







作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
目标网站:aHR0cHM6Ly93d3cubmlrZS5jb20vdy9tZW5zLWNsb3RoaW5nLTZ5bXg2em5pazE=
1.确定抓取内容
我们主要获取商品的url、标题、分类、价格和详情图片的url。
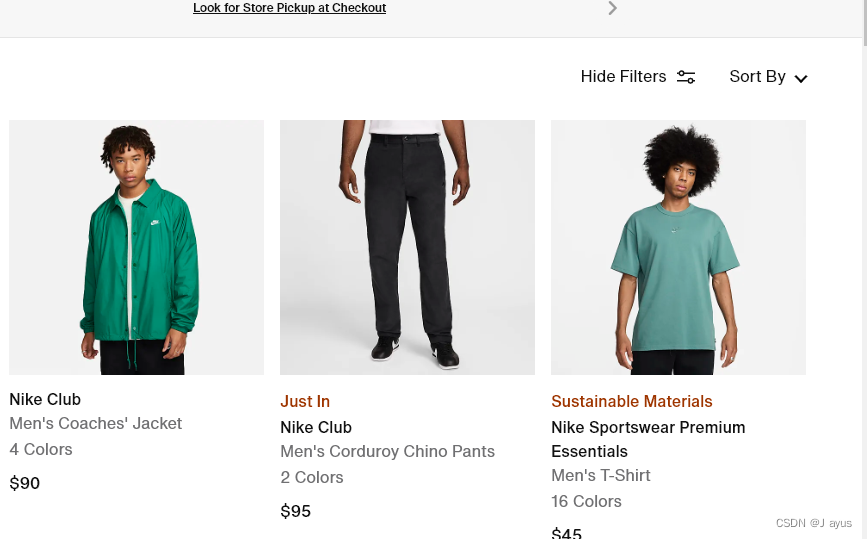
2.循环获取数据
在主页面得到多个子页面的url后,然后通过循环请求网页并获得数据,利用的是drissionpage + xpath。接下来就是实现该目的的步骤。
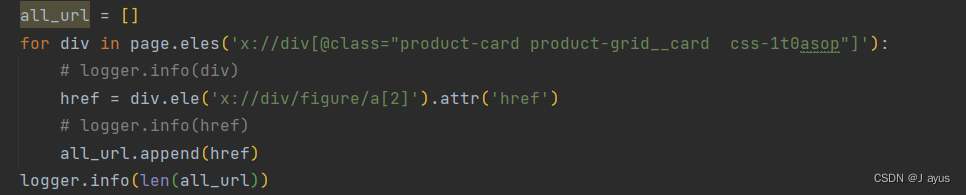
第一步:获取商品url
由于页面中只存在24个商品信息,需要下滑才可以得到更多商品信息。有什么函数不懂的可以在官方文档查询:https://drissionpage.cn/ChromiumPage/intro

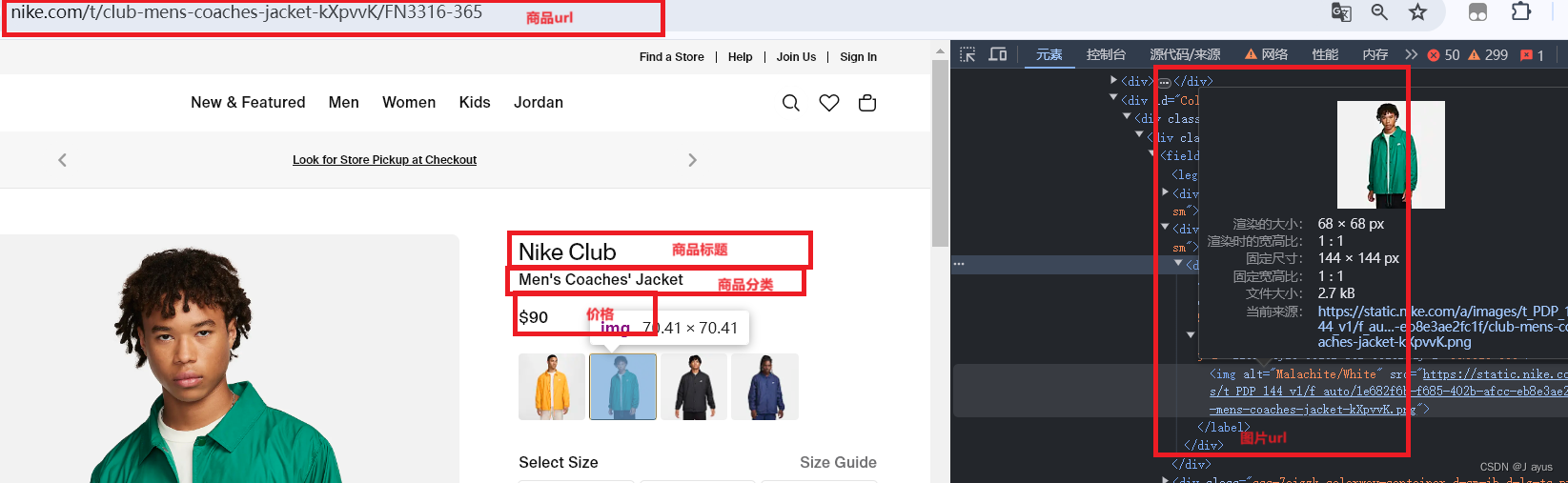
刷新后利用xpath定位到商品的url并保存。
第二步:定位信息
利用xpath定位数据所在网页位置、编写提取规则
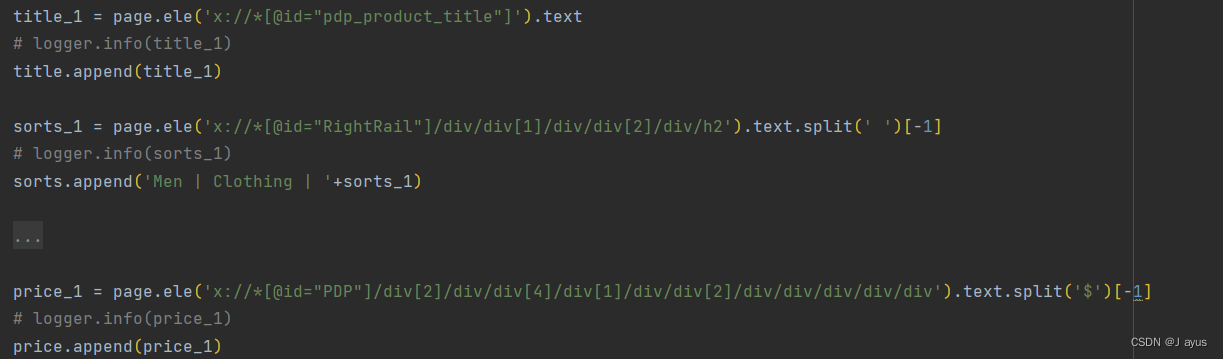
第三步:循环请求

3.储存数据
得到数据后可将其存入csv文件或者xlsx文件。
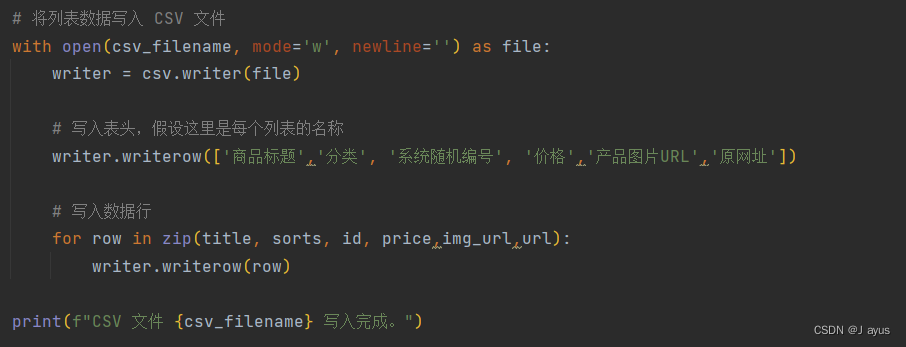
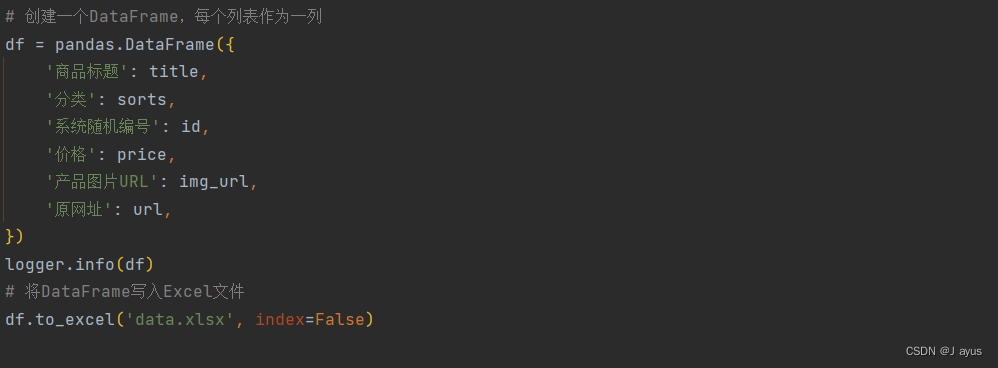
数据结果如图:(其中8位随机字符串为自己定义的编码,用于存放获取到的图片。)
















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









