







1.背景
由于项目模型需要使用趵突泉景区数据进行微调训练,而没有现成的数据集可供使用,于是进行了数据爬虫采集并清理。
想要爬虫的数据:趵突泉景区景点图片与介绍,经处理后形成图片问答数据集。
2.过程
主要从趵突泉景区官网、大众点评小程序、驴迹导游小程序等爬取数据。其中趵突泉景区官网和大众点评小程序主要爬取景点图片与介绍,驴迹导游小程序主要爬取景点对应的导游解说词。
1> 网页数据
针对趵突泉官网,使用后羿采集器该爬虫工具进行爬取,得到每个景点的图片和介绍,其中爬取到的景点介绍作为answer。
爬取后的数据如图示(csv文件,图片存在本地):

初步数据清洗与处理:
因为要将景点介绍作为图片问答的answer,所以在每条景点介绍中加入“该图片指示的景点是趵突泉/漱玉泉...”,提高答案的质量,使用prompt来构建辅助问题,如“介绍一下这张图片中的景点?”、“这张图片中的景点是什么?”,同时将存在缺失或者重复的数据删去,这样得到了初步的针对趵突泉景区的图片识别问答数据集。
处理后效果如下图(csv文件):

2> 小程序数据
针对小程序数据,使用Fiddler软件进行小程序抓包并获取相应图片和文字数据。
进入电脑微信中驴迹导游或大众点评小程序所需数据界面,启动Fiddler进行抓包,找到所需的包并解析文字,得到如下图所示的结果,将其保存成文件再进行数据处理。
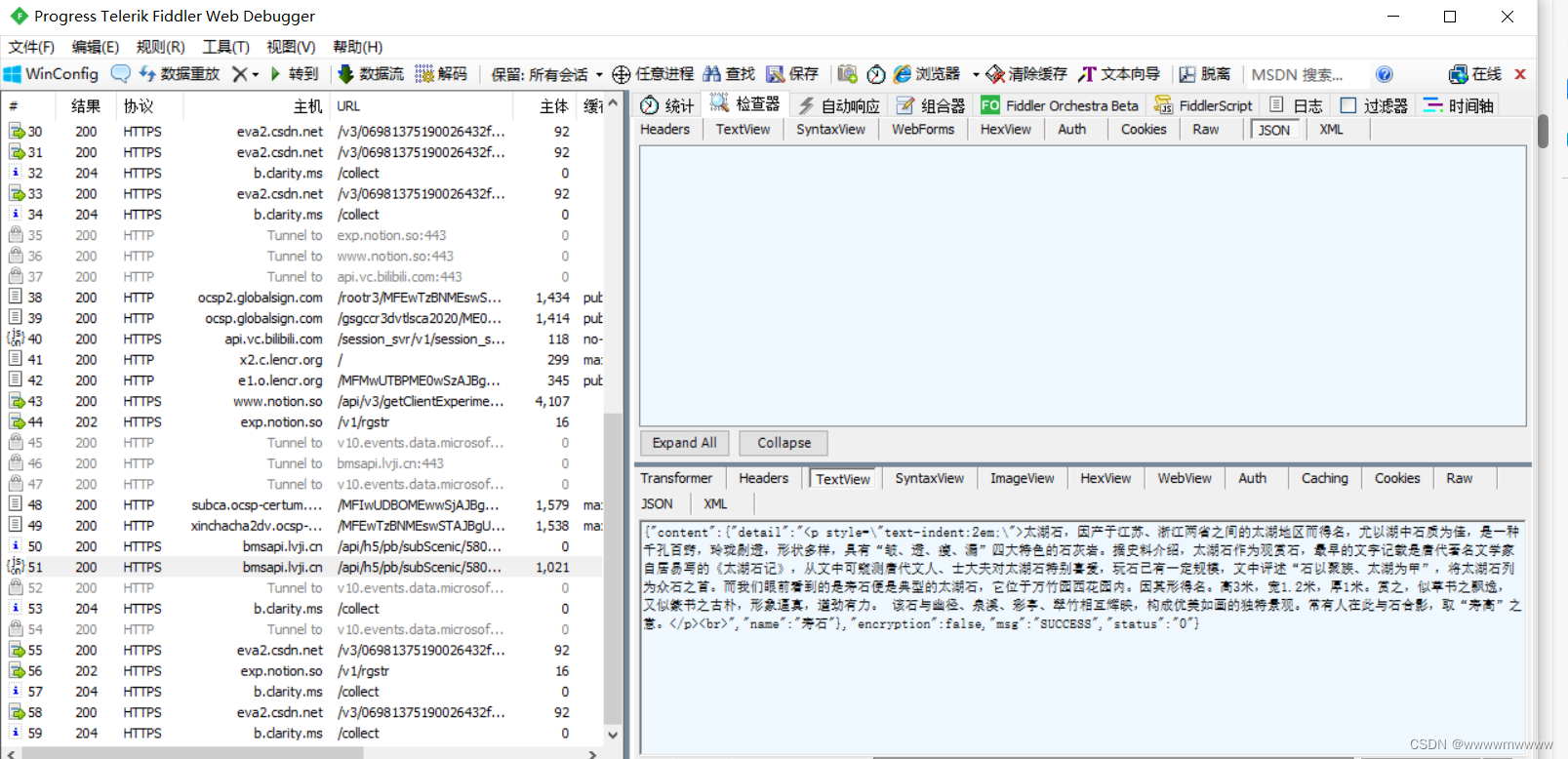
处理后的数据如下所示:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









