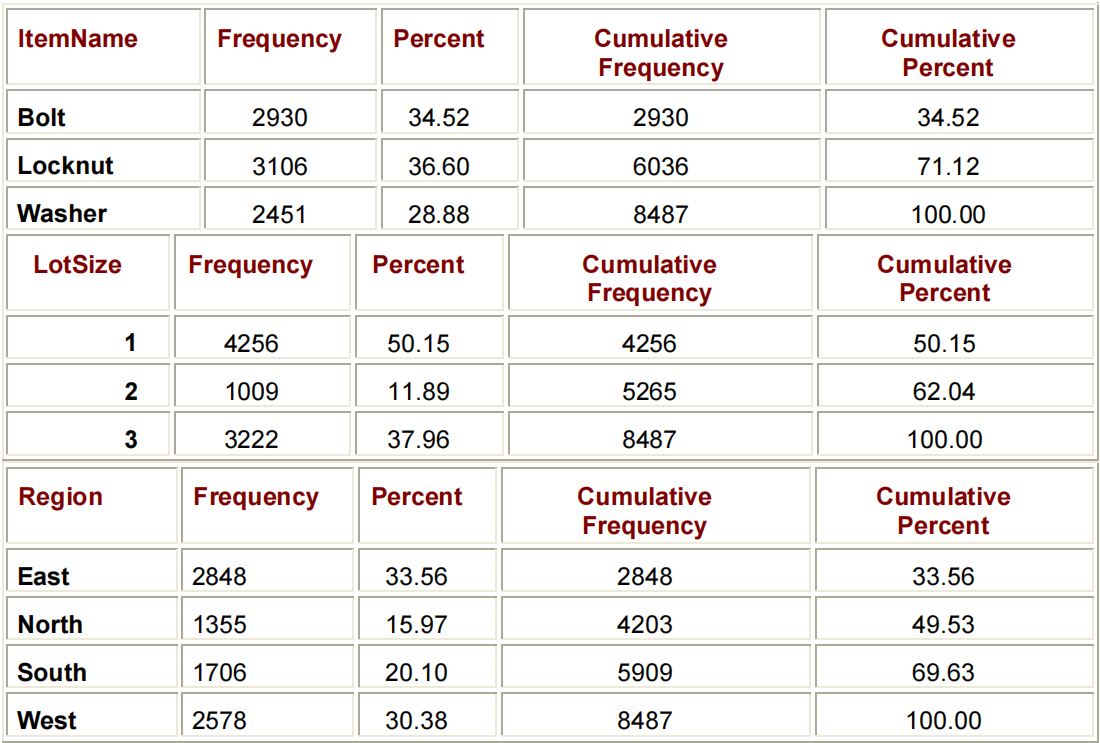
TABLES STATEMENT:
TABLES VARIABLE(S);PROC FREQ DATA=PERM.SURVEY;
TABLES ITEM1-TIEM3;
RUN;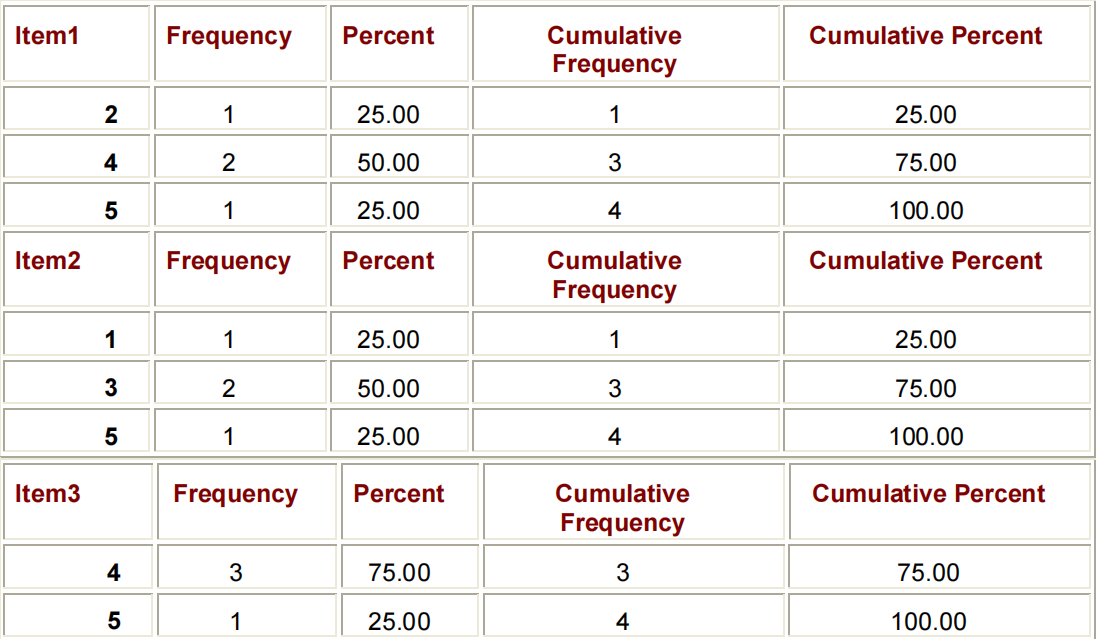
将NOCUM选项添加到TABLES语句中,将不会在单向频率表(ONE-WAY FREQUENCY)和列表输出中显示累积频率和累积百分比。NOCUM选项的语法如下所示:
TABLES VARIABLE(S) / NOCUM最简单的交叉统计方法是一个双向表(TWO-WAY)。要创建一个双向表,请在PROC FREQ步骤的表语句中使用星号(*)连接两个变量。
TABLES STATEMENT FOR CROSSTABULATION:
TABLES VARIABLE-1*VARIABLE-2<*...VARIABLE-N>;变量的顺序很重要。在N-WAY表中,TABLES语句的最后两个变量成为双向行和列。表语句中最后两个变量之前的变量会对交叉统计表进行分层。
从SAS 9开始,将CROSSLIST选项添加到TABLES语句中,将以ODS列格式显示交叉统计表。此选项创建一个表定义,可以使用TEMPLATE过程自定义。
PROC FORMAT;
VALUE WTFMT LOW-139='<140'
140-180='140-180'
181-HIGH='>180';
VALUE HTFMT LOW-64='<5''5"'
65-70='5''5-10"'
71-HIGH='>5''10"';
RUN;
PROC FREQ DATA=CLINIC.DIABETES;
TABLES SEX*WEIGHT*HEIGHT / CROSSLIST;
FORMAT WEIGHT WTFMT. HEIGHT HTFMT.;
RUN;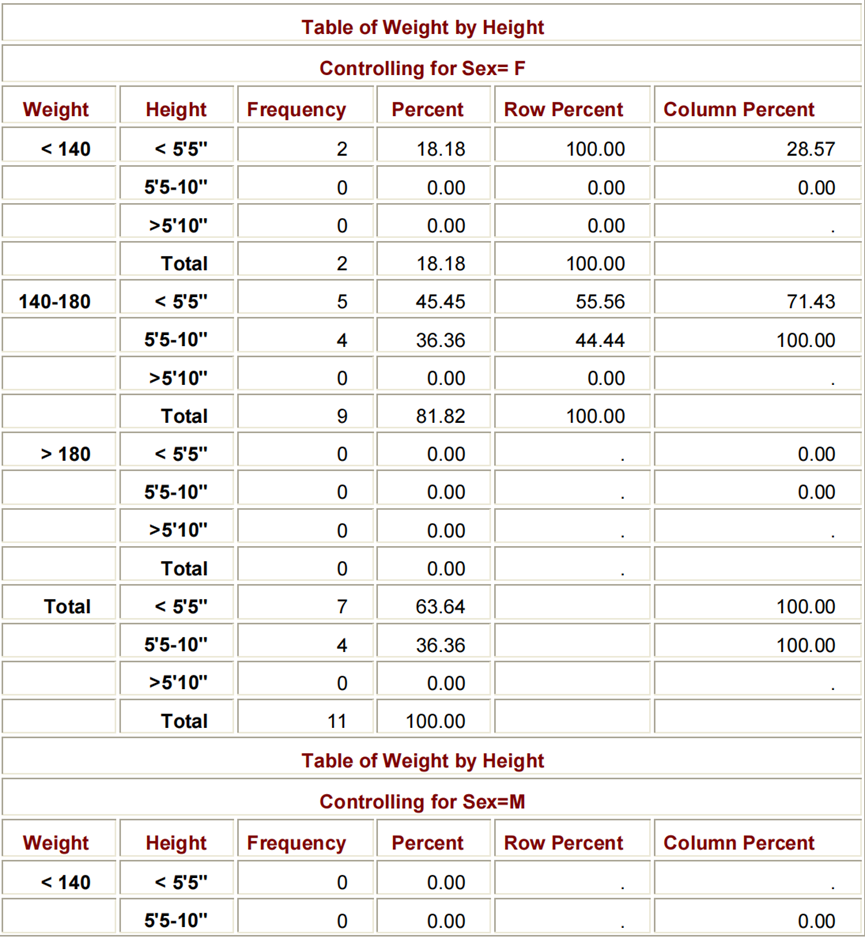
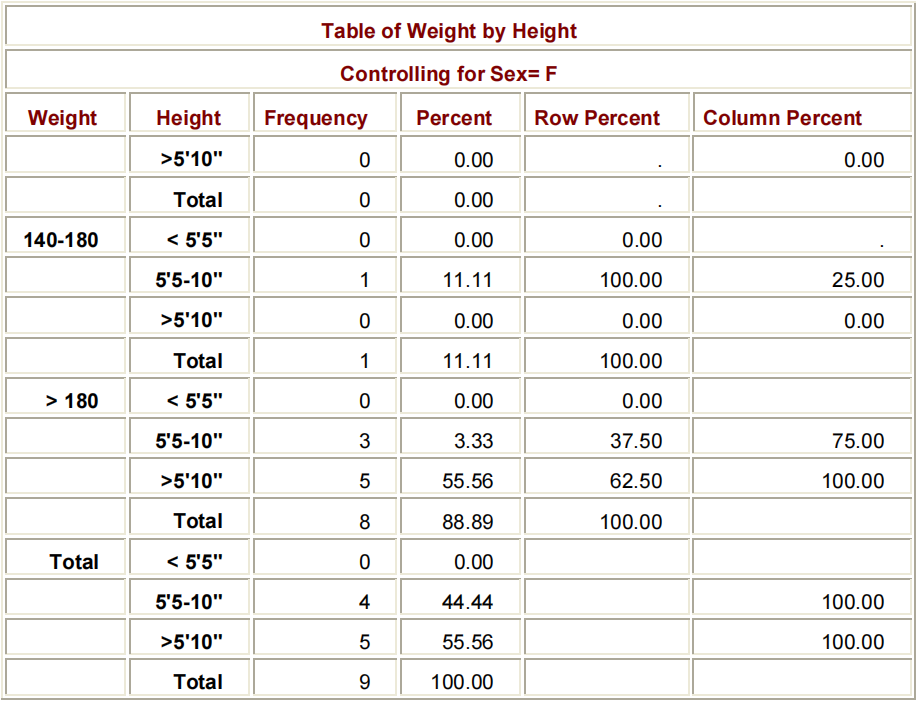
当指定了三个或更多的变量时,N-WAY表的多个级别可以产生大量的输出。这种庞大、通常复杂的交叉稳定通常更容易解读为一个连续的列表。虽然这消除了行和列的频率和百分比,但结果是紧凑和清晰的。
若要生成交叉稳定的列表输出,请在PROC FREQ步骤中的TABLES语句中添加一个斜杠(/)和LIST选项。
TABLES VARIABLE-1*VARIABLE-2 <*...VARIABLE-N> / LIST;添加列表选项到CLINIC.DIABETES项目将该项目的频率放在一个简单、简短的表格中。
PROC FORMAT;
VALUE WTFMT LOW-139='<140'
140-180='140-180'
181-HIGH='>180';
VALUE HTFMT LOW-64='<5''5"'
65-70='5''5-10"'
71-HIGH='>5''10"';
RUN;
PROC FREQ DATA=CLINIC.DIABETES;
TABLES SEX*WEIGHT*HEIGHT / LIST;
FORMAT WEIGHT WTFMT. HEIGHT HTFMT.;
RUN;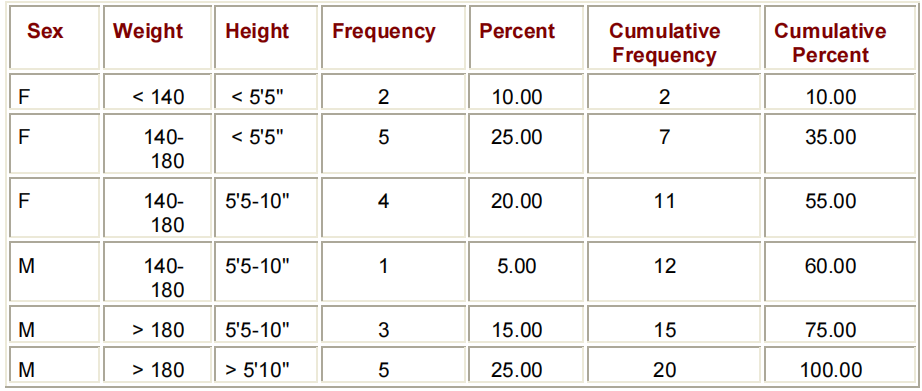
可以使用选项来控制输出的这些统计信息。要控制交叉统计结果,可在表语句中添加一个斜杠(/)和以下选项的任意组合:
NOFREQ不显示频率
NOPERCENT不显示百分数
NOROW不显示行百分比
NOCOL不显示列百分数
PROC FORMAT;
VALUE WTFMT LOW-139='<140'
140-180='140-180'
181-HIGH='>180';
RUN;
PROC FREQ DATA=CLINIC.DIABETES;
TABLES SEX*WEIGHT / NOFREQ NOROW NOCOL;
FORMAT WEIGHT WTFMT.;
RUN;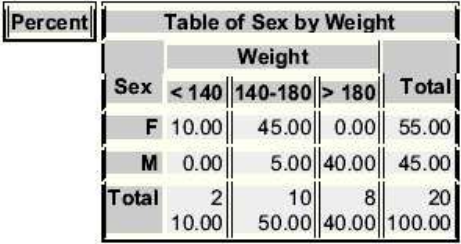
您可以使用ODS语句为输出指定DESTINATIONS。每个目标都会创建一个特定类型的格式化输出。下表列出了受支持的ODS DESTINATION
THIS DESTINATIONS... | PRODUCES... |
HTML | HyperText Markup Language(SAS Enterprise Guide默认输出格式) |
LISTING | traditional output |
MARKUP LANGUAGE FAMILY | 使用标记语言(如可扩展标记语言(XML))进行格式化的输出 |
ODS DOCUMENT | 输出对象的层次结构,使您能够渲染多个ODS输出,而无需重新运行输出过程 |
OUTPUT | SAS数据集 |
PRINTER FAMILY | 为高分辨率打印机格式化的输出,如PostScript(PS)、便携式文档格式(PDF)或打印机控制语言(PCL)文件 |
RTF | 与微软Word一起使用的富文本格式输出 |
ODS STATEMENT TO OPEN AND CLOSE DESTINATIONS:
ODS OPEN-DESTINATION;
ODS CLOSE-DESTINATION CLOSE;
ODS _ALL_ CLOSE;OPEN-DESTINATION是一个关键字和您想要创建的输出类型的任何必需的选项,例如
HTML FILE='HTML-FILE-PATHNAME'
LISTING
CLOSE-DESTINATION是输出类型的关键字
LISTING | 标准SAS输出 |
OUTPUT | SAS输出数据集 |
HTML | 超文本标记语言 |
RTF | 富文本格式 |
PRINTER | 高分辨率的打印机输出(PS,PCL,PD) |
PS | 附言 |
PCL | 打印机控制语言 |
MARKUP | 包括XML |
DOCUMENT | 文档 |
以下程序生成HTML并列出输出:
ODS HTML BODY='C:\MYDATA.HTML';
PROC PRINT DATA=SASUSER.MYDATA;
RUN;
ODS HTML CLOSE;如您所了解的,LISTING DESTINATION默认是打开的。因为OPTN DESTINATIONS使用系统资源,所以如果您不想产生清单输出,最好在程序开始时关闭列表目标。下面是一个示例:
ODS LISTING CLOSE;在结束当前SAS会话或重新打开目标之前,LISTING目标将一直处于关闭状态。在程序结束时重新将ODS设置为列出输出(默认设置)是一个很好的编程实践。下面是一个示例:
ODS LISTING;下面的程序只产生HTML输出:
ODS LISTING CLOSE;
ODS HTML BODY='C:\MYDATA.HTML';
PROC PRINT DATA=SASUSER.MYDATA;
RUN;
ODS HTML CLOSE;
ODS LISTING;当您有多个打开的ODS DESTINATIONS时,您可以使用ODS CLOSE语句中的关键字_ALL_来同时关闭所有打开的DESTINATIONS。
下面的程序在PROC步骤之前打开HTML和PDF DESTINATIONS,并在程序结束时关闭所有ODS DESTINATIONS:
ODS HTML FILE='HTML-FILE-PATHNAME';
ODS PDF FILE='PDF-FILE-PATHNAME';
PROC PRINT DATA=SASUSER.ADMIT;
RUN;
ODS _ALL_ CLOSE;
ODS LISTING;ODS HTML STATEMENT:
ODS HTML BODY=FILE-SPECIFICATION;
ODS HTML CLOSE;ODS LISTING CLOSE;
ODS HTML BODY='F:\ADMIT.HTML';
PROC PRINT DATA=CLINIC.ADMIT LABEL;
VAR SEX AGE HEIGHT WEIGHT ACTLEVEL;
LABEL ACTLEVEL='ACTIVITY LEVEL';
RUN;
ODS HTML CLOSE;
ODS LISTING;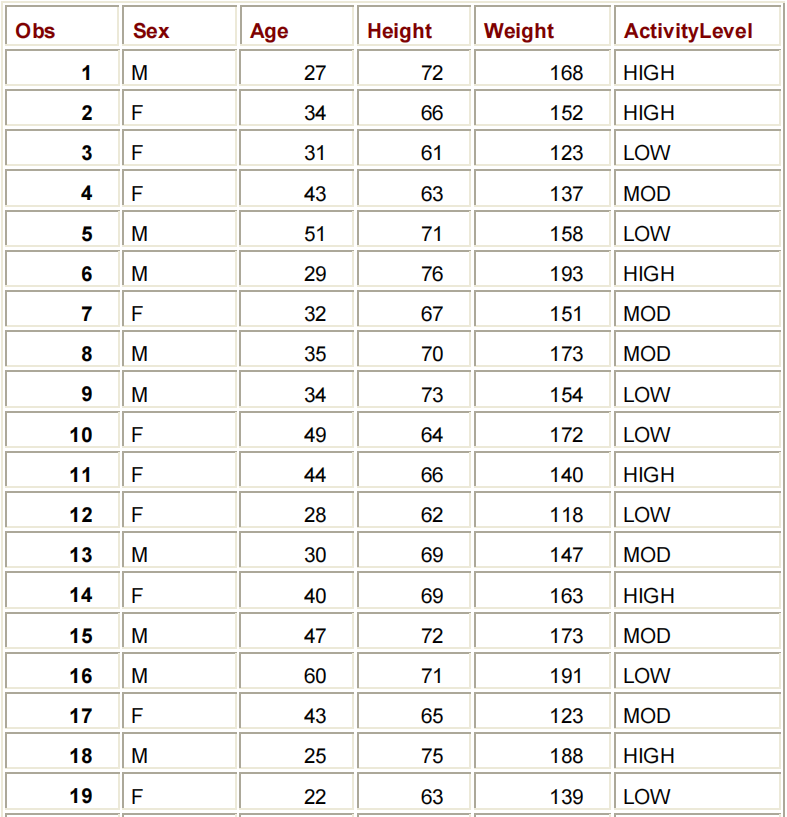
下面的程序为PRINT和TABULATE的过程生成HTML输出。这两个过程的结果都被保存到文件C:\Records\data.html中(在窗口操作系统中)。
ODS LISTING CLOSE;
ODS HTML BODY='C:\RECORDS\DATA.HTML';
PROC PRINT DATA=CLINIC.ADMIT LABEL;
VAR ID SEX AGE HEIGHT WEIGHT ACTLEVEL;
LABEL ACTLEVEL='ACTIVITY LEVEL';
RUN;
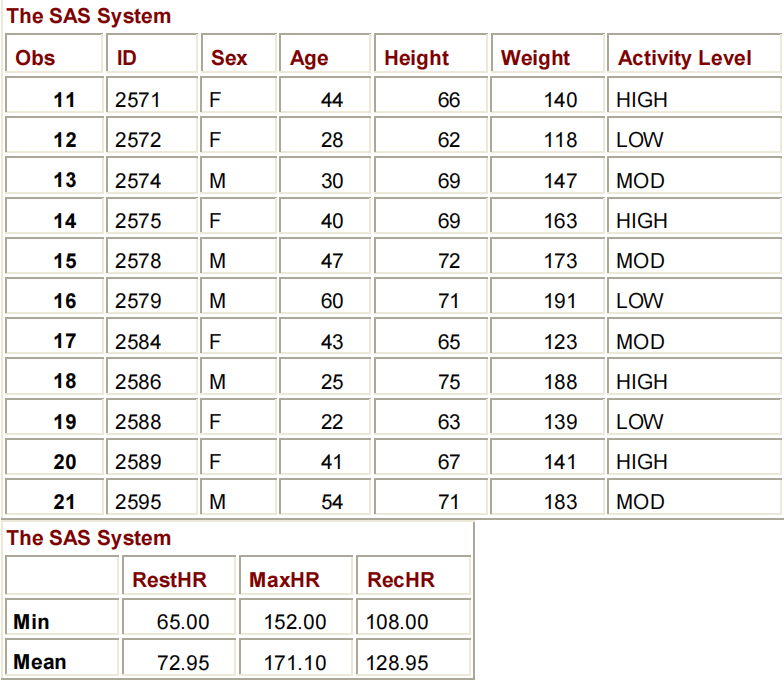
PROC TABULATE DATA=CLINIC.STRESS2;
VAR RESTHR MAXHR RECHR;
TABLE MIN MEAN, RESTHR MAXHR RECHR;
RUN;
ODS HTML CLOSE;
ODS LISTING;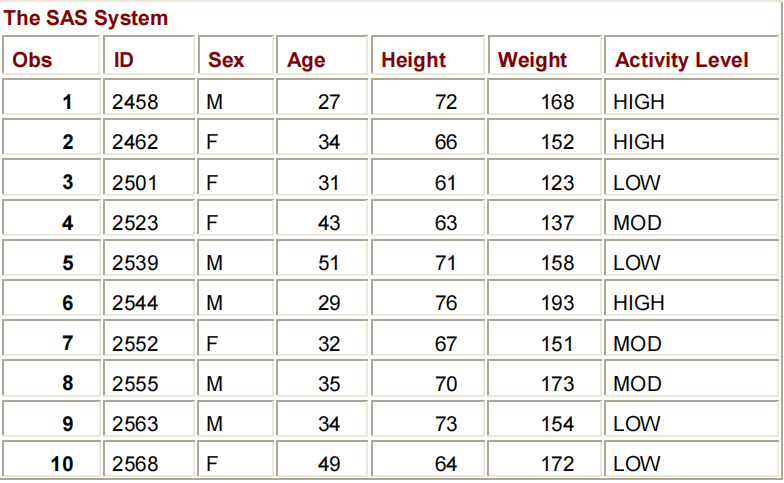
ODS HTML STATEMENT TO CREATE A LINKED TABLE OF CONTENTS:
ODS HTML;
BODY=BODY-FILE-SPECIFICATION
CONTENTS=CONTENTS-FILE-SPECIFICATION
FRAME=FRAME-FILE-SPECIFICATION;
ODS HTML CLOSE;其中:
BODY-FILE-SPECIFICATION是包含过程输出的HTML文件的名称
CONTENTS-FILE-SPECIFICATION是一个HTML文件的名称,该文件包含一个包含链接到过程输出的目录
FRAME-FILE-SPECIFICATION是集成了目录和正文文件的HTML文件的名称。如果您指定了FRAME=,则您还必须指定CONTENTS=
ODS LISTING CLOSE;
ODS HTML BODY='C:\RECORDS\DATA.HTML'
CONTENTS='C:\RECORDS\TOC.HTML'
FRAME='C:\RECORDS\FRAME.HTML';
PROC PRINT DATA=CLINIC.ADMIT LABEL;
VAR ID SEX AGE HEIGHT WEIGHT ACTLEVEL;
LABEL ACTLEVEL='ACTIVITY LEVEL';
RUN;
PROC PRINT DATA=CLINIC.STRESS2;
VAR ID RESTHR MAXHR RECHR;
RUN;
ODS HTML CLOSE;
ODS LISTING;通过在BODY=或CONTENTS=FILE SPECIFICATION中指定URL=SUBPOTION,您可以提供一个ODS在它创建到文件的所有链接中使用的URL。您可以在除FRAME=之外的任何ODS文件规范中使用URL=SUBOPTION(因为没有ODS文件引用FRAME文件)。
GENERAL FORM, URL=SUBPOTION IN A FILE SPECIFICATION:
(URL='UNIFORM-RESOURCE-LOCATOR')其中,UNIFORM-RESOURCE-LOCATOR是HTML文件的名称或HTML文件的完整URL。ODS使用这个URL,而不是它创建的所有链接和引用中的文件名,它都指向该文件。
RELATIVE URLs:
在此ODS HTML语句中,URL=SUBPOTION只指定HTML文件名。这是文件之间最常见的链接方式,因为维护更容易,而且只要文件都保持在同一目录或存储位置上,就可以移动文件。
ODS HTML BODY='C:\RECORDS\DATA.HTML' (URL='DATA.HTML')
CONTENTS='C:\RECORDS\TOC.HTML' (URL='TOC.HTML')
FRAME='C:\RECORDS\FRAME.HTML';ABSOLUTE URLs:
ODS HTML BODY='C:\RECORDS\DATA.HTML'
(URL='HTTP://MYSITE.COM/MYREPORTS/DATA.HTML')
CONTENTS='C:\RECORDS\TOC.HTML'
(URL='HTTP://MYSITE.COM/MYCONTENTS/TOC.HTML')
FRAME='C:\RECORDS\FRAME.HTML';为了简化ODS HTML语句,您还可以使用PATH=OPTION来指定您要存储HTML输出的位置,并且您可以使用URL=NONE来防止ODS在它在文件中创建的任何链接中使用路径名。
PATH=OPTION:
PATH=FILE-SPECIFICATION <(URL='UNIFORM-RESOURCE-LOCATOR'|NONE)>ODS LISTING CLOSE;
ODS HTML PATH='C:\RECORDS' (URL=NONE)
BODY='DATA.HTML'
CONTENTS='TOC.HTML'
FRAME='FRAME.HTML';
PROC PRINT DATA=CLINIC.ADMIT;
RUN;
PROC PRINT DATA=CLINIC.STRESS2;
RUN;
ODS HTML CLOSE;
ODS LISTING;您可以通过使用ODS HTML语句中的STYLE=选项来更改HTML输出的外观。
STYLE=OPTION:
STYLE=STYLE-NAME其中,STYLE-NAME是有效的SAS或用户定义的样式定义的名称。
ODS LISTING CLOSE;
ODS HTML BODY='C:\RECORDS\DATA.HTML' (URL='DATA.HTML')
CONTENTS='C:\RECORDS\TOC.HTML' (URL='TOC.HTML')
FRAME='C:\RECORDS\FRAME.HTML'
STYLE=BRICK;
PROC PRINT DATA=CLINIC.ADMIT LABEL;
VAR ID SEX AGE HEIGHT WEIGHT ACTLEVEL;
LABEL ACTLEVEL='ACTIVITY LEVEL';
RUN;
PROC PRINT DATA=CLINIC.STRESS2;
VAR ID RESTHR MAXHR RECHR;
RUN;
ODS HTML CLOSE;
ODS LISTING;SUM STATEMENT:
VARIABLE + EXPRESSION;
# 如果EXPRESSION含有一个缺失的值,则SUM语句会将其视为零。(相比之下,在赋值语句中,如果表达式产生缺失值,则会分配缺失值。)*正确运行;
DATA ALL_SALES;
INPUT RECEIPTS;
*A;
TOTAL+RECEIPTS;
*B;
*TOTAL 0;
*SUM TOTAL;
*C;
TOTAL=TOTAL+RECEIPTS;
*D;
TOTAL=SUM(TOTAL,RECEIPTS);
DATALINES;
10
23
20
15
;
RUN;VAR20=SUM(OF VAR12-VAR19); #多个变量同时相加VARIABLE指定累加器变量的名称。此变量必须为数字变量。在读取第一个观察结果之前,该变量会被自动设置为0。变量的值从一个数据步骤执行保留到下一个。
如果EXPRESSION产生了一个缺失的值,则SUM语句会将其视为零。(相比之下,在赋值语句中,如果表达式产生缺失值,则会分配缺失值。)
Sum语句是少数不以关键字开头的SAS语句之一。
DATA CLINIC.STRESS;
INFILE TESTS;
INPUT ID $ 1-4 NAME % 6-25 RESTHR 27-29 MAXHR 31-33
RECHR 35-37 TIMEMIN 39-40 TIMESEC 42-43
TOLERANCE % 45;
TOTALTIME=(TIMEMIN*60)+TIMESEC;
SUMSEC+TOTALTIME;
RUN;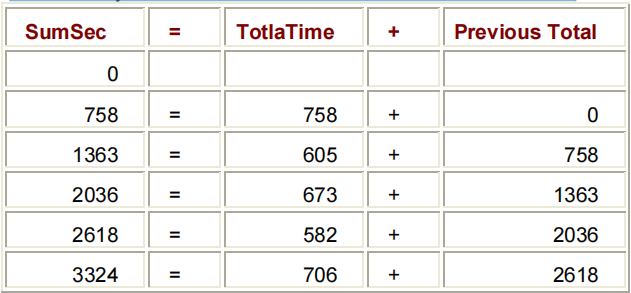
您可以使用RETAIN语句将缺省值0以外的初始值分配给一个由Sum语句分配的变量。
RETAIN STATEMENT:
为一个保留的变量分配一个初始值
防止在每次执行数据步骤时都要初始化变量
是一个仅编译时语句,如果变量不存在则创建它们
如果不提供初始值,则将保留的变量在第一次执行数据步骤之前初始化为缺失
对使用SET、MERGE或UPDATE语句读取的变量没有影响
RETAIN STATEMENT FOR INITIALIZING ACCUMULATOR VARIABLES:
RETAIN VARIABLE INITIAL-VALUE;IF-THEN STATEMENT:
IF EXPRESSION THEN STATEMENT;ELSE STATEMENT:
ELSE STATEMENT;LENGTH STATEMENT:
LENGTH VARIABLE(S) <$> LENGTH;其中
VARIABLE(S)命名要指定长度的变量
如果该变量是一个字符变量,则指定$
LENGTH是一个指定变量长度的整数
EXPRESSION | EXAMPLE | RESULTING TYPE OF X | RESULTING LENGTH OF X | EXPLANATION |
CHARACTER VARIABLE | LENGTH A $ 4; X=A; | CHARACTER VARIABLE | 4 | 源变量的长度 |
CHARACTER LITERAL (CHARACTER CONSTANT) | X='ABC'; X='ABCDE'; | CHARACTER VARIABLE | 3 | 第一次赋值时文字的长度 |
CONCATENATION OF VARIABLES | LENGTH A $ 4 B $ 6 C $ 2; X=A||B||C; | CHARACTER VARIABLE | 12 | 所有变量的长度之和 |
CONCATENATION OF VARIABLES AND LITERALS | LENGTH A $ 4; X=A||'CAT'; X=A||'CATNIP'; | CHARACTER VARIABLE | 7 | 在第一个赋值语句中遇到的变量和文字(常量)的长度之和 |
NUMERIC VARIABLE | LENGTH A 4; X=A; | NUMERIC VARIABLE | 8 | 默认数字长度(除非另有指定,否则为8字节),请注意:一般情况下,不建议您更改数值变量的默认长度,因为这可能会影响数值精度。有关更多信息,请参阅有关操作环境的SAS文档。 |
DELETE STATEMENT:
DELETE;若要有条件地执行删除语句,以以下通用格式提交语句:
IF EXPRESSION THEN DELETE;下面的IF-THEN和DELETE语句省略了RESTHR值低于70的观察:
DATA CLINIC.STRESS;
INFILE TESTS;
INPUT ID $ 1-4 NAME $ 6-25 RESTHR 27-29 MAXHR 31-33
RECHR 35-37 TIMEMIN 39-40 TIMESEC 42-43
TOLERANCE $ 45;
IF RESTHR<70 THEN DELETE;
TOTALTIME=(TIMEMIN*60)+TIMESEC;
RETAIN SUMSEC 5400;
SUMSEC+TOTALTIME;
LENGTH TESTLENGTH $ 6;
IF TOTALTIME>800 THEN TESTLENGTH='LONG';
ELSE IF 750<=TOTALTIME<=800 THEN TESTLENGTH='NORMAL';
ELSE IF TOTALTIME<750 THEN TESTLENGTH='SHORT';
RUN; 有时,您可能需要读取和处理您不想保留在数据集中的字段。在这种情况下,您可以使用DROP=和KEEP=data set options来指定您要删除或保留的变量。
如果删除的变量过多,则使用KEEP=选项而不是DROP=选项。您可以在SAS数据集名称后的括号中指定数据集选项。
DROP= AND KEEP= DATA SET OPTIONS:
(DROP=VARIABLE(S))
(KEEP=VARIABLE(S))假设您希望只保留新变量TOTALTIME,而不是原始变量TIMEMIN和TIMESEC。在创建STRESS数据集时,您可以删除TIMEMIN和TIMESEC。
DATA CLINIC.STRESS (DROP=TIMEMIN TIMESEC);
INFILE TESTS;
INPUT ID $ 1-4 NAME $ 6-25 RESTHR 27-29 MAXHR 31-33
RECHR 35-37 TIMEMIN 39-40 TIMESEC 42-43
TOLERANCE $ 45;
IF TOLERANCE='D';
TOTALTIME=(TIMEMIN*60)+TIMESEC;
RETAIN SUMSEC 5400;
SUMSEC+TOTALTIME;
LENGTH TESTLENGTH $ 6;
IF TOTALTIME>800 THEN TESTLENGTH='LONG';
ELSE IF 750<=TOTALTIME<=800 THEN TESTLENGTH='NORMAL';
ELSE IF TOTALTIME<750 THEN TESTLENGTH='SHORT';
RUN;DROP AND KEEP STATEMENTS:
DROP VARIABLE(S);
KEEP VARIABLE(S);您不能在SAS PROC步骤中使用DROP语句。
DATA CLINIC.STRESS (DROP=TIMEMIN TIMESEC);
INFILE TESTS;
INPUT ID $ 1-4 NAME $ 6-25 RESTHR 27-29 MAXHR 31-33
RECHR 35-37 TIMEMIN 39-40 TIMESEC 42-43
TOLERANCE $ 45;
IF TOLERANCE='D';
DROP TIMEMIN TIMESEC; <INSERT HERE>
TOTALTIME=(TIMEMIN*60)+TIMESEC;
RETAIN SUMSEC 5400;
SUMSEC+TOTALTIME;
LENGTH TESTLENGTH $ 6;
IF TOTALTIME>800 THEN TESTLENGTH='LONG';
ELSE IF 750<=TOTALTIME<=800 THEN TESTLENGTH='NORMAL';
ELSE IF TOTALTIME<750 THEN TESTLENGTH='SHORT';
RUN;除了IF-THEN/ELSE,您还可以使用数据步骤中的SELECT GROUPS来执行条件处理。SELECT GROUPS包含以下语句:
USE THIS STATEMENT | TO PERFORM THIS ACTION |
SELECT | 起始一个SELECT GROUP |
WHEN | 标识在特定条件为真时执行的SAS语句。 |
OTHERWISE(OPTIONAL) | 指定在不满足WHEN条件时要执行的语句 |
END | 结束一个SELECT GROUP |
SELECT GROUP:
SELECT <(SELECT-EXPERSSION)>;
WHEN-1 (WHEN-EXPRESSION-1 <...,WHEN-EXPRESSION-N>) STATEMENT;
WHEN-N (WHEN-EXPRESSION-1 <...,WHEN-EXPRESSION-N>) STATEMENT;
<OTHERWISE STATEMENT;>
END;下面的代码是一个SELECT GROUP的一个简单示例。请注意,变量a在SELECT语句中指定了,并且在WHEN语句中指定了要与a进行比较的各种值。当变量a的值为
SELECT (A);
WHEN (1) X=X*10;
WHEN (3,4,5) X=X*100;
OTHERWISE;
END;您已经看到了条件处理(IF-THEN/ELSE语句和选择组)的示例,当一个条件为真时,它们只执行一个SAS语句。但是,您也可以通过使用DO组作为一个单元来执行一组语句。
DO GROUP:
DO;
SAS STATEMENTS;
END;IF TOTALTIME>800 THEN
DO;
TESTLENGTH='LONG';
MESSAGE='RUN BLOOD PANEL';
END;DATA PAYROLL;
SET SALARIES;
SELECT(PAYCLASS);
WHEN ('MONTHLY') AMT=SALARY;
WHEN ('HOURLY')
DO;
AMT=HRLYWAGE*MIN (HRS,40);
IF HRS>40 THEN PUT 'CHECK TIMECARD';
END;
OTHERWISE PUT 'PROBLEM OBSERVATION';
END;
RUN;DATA STEP FOR READING A SINGLE DATA SET:
DATA SAS-DATA-SET;
SET SAS-DATA-SET;
RUN;数据清洗:
TO DO THIS | USE THIS TYPE OF STATEMENT |
SUBSET DATA | IF RESTHR<70 THEN DELETE; IF TOLERANCE='D'; |
DROP UNWANTED VARIABLES | DROP TIMEMIN TIMESEC; |
CREATE OR MODIFY A VARIABLE | TOTALTIME=(TIMEMIN*60)+TIMESEC; |
INITIALIZE A SUM VARIABLE SUM ACCUMULATED VALUES | RETAIN SUMSEC 5400; SUMSEC+TOTALTIME; |
SPECIFY A VARIABLE'S LENGTH | LENGTH TESTLENGTH $ 6; |
EXECUTE STATEMENTS CONDITIONALLY | IF TOTALTIME>800 THEN TESTLENGTH='LONG'; ELSE IF 750<=TOTALTIME<=800 THEN TESTLENGTH='NORMAL'; ELSE IF TOTALTIME<750 THEN TESTLENGTH='SHORT'; |
LABEL A VARIABLE FORMAT A VARIABLE | LABEL SUMSEC='CUMULATIVE TOTAL SECONDS'; FORMAT SUMSEC COMMA6.; |
您还可以使用DATA步骤中的BY语句对观察结果进行分组以进行处理
DATA TEMP;
SET SALARY;
BY DEPT;
RUN;当您使用BY语句和SET语句时,
在SET语句中列出的数据集必须按BY变量(s)的值进行排序,或者这些数据集必须具有适当的索引。
数据步骤为每个BY变量创建两个临时变量。一个变量命名为FIRST.VARIABLE,其中VARIABLE是BY变量的名称,另一个变量命名为LAST.VARIABLE。它们的值要么是1,要么是0。FIRST.VARIABLE和LAST.VARIABLE确定了每个BY组的第一个和最后一个观察结果。
THIS VARIABLE | EQUALS |
FIRST.VARIABLE | 1 FOR THE FIRST OBSERVATION IN A BY GROUP 0 FOR ANY OTHER OBSERVATION IN A BY GROUP |
LAST.VARIABLE | 1 FOR THE LAST OBSERVATION IN A BY GROUP 0 FOR ANY OTHER OBSERVATION IN A BY GROUP |
以下程序按部门计算年度工资单。请注意,变量名DEPT已附加FIRST.和LAST.
PROC SORT DATA=COMPANY.USA OUT=WORK.TEMP;
BY DEPT;
RUN;
DATA COMPANY.BUDGET (KEEP=DEPT PAYROLL);
SET WORK.TEMP;
BY DEPT;
IF WAGECAT='S' THEN YEARLY=WAGERATE*12;
ELSE IF WAGECAT='H' THEN YEARLY=WAGERATE*2000;
IF FIRST.DEPT THEN PAYROLL=0;
PAYROLL+YEARLY;
IF LAST.DEPT;
RUN;PROC PRINT DATA=COMPANY.BUDGET2 NOOBS;
BY MANAGER;
VAR JOBTYPE;
SUM PAYROLL;
WHERE MANAGER IN ('COXE','DELGADO');
FORMAT PAYROLL DOLLAR12.2;
RUN;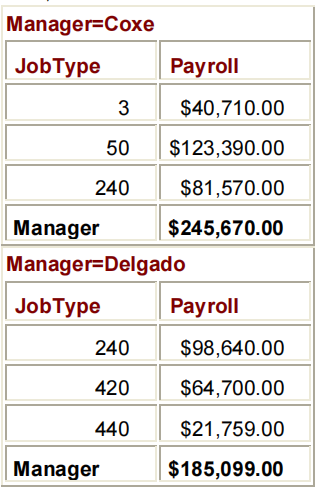
要通过观测序号直接访问观测值,请使用SET语句中的POINT=OPTION。
POINT=OPTION:
POINT=VARIABLE;其中,VARIABLE
必须在执行SET语句之前给定一个值
假设您只想读取来自一个数据集的第五个观察结果。在下面的DATA步骤中,将值5分配给变量OBSNUM。POINT=OPTION读取OBSNUM的值,以确定从数据集读取哪个观察结果COMPANY.USA
DATA WORK.GETOBS5;
OBSNUM=5;
SET COMPANY.USA (KEEP=MANAGER PAYROLL) POINT=OBSNUM;
RUN;STOP语句可被用来防止连续循环。STOP语句会使SAS立即停止处理当前的DATA步骤,并在当前的DATA步骤结束后重新恢复处理语句。
使用POINT=VARIABLE的无效值的编程逻辑。如果SAS读取POINT=VARIABLE的无效值,它会将自动变量_ERROR_设置为1。您可以使用此信息来检查导致连续处理的条件。
STOP STATEMENT:
STOP;DATA WORK.GETOBS5(DROP=OBSNUM);
OBSNUM=5;
SET COMPANY.USA(KEEP=MANAGER PAYROLL) POINT=OBSNUM;
STOP;
RUN;在此程序中,STOP语句会在数据步骤结束前立即停止处理,不会产生输出。
要覆盖DATA步骤将观察结果写入输出的默认方式,您可以在DATA步骤中使用输出语句。在DATA步骤中放置显式OUTPUT语句将覆盖自动输出,因此只有在执行显式OUTPUT语句时才会将观察结果添加到数据集中。
OUTPUT STATEMENT:
OUTPUT <SAS-DATA-SET(S)>;DATA WORK.GETOBS5(DROP=OBSNUM);
OBSNUM=5;
SET COMPANY.USA(KEEP=MANAGER PAYROLL) POINT=OBSNUM;
OUTPUT;
STOP;
RUN;
PROC PRINT DATA=WORK.GETOBS5 NOOBS;
RUN;END= OPTION;
END=VARIABLE;其中,当VARIABLE创建并命名一个包含文件结束标记的临时变量。当set语句读取数据集的最后一次观察值时,初始化为0的临时变量被设置为1。
如果只需要输出的FINAL TOTAL(最后一次观察结果),下面的程序使用END=VARIABLE LAST选择数据集的最后观察。您在SET语句中指定END=,并在处理中需要它的地方使用(这里,在子集IF语句中)。
DATA WORK.ADDTOEND(DROP=TIMEMIN TIMESEC);
SET CLINIC.STRESS2(KEEP=TIMEMIN TIMESEC) END=LAST;
TOTALMIN+TIMEMIN;
TOTALSEC+TIMESEC;
TOTALTIME=TOTALMIN*60+TIMESEC;
IF LAST;
RUN;
PROC PRINT DATA=WORK.ADDTOEND NOOBS;
RUN;
编译阶段包括以下步骤:
创建了程序数据向量,并包含自动变量_N_和_ERROR_。
SAS还会扫描DATA步骤中的每个语句,以查找语法错误。
当编译SET语句时,将为输入数据集中的每个变量的程序数据向量添加一个插槽。输入数据集提供变量名称,以及类型和长度等属性。
在数据步骤中创建的任何变量也将被添加到程序数据向量中。这些变量的属性都由语句中的表达式决定。
在DATA步骤的底部,编译阶段已经完成,并创建了新的SAS数据集的描述符部分。没有观察结果,因为数据步骤还没有执行。
执行阶段包括以下步骤:
DATA步骤对输入数据集中的每个观察结果执行一次。例如,这个数据步骤将执行四次,因为在输入数据集FINANCE.LOANS中有四个观察结果。
在执行阶段开始时,_N_的值为1。因为没有数据错误,所以_ERROR_的值为0。其余的变量被初始化为缺失。缺失的数值用句号(.)表示,缺失的字符值用空白表示。
SET语句从输入数据集读取第一个观察值,并将这些值写入程序数据向量。
然后,执行分配语句来计算INTEREST的值。
在数据步骤的第一次迭代结束时,将程序数据向量中的值作为第一次观察值写入新的数据集。
_N_的值被设置为2,控制返回到DATA步骤的顶部。请记住,自动变量_N_会跟踪数据步骤已经开始执行的次数。
SAS保留使用SET语句从SAS数据集中读取的变量的值,或由Sum语句创建的变量的值。所有其他变量值,如变量INTEREST的值,都被设置为缺失。
在第二次迭代开始时,_N_的值被设置为2,而_ERROR_的值被重新设置为0。请记住,自动变量_N_会跟踪数据步骤已经开始执行的次数。
当SET语句执行时,来自第二次观察的值被写入程序数据向量。
再次执行赋值语句,以计算第二次观察的INTEREST值。
在DATA步骤的底部,程序数据向量中的值被写入作为第二次观察值的数据集。
_N_的值被设置为3,控制返回到DATA步骤的顶部。SAS保留使用SET语句从SAS数据集中读取的变量的值,或由Sum语句创建的变量的值。所有其他变量值,如变量INTEREST的值,都被设置为缺失。
Combining SAS Data Sets:


ONE-TO-ONE- READING:
DATA STEP FOR ONE-TO-ONE READING:
DATA OUTPUT-SAS-DATA-SET;
SET SAS-DATA-SET-1;
SET SAS-DATA-SET-2;
RUN;下面有两个数据集:
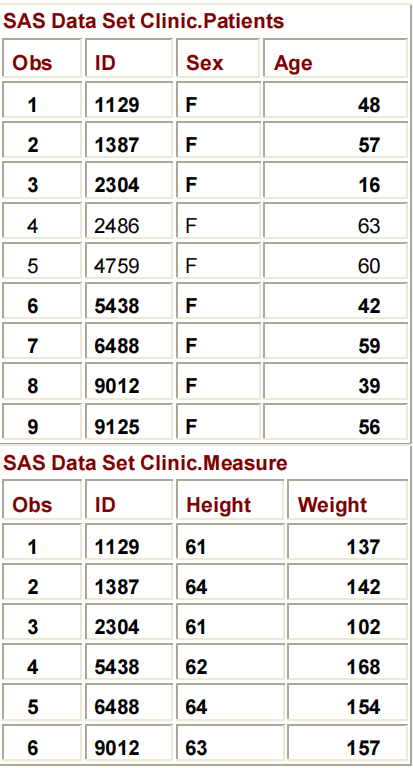
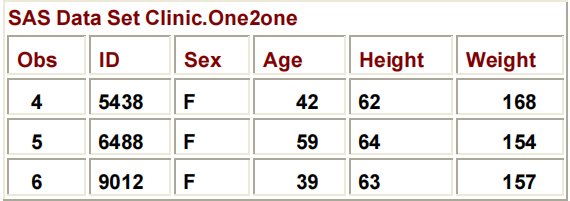
要将第一个数据集的观测数据作为子集,并将其与第二个数据集的观测数据相结合,您可以提交以下程序:
DATA CLINIC.ONE2ONE;
SET CLINIC.PATIENCE;
IF AGE<60;
SET CLINIC.MEASURE;
RUN;
DATA STEP FOR CONCATENATING:
DATA OUTPUT-SAS-DATA-SET;
SET SAS-DATA-SET-1 SAS-DATA-SET-2;
RUN;DATA STEP FOR INTERLEAVING:
DATA OUTPUT-SAS-DATA-SET;
SET SAS-DATA-SET-1 SAS-DATA-SET-2;
BY VARIABLE(S);
RUN;DATA STEP FOR MATCH-MERGING:
DATA OUTPUT-SAS-DATA-SET;
MERGE SAS-DATA-SET-1 SAS-DATA-SET-2;
BY <DESCENDING> VARIABLE(S);
RUN;PROC SORT DATA=CERT.INPUT08A OUT=WORK.INPUT08A;
BY ID;
RUN;
PROC SORT DATA=CERT.INPUT08B OUT=WORK.INPUT08B;
BY ID;
RUN;
DATA RESULTS.MATCH08 RESULTS.NOMATCH08 (DROP=EX: );
MERGE WORK.INPUT (IN=A) WORK.INPUT08B (IN=B);
BY ID;
IF A AND B THEN OUTPUT RESULTS.MATCH08;
ELSE OUTPUT RESULTS.NOMATCH08;
RUN;
# 数据集CERT.INPUT08A和CERT.INPUT08B按ID排序
# 数据集CERT.INPUT08A和CERT.INPUT08B按ID合并
# 数据集CERT.INPUT08A和CERT.INPUT08B同时含有的变量写入RESULTS.MATCH08
# 其余变量写入RESULTS.NOMATCH08
# 数据集RESULTS.NOMATCH08中排除以ex开头的变量RENAME=DATA SET OPTION:
(RENAME=(OLD-VARIABLE-NAME=NEW-VARIABLE-NAME))IN= DATA SET OPTION:
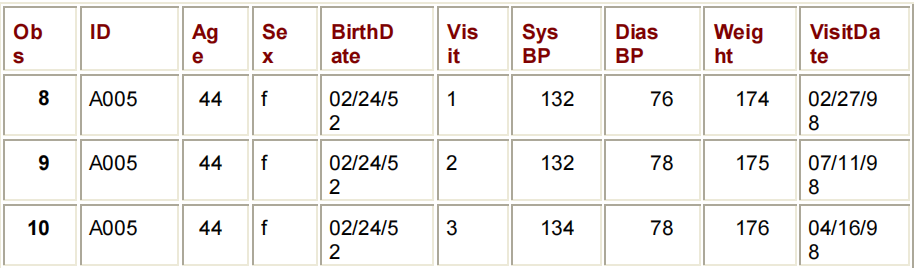
(IN= VARIABLE)在下面的DATA步骤中,子设置IF语句检查INDEMOG和INVISIT的值,并继续只处理那些满足表达式条件的观察值。这里的情况是,这两个CINIC.DEMOG和CLINIC.VISIT有助于观察。如果符合条件,新的观察结果就会写给CLINIC.MERGED。否则,将删除该观察结果。
DATA CLINIC.MERGED;
MERGE CLINIC.DEMOG(IN=INDEMOG
RENAME=(DATE=BIRTHDATE))
CLINIC.VISIT(IN=INVISIT
RENAME=(DATE=VISITDATE));
BY ID;
IF INDEMOG=1 AND INVISIT=1;
RUN;
PROC PRINT DATA=CLINIC.MERGED;
RUN;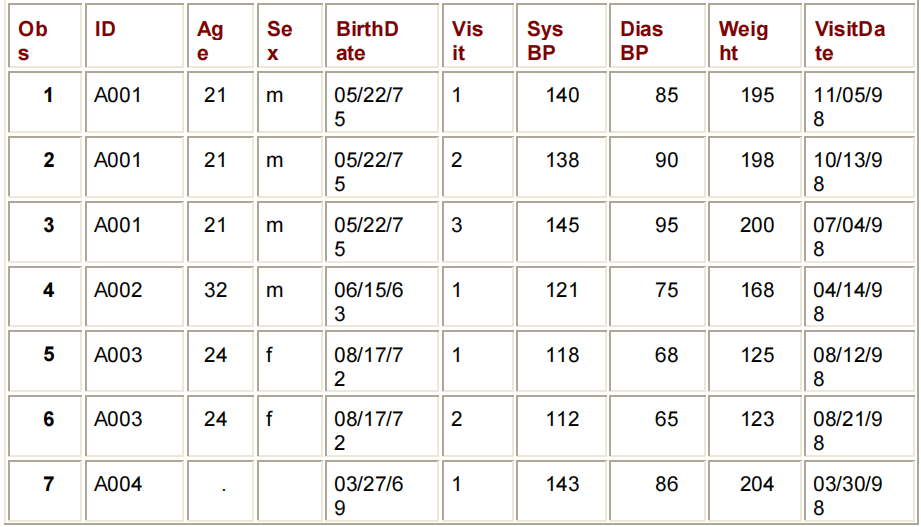
日期函数:
FUNCTION | DESCRIPTION | FORM | SAMPLE VALUE |
YEAR | EXTRACTS THE YEAR VALUE FROM A SAS DATE VALUE | YEAR(DATE) | 2006 |
QTR | EXTRACTS THE QUARTER VALUE FROM A SAS DATE VALUE | QTR(DATE) | 1 |
MONTH | EXTRACTS THE MONTH VALUE FROM A SAS DATE VALUE | MONTH(DATE) | 12 |
DAY | EXTRACTS THE DAY VALUE FROM A SAS DATE VALUE | DAY(DATE) | 5 |
SAS FUNCTIONS THAT COMPUTE DESCRIPTIVE STATISTICS | ||
FUNCTION | SYNTAX | CALCULATES |
SUM | SUM(ARGUMENT, ARGUMENT,...) | SUM OF VALUES |
MEAN | MEAN(ARGUMENT, ARGUMENT, ...) | AVERAGE OF NOMISSING VALUES |
MIN | MIN(ARGUMENT, ARGUMENT, ...) | MINIMUM VALUE |
MAX | MAX(ARGUMENT, ARGUMENT, ...) | MAXIMUM VALUE |
VAR | VAR(ARGUMENT, ARGUMENT, ...) | VARIANCE OF THE VALUES |
STD | STD(ARGUMENT, ARGUMENT, ...) | STANDARD DEVIATION OF THE VALUES |
INPUT STATEMENT:
INPUT(SOURCE, INFORMAT);PUT FUNCTION:
PUT(SOURCE,FORMAT);SAS DATE FUNCTIONS:
FUNCTION | TYPICAL USE | RESULT |
MDY | DATE=MDY(MON,DAY,YR); | SAS DATE |
TODAY DATE | NOW=TODAY(); NOW=DATE(); | TODAY'S DATE AS A SAS DATE |
TIME | CURTIME=TIME(); | CURRENT TIME AS A SAS TIME |
DATE EXPRESSION | SAS DATE INFORMAT |
30MAY00 | DATE7. |
30MAY2000 | DATE9. |
30-MAY-2000 | DATE11. |
TIME EXPRESSION | SAS TIME INFORMAT |
17:00:01:34 | TIME11. |
17:00 | TIME5. |
2:34 | TIME5. |
DATE AND TIME EXPRESSION | SAS DATETIME INFORMAT |
30MAY2000:10:03:17.2 | DATETIME20. |
30MAY00 10:03:17.2 | DATETIME18. |
30MAY2000/10:03 | DATETIME15. |
下列函数可以从SAS日期值中提取月、季度、天和年。
FUNCTION | TYPICAL USE | RESULT |
DAY | DAY=DAY(DATE); | DAY OF MONTH (1-31) |
QTR | QUARTER=QTR(DATE); | QUARTER (1-4) |
WEEKDAY | WKDAY=WEEKDAY(DATE); | DAY OF WEEK (1-7) |
MONTH | MONTH=MONTH(DATE); | MONTH (1-12) |
YEAR | YR=YEAR(DATE); | YEAR (4 DIGITS) |
INTCK | X=INTCK('DAY',D1,D2); X=INTCK('WEEK',D1,D2); X=INTCK('MONTH',D1,D2); X=INTCK('QTR',D1,D2); X=INTCK('YEAR',D1,D2); | DAYS FROM D1 TO D2 WEEKS FROM D1 TO D2 MONTHS FROM D1 TO D2 QUARTERS FROM D1 TO D2 YEARS FROM D1 TO D2 |
INTNX | X=INTNX('INTERVAL',START-FROM,INCREMENT); | DATE,TIME, OR DATETIME VALUE |
DATDIF YRDIF | X=DATDIF('DATE1',DATE2,ACT/ACT); X=YRDIF('DATE1',DATE2,ACT/ACT) | DAY BETWEEN DATE1 AND DATE2 YEARS BETWEEN DATE1 AND DATE2 |
WEEKDAY函数返回一个从1到7的数值。这些值表示一周中的天数。
VALUE | EQUALS | DAY OF THE WEEK |
1 | = | SUNDAY |
2 | = | MONDAY |
3 | = | TUESDAY |
4 | = | WEDNESDAY |
5 | = | THURSDAY |
6 | = | FRIDAY |
7 | = | SATURDAY |
MDY函数从表示月份、日期和年份的数值中创建一个SAS日期值。
MDY FUNCTION:
MDY(MONTH,DAY,YEAR);MONTH可以是表示月份的变量,也可以是1-12之间的数字
DAY可以是表示日期的变量,也可以是1-31的数字
YEAR可以是表示年份的变量,也可以是带有2或4位数字的数字
INTCK函数返回在给定的时间跨度内发生的时间间隔数。你可以用它来计算天数、周、月等等。
INTCK FUNCTION:
INTCK('INTERVAL',FROM,TO)INTNX函数类似于INTCK函数。INTNX函数将给定时间间隔的倍数应用于日期、时间或日期时间的值,并返回结果值。您可以使用INTNX函数来识别过去或将来的日子、几周、月份等等。
INTNX FUNCTION:
INTNX('INTERVAL',START-FROM,INCREMENT<,'ALIGNMENT'>);DATDIF和YRDIF函数分别计算两个SAS日期之间的天数和年差。这两个函数都接受被指定为SAS日期值的开始日期和结束日期。此外,这两个函数都使用了一个BASIS参数来描述SAS如何计算日期差异。
DATDIF AND YRDIF FUNCTIONS:
DATDIF(START_DATE,END_DATE,BASIS);
YRDIF(START_DATE,END_DATE,BASIS);BASIS指定一个字符常量或变量,描述SAS常量如何计算日期差异。
AGE=YRDIF('05MAY1999'D,'10NOV1999'D,'ACT/ACT');
# 结果AGE=0.5178FUNCTION | PURPOSE |
SCAN | 从字符值中返回指定的单词。 |
SUBSTR | 提取子字符串或替换字符值。 |
TRIM | 从字符值中修剪尾随的空格。 |
CATX | 连接字符串,删除前导和后面的空格,并插入分隔符。 |
INDEX | 搜索特定字符串的字符值。 |
FIND | 搜索指定的字符串中特定的字符串。 |
UPCASE | 将值中的所有字母转换为大写。 |
LOWCASE | 将值中的所有字母转换为小写。 |
PROPCASE | 将一个值中的所有字母转换为正确的大小写。 |
TRANWRD | 替换或删除字符串中字符模式的所有出现情况。 |
SCAN FUNCTION:
SCAN(ARGUMENT,N,DELIMITERS)其中
ARGUMENT指定要扫描的字符变量或表达式
N指定要读取的单词位置
DELIMITERS是必须用单引号(“”)括起来的特殊字符。
SUBSTR FUNCTION:
SUBSTR(ARGUMENT,POSITION,<N>)DATA WORK.AREACODES;
PHONENUMBER=3125551212;
CODE='('!!SUBSTR(PHONENUMBER,1,3)!!')';
RUN;DATA TEST;
SET HRD.TEMP;
SUBSTR(PHONE,1,3)='433';
RUN;
# 将变量PHONE从第1位开始向后数3位用433替换SCAN和SUBSTR函数:
SCAN 提取用分隔符标记的值内的单词。
SUBSTR通过从指定的位置开始来提取值的一部分。
TRIM FUNCTION:
TRIM(ARGUMENT);TRIM函数允许您从字符值中删除尾随空格。
DATA WORK.TEST;
LENGTH CITY $ 20;
CITY='PARIS';
CITY2=TRIM(CITY);
RUN;
# 变量CITY2的长度为20CATX FUNCTION:
CATX(SEPARATOR,STRING-1<,...STRING-N>)NEWADDRESS=TRIM(ADDRESS)||','||TRIM(CITY)||','||ZIP;
NEWADDRESS=CATX(',',ADDRESS,CITY,ZIP);您可以使用CATX函数来完成字符串连接。
INDEX FUNCTION:
INDEX(SOURCE,EXCEPT)用于搜索变量中的子字符串
INDEX(JOB,'WORD PROCESSING');要创建新的数据集,请在子集IF语句中包含索引函数。只有那些函数定位字符串并返回大于0的值才被写入数据集。
DATA HRD.DATAPOOL;
SET HRD.TEMP;
IF INDEX(JOB,'WORD PROCESSING')>0;
RUN;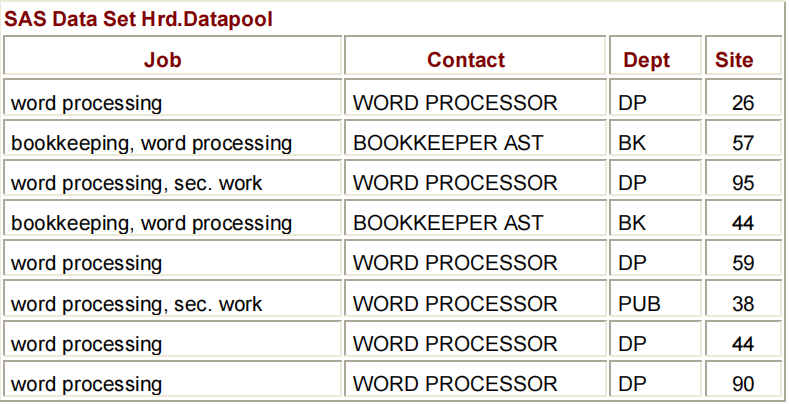
FIND FUNCTION:
FIND(STRING,SUBSTRING<,MODIFIERS><,STARTPOS>)以i作为MODIFIER可使得FIND函数在搜索过程中忽略大小写
以t作为MODIFIER可在FIND函数搜索过程中修剪尾随空格
如果没有指定起始位置,则FIND将在字符串的开头开始搜索,并从左到右搜索该字符串。如果指定了起始位置,则起始位置的绝对值决定了开始搜索的位置。标准的标志决定了搜索的方向。如果开始是正的,则从开始到右进行搜索;如果开始是负的,则从开始到左进行发现搜索。
FIND(JOB,'WORD PROCESSING','T');DATA HRD.DATAPOOL;
SET HRD.DATAPOOL;
IF FIND(JOB,'WORD PROCESSING','T')>0;
RUN;UPCASE FUNCTION:
UPCASE(ARGUMENT)LOWCASE FUNCTION:
LOWCASE(ARGUMENT)PROPCASE FUNCTION:
PROPCASE(ARGUMENT<,DELIMITER(S)>)TRANWRD FUNCTION:
TRANWRD(SOURCE,TARGET,REPLACEMENT)TRANWRD函数将替换或删除字符串中出现的所有字符模式。翻译后的字符可以位于字符串中的任何位置。
SOURCE范围
TARGET目标
REPLACEMENT,替换TARGET的单词
INT FUNCTION:
INT(ARGUMENT)若要返回数值的整数部分,请使用INT函数。INT函数参数的任何十进制部分都将被丢弃。
ROUND FUNCTION:
ROUND(ARGUMENT,ROUND-OFF-UNIT)ROUND(ARGUMENT,1) #只保留整数如果没有提供一个ROUND-OFF UNIT,则使用一个默认值1,并且该参数将四舍五入到最接近的整数。下面所示的两个数据集给出了由圆角函数修改的值的前后视图。
DO LOOP:
DO INDEX-VARIABLE=START TO STOP BY INCREMENT;
SAS STATEMENTS;
END;例如,使用数组和DO循环,下面的程序替代了365个单独的程序语句将日温度从华氏度转换为摄氏度
DATA WORK.REPORT (DROP=I);
SET MASTER.TEMPS;
ARRAY DAYTEMP{365} DAY1-DAY365;
DO I=1 TO 365;
DAYTEMP{I}=5*(DAYTEMP{I}-32)/9;
END;
RUN;通过将这些变量分组到一个一维数组中,可以在一个DO循环中处理这些变量。使用更少的语句,并且数据步骤程序更容易修改或纠正。
DATA WORK.REPORT (DROP=I);
SET MASTER.TEMPS;
ARRAY WKDAY{7} MON TUE WED THR FRI SAT SUN;
DO I=1 TO 7;
WKDAY{I}=5*(WKDAY{I}-32)/9;
END;
RUN;VARIABLES | FORM |
一个变量的编号范围 | VAR1-VARN |
所有数值变量 | _NUMERIC_ |
所有字符变量 | _CHARACTER_ |
所有的变量 | _ALL_ |
ARRAY SALES{*} _NUMERIC_;
ARRAY SALES{*} _CHARACTER_;
ARRAY SALES{*} _ALL_;DATA HRD.DIFF;
SET HRD.CONVERT;
ARRAY WT{6} WEIGHT1-WEIGHT6;
ARRAY WGTDIFF{5};
DO I=1 TO 5;
WGTDIFF{I}=WT{I+1}-WT{I};
END;
RUN;给数组分配初始值
ARRAY GOAL{4} G1 G2 G3 G4 (9000 9300 9600 9900);
# 用引号标注每个字符值。
ARRAY COL{3} $ COLOR1-COLOR3 ('RED','GREEN','BLUE');# 若要创建针对DATA步骤处理的临时数组元素而不创建新变量,在数组名称和维数之后指定_TEMPORARY_。
DATA FINANCE.REPORT;
SET FINANCE.QSALES;
ARRAY SALE{4} SALES1-SALES4;
ARRAY GOAL{4} _TEMPORARY_ (9000 9300 9600 9900);
ARRAY ACHIEVED{4};
DO I=1 TO 4;
ACHIEVED{I}=100*SALE{I}/GOAL{I};
END;
RUN;二维数组
ARRAY NEW{3,4} X1-X12;DO UNTIL:
DO UNTIL (EXPRESSION);
SAS STATEMENTS;
END;一个DO UNTIL循环总是至少执行一次,因为条件直到循环的底部才被考虑。
DATA WORK.INVENTORY;
PRODUCTS=7;
DO UNTIL (PRODUCTS GT 6);
PRODUCTS+1;
END;
RUN;
*OUTPUT PRODUCTS=8;DO WHILE:
DO WHILE (EXPRESSION);
SAS STATEMENTS;
END;CONDITIONAL CLAUSES WITH THE ITERATIVE DO STATEMENT:
DO INDEX-VARIABLE=START TO STOP BY INCREMENT WHILE (EXPRESSION);
SAS STATEMENTS;
END;ARRAY STATEMENT:
ARRAY ARRAY-NAME{DIMENSION}<ELEMENTS>;VARIABLE LISTS AS ARRAY ELEMENTS
VARIABLES | FORM |
A NUMBERED RANGE OF VARIABLES | VAR1-VARN |
ALL NUMERIC VARIABLES | _NUMERIC_ |
ALL CHARACTER VARIABLES | _CHARACTER_ |
ALL VARIABLES | _ALL_ |
DIM FUNCTION:
DIM(ARRAY-NAME)ARRAY STATEMENT TO CREATE NEW VARIABLES:
ARRAY ARRAY-NAME{DIMENSION}DATA TEST;
SET FIR.INPUT04;
ARRAY DIFF{3} DIFCOUNT1-DIFCOUNT3;
*ARRAY DIFF{*} DIFCOUNT1-DIFCOUNT3; /*生成由变量个数决定的数组*/
RUN;
# 生成DIFCOUNT1 DIFCOUNT2 DIFCOUNT3三列INPUT STATEMENT USING FORMATTED INPUT:
INPUT <POINTER-CONTROL> VARIABLE INFORMAT.;TWO COLUMN POINTER CONTROLS:
@N 将输入指针移动到某特定列(绝对)
+N 将输入指针向前移动到相对于当前位置的列号(相对)
#N 指定要将指针移动到的行的绝对数目。
INPUT STATEMENT USING FORMATTED INPUT AND THE @N POINTER CONTROL:
INPUT @N VARIABLE INFORMAT.;VARIABLE是正在创建的变量的名称
INFORMAT是指定SAS如何读取原始数据的特殊指令
GENERAL FORM, INPUT STATEMENT USING FORMATTED INPUT AND THE +N POINTER CONTROL:
INPUT +N VARIABLE INFORMAT.;INPUT STATEMENT FOR FORMATTED INPUT:
INPUT <POINTER-CONTROL> VARIABLE INFORMAT.;INPUT STATEMENT USING LIST INPUT:
INPUT VARIABLE <$>;VARIABLE 指定INPUT 语句要读取的值的名称
$指定变量是否是字符型变量
DLM=OPTION:
DLM=DELIMITER(S)PUT STATEMENT USING LIST OUTPUT:
PUT VARIABLE <: FORMAT>;PROC EXPORT:
PROC EXPORT DATA=SAS-DATA-SET;
OUTFILE=FILENAME <DELIMITER='DELIMITER'>;
RUN;DATE INFORMAT:
DATE EXPRESSION | SAS DATE INFORMAT | SAS DATE VALUE |
02Jan00 | DATEw. | 14611 |
01-02-2000 | MMDDYYw. | 14611 |
02/01/00 | DDMMYYw. | 14611 |
2000/01/02 | YYMMDDw. | 14611 |
INPUT STATEMENT WITH AN INFORMAT:
INPUT <POINTER-CONTROL> VARIABLE INFORMAT.;MMDDYYw. INFORMAT:
DATE EXPRESSION | SAS DATE INFORMAT |
101599 | MMDDYY6. |
10/15/99 | MMDDYY8. |
10 15 99 | MMDDYY8. |
10-15-1999 | MMDDYY10. |
DATEw. INFORMAT:
DATE EXPRESSION | SAS DATE INFORMAT |
30May00 | DATE7. |
30May2000 | DATE9. |
30-May-2000 | DATE11. |
TIMEw. INFORMAT:
TIME EXPRESSION | SAS TIME INFORMAT |
17:00:01.34 | TIME11. |
17:00 | TIME5. |
2:34 | TIME5. |
DATETIMEw. INFORMAT:
DATE AND TIME EXPRESSION | SAS DATETIME INFORMAT |
30May2000:10:03:17.2 | DATATIME20. |
30May00 10:03:17.2 | DATETIME18. |
30May2000/10:03 | DATETIME15. |
PERCENTw.d | DATEw. | NENGOw. |
$BINARYw. | DATETIMEw. | PDw.d |
$VARYINGw. | HEXw. | PERCENTw. |
$w. | JULIANw. | TIMEw. |
COMMAw.d | MMDDYYw. | w.d |
YEARCUTOFF=选项只影响两位数的年数(TWO-DIGIT YEAR)(默认YEARCUTOFF=1920)
DATE EXPRESSION | SAS DATE INFORMAT | INTERPRETED AS |
06Oct59 | DATE7. | 06Oct1959 |
17Mar1783 | DATE9. | 17Mar1783 |
WEEKDATEw. FORMAT:
FORMAT STATEMENT | RESULT |
FORMAT DATEIN WEEKDATE3.; | Mon |
FORMAT DATEIN WEEKDATE6.; | Monday |
FORMAT DATEIN WEEKDATE17.; | Monday,Apr 5,99 |
FORMAT DATEIN WEEKDATE21.; | Monday, April 5,1999 |
WORDDATEw. FORMAT(它不显示一周之中的日期数和两位数年值):
FORMAT STATEMENT | RESULT |
FORMAT DATEIN WORDDATE3. | Apr |
FORMAT DATEIN WORDDATE5.; | April |
FORMAT DATEIN WORDDATE14.; | April 15,1999 |
LINE POINTER CONTROL:
/ 使得输入指针移动到下一行
#N 指定输入指针将移动到的绝对行值


















 1951
1951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











