







一.索引
1.1 概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
可以简单了解为文章目录!!存在的意义就是方便加速查询
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助
索引本质上就是引入额外的数据结构,来加快查询的效率的
- 消耗额外的空间 !!
- 虽然有了索引,加快了查询的速度,但是拖慢了增删改的速度!!
1.3 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间
总结就是:
- 对于空间不紧张,对于时间更敏感(空间换时间)
- 查询频繁,增删改不频繁(这其实是大多数情况)
1.4 使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
- 查看索引
show index from 表名;
例如查看学生表已有的索引:

- 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
例如创建班级表中,name 字段的索引
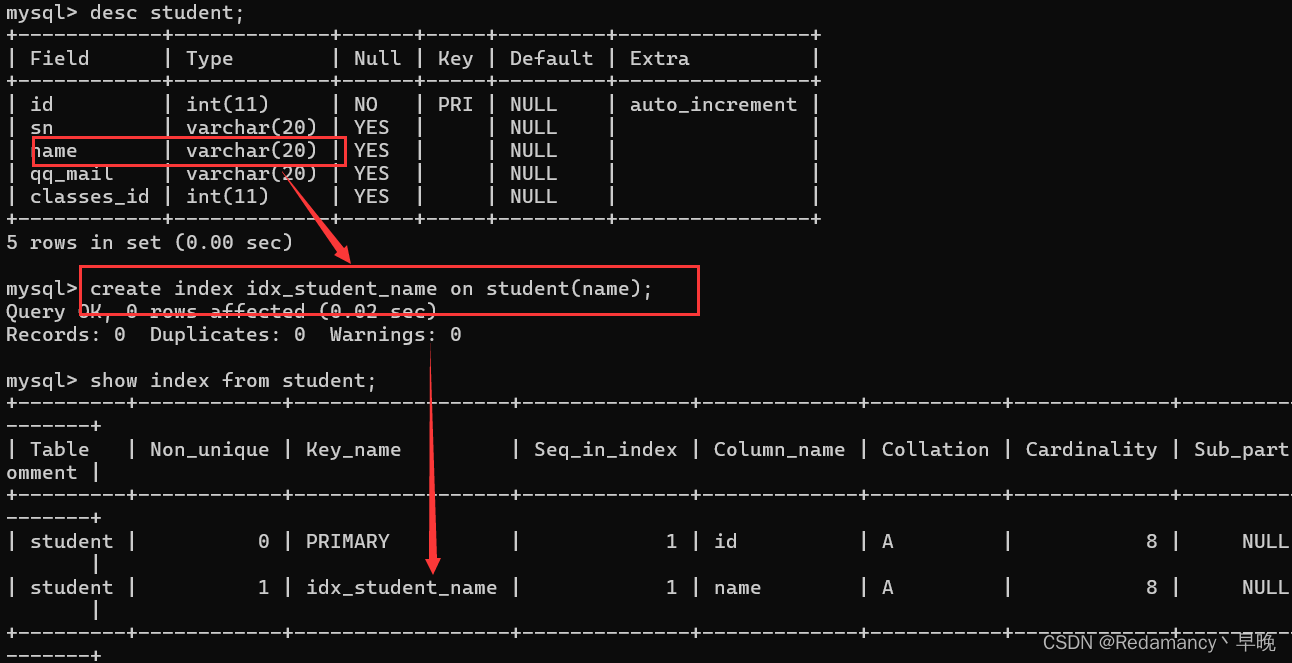
像主键这种,要保证记录不重复,每次插入新纪录,都需要查询一下旧记录,看看新纪录是否已经存在!判定重复!
- 删除索引
drop index 索引名 on 表名;
例如删除班级表中 name 字段的索引
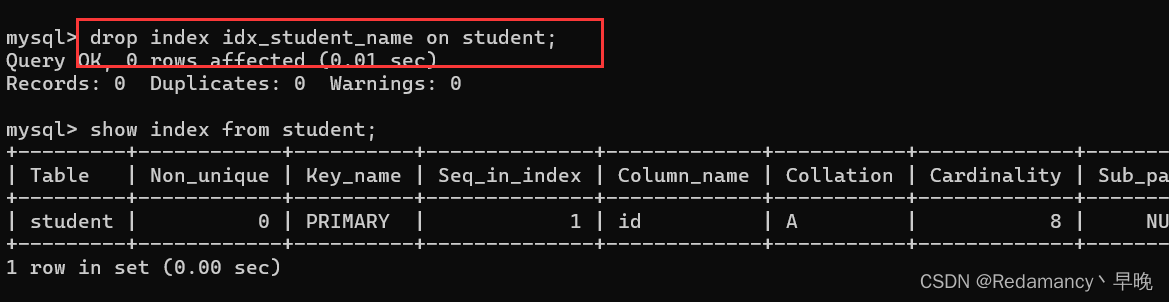
创建索引和删除索引,也是危险操作!!尤其是针对一个已经包含很大数据量的表进行操作的时候!!如果是针对一个大表,创建索引,就会导致大规模磁盘 IO,直接把主机的磁盘 IO 吃满!!主机可能就卡了,无法对线上服务进行响应…
1.5 索引的数据结构
由于我们已知在数据结构里面实现搜索效率高的就二叉搜索树和哈希表,但是这两个也有不足的地方:
-
二叉搜索树(红黑树):高度可能比较高,数据库高度每增加一层,就都要多出磁盘IO操作!!
-
哈希表:查的是快,但是不能支持范围查找和模糊匹配…
然后从此处我们引入了其他的数据结构来实现索引:
核心思路:N 叉搜索树(和二叉搜索树类似,只不过是节点的度多了)
此处介绍的是 B 树:
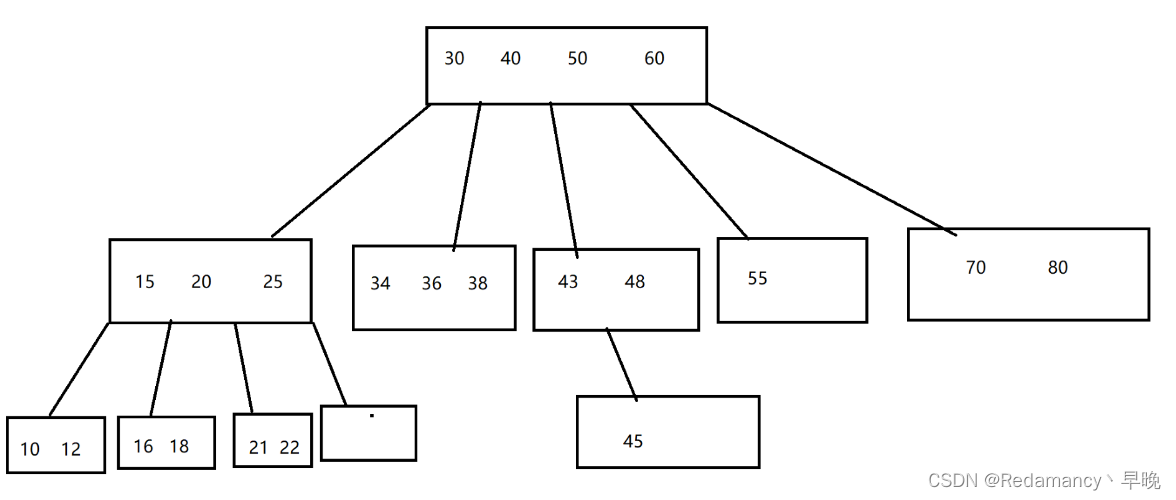
从上面可以看到像这样的树,整体的高度,就大大缩短了!!
二叉搜索树的高度,是以2为底的对数,叉搜索树的高度,是以N为底的对数。
但是在实现数据库的时候一般也不会直接使用B树,而是使用 B树的改进版本,B+树!!
B+树:
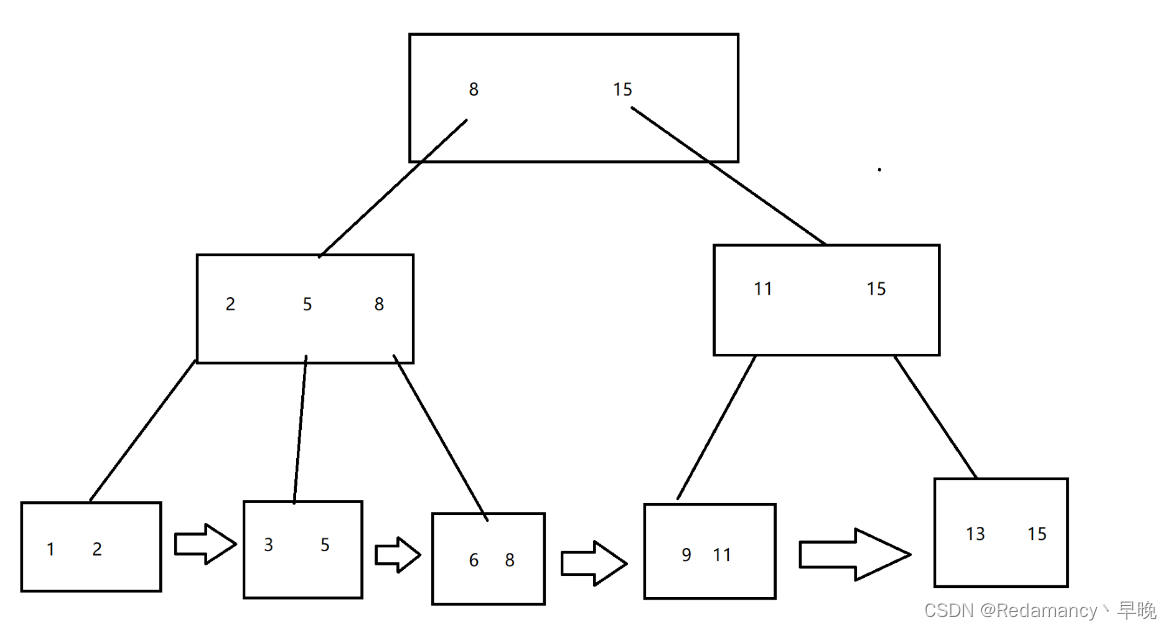
结构特点:
- 每个节点上面存了几个值,最多就有几个子树
- 父节点的元素都存在于子节点中,是子节点上面值的最大值(或者最小值)
- 最下方的叶子节点使用链表的方式相连
B+树 可以说是为了实现数据库索引,量身定做的数据结构
- 查询速度快,类似于二叉搜索树的查询
- 单个节点存储更多的数据,树的高度比较低,比较次数就少了
- 所有的叶子节点,使用链表首尾相连,非常便于范围查找(叶子节点包含了整个数据库的数据全集)
- 每一个数据行,只需要保存在叶子节点上就够了.非叶子节点不必存储真实的数据行,只要存储用来做索引的 id 即可!!此时非叶子节点占用的空间小,就有了在内存中缓存非叶子节点的可能性!如果把非叶子节点都在内存缓存了(哪怕缓存一部分也好)都能够大大降低磁盘 IO!!
此处面试官问到你谈谈对于数据库索引的理解就可以从上面三个方面来回答:
- 理解数据库的索引为啥使用B+树,而不是红黑树/哈希表.
- 理解B+树的结构特点
- 理解B+树的优势
二. 事务
2.1 什么是事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败
实际操作数据库的过程中,有些操作,希望是一个整体
例如转账操作:
张三给李四转 300,自己账户扣 300
李四接收 300,自己账户加 300
如果此时无论是步骤一出了问题还是步骤二出了问题,都会导致双方账户转账对不上,因此,要么让他们一起成功,要么一起失败。
事务就是这两个操作希望能够一气呵成,当做一个整体来进行!!如果执行中间过程中,出现异常,就需要把前面已经进行过的操作进行回退/恢复恢复成好像完全没操作过的样子
2.2 事务回滚
事务是两个要么一起执行,要么一个都不执行:
注意!此处的 “一个都不执行” 不是真的没执行,而是通过恢复的方式,把之前操作造成的影响给还原了,这个还原的过程,称为 “回滚” (rollback)
数据库的事务回滚,是如何做到的?
数据库里面的每个操作,在内部都有记录,尤其是事务内部的操作如果事务中间出现问题,就可以根据之前的记录,来进行恢复了
2.3 事务使用
- 开启事务:start transaction;
- 执行多条SQL语句
- 回滚或提交:rollback/commit;
说明:rollback 即是全部失败,commit 即是全部成功。
2.4 事务的基本特性
- 原子性:最小的不可分割的单位(最核心的特性,事务诞生的初衷)
- 一致性:一致数据是对的,没有纰漏
- 持久性:(存储在磁盘上)事务进行的操作都会写磁盘,只要事务执行成功,造成的修改,就是持久化保存的了,哪怕重启主机,这样的改变也仍然存在
- 隔离性:描述多个事务并发执行的时候,所产生的情况
此处讲讲并发事务执行
数据库中的事务,彼此之间,也是可能相互影响的,事务的隔离性也就是在描述事务执行过程中,影响情况能接受到啥程度
由于一个数据库服务器可以给多个客户端提供服务,这个时候就可能会涉及到说多个客户端同时尝试操作同一个表就可能产生这种并发事务的情况
例如疫情的隔离,有几种级别:
- 定点医院隔离(隔离效果最好!出现交叉感染的概率最小!)
- 指定酒店隔离(成本最高隔离效果比较好,成本比较高)
- 居家隔离 / 在学校隔离(贴上封条)(隔离效果一般,成本比较低)
- 不隔离(没啥隔离效果)
为了避免相互干扰,就引入了"隔离性",通过隔离性来降低上述的影响
为啥要并发执行?目标是为了提高执行效率!!
提高隔离性,带来的问题就是数据更准了,但是效率更低了
为了解决并发执行事务带来的问题,MySQL等数据库引入了"隔离级别",可以让用户自行选择一个适合自己当前业务场景的级别
此处先有个问题就是并发执行事务的时候都还会有哪些问题?
- 脏读问题.(读脏数据)
数据被污染了,不准了
一个事务A,在执行过程中,对数据进行了一系列修改,在提交到数据库之前(完成事务之前),另一个事务B,读取了对应的数据,此时这个 B 读到的数据都是一些临时结果,后续可能马上就被 A 给改了,此时 B 的读取行为就是 “脏读"
如何解决脏读?
给读操作加锁。相当于降低了并发程度,降低了效率,提高了隔离性
- 不可重复读
事务 A 先提交了,事务 B 再读,事务 B 读的过程中,又开启了个事务 A 又进行了修改呢?
事务 A 提交了之后,事务 B 才开始读(读是加锁了)然后在 B 的执行过程中,A 又开启了一次,修改了数据,此时 B 执行中,两次读取操作可能结果就不一致
如何解决不可重复读?
第一是给读操作加锁,第二是读的时候也不修改代码
因此隔离性又提高了,并发性又降低了,数据更准确了,效率更低了
- 幻读
事务B读取过程中,事务A进行了修改,没有直接修改 B 读取的数据,但是影响到了 B 读取的结果集,事务 B 两次读取到的结果集不一样.(幻读相当于是不可重复读的特殊情况)
解决幻读问题,核心思路就是 “串行化”
保证读和写操作都是严格串行执行的.(一个执行完,才能执行另一个)
隔离性最高,并发程度最低,数据的准确性最好,同时速度最慢
2.5 隔离级别
MySQL 里给我们提供了四个隔离级别,供我们自由选择
- read uncommitted(读未提交):并发能力最强,隔离性最弱.
- read committed(读已提交):只能读取提交之后的数据,解决了脏读问题,并发能力下降一些,隔离性增加了一些.
- repeatable read(可重复读):针对读和写都进行限制了,解决了不可重复读问题,并发能力由进一步下降,隔离性进一步增加
- serializable(串行化):严格的串行执行,解决了幻读问题,并发能力最低,隔离性最高
















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











