







秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
ConvNeXt是一种新型的纯卷积神经网络架构,它借鉴了Vision Transformers的元素并对标准ResNet进行了改进。这种架构通过采用大规模设计、优化模块、宏观设计变更以及ViT中的训练技巧,实现了在图像分类、目标检测和语义分割等多种视觉任务上与Transformers相媲美的性能,同时保持了标准ConvNets的简洁性和高效性。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
1. 原理

ConvNeXt 是一种新的卷积神经网络架构,其设计受到了现代深度学习模型的启发,特别是 Transformer 模型。ConvNeXt 旨在结合卷积神经网络(CNN)和 Transformer 的优势,以达到更高的性能和更好的计算效率。以下是 ConvNeXt 的主要原理和设计思想:
1. 背景与动机
随着 Transformer 模型在计算机视觉任务中的崛起,如 Vision Transformer (ViT) 和 Swin Transformer,研究者们开始探索如何改进传统的 CNN 以缩小与 Transformer 模型在性能上的差距。ConvNeXt 的设计初衷是通过现代化的设计理念来提升传统 CNN 的性能。
2. 架构设计
ConvNeXt 在保留 CNN 基本结构的同时,引入了一些现代化的设计元素,包括更深的网络、更大的卷积核以及新的归一化方法。其主要组成部分如下:
基础模块
ConvNeXt 的基本构件是 ConvNeXt Block,它类似于 ResNet 的残差块,但在结构和细节上有所改进。一个典型的 ConvNeXt Block 包括以下几部分:
-
深度卷积(Depthwise Convolution):使用更大的卷积核(例如 7x7),提高局部感受野。
-
逐点卷积(Pointwise Convolution):1x1 卷积,用于跨通道的信息融合。
-
Layer Normalization:替代传统的批量归一化(Batch Normalization),提供更稳定的训练过程。
-
GELU 激活函数:使用更平滑的激活函数,以改善非线性特性。
-
跳跃连接(Skip Connections):与 ResNet 类似,保留了跳跃连接以防止梯度消失问题。
模块化设计
ConvNeXt 的整体架构是通过堆叠多个 ConvNeXt Block 来构建的,并通过在不同阶段改变特征图的通道数和分辨率,以构建一个多尺度的表示。
3. 关键改进点
更大的卷积核
使用更大的卷积核(例如 7x7)可以有效地增加感受野,使得每个卷积操作能够捕捉到更大范围的上下文信息。与传统的 3x3 卷积相比,更大的卷积核可以减少网络的深度,同时保持甚至提高性能。
Layer Normalization
Layer Normalization 适用于较小的批次和变长输入,能够提供更稳定的训练过程。相较于 Batch Normalization,Layer Normalization 在不同任务和数据集上的表现更为一致。
更深的网络
通过堆叠更多的卷积层和增加网络的深度,ConvNeXt 能够捕捉更复杂的特征表示,从而提升模型的表达能力和性能。
高效的参数化设计
ConvNeXt 通过精心设计的卷积层和激活函数,尽量减少参数量和计算开销,使得网络在保持高性能的同时,具有更高的计算效率。
4. 实验结果
在各类计算机视觉任务中,如图像分类、目标检测和语义分割,ConvNeXt 展现出了与最新的 Transformer 模型相媲美的性能,同时保持了 CNN 的高效计算特点。这表明,通过现代化的设计理念,传统的 CNN 也能够达到顶尖的性能。
总结
ConvNeXt 是对传统 CNN 的一次重要改进,通过引入更大的卷积核、Layer Normalization、GELU 激活函数和更深的网络结构,成功地将 CNN 的性能提升到了新的高度。它证明了即使在 Transformer 模型日益流行的今天,卷积神经网络依然具有巨大的潜力和发展空间。
2. 将ConvNeXt添加到YOLOv5中
2.1 代码实现
关键步骤一:将下面代码粘贴到/yolov5-6.1/models/common.py文件中
#------------------------------------Convnext start -------------------------------------
#ConvNextBlock
class ConvNextBlock(nn.Module):
def __init__(self, inputdim, dim, drop_path=0., layer_scale_init_value=1e-6, kersize = 7): #demo: [64, 64, 1] 1 denotes the number of repeats
super().__init__()
#匹配yolov5配置文件加入outdim输出通道
# self.flag = True if dim == outdim else False
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kersize, padding=kersize // 2, groups=dim) # depthwise conv
self.norm = LayerNorm_s(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
# if self.flag == False:
# raise ValueError(
# f"Expected input out to have {dim} channels, but got {outdim} channels instead")
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class LayerNorm_s(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
#------------------------------------Convnext end -------------------------------------ConvNeXt 是一种现代化的卷积神经网络架构,专注于结合卷积神经网络(CNN)和 Transformer 的优势。处理图片的主要流程如下:
1. 输入图片预处理
对输入图片进行预处理,例如调整大小和归一化。将图片调整为固定的尺寸,并将像素值归一化到一定范围,以便网络能够一致地处理输入数据。
2. 初始卷积层
使用一个初始的标准卷积层将输入图片转换为初步的特征图。这一步将图片的 RGB 通道转化为具有更多特征通道的特征图,提供后续处理的基础。
3. 深度卷积块 (ConvNeXt Block)
ConvNeXt 的核心由多个深度卷积块组成,每个块包含几个关键步骤:
-
深度卷积:使用更大的卷积核(如 7x7)进行深度卷积,能够捕捉更广泛的上下文信息,同时计算效率较高。
-
层归一化:对卷积输出进行层归一化,提供更稳定的训练过程,适用于较小的批次和变长输入。
-
GELU 激活函数:使用 GELU 激活函数代替传统的 ReLU,改善非线性特性,提供更平滑的激活。
-
逐点卷积:通过 1x1 卷积进行逐点卷积,用于跨通道的信息融合,提高特征表达能力。
4. 多尺度特征提取
网络分为不同的阶段(如 Stage 1, Stage 2, Stage 3, Stage 4),每个阶段提取不同尺度的特征。在每个阶段,通过改变特征图的通道数和分辨率,逐步提取更高级和抽象的特征表示。
5. 全局平均池化
在最后阶段,对特征图进行全局平均池化,将每个通道的特征值进行平均,生成一个固定大小的向量表示。这一步有助于将空间特征整合为全局特征,简化后续的分类任务。
6. 全连接层
将全局平均池化的输出送入全连接层,生成最终的分类结果或其他任务的输出(如目标检测、语义分割等)。全连接层将高维特征映射到所需的输出类别。
7. 输出结果
输出模型的预测结果,用于后续的任务处理或评估。这一步通常包括将网络的输出映射到具体的标签或类别,以实现目标应用的具体要求。
总结
ConvNeXt 通过现代化的设计理念,结合了深度卷积、层归一化、GELU 激活函数和逐点卷积,提升了传统卷积神经网络的性能和计算效率。其处理图片的流程涉及从预处理输入图片、逐层提取特征,到最终生成预测结果的各个步骤,体现了卷积神经网络在高效特征提取和分类任务中的强大能力。
2.2 新增yaml文件
关键步骤二:在下/yolov5-6.1/models下新建文件 yolov5_ConvNeXt.yaml并将下面代码复制进去
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2, 2]], # 1-P2/4
[-1, 1, C3, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P3/8
[-1, 2, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P4/16
[-1, 1, ConvNextBlock, [256, 256, 9, 7]],
[-1, 1, Conv, [512, 3, 2]], # 7-P5/32
[-1, 1, C3, [512]],
[-1, 1, SPPF, [512, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 13
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py中注册 添加“ConvNextBlock",
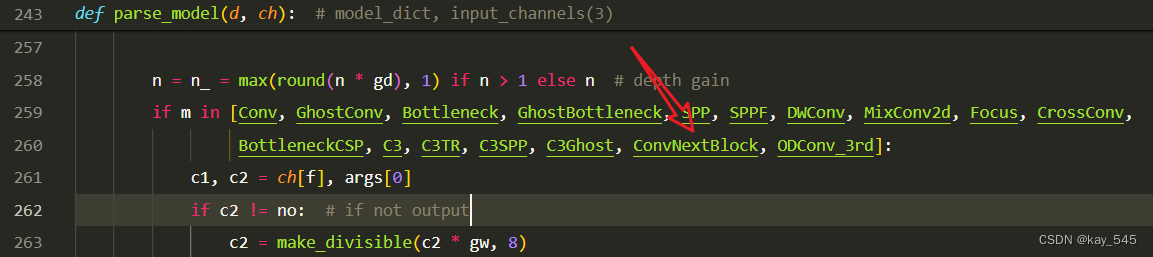
2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_ConvNeXt.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀

3. 完整代码分享
https://pan.baidu.com/s/1KHZBKJtvJHw1NS6IRkCNjA?pwd=rccf提取码: rccf
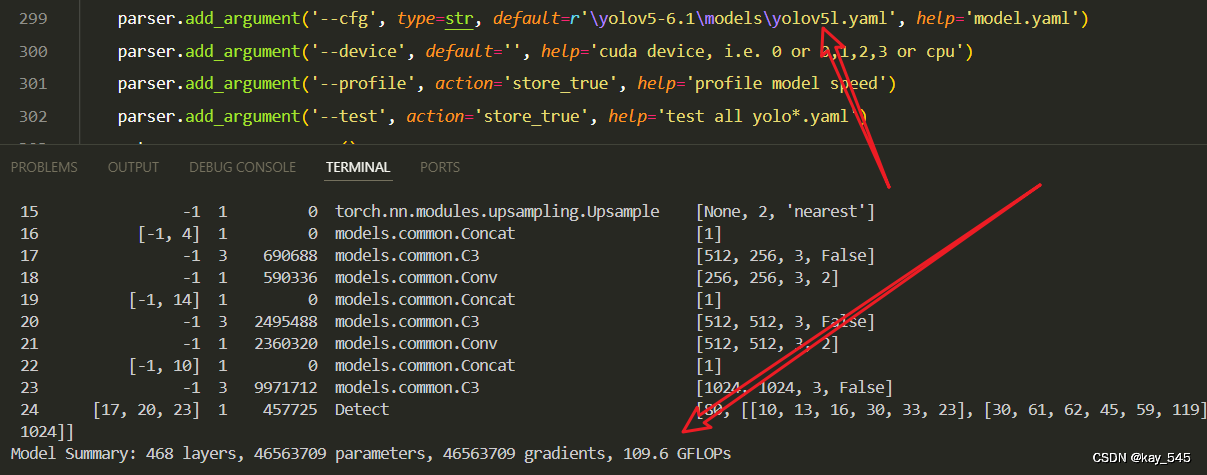
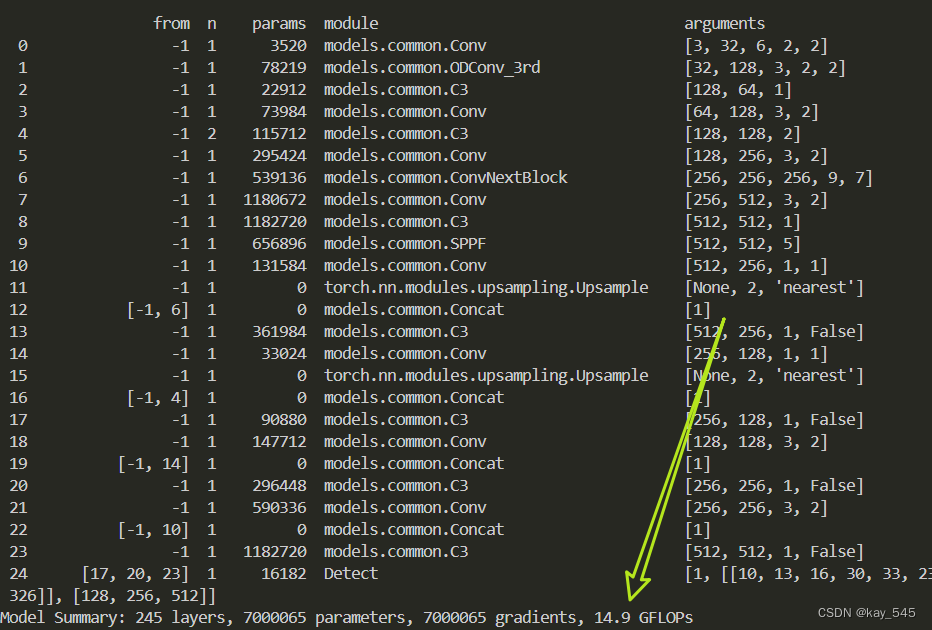
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
改进后的GFLOPs
5. 进阶
融合ODConvd和ConNeXt可能会进一步提升检测的效果。
ODConv:YOLOv5改进 | 卷积模块| 动态卷积模块ODConv【完整代码 + 小白必备】——点击即可跳转
yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 6, 2, 2]], # 0-P1/2
[-1, 1, ODConv_3rd, [128, 3, 2, 2]], # 1-P2/4
[-1, 1, C3, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P3/8
[-1, 2, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P4/16
[-1, 1, ConvNextBlock, [256, 256, 9, 7]],
[-1, 1, Conv, [512, 3, 2]], # 7-P5/32
[-1, 1, C3, [512]],
[-1, 1, SPPF, [512, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 13
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]6. 总结
ConvNeXt 是一种现代化的卷积神经网络架构,其设计融合了传统卷积神经网络(CNN)和 Transformer 模型的优势,主要原理包括使用更大的卷积核以扩展感受野、引入层归一化(Layer Normalization)替代批量归一化(Batch Normalization)以提供更稳定的训练、采用 GELU 激活函数代替 ReLU 提升非线性表达能力、通过逐点卷积进行通道间信息融合、并在不同阶段通过调整特征图的通道数和分辨率提取多尺度特征。结合这些改进,ConvNeXt 能在保持高计算效率的同时显著提升模型性能,特别是在图像分类、目标检测和语义分割等计算机视觉任务中。

















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











