







目录
前言:
线性回归模型属于经典的统计学模型,该模型的应用场景是根据已知的变量(即自变量)来预测某个连续的数值变量(即因变量)。例如餐厅根据媒体的营业数据(包括菜谱价格、就餐人数、预订人数、特价菜折扣等)预测就餐规模或营业额;网站根据访问的历史数据(包括新用户的注册量、老用户的活跃度、网站内容的更新频率等)预测用户的支付转化率;医院根据患者的病历数据(如体检指标、药物复用情况、平时的饮食习惯等)预测某种疾病发生的概率。
由于针对具体操作相关文档太多,所以本文内容涉及具体操作较少,主要是讲方法。
本文内所用到的包:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import scipy.stats as stats
import statsmodels.api as sm
from scipy.stats import chi2_contingency
1.简单线性回归模型
- 也被称为一元线性回归模型,是指模型中只含有一个自变量和一个因变量
- 一般可以通过散点图刻画两个变量之间的关系,并基于散点图绘制简单线性拟合线,进而使变量之间的关系体现地更加直观
以经典的刹车距离为例:
ccpp=pd.read_csv('cars.csv')
sns.set(font=getChineseFont(8).get_name())
sns.lmplot(x='speed',y='dist',data=ccpp,
legend_out=False,#将图例呈现在图框内
truncate=True#根据实际的数据范围,对拟合线做截断操作
)
plt.show()
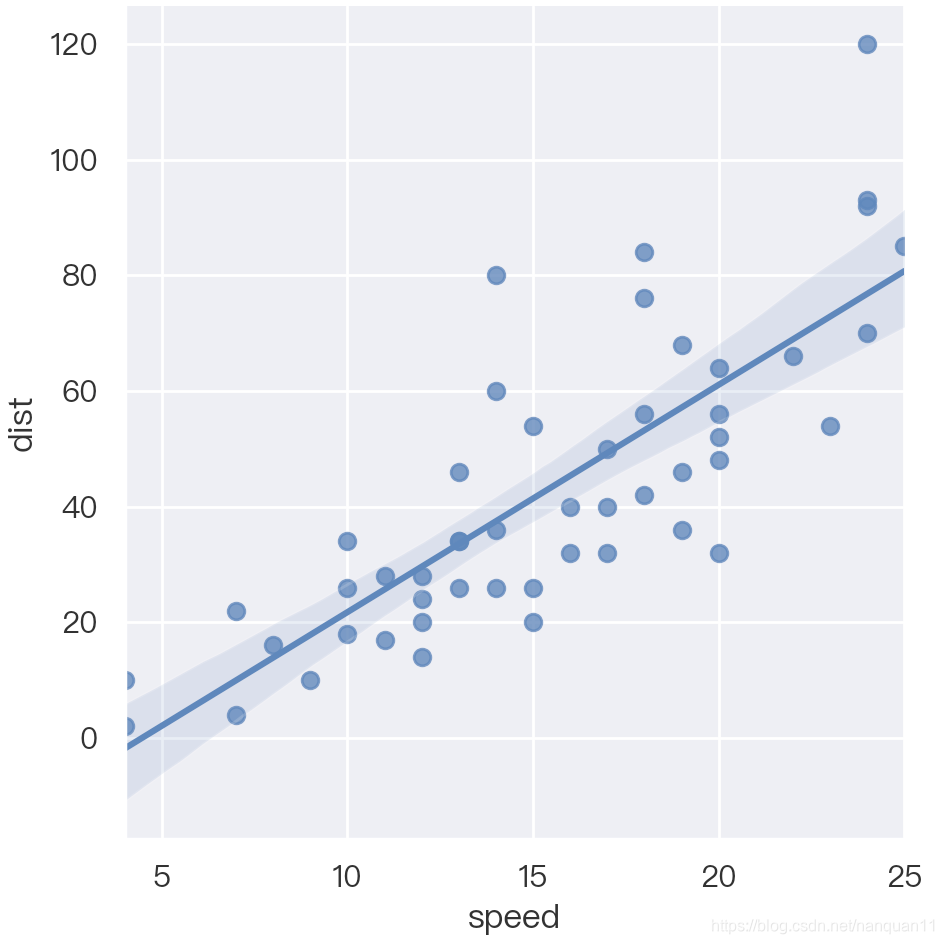 从散点图来看,自变量speed与因变量dist之间存在明显的正相关,即刹车速度越大,刹车距离越长。图内的阴影部分为拟合线95%的置信区间,每个散点都是尽可能地围绕在拟合线附近。
从散点图来看,自变量speed与因变量dist之间存在明显的正相关,即刹车速度越大,刹车距离越长。图内的阴影部分为拟合线95%的置信区间,每个散点都是尽可能地围绕在拟合线附近。
通过ols函数求得回归模型的参数解’y~s’表示简单线性回归模型
fit=sm.formula.ols('dist~speed',data=ccpp).fit()
print(fit.params)#Intercept:-17.579095,speed:3.932409
因此,关于刹车距离的简单线性模型为:
dist=-17.579095+3.932409speed
也就是说,刹车速度每提升一个单位,将促使刹车距离增加3.93个单位。
2.多元线性回归模型
- 实际应用中,简单线性回归模型并不多见,因为影响因变量的自变量往往不止一个
- 用于构建多元线性回归模型的数据实际上由两部分组成:一个是一维的因变量y;另一个是二维矩阵的自变量x
以利润表Profit为例,研究影响利润的因素
表结构如下:
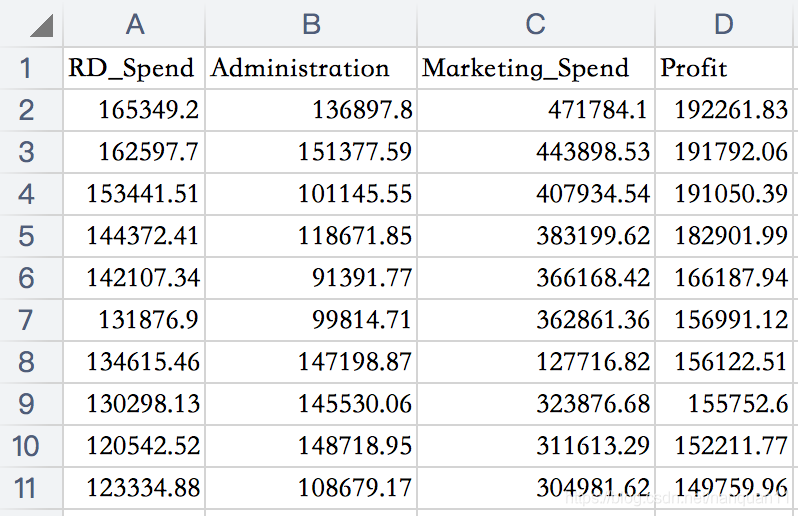
profit=pd.read_csv(‘Profit.csv’,sep=“,”)
fit=sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend',data=profit).fit()
print(fit.params)#Intercept:50122.192990,RD_Spend:0.805715,Administration:-0.026816,Marketing_Spend:0.027228
不考虑模型的显著性和回归系数的显著性,得到的回归模型可以表示为:
P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3112
3112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









