










InputFormat
Inputformat的介绍

官方英文文档:大致的意思是InputFormat是MapReduce框架用于处理输入的job
1.它用来验证job的输入规范
2.将输入文件切开,每个被切开的文件被分配到单独的Mapper中
3.提供RecordReader(抽象方法),用来收集Mapper的输入数据,说人话就是怎么读取数据就由这个RecordReader方法来提供的
4.FileInputFormat是最常的子类等等
1. InputFormat的继承树
查看InputFormat类
查看父子类关系(ctrl+h)
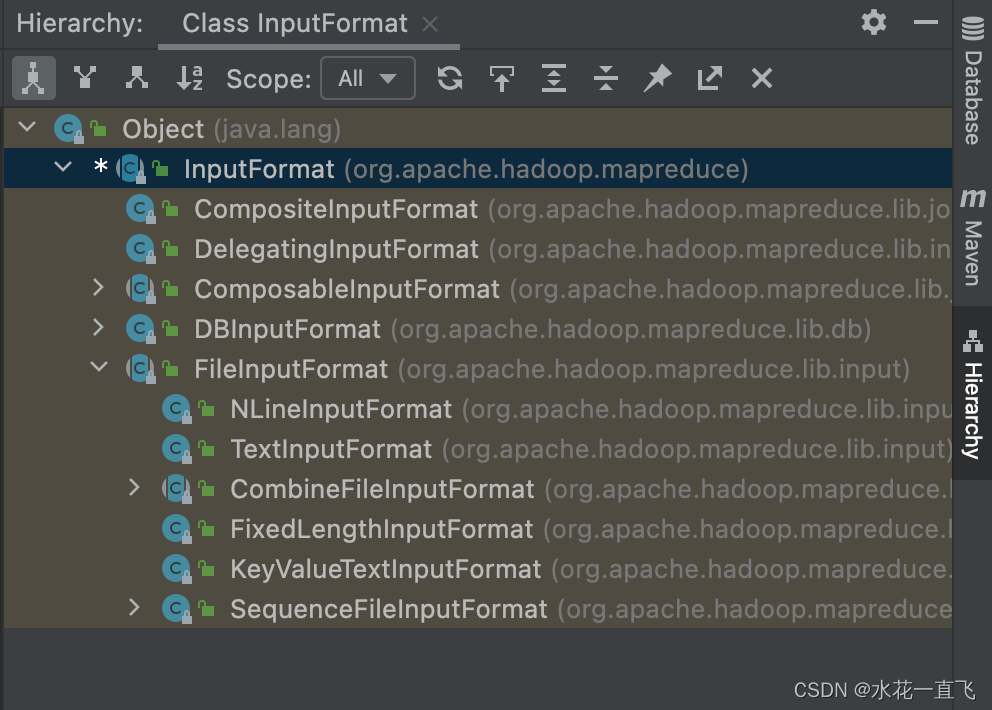
在这里我们主要看的是InputFormat和FileInputFormat和TextInputFormat,先从InputFormat开始看。
Alt+7查看类中的所有方法

1.1 InputFormat源码:
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
public abstract RecordReader<K,V> createRecordReader(InputSplit
split,TaskAttemptContext context) throws IOException, InterruptedException;
}
InputFormat类是抽象类,getSplits和createRecordReader都被声明成抽象方法
getSplits:用来生成切片信息
createRecordReader:用来创建RecordReader对象。RecordReader是用来读取数据的。
1.2 FileInputFormat源码:

官方英文文档
FileInputFormat类是抽象类继承InputFormat重写了它的getSplits的抽象方法:

1.3 TextInputFormat源码

TextInputFormat作为FileInputFormat默认使用的InputFormat,它重写了createRecordReader,在createRecordReader方法内返回了一个LineRecordReader对象。LineRecordReader是真正用来读取数据的类,我们走进LineRecordReader。
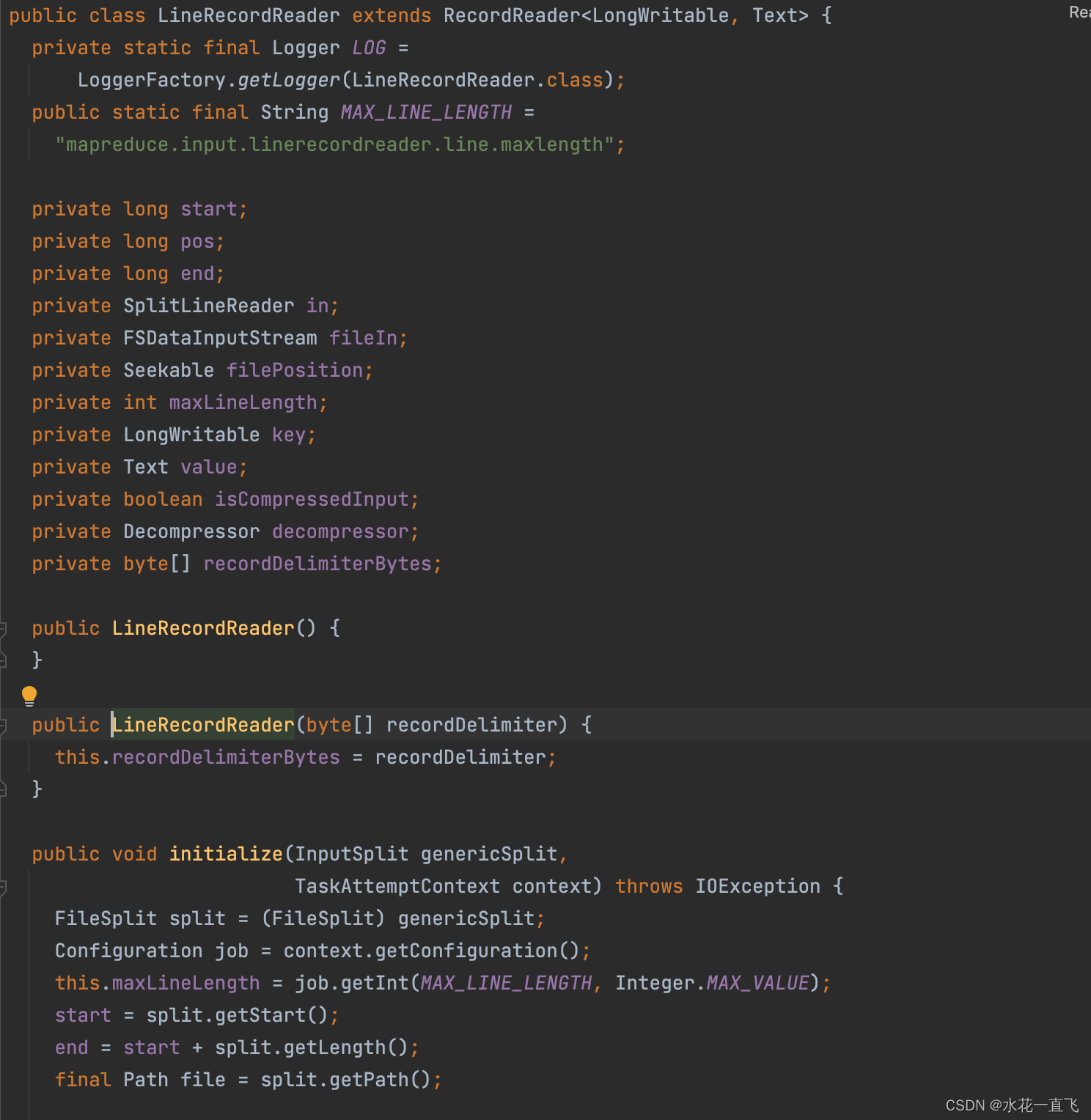
LineRecordReader继承自RecordReader,RecordReader是抽象类


具体代码细节在:
link切片源码有详细说明,本篇主要是讲述InputFormat的目录结构
XMind图后面补
















 3834
3834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











