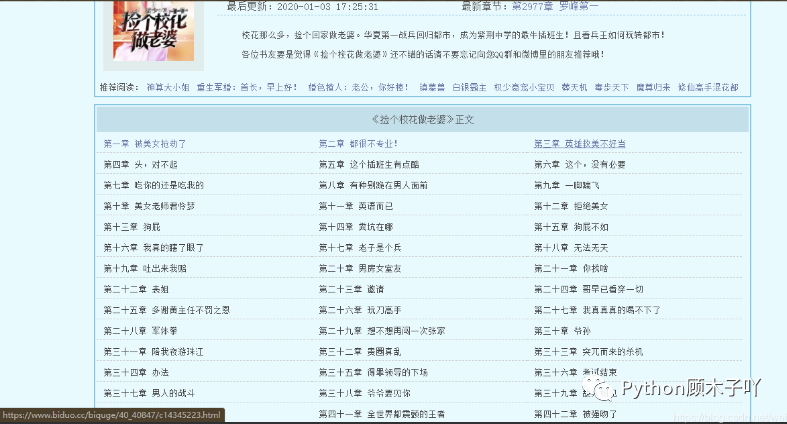
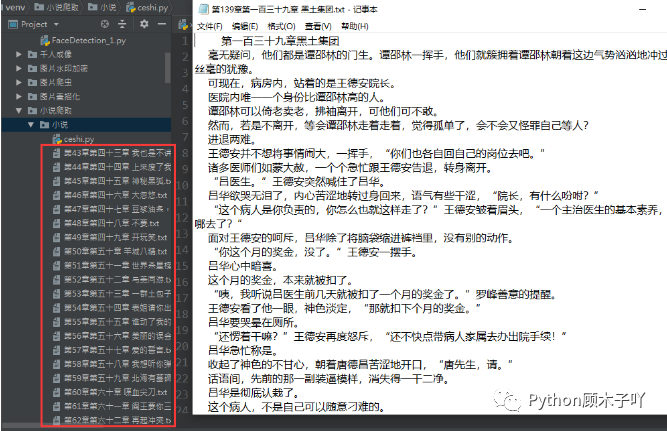
前言 遇见你时,漫天星河皆为浮尘 不知从什么时候开始。小说开始掀起了一股浪潮,它让我们平日里的生活不在枯燥乏 味,很多我们做不到的事情在小说里都能轻易实现。 那么话不多说,下面我们就来具体看看它是如何实现的吧?? 正文 这里以一部小说为例,将每一章的内容爬取下来保存到本地。 ??是我们要爬的小说目录 爬取下来的数据: 分析网页拿数据 首先利用requests库的强大能力,向目标发起请求,拿到页面中的所有HTML数据。<











 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






