






日常生活中,我们常常需要在一堆数据中找到最优/劣,亦或是最大/小的数据,比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。那么到底该如何才能最高效地实现这一算法呢?
显然,排序取值是不可取的,原因就是当基数过大时,会很复杂。
那么,对于此类算法的最优解就是采用堆来解决。
基本思路如下:
1. 用数据集合中前K个元素来建堆,若是求前k个最大的元素,则建小堆;若是求前k个最小的元素,则建大堆。
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素。将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
如下例题: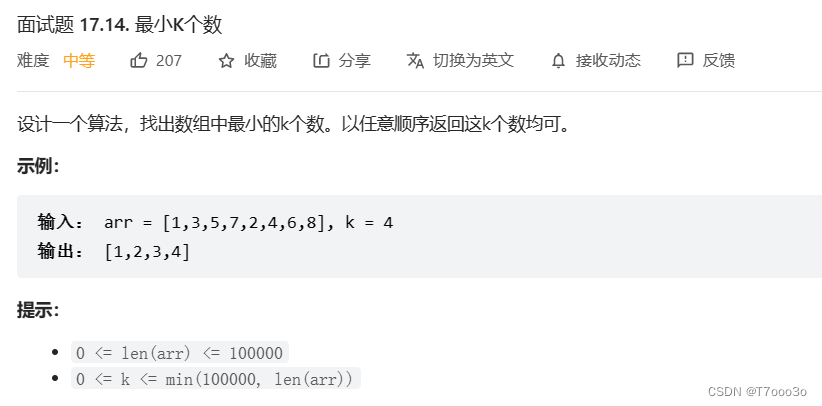
这里直接附上代码:
class Solution {
public int[] smallestK(int[] arr, int k) {
int[] ret = new int[k];
if(k ==0 || arr ==null){
return ret;
}
LargeIntCmp intCmp = new LargeIntCmp();
Queue<Integer> priorityQueue = new PriorityQueue<>(intCmp);
//用数据集合中前K个元素来建堆
for(int i=0;i<k;i++){
priorityQueue.offer(arr[i]);
}
//用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
for(int i=k;i<arr.length;i++){
if(arr[i]<priorityQueue.peek()){
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
//取出前k个元素
for(int i=0;i<k;i++){
ret[i] = priorityQueue.poll();
}
return ret;
}
}
class LargeIntCmp implements Comparator<Integer>{
public int compare(Integer o1,Integer o2){
return o2 - o1;
}
}此处存在一个比较关键的点,就是在构造堆的时候,需要传一个用户自定义的比较器来实现大根堆的底层逻辑,这是因为PriorityQueue的底层是采用的小根堆的构建逻辑。
具体方法就是:由用户自定义的构造器类来实现Comparator接口,并通过该构造器的实例化对象 来 初始化堆(作为堆的构造方法的形参),从而把底层实现成大根堆的构建逻辑。
uu们加油(ง •_•)ง!!!
















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











