







无量纲化与预处理的关系
在机器学习算法实践中,我们往往有着不同规格的数据转换到同一规格,或不同分布的数据转换成某个特定分布。的需求。这种需求统称:将数据无量纲化。例如逻辑回归,支持向量机,神经网络,无量纲化的可以加快求解速度,而在距离模型比如K近邻, K—Means聚类中无量钢化可以帮助我们提高模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
预处理就是用来实现无量钢化的方式。
- 特征抽取后,我们就可以获取对应数值型样本数据。然后就可以进行预处理了。
- 方式
1.归一化
2.标准化 - 案例分析
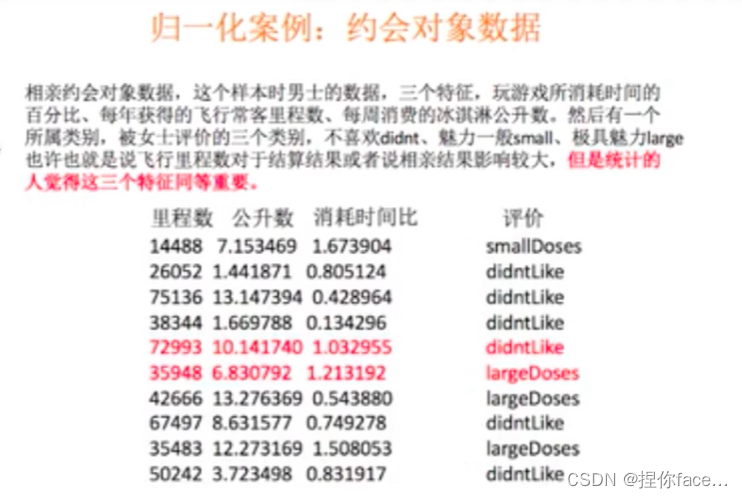
如果认为每一个特征具有同等大小权重都同等重要,则必须进行归一化处理。
可以用knn算法对特征影响进行说明。
归一化的实现

API:from sklearn.preprocessing import MinMaxScaler
参数:feature_range表示缩放范围,通常用(0,1)
作用:使得某一个值不会对·最终结果造成太大影响
from sklearn.preprocessing import MinMaxScaler
mm=MinMaxScaler(feature_range=(0,1))#每个特征要缩放的范围
data=[[90,2,10,40],[60,5,15,45],[73,3,13,45]]
data=mm.fit_transform(data)
print(data)

- 问题:如果数据中存在异常值较多,会对结果造成什么样的影响?
——结合归一化的公式可知,异常值对原始特征的最大值和最小值影响很大。因此也会影响归一化之后的值。这个也是归一化的一个弊端,无法很好的处理异常值。 - 所以在特定场景下的最大值和最小值是变化的,另外最大值和最小值容易受到异常值的影响。所以归一法有一定的局限性,因此引出了一种更好的方法,叫做标准化。
标准化

- 对于归一化来说,如果出现了异常职责会影响特征的最大最小值,那么最终结果受影响会比较大。
- 对于标准化来说,如果出现了异常点,由于具有一定的数据量,少量的异常点对平均值影响不大,从而标准差改变的比较少。
StandardScaler和MinMaxScaler选哪个?
在大多数的机器学习算法中非常敏感。非常敏感。在PC、聚类、逻辑回归。支持向量机,神经网络这些算法中StandardScaler往往是最好的选择。MinMaxScaler在不涉及距离、梯度、协方差计算以及数据需要被压缩到特定区间的时候使用广泛,比如数字图像处理量化像素强度时,都会先使用MinMaxScaler将数据压缩在【0~1】区间中。
- API
- 处理后,每列的所有数据都聚集在均值为0,标准差为一的范围附近。
- 标准化:from sklearn.preprocessing import StandardScaler
- fit_transform():对x进行标准化
- mean_:均值
- var_:方差
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
data=[[90,2,10,40],[60,5,15,45],[73,3,13,45]]
data=ss.fit_transform(data)
print(data)`
















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









