







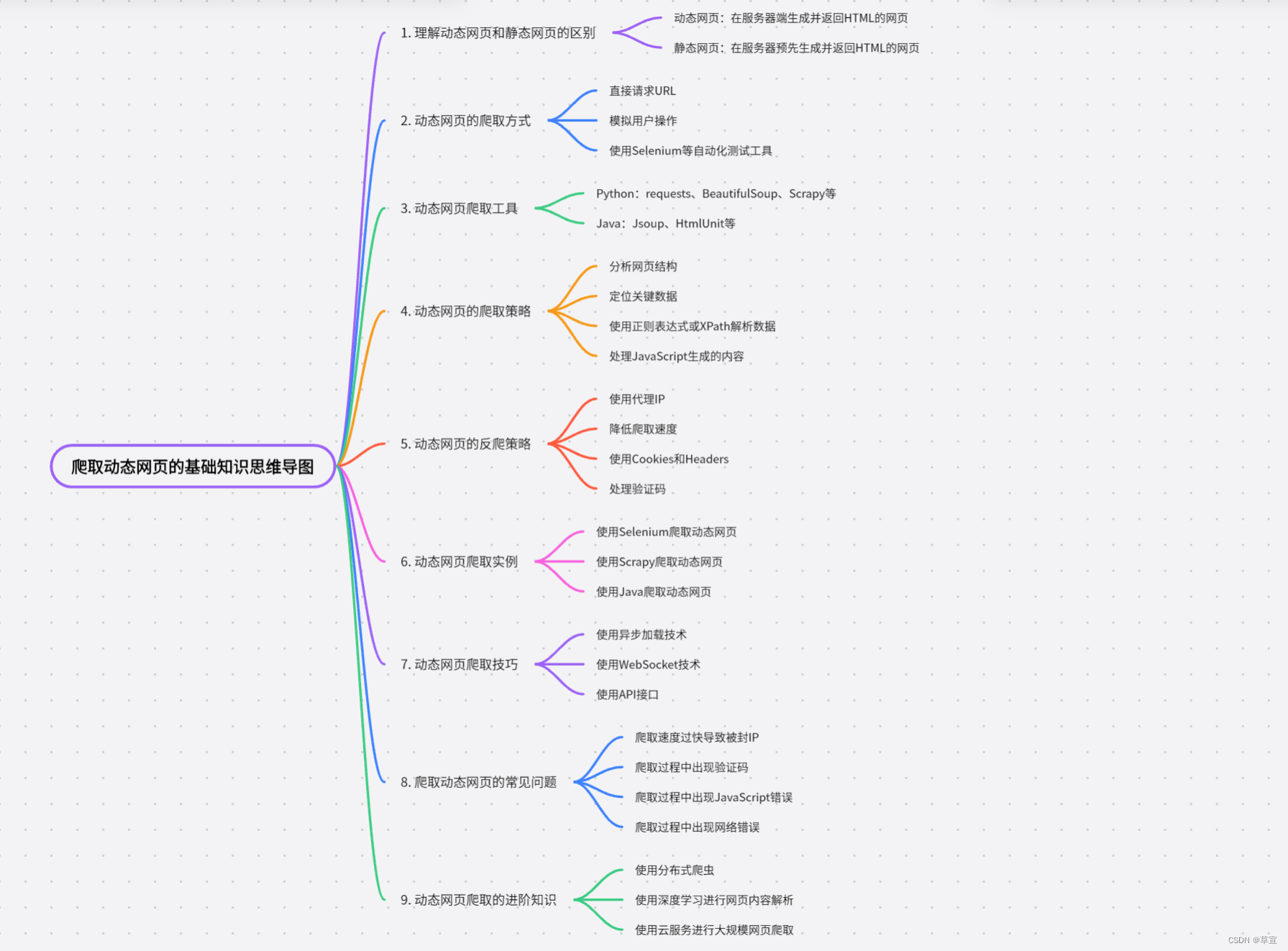
一、基础知识
抓取动态网页数据是指从使用 JavaScript 或其他前端技术生成内容的网页中提取数据。相比于静态网页,动态网页的内容是通过 JavaScript 在客户端动态生成的,因此传统的静态网页抓取方法可能无法获取到动态生成的数据。
1.理解动态网页:
动态网页是指使用 JavaScript 或其他前端技术在客户端生成内容的网页。这些技术可以通过 AJAX 请求从服务器获取数据,并使用 JavaScript 动态更新网页内容。
2.分析网页结构:
在抓取动态网页数据之前,需要仔细分析网页的结构和行为。了解网页中使用的 JavaScript、AJAX 请求和数据渲染方式,以及数据所在的位置。
3.使用开发者工具:
现代浏览器提供了开发者工具,可以帮助我们分析网页的结构和行为。通过查看网络请求、元素检查器和控制台等功能,可以获取有关网页加载和数据请求的详细信息。
4.模拟请求:
了解网页中的数据请求方式(如 AJAX 请求),可以使用编程语言中的相应库来模拟这些请求,并获取返回的数据。通常,可以通过分析网络请求的 URL、请求方法、请求头和请求体等信息来模拟请求。
5.处理动态渲染:
有些动态网页使用 JavaScript 在客户端动态渲染内容。在这种情况下,传统的静态网页抓取方法可能无法获取到完整的数据。可以使用无头浏览器(Headless Browser)来模拟浏览器行为,执行 JavaScript 并获取完整的渲染后的页面内容。
6.数据提取与解析:
一旦获取到动态网页的内容,可以使用相应的数据提取和解析技术来从中提取所需的数据。可以使用正则表达式、XPath、CSS 选择器等方法来定位和提取数据。
二、爬取NBA球员数据并存入数据库
1.网址
所爬取网页的网址:
因为传统的静态网页抓取方法可能无法获取到动态生成的数据,所以基础URL就不顶事了,经过分析的动态内容URL才是我们要的结果。
点击进入上面网页,按F12或右键检查进入以下界面并刷新。
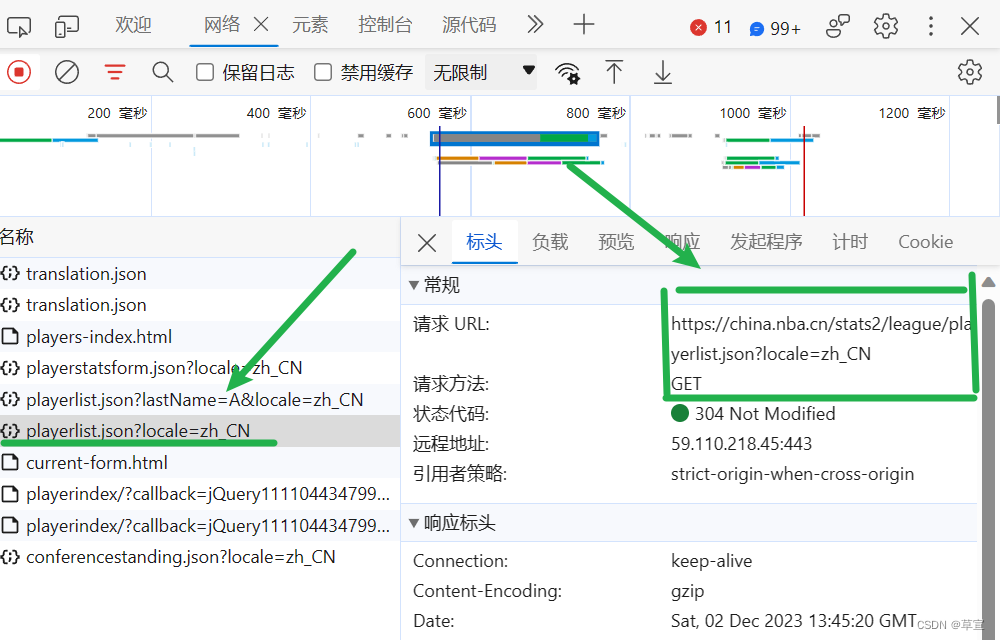
绿色横线的地方即是我们要寻找的json文件,绿色方框是我们所需要的URL。
2.发送HTTP请求
使用Python中的requests库或类似的工具,发送HTTP请求来获取API的数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









