






爬虫流程
用爬虫爬取数据相当于是由你的电脑往对方服务器上发送虫子,然后虫子背着对方服务器上的数据返回你的电脑。即由本地向服务器发送请求再返回本地的过程。
1.数据在哪?
需要知道数据在哪(即url地址是什么)。
2.解析网页
即分析数据如何获取。
3.处理数据
即将数据保存下来。
1.数据在哪?
# 目前代码:
# 发送的地址
url = 'https://nba.hupu.com/stats/players'发送请求
python中用requests.get()发送请求。虽然能发送,但是python默认情况下是不支持的,所以需要安装request这个包即import requests。
# 目前代码:
import requests
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
# 发送请求
resp = requests.get(url)因为网页都不支持代码访问,所以需要伪装成浏览器的形式。如何伪装?
1.在网页中右键,然后点“检查”。需要复制“use-agent”里的内容。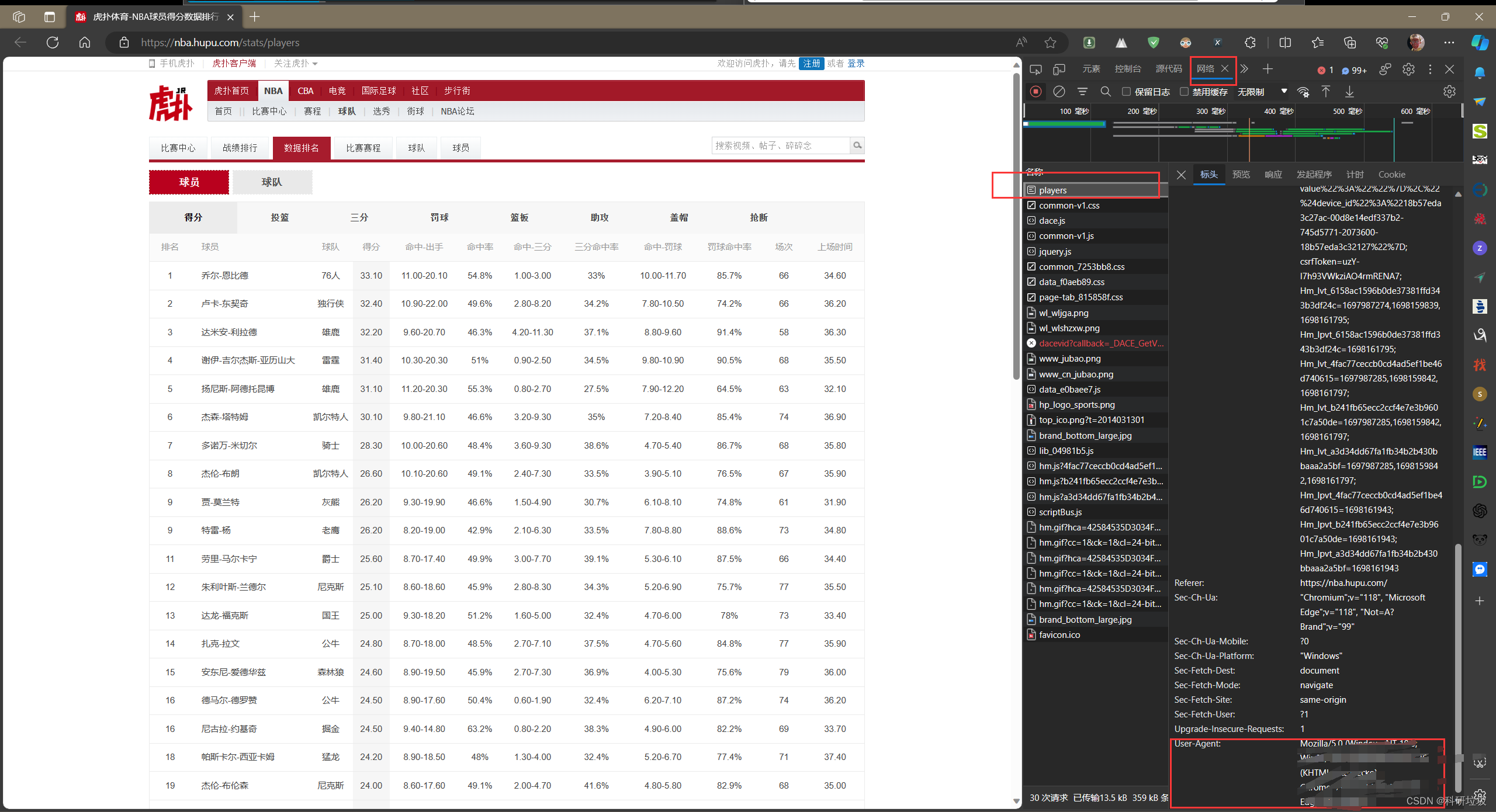
# 目前代码:
import requests
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
headers = {'user-agent':'**********'}
# 发送请求
resp = requests.get(url, headers=headers)到这里可以运行看一下结果,运行下面代码
# 目前代码:
import requests
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
headers = {'user-agent':'**********'}
# 发送请求
resp = requests.get(url, headers=headers)
print(resp.text)显示一些乱七八糟的东西,即:
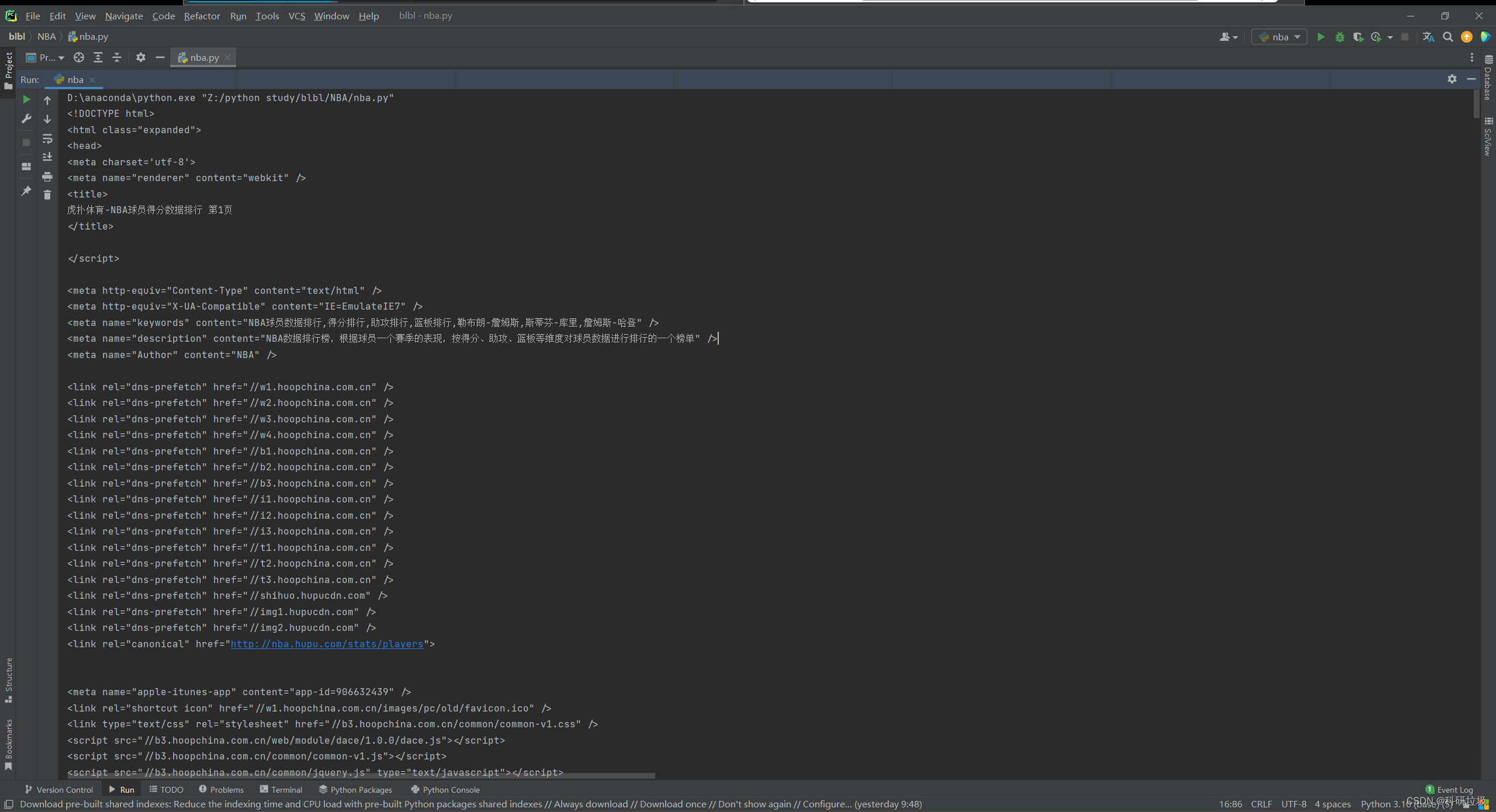
其实可以看出已经显示了球员信息,但是里面有一些没用的信息。为什么会这样呢?是因为html语言。在网页中右键,点“查看页面源代码”显示:
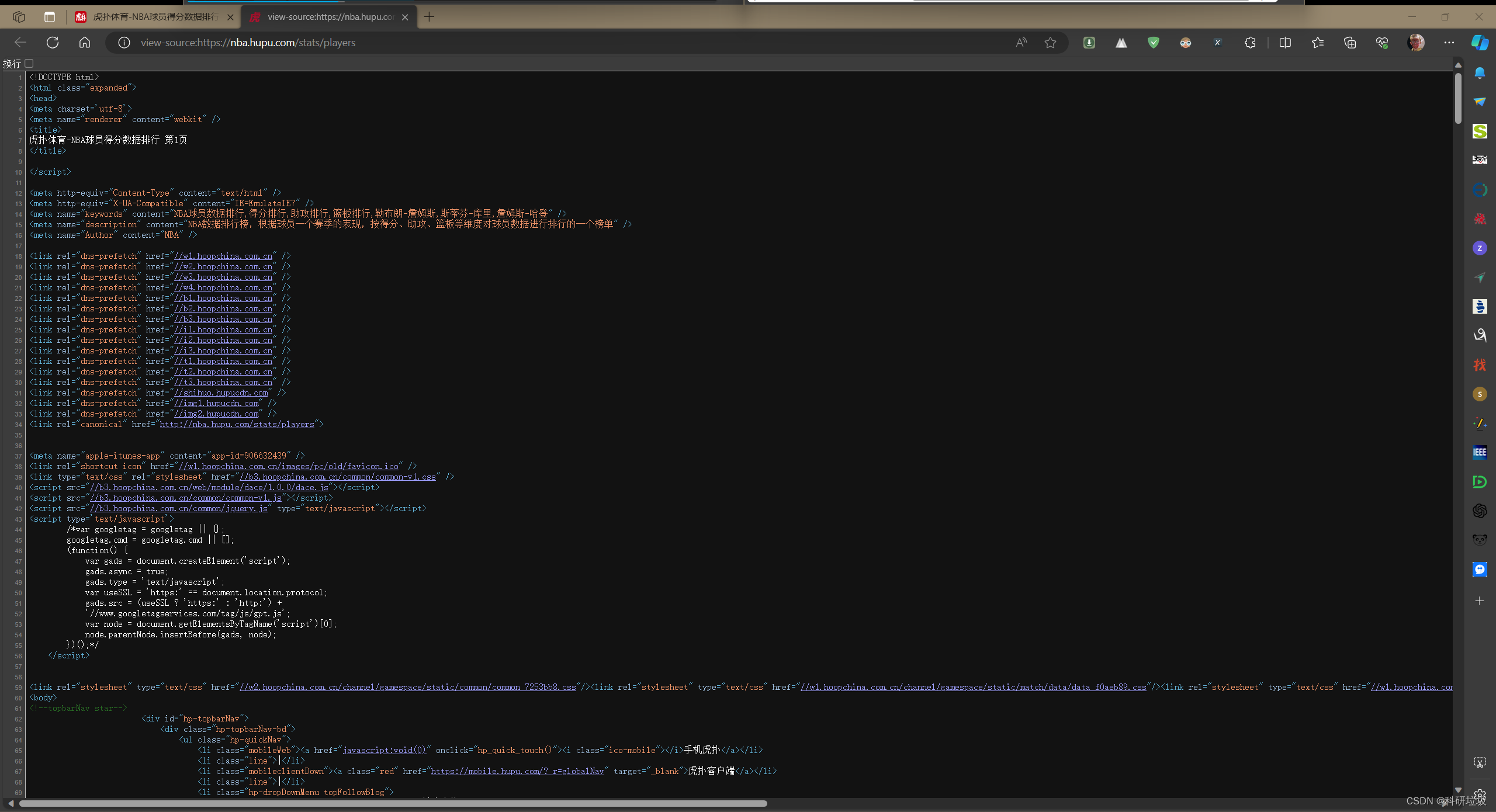
可以看出,我们打印出来的其实是网页的源代码。我们需要的是球员数据,所以需要一系列操作提取我们需要的东西。此时需要用到“xpath”(在浏览器中下载一个名叫“xpath helper”的扩展即可)。
在网页中打开“xpath helper”,然后右键网页,点“检查”。查看“元素”中的内容。可以看出“乔尔-恩比德”在>a中,“>a”在“>td”下,“>td”在“>tr”下,tr在tbody下,tbody在table下。
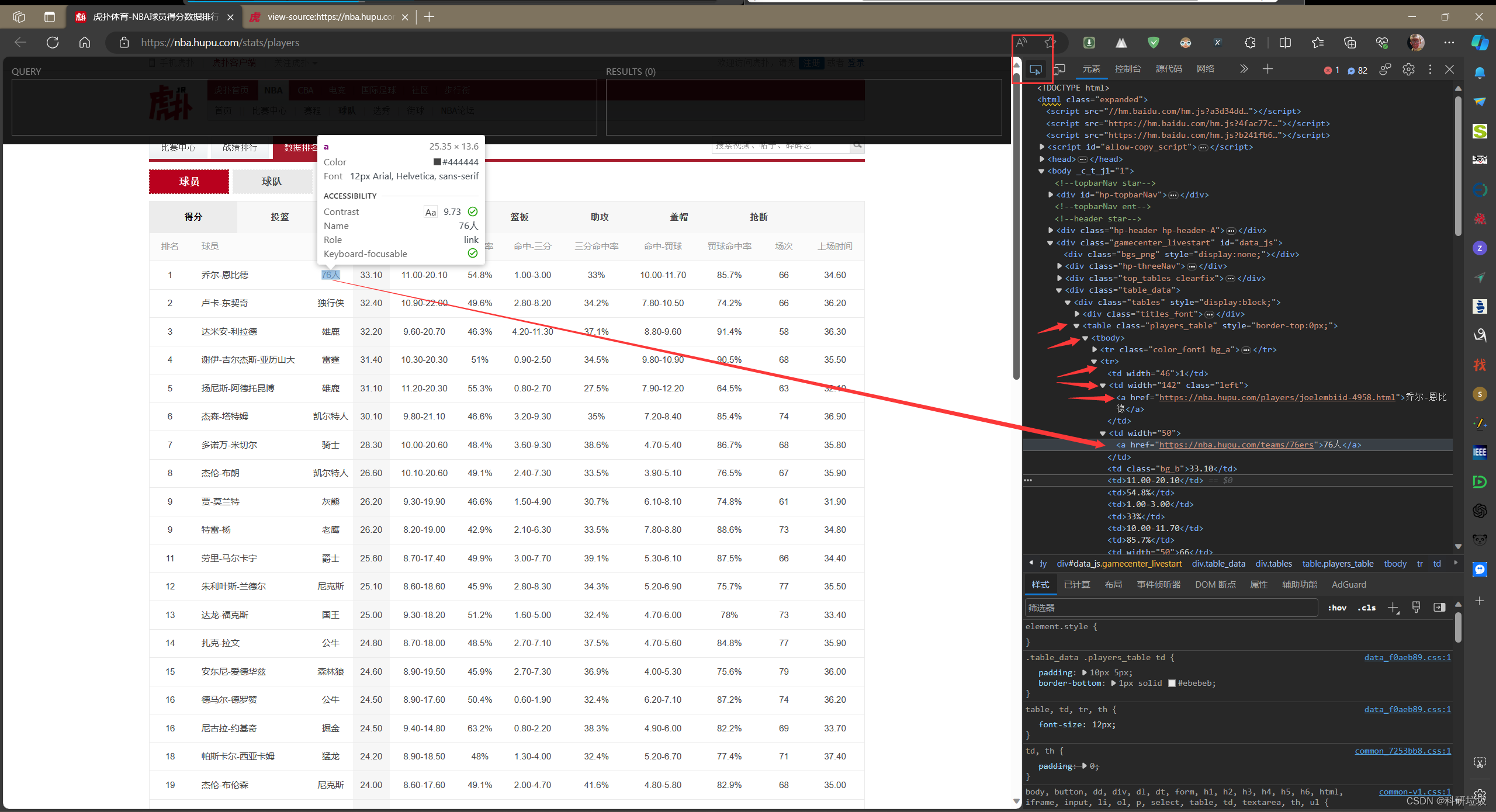
在“xpath helper”中输入下列代码即可展示出所选取的数据。
//table[@class="players_table"]//tr/td/a/text()
# 两个“//”代表任何一个标签,“table”表示在table中,[]表示开始过滤。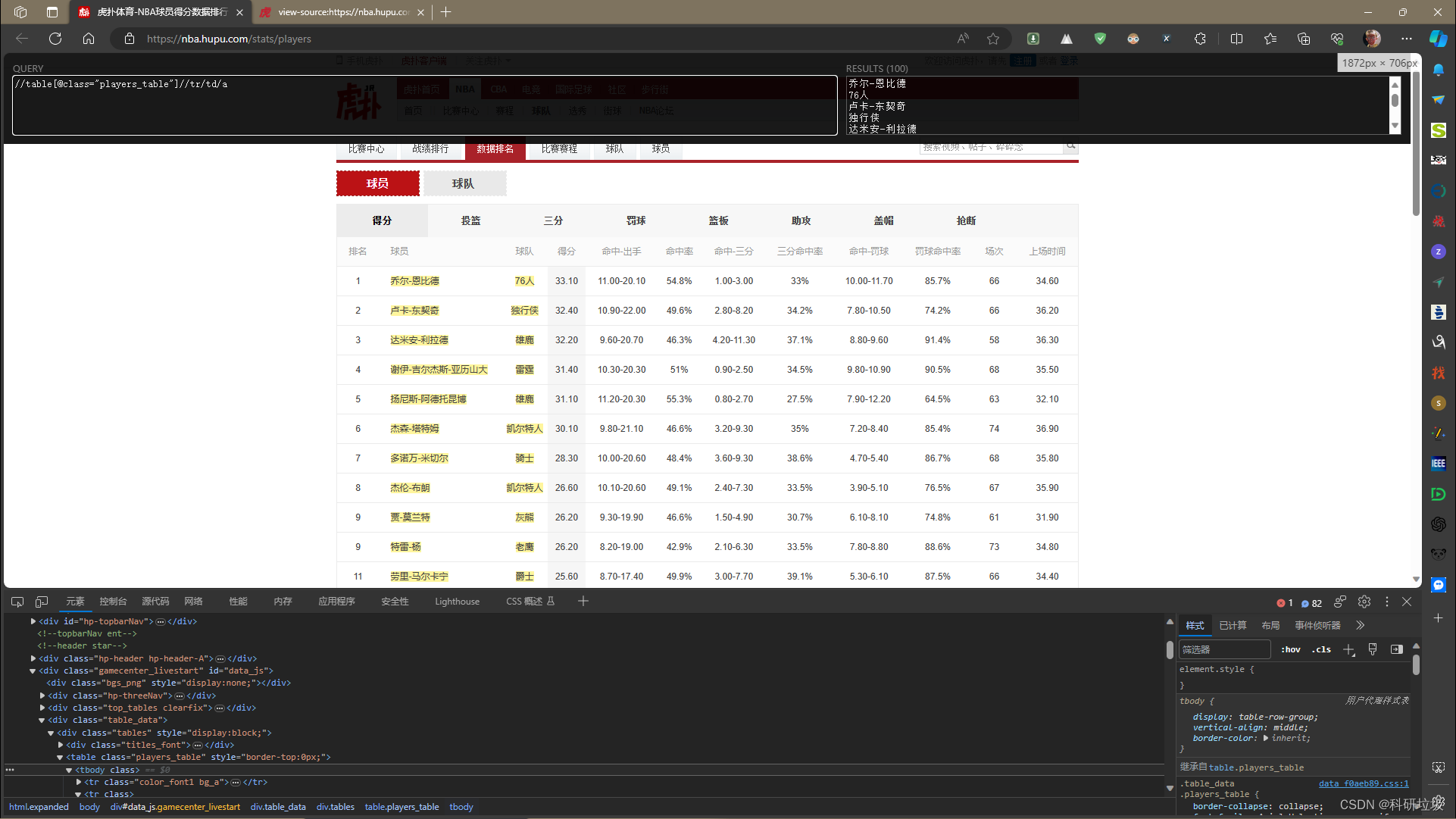
这个代码是xpath的代码表达式,怎么才能在python中应用呢?需要用“lxml”模块中的“etree”,“etree”可以解析xpath的表达式。有了之后怎么用呢?需要先创建,怎么创建呢?因为是html语言,所以要写出需要解析的html对象。即:
# 目前代码:
import requests
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
headers = {'user-agent':'**********'}
# 发送请求
resp = requests.get(url, headers=headers)
# 处理结果
e = etree.HTML(resp.text)然后就可以进行xpath解析帮助提取了。打印结果。
# 目前代码:
import requests
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
headers = {'user-agent':'**********'}
# 发送请求
resp = requests.get(url, headers=headers)
# 处理结果
e = etree.HTML(resp.text)
# 解析相应的数据
nanmes = e.xpath('//table[@class="players_table"]//tr/td/a/text()')
print(names)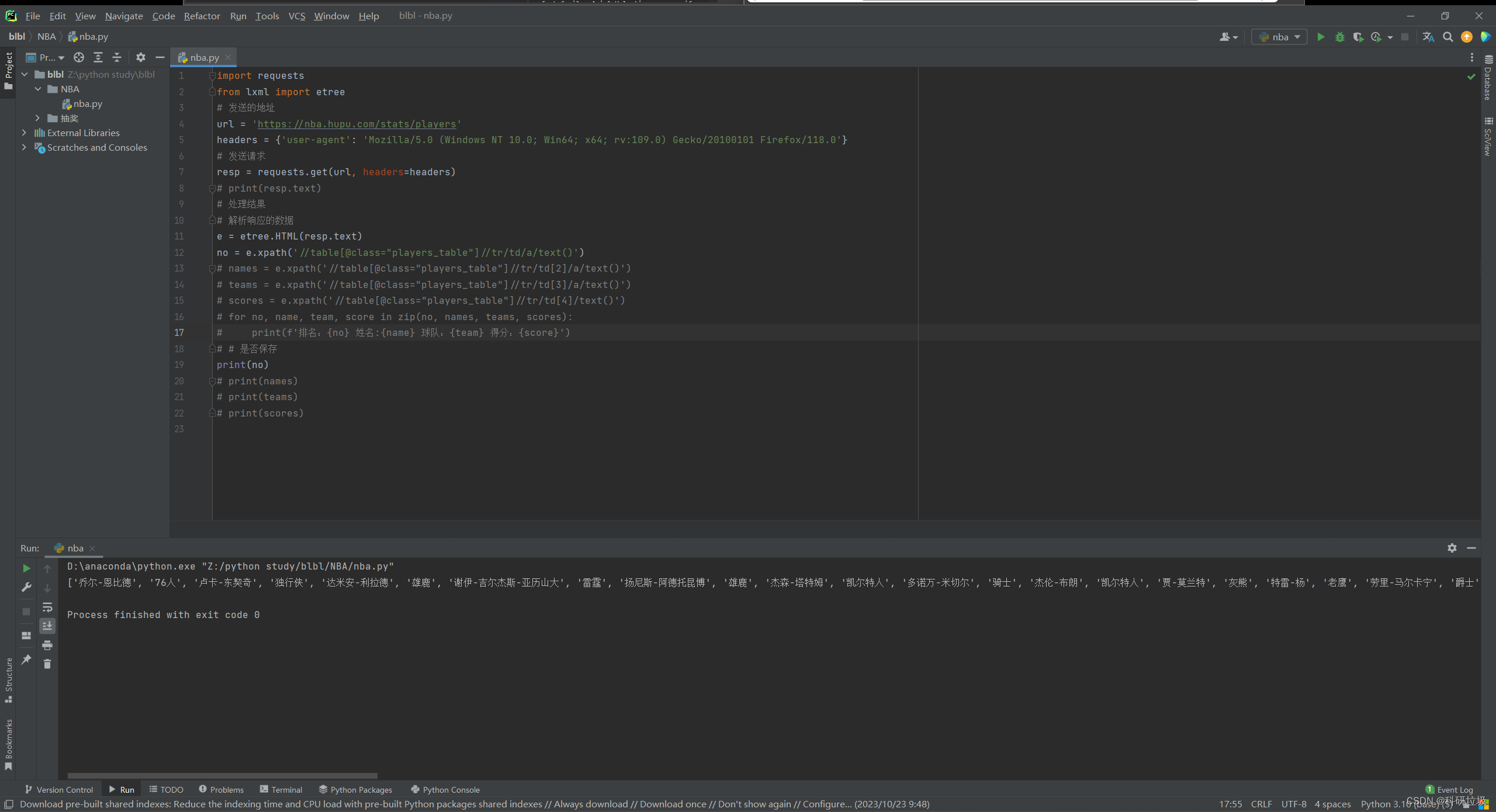
下面自由发挥,爬取排名数据,球员信息,球队信息,得分情况。
参考视频:
【2022年B站最全系列项目实战】70个python练手项目合集,七天练完,练完即可就业~练手/项目经验/毕设















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









