









1 本地提交
运行Job处打断点

F7进入waitForCompletion方法

JobState有DEFINE和RUNNING两个枚举类型(ctrl+左键进入)

走DEFINE,F8走到submit方法F7进入

在submit方法中再次确认Job状态,设置使用新的API为了将旧的API替换为新的API(兼容性)
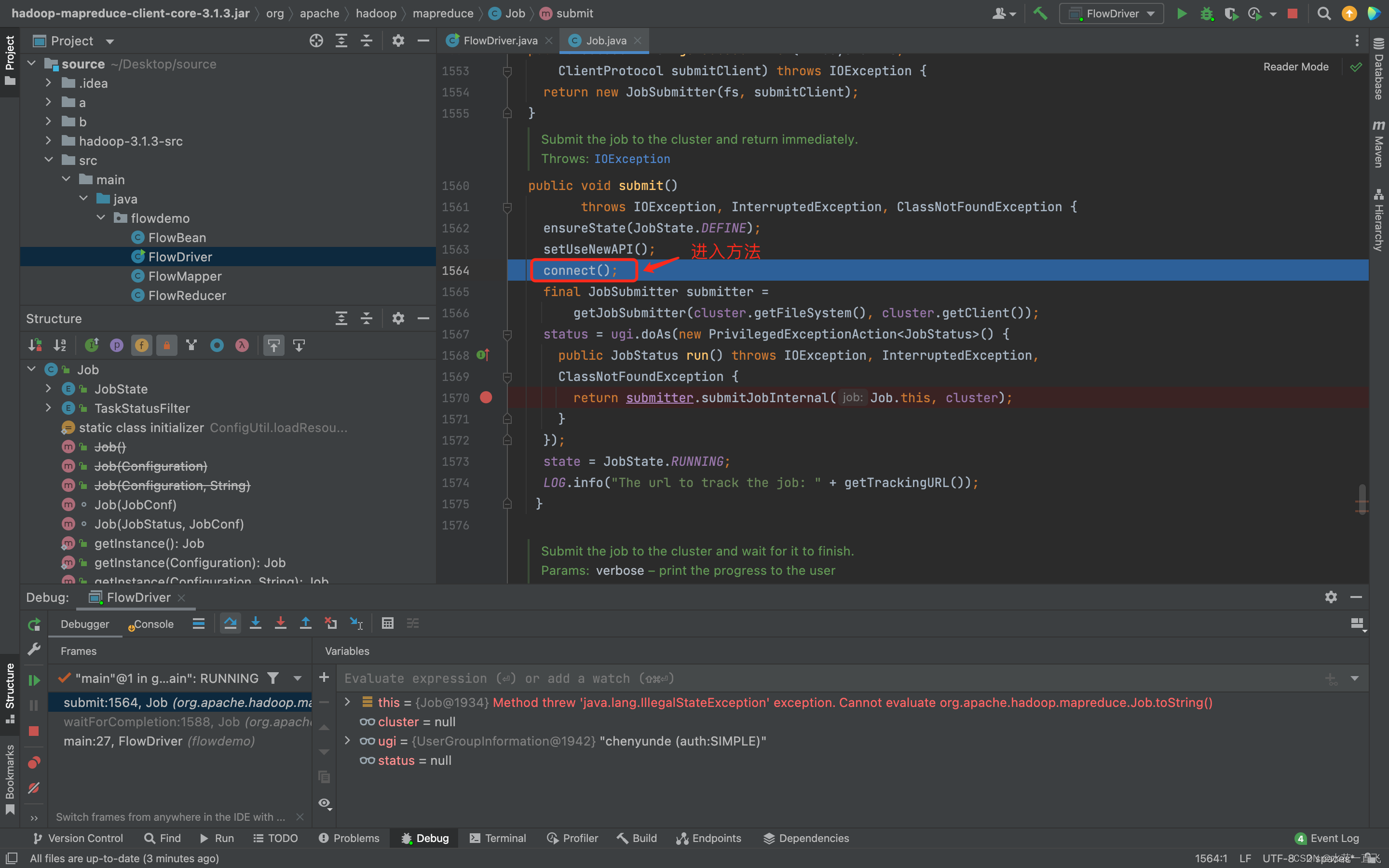
connect是建立连接的方法

查看连接集群的方法

集群为空
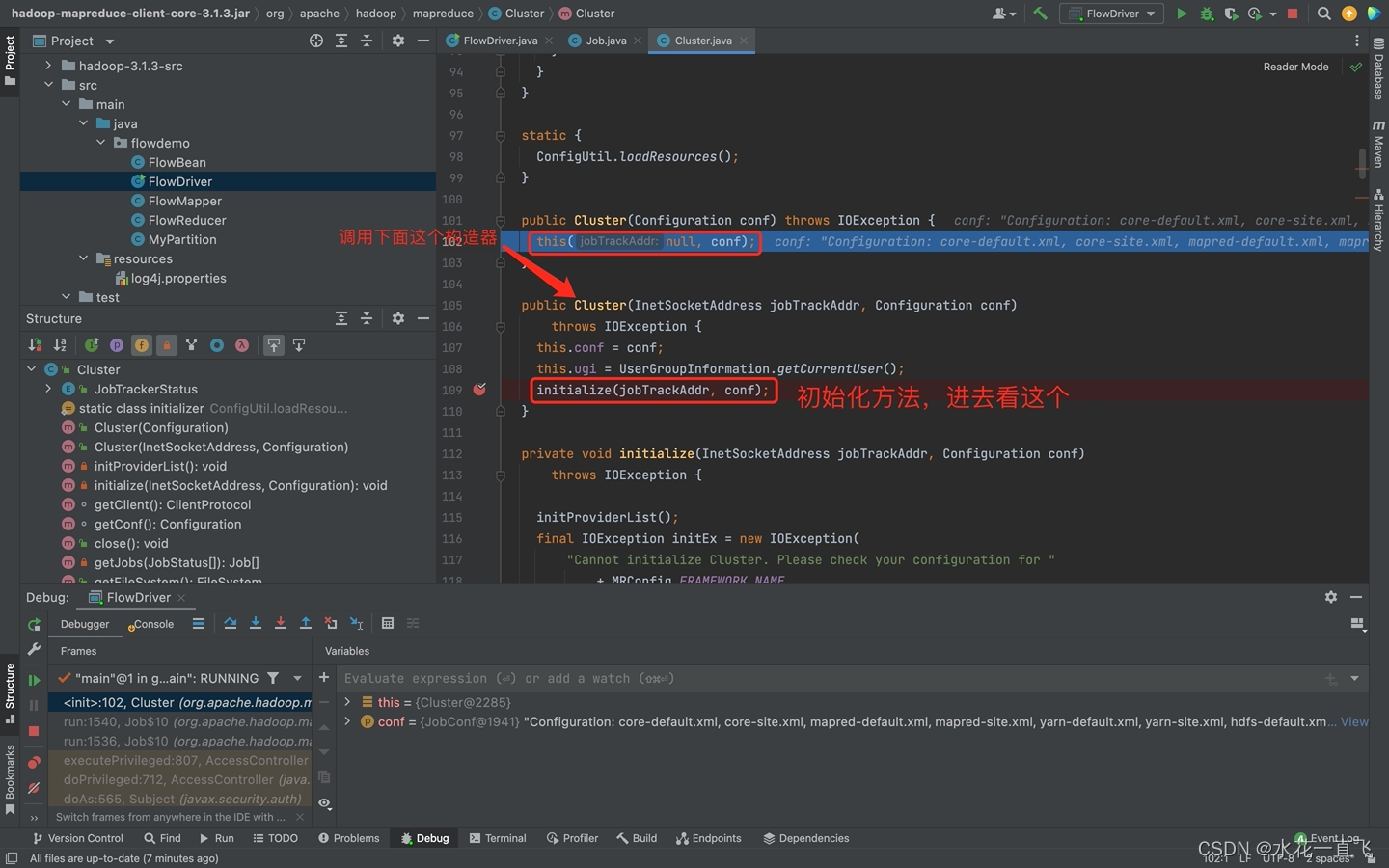
//判断是本地yarn还是远程
//本地会创建LocalJobRunner对象
//远程(集群)会创建YarnRunner对象
initialize(jobTrackAddr, conf);
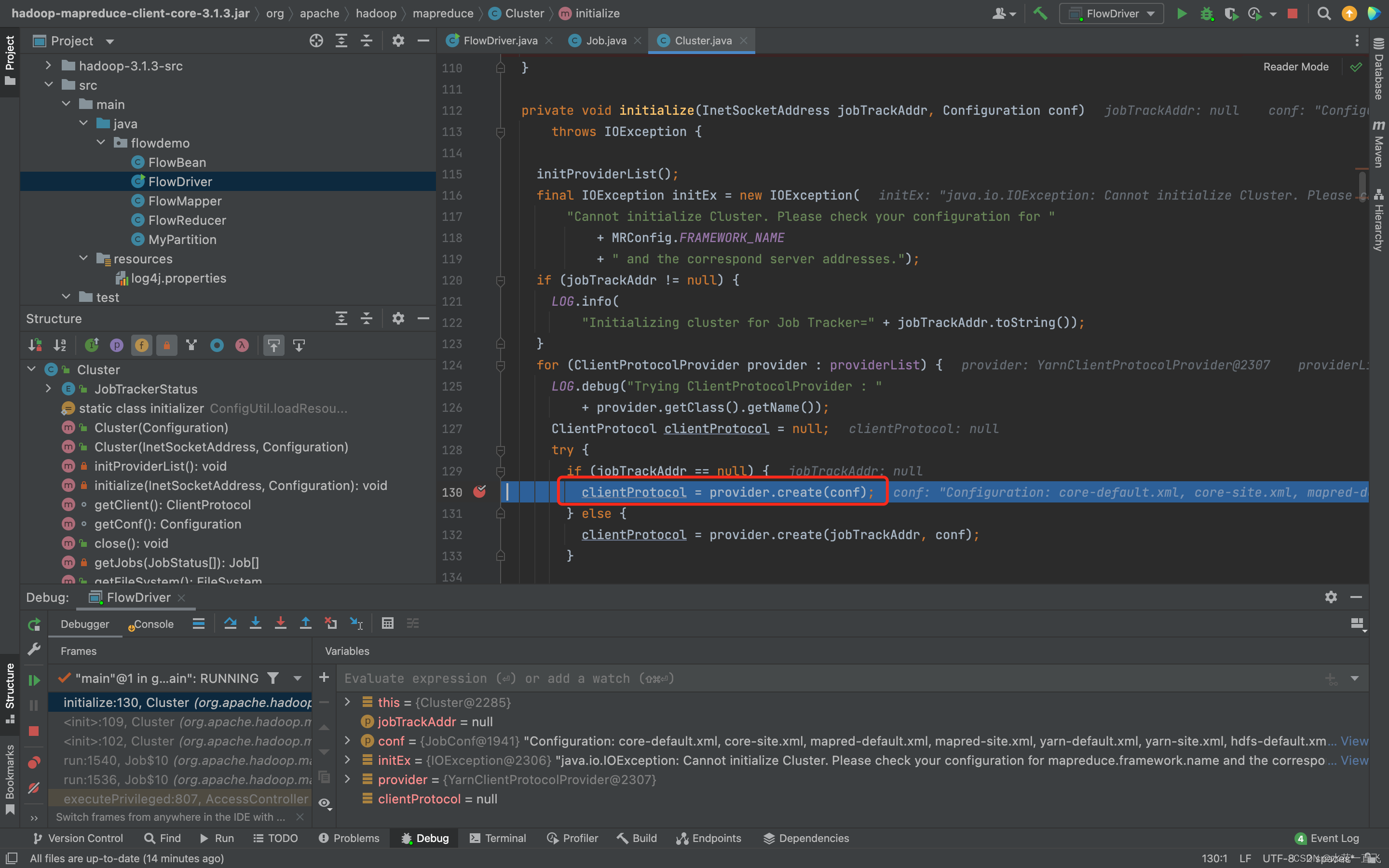
其他方法不看,直接看这个创建Job对象的方法
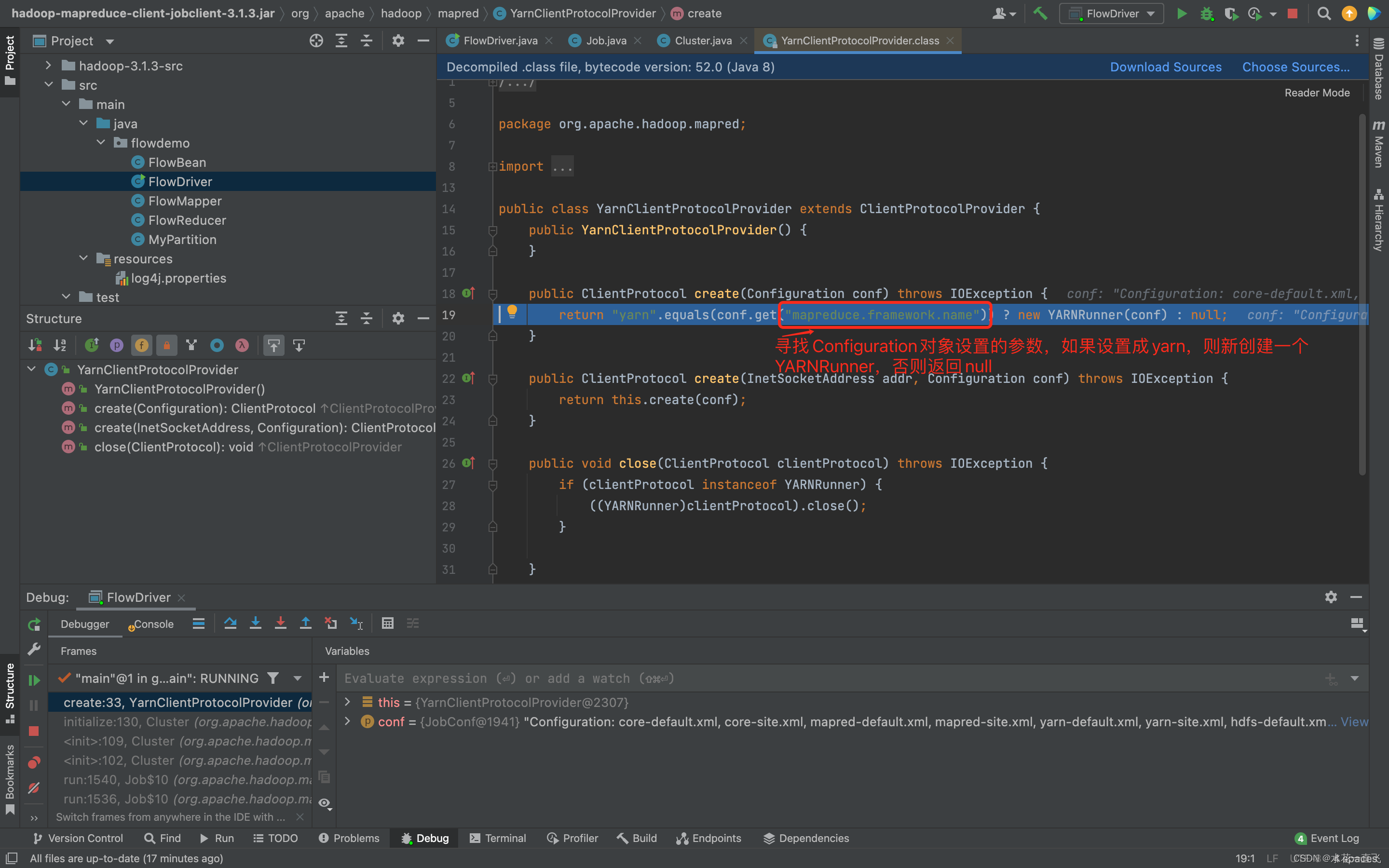
这里Configuration对象.get的方法就是我们在Driver中set配置的参数
如果这里在Driver设置了conf.set(“map reduce.framework.name”,“yarn”)则返回的是集群模式
看完这个方法F8出来

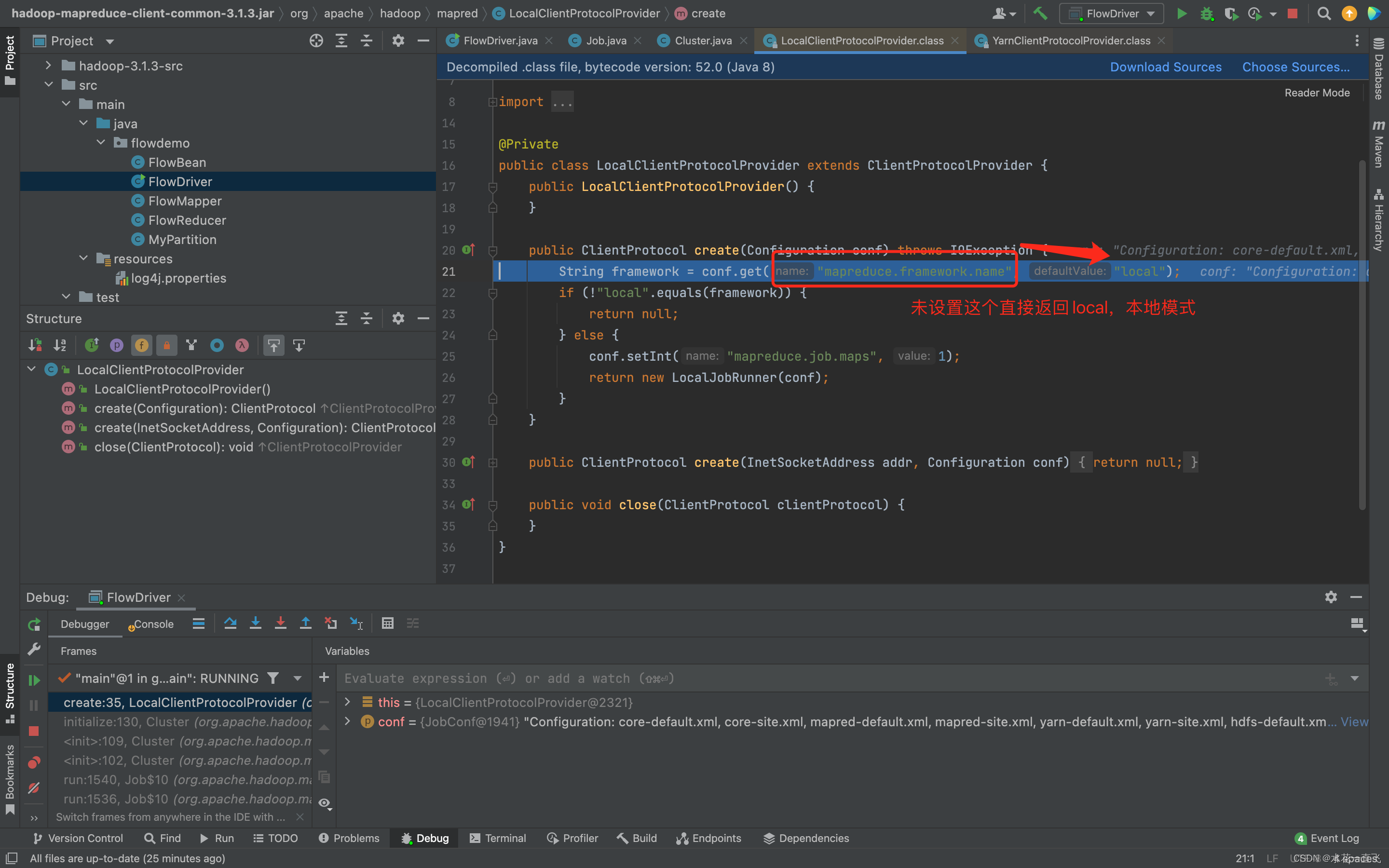
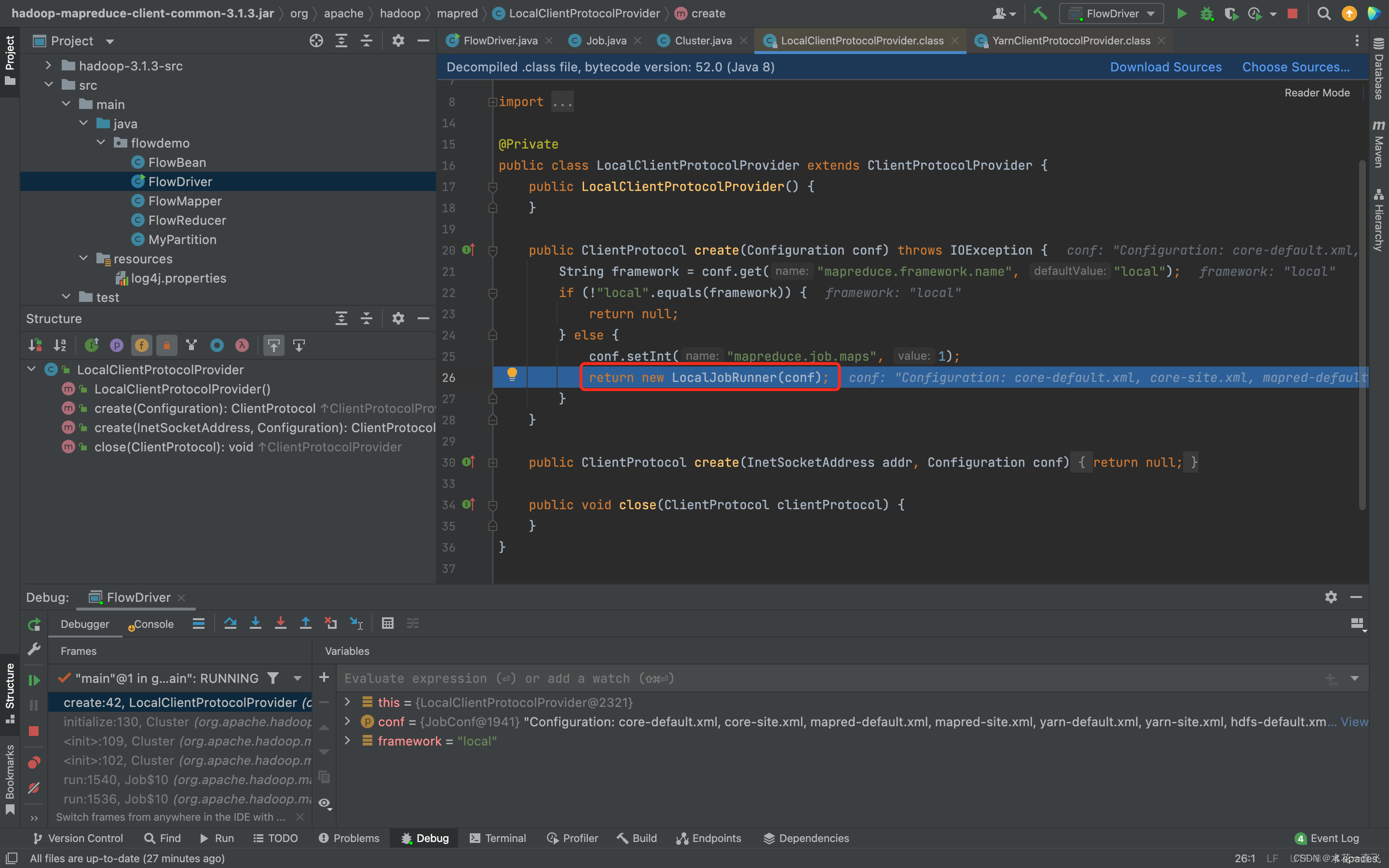
Local本地模式返回的LocalJobRunner
ClientProtocol clientProtocol客户端协议则指向new出来的LocalJobRunner对象
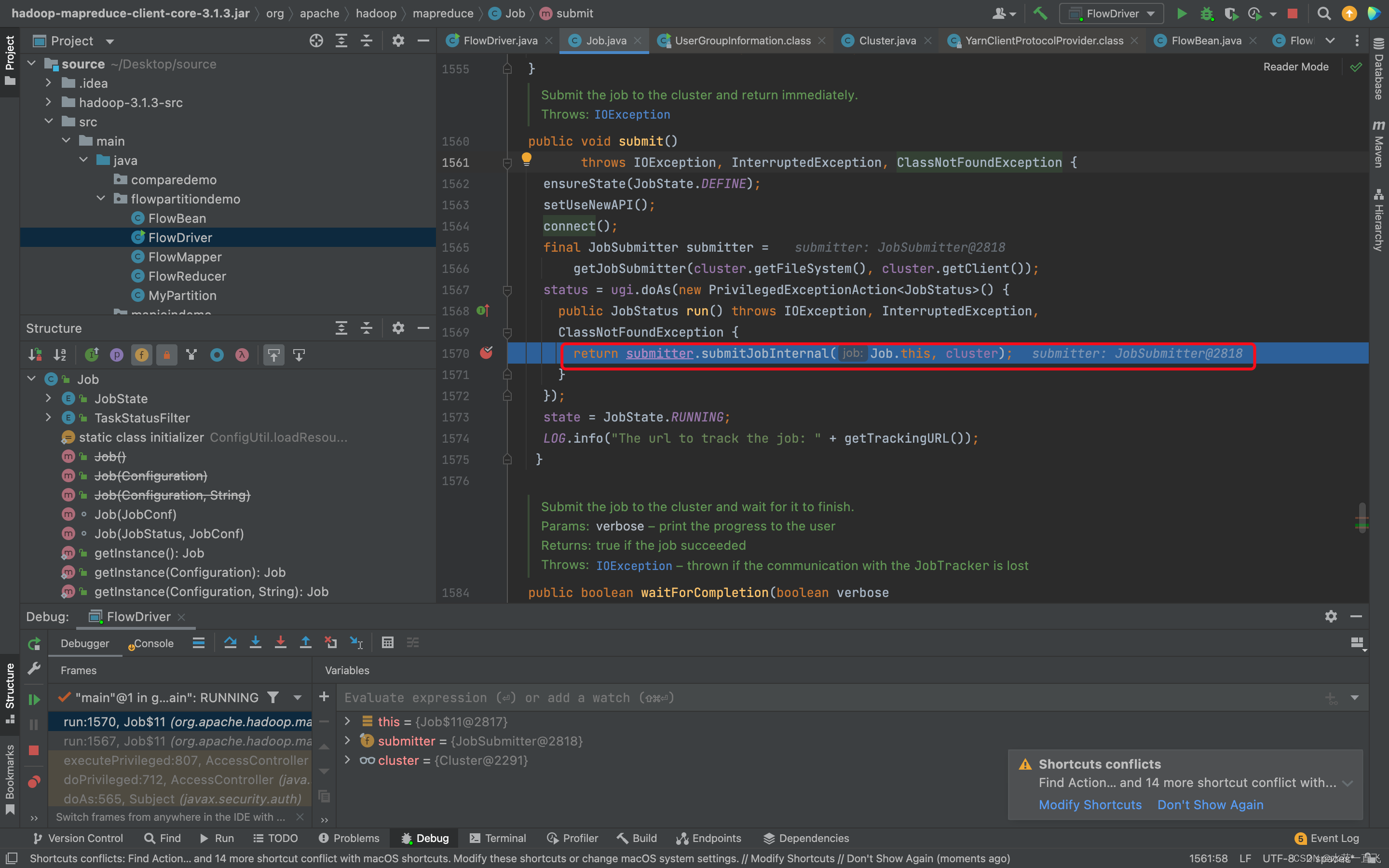
一直出来整个connet方法结束,进入到这个job提交的方法
//提交job
submitter.submitJobInternal(Job.this, cluster)

进入

继续进入
output.checkOutputSpecs(job);这个是检查output的方法
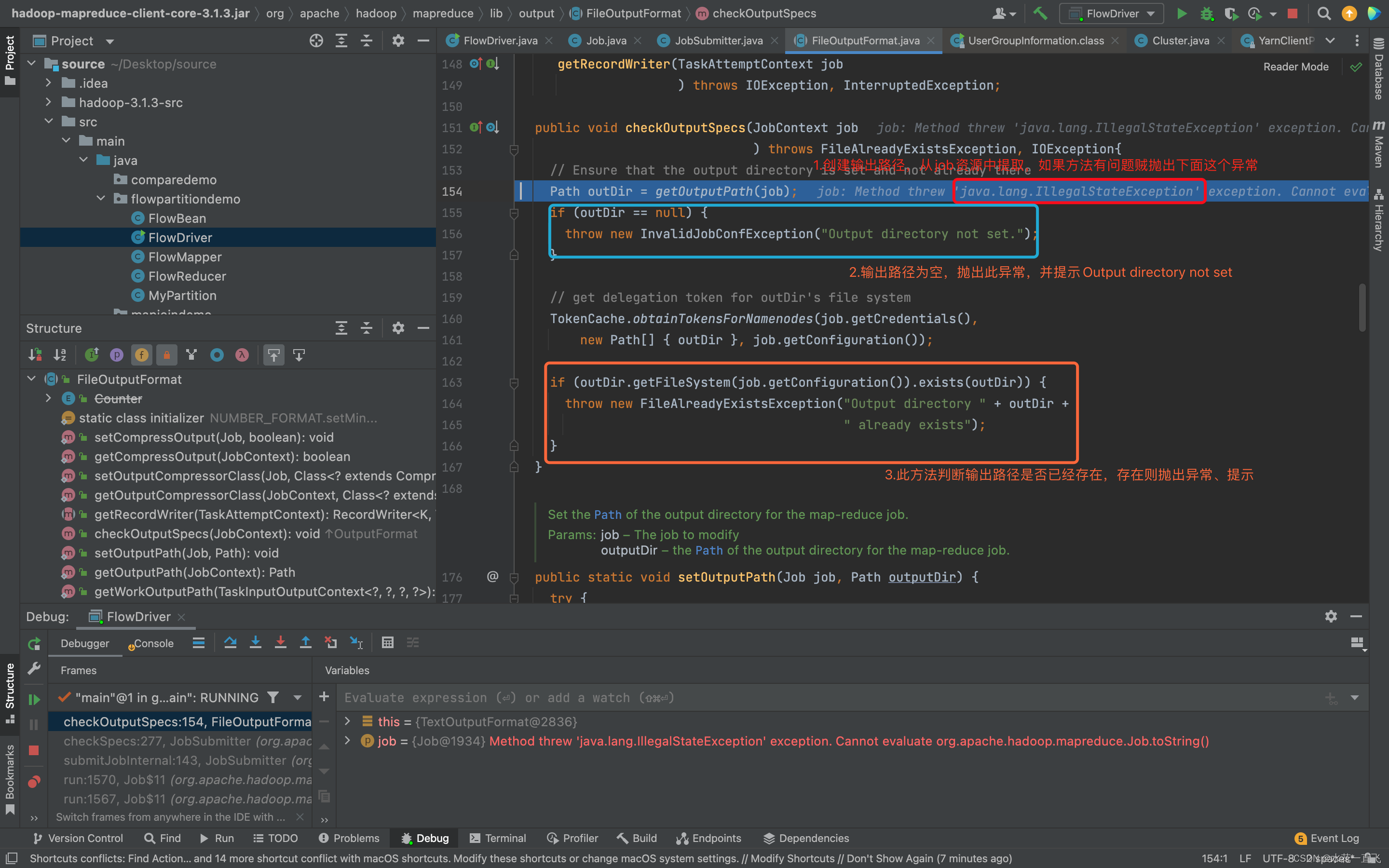
看完
checkSpeck(job)方法,出去到方法外
//创建给集群提交数据的Stag路径
//这里进的是本地的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
进入这个方法中


在Mac本地中会创建一个jobstag路径
此时还没有生成数据文件
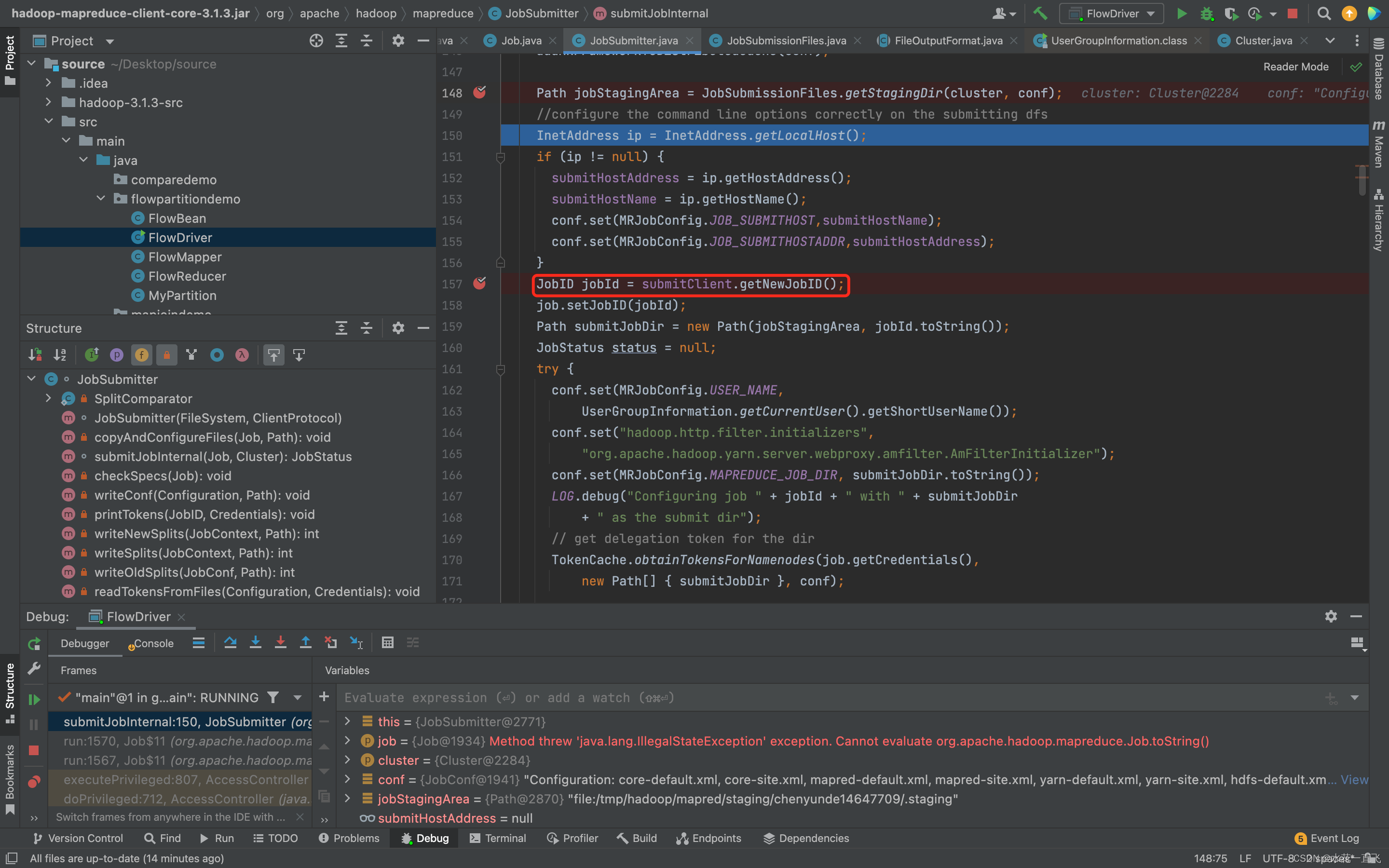
获取JobID的方法
// 获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 内部详细代码(了解)
public synchronized org.apache.hadoop.mapreduce.JobID getNewJobID() {
return new org.apache.hadoop.mapreduce.JobID("local" + this.randid, ++jobid);
}

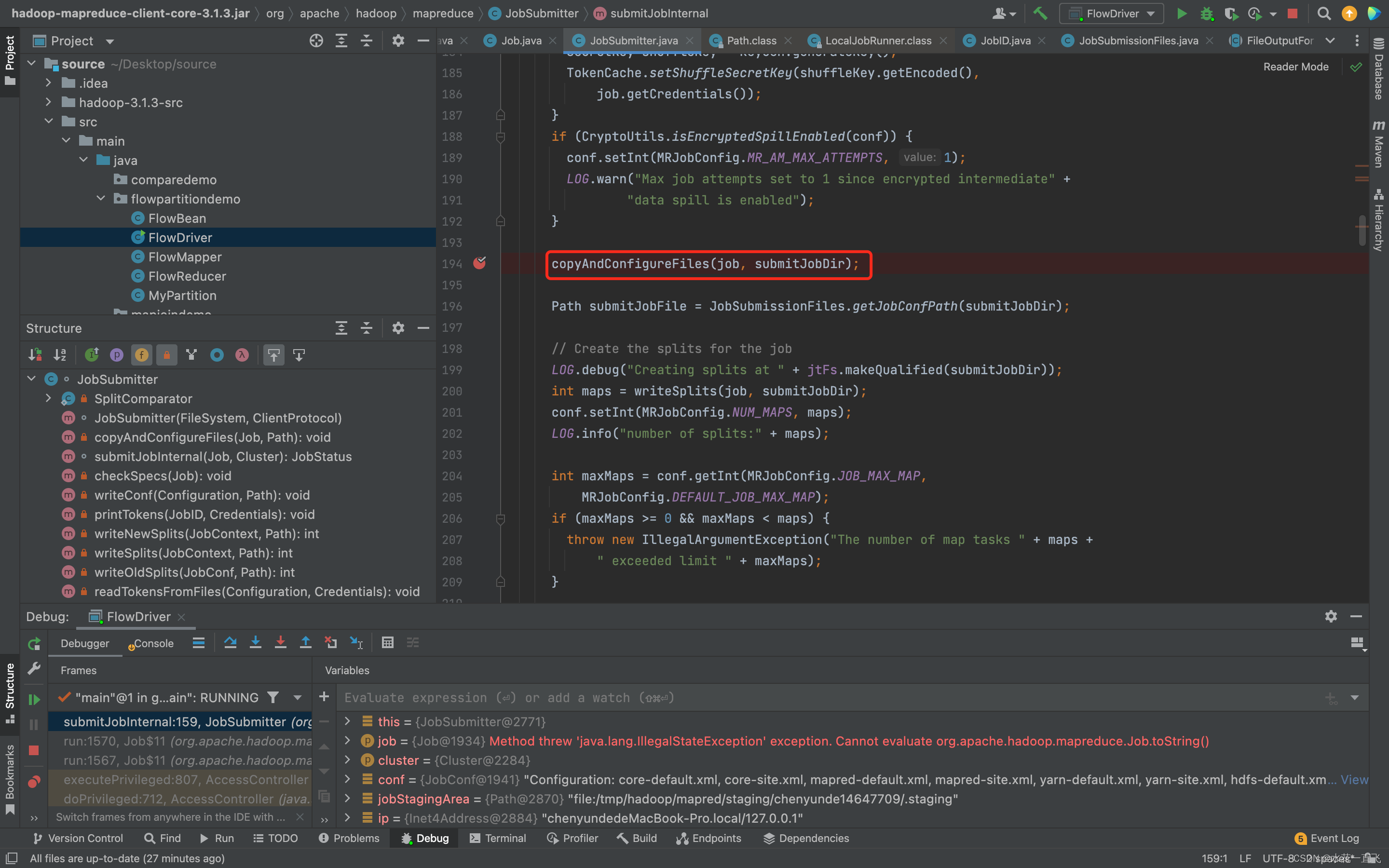
本地的话是不会走这个方法的copyAndConfigureFiles(job, submitJobDir); 集群走这个方法会上传一个jar包
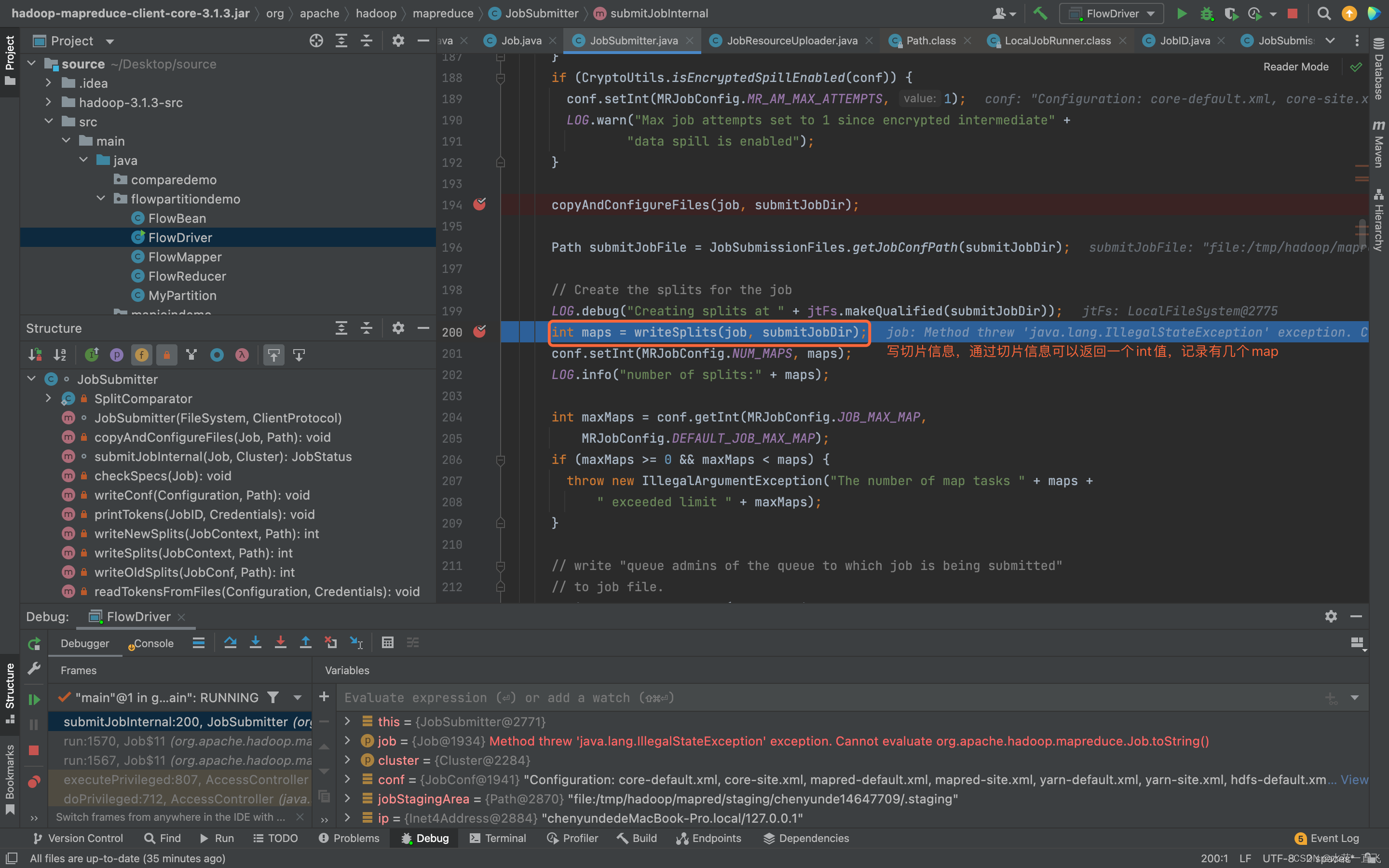
进入writeSplits的方法
// 计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 方法内
// 通过ReflectionUtils(反射的工具类)去创建实例对象(TextInputFormat对象),默认的InputFormat>>TextInputFormat中重写了getSplits的切片方法
InputFormat<?,?> input = ReflectionUtils.newInstance(job.getInputFormatClass(),conf);
// TextInputformat对象调用父类(FileInputFormat)的getSplits方法[这句话有点难懂解释一下,TextInputFormat中是没有getSplits方法的,它的父类重写了InputFormat的getSplits方法,TextInputFormat只重写了InputFormat的createRecordReader方法,实在还是不懂的话可以看看我上一篇源码把思路捋清楚再继续走]
List<InputSplit> splits = input.getSplits(job);
writeSplits方法执行完本地会会创建一个jobStag路径
// 向Stag路径写XML配置文件(同jobStag原理,在同样的路径生成job.xml文件)
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 提交Job(LocalJobRunner对象),返回提交状态
// job提交流程结束后本地jobStag路径中清空文件
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
上面说到的两个方法,多自己跑两次思路会很清晰
2 集群提交模式
集群提交模式前提是在集群上运行再debug,集群要开,设置配置要先调好
差异处:submitJobInternal
//这里进入的时候会进入到YarnClientProtocolProvider类中(本地是进入到的是LocalClientProtocolProvider类)
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
//由于我们配置了mapreduce.framework.name,所以能进入YARNRunner(conf)这个方法
public ClientProtocol create(Configuration conf) throws IOException {
return "yarn".equals(conf.get("mapreduce.framework.name")) ? new YARNRunner(conf) : null;
}
所以此时会创建出一个YARNRunner对象
connect方法执行完毕,走进提交job代码
return submitter.submitJobInternal(Job.this, cluster);
// 创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 计算切片,生成切片规划文件,向Stag路径写XML配置文件
3 总结
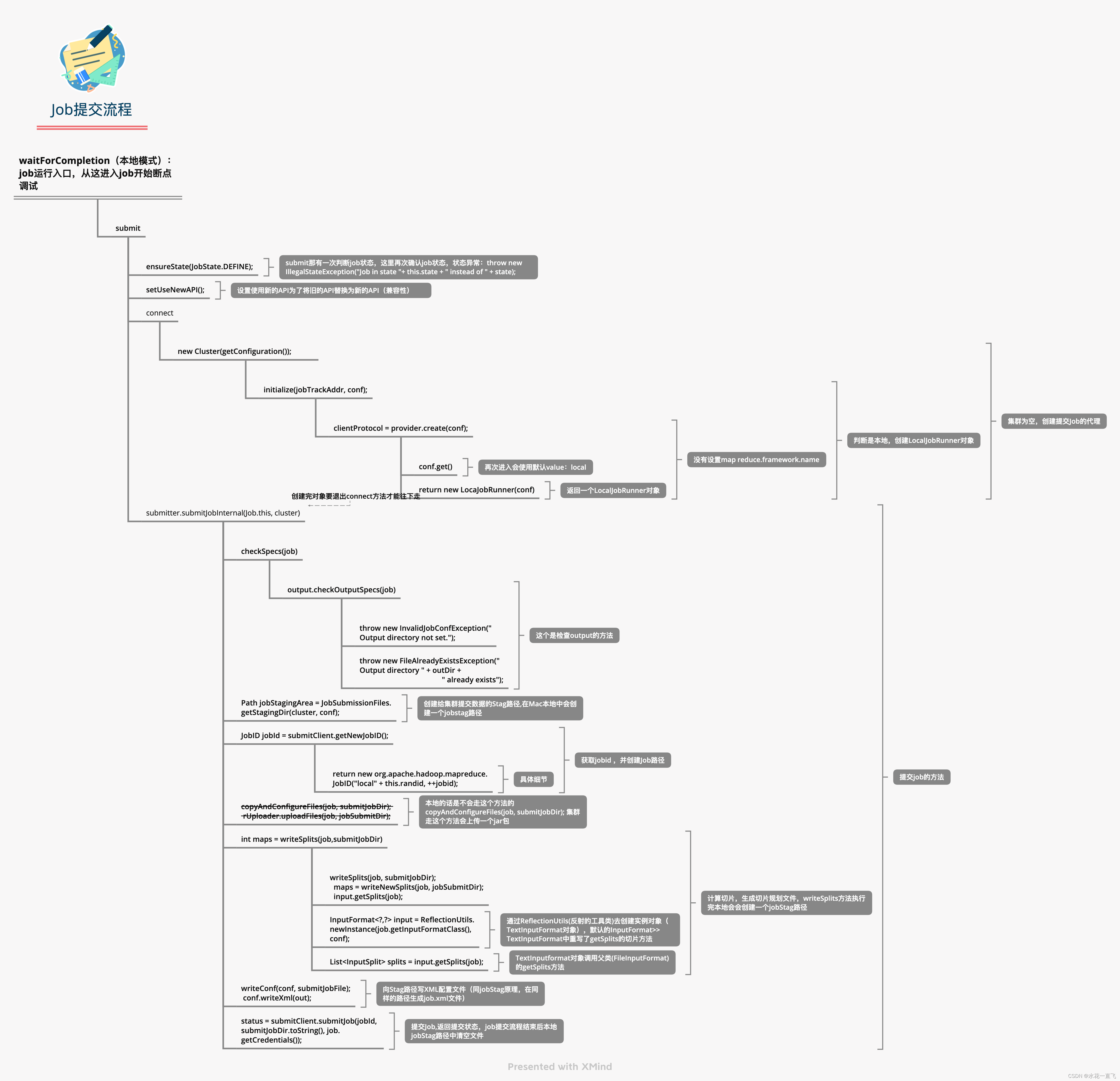
集群类似,有空再画,已经肝不动了















 3915
3915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









