






项目1:中国计算机设计大赛赛事统计
1、问题分析和任务定义
【问题描述】
参加计算机设计大赛的n个学校编号为1~n,赛事分成m个项目,项目的编号为1~m.比赛获奖按照得分降序,取前三名,写一个统计程序产生各种成绩单和得分报表。
【基本要求】
1)每个比赛项目至少有10支参赛队;每个学校最多有6支队伍参赛;
2)能统计各学校的总分;
3)可以按照学校编号或名称,学校的总分、各项目的总分排序输出;
4)可以按学校编号查询学校某个项目的获奖情况;可以按项目编号查询取得前三名的学校;
5)数据存入文件并能随时查询
- 数据结构的选择和概要设计
学校定义为一个结构体类型,
typedef struct
{
int schnum, i;//学校的编号
int teamnum[6];//每个学校六个参赛队
int score[6];//学校六个项目得分
int summscore;
}school;//学校记录类型
顺序表中存放学校数组和长度:
struct List
{
school r[10];
int length;
};
还有对顺序表进行排序的void InsertSort(List& L)函数和打印顺序表void print(List L)函数。
流程图:

项目2:校园导游咨询
要求:
设计一个校园导游程序,为来访的客人提供各种信息查询服务。
(1)设计你所在学校的校园平面图,所含景点不少于10个.以图中顶点表示校内各景点,存放景点名称、代号、简介 等信息;以边表示路径,存放路径长度等相关信息。
- 为来访客人提供图中任意景点相关信息的查询。
- 为来访客人提供图中任意景点的问路查询,即查询任意两个景点之间的一条最短的简单路径。
思路:本次程序设计中对于图的存储采用的是邻接矩阵,其实就是二维数组。查询路径采用的则是弗洛伊德算法,其中对于所求的路径地点名采用的是三元组的形式,第一个数表示始点,第二个表示终点,第三个表示中间经过的点的下标。
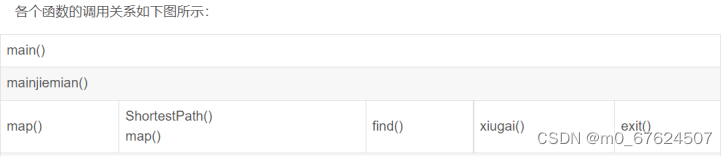
本程序中包含5个模块
(1)主函数:int main();
(2)主界面函数:mainjiemian();
(3)显示地图信息:map();
(4)求取最短路径的算法:ShortestPath();
(5)退出函数:exit();
3.元素类型、结点类型和指针类型
#define MX65535 //最大值 无穷
#defineNUM 10 //最大顶点个数
typedef intadjmatrix[NUM][NUM];
typedef intpath[NUM][NUM][NUM];
typedefstruct
{ int vex; /*顶点号*/
string name; /*景点名字*/
string jieshao; /*景点简介*/
}Vertex;
项目3:算术表达式求解
- 问题分析和任务定义
设计一个简单的算术表达式计算器。实现标准整数类型的四则运算表达式的求值(包含括号,可多层嵌入)。
- 数据结构的选择和概要设计
模拟计算器程序主要利用了“栈”这种数据结构来把中缀表达式转化为后缀表达式,并且运用了递归的思想来解决Abs()和Sqrt()中嵌套表达式的问题,其中还有一些统计的思想来判定表达式是否合法的算法
- 详细设计和编码
本设计需要考虑许多的问题,首先是表达式的合法判断,然后是字符串表达式提取分离的问题,核心部分就是中缀表达式转化为后缀表达式。对于第一个问题,我是分步来判断,首先表达式中是否含有其它非法字符,然后判断括号是否合法,接着判断运算法两边是否合法,比如除法时,除数不能为零。对于第二个问题,我是直接转换的,从左到右遍历中缀表达式,把数据全部取出来。对于核心问题,利用了“栈”这种“后进先出”的数据结构,利用两个“栈”,一个“数据栈”,一个“运算符栈”来把中缀表达式转换成后缀表达式。最后利用后缀表达式来求解表达式的值。
3.1 表达式的合法判定
表达式的合法判定过程如图所示:
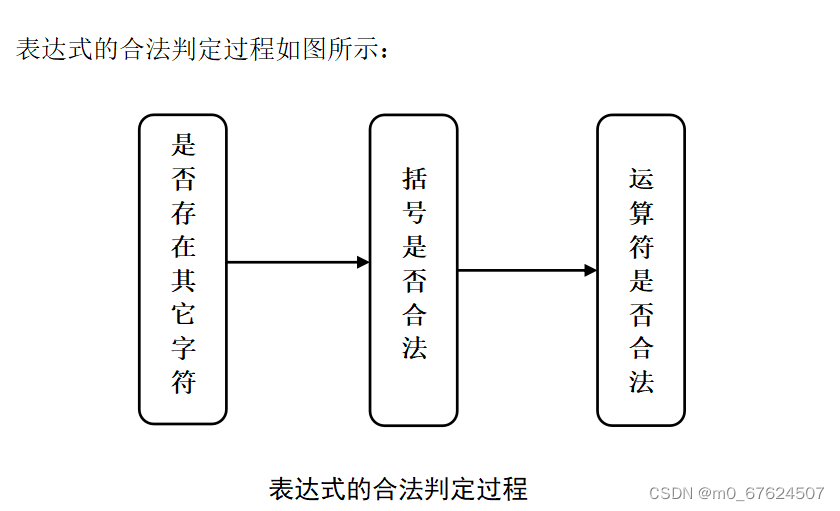
首先是其它字符的判定,从左到右遍历中缀表达式,看是否存在其它非法的。
然后是判定括号是否的匹配是否和合法,首先把“(”对应为1,相应的“)”对应为-1。从左到右遍历表达式,如果遇到括号就加上其对应的值,用sum来保存其累加值。如果在中途出现sum小于零的情况,即出现“..... )” 那么的情况,即非法。在遍历的最后,还要判断sum的值是否为零,如果为零就是合法,否则就是非法。代码如下:
for(i=0;i<s.length();i++){ //检验括号是否合法,以及是否存在非法字符
if(!IsNum(s[i]) && !IsSign(s[i]) && s[i]!='('
&& s[i]!=')' && s[i]!='A' && s[i]!='S' && s[i]!='.')return false;
if(s[i]=='(')sum+=1;
else if(s[i]==')')sum-=1;
if(sum<0)return false; //括号匹配不合法
}
运算符判断是否合法,也是遍历一遍表达式,遇到“/”,看其后面的除数是否为零。这里要考虑表达式中出现负数的情况,因此特殊考虑“-”号,判断它的前面是“(”还是没有字符了,那么就是负数。
中缀表达式转化为后缀表达式
中缀表达式转化为后缀表达式,利用两个“栈”,一个“数据栈”,一个“运算符栈”来把中缀表达式转换成后缀表达式。最后利用后缀表达式来求解表达式的值。设一个stack存后缀数据,一个rout栈存运算符。
算法流程如下:
(1)从右向左依次取得数据ch。
(2)如果ch是操作数,直接加进stack中。
(3)如果ch是运算符(含左右括号),则:
a:如果ch = '(',放入堆栈rout中。
b:如果ch = ')',依次输出堆栈rout中的运算符,直到遇到'('为止。
c:如果ch不是')'或者'(',那么就和堆栈rout顶点位置的运算符top做优先级比较。
1:如果ch优先级比rtop高,那么将ch放入堆栈rout。
2:如果ch优先级低于或者等于rtop,那么输出top到stack中(直到!top或者满足 1),然后将ch放入堆栈rout。
可以看出算法复杂度是O(n)的,因此效率是比较高的,能够在1s内处理百万级别长度的表达式。算法的主要思想是利用“栈”的后进先出的特性,以及运算符的优先级,这里我们定义运算符的优先级;代码如下:
int GetKey(char c){ //定义运算符的关键字
int key;
switch(c){
case '+':key=1;break;
case '-':key=1;break;
case '*':key=2;break;
case '/':key=2;break;
case '(':key=4;break;
case ')':key=5;break;
}
return key;
}
中缀转化为后缀处理的核心代码如下:
/* 双栈,sta1存放后缀表达式,sta2存放运算符符号*/
stack<pair<double,int> > sta1,sta2;
for(i=0;i<k;i++){
if(!num[i].second)sta1.push(num[i]); //为数据,直接放入sta1
else if(num[i].second==4)sta2.push(num[i]); //为'(',直接放入sta2
/* 为')',从sta2中取出运算符,push到sta1中,直到遇到')' */
else if(num[i].second==5){
while(sta2.top().second!=4){
sta1.push(sta2.top());
sta2.pop();
}sta2.pop(); //取出'('括号
}
/*为'+','-','*'或者'/'运算符,取出sta2中的运算符,
push到sta1中,直到比sta2栈顶中的优先级大*/
else {
while(!sta2.empty() && sta2.top().second>=num[i].second && sta2.top().second!=4){
sta1.push(sta2.top());
sta2.pop();
}
sta2.push(num[i]); //放入当前运算符
}
}
最后,后缀表达式就存放在sta1栈中,把sta1栈中的结果存放到SufExp中就得到了后缀表达式。
处理后缀表达式
这里也是运用“栈”来处理,运用栈模板在求值过程顺序扫描后缀表达式,每次遇到操作数便将它压入堆栈;遇到运算符,则从栈中弹出两个操作数进行计算,然后再把结果压入堆栈,等到扫描结束时,则表达式的结果就求出来了。算法流程如图所示:

处理后缀表达式流程
核心代码如下:
double Expression::GetAns()
{
int i;
double temp,num1,num2; //num1和num2为运算符两遍的操作数
stack<double> sta; //数据栈
for(i=0;i<Size;i++){
if(!SufExp[i].second){ //为数据
sta.push(SufExp[i].first);
}
else { //为运算符
num1=sta.top(); //取出第一个操作数
sta.pop();
num2=sta.top(); //取出第二个操作数
sta.pop();
temp=Cal((char)SufExp[i].first,num2,num1);
sta.push(temp); //放入操作数结果
}
}
Ans=sta.top();
return Ans; //返回最终结果
}
表达式嵌套处理
如果遇到A()和S()中含有表达式,而不是单纯的数字,例如A(1.1+3.4*S(2.5)),那么就需要对其字表达式“1.1+3.4*S(2.5)”进行递归处理,这个子表达式中还含有子表达式“2.5”,然后再递归处理,依次类推下去。其核心代码如下:
if(s[i]=='A' || s[i]=='S'){ //遇到Abs()或者Sqrt()递归处理子表达式
Expression temp; //创建子表达式
temp.Init();
for(j=0;i+j+2<Pos[i+1];j++) //复制表达式
st[j]=s[i+j+2];
st[j]=0;
temp.s=st; //复制表达式
temp.SloveExp(); //得到子表达式的值
num[k].first=(s[i]=='A'?fabs(temp.Ans):sqrt(temp.Ans));
num[k].second=0; //标记为数据
if(s[i-1]=='-' && (i-1==0 || s[i-2]=='('))num[k].first=-num[k].first;
k++,i=Pos[i+1];
}















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









