






用python下载我喜欢的一本小说《散落星河的记忆》
下载小说首先引入一些所需要的第三方库,requests库用来访问网页源代码,os是与操作系统进行交互功能,用于寻找文件路径,pool是进行多线程操作,加快程序的运行速度,re是正则表达式,用于提取自己想要的内容
import requests
import os
from multiprocessing.dummy import Pool
import re建立一个获取网页源代码的函数
def get_source(url):
html = requests.get(url).content.decode()
return html这是小说网页的源代码,里面有小说每个章节的网址链接

下来用正则表达式从上面获取到的网页源代码中获取每个章节的网址链接,并保存在一个列表中
def get_url(html):
html_lists=[]
html_list = re.findall('href="(https://www.zhenhunxiaoshuo.com/121.*?)">', html, re.S)
for html1 in html_list:
html_lists.append(html1)
return html_lists再用正则表达式从每个章节网址的源代码中获取小说章节目录和正文
def get_article(html1):
chapter_name = re.search('<h1 class="article-title">(第.*?)</h1>', html1, re.S).group(1)
article_=re.search('<article class="article-content"><p>(.*?)</article>',html1,re.S).group(1)
article_=article_.replace('<p>','').replace('</p>','')
return chapter_name,article_建立并保存小说文件的函数(分章节保存)
def save(chapter,article):
os.makedirs('散落星河的记忆',exist_ok=True)
with open(os.path.join('散落星河的记忆',chapter+'.txt'),'a',encoding='UTF-8') as f:
f.write(article)利用上面的函数构建一个获取小说章节源代码并保存章节名称和正文的函数
def toc_article(url):
html1=get_source(url)
chapter,article=get_article(html1)
save(chapter,article)利用多线程去爬取这本小说,提高爬取效率
import requests
import os
from multiprocessing.dummy import Pool
import re
start_url='https://www.zhenhunxiaoshuo.com/sanluoxinghedejiyi/'
def get_source(url):
html = requests.get(url).content.decode()
return html
def get_url(html):
html_lists=[]
html_list = re.findall('href="(https://www.zhenhunxiaoshuo.com/121.*?)">', html, re.S)
for html1 in html_list:
html_lists.append(html1)
return html_lists
def get_article(html1):
chapter_name = re.search('<h1 class="article-title">(第.*?)</h1>', html1, re.S).group(1)
article_=re.search('<article class="article-content"><p>(.*?)</article>',html1,re.S).group(1)
article_=article_.replace('<p>','').replace('</p>','')
return chapter_name,article_
def save(chapter,article):
os.makedirs('散落星河的记忆',exist_ok=True)
with open(os.path.join('散落星河的记忆',chapter+'.txt'),'a',encoding='UTF-8') as f:
f.write(article)
def toc_article(url):
html1=get_source(url)
chapter,article=get_article(html1)
save(chapter,article)
if __name__ =='__main__':
novel_html=get_source(start_url)
list=get_url(novel_html)
pool=Pool(45)
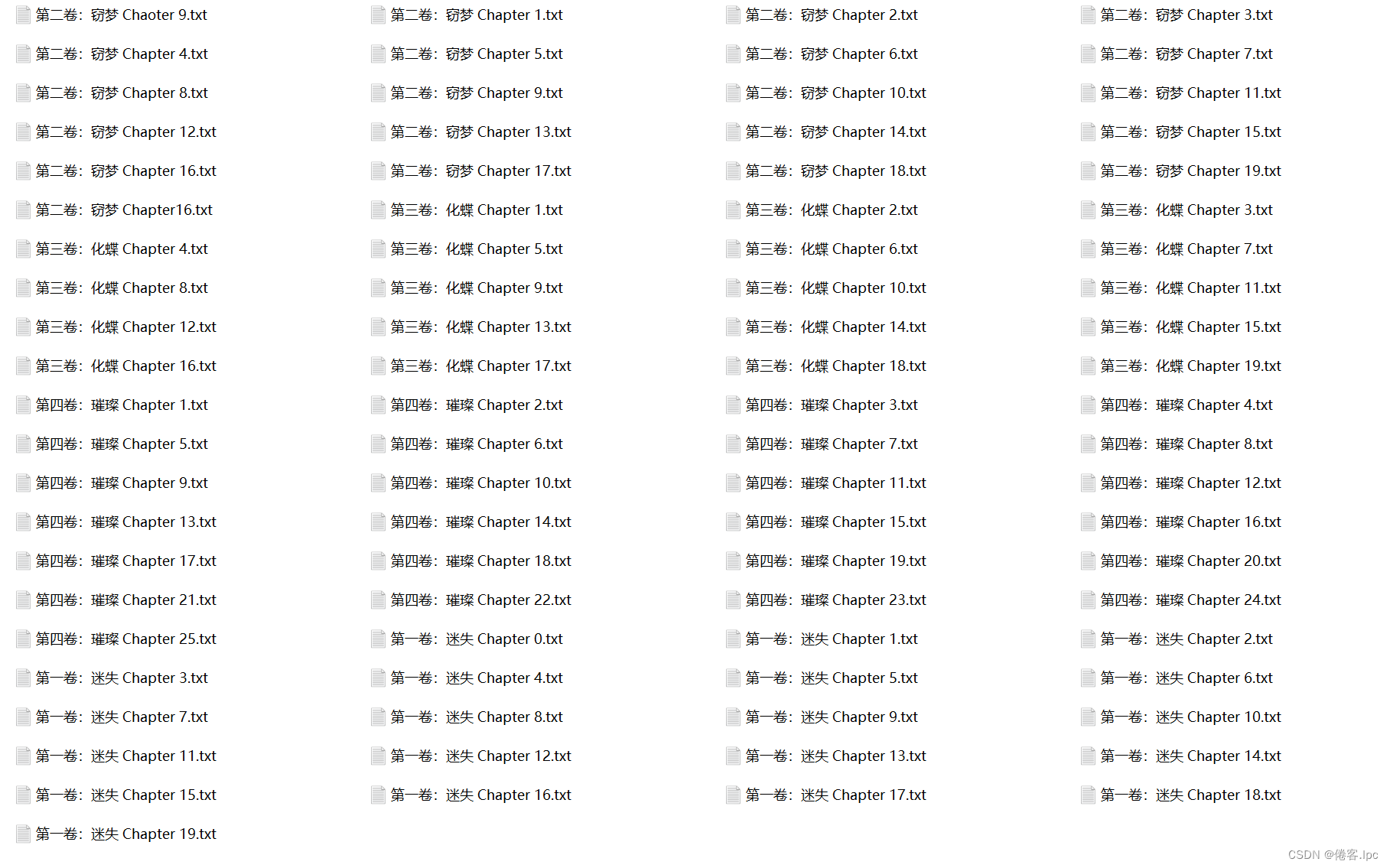
pool.map(toc_article,list)运行代码后,会自动建立一个文件夹,将小说每个章节以txt的文件类型分别保存在文件夹内。















 3929
3929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











