







文章目录
前言
必备条件:
- 电脑内存最好8G以上
- 虚拟机ip为静态ip!!!且可以 ping 通外网!!!
提示:若满足以上条件,下面案例可供参考
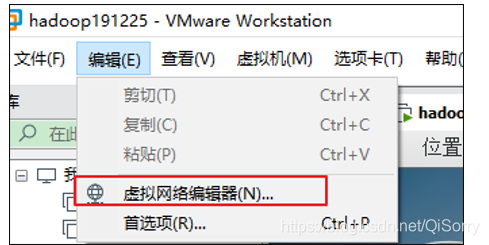
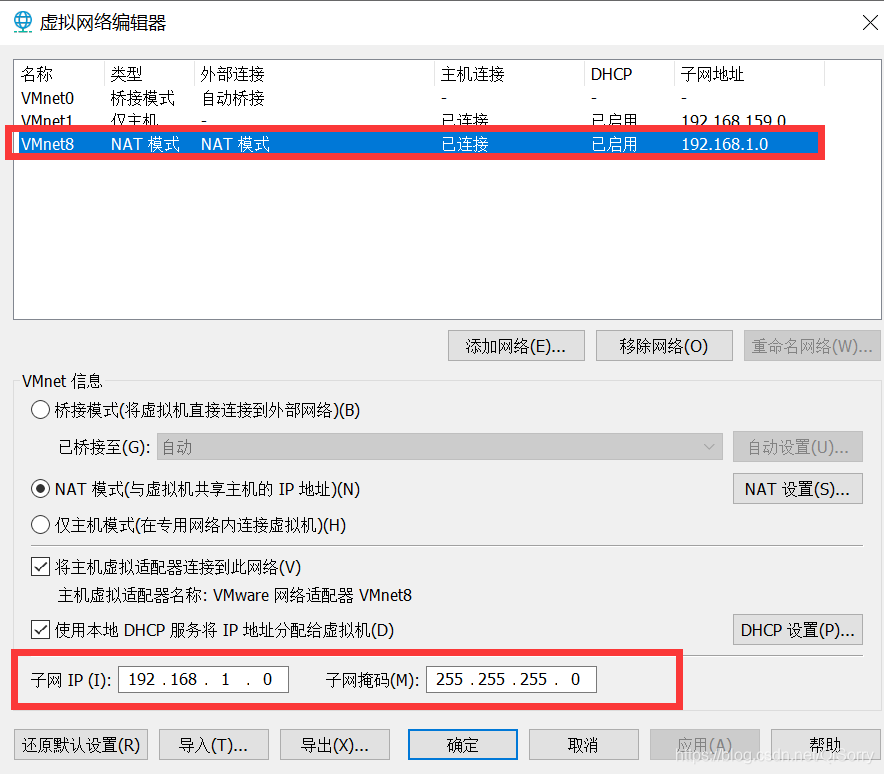
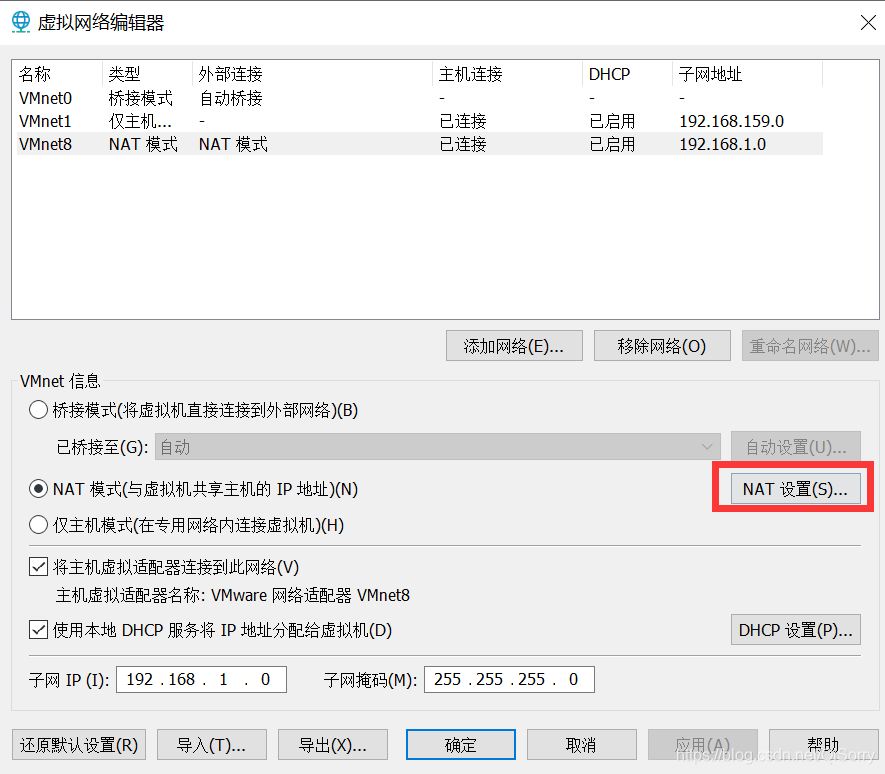
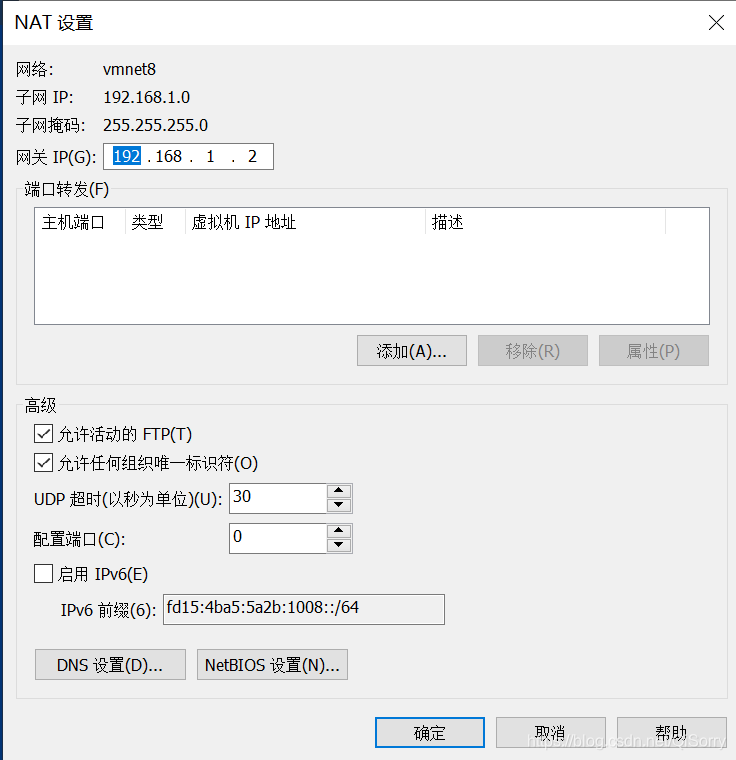
虚拟机网络配置
如果虚拟机不能ping通外网或者非静态ip可以参考如下配置
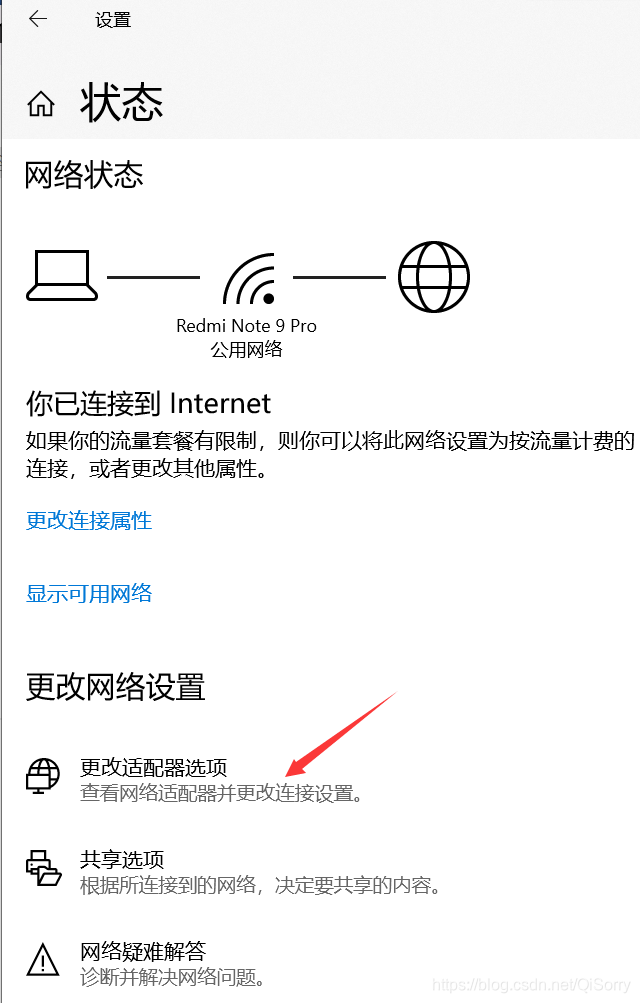
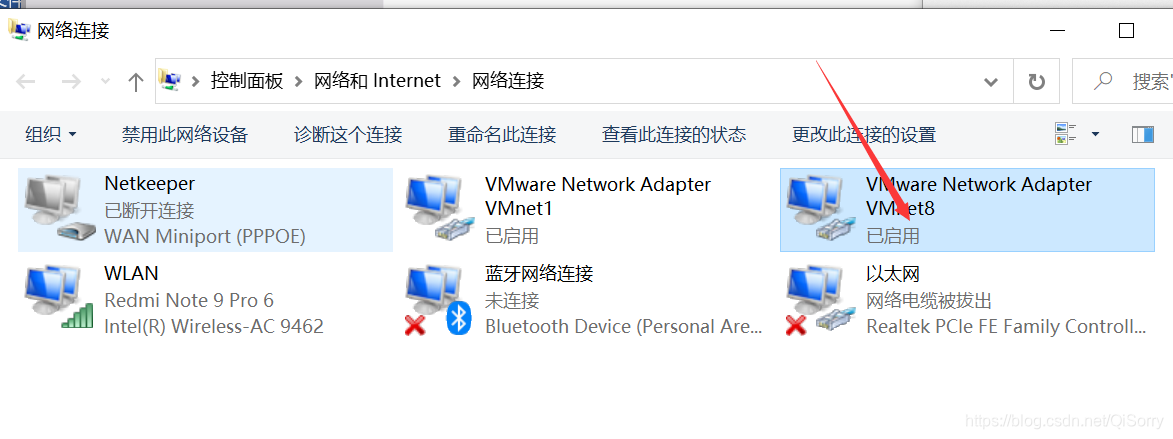
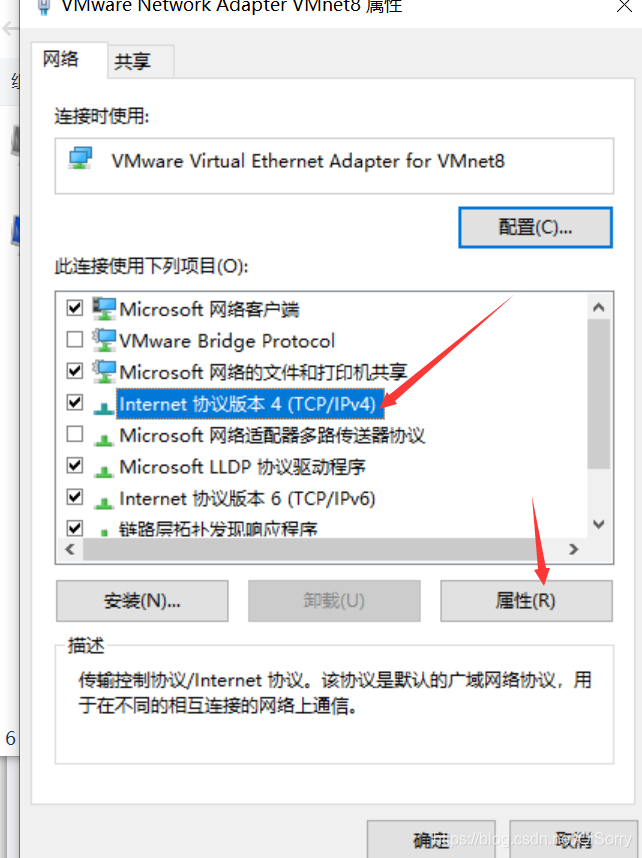
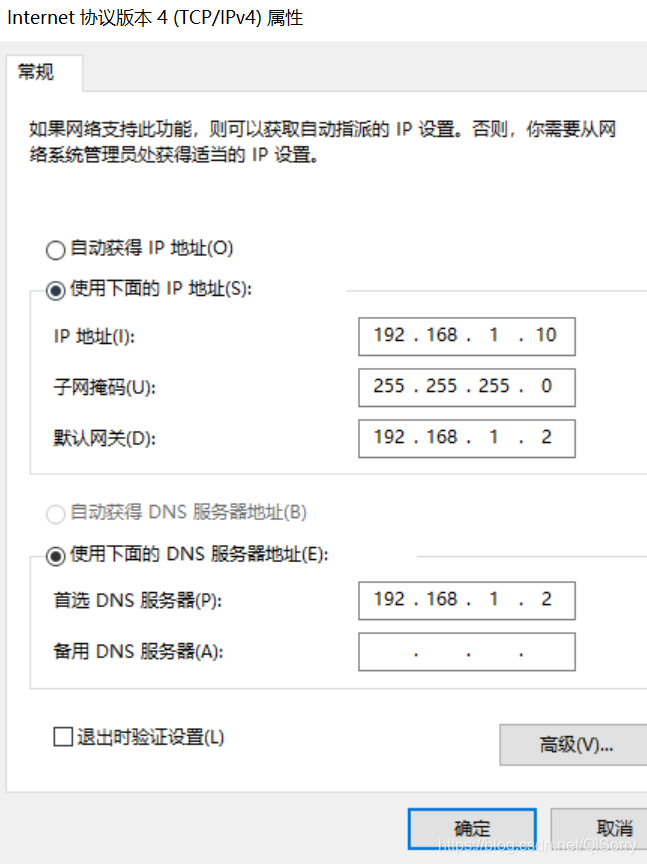

注意:可能大家最后那个文件不是 ifcfg-ens33,根据自己的情况选择,如果是centos7.5版本的话,基本都是ifcfg-ens33文件,一般打开这个文件是有内容的,如果大家打开是空的,说明不是 ifcfg-ens33文件。
修改BOOTPROTO,最后添加三行内容
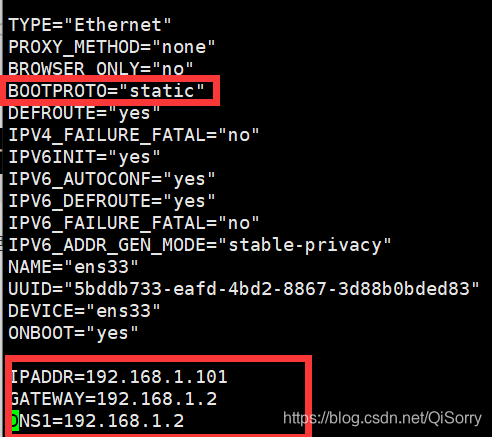
修改完后重启网络
[root@hadoop101 ~]# systemctl restart network
一、虚拟机准备
**注意:**最好切换到 root 用户执行
1 可以正常上网
[root@hadoop101 ~]# ping www.baidu.com
PING www.wshifen.com (104.193.88.77) 56(84) bytes of data.
64 bytes from 104.193.88.77 (104.193.88.77): icmp_seq=1 ttl=128 time=209 ms
64 bytes from 104.193.88.77 (104.193.88.77): icmp_seq=2 ttl=128 time=209 ms
2 查看ip相关信息
ifconfig查看ip信息
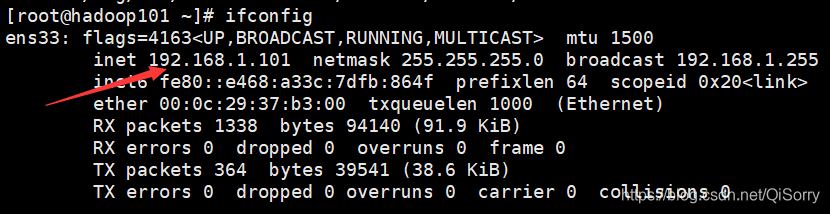
我的虚拟机的 ip地址为192.168.1.101
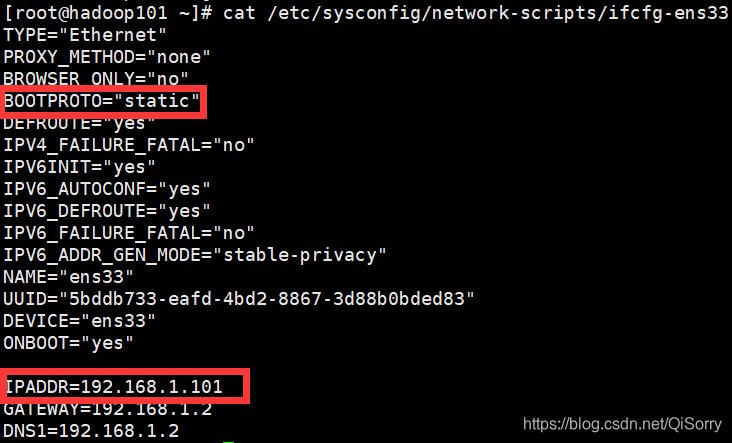
3 安装必要的环境
**注意:**最好切换到 root 用户执行
[root@hadoop101 ~]# yum install -y epel-release
[root@hadoop101 ~]# yum install -y net-tools
[root@hadoop101 ~]# yum install -y vim
4 关闭防火墙以及防火墙开机自启动
[root@hadoop101 ~]# systemctl stop firewalld
[root@hadoop101 ~]# systemctl disable firewalld
5 修改主机名及添加映射
我的主机名就是 hadoop101,主机名可以随意设定
[root@hadoop101 ~]# vim /etc/hostname
hadoop101
添加映射,我的这台虚拟机的 ip 地址为 192.168.1.101,另外两台虚拟机的 主机名和ip 地址我会分别设置为 hadoop102,192.168.1.102; hadoop103,192.168.1.103。
这里要注意:大家要根据自己的虚拟机的 ip 地址来设置,其他两台的虚拟机的最后三位不能和第一台一样,最好是叠加,如:101、102、103,这样方便记忆与配置
[root@hadoop101 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
在 win10中添加映射:打开C:WindowsSystem32driversetc路径下的 hosts 文件,在末尾加入如下内容
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
在win10中配置映射并不是必须要配置,配置这个主要是为了将 ip 地址和用户名在 win10 主机上做一个映射,不配也行,建议还是配置一下。
6 创建用户
-
我这里创建一个 bigdata 用户,大家随意,然后给用户设置密码
[root@hadoop101 ~]# useradd bigdata
[root@hadoop101 ~]# passwd bigdata -
配置 bigdata 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令,这样就可以不用切换到 root 用户来执行了
编辑 /etc/sudoers文件,添加两行内容[root@hadoop101 ~]# vim /etc/sudoers ## Allow root to run any commands anywhere root ALL=(ALL) ALL # 添加如下两行内容 %wheel ALL=(ALL) ALL bigdata ALL=(ALL) NOPASSWD:ALL -
创建 /opt/app 和 /opt/software文件夹
app:用来存放解压后的 jar 包
software:用来存放 jar 包[root@hadoop101 ~]# mkdir /opt/app [root@hadoop101 ~]# mkdir /opt/software -
修改并查看 app 和 software文件权限
[root@hadoop101 ~]# chown bigdata:bigdata /opt/app [root@hadoop102 ~]# chown bigdata:bigdata /opt/software [root@hadoop101 opt]# ll /opt/ 总用量 0 drwxr-xr-x. 2 bigdata bigdata 6 3月 1 22:50 app drwxr-xr-x. 2 bigdata bigdata 6 1月 28 21:48 software -
卸载自带的 JDK
[root@hadoop101 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps -
重启虚拟机
[root@hadoop101 ~]# reboot
7 克隆另外两台虚拟机:hadoop102 hadoop103
7.1 克隆 hadoop102
克隆时,应该关闭 hadoop101
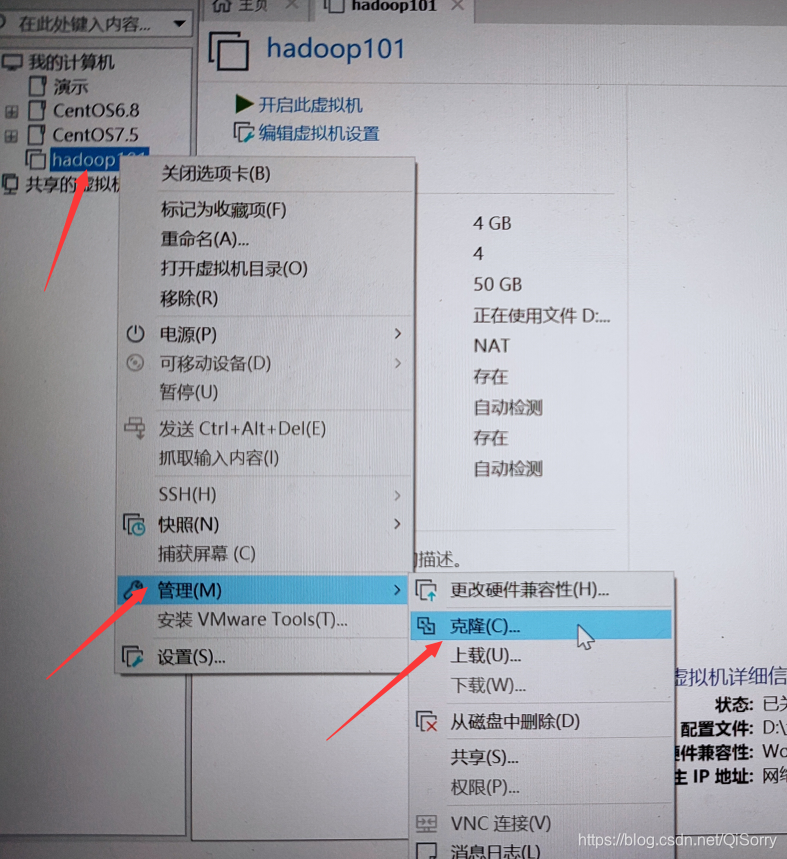
点击克隆后一直点下一步,直到下面图片
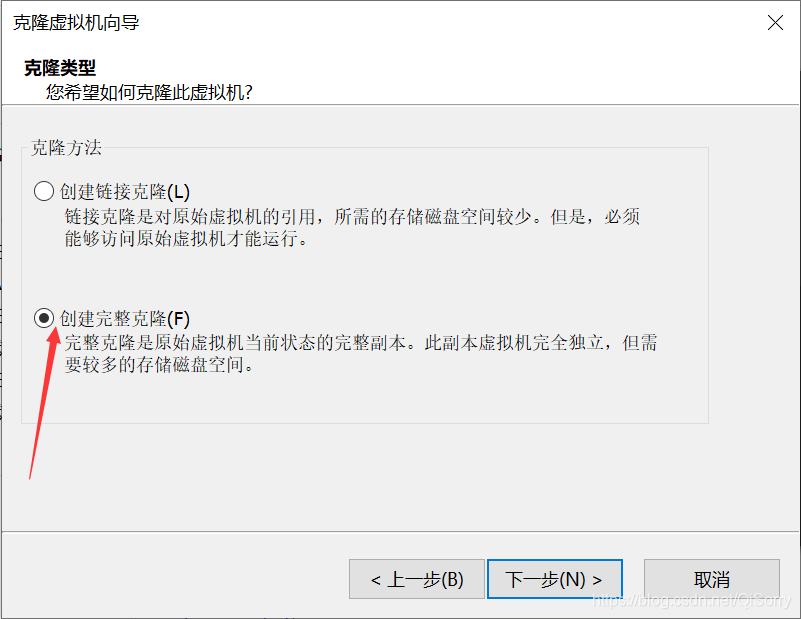
创建虚拟机名称和存放地址
克隆完成
7.2 更改 hadoop102 相关信息
-
使用 root 用户登录
-
将主机名修改为 hadoop102
[root@hadoop101 ~]# vim /etc/hostname hadoop102 -
查看一下主机映射(hadoop101已经配置过了,克隆过来也是配置好了的)
[root@hadoop101 ~]# vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.101 hadoop101 192.168.1.102 hadoop102 192.168.1.103 hadoop103 -
将 hadoop102 的ip地址修改为 192.168.1.102
[root@hadoop101 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
将 IPADDR 改为 192.168.1.102 即可
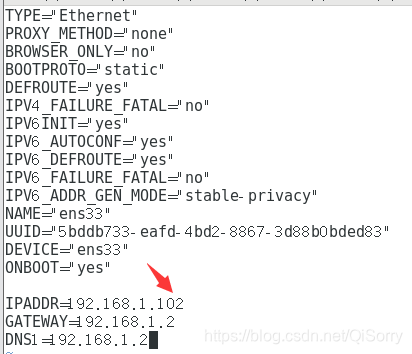
注意: 这里不要生搬硬套,因为我的 hadoop101 的ip地址为 192.168.1.101,所以我才将 hadoop102 的ip地址改为 192.168.1.102,大家根据自己第一台虚拟机的静态ip来更改
-
修改完后保存退出,reboot 重启
-
重启后可以看到用户名更改为 hadoop102,并且可以上网
Last login: Mon Mar 1 23:32:44 2021 [root@hadoop102 ~]# ping www.baidu.com PING www.a.shifen.com (220.181.38.149) 56(84) bytes of data. 64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=1 ttl=128 time=37.5 ms -
查看 ip信息
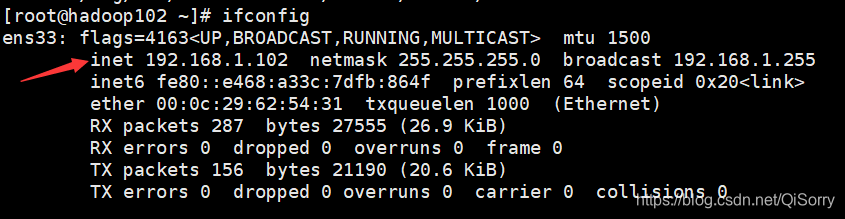
我们发现 hadoop102 的ip地址变为 192.168.1.102 -
至此,hadoop102 就克隆完毕
-
同理,第三台虚拟机 hadoop103也是如此操作
7.3 测试三台虚拟机是否可以相互通信
测试 hadoop101 与其他两台虚拟机之间能否相互通信
[bigdata@hadoop101 opt]$ ping hadoop101
PING hadoop101 (192.168.1.101) 56(84) bytes of data.
64 bytes from hadoop101 (192.168.1.101): icmp_seq=1 ttl=64 time=0.033 ms
[bigdata@hadoop101 opt]$ ping hadoop102
PING hadoop102 (192.168.1.102) 56(84) bytes of data.
64 bytes from hadoop102 (192.168.1.102): icmp_seq=1 ttl=64 time=0.522 ms
[bigdata@hadoop101 opt]$ ping hadoop103
PING hadoop103 (192.168.1.103) 56(84) bytes of data.
64 bytes from hadoop103 (192.168.1.103): icmp_seq=1 ttl=64 time=0.487 ms
我们可以看到 hadoop101 可以与其他两台虚拟机相互通信,同理测试hadoop102、hadoop103 各自能否与其他两台虚拟机相互通信。
二、Hadoop安装及相关配置
1 安装 jdk、hadoop
-
使用 Xshell 或者 SecureCRT 用**bigdata(你自己创建的用户)**登录到三台虚拟机。
-
在 hadoop101(第一台虚拟机)进入到 /opt/software 目录,将 jdk 和 hadoop jar包上传到该目录
[bigdata@hadoop101 ~]$ cd /opt/software/上传完毕后查看一下
[bigdata@hadoop101 software]$ ll 总用量 520600 -rw-r--r--. 1 bigdata bigdata 338075860 2月 24 09:00 hadoop-3.1.3.tar.gz -rw-r--r--. 1 bigdata bigdata 195013152 2月 24 09:09 jdk-8u212-linux-x64.tar.gz -
解压 jdk 和 hadoop jar包
[bigdata@hadoop101 software]$ tar -zxvf jdk-8u121-linux-x64.tar.gz -C /opt/app/ [bigdata@hadoop101 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/app/ -
到 /opt/app 目录查看解压后的 jar 包
[bigdata@hadoop101 software]$ cd /opt/app/ [bigdata@hadoop101 app]$ ll 总用量 0 drwxr-xr-x. 9 bigdata bigdata 149 9月 12 2019 hadoop-3.1.3 drwxr-xr-x. 7 bigdata bigdata 245 4月 2 2019 jdk1.8.0_212
2 配置环境变量
[bigdata@hadoop101 app]$ sudo vim /etc/profile.d/my_env.sh
分别进入 jdk 和 hadoop 安装目录并查看各自的路径
[bigdata@hadoop101 app]$ cd /opt/app/jdk1.8.0_212/
[bigdata@hadoop101 jdk1.8.0_212]$ pwd
/opt/app/jdk1.8.0_212
[bigdata@hadoop101 jdk1.8.0_212]$ cd ../hadoop-3.1.3/
[bigdata@hadoop101 hadoop-3.1.3]$ pwd
/opt/app/hadoop-3.1.3
在 /etc/profile.d/ 目录下创建一个文件,根据刚才查看到的路径编写文件,配置 JAVA_HOME 和 HADOOP_HOME
[bigdata@hadoop101 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/app/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/opt/app/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
编写完后后,保存退出,source 一下,让环境变量生效
[bigdata@hadoop101 hadoop-3.1.3]$ source /etc/profile.d/my_env.sh
验证环境变量是否生效,输入 java -version 和 hadoop version,若打印出版本信息表示环境变量已经配置完成
[bigdata@hadoop101 hadoop-3.1.3]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[bigdata@hadoop101 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/app/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
3 配置SSH无密登录
一般我们使用 ssh 登录到其他机器需要输入密码,如从 hadoop101 登录到 hadoop102 过程如下: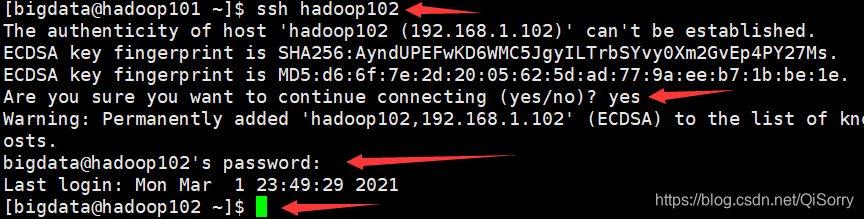
配置免密登录后,就不需要密码了,感兴趣可以看看原理,这里不解释了
这里仅需配置 hadoop101(你的第一台虚拟机)的 bigdata 用户到其他两台虚拟机的免密登录。为什么只需要配置 hadoop101呢?因为我是把 hadoop101 用户当做集群的主节点(Master),其他两台是从节点。步骤如下
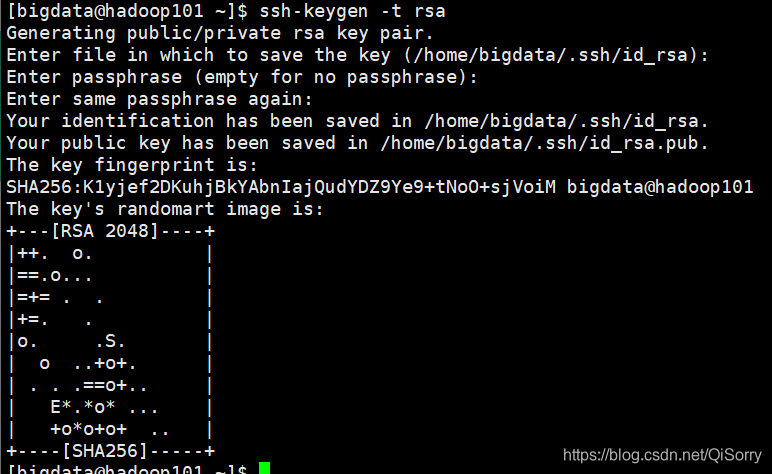
[bigdata@hadoop101 ~]$ ssh-keygen -t rsa
敲三下回车,结果如下,会生成 id_rsa(私钥)和 id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上(注意 hadoop101 也要配置到自己的免密登录)
[bigdata@hadoop101 ~]$ ssh-copy-id hadoop101
[bigdata@hadoop101 ~]$ ssh-copy-id hadoop102
[bigdata@hadoop101 ~]$ ssh-copy-id hadoop103
配置完后,我们测试一下从 hadoop101 登录到 hadoop103 上还需要密码不
[bigdata@hadoop101 ~]$ ssh hadoop103
Last login: Mon Mar 1 23:47:30 2021
[bigdata@hadoop103 ~]$
[bigdata@hadoop103 ~]$ exit
登出
Connection to hadoop103 closed.
[bigdata@hadoop101 ~]$
同理要配置hadoop102、hadoop103分别到另外两台虚拟机的免密登录
4 集群配置
4.1 集群各节点的规划
hadoop101
hadoop102
hadoop103
HDFS
NameNode
SecondaryNameNode
HDFS
DataNode
DataNode
DataNode
Yarn
ResourceManager
Yarn
NodeManager
NodeManager
NodeManager
4.1 配置集群
进入到配置文件目录,这里一定要注意要先按 i 进入编辑模式再粘贴,否则会少内容
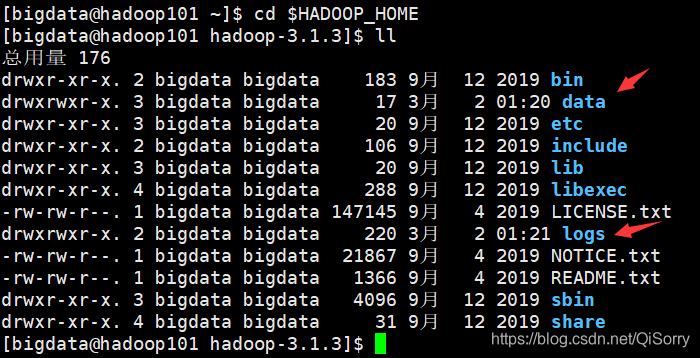
[bigdata@hadoop101 ~]$ cd $HADOOP_HOME/etc/hadoop
[bigdata@hadoop101 hadoop]$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 数据存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为bigdata -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>bigdata</value>
</property>
</configuration>
[bigdata@hadoop101 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- SecondaryNameNode web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
[bigdata@hadoop101 hadoop]$ vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR执行shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
[bigdata@hadoop101 hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置 workers 文件时的注意事项:
-
hadoop版本3.0以下的应该编辑文件 slaves
-
workers文件中不能出现空格和多余的行
[bigdata@hadoop101 hadoop]$ vim workers
hadoop101
hadoop102
hadoop103
至此 hadoop 一些基本的配置信息完成了,其实还有很多配置信息用的都是默认的,可以自己去官网查看并配置。
4.2 分发 jdk 和 hadoop 到另外两台虚拟机
分发的时候要注意:另外两台机器要有 /opt/app 文件夹,使用bigdata(你自己创建的那个用户)分发
[bigdata@hadoop101 hadoop]$ rsync -av /opt/app/ bigdata@hadoop102:/opt/app/
[bigdata@hadoop101 hadoop]$ rsync -av /opt/app/ bigdata@hadoop103:/opt/app/
分发完成后可以查看一下相应的目录中是否有 jdk 和 hadoop
[bigdata@hadoop102 ~]$ ll /opt/app/
drwxr-xr-x. 9 bigdata bigdata 149 9月 12 2019 hadoop-3.1.3
drwxr-xr-x. 7 bigdata bigdata 245 4月 2 2019 jdk1.8.0_212
[bigdata@hadoop103 ~]$ ll /opt/app/
drwxr-xr-x. 9 bigdata bigdata 149 9月 12 2019 hadoop-3.1.3
drwxr-xr-x. 7 bigdata bigdata 245 4月 2 2019 jdk1.8.0_212
最后别忘记在另外两台虚拟机上编辑环境变量(将hadoop101中/etc/profile.d/my_env.sh的内容拷贝过去即可)
[bigdata@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/app/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
#HADOOP_HOME
export HADOOP_HOME=/opt/app/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
最后别忘记 source 一下,并查看环境变量是否生效
[bigdata@hadoop102 ~]$ source /etc/profile.d/my_env.sh
[bigdata@hadoop102 ~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[bigdata@hadoop102 ~]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/app/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
另外一台机器也要拷贝一下环境变量,这里我就不做演示了
4.3 格式化NameNode
格式化注意事项!!!!!!!!!!!!!!!!
- 用你的集群中的主机点(Master)即 NameNode所在节点进行格式化,我这里是 hadoop101,大家自己对应
- 只能格式化一次!!!!!
- 如果格式化1次以上,先进入到 hadoop 安装目录,然后删除 logs 和 data文件(三台虚拟机都要删除),删除后在重新格式化。(另外一种解决办法是修改集群Cluster ID使他们保持一致,可以自己去网上参考一下,这里不再展示)
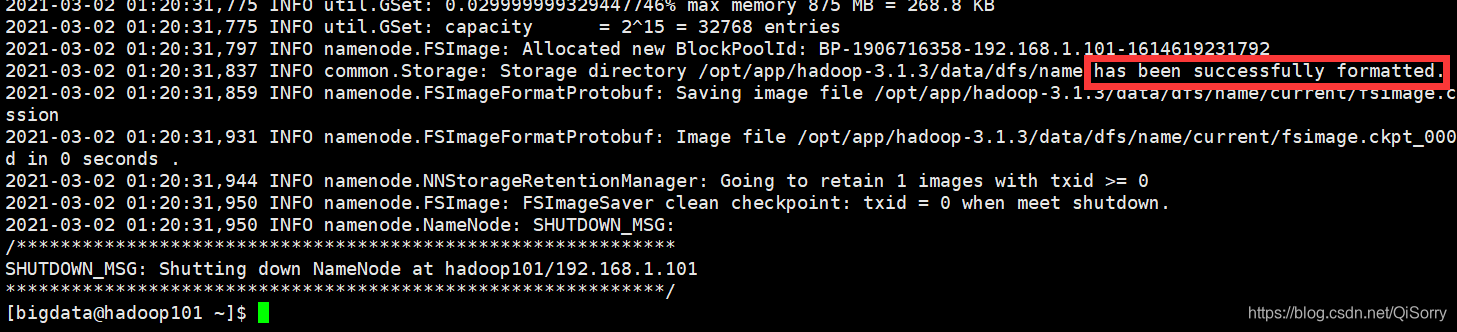
开始格式化
[bigdata@hadoop101 ~]$ hdfs namenode -format
如果看到以下信息说明格式化成功
4.4 群起集群
HDFS测试
注意:群起集群的前提条件是配置了 ssh 免密登录,否则只能一台机器一台机器的启动。
在主节点(Master),我这里是hadoop101启动 HDFS
[bigdata@hadoop101 ~]$ start-dfs.sh
Starting namenodes on [hadoop101]
Starting datanodes
hadoop102: WARNING: /opt/app/hadoop-3.1.3/logs does not exist. Creating.
hadoop103: WARNING: /opt/app/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [hadoop103]
在各个虚拟机上执行 jps 查看相应的进程
[bigdata@hadoop101 ~]$ jps
4928 DataNode
5625 Jps
4766 NameNode
[bigdata@hadoop102 ~]$ jps
4630 Jps
4359 DataNode
[bigdata@hadoop103 ~]$ jps
3665 Jps
3238 DataNode
3324 SecondaryNameNode
查看进程后发现没有问题
启动后就可以到 Web界面,输入你的主机点IP+9870端口号即可访问
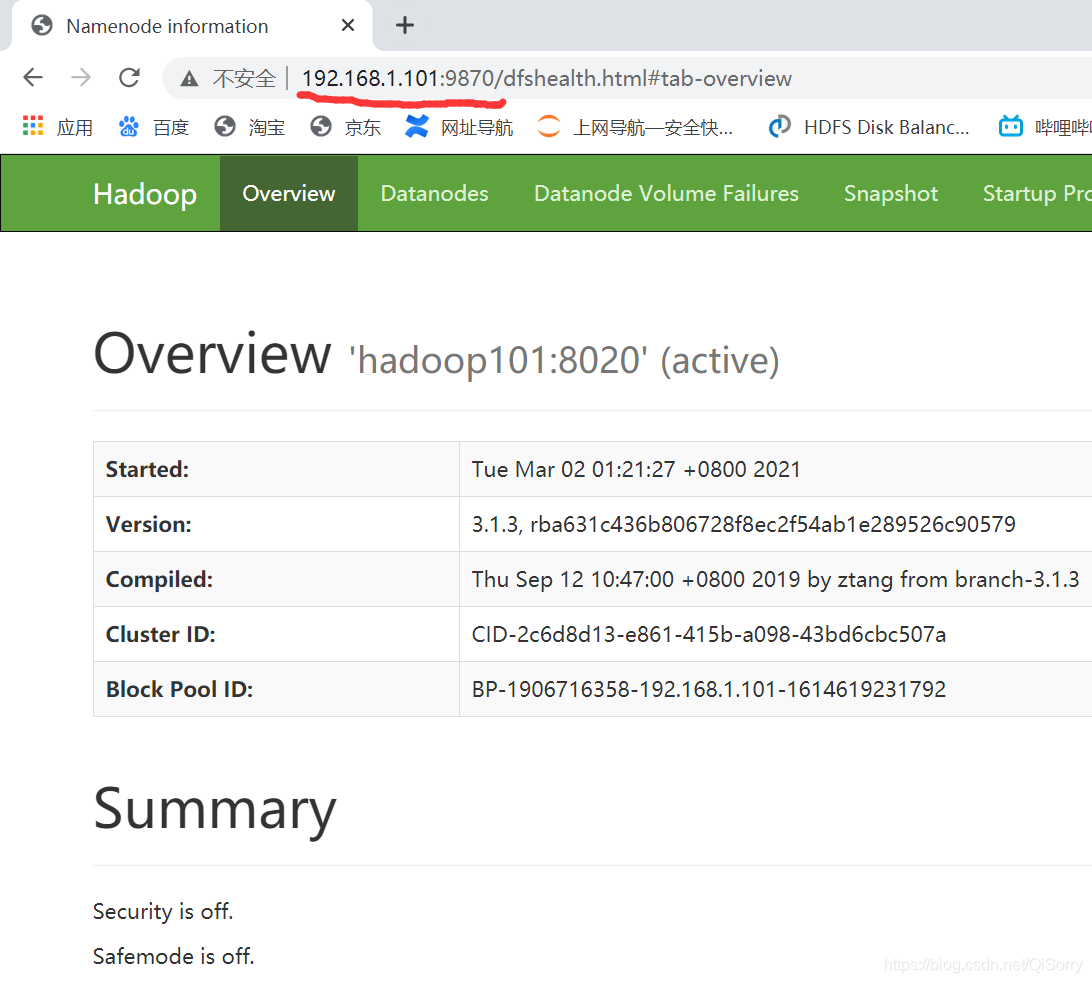
如果你在 win10 配置了主机映射,可以通过主机名访问如 hadoop101:9870
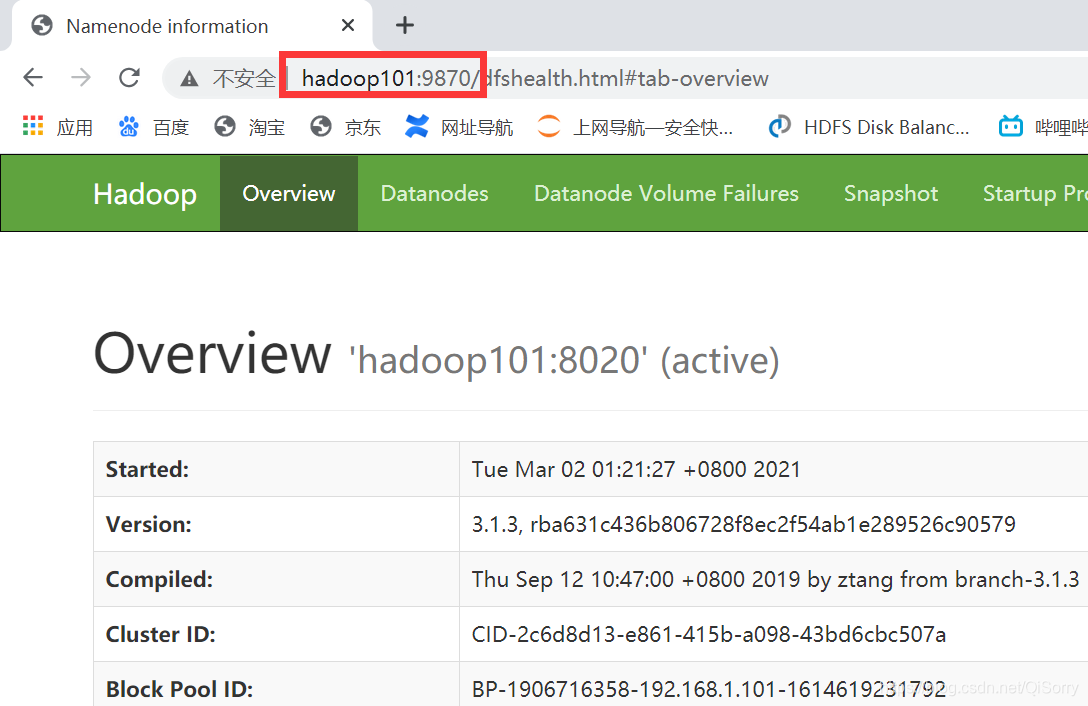
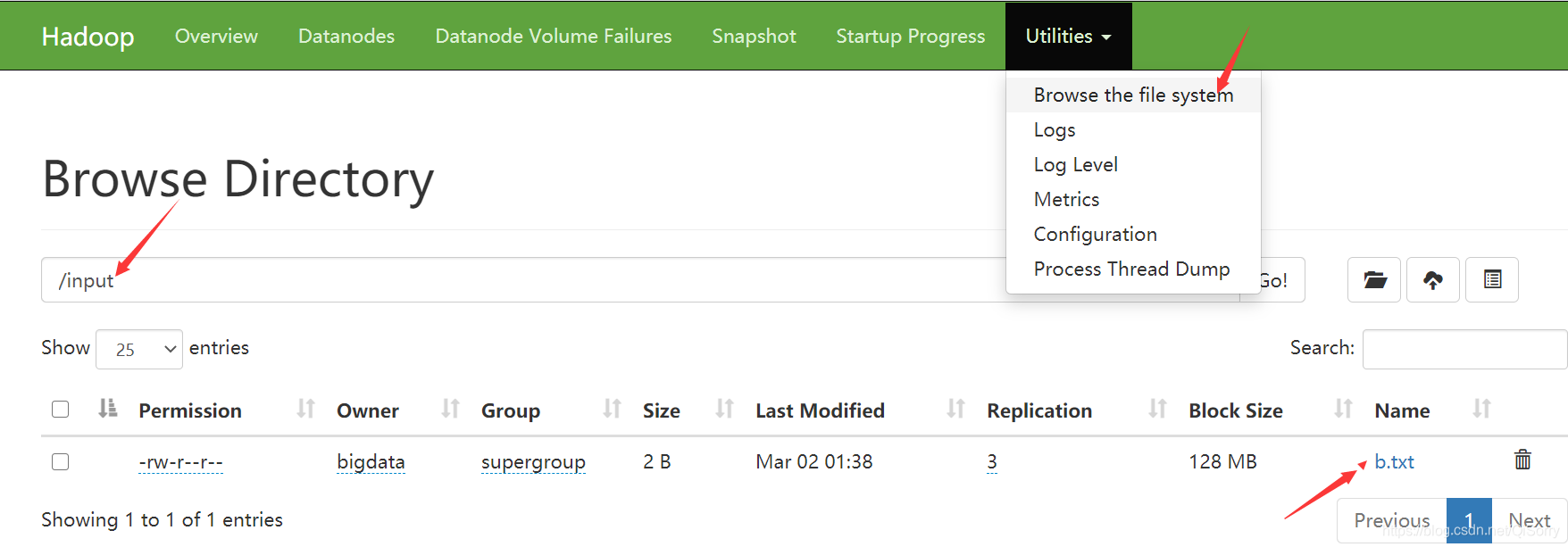
我们上传一个文件看看HDFS是否能真正的工作
[bigdata@hadoop101 hadoop-3.1.3]$ echo b >> b.txt
[bigdata@hadoop101 hadoop-3.1.3]$ hadoop fs -mkdir /input
[bigdata@hadoop101 hadoop-3.1.3]$ hadoop fs -put b.txt /input
去web界面查看一下
Yarn测试
在配置了ResourceManager的节点上(我这里是hadoop102)执行 start-yarn.sh命令
[bigdata@hadoop102 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
查看各个虚拟机的进程
[bigdata@hadoop101 ~]$ jps
4928 DataNode
6043 Jps
5884 NodeManager
4766 NameNode
[bigdata@hadoop102 ~]$ jps
4816 Jps
4707 NodeManager
4359 DataNode
5486 ResourceManager
[bigdata@hadoop103 ~]$ jps
3238 DataNode
3754 NodeManager
3324 SecondaryNameNode
3869 Jps
访问一下web界面,我这里是 192.168.1.102:8088,如果win10配置了主机映射 hadoop102:8080也可以访问。注意:因为ResourceManager配置在hadoop102,所以应该用hadoop102的ip+端口号访问,大家自己对应
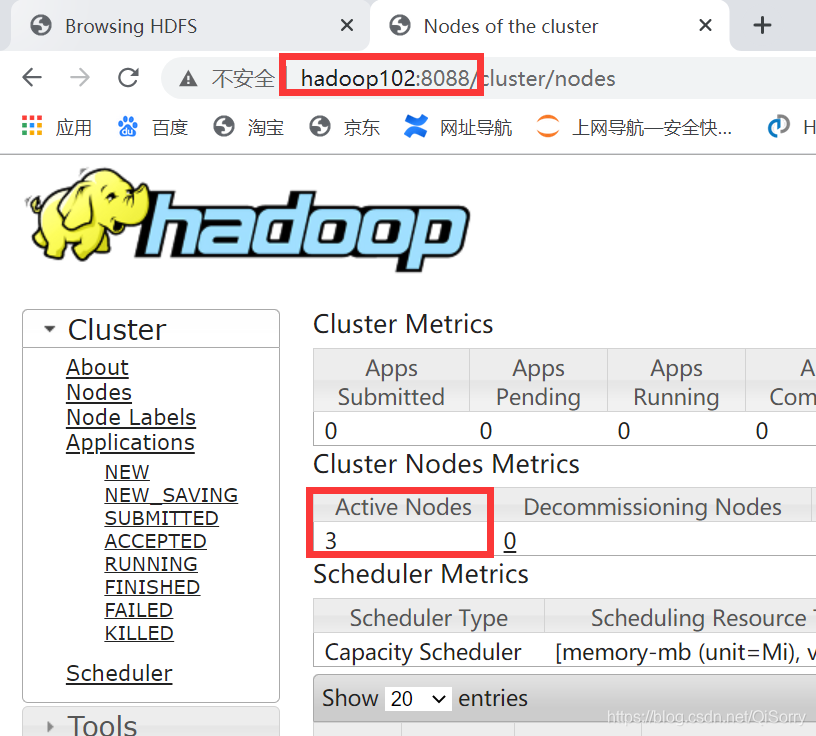
Mr on Yarn测试
在hadoop101上创建一个测试文件,放入到/input2中
[bigdata@hadoop101 ~]$ vim test.txt
a b c
b c
c
[bigdata@hadoop101 ~]$ hadoop fs -mkdir /input2
[bigdata@hadoop101 ~]$ hadoop fs -put test.txt /input2
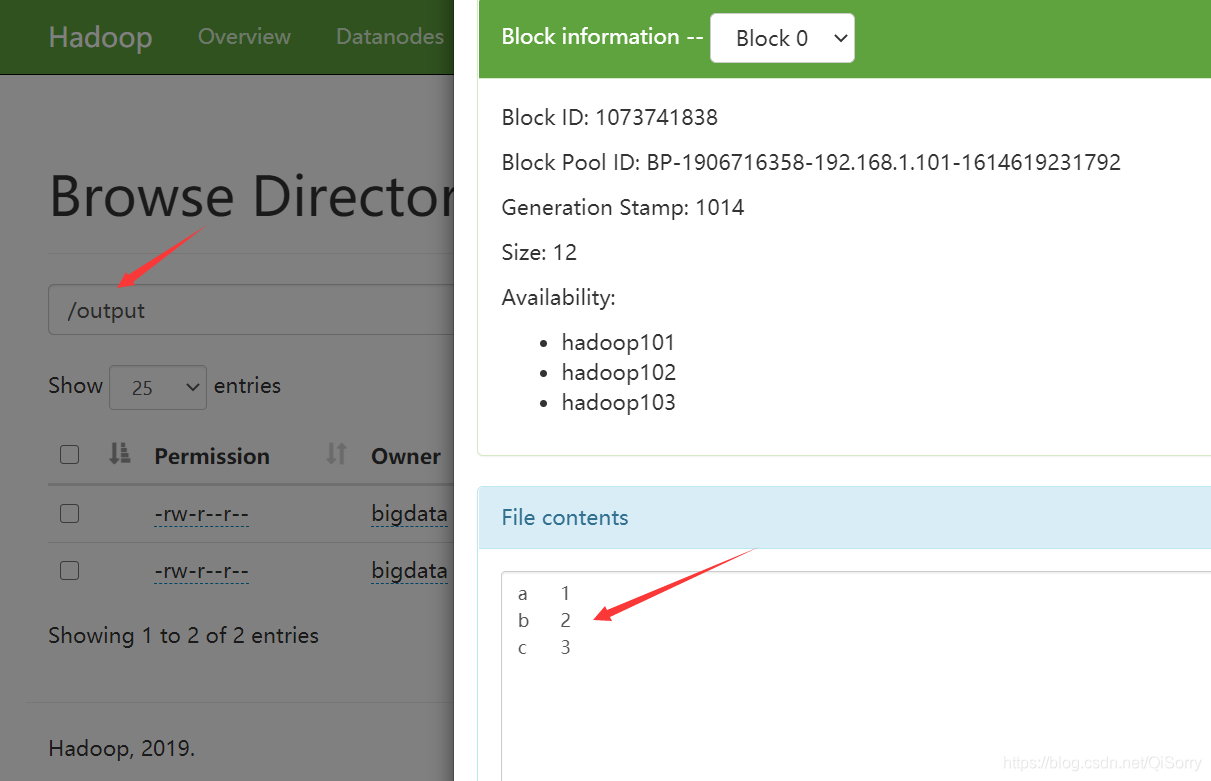
跑一个wordcount程序测试一下,该程序负责统计 /input2中各个文件的单词数,结果输入到/output中,注意:/output目录不能存在,否则报错
[bigdata@hadoop101 ~]$ hadoop jar /opt/app/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input2 /output
可以看到任务完成了

去HDFS web界面查看一下结果
进入 /output 目录,查看一下结果文件
总结
本文先从虚拟机的准备开始,然后讲了 Hadoop 的基本安装过程。遇到错误是很正常的,需要自己查看报错信息,并解决,希望大家都能踩过这个坑。内容方面如若有误,请大家多多指正,相互学习,相互进步!
















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









