







文章目录
一、上传文件到集群
hadoop103上传一个服务器的小文件:
hadoop fs -mkdir /input
刷新页面可以看到:
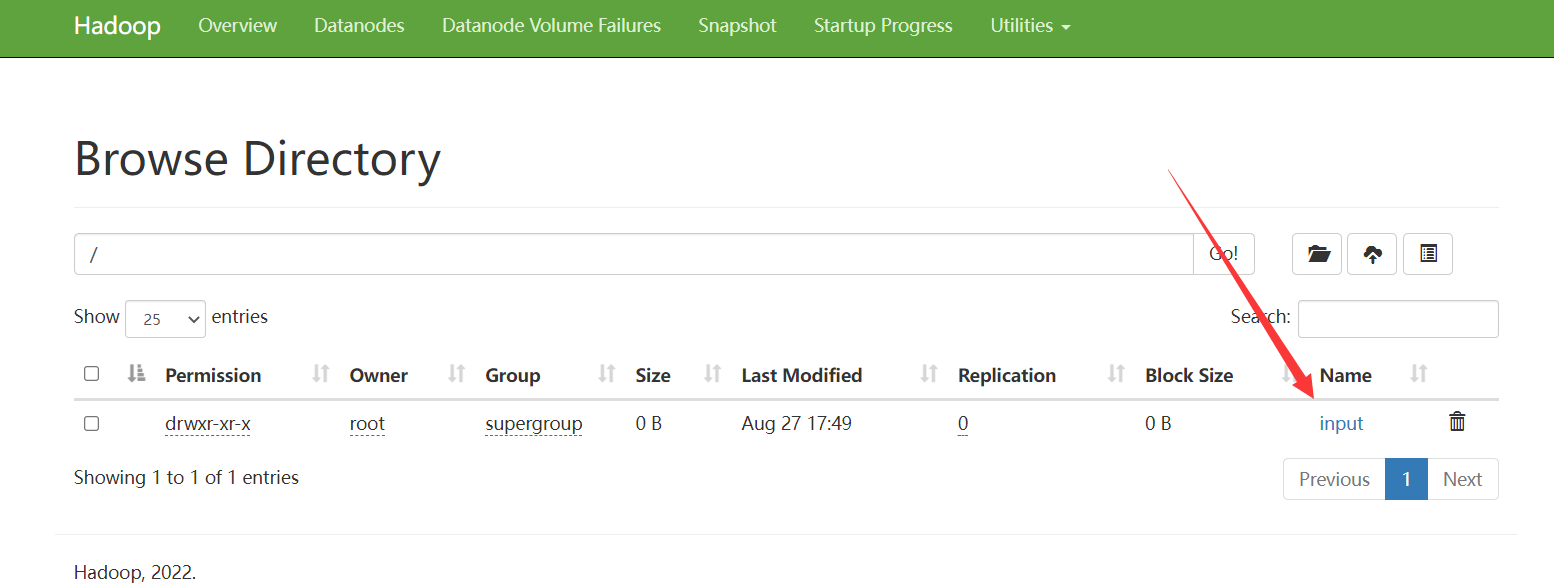
hadoop102试试:
hadoop fs -mkdir /test
刷新如下,还是可以的:
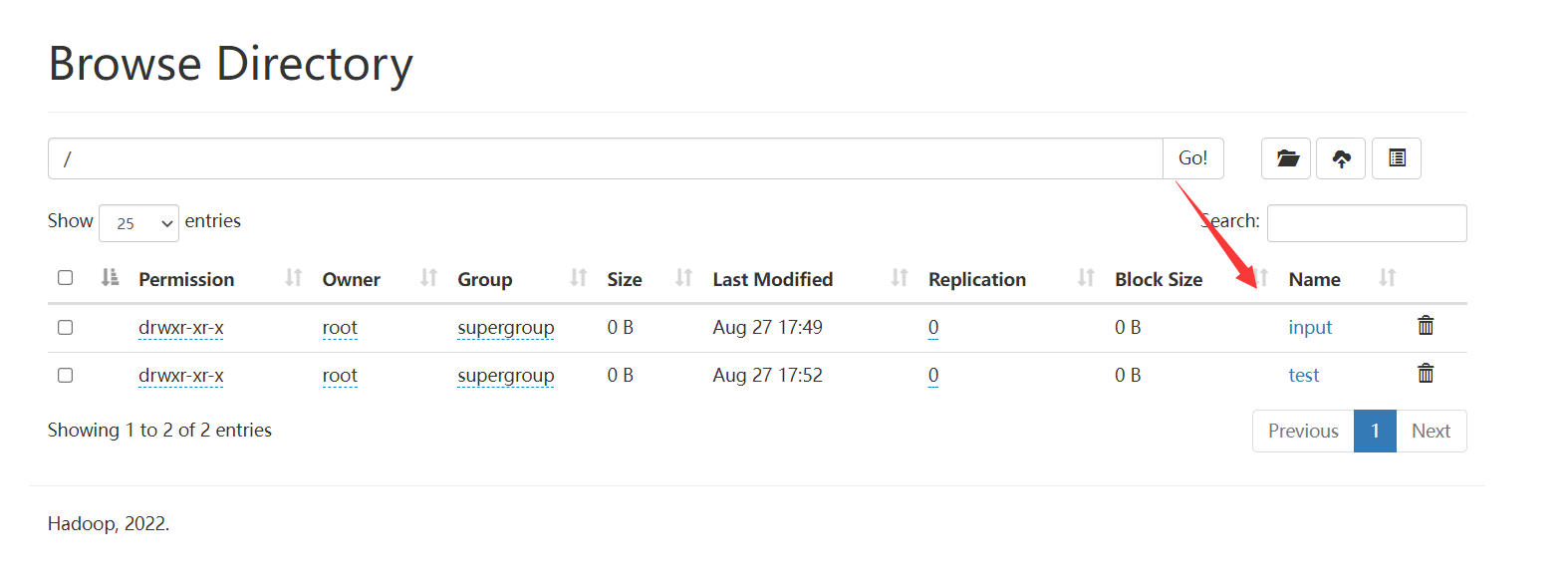
上传一个文件a.txt到test文件夹:
hadoop fs -put a.txt /test
如下:
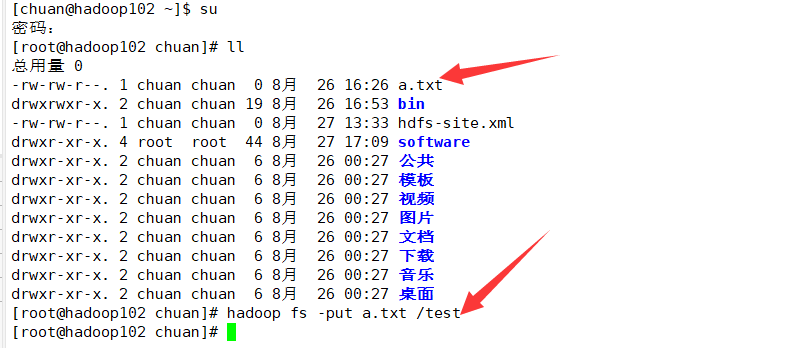
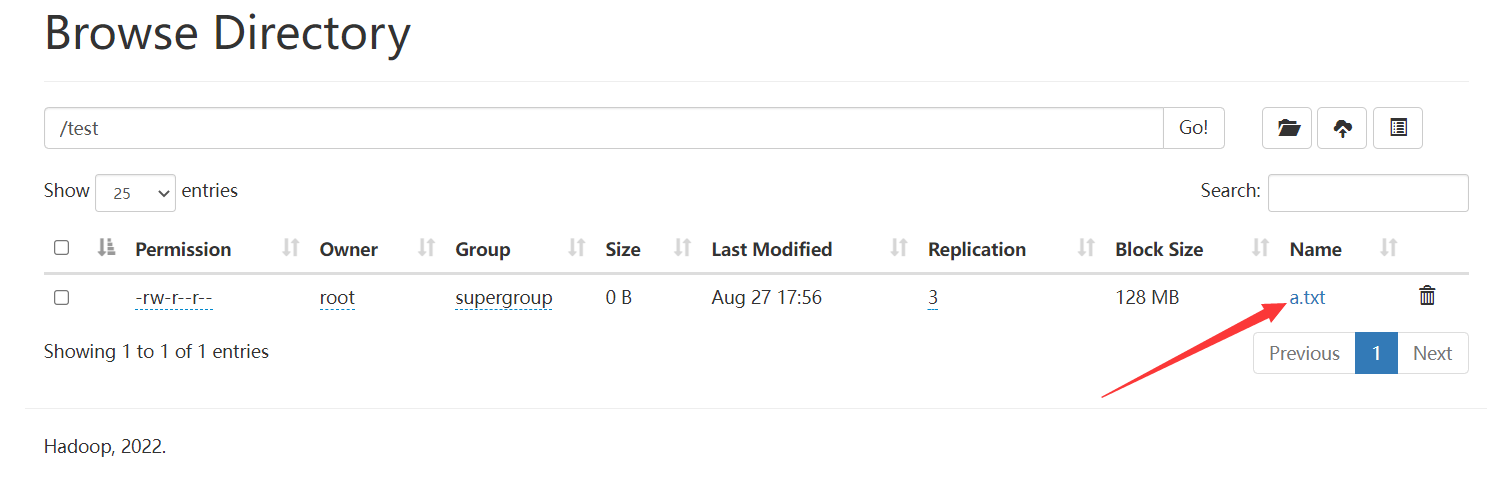
再试试上传大文件:
hadoop fs -put jdk-13.0.2_linux-x64_bin.tar.gz /test
如下:
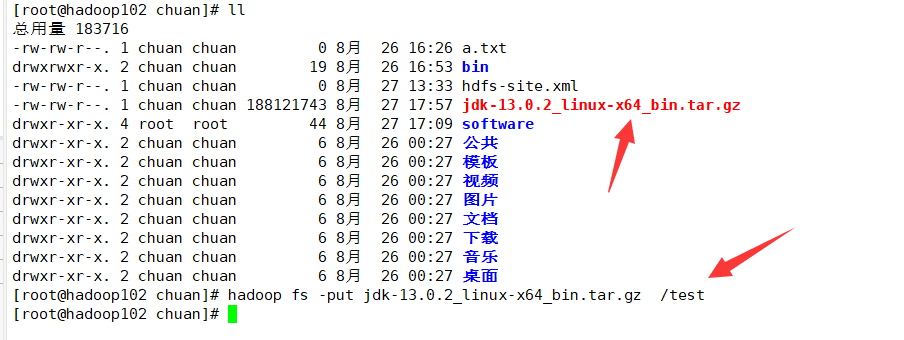
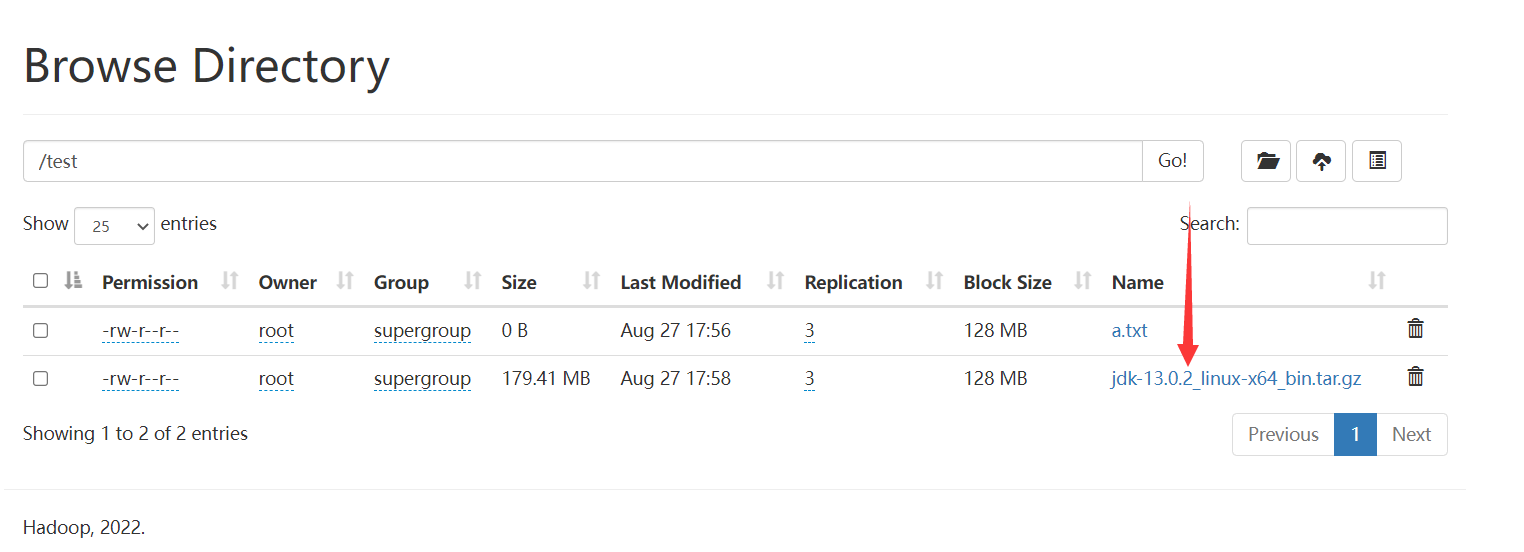
这里面实际只存储了一个链接,实际存储的数据在datanode节点
查看目录:
hadoop fs -ls /
如下:

二、上传的文件存放位置
cd到数据的目录:
cd /home/chuan/software/hadoop-3.2.4/data/temp/dfs/data/current
如下:

其中数据就在BP-258424537-192.168.10.102-1661593286435中,cd进去:
cd BP-258424537-192.168.10.102-1661593286435、current/finalized/subdir0/subdir0
最终确定完整路径为:
/home/chuan/software/hadoop-3.2.4/data/temp/dfs/data/current/BP-258424537-192.168.10.102-1661593286435/current/finalized/subdir0/subdir0
如下:
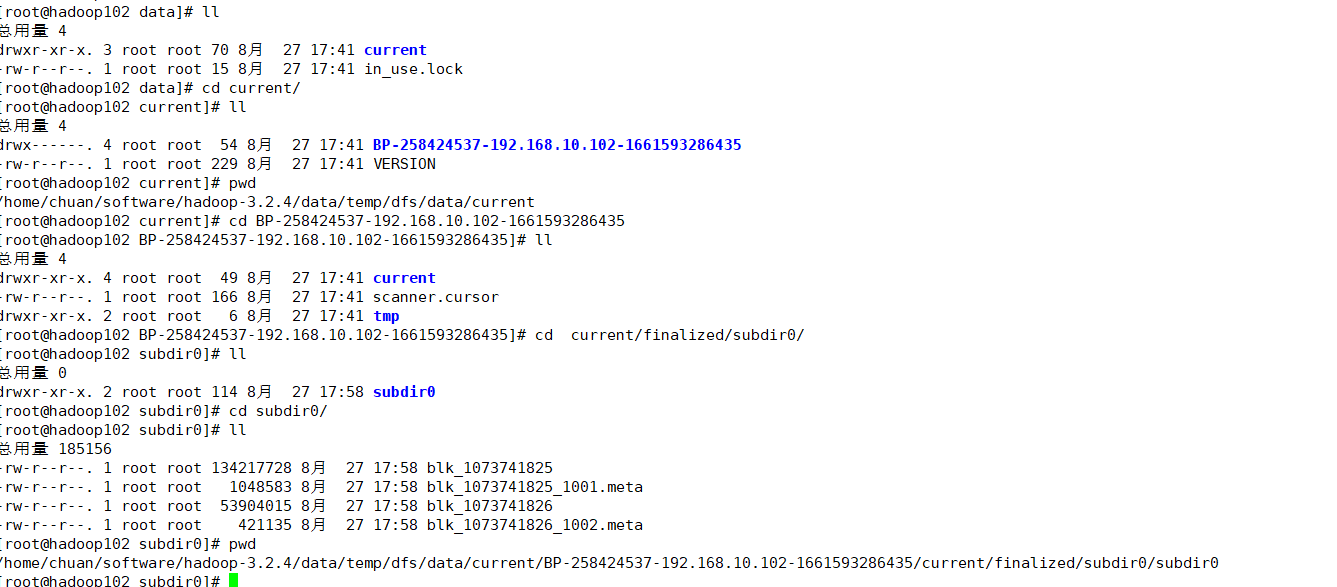
blk_1073741825和blk_1073741825_1001.meta中就是相关文件。
文件的命名和命令行终端不同,命名规则是 “blk_”+ID,后面 .meta也是存储信息的描述
2.1 拼接
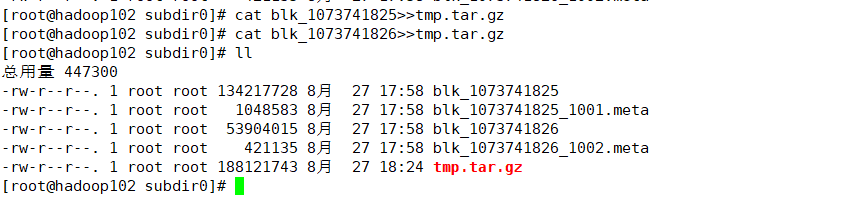
解压:
tar -zxvf tmp.tar.gz
查看路径:
pwd
即HDFS存储的文件就在:
/home/chuan/software/hadoop-3.2.4/data/temp/dfs/data/current/BP-258424537-192.168.10.102-1661593286435/current/finalized/subdir0/subdir0
2.2 执行程序
使用自带的wordcount测试:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount /input /output
















 3185
3185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









