






什么是OpenResty?
将Lua和Nginx粘合ngx_lua模块,并且将Nginx核心、LuaJIT、ngx_lua模块、许多有用的Lua库和常用的第三方Nginx模块组合而成。
什么是ngx_lua及原理?
ngx_lua是Nginx的一个模块,将Lua嵌入到Nginx中,从而可以使用Lua来编写脚本,这样就可以使用Lua编写应用脚本,部署到Nginx中运行,即Nginx变成了一个Web容器。
注:Tengine也包含ngx_lua模块。至于二者的区别:OpenResty是Nginx的Bundle;而Tengine则是Nginx的Fork。
ngx_lua模块的原理:
1、每个worker(工作进程)创建一个Lua VM,worker内所有协程共享VM;
2、将Nginx I/O原语封装后注入 Lua VM,允许Lua代码直接访问;
3、每个外部请求都由一个Lua协程处理,协程之间数据隔离;
4、Lua代码调用I/O操作等异步接口时,会挂起当前协程(并保护上下文数据),而不阻塞worker;
5、I/O等异步操作完成时还原相关协程上下文数据,并继续运行;
为什么Nginx与ngx_lua结合?
Nginx设计为一个主进程多个工作进程的工作模块,每个进程是单线程处理多个连接,而且每个工作进程采用了非阻塞I/O(select()、poll()等系统调用)来处理多个连接,从而减少了线程上下文切换,从而实现了公认的高性能、高并发;在生产环境中会通过把CPU绑定到Nginx工作进程提升性能;另外因为单线程工作模式的特点,内存占用就非常少了。Nginx更改配置重启速度非常快,可以毫秒级,而且支持不停止Nginx进行升级Nginx版本、动态重载Nginx配置。
每个Nginx worker(工作进程)会创建一个Lua VM(Lua虚拟机)。每个外部请求进入Nginx绑定一个worker进行处理。worker内部针对每一个请求由Lua VM产生一个协程(此协程执行Lua代码进行业务处理),业务处理完毕请求返回后,由Lua VM回收此协程。逻辑上看,每个外部请求生命周期都是在Lua VM中由一个协程完成。
Nginx+Lua的应用场景
Nginx 配合 Lua 可以用于编写高性能的 web 应用,尤其是当需要处理高并发和复杂逻辑时。
以下是一些常见的应用场景:
-
请求限流:使用 Lua 脚本来实现复杂的限流策略。Nginx+Lua可以更好的实现:防重、防抖、防刷;
-
负载均衡:结合 Lua 实现更高级的负载均衡策略。
-
动态上游服务器配置:在运行时根据 Lua 脚本动态更改上游服务器配置。
-
动态路由:根据 Lua 脚本动态计算请求的后端服务器。
-
数据缓存:使用 Lua 表作为缓存机制。
-
身份验证和授权:可以使用 Lua 来实现复杂的身份验证逻辑。
-
灰度发布:lua筛选请求头
Nginx中的LUA脚本
1、主要特点
- 轻量级和高效:Lua 语言本身非常轻量级,并且与 Nginx 紧密结合,可以高效地处理请求。
- 可嵌入性:Lua 代码可以直接嵌入到 Nginx 配置文件中,也可以作为外部文件引用。
- 非阻塞 I/O:Nginx Lua 支持非阻塞 I/O 操作,可以处理高并发场景。
- 共享内存:通过 lua_shared_dict 指令,Lua 脚本可以访问共享的内存区域,用于缓存数据或实现其他功能。
- 与 Nginx 模块的交互:Lua 脚本可以与 Nginx 的其他模块进行交互,如访问请求头、响应头、变量等。
2、用途
- 动态请求处理:使用 Lua 脚本可以根据请求的内容、头部信息或其他条件动态地处理请求,例如重定向、转发、修改响应内容等。
- 访问外部服务:Lua 脚本可以调用外部服务,如数据库、缓存、REST API 等,以获取额外的数据或执行特定的操作。
- 实现复杂的逻辑:对于需要在 Nginx 中实现复杂逻辑的场景,如限流、鉴权、日志记录等,Lua 脚本可以提供一个灵活的解决方案。
- 性能优化:通过 Lua 脚本优化 Nginx 的性能,例如通过缓存机制减少不必要的请求或计算。
- 扩展 Nginx 功能:Lua 脚本可以扩展 Nginx 的功能,实现 Nginx 本身不直接支持的特性或协议。
使用 Lua 扩展 Nginx 功能
Lua是一种轻量级、高效的脚本编程语言,特别适合嵌入到其他应用程序中。
它由Roberto Ierusalimschy、Waldemar Celes和Luiz Henrique de Figueiredo于1993年开发,设计目标是提供一种简单的、易扩展的脚本语言。
Lua的语法简单明了,支持基本的数据类型如数字、字符串、表格等,以及流程控制结构和函数定义。由于其轻量级和高效的特性,Lua在游戏开发、嵌入式系统、脚本扩展等领域得到了广泛应用。
Lua的代码通常以.lua为扩展名保存,并且由于其自动内存管理和易嵌入的特性,Lua成为了一种理想的配置文件和快速原型设计的工具。
此外,Lua支持多种编程范式,包括过程式、面向对象、函数式和数据驱动编程,结合基于关联数组的强大数据描述构建,提供了灵活的扩展性和动态类型。
Lua的运行时环境包括一个基于寄存器的虚拟机,支持字节码解释和具有增量垃圾回收的自动内存管理,使得Lua非常适合用于配置脚本和快速原型设计。
如何在nginx中使用LUA脚本
如果你要用lua脚本,建议直接使用OpenResty,当然原生nginx也可以添加lua模块。
1、原生nginx
nginx安装默认是不支持lua脚本的,需要在安装编译环节,编译安装ngx_http_lua_module模块。安装过程如下:
A、安装lua开发库
虽然ngx_http_lua_module模块本身包含了与Nginx集成的Lua解释器,但你仍然需要Lua的开发库来编译Nginx。
yum install lua -y
B、下载ngx_http_lua_module模块
wget https://github.com/openresty/lua-nginx-module/archive/v0.10.9rc7.tar.gz
tar -xzvf ?lua-nginx-module-0.10.9rc7.tar.gz
C、nginx编译安装lua模块
tar -zxvf nginx-x.y.z.tar.gz ?
cd nginx-x.y.z ?
??
# 假设你已经下载了ngx_http_lua_module并将其放在当前目录下 ?
./configure --prefix=/usr/local/nginx ?
? ? --with-http_ssl_module ?
? ? --add-module=./ngx_http_lua_module ?
??
make ?
make install
然后就可以在nginx中使用lua脚本了
2、OpenResty
Openresty就是一个打包程序,包括大量的第三方Nginx模块,比方HttpLuaModule,HttpRedis2Module,HttpEchoModule等。省去下载模块。而且安装很方便。
所以如果你使用的是OpenResty,那么直接就可以在nginx中使用lua脚本。
安装OpenResty很简单,用yum安装就可以:yum install openresty -y
安装目录在/usr/local/openresty
可以用openresty命令进行管理,和nginx的命令使用一模一样
(当然也可以去openresty安装目录下的nginx目录下的sbin目录用nginx命令管理)
直接执行命令openresty 就可以启动了
访问就会出现欢迎页面了,和原生Nginx一模一样
3、nginx lua配置验证
可以在nginx配置文件中,加入一条简单的lua脚本,验证当前nginx是否支持lua脚本
? ? ? ? location /hello {
? ? ? ? ? ? # 使用 Lua 脚本生成响应体
? ? ? ? ? ? content_by_lua_block {
? ? ? ? ? ? ? ? ngx.say("Hello, World!")
? ? ? ? ? ? ? ? ngx.exit(ngx.HTTP_OK)
? ? ? ? ? ? }
? ? ? ? }
保存配合文件之后,nginx -t 测试配置文件是否ok,如果ok,说明支持lua脚本语法

Nginx执行lua的步骤
Nginx执行Lua脚本的步骤通常包括以下几个步骤:
-
安装OpenResty:OpenResty将Nginx与Lua进行集成,安装OpenResty可以直接获得支持Lua的Nginx。
-
配置Nginx:在Nginx配置文件中添加Lua代码处理的相关配置。
-
编写Lua脚本:在Nginx服务器的指定目录下编写Lua脚本。
-
配置Lua脚本的执行:在Nginx配置文件中引用Lua脚本,并指定何时执行。
-
重载Nginx配置:修改配置后,需要重载Nginx使配置生效。
示例配置:
http {
server {
listen 80;
location /lua_content {
# 设置内容类型
default_type 'text/plain';
# 执行Lua脚本
content_by_lua_block {
ngx.say('Hello, Lua!')
}
}
}
}
在上述配置中,当访问/lua_content路径时,Nginx将执行Lua脚本,输出 “Hello, Lua!”。
Nginx执行lua过程详解
这里只做简单介绍;
1、post-read
读取请求内容阶段,nginx读取并解析完请求头之后就立即开始运行;
2、server-rewrite
server请求地址重写阶段;
3、find-config
配置查找阶段,用来完成当前请求与location配重块之间的配对工作;
4、rewrite
location请求地址重写阶段,当ngx_rewrite指令用于location中,就是再这个阶段运行的;
5、post-rewrite
请求地址重写提交阶段,当nginx完成rewrite阶段所要求的内部跳转动作,如果rewrite阶段有这个要求的话;
6、preaccess
访问权限检查准备阶段,ngx_limit_req和ngx_limit_zone在这个阶段运行,ngx_limit_req可以控制请求的访问频率,ngx_limit_zone可以控制访问的并发度;
7、access
权限检查阶段,ngx_access在这个阶段运行,配置指令多是执行访问控制相关的任务,如检查用户的访问权限,检查用户的来源IP是否合法;
8、post-access
访问权限检查提交阶段;
9、try-files
配置项try_files处理阶段;
10、content
内容产生阶段,是所有请求处理阶段中最为重要的阶段,因为这个阶段的指令通常是用来生成HTTP响应内容的;
11、log
日志模块处理阶段;
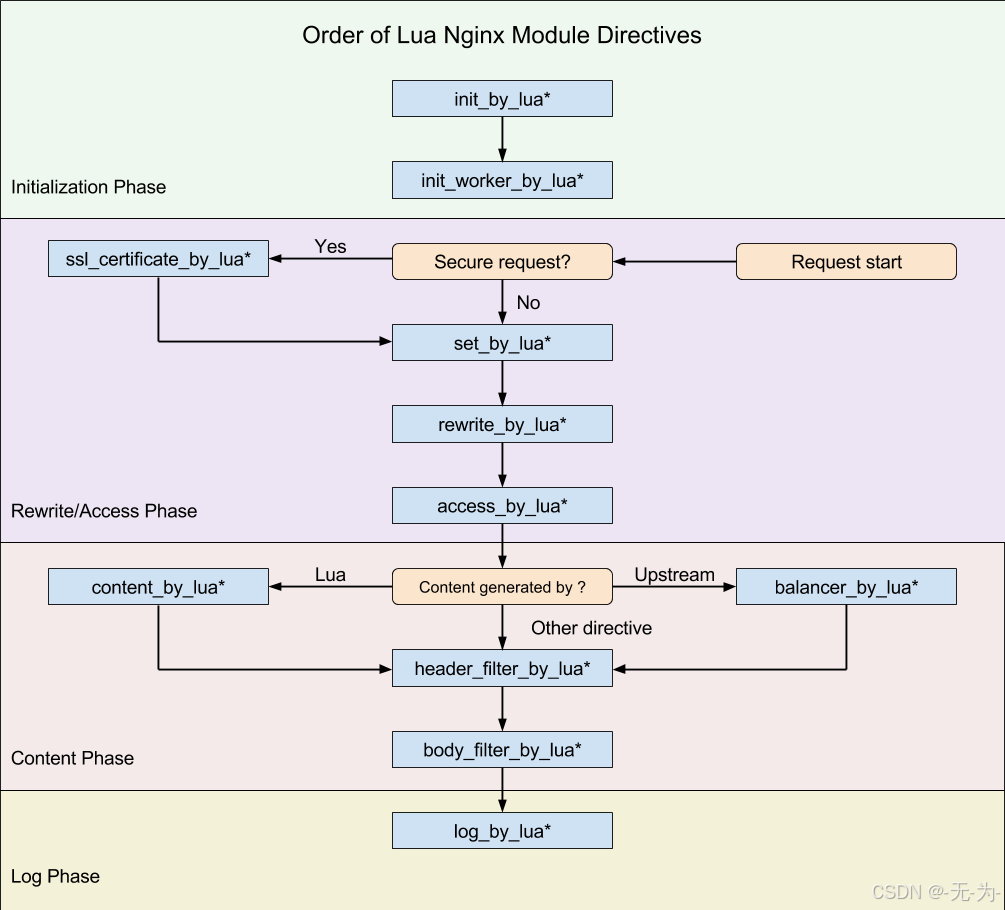
Ngx_lua运行的命令
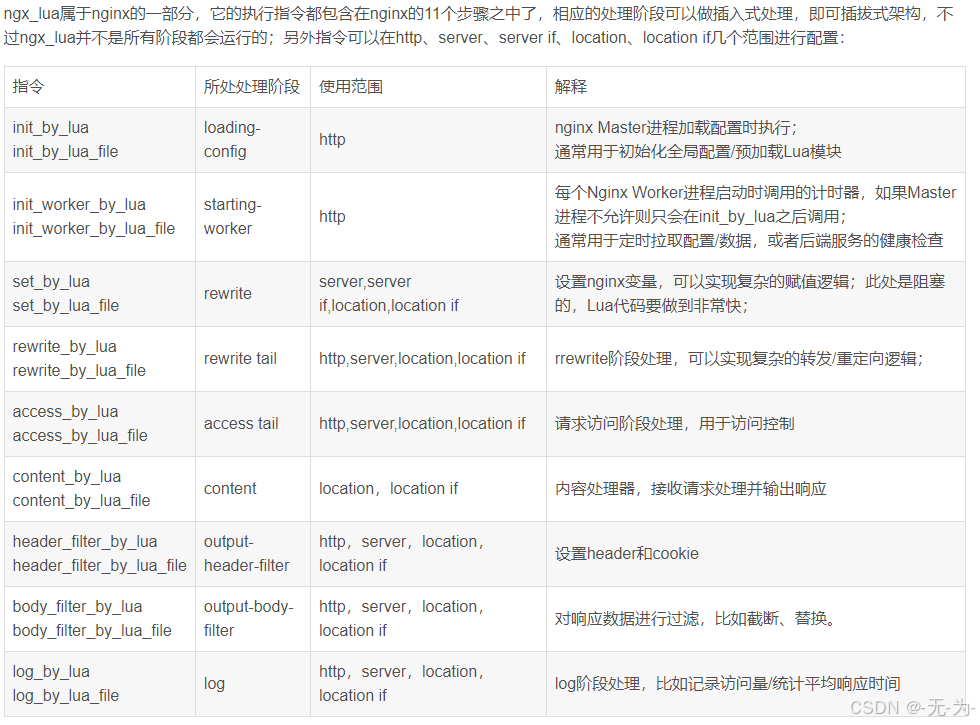
Nginx+Lua实际应用场景示例
实际上nginx+lua虽然暂时取代不了后端成熟的phpjavapython之流但是在一些简单逻辑处理+高并发负载的情况下nginx+lua的搭配完全可以让你眼前一亮.
下面列举了nginx+lua使用案例,真实场景要复杂很多,为了方便大家理解,特意将案例做了简化。
场景1: 灰度发布应用场景
灰度发布是一种平滑过渡的发布方式。灰度发布可以保证整体系统的稳定在初始灰度的时候就可以发现、调整问题以保证其影响度。比如淘宝想要发布一个应用但为了保障整体系统的稳定选择让浙江省的用户先体验新系统然后再慢慢推广到全国。
我们可以选择Nginx+lua可实现这个灰度发布场景。下面我来用简单的代码介绍下是如何实现的。
首先我们先写如下的文件保存为release.lua
clientip=ngx.req.get_headers()["ip"] --- 获取客户端IP真实情况下需要判断X-Real-IP X-Forworded—For这里用ip代替客户端的IP
is_in=0
local ipfile = io.open("iplist.txt","r") ---读取IP地址库这里我们可以使用Redis或者Memcached代替可以后台处理。
local ip_arr = {}
for line in ipfile:lines() do
? ? table.insert(ip_arr,line);
end
for i=1,#ip_arr do
? ? if clientip==ip_arr[i] then
? ? ? ? is_in=1
? ? end
end
if is_in == 1 then
? ? ngx.exec('/test_env'); ? ? ?--- 如果是在浙江的用户跳转到新系统中
else
? ? ngx.exec('/product_env'); ? --- 如果是其他的用户还是在原先的生产环境
end
我们的nginx.conf可以这么配置
server {
? ? server_name localhost;
? ? lua_code_cache off; ?--- 如果开启Lua_cache可以大幅度提高处理请求的能力
? ? listen 10013;
? ? default_type 'text/plain';
? ? location ?= / { content_by_lua_file luafile/release.lua;
? ? }
? ? location = /test_env {
? ? ? ? content_by_lua '
? ? ? ? ? ? ngx.say("我是浙江省用户所以我在新的测试系统上"); --- 实际上我们可以使用proxy_pass到后端服务的端口
? ? ? ? ';
? ? }
? ? location = /product_env {
? ? ? ? content_by_lua '
? ? ? ? ? ? ngx.say("我是非浙江省用户所以我仍然在原先的生产环境上.");
? ? ? ? ';
? ? }
}
我们接下来使用curl测试
场景1-入口层流量的灰度识别
何谓入口层流量的灰度识别呢,简单来说就是A用户的请求打到线上环境,B用户的请求打到灰度环境,目的就是做新功能的验证,实现逻辑很简单,大体流程如下:
1.测试同学在灰度控制台配置灰度规则,规则里会约束哪些url下哪些商户的请求进入灰度环境;
2.灰度控制台推送规则给入口层nginx,nginx会将规则存储到本地内存中,借助ngx.shared.DICT;
3.请求进入的时候(通过rewrite_by_lua_file触发)获取本地内存中的规则进行比对,如何命中规则就将请求转发到灰度环境,对nginx来说就是切换不同的upstream,比如线上是prod_serverA,灰度是gray_serverA;
代码片段如下:
upstream gray_serverA {
server 192.68.1.1:8080;
}
upstream prod_serverA {
server 192.68.1.2:8080;
}
server {
listen 80;
server_name graytest.demo.com;
charset utf-8;
location ~ .do$ {
set $backend 'prod_serverA'; #默认的upstream为线上服务
rewrite_by_lua_file "conf/lua-gray/rewriter.lua"; # <a href="https://github.com/openresty/lua-nginx-module/#rewrite_by_lua_file" target="_blank">rewrite_by_lua_file</a> 可以简单的理解为一个过滤器,nginx在rewrite阶段会执行你指定的脚本文件,
#在这个文件中我们会判断请求是否为灰度请求如果是灰度请求就将backend改为gray_serverA
proxy_pass http://$backend;
}
}
场景2: 秒杀活动
某电商曾经做过抽奖秒杀活动。举办一场秒杀无异于发动一次对于自己的DDos攻击,尤其是淘宝或者支付宝这样的大型网站。所以我们可以如此设计由Nginx+lua接受用户请求我们通过lua直接放弃大部分的请求剩下的10%交由java server处理这样就可以减轻了各方的压力。
我们来看一下我写的nginx.conf
server {
? ? server_name localhost;
? ? lua_code_cache off;
? ? listen 10014;
? ? default_type 'text/plain';
? ? location ?= / {
? ? ? ? content_by_lua '
? ? ? ? ? ? ip=ngx.req.get_headers()["ip"] ?---获取客户端IP
? ? ? ? ? ? ip = string.sub(ip,-1)
? ? ? ? ? ? --- 根据时间和客户端IP设为随机数种子当然也可以选取Header或者其他元素设为种子目标是分离同一秒内的压力
? ? ? ? ? ? math.randomseed( tonumber(tostring(os.time()+ip):reverse():sub(1,6)) )
? ? ? ? ? ? math.random();math.random();math.random()
? ? ? ? ? ? rand = math.random(100)
? ? ? ? ? ? if rand > 95 then
? ? ? ? ? ? ? ? ngx.say("开始抽奖,发送请求给后端Java,PHP等再继续处理") --实际情况是proxy给后端
? ? ? ? ? ? else
? ? ? ? ? ? ? ? ngx.say("lua抛弃请求,直接返回未中奖结果给用户")
? ? ? ? ? ? end
? ? ? ? ';
? ? }
}
我们仍然使用curl模拟浏览器行为测试
虽然以下两个请求是同时请求的但是由于IP(header区分),引大部分流到lua端处理大幅度减轻后端的压力。
场景3:API调用
一次双11活动一天有1亿笔交易背后带来是的是几十亿次服务调用对于服务器的压力可想而知这时候有nginx+lua提供API接口服务完全可以解决这个问题。
我们来看一下mysql.lua
# 添加MySQL配置
upstream backend {
? ? drizzle_server 127.0.0.1 dbname=dbname password=123456 user=root protocol=mysql ? ? ? ? charset=utf8;
? ? }
server {
? ? server_name localhost;
? ? # lua_code_cache off;
? ? listen 10012;
?
? ? location /a {
? ? ? ?drizzle_query "select * from test_user where userid=$arg_id";
? ? ? ?drizzle_pass backend;
? ? ? ?rds_json on;
? ? }
? ? # 查看MySQL状态
? ? location = /mysql-status {
? ? ? ? drizzle_status;
? ? }
} ??
然后我们通过drizzle模块很轻松的可以访问MySQL而且这也完全是非阻塞的。
我们使用curl模拟一下发送请求。
这个时候返回的是json格式的数据由前端Js做页面渲染这个已经在淘宝量子统计部门大量使用了。
nginx+lua的使用也不是万能的但是在一些场合下的确能够带来很大的好处我们可以基于ngx_lua来完成传统fastcgi的大部分工作我们选用这些技术必须在充分了解的前提下并结合业务需要做出权衡也不能忙碌的追求性能
场景4:入口层记录错误日志
springmvc偶尔会报415错误,这个错误的一个常见原因是传递的Content-Type头不对,比如后端需要application/json,但是前端传递了application/x-www-form-urlencoded,那就会报这个错。
但是跟前端确认了传递的头是没有问题的,有人猜测可能是头信息有特殊字符,导致后端web 容器(tomcat、resin)解析头出现了问题,既然这样把所有请求头打出来一看究竟,于是lua再一次出场,这次主要用来输出请求头到日志文件中,主要用到了log_by_lua_block这个指令,代码片段如下:
location ~ .do$ {
proxy_pass http://$backend;
log_by_lua_block {
//判断下如果http 响应状态码为415就输出请求头到文件中
if tonumber(ngx.var.status) == 415 then
ngx.log(ngx.ERR,"upstream reponse status is 415,please notice it,here are request headers:")
local h, err = ngx.req.get_headers(100,true)
if err == "truncated" then
ngx.log(ngx.ERR,"request headers beyond 100,will not return")
else
local cjson = require("cjson")
ngx.log(ngx.ERR,cjson.encode(h))
end
end
}
}
场景5:将nginx信息注册到监控平台
需求很简单,当nginx启动的时候将自身信息上报到redis中,上报内容包扣自身的ip,代理的域名信息等,有个监控平台会定期从redis读取这些信息做展示,方便运维干活,流程很简单就是定时读取自身ip和代理的域名信息写到redis中,为什么要定时呢,这里还起到一种心跳的效果,当长时间没有上报时可能是nginx出问题了,主要用到的指令如下:
1.init_worker_by_lua_file “conf/ua-grayngxReloadListener.lua”,当nginx启动或者reload的时候会执行指定的文件;
2.ngx.worker.id() 这个方法会返回nginx worker进程的编号,从0开始,如果nginx有4个worker,那取值范围为0-3,这个主要是为了防止并发上报,因为第一步里面提到的init_worker_by_lua_file,如果有几个worker就会触发几次,所以为了只上报一次,会判断下返回值是否为0,也就是只让第一个worker执行;
3.ngx.timer.every 用来执行定时任务;
代码片段如下:
local workerId = ngx.worker.id()
if(workerId == 0) then
ngx.log(ngx.INFO,'workerId is 0 will startup task')
local ok, err = ngx.timer.every(4,function()
#1. get local ip and domins
#2. write to redis
end)
else
ngx.log(ngx.INFO,'workerId is not 0 ,just ignore it')
end
场景6:将入口层流量同时转发到多个后端服务
类似于消息队列的发布订阅一样,在nginx这一层可以将一个请求同时发到多个地址,代码片段如下:
location ~ /capture_test$ {
content_by_lua_block {
ngx.req.read_body()
res1, res3 = ngx.location.capture_multi{
{ "/capture_test1",{ method = ngx.HTTP_POST, always_forward_body=true}},
{ "/capture_test2",{ method = ngx.HTTP_POST, always_forward_body=true}},
}
ngx.say(res3.body)
ngx.exit(res3.status)
}
场景7:Modified Long Polling长连接 和共享内存
此方案的主要思路是这样的:使用Nginx作为服务端,通过Lua协程来创建长连接,一旦数据库里有新数据,它便主动通知Nginx,并把相应的标识(比如一个自增的整数ID)保存在Nginx共享内存中,接下来,Nginx不会再去轮询数据库,而是改为轮询本地的共享内存,通过比对标识来判断是否有新消息,如果有便给客户端发出响应。
首先,我们简单写一点代码实现轮询(篇幅所限省略了查询数据库的操作):
lua_shared_dict config 1m;
server {
location /push {
local id = 0;
local ttl = 100;
local now = ngx.time();
local config = ngx.shared.config;
if not config:get("id") then
config:set("id", "0");
end
while id >= tonumber(config:get("id")) do
local ttl = math.random(ttl - 10, ttl + 10);
if ngx.time() - now > ttl then
break;
end
ngx.sleep(1);
end
ngx.say("OK");
}
...
}
注:为了解决服务端不知道客户端何时断开连接的情况,代码中引入超时机制。
其次,我们需要做一些基础工作,以便操作Nginx的共享内存:
lua_shared_dict config 1m;
server {
location /config {
content_by_lua '
local config = ngx.shared.config;
if ngx.var.request_method == "GET" then
local field = ngx.var.arg_field;
if not field then
ngx.exit(ngx.HTTP_BAD_REQUEST);
end
local content = config:get(field);
if not content then
ngx.exit(ngx.HTTP_BAD_REQUEST);
end
ngx.say(content);
ngx.exit(ngx.HTTP_OK);
end
if ngx.var.request_method == "POST" then
ngx.req.read_body();
local args = ngx.req.get_post_args();
for field, value in pairs(args) do
if type(value) ~= "table" then
config:set(field, value);
end
end
ngx.say("OK");
ngx.exit(ngx.HTTP_OK);
end
';
}
...
}
如果要写Nginx共享内存的话,可以这样操作:
shell> curl -d id=123 http:///config
如果要读Nginx共享内存的话,可以这样操作:
shell> curl http:///configfield=id
注:实际应用时,应该加上权限判断逻辑,比如只有限定的IP地址才能使用此功能。
当数据库有新数据的时候,可以通过触发器来写Nginx共享内存,当然,在应用层通过观察者模式来写Nginx共享内存通常会是一个更优雅的选择。
如此一来,数据库就彻底翻身做主人了,虽然系统仍然存在轮询,但已经从轮询别人变成了轮询自己,效率不可相提并论,相应的,我们可以加快轮询的频率而不会造成太大的压力,从而在根本上提升用户体验。

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









