







文章目录
Hadoop 集群小案例
有些什么小任务都放在里面
一,词频统计
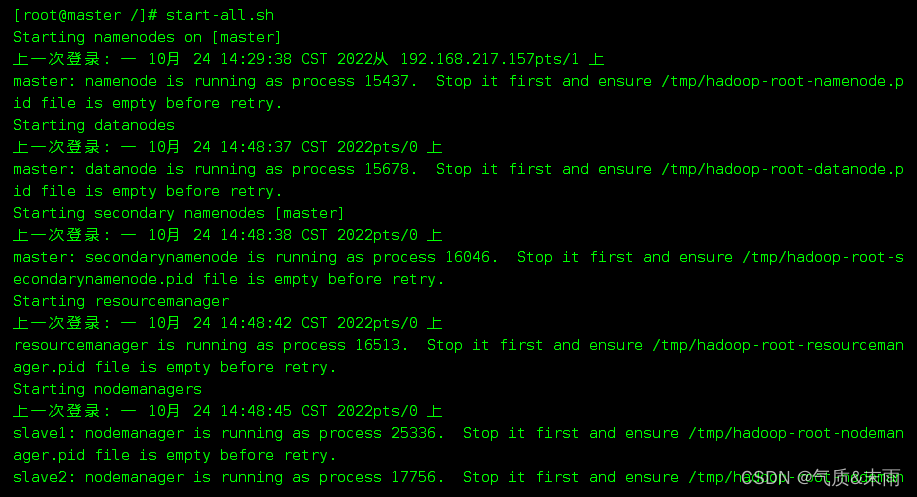
1,第一步,先启动Hadoop集群
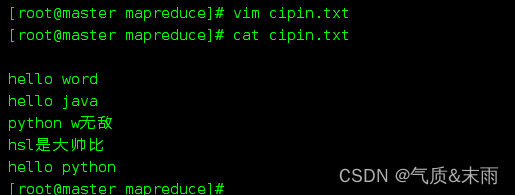
2,创建一个文件,用来装词频统计所需要的用到的词
创建一个cipin.txt

查看一下刚刚随便写的一些语句
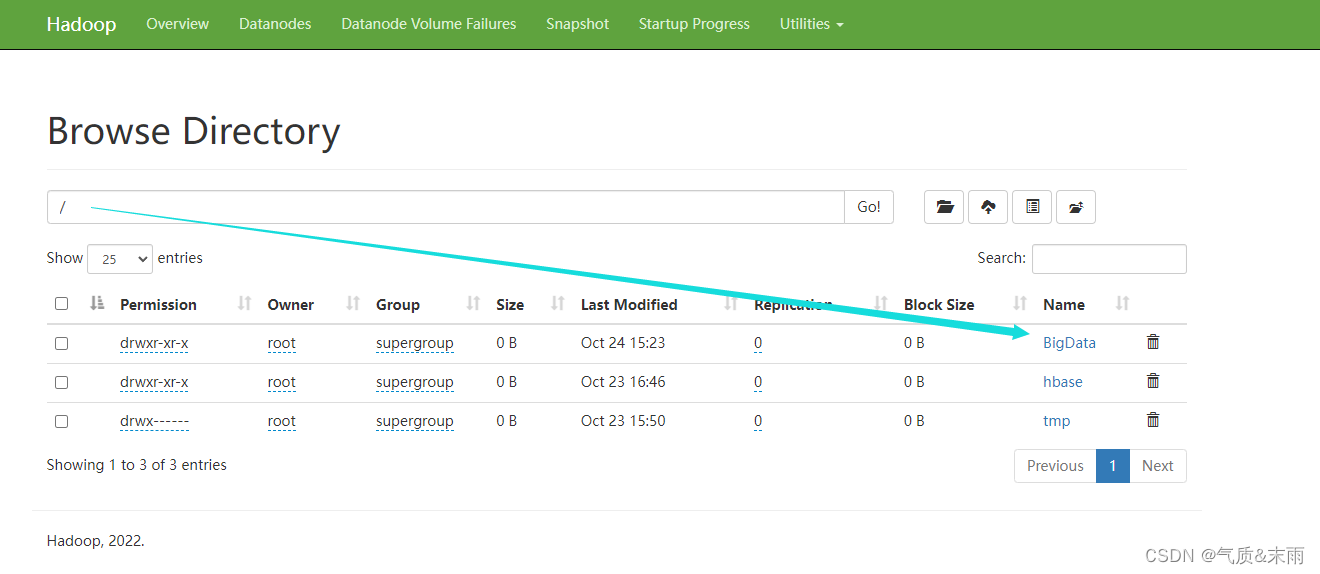
3,在HDFS上创建一个文件夹,/BigData
输入命令: hdfs dfs -mkdir /BigData

可以看到执行完命令后,hadoop集群上多了一个 /BigData
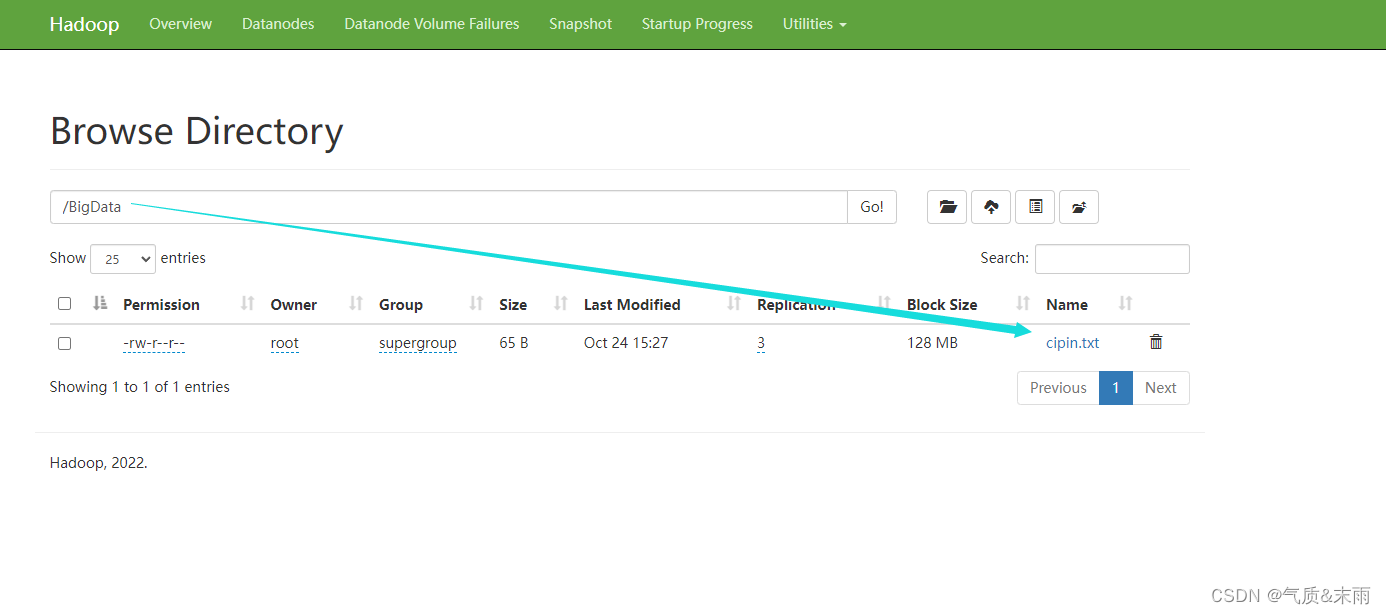
4,将文件上传到HDFS指定的目录
把刚刚创建的 cipin.txt 上传到HDFS的 /BigData 这个文件上
输入命令: hdfs dfs -put cipin.txt /BigData

/BigData 下面就有了这个cipin.txt 文件了
5,运行词频统计程序的jar包
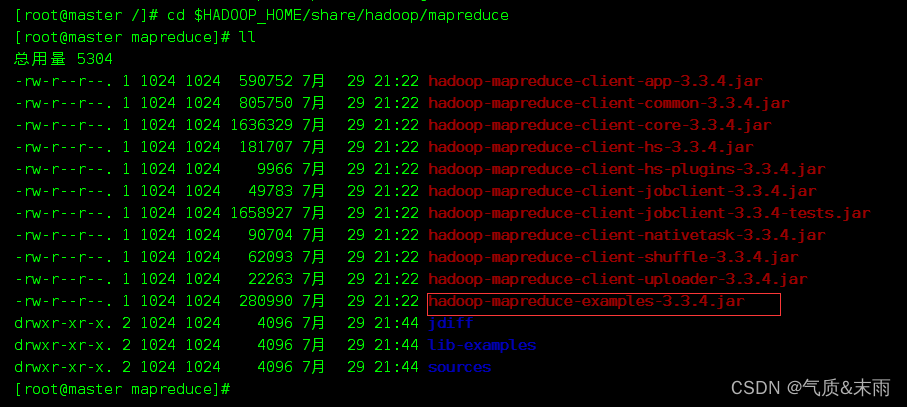
输入命令: cd $HADOOP_HOME/share/hadoop/mapreduce 可以看到有很多的包,我们这里要使用的是最后一个
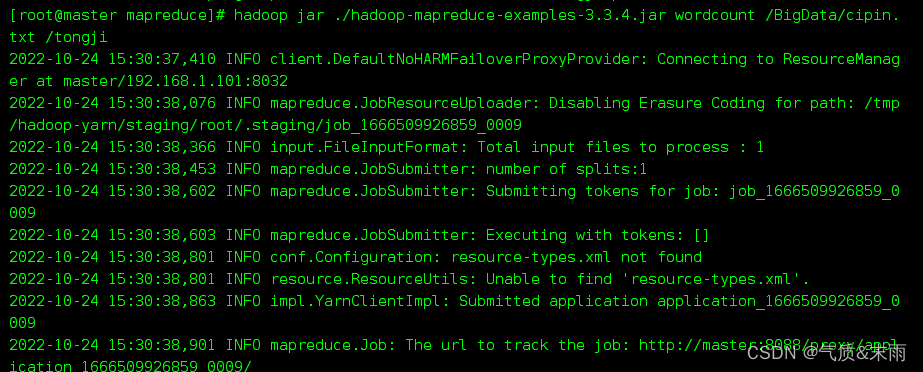
输入命令: hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount /BigData/cipin.txt /tongji
意思就是调动 hadoop下的jar包 hadoop-mapreduce-examples-3.3.4.jar 词频统计 目标文件,然后最后那个是统计完的结果放在 /tongji 这个文件中
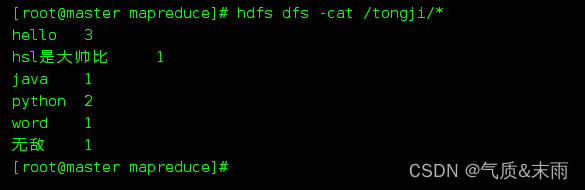
输出查看刚才的存放结果的目录 /tongji,可以看到下面有两个文件

查看词频统计结果,执行命令:hdfs dfs ls /tongji/* ,*是通配符所有,必须要加
6,在HDFS集群UI界面查看生成的结果文件
在HDFS集群UI界面生成了一个tongji目录,查看 /tongji 目录
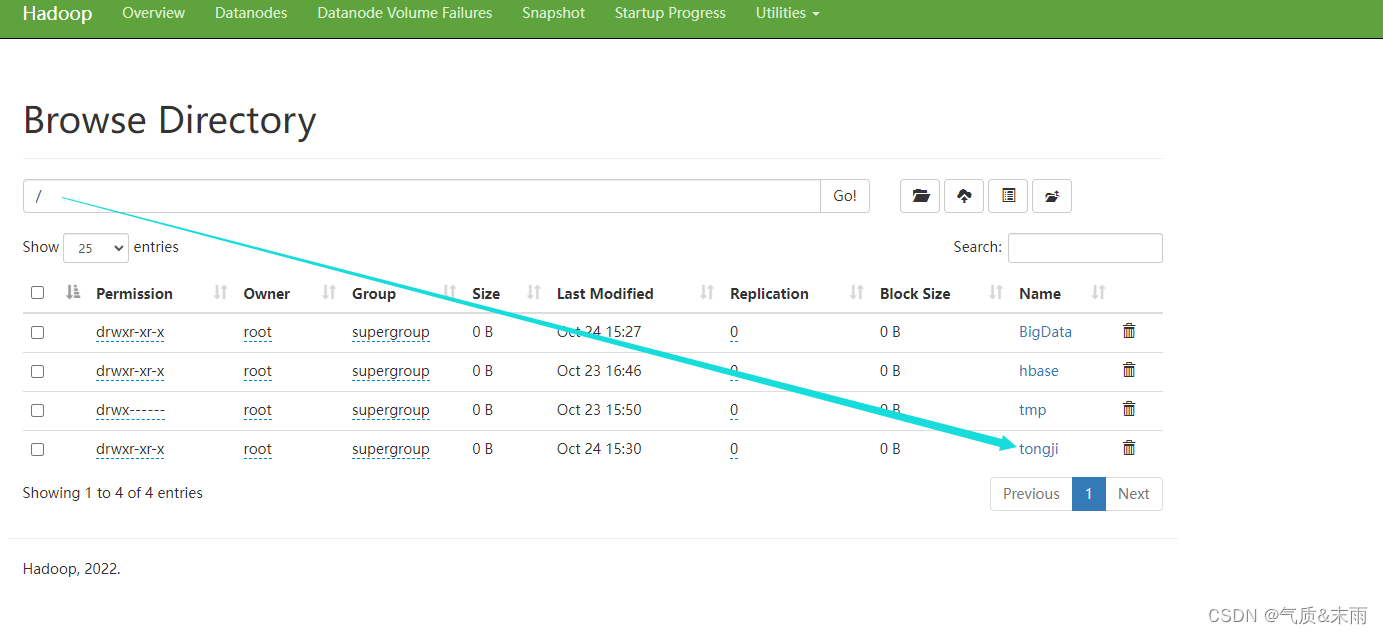
下面有两个目录,查看结果存放目录
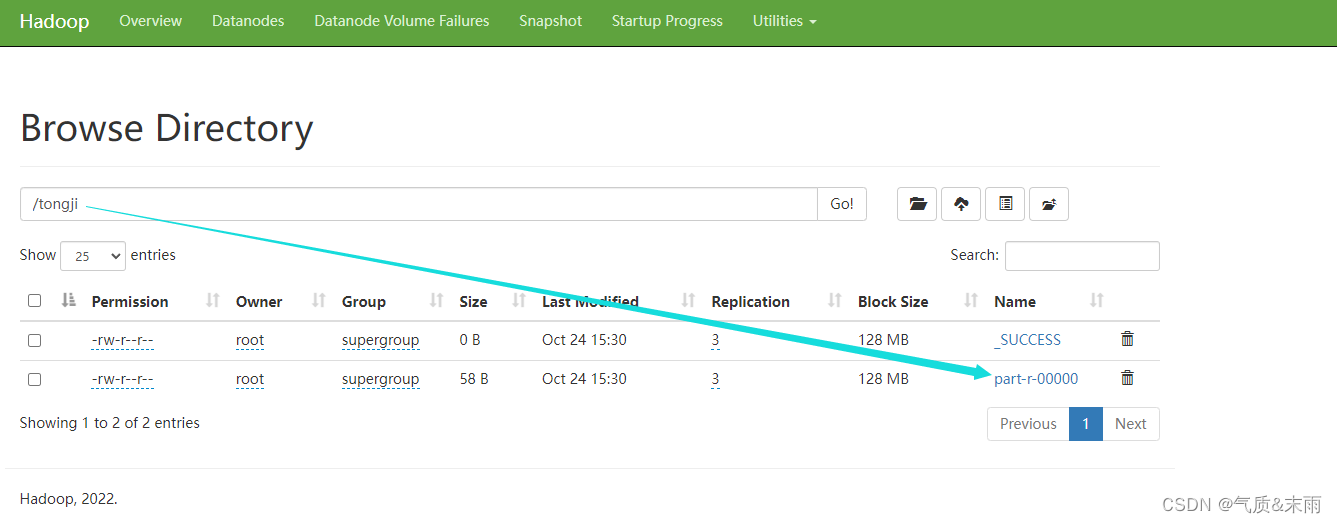
点击之后,会出现一个Download,单击下载到本地
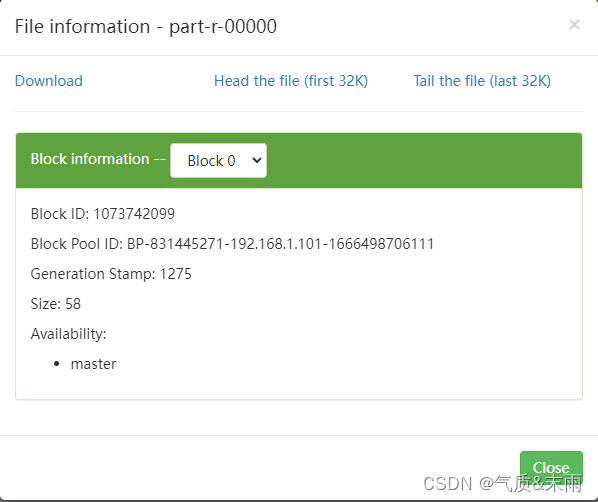
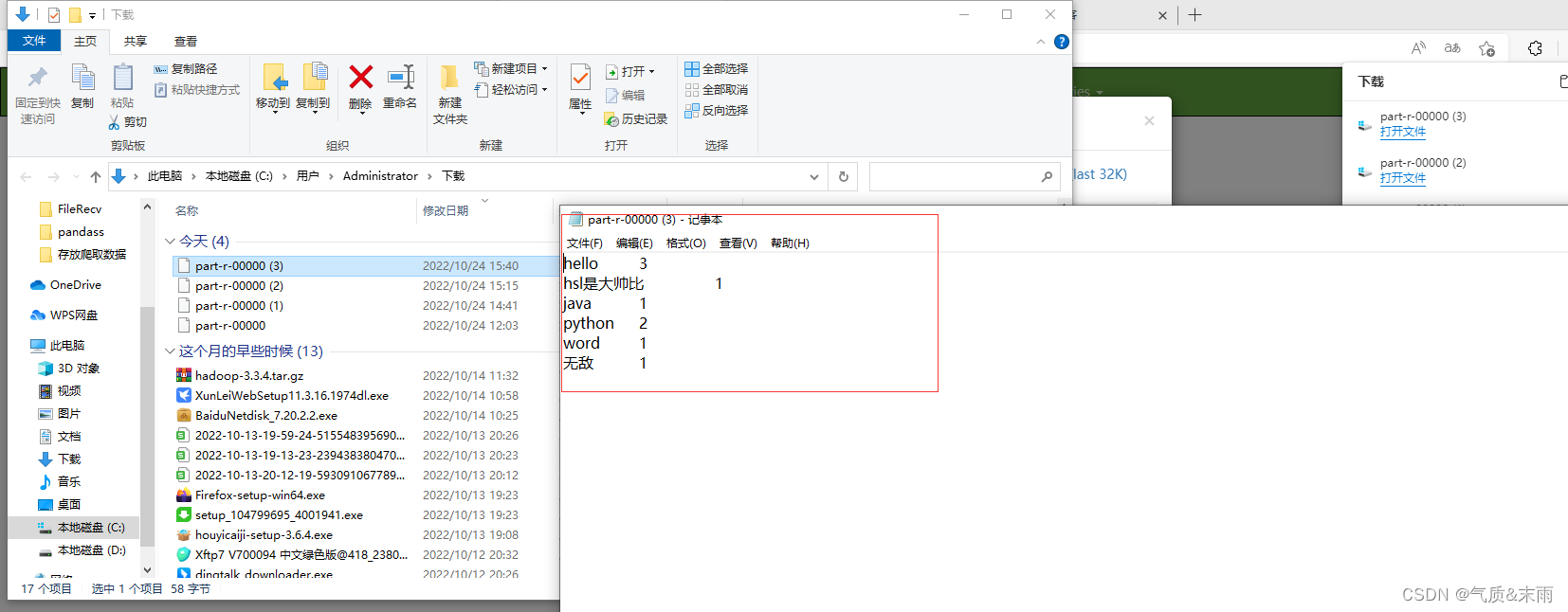
下载到本地,用记事本打开就行了














 4599
4599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









