









Java基础11——数据结构
数据结构
数据结构是计算机科学中的一个重要概念,用于组织和存储数据以便有效地进行访问、操作和管理。它涉及了如何在计算机内存中组织数据,以便于在不同操作中进行查找、插入、删除等操作
数据结构可以看作是一种数据的组织方式,不同的数据结构适用于不同的应用场景,根据操作的需求和效率要求,选择合适的数据结构可以提高算法的执行效率。
常见的数据结构
-
数组(Array) 将相同类型的数据元素按顺序存储在连续的内存单元中,可以通过索引快速访问元素,定长。
-
哈希表(Hash Table):通过散列函数将键映射到值,实现高效的数据查找和插入
-
栈(Stack) 一种具有后进先出(LIFO)特性的数据结构,常用于处理函数调用、表达式求值等。
-
队列(Queue):一种具有先进先出(FIFO)特性的数据结构,常用于任务调度、广度优先搜索等。
- 像生活中安检机
-
链表(Linked List):通过节点与节点之间的引用(指针)链接来存储数据,分为单向链表和双向链表、循环链表,对于插入和删除操作较为高效。
-
树(Tree):一种层次结构的数据结构,包括二叉树、平衡树、二叉搜索树等,常用于搜索和排序操作。
-
图(Graph):由节点和边构成的数据结构,用于表示各种复杂的关系和连接。
数组
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。数组的特点是:提供随机访问 并且容量有限。
假如数组的长度为 n。
访问:O(1)//访问特定位置的元素
插入:O(n )//最坏的情况发生在插入发生在数组的首部并需要移动所有元素时
删除:O(n)//最坏的情况发生在删除数组的开头发生并需要移动第一元素后面所有的元素时

栈
栈简介
-
栈 (Stack) 只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out)的原理运作。
-
在栈中,push 和 pop 的操作都发生在栈顶。
-
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈
如何创建一个类实现栈的功能?
- 底层存元素使用数组
- 添加元素始终添加到数组的最后一个
- 获取元素时永远从最后一个开始取元素
- 扩容问题
- 栈既可以通过数组实现,也可以通过链表来实现。
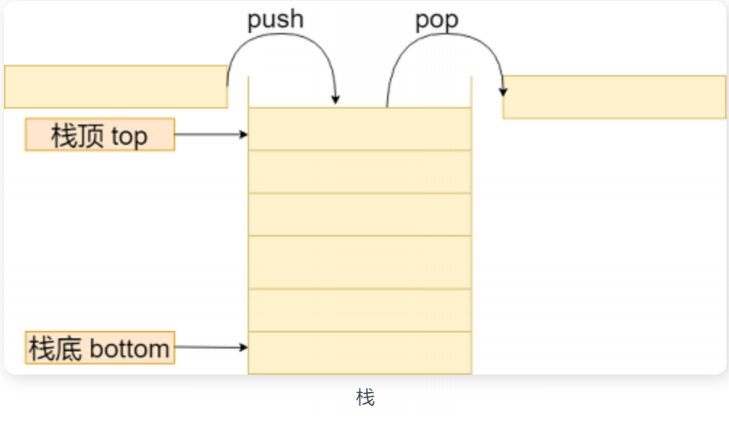
栈使用场景
- 实现浏览器的回退和前进功能
- 反转字符串,将字符串中的每个字符先入栈再出栈就可以了
- 方法之间的调用
public abstract class Stack {
/**
* 将元素压入栈顶
* 入栈
* @param element 要压入的元素
*/
abstract void push(Object element);
/**
* 弹出栈顶元素并返回
* 把栈顶元素删除,并返回
* 出栈
* @return 弹出的栈顶元素, 如果栈为空返回 null
*/
abstract Object pop();
/**
* 返回栈顶元素,但不弹出
* @return 栈顶元素
*/
abstract Object peek();
/**
* 检查栈是否为空
* @return 如果栈为空则返回true,否则返回false
*/
abstract boolean isEmpty();
/**
* 返回栈中的元素个数
* @return 栈中元素的个数
*/
abstract int size();
}
通过继承抽象类 Stack 实现一个栈。并重写 toString/equals/hashCode 方法
队列
队列简介
- 队列(Queue) 是 先进先出 (FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。
- 队列只允许在后端(rear)进行插入操作也就是入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue
- 队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
如何实现?
- 使用数组存元素
- 存元素还是放到数组的最后
- 取元素从第一个开始取

队列分类
- 单队列:单队列每次添加元素时,都是添加到队尾。
- 循环队列:队尾移出队列后,从头开始,这样也就会形成头尾相接的循环。
- 双端队列:队列的两端都可以进行插入和删除操作的队列
public abstract class Queue {
/**
* 将元素插入队尾
* @param element 要插入的元素
*/
void enqueue(Object element);
/**
* 移除并返回队首元素
* 删除第一个元素,并返回
* @return 队首元素, 如果队列为空时,返回 null
*/
abstract Object dequeue();
/**
* 返回队首元素,但不移除
* @return 队首元素
*/
abstract Object peek();
/**
* 检查队列是否为空
* @return 如果队列为空则返回true,否则返回false
*/
abstract boolean isEmpty();
/**
* 返回队列中的元素个数
* @return 队列中元素的个数
*/
abstract int size();
}
通过继承抽象类 Queue 实现一个队列。并重写 toString/equals/hashCode 方法
链表
-
链表不是连续的内存空间来存储数据。
-
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利
-
用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。
-
除此之外,链表不具有数组随机读取的优点。
-
常见链表分类单链表
- 双向链表
- 循环链表
- 双向循环链表
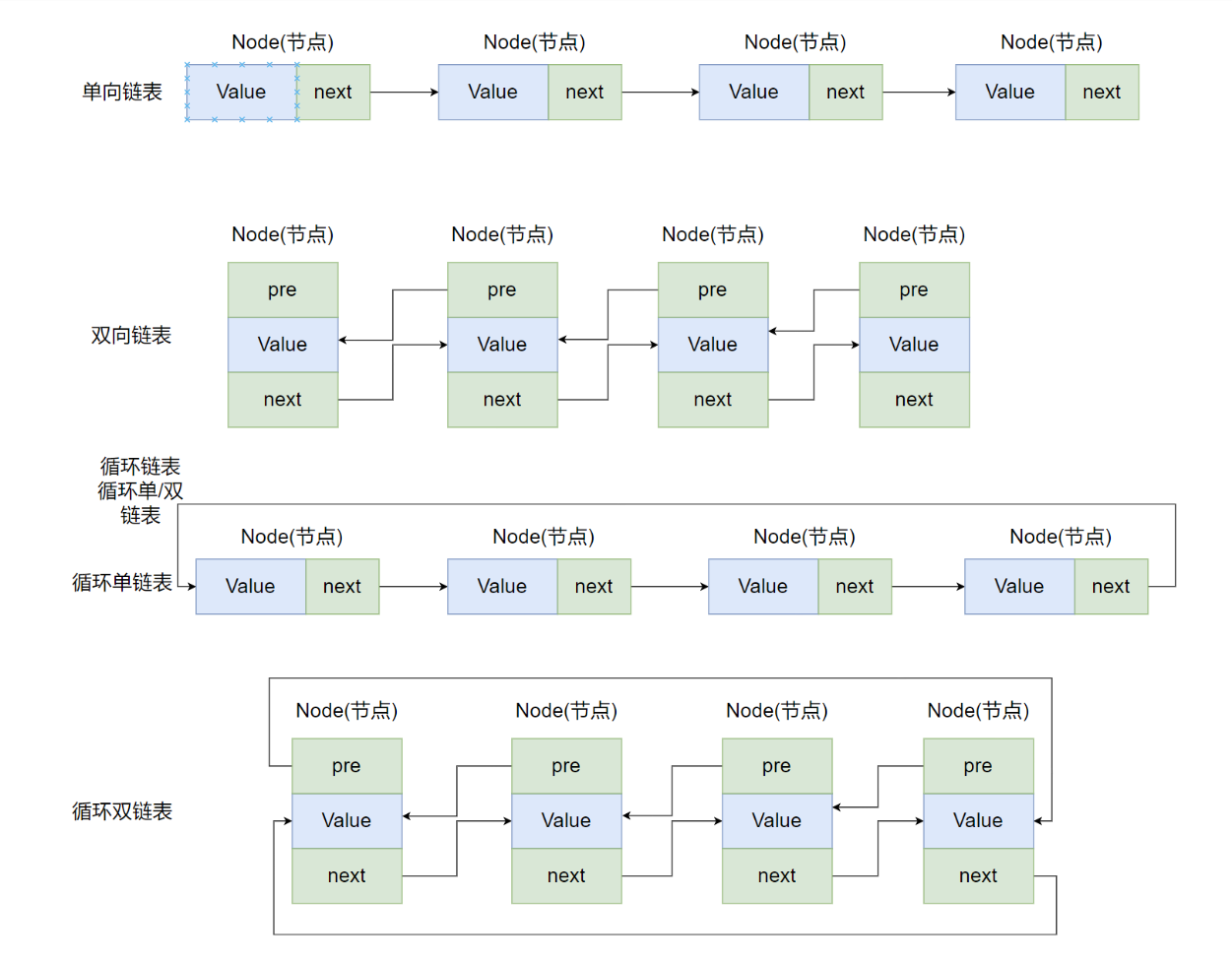
单链表
- 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。
- 我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head节点(头结点),通过头结点我们可以遍历整个链表。
- 尾结点通常指向 null。
循环链表
- 循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点
双向链表
- 双向链表 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点
双向循环链表
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
链表使用场景
- 如果需要支持随机访问的话,链表没办法做到。
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
数组 vs 链表
- 数组支持随机访问,而链表不支持。
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
树
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
一棵树具有以下特点:
- \1. 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- \2. 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- \3. 一棵树不包含回路。
下图就是一颗树,并且是一棵二叉树
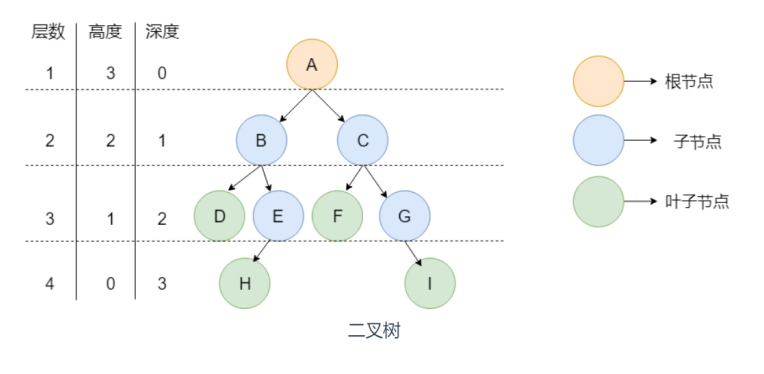
如上图所示,通过上面这张图说明一下树中的常用概念:
节点:树中的每个元素都可以统称为节点。
根节点:顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的
B 节点是 D 节点、E 节点的父节点。
子节点:一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E
节点是 B 节点的子节点。
兄弟节点:具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共
同父节点是 B 节点,故 D 和 E 为兄弟节点。
叶子节点:没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
节点的高度:该节点到叶子节点的最长路径所包含的边数。
节点的深度:根节点到该节点的路径所包含的边数
节点的层数:节点的深度+1。
树的高度:根节点的高度
二叉树分类
二叉树(Binary tree)是每个节点最多只有两个分支(即不存在分支度大于 2 的节点)的树结构。
二叉树 的分支通常被称作“左子树”或“右子树”。并且,二叉树 的分支具有左右次序,不能随意颠倒。
二叉树 的第 i 层至多拥有 2^(i-1) 个节点,深度为 k 的二叉树至多总共有2^(k+1)-1 个节点(满二叉树的情况。
满二叉树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是 满二叉树。
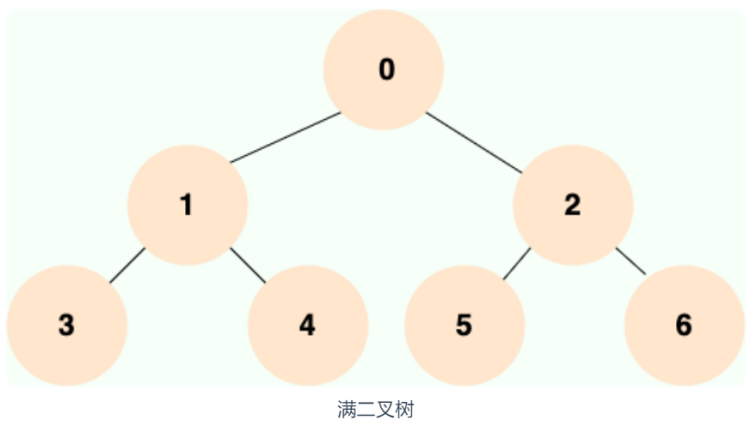
完全二叉树
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。
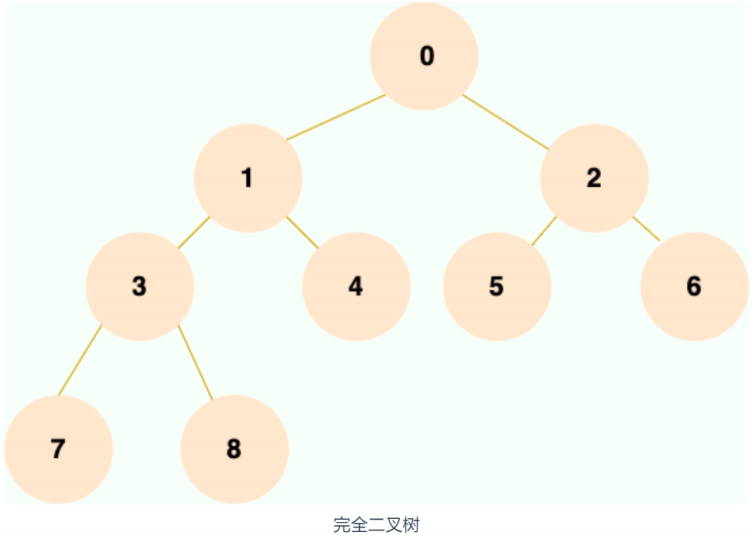
平衡二叉树
平衡二叉树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树
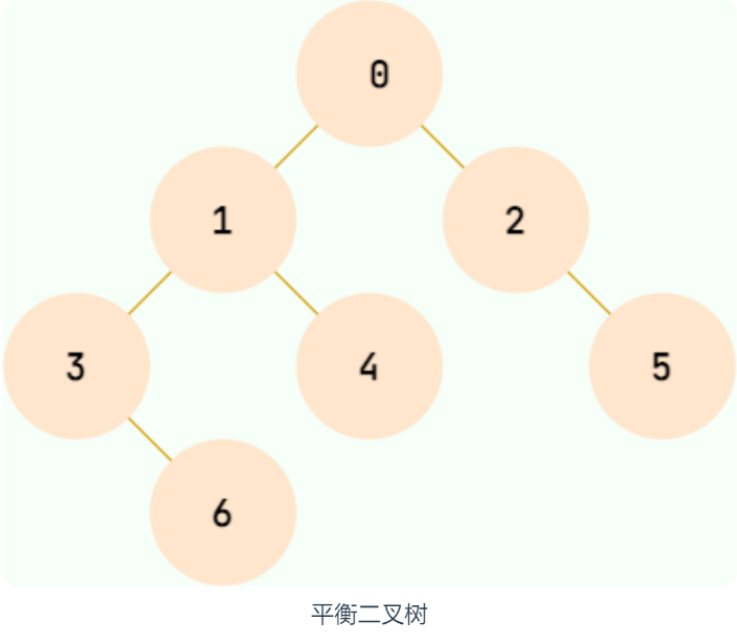
二叉树的存储
二叉树的存储主要分为 链式存储 和 顺序存储 两种:
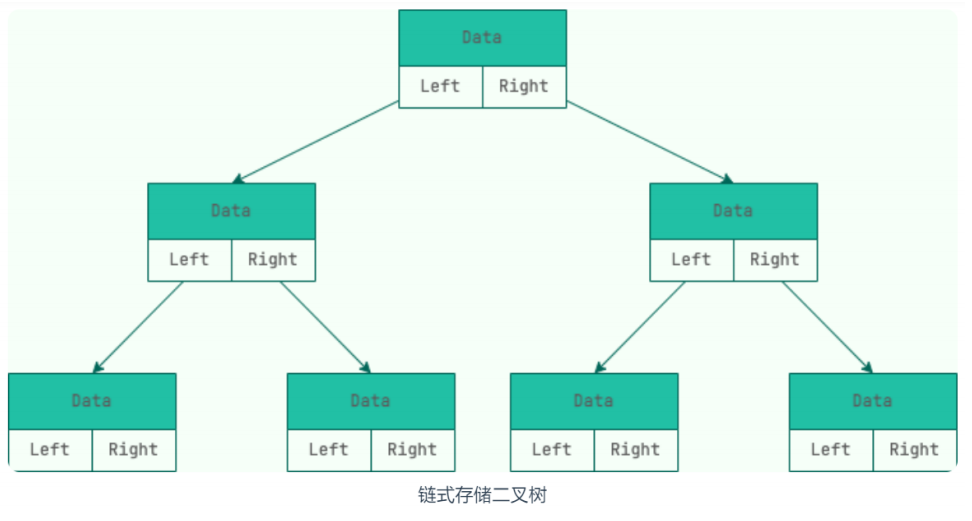
链式存储
和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
每个节点包括三个属性:
- 数据 data
- 左节点指针 left
- 右节点指针 right
顺序存储
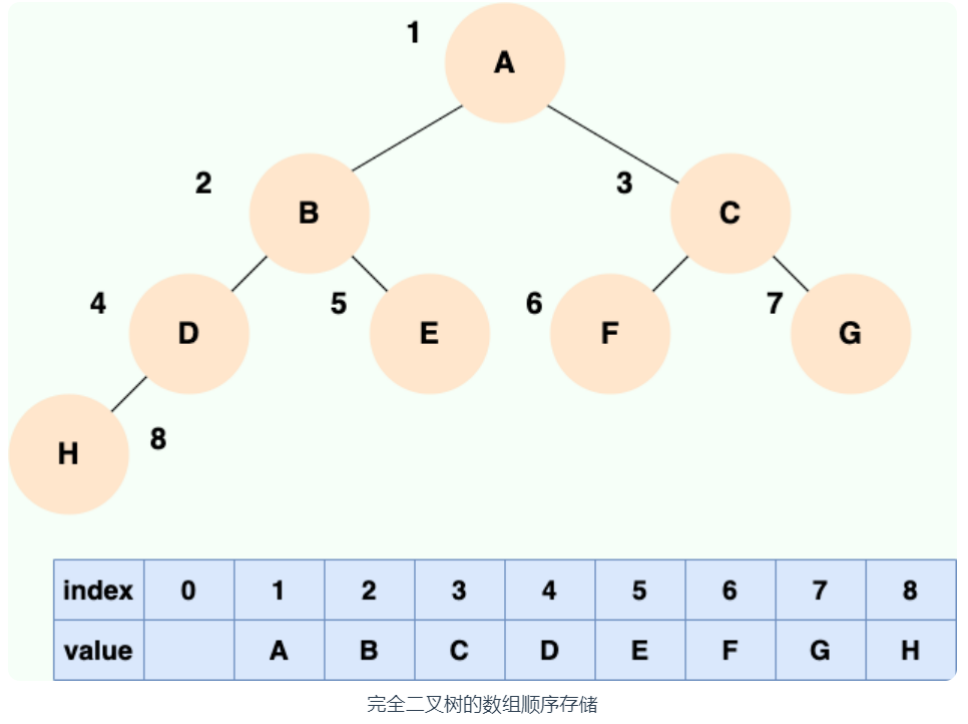
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2i的位置,它的右子节点存储在下标为 2i+1 的位置。
一棵完全二叉树的数组顺序存储如下图所示:
二叉树的遍历
先序遍历
先序遍历:根左右
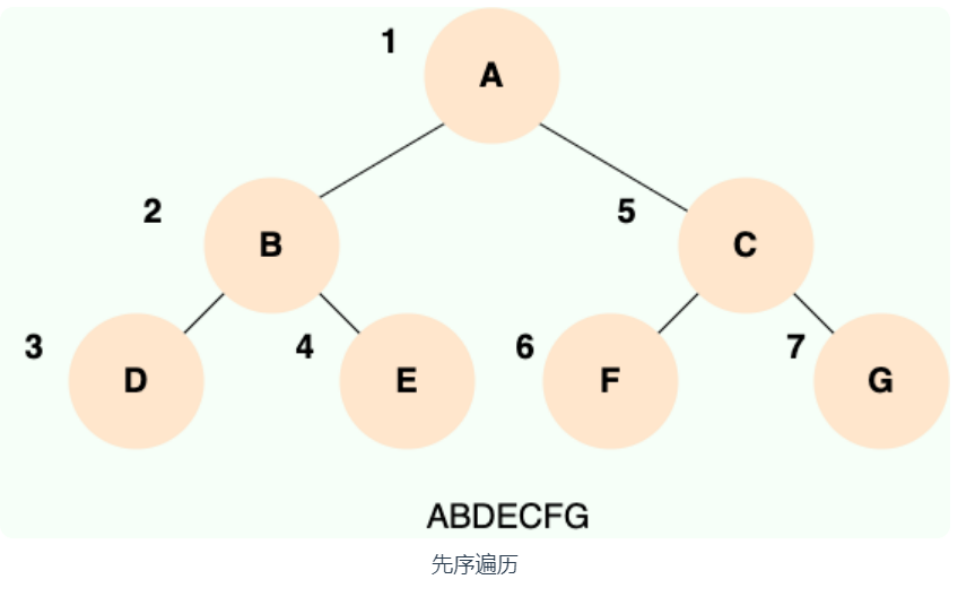
示例
public void preOrder(TreeNode root){
if(root == null){
return;
}
system.out.println(root.data);
preOrder(root.left);
preOrder(root.right);
}
中序遍历
中序遍历:左根右
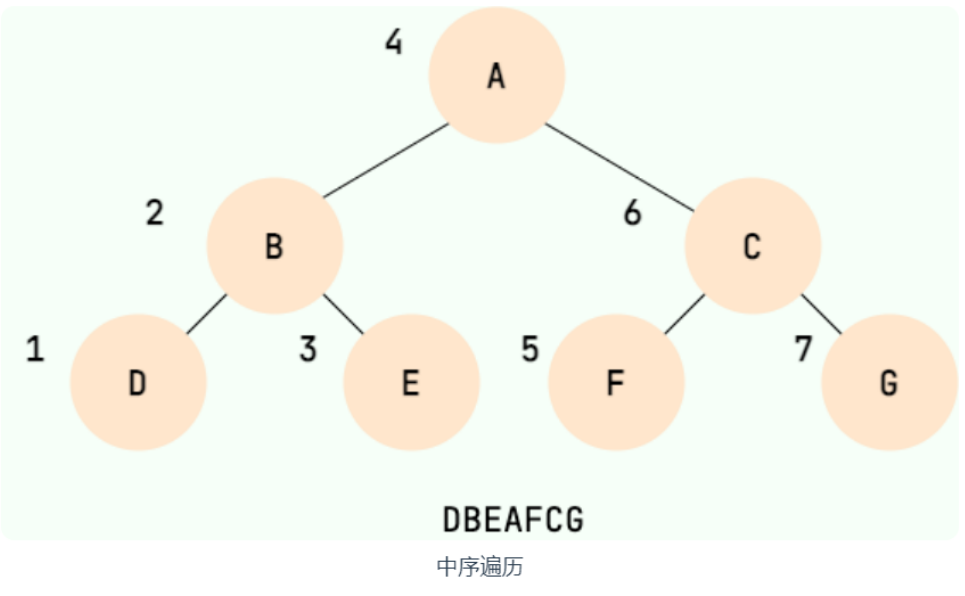
示例
public void inOrder(TreeNode root){
if(root == null){
return;
}
inOrder(root.left);
system.out.println(root.data);
inOrder(root.right);
}
后序遍历
后序遍历:左右根
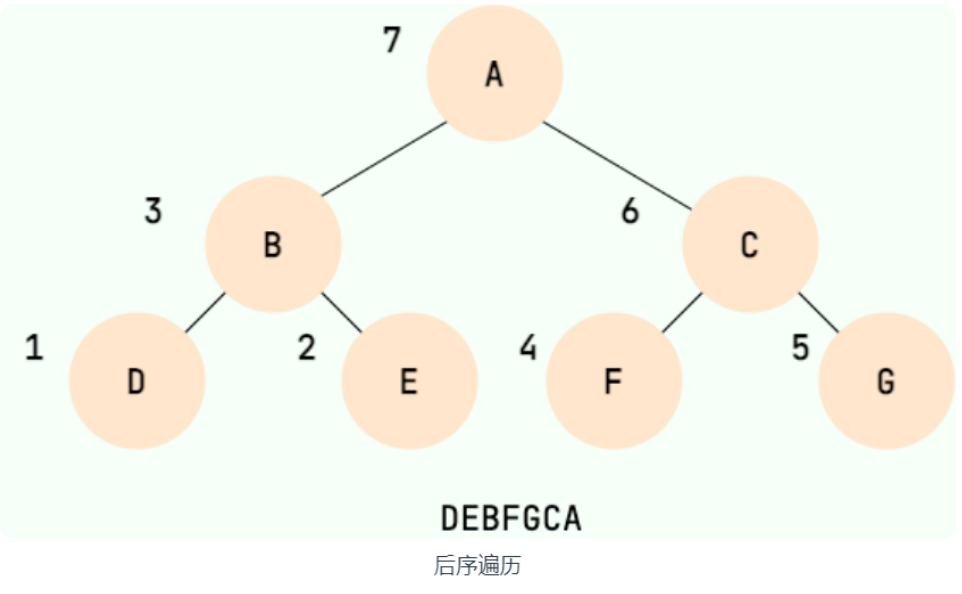
示例
public void postOrder(TreeNode root){
if(root == null){
return;
}
postOrder(root.right);
postOrder(root.left);
system.out.println(root.data);
}
二叉排序树
为什么使用二叉排序树
先来看一个需求:给你一个数列 (7, 3, 10, 12, 5, 1, 9),要求能够高效的完成对数据的查询和添加。
对需求进行分析:
1**:使用数组存储**
-
若数组未排序
- 优点:直接在数组尾添加,速度快。
- 缺点:查找速度慢。
-
若数组排序
- 优点:可以使用二分查找,查找速度快。
- 缺点:为了保证数组有序,在添加新数据时,找到插入位置后,后面的数据需整体移动,速度慢
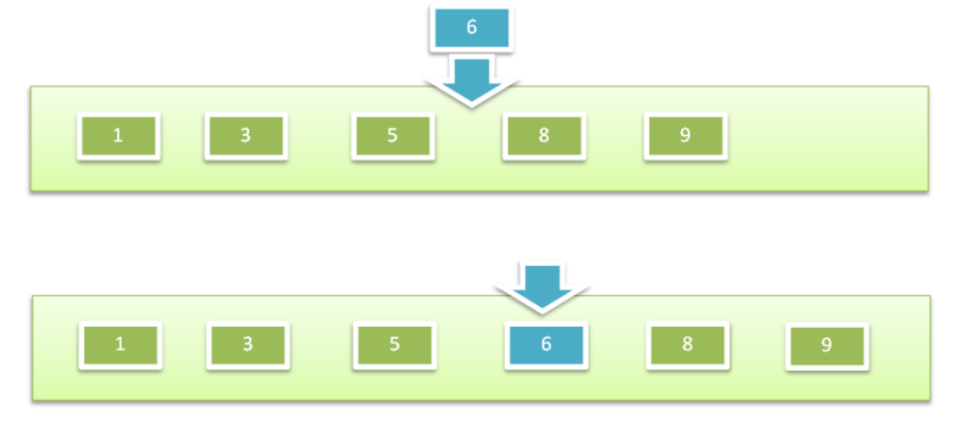
使用链表存储
- 优点:添加数据和删除数据速度比数组快,不需要数据整体移动。
- 缺点:不管链表是否有序,查找速度都慢。
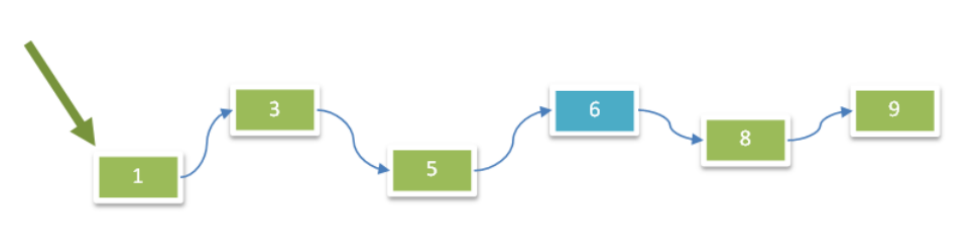
使用二叉排序树存储
- 二叉排序树既有链表的优点,也有数组的优点。
- 适合在处理大批量的动态数据时使用
什么是二叉排序树
二叉排序树:BST: (Binary Sort(Search) Tree),也叫二叉查找树, 对于二叉排序树的任何一个非叶子节点,要求左子节点的值比当前节点的值小,右子节点的值比当前节点的值大。
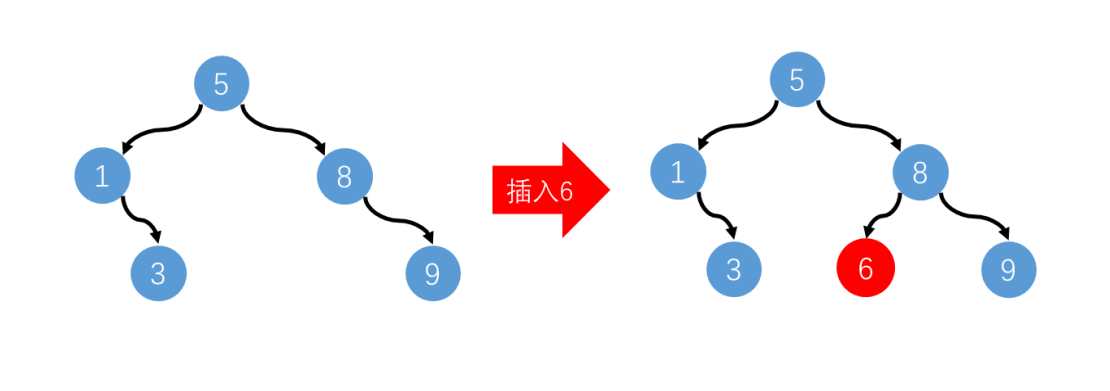
比如上图所示的二叉排序树
- 插入6时,不用移动数据,把6挂在8的左子节点即可,插入效率高
- 查找9时,不用全部遍历,只访问5,8,9三个节点即可找到,查找效率高
红黑树
什么是红黑树
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL 节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
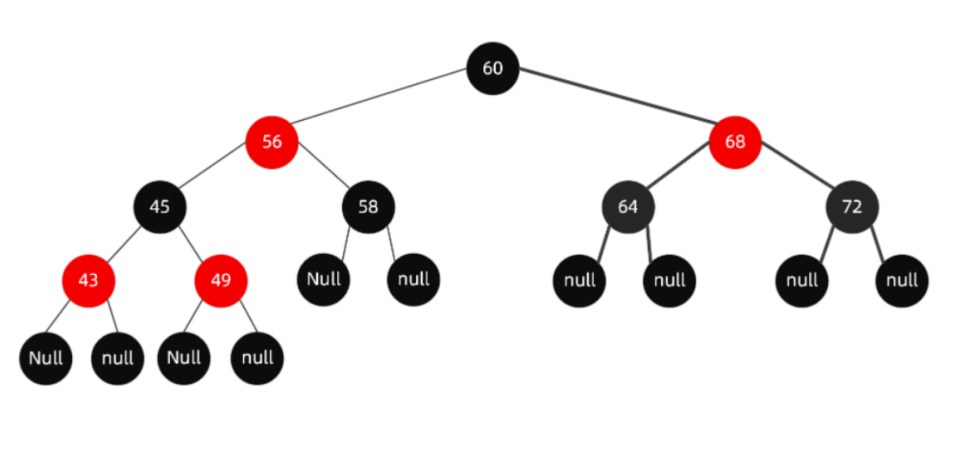
为什么要用红黑树
简单来说红黑树就是为了解决二叉排序树的缺陷,因为二叉排序树在某些情况下会退化成一个线性结构
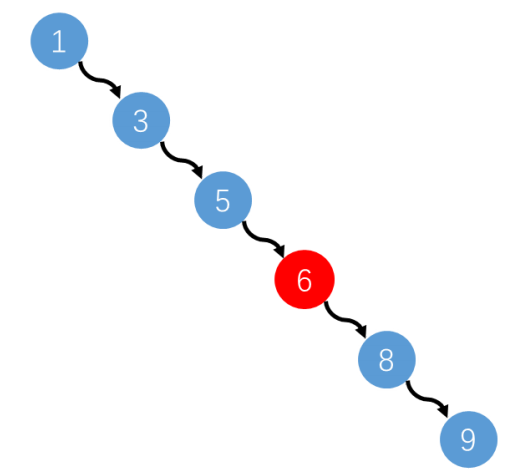
上图这种二叉排序树是不是就成了线性结构,查找效率最低啦,如果查找9的话,要遍历每一个节点,共招6次,查找路径是1,3,5,6,8,9。
而红黑树的规则使得红黑树本身就是一个带有自平衡功能的二叉排序树,关键是自平衡,自平衡后就不会出现线性结构,所以红黑树的查询效率高。
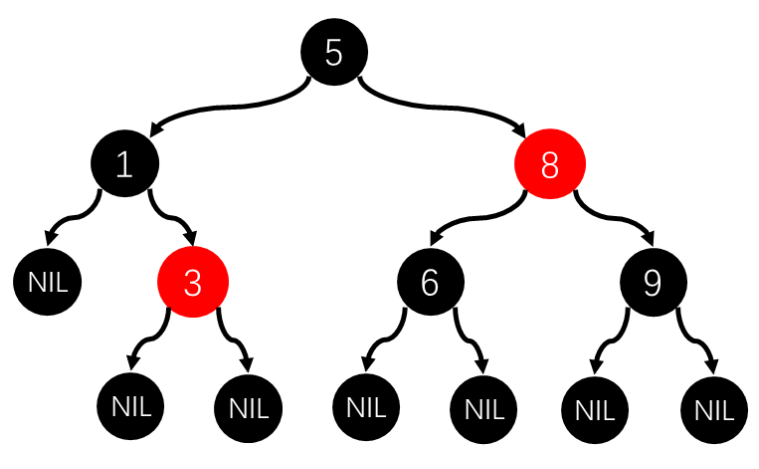
用红黑树找9,如下图,只需找3次,查找路径是5,8,9。
旋转和变色
当向红黑树中添加或者删除节点时,为了保证红黑树平衡,可能会让红黑树发生向左旋转(左旋)或者向右旋转(右旋)。并且在旋转后节点发生变色。
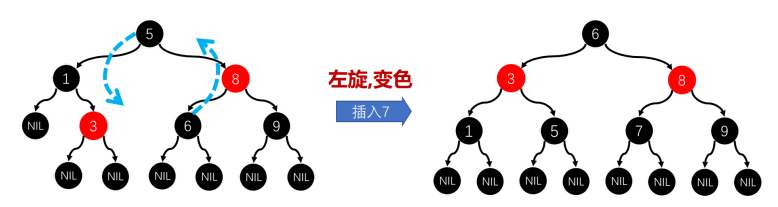
向红黑树上再添加数字7,就会导致红黑树左旋和节点变色,如下图。
- 根节点5变成了左侧的子节点
- 6变成了根节点
- 本例中没有变色的节点
红黑树的优缺点
优点:查找速度快
线性结构,查找效率最低啦,如果查找9的话,要遍历每一个节点,共招6次,查找路径是1,3,5,6,8,9。
而红黑树的规则使得红黑树本身就是一个带有自平衡功能的二叉排序树,关键是自平衡,自平衡后就不会出现线性结构,所以红黑树的查询效率高。
用红黑树找9,如下图,只需找3次,查找路径是5,8,9。
[外链图片转存中…(img-K43qH07O-1695132286589)]
旋转和变色
当向红黑树中添加或者删除节点时,为了保证红黑树平衡,可能会让红黑树发生向左旋转(左旋)或者向右旋转(右旋)。并且在旋转后节点发生变色。
向红黑树上再添加数字7,就会导致红黑树左旋和节点变色,如下图。
- 根节点5变成了左侧的子节点
- 6变成了根节点
- 本例中没有变色的节点
[外链图片转存中…(img-C1YFxQKr-1695132286589)]
红黑树的优缺点
优点:查找速度快
缺点:增、删影响效率,因为增删可能需要旋转和变色
















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









