








1.500. 键盘行
给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词。键盘如下图所示。
美式键盘 中:
第一行由字符 “qwertyuiop” 组成。
第二行由字符 “asdfghjkl” 组成。
第三行由字符 “zxcvbnm” 组成。
示例 1:
输入:words = [“Hello”,“Alaska”,“Dad”,“Peace”]
输出:[“Alaska”,“Dad”]
示例 2:
输入:words = [“omk”]
输出:[]
示例 3:
输入:words = [“adsdf”,“sfd”]
输出:[“adsdf”,“sfd”]
提示:
1 <= words.length <= 20
1 <= words[i].length <= 100
words[i] 由英文字母(小写和大写字母)组成
这道题没什么好说的,将三行键盘上的大小写字母都标记上对应行号模拟即可。
class Solution {
unordered_map<char,int> map;
public:
vector<string> findWords(vector<string>& words) {
string s1="qwertyuiop";
string s2="asdfghjkl";
string s3="zxcvbnm";
for(auto i:s1){
map[i]=1;
map[i+'A'-'a']=1;
}
for(auto i:s2){
map[i]=2;
map[i+'A'-'a']=2;
}
for(auto i:s3){
map[i]=3;
map[i+'A'-'a']=3;
}
vector<string> ans;
for(int i=0;i<words.size();i++){
int number=map[words[i][0]];
bool flag=true;
for(int j=1;j<words[i].size();j++){
if(map[words[i][j]]!=number){
flag=false;
break;
}
}
if(flag){
ans.push_back(words[i]);
}
}
return ans;
}
};
2.1160. 拼写单词
给你一份『词汇表』(字符串数组) words 和一张『字母表』(字符串) chars。
假如你可以用 chars 中的『字母』(字符)拼写出 words 中的某个『单词』(字符串),那么我们就认为你掌握了这个单词。
注意:每次拼写(指拼写词汇表中的一个单词)时,chars 中的每个字母都只能用一次。
返回词汇表 words 中你掌握的所有单词的 长度之和。
示例 1:
输入:words = [“cat”,“bt”,“hat”,“tree”], chars = “atach”
输出:6
解释:
可以形成字符串 “cat” 和 “hat”,所以答案是 3 + 3 = 6。
示例 2:
输入:words = [“hello”,“world”,“leetcode”], chars = “welldonehoneyr”
输出:10
解释:
可以形成字符串 “hello” 和 “world”,所以答案是 5 + 5 = 10。
提示:
1 <= words.length <= 1000
1 <= words[i].length, chars.length <= 100
所有字符串中都仅包含小写英文字母
和上一题一样的思路,先统计chars中的字母频率,不同的是这里需要再创建一个临时的map用于每个字符串的比较。
class Solution {
public:
int countCharacters(vector<string>& words, string chars) {
unordered_map<char,int> map;
for(auto i:chars){
map[i]++;
}
int ans=0;
for(int i=0;i<words.size();i++){
auto tmp=map;
bool flag=true;
for(int j=0;j<words[i].size();j++){
if(--tmp[words[i][j]]<0){
flag=false;
break;
}
}
if(flag){
ans+=words[i].size();
}
}
return ans;
}
};
3.1047. 删除字符串中的所有相邻重复项
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:“abbaca”
输出:“ca”
解释:
例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
提示:
1 <= S.length <= 20000
S 仅由小写英文字母组成。
很经典的括号匹配类型的题,这里我么可以借助一个栈来做,具体做法就是我么先将当前遍历到的字符先与栈顶元素比较,如果二者相等就将栈顶元素删去并且当前元素不入栈,否则就入栈。这样遍历字符串一次就可以解决问题。不过这里我并没有用栈,因为无论用不用栈都需要对原数组进行操作,最后还需要返回一个string,所以这里就直接利用string来当栈用了。
class Solution {
public:
string removeDuplicates(string s) {
string stk;
for(int i=0;i<s.size();i++){
if(!stk.empty()&&stk.back()==s[i]){
stk.pop_back();
}else stk.push_back(s[i]);
}
return stk;
}
};
4.1935. 可以输入的最大单词数
键盘出现了一些故障,有些字母键无法正常工作。而键盘上所有其他键都能够正常工作。
给你一个由若干单词组成的字符串 text ,单词间由单个空格组成(不含前导和尾随空格);另有一个字符串 brokenLetters ,由所有已损坏的不同字母键组成,返回你可以使用此键盘完全输入的 text 中单词的数目。
示例 1:
输入:text = “hello world”, brokenLetters = “ad”
输出:1
解释:无法输入 “world” ,因为字母键 ‘d’ 已损坏。
示例 2:
输入:text = “leet code”, brokenLetters = “lt”
输出:1
解释:无法输入 “leet” ,因为字母键 ‘l’ 和 ‘t’ 已损坏。
示例 3:
输入:text = “leet code”, brokenLetters = “e”
输出:0
解释:无法输入任何单词,因为字母键 ‘e’ 已损坏。
提示:
1 <= text.length <= 104
0 <= brokenLetters.length <= 26
text 由若干用单个空格分隔的单词组成,且不含任何前导和尾随空格
每个单词仅由小写英文字母组成
brokenLetters 由 互不相同 的小写英文字母组成
仍然是跟前两题思路相似的题目,需要注意的是由于最后一个单词没有空格需要额外判断,这里不再过多赘述了。
class Solution {
public:
int canBeTypedWords(string text, string brokenLetters) {
int broken[128];
memset(broken,0,sizeof(broken));
for(auto i:brokenLetters){
broken[i]=1;
}
int ans=0;
bool flag=true;
for(int i=0;i<text.size();i++){
if(text[i]==' '){
if(!flag){
flag=true;
}else {
ans++;
}
}else {
if(flag){
if(broken[text[i]]){
flag=false;
}
}
}
}
if(flag){
ans++;
}
return ans;
}
};
5.591. 标签验证器
给定一个表示代码片段的字符串,你需要实现一个验证器来解析这段代码,并返回它是否合法。合法的代码片段需要遵守以下的所有规则:
1.代码必须被合法的闭合标签包围。否则,代码是无效的。
2.闭合标签(不一定合法)要严格符合格式:<TAG_NAME>TAG_CONTENT</TAG_NAME>。其中,<TAG_NAME>是起始标签,</TAG_NAME>是结束标签。起始和结束标签中的 TAG_NAME 应当相同。当且仅当 TAG_NAME 和 TAG_CONTENT 都是合法的,闭合标签才是合法的。
3.合法的 TAG_NAME 仅含有大写字母,长度在范围 [1,9] 之间。否则,该 TAG_NAME 是不合法的。
4.合法的 TAG_CONTENT 可以包含其他合法的闭合标签,cdata (请参考规则7)和任意字符(注意参考规则1)除了不匹配的<、不匹配的起始和结束标签、不匹配的或带有不合法 TAG_NAME 的闭合标签。否则,TAG_CONTENT 是不合法的。
5.一个起始标签,如果没有具有相同 TAG_NAME 的结束标签与之匹配,是不合法的。反之亦然。不过,你也需要考虑标签嵌套的问题。
6.一个<,如果你找不到一个后续的>与之匹配,是不合法的。并且当你找到一个<或</时,所有直到下一个>的前的字符,都应当被解析为 TAG_NAME(不一定合法)。
7.cdata 有如下格式:<![CDATA[CDATA_CONTENT]]>。CDATA_CONTENT 的范围被定义成 <![CDATA[ 和后续的第一个 ]]>之间的字符。
8.CDATA_CONTENT 可以包含任意字符。cdata 的功能是阻止验证器解析CDATA_CONTENT,所以即使其中有一些字符可以被解析为标签(无论合法还是不合法),也应该将它们视为常规字符。
这道题是一道相当麻烦的题目,规则多也就意味着我们要考虑的状况很多,先看代码:
class Solution {
stack<string> stk;
bool flagTag=false;
bool validTag(const string & str,bool isend){ // 1))
if(str.size()<1||str.size()>9){
return false;
}
for(int i=0;i<str.size();++i){
if(str[i]<'A'||str[i]>'Z'){
return false;
}
}
if(isend){
if(stk.empty()||stk.top()!=str){
return false;
}
stk.pop();
}else {
flagTag=true;
stk.push(str);
}
return true;
}
public:
bool isValid(string code) {
int n=code.size();
if(code[0]!='<'||code[n-1]!='>'){
return false;
}
for(int i=0;i<n;++i){
if(stk.empty()&&flagTag){
return false;
}
if(code[i]=='<'){
int index=0;
//<![CDATA[CDATA_CONTENT]]>
if(!stk.empty()&&code[i+1]=='!'){ // 3))
index=code.find("[CDATA[",i+2);
if(index==-1||index!=i+2){
return false;
}
index=code.find("]]>",i+1);
if(index==-1){
return false;
}
index+=2;
}
else {
bool isend=false; // 2))
//</DIV>
if(code[i+1]=='/'){
++i;
isend=true;
}
//i -> D
index=code.find('>',i+1);
if(index==-1||!validTag(code.substr(i+1,index-i-1),isend)){
return false;
}
}
i=index;
}
}
return stk.empty()&&flagTag;
}
};
其实我是很讨厌做这样匹配类型的题的,因为要考虑的因素实在是太多了,就比如这道题我也是错了很多次的。比如开头和末尾的标签重复,例如这个示例: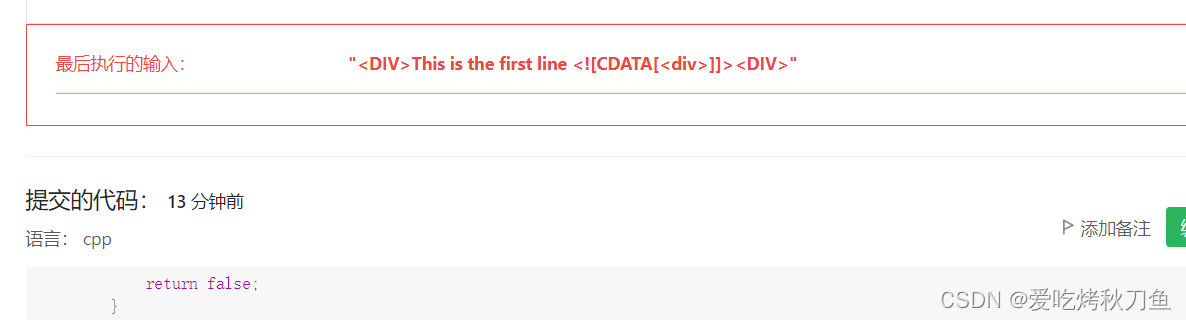
于是想到了在判断标签的过程中加入去重的步骤,听上去是不是很合理,但是这个示例又告诉了我我太天真了:
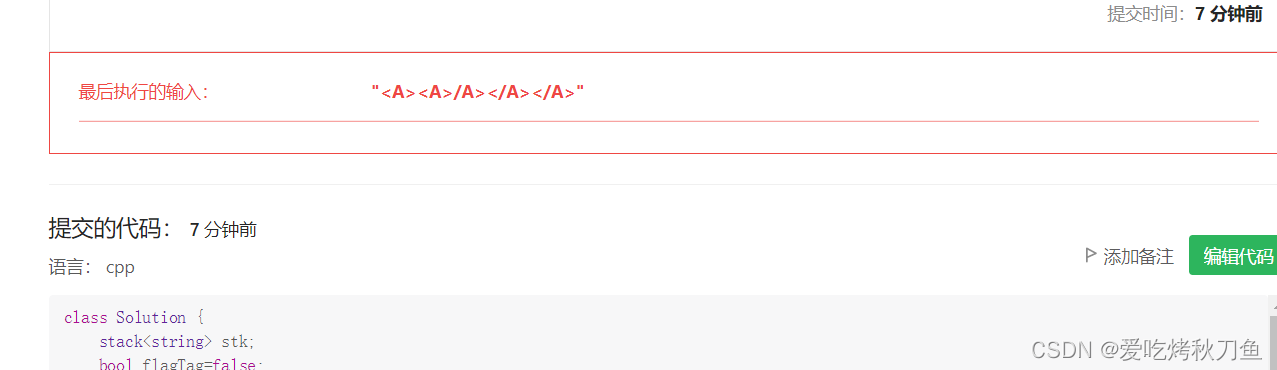
也就是说中间的内容也可能存在重复的标签,(并且观察代码会发现,之前我已经考虑到了这种情况,但是之后却把他忘了!)那么这样在检查标签过程重进行去重就不可行了。于是想到了在最后判断栈是否为空,也就是我们是否把所有的标签都匹配到了。但是问题又来了,如果没有标签怎么办?于是又引入了判断是否找到过标签也就是把flagTag设置成了全局变量。做这种题要考虑的东西实在是太多了,一不注意就会 出错。。。。。。
下面来解析一下代码
1):这一步是为了让头尾标签匹配,isend也就是是否是尾标签的标志,如果是尾标签就要与栈顶匹配并且删除栈顶。如果不是就说明他是一个新的头标签,加入到栈中。
2):这一步是对标签进行判断,也就是匹配标签的过程。很容易理解就不再解释了。
3):这一步就是对中间的<![CDATA[CDATA_CONTENT]]>这一部分进行判断是否合法,首先我们要找到“ [CDATA[”,来说明我们要对他进行匹配,如果找不到又含有"<!"就可以直接返回false,然后跳过中间内容查找“ ]]> ”,如果找不到也说明这段内容是不合法的形式返回false。
具体到为什么要设置index和让i=index都是为了进行加速,跳过“<”和“>”中间的内容,并且利用index和i的对应关系能够更简单的进行匹配操作,这种对应关系通过读代码会很容易理解这里就不再赘述了。
那么其实看完代码并且理解了过程之后,我们会发现这道题的难点主要是在于对“<”和“>”匹配问题,中间的内容实质上是不需要我们进行处理的,也因此在代码中并不会看到任何对其进行操作的过程,也算是简化了一部分操作。















 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









