







一、环境配置需求
服务器数量:需要3台服务器节点,一台NameNode节点,两台DataNode节点,另外还需要一个SecondaryNameNode,可放在DataNode节点里
服务器作用:
1)NameNode:保存数据的存储位置,不保存数据。
完全基于内存存储和管理文件元数据、目录结构、文件block映射,提供了副本放置策略,与SecondaryNameNode配合实现持久化方案保证数据可靠性
2)DataNode:保存数据。
基于本地磁盘存储block(文件形式),并保存block的校验和数据保证block的可靠性,与NameNode保持心跳,汇报block列表状态
3)SecondaryNameNode:周期性实现NameNode镜像和日志的合并。
日志保存的信息比较完全但恢复启动慢,镜像的恢复启动比较快但更新速度有限,所以要周期性地将日志的信息更新到镜像中,然后删除日志,最后使用镜像+日志进行NameNode的启动。SecondaryNameNode可以周期完成对Namenode的EditLog向FsImage合并,减少EditLog大小,减少Namenode启动时间
备份原理:
- NameNode格式化会生成一个空的FsImage,用来存储内存所有的元数据状态
- 任何对文件系统元数据产生修改的操作,都会使用EditLog事务日志记录下来,然后写FsNameSystem内存
- SecondaryNameNode周期性下载EditLog,同时把FsImage下载下来,完成对EditLog向FsImage合并形成新的FsImage,然后替换旧的FsImage,删除旧的EditLog,减少EditLog大小
- 使用本地磁盘保存EditLog和FsImage,Namenode启动时,它从硬盘中读取EditLog和FsImage
二、hadoop完全分布式搭建
1.基础环境配置(3个节点都需配置)
#临时关掉NetworkManager
systemctl stop NetworkManager
#永久关掉NetworkManager
systemctl disable NetworkManager
#关闭防火墙
systemctl disable --now firewalld
setenforce 0
#关闭dnsmasq
systemctl disable --now dnsmasq
#开启service服务
systemctl start network.service
service network restart
2.网卡配置
三个节点分别命名分别为master01,node01,node02,并配置对应ip,启动对应的节点服务
master01:192.168.132.101(NameNode)
node01:192.168.132.102(SecondaryNameNode,DataNode)
node02:192.168.132.103(DataNode)
1)配置服务器名(3个节点的HOSTNAME分别设置为master01,node01,node02):/etc/sysconfig/network
#NETWORKING表示系统是否使用网络ipv4
NETWORKING=yes
HOSTNAME=master01
2)网卡ip配置(3个节点的IPADDR分别配置为192.168.132.101,192.168.132.102,192.168.132.103):/etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.132.101
NETMASK=255.255.255.0
GATEWAY=192.168.132.2
DNS1=8.8.8.8
3)DNS配置(3个节点相同配置): /etc/resolv.conf
nameserver 8.8.8.8
4)重启网卡(3个节点都需重启网卡)
systemctl restart network
3.新建用户并添加sudo权限(3台节点分别建master01,node01,node02用户)
1)添加用户:useradd 用户名
master01节点添加master01用户
node01节点添加node01用户
node02节点添加node02用户
useradd master01
2)修改密码:passwd 用户名
master01节点修改master01用户密码
node01节点修改node01用户密码
node02节点修改node02用户密码
passwd master01
3)修改sudoers文件,给用户sudo权限
master01节点在sudoers下添加一行:master01 ALL=(ALL) ALL
node01节点在sudoers下添加一行:node01 ALL=(ALL) ALL
node02节点在sudoers下添加一行:node02 ALL=(ALL) ALL
#修改sudoers权限
chmod 777 /etc/sudoers
#修改sudoers文件
vi /etc/sudoers
#在文件/etc/sudoers的root ALL=(ALL) ALL下添加一行
master01 ALL=(ALL) ALL
#将sudoers文件权限改回来
chmod 440 /etc/sudoers
4)修改hosts文件(3个节点都需修改)
#修改hosts文件
vi /etc/hosts
#在/etc/hosts下添加
192.168.132.101 master01
192.168.132.102 node01
192.168.132.103 node02
5)修改hostname文件(3个节点都需修改为对应服务器名)
#修改/etc/hostname文件
vi /etc/hostname
#将/etc/hostname的文本修改为对应服务器名(master01,node01,node02)
master01
4.时间修改,避免节点心跳时间对不上导致出错(3个节点都需配置)
#修改时区
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
#修改时间
#查看硬件的时间
hwclock --show
#设置硬件时间,正常修改时区就够了,如有需要,可以定一个固定的时间
hwclock --set --date '2024-02-...'
#设置系统时间和硬件时间同步
hwclock --hctosys
#保存时钟
clock -w
5.安装jdk环境(3个节点都需配置)
下载地址:https://www.oracle.com/downloads/graalvm-downloads.html
jdk8下载地址:https://www.oracle.com/java/technologies/downloads/#java8
#解压
tar -zxvf jdk-8u401-linux-x64.tar.gz
#新建放jdk的文件夹
mkdir -p /usr/java
mv jdk1.8.0_401 /usr/java/jdk
#编辑/etc/profile文件
vi /etc/profile
#添加环境变量
export JAVA_HOME=/usr/java/jdk
export PATH=$JAVA_HOME/bin:$PATH
#刷新环境变量
source /etc/profile
#验证
java -version
6.安装hadoop(3个节点都需配置)
下载地址:https://dlcdn.apache.org/hadoop/common
#解压
tar -zxvf hadoop-3.3.6.tar.gz
#移动hadoop到对应的文件夹
mv hadoop-3.3.6 /usr/hadoop
#编辑/etc/profile文件
vi /etc/profile
#添加环境变量
export HADOOP_HOME=/usr/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#刷新环境变量
source /etc/profile
#验证
hdfs version
7.ssh免密(3个节点都需配置,NameNode和SecondaryNameNode需要能免密到所有节点)
1)安装ssh
#安装ssh
yum install ssh
2)生成RSA密钥和公钥
需要先进入对应用户再生成密钥和公钥
master01节点进入master01用户
node01节点进入node01用户
node02节点进入node02用户
su master01
生成密钥和公钥
#生成RSA密钥和公钥,-t表示type
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3)在~/.ssh文件夹下新增config,配置需要ssh的服务器信息
#编辑~/.ssh/config
vi ~/.ssh/config
在~/.ssh/config文件下添加ssh的服务器信息
Host master01
HostName 192.168.132.101
User master01
IdentitiesOnly yes
Host node01
HostName 192.168.132.102
User node01
IdentitiesOnly yes
Host node02
HostName 192.168.132.103
User node02
IdentitiesOnly yes
修改下config的权限
chmod 600 ~/.ssh/config
4)将公钥发送到对应服务器,实现对对应服务器的免密登录
#将公钥发给自己
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#在master01上执行,将master01的公钥发给所有node节点,让master01能直接免密登录到其他node节点
ssh-copy-id node01
ssh-copy-id node02
#在node01上执行,作为SecondaryNameNode节点也需要连其他节点
ssh-copy-id master01
ssh-copy-id node02
#修改下authorized_keys的权限,否则会无法免密登录
chmod 600 ~/.ssh/authorized_keys
5)master01上验证免密登录
#验证是否免密成功localhost
ssh localhost
#退出免密的localhost(上一步只是验证,验证后退出下)
exit
#验证是否免密成功node01
ssh node01
#退出免密的node01
exit
#验证是否免密成功node02
ssh node02
#退出免密的node02
exit
8.hadoop配置hdfs(3个节点可以用同一份配置)
1)修改hadoop-env.sh文件,添加启动的java路径,分布式部署后,每个地方的java路径不一定相同
#编辑hadoop-env.sh文件
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
#取消对应注释并修改为对应java路径
export JAVA_HOME=/usr/java/jdk
2)修改core-site.xml文件,添加启动的namenode节点和对应端口
#编辑core-site.xml文件
vi $HADOOP_HOME/etc/hadoop/core-site.xml
#修改并添加namenode启动ip为localhost,端口为9000
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master01:9000</value>
</property>
<property>
<!--指定数据默认存储地址-->
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
</configuration>
3)编辑workers,指定从哪些节点里启动DataNode(2.x版本是编辑slaves)
#编辑workers文件
vi $HADOOP_HOME/etc/hadoop/workers
#在workers文件里修改并添加DataNode启动节点(把里面默认的localhost去掉)
node01
node02
4)修改hdfs-site.xml文件,添加副本数量、hdfs的web访问地址、SecondaryNameNode的web访问地址等配置
#编辑hdfs-site.xml文件
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
#设置namenode,datanode文件存储地址,web地址,secondarynamenode镜像地址
<configuration>
<property>
<!--指定namenode文件存储地址-->
<name>dfs.namenode.name.dir</name>
<value>/bigdata/hadoop/hdfs_name</value>
</property>
<property>
<!--指定datanode文件存储地址-->
<name>dfs.datanode.data.dir</name>
<value>/bigdata/hadoop/hdfs_data</value>
</property>
<property>
<!--指定hdfs web 端访问地址-->
<name>dfs.http.address</name>
<value>master01:50070</value>
</property>
<property>
<!--指定SecondaryNameNode web 端访问地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50070</value>
</property>
<property>
<!--指定secondarynamenode存放临时镜像的目录-->
<name>dfs.namenode.checkpoint.dir</name>
<value>/bigdata/hadoop/hdfs_secondary</value>
</property>
<property>
<!--设置副本数-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!-- 修改datanode通讯端口 -->
<name>dfs.datanode.address</name>
<value>0.0.0.0:8088</value>
</property>
<property>
<!--是否允许在namenode和datanode中启用WebHDFS (REST API)-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
9.格式化namenode并启动hdfs(只需namenode节点进行格式化就行)
1)修改hadoop文件权限
master01上执行
chown -R master01 /usr/hadoop
chmod -R 760 /usr/hadoop
node01上执行
chown -R node01 /usr/hadoop
chmod -R 760 /usr/hadoop
node02上执行
chown -R node02 /usr/hadoop
chmod -R 760 /usr/hadoop
2)创建数据存储文件夹(3个节点都需创建)
mkdir -p /bigdata/hadoop
3)修改数据存储文件夹权限
master01上执行
chown -R master01 /bigdata/hadoop
chmod -R 760 /bigdata/hadoop
node01上执行
chown -R node01 /bigdata/hadoop
chmod -R 760 /bigdata/hadoop
node02上执行
chown -R node02 /bigdata/hadoop
chmod -R 760 /bigdata/hadoop
4)master01节点切换到对应用户准备启动
su master01
5)格式化namenode(master01节点执行就行)
hdfs namenode -format
6)启动hdfs
start-dfs.sh
7)查询是否启动(对应节点需要切换到对应用户再执行jps)
master01上有:NameNode
node01上有:SecondaryNameNode和DataNode
node02上有:DataNode
master01上执行
#切换用户
su master01
#查询启动的节点服务
jps
node01上执行
#切换用户
su node01
#查询启动的节点服务
jps
node02上执行
#切换用户
su node02
#查询启动的节点服务
jps
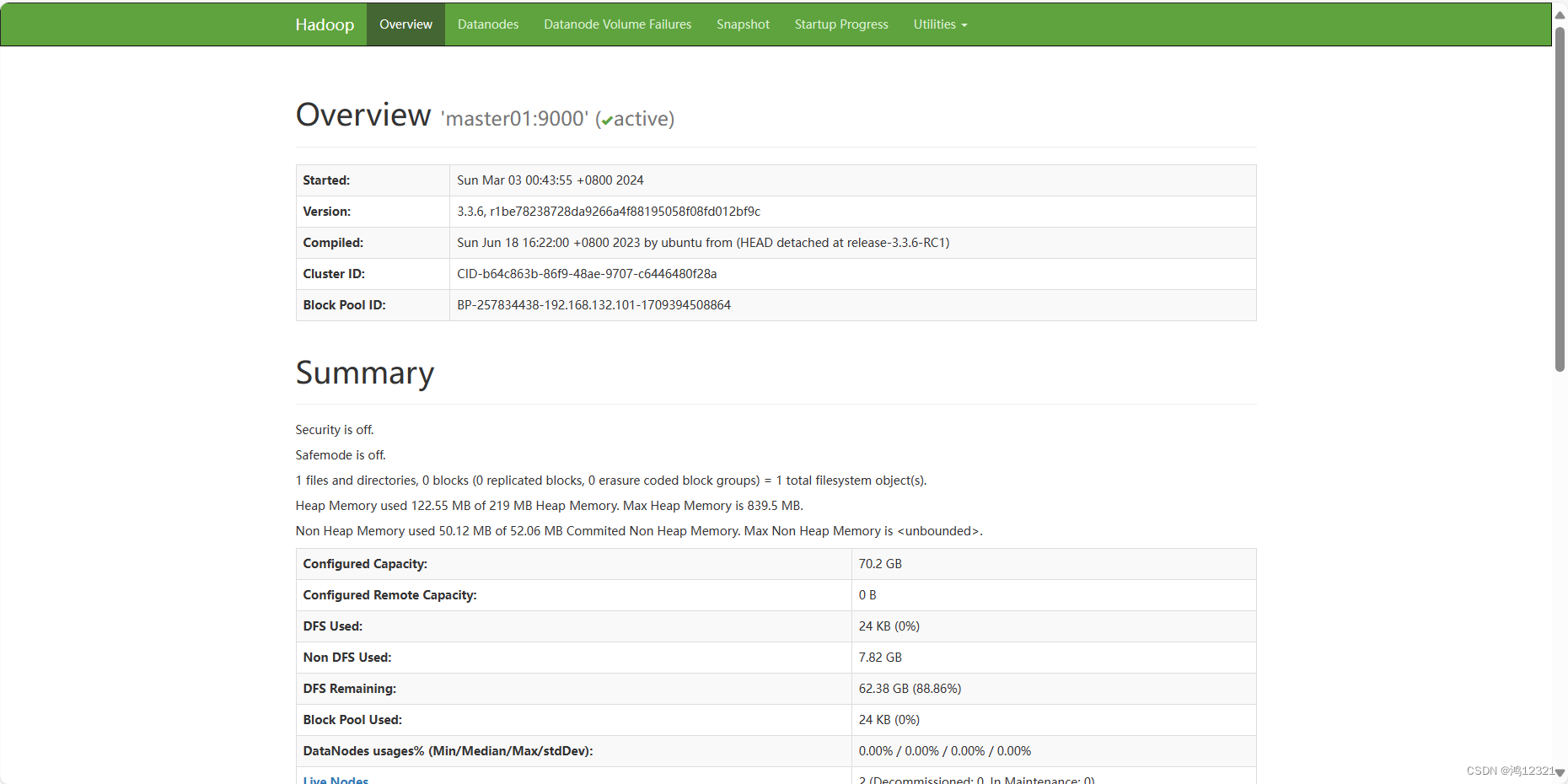
6)可以通过http://192.168.132.101:50070查看hdfs管理页面,ip是对应服务器的ip
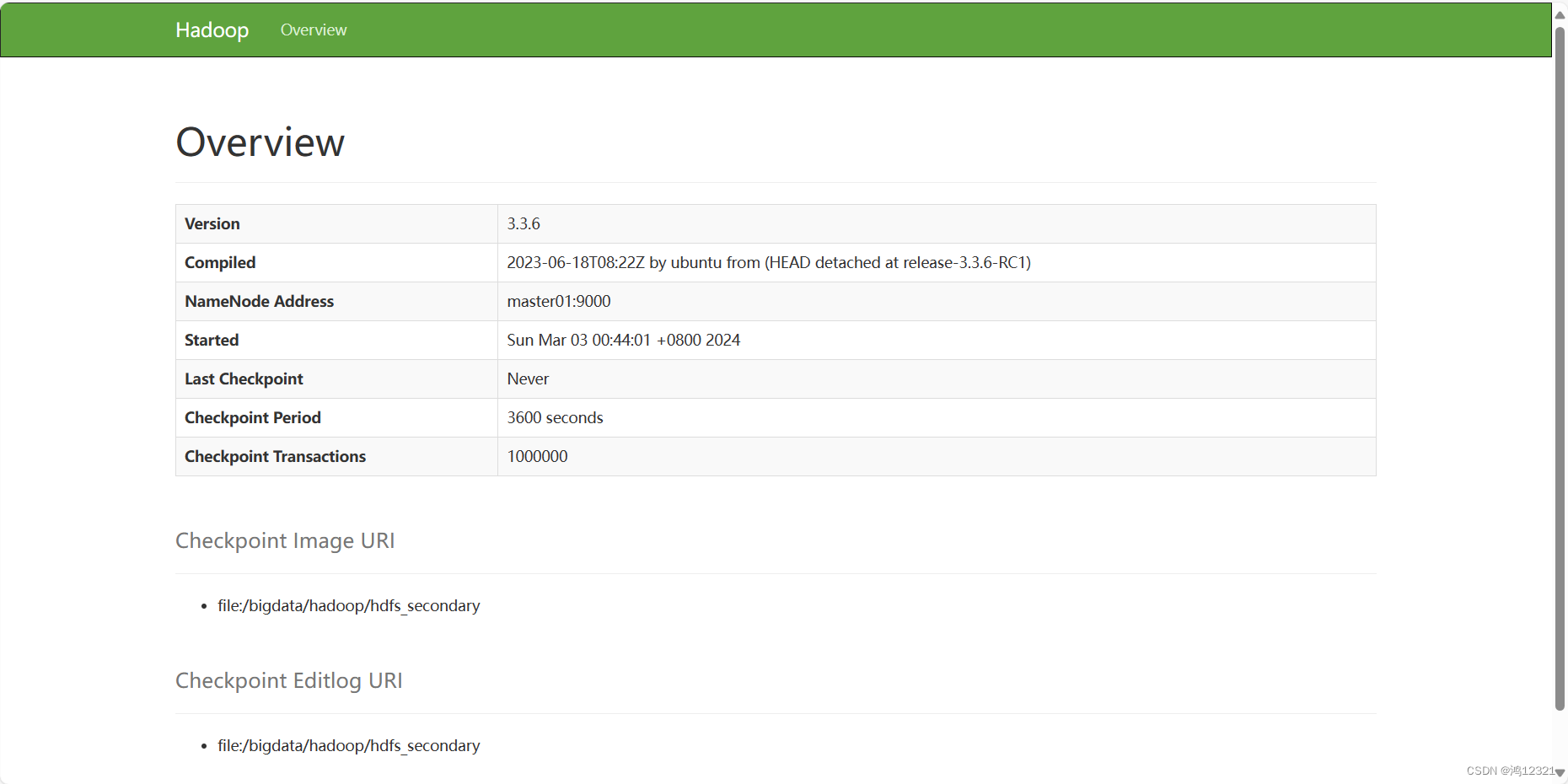
7)可以通过http://192.168.132.102:50070查看SecondaryNameNode管理页面,ip是对应服务器的ip
10.MapReduce的Yarn原理
MapReduce主要用于分布式计算,分为ResourceManager和NodeManager。
ResourceManager:主要用于资源管理。
NodeManager:每个DataNode节点上都会有NodeManager,会定时向ResourceManager汇报自身DataNode的资源情况。
执行原理:
1)用户向yarn的ResourceManager提交应用
2)ResourceManager通知一台不忙的NodeManager启动一个Container,在里面启动一个AppMaster。
3)AppMaster启动后从hdfs下载对应的切片清单,然后向ResourceManager请求获取切片清单对应的资源
4)ResourceManager收到AppMaster的请求后,会根据自己掌握的资源情况找到对应合适的NodeManager分配一个Container并反向注册到AppMaster
5)AppMaster将任务Task发送给Container
6)Container会反射相应的Task类为对象,调用方法执行
11.hadoop配置MapReduce(3个节点可以用同一份配置)
1)修改mapred-site.xml
#编辑mapred-site.xml
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
#设置MapReduce作业的运行时框架
<configuration>
<property>
<!--指定执行MapReduce作业的运行时框架,可以是local,classic,yarn,默认为local-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2)修改yarn-site.xml
#编辑yarn-site.xml
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
#设置MapReduce通过shuffle进行分发,管理resourcemanager的地址等配置
<configuration>
<property>
<!-- 设置从map到reduce通过shuffle进行分发 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 指定混洗技术对应的字节码文件 -->
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--指定resourcemanager应用程序管理器接口的地址-->
<name>yarn.resourcemanager.address</name>
<value>master01:8032</value>
</property>
<property>
<!-- 用于指定调度程序接口的地址 -->
<name>yarn.resourcemanager.scheduler.address</name>
<value>master01:8030</value>
</property>
<property>
<!-- 用于指定resourcemanager下的resource-tracker地址 -->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master01:8031</value>
</property>
<property>
<!-- 用于指定resourcemanager的管理地址 -->
<name>yarn.resourcemanager.admin.address</name>
<value>master01:8033</value>
</property>
<property>
<!-- 用于指定resourcemanager的web访问地址 -->
<name>yarn.resourcemanager.webapp.address</name>
<value>master01:8088</value>
</property>
</configuration>
3)编辑workers,指定从哪些节点里启动DataNode的同时指定了NodeManager从哪些节点启动
12.启动并验证MapReduce
1)启动
start-yarn.sh
2)查询是否启动(对应节点需要切换到对应用户再执行jps)
master01上有:NameNode、ResourceManager
node01上有:SecondaryNameNode、DataNode和NodeManager
node02上有:DataNode、NodeManager
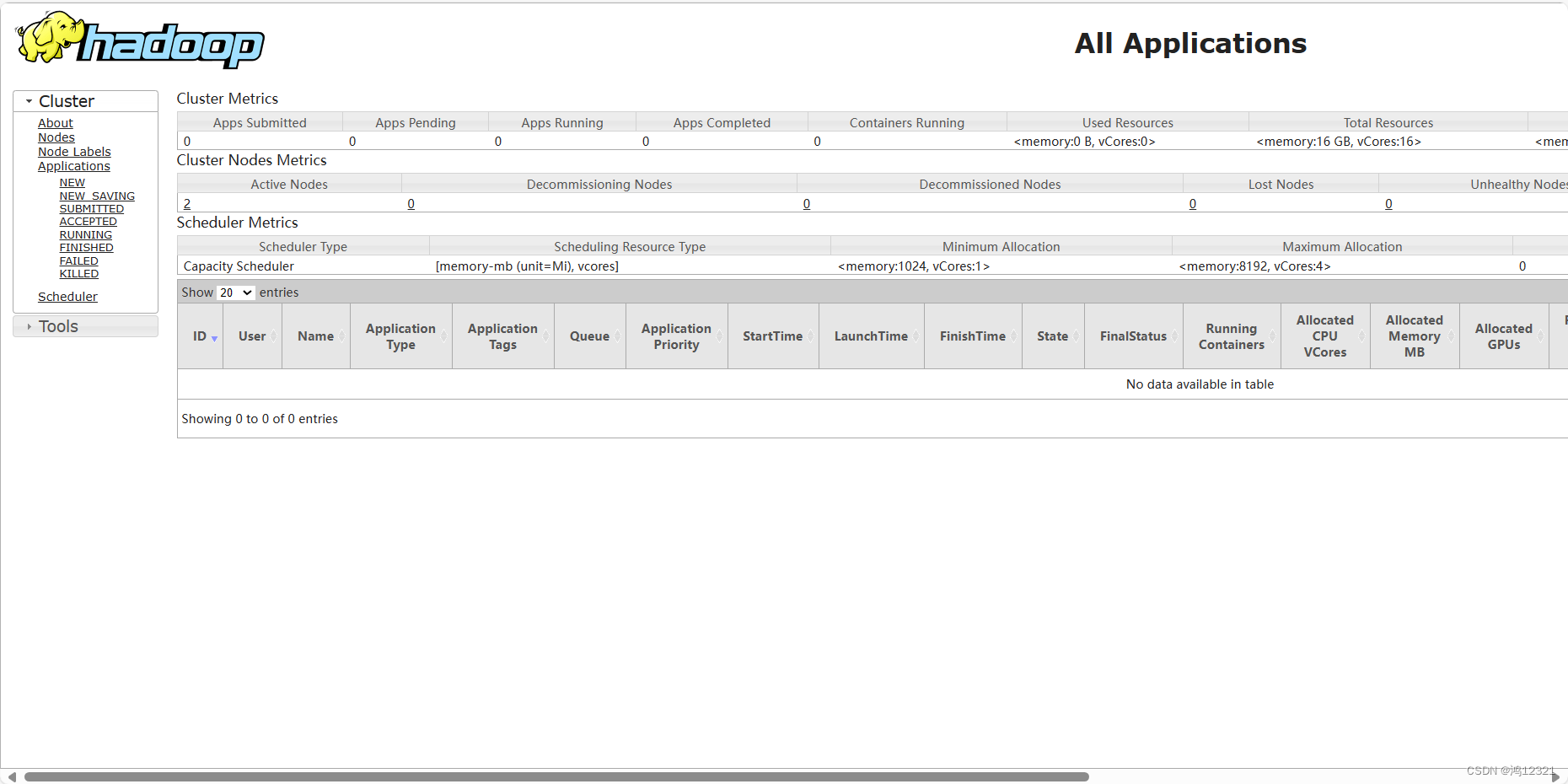
3)可以通过http://192.168.132.101:8088查看resourcemanager的管理页面















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









