







一、马尔科夫决策:
- 以数学的形式来描述智能体在与环境交互的过程中学到一个目标的过程。这里智能体充当的是作出决策或动作,并且在交互过程中学习的角色,环境指的是智能体与之交互的一切外在事物,不包括智能体本身。(智能体理解为研究对象就可以)
- ps:有时智能体和环境的角色是能相互对调的,只要能各自建模成马尔可夫决策过程即可
-
智能体(agent):MDP中进行机器学习的代理,可以感知外界环境的状态进行决策、对环境做出动作并通过环境的反馈调整决策。
-
环境(environment):MDP模型中智能体外部所有事物的集合,其状态会受智能体动作的影响而改变,且上述改变可以完全或部分地被智能体感知。环境在每次决策后可能会反馈给智能体相应的奖励。
- 智能体与环境交互过程

奖励分为:正向,反向
举个例子:研究小明写作业这个过程。小明就是智能体,动作可以有认真写,乱写,不写。环境就可以是老师批作业,那么奖励就会有:(+)奖励小红花,表扬。(-) 叫家长,作业给撕喽(0)老师不管不问。 状态就可以有:喜欢学习,不喜欢学习,无感学习。
所以会有过程:无感--》随便写写作业-》老师批作业-》老师不管不问--》无感--》认真写作业--》老师批作业-》老师表扬--》喜欢学习--》……
抽象一下:
在每个时步 t, 智能体会观测或者接收到当前环境的状态 St,根据这个状态 St执行动作at。执行完动作之后会收到一个奖励 rt+1 ③,同时环境也会受到动作 at 的影响会变成新的状态 St+1,并且在 t+1 时步被智能体观测到。如此循环下去,我们就可以在这个交互过程中得到一串轨迹。
S0,a0,r1,s1,a1,r2,s2……
ps:这里时步 t的大小并不固定,例如老师当堂批作业,t就偏小,老师第二天才发作业,t就偏大。
注意:在强化学习中我们通常考虑的是有限马尔可夫决策过程( Finite MDP ),即 t(时步) 是有限的,这个上限一般用 T表示,也就是当前交互过程中的最后一个时步或最大步数,从 t=0 和 t=T 这一段时步我们称为一个回合( episode ),比如游戏中的一局。
二、马尔科夫性质:
- 在给定历史状态的情况下,某个状态的未来只与当前状态有关,与历史的状态无关
注意:但在现实情况下,某个状态的未来不仅与当前状态有关,还历史的状态有关。比如,你喜欢学习,总不能之前很讨厌,现在老师表扬你一下,就喜欢吧。这个具体实现后面提。
三、回报
马尔可夫决策过程中智能体的目标是获得最大化累积的奖励,通常我们把这个累积的奖励称为回报(Return),用Gt 表示。
其中 T 前面提到过了,表示最后一个时步,也就是每回合的最大步数。这个公式其实只适用于有限步数的情境,例如玩一局游戏,无论输赢每回合总是会在有限的步数内会以一个特殊的状态结束,这样的状态称之为终止状态。
四、状态转移矩阵:
截至目前,我们讨论的都是有限状态马尔可夫决策过程( finite MDP ),这指的是状态的数量必须是有限的(无论是离散的还是连续的。)
既然状态数有限,那么我们就可以用一种状态流向图来表示智能体与环境交互过程(马尔科夫决策)中的走向。
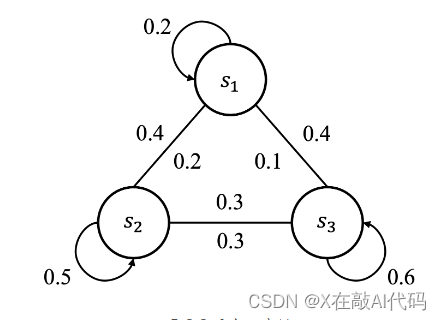
这就是马尔科夫链
将此链赋予实际意义:s1表示喜欢学习,s2表示讨厌,s3表示无感。那么s1上指向自己的环就是从喜欢学习到喜欢学习的概率p11(仍喜欢学习),s1到s2的外边就是从喜欢学习到不喜欢。其余同理。
将此链在抽象一下,就可以得到状态表

- 状态转移矩阵(State Transition Matrix)
ps:pij表示从状态si到sj。
注意:1.其中 n表示状态数,对于同一个状态所有状态转移概率加起来是等于 1 的,比如对于状态 s1 来说,p11+p12+⋯+p1n=1。
2.状态转移矩阵是环境的一部分,跟智能体是没什么关系的,而智能体会根据状态转移矩阵来做出决策。在学习这个例子中,小明无法决定,老师是(+)奖励小红花,表扬。(-) 叫家长,作业给撕喽(0)老师不管不问 这三个中的那个状态。他只能根据这个状态,做出他的决策,比如好好写作业还是糊弄写。
五、五元组定义
我们可以把马尔可夫决策过程用一个五元组 <S,A,R,P,y> 来表示。其中 S表示状态空间,即所有状态的集合,A表示动作空间,R 表示奖励函数,P 表示状态转移矩阵,y 表示折扣因子。
关于折扣因子补充一下:这个y主要用于没有终止的情况(对比回报那块),比如人造卫星,除非报废才会终止。这种情况下 T=无穷

六、相关习题:
1.强化学习所解决的问题一定要严格满足马尔可夫性质吗?请举例说明。
答:不需要,例如在围棋游戏场景中,不仅需要考虑当前棋子的位置,还需要考虑棋子的历史位置,因此不满足马尔可夫性质。
但依然可以使用强化学习的方法进行求解,例如在 AlphaGO 论文中使用了蒙特卡洛树搜索算法来解决这个问题。
在一些时序性场景中,也可以通过引入记忆单元来解决这个问题,例如在 DQN 算法中,使用了记忆单元来存储历史状态,从而解决了这个问题,尽管它也不满足马尔可夫性质
2.马尔可夫决策过程主要包含哪些要素?
答:马尔可夫决策 <S,A,R,P,y> 来表示。
其中 S表示状态空间,即所有状态的集合,A表示动作空间,R 表示奖励函数,P 表示状态转移矩阵,y 表示折扣因子。
状态转移矩阵 p 是环境的一部分,而其他要素是智能体的一部分。
在实际应用中,通常还考虑值函数 V 和策略函数 π等要素,值函数用于某个状态下的长期累积奖励,策略函数用于某个状态下的动作选择。
3.马尔可夫决策过程与金融科学中的马尔可夫链有什么区别与联系?
答:马尔可夫链是一个随机过程,其下一个状态只依赖于当前状态而不受历史状态的影响,即满足马尔可夫性质。马尔可夫链由状态空间、初始状态分布和状态转移概率矩阵组成。
马尔可夫决策过程是一种基于马尔可夫链的决策模型,它包含了状态、行动、转移概率、奖励、值函数和策略等要素。
马尔可夫决策过程中的状态和状态转移概率满足马尔可夫性质,但区别在于它还包括了行动、奖励、值函数和策略等要素,用于描述在给定状态下代理如何选择行动以获得最大的长期奖励。















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









