






爬虫基础入门
爬虫的分类
网络爬虫按照系统结构和实现技术,大致可分为4类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深层次网络爬虫。
1.通用网络爬虫:搜索引擎的爬虫
比如用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关的再根据一定的排名规则进行排序后展现给用户,那么就需要尽可能多的互联网的优质网页。
从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
2.聚焦网络爬虫:针对特定网页的爬虫
也叫主题网络爬虫,爬取的 目标网页定位在与主题相关的页面中 ,主要为某一类特定的人群提供服务,可以节省大量的服务器资源和带宽资源。聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
比如要获取某一垂直领域的数据或有明确的检索需求,此时需要过滤掉一些无用的信息。
例如:那些比较价格的网站,就是爬取的其他网站的商品。
3.增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,即增量式更新。增量式更新指的是再更新的时候只更新改变的地方,而为改变的地方则不更新,所以该爬虫只爬取内容发生变化的网页或者新产生的网页。
比如:招聘网爬虫
4.深层网络爬虫
深层网络爬虫(Deep Web Crawler),首先,什么是深层页面?
在互联网中,网页按存在方式划分为表层页面和深层页面。所谓表层页面,指的是不需要提交表单,使用静态的链接能够到达的静态页面;而深层页面是需要调教一定的关键词之后才能获取的页面。在互联网中,深层页面数量往往比表层页面多得多。
深层网络爬虫主要由URL列表、LVS【虚拟服务器】列表、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等构成。
后面我们主要学习聚焦爬虫,聚焦爬虫学会了,其他类型的爬虫也就能轻而易举的写出来
4.通用爬虫与聚焦爬虫的原理
通用爬虫:
第一步:抓取网页(url)
- start_url发送请求,在获取响应解析;
- 从响应解析中获取到了需要的新的url,将这些URL放入待抓取URL队列;
- 取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
- 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环…
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字、导航条、广告等……)
- 索引处理
- 链接关系计算
- 特殊文件处理
- …
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
聚焦爬虫:
第一步:start_url 发送请求
第二步:获取响应(response)
第三步:解析响应,若响应中有需要的新的url地址,重复第二步;
第四步:提取数据
第五步:保存数据
通常,我们会把获取响应,解析放在一个步骤中完成,所以说,聚焦爬虫的步骤,通俗的来讲一共四步
1.Http与Https
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息

浏览器发送HTTP请求的过程
-
当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
统一资源定位符:URL(Uniform / Universal Resource Locator的缩写)是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
-
当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
-
浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
-
当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
协议://主机:[端口号]/路径/?[请求or查询参数]…/[#锚点]
- scheme:协议(例如:http, https, ftp)
- host:服务器的IP地址或者域名
- port#:服务器的端口(如果是走协议默认端口,缺省端口80)
- path:访问资源的路径
- query-string:参数,发送给http服务器的数据
- anchor:锚(用于页面 内跳转)
例如:
- ftp://192.168.0.116:8080/index
- http://www.baidu.com
- http://item.jd.com/11936238.html#product-detail
HTTP请求主要分为Get和Post两种方法
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,即“Get”请求的参数是URL的一部分。 例如:
http://www.baidu.com/s?wd=Chinese - POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
注意:避免使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。
当然,让我帮你进行一些调整以提高笔记的可读性和美观程度:
常用的请求报头
1. Host (主机和端口号)
-
Host:对应网址URL中的Web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常属于URL的一部分。
2. Connection (链接类型)
- Connection:表示客户端与服务连接类型
- Client 发起一个包含
Connection:keep-alive的请求,HTTP/1.1使用keep-alive为默认值。 - Server收到请求后:
- 如果 Server 支持 keep-alive,回复一个包含 Connection:keep-alive 的响应,不关闭连接;
- 如果 Server 不支持 keep-alive,回复一个包含 Connection:close 的响应,关闭连接。
- 如果client收到包含
Connection:keep-alive的响应,向同一个连接发送下一个请求,直到一方主动关闭连接。 - keep-alive在很多情况下能够重用连接,减少资源消耗,缩短响应时间,比如当浏览器需要多个文件时(比如一个HTML文件和相关的图形文件),不需要每次都去请求建立连接。
- Client 发起一个包含
3. Upgrade-Insecure-Requests (升级为HTTPS请求)
- Upgrade-Insecure-Requests:升级不安全的请求,意思是会在加载 http 资源时自动替换成 https 请求,让浏览器不再显示https页面中的http请求警报。
- HTTPS 是以安全为目标的 HTTP 通道,所以在 HTTPS 承载的页面上不允许出现 HTTP 请求,一旦出现就是提示或报错。
4. User-Agent (浏览器名称)
- User-Agent:是客户浏览器的名称,通过这个名称网站才能了解到你使用的是什么设备,如果是非法设备会判断403
5. Accept (传输文件类型)
- Accept:指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions(多用途互联网邮件扩展))文件类型,服务器可以根据它判断并返回适当的文件格式。
- 举例:
Accept: */*:表示什么都可以接收。Accept:image/gif:表明客户端希望接受GIF图像格式的资源;Accept:text/html:表明客户端希望接受html文本。Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8:表示浏览器支持的 MIME 类型分别是 html文本、xhtml和xml文档、所有的图像格式资源。- q是权重系数,范围 0 =< q <= 1,q 值越大,请求越倾向于获得其“;”之前的类型表示的内容。若没有指定q值,则默认为1,按从左到右排序顺序;若被赋值为0,则用于表示浏览器不接受此内容类型。
- 举例:
6. Referer (页面跳转处)
- Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
- 有时候遇到下载某网站图片,需要对应的referer,否则无法下载图片,那是因为人家做了防盗链,原理就是根据referer去判断是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载;
7. Accept-Encoding(文件编解码格式)
- Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
- 如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
- *举例:Accept-Encoding:gzip;q=1.0, identity; q=0.5, ;q=0
8. Accept-Language(语言种类)
- Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
9. Accept-Charset(字符编码)
- Accept-Charset:指出浏览器可以接受的字符编码。
- 举例:Accept-Charset:iso-8859-1,gb2312,utf-8
- ISO8859-1:通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,英文浏览器的默认值是ISO-8859-1.
- gb2312:标准简体中文字符集;
- utf-8:UNICODE 的一种变长字符编码,可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
- 如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
- 举例:Accept-Charset:iso-8859-1,gb2312,utf-8
10. Cookie (Cookie)
- Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能
11. Content-Type (POST数据类型)
-
Content-Type:POST请求里用来表示的内容类型。
服务端HTTP响应
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文

HTTP/1.1 200 OK
Server: Tengine
Connection: keep-alive
Date: Wed, 30 Nov 2016 07:58:21 GMT
Cache-Control: no-cache
Content-Type: text/html;charset=UTF-8
Keep-Alive: timeout=20
Vary: Accept-Encoding
Pragma: no-cache
X-NWS-LOG-UUID: bd27210a-24e5-4740-8f6c-25dbafa9c395
Content-Length: 180945
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
理论上所有的响应头信息都应该是回应请求头的。但是服务端为了效率,安全,还有其他方面的考虑,会添加相对应的响应头信息,从上图可以看到:
1. Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,不能从缓存副本中获取资源。
- Cache-Control是响应头中很重要的信息,当客户端请求头中包含Cache-Control:max-age=0请求,明确表示不会缓存服务器资源时,Cache-Control作为作为回应信息,通常会返回no-cache,意思就是说,“那就不缓存呗”。
- 当客户端在请求头中没有包含Cache-Control时,服务端往往会定,不同的资源不同的缓存策略,比如说oschina在缓存图片资源的策略就是Cache-Control:max-age=86400,这个意思是,从当前时间开始,在86400秒的时间内,客户端可以直接从缓存副本中读取资源,而不需要向服务器请求。
2. Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
3. Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4. Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5. Date:Sun, 21 Sep 2016 06:18:21 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
6. Expires:Sun, 1 Jan 2000 01:00:00 GMT
这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
7. Pragma:no-cache
这个含义与Cache-Control等同。
8.Server:Tengine/1.4.6
这个是服务器和相对应的版本,只是告诉客户端服务器的信息。
9. Transfer-Encoding:chunked
这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
10. Vary: Accept-Encoding
告诉缓存服务器,缓存压缩文件和非压缩文件两个版本,现在这个字段用处并不大,因为现在的浏览器都是支持压缩的。
Cookie 和 Session
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
网页的两种加载方法
- 同步加载:改变网址上的某些请求参数会导致网页发生改变,例如:www.itjuzi.com/company?page=1(改变page=后面的数字,网页会发生改变)
- 异步加载:改变网址上的请求参数不会使网页发生改变,例如:www.lagou.com/gongsi/(翻页后网址不会发生变化)
认识网页源码的构成
在网页中右键点击查看网页源码,可以查看到网页的源代码信息。
源代码一般由三个部分组成,分别是:
- html:描述网页的内容结构
- css:描述网页的排版布局(高深的反爬,css)
- JavaScript(js文件):描述网页的事件处理,即鼠标或键盘在网页元素上的动作后的程序
爬虫协议(了解)
robots协议:网站通过robots协议,告诉我们搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是道德层面上的约束。
2.Request模块
Requests的简单了解
虽然Python的标准库中 urllib 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用:)
Requests 继承了urllib的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
requests 的底层实现其实就是 urllib
Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6–3.5,而且能在PyPy下完美运行。
开源地址:https://github.com/kennethreitz/requests
中文文档 API: http://docs.python-requests.org/zh_CN/latest/index.html
为什么重点学习requests模块,而不是urllib
-
requests的底层实现就是urllib
-
requests在python2和python3中通用,方法完全一样
-
requests简单易用
-
requests能够自动帮助我们解压(gzip压缩的等)网页内容
基本GET请求
1.最基本的get请求
response = requests.get("http://www.baidu.com/")
# 也可以这么写
url="http://www.baidu.com/"
response = requests.get(url)
2.headers头部和params参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests
parmas = {'wd':'长城'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = parmas, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print (response.text) # <html><head>...
# 查看响应内容,response.content返回的字节流数据
print (response.content) # b'\xe9\x95\xbf\xe5\x9f\x8e'
# 查看完整url地址
print (response.url) # http://www.baidu.com/s?wd=%E9%95%BF%E5%9F%8E
# 查看响应头部字符编码
print (response.encoding) # utf-8
# 查看响应码
print (response.status_code) # 200
基本POST请求(DATA参数)
- 最基本post方法
response = requests.post("http://www.baidu.com/", data = data)
- 传入data数据
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
import requests
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data = formdata, headers = headers)
print (response.text)
# **【如果是json文件可以直接显示】**
print (response.json())
代理(proxies) 参数
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
import requests
# **【根据协议类型,选择不同的代理】**
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
私密代理验证 和 Web客户端验证
私密代理
import requests
# **【如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:】**
proxy = { "http": "mr_mao_hacker:sffqry9r@61.158.163.130:16816" }
response = requests.get("http://www.baidu.com", proxies = proxy)
print (response.text)
web客户端验证
如果是Web客户端验证,需要添加 auth = (账户名, 密码)
import requests
auth=('test', '123456')
response = requests.get('http://192.168.199.107', auth = auth)
print (response.text)
Cookies 和 Sission
【1.1 cookie和session的区别】
cookie数据存放在客户的浏览器上,session数据放在服务器上
cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
session会在一定时间内保存在服务器上,当访问增多,会比较占用你服务器的性能
单个cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie
【1.2 爬虫中问什么要使用cookie】
带上cookie的好处:
【能够访问登录后的页面】
【正常的浏览器在请求服务器的时候会带上cookie(第一次请求除外),所以对方服务器有可能会通过是否携带cookie来判断我们是否是一个爬虫,对应的能起到一定的反爬效果】
带上cookie的坏处:
【一套cookie往往对应的是一个用户的信息,请求太频繁有更大可能性被对方识别为爬虫】
【那么,面对这种情况如何解决----使用多个账号】
【1.3 requests处理cookie相关的请求之session】
requests提供了一个叫做session类,来实现客户端和服务端的会话保持
会话保持有两个内涵:
【保存cookie】
【实现和服务器的长连接】
Cookies
如果一个响应中包含了cookie,那么我们可以利用 cookies参数拿到:
import requests
response = requests.get("http://www.baidu.com/")
# **【返回CookieJar对象:】**
cookiejar = response.cookies
# **【将CookieJar转为字典:】**
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print (cookiejar)
print (cookiedict)
运行结果:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
session
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
实现人人网登录
import requests
# **【创建session对象,可以保存Cookie值】**
ssion = requests.session()
# **【处理 headers】**
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# **【需要登录的用户名和密码】**
data = {"email":"mr_mao_hacker@163.com", "password":"alarmchime"}
# **【发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里】**
ssion.post("http://www.renren.com/PLogin.do", data = data)
# **【ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面】**
response = ssion.get("http://www.renren.com/410043129/profile")
# **【打印响应内容】**
print (response.text)
3.chrome抓包
目标:掌握chrome在爬虫中的使用
1. 新建隐身窗口(无痕窗口)
作用:在打开无痕窗口的时候,第一次请求某个网站是没有携带cookie的,和代码请求一个网站一样,这样就能够尽可能理解代码请求某个网站的结果,除非数据是通过js加密加载出来的,不然爬虫请求到的数据和浏览器请求到的数据大部分时候是相同的
2. chrome中network的更多功能
2.1 Perserve log
默认情况下,页面发生跳转之后,之前的请求url地址信息都会消失,勾选perserve log后,之前的请求都会被保留
2.2 filter过滤
在url地址很多的时候,可以在filter中输入部分url地址,对所有的url地址起到一定的过滤效果,具体位置在上面的图中2号位置
2.3 观察特定种类的请求
图中有很多选项,默认是选择all,即会观察到所有种类的请求,很多时候处于自己的目的的可以选择all右边的其他选项,比如常见的选项:
XHR:大部分情况表示ajax请求
JS:js请求
CSS:css请求
但是很多时候我们并不能保证我们需要的请求是什么类型,特别是我们不清楚一个请求是否为ajax请求的时候,直接选择all,从前往后观察即可,其中js,css,图片等不去观察即可
不要被浏览器中的一堆请求吓到了,这些请求中除了js,css,图片请求外,请他的请求并没有多少个
2.4 其他方法
search all file
确定js文件位置
js中添加断点
3. 抓包分析说明
通常,我们所抓的第一个包,就是我们访问这个url地址的响应,在点击所抓的第一个包,右边的headers里面包含了,请求所携带的请求头,响应头等等信息,爬虫在遇到反爬的时候,可以通过查看判断分析,加入缺少的请求信息即可
response里面放入的是请求这个url地址的响应,通常是请求url地址的源码或者json数据
4. 寻找登录接口
4.1 寻找action对的url地址
回顾之前人人网的爬虫我们找到了一个登陆接口,那么这个接口从哪里找到的呢?
可以发现,这个地址就是在登录的form表单中action对应的url地址,回顾前端的知识点,可以发现就是进行表单提交的地址,对应的,提交的数据,仅仅需要:用户名的input标签中,name的值作为键,用户名作为值,密码的input标签中,name的值作为键,密码作为值即可
思考:
如果action对应的没有url地址的时候可以怎么做?
4.2 通过抓包寻找登录的url地址
通过抓包可以发现,在这个url地址和请求体中均有参数,比如uniqueTimestamp和rkey以及加密之后的password
这个时候我们可以观察手机版的登录接口,是否也是一样的
可以发现在手机版中,依然有参数,但是参数的个数少一些,这个时候,我们可以使用手机版作为参看,来学习如何分析js
4.数据解析
正则表达式
正则表达式几十个符号,看似很复杂,但如果能否分清楚类别和作用,就没那么复杂了。
-
字符类别表达 - 表达某一类字符,比如数字,字母,1到9之间的任何数字等(我是大脑瘫记忆法)
正则 匹配 \w 一个字母数字下划线 \s 一个空格 \d 一个数字 \n 一个换行符 \t 一个制表符 \W 不取数字字母下划线 \S 不取空格 \D 不取数字 [abcf] 取abcf中的任意一个字符 [a-f] 上面的简写形式 [^a-f] 不取这其中的字符 . 通配符:除了换行\n之外的任意字符
- 字符的重复次数,也叫做量词。比如身份证是数字重复15或18次,也就是:\d{15}或者\d{18}。
| 正则 | 匹配 |
|---|---|
| * | 0个或者多个 |
| + | 1个或者多个 |
| ? | 0个或者1个 |
| {2} | 2个 |
| {2,5} | 2到5个 |
| {2,} | 至少两个,无上限 |
| {,5} | 最多五个 |
- 组合模式:把多个简单的模式组合在一起,可以是拼接,也可以是二者选其一。
| 正则 | 匹配 |
|---|---|
| \d{6}[a-z]{6} | 表示六个数字后面跟着六个小写英文字母 |
| \d{3}|[a-z]{4} | 表示三个数字或者四个小写字母都可以 |
| (abc){3} | 分组:表示abc abc abc为一组,一共会分出来三组 |
Python正则模块re的用法
re模块是 Python 中用于处理正则表达式的标准库之一。它提供了一系列函数用于对字符串进行模式匹配和搜索,以及对字符串进行替换和分割。
| 方法 | 简介 |
|---|---|
| re.compile | 编译正则表达式 |
| re.search | 搜索匹配模式 |
| re.match | 开头匹配模式 |
| re.findall | 查找所有匹配项 |
| re.finditer | 迭代查找匹配项 |
| re.sub | 替换匹配部分 |
| re.split | 分割字符串 |
| re.fullmatch | 完全匹配字符串 |
详细介绍
re.compile(pattern, flags=0): 编译正则表达式模式,返回一个正则表达式对象。re.match(pattern, string, flags=0): 从字符串的开头开始匹配给定的模式。如果字符串的开头与模式匹配,则返回一个匹配对象;否则返回 None。这意味着match只会在字符串的开头进行匹配。re.search(pattern, string, flags=0): 在字符串中搜索匹配给定的模式。如果字符串中任意位置有匹配项,则返回第一个匹配对象;否则返回 None。search会搜索整个字符串,找到第一个匹配项即返回。re.findall(pattern, string, flags=0): 在字符串中查找所有匹配给定的模式的项,并以列表形式返回所有匹配项。不同于search和match,findall不返回匹配对象,而是返回匹配的字符串列表。re.finditer(pattern, string, flags=0): 在字符串中查找所有匹配的模式,返回一个包含所有匹配项的迭代器。re.sub(pattern, repl, string, count=0, flags=0): 在字符串中搜索给定的模式,并将匹配的部分替换为指定的字符串。re.split(pattern, string, maxsplit=0, flags=0): 根据给定的模式将字符串分割成列表。re.fullmatch(pattern, string, flags=0): 尝试匹配整个字符串,如果字符串与模式完全匹配,则返回一个匹配对象,否则返回 None。
因此,match 主要用于检查字符串的开头是否匹配模式,search 用于在字符串中查找任意位置的匹配项,而 findall 则用于查找字符串中所有的匹配项。
flag能给定的参数:
re.IGNORECASE(或re.I):忽略大小写匹配。re.MULTILINE(或re.M):多行匹配,影响^和$的行为。re.DOTALL(或re.S):使.匹配任何字符,包括换行符。re.VERBOSE(或re.X):忽略空白和注释,使正则表达式更易读。re.ASCII(或re.A):使\w,\W,\b,\B,\d,\D,\s,\S只匹配 ASCII 字符。re.UNICODE(或re.U):使\w,\W,\b,\B,\d,\D,\s,\S匹配 Unicode 字符。re.LOCALE(或re.L):使\w,\W,\b,\B取决于当前区域设置。
注意:贪婪模式和惰性模式
1.贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配(.*)
2.惰性模式:在整个表达式匹配成功的前提下,尽可能少的匹配(.*?)
3.python里数词默认是贪婪的
- 使用贪婪的数量词的正则表达式:
<div>.*</div> - 匹配结果:
<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个"
</div>“时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个”</div>“后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为”<div>test1</div>bb<div>test2</div>"
- 使用非贪婪的数量词的正则表达式:
<div>.*?</div> - 匹配结果:
<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个"
</div>“时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为”<div>test1</div>"。
BS4
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。使用 pip 安装即可:
pip install beautifulsoup4
| 抓取工具 | 速度 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则 | 最快 | 困难 | 无(内置) |
| BeautifulSoup | 慢 | 最简单 | 简单 |
| lxml | 快 | 简单 | 一般 |
四大对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
1. Tag (标签)
Tag 通俗地说就是 HTML 中的一个个标签,例如:
<head><title>The Dormouse's story</title></head>
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
上面的 <title>、<head>、<a>、<p> 等 HTML 标签加上里面包括的内容就是 Tag。通过 Beautiful Soup 来获取 Tags:
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html)
print(soup.title)
# <title>The Dormouse's story</title>
print(soup.head)
# <head><title>The Dormouse's story</title></head>
print(soup.a)
# <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print(soup.p)
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
print(type(soup.p))
# <class 'bs4.element.Tag'>
对于 Tag,它有两个重要的属性,是 name 和 attrs:
print(soup.name)
# [document] # soup 对象本身比较特殊,它的 name 即为 [document]
print(soup.head.name)
# head # 对于其他内部标签,输出的值即为标签本身的名称
print(soup.p.attrs)
# {'class': ['title'], 'name': 'dromouse'}
# 在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
print(soup.p['class']) # soup.p.get('class')
# ['title'] # 还可以利用 get 方法,传入属性的名称,二者是等价的
soup.p['class'] = "newClass"
print(soup.p) # 可以对这些属性和内容进行修改
# <p class="newClass" name="dromouse"><b>The Dormouse's story</b></p>
del soup.p['class'] # 还可以对这个属性进行删除
print(soup.p)
# <p name="dromouse"><b>The Dormouse's story</b></p>
2. NavigableString (可遍历字符串)
NavigableString 对象表示标签内部的文字,可以通过 .string 属性获取。
print(soup.p.string)
# The Dormouse's story
print(type(soup.p.string))
# <class 'bs4.element.NavigableString'>
3. BeautifulSoup
BeautifulSoup 对象表示整个文档的内容,可以当作 Tag 对象,但是有些属性会有所不同。
print(type(soup.name))
# <class 'str'>
print(soup.name)
# [document]
print(soup.attrs) # 文档本身的属性为空
# {}
4. Comment (文档注释)
Comment 对象是一个特殊类型的 NavigableString 对象,其内容是 HTML 文档中的注释。
print(soup.a)
# <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print(soup.a.string)
# Elsie
print(type(soup.a.string))
# <class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容时,注释符号已经被去掉了。
遍历文档树
1. 直接子节点 :.contents .children 属性
.content
tag 的 .content 属性可以将标签的子内容以列表的样式输出出来
print soup.head.contents
#[<title>The Dormouse's story</title>]
输出方式为列表,我们可以用列表索引来获取它的某一个元素
print soup.head.contents[0]
#<title>The Dormouse's story</title>
.children
它返回的不是一个 list,不过我们可以通过遍历获取所有子节点。
我们打印输出 .children 看一下,可以发现它是一个 list 生成器对象
print soup.head.children
#<listiterator object at 0x7f71457f5710>
for child in soup.body.children:
print child
2. 所有子孙节点: .descendants 属性
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似,我们也需要遍历获取其中的内容。
for child in soup.descendants:
print child
3. 节点内容: .string 属性
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
通俗点说就是:如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。例如:
print soup.head.string
#The Dormouse's story
print soup.title.string
#The Dormouse's story
搜索文档树
1.find_all(name, attrs, recursive, text, **kwargs)
参数解释:
-
name: 可以是字符串、正则表达式、列表,用来查找所有名字为 name 的标签。
A.传字符串 :
soup.find_all('b') # [<b>The Dormouse's story</b>]B.传正则表达式:
import re for tag in soup.find_all(re.compile("^b")): print(tag.name) # body # bC.传列表
soup.find_all(["a", "b"]) #找到所有的a和b标签D.keyword 参数
soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] -
attrs: 用于传入字典参数,查找具有特定属性的标签。
-
recursive: 布尔值,指定是否递归搜索子孙节点,默认为 True。
-
text: 可以是字符串、正则表达式、列表,用于搜索文档中的字符串内容。
-
kwargs: 关键字参数,用于匹配具有指定属性值的标签。
CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法.
- 写 CSS 时,标签名不加任何修饰,类名前加
.,id名前加# - 在这里我们也可以利用类似的方法来筛选元素,用到的方法是
soup.select(),返回类型是list - (1)通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]
print soup.select('a')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('b')
#[<b>The Dormouse's story</b>]
(2)通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
(3)通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(4)组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
直接子标签查找,则使用 > 分隔
print soup.select("head > title")
#[<title>The Dormouse's story</title>]
(5)属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(6) 获取内容
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()
Xpath
我正则用的不好,处理HTML文档很累,有没有其他的方法?
有!那就是XPath,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。
1. 什么是XML
- XML 指可扩展标记语言
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义
2. XML和HTML的区别
| 数据格式 | 描述 | 设计目标 |
|---|---|---|
| XML | Extensible Markup Language (可扩展标记语言) | 被设计为传输和存储数据,其焦点是数据的内容。 |
| HTML | HyperText Markup Language (超文本标记语言) | 显示数据以及如何更好显示数据。 |
| HTML DOM | Document Object Model for HTML (文档对象模型) | 通过 HTML DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。 |
3.什么是XPath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
4.XPath语法
选取节点
XPath使用路径来指定在XML文档中选择节点的方法。这些路径表达式类似于我们在文件夹系统中看到的路径,用来定位并选择特定的节点。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选择 bookstore 元素下的前两个 book 元素 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点,包括元素、文本、注释、处理指令等 |
如下:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python 2.7中自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
- 对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。- 数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
您的解释基本正确,但对一些细节进行了纠正和补充:
1. json.loads()
作用:把 JSON 格式的字符串转为 Python 数据类型
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
# 把 JSON 字符串转为 Python 列表
python_list = json.loads(strList)
print(python_list) # [1, 2, 3, 4]
# 把 JSON 字符串转为 Python 字典
python_dict = json.loads(strDict)
print(python_dict) # {'city': '北京', 'name': '大猫'}
2. json.dumps()
作用:把 Python 数据类型转换为 JSON 格式的字符串
import json
# json.dumps()之前
item = {'name': 'QQ', 'app_id': 1}
print('before dumps:', type(item)) # <class 'dict'>
# json.dumps()之后
item_json = json.dumps(item, ensure_ascii=False)
print('after dumps:', type(item_json)) # <class 'str'>
print('JSON string:', item_json) # {"name": "QQ", "app_id": 1}
3. json.dump()
作用:把 Python 数据类型转为 JSON 格式的字符串,并写入文件
# 示例1
import json
item = {'name': 'QQ', 'app_id': 1}
with open('xiaomi.json', 'w', encoding='utf-8') as f:
json.dump(item, f, ensure_ascii=False)
# 示例2
import json
item_list = []
for i in range(3):
item = {'name': 'QQ', 'id': i}
item_list.append(item)
with open('xiaomi_list.json', 'w', encoding='utf-8') as f:
json.dump(item_list, f, ensure_ascii=False)
4. json.load()
作用:从 JSON 文件中读取数据,并转为 Python 数据类型
import json
with open('xiaomi_list.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data) # [{'name': 'QQ', 'id': 0}, {'name': 'QQ', 'id': 1}, {'name': 'QQ', 'id': 2}]
JsonPath(了解)
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ | $ | 根节点 |
. | @ | 现行节点 |
/ | .or[] | 取子节点 |
.. | n/a | 取父节点,Jsonpath未支持 |
// | .. | 就是不管位置,选择所有符合条件的条件 |
* | * | 匹配所有元素节点 |
@ | n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] | [] | 迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选。 |
[] | ?() | 支持过滤操作. |
| n/a | () | 支持表达式计算 |
() | n/a | 分组,JsonPath不支持 |
示例:
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
# jsonpath_lagou.py
import requests
import jsonpath
import json
import chardet
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
response = equests.get(url)
html = response.text
# 把json格式字符串转换成python对象
jsonobj = json.loads(html)
# 从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj,'$..name')
print citylist
print type(citylist)
fp = open('city.json','w')
content = json.dumps(citylist, ensure_ascii=False)
print content
fp.write(content.encode('utf-8'))
fp.close()
拼接连接的库
from urllib.parse import urljoin
parsel库
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据,相比于BeautifulSoup,xpath,parsel效率更高,使用更简单
CSS选择器
无论是使用css选择器,还是xpath,re,都需要先创建一个parsel.Selector对象
from parsel import Selector
# html 可以是请求某个网页的源码,也可以是html,xml格式的字符串
selector = Selector(html)
创建Selector对象之后就可以开始使用了
tags = selector.css('.content')
# 我们平时使用的css中,对某一个标签进行修饰时,使用的是 .class_attr
#在这里也是如此
# .content 就是指查询所有 class 为 content 的标签
# 查询的结果是一个特殊的对象,不能直接得到需要的数据
将css()函数查询到的结果转换为字符串或者列表,需要使用一个函数
get():将css() 查询到的第一个结果转换为str类型getall()将css() 查询到的全部结果转换为list类型
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<body>
<p>css标签选择器的介绍</p>
<p class='p'>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com" title="百度搜索">百度一下</a>
<span> 我是一个span标签</span>
<div id="map">
<p class="content">早上祝您端午节快乐!</p>
</div>
<span id="map">
<p class="content">晚上祝您端午节快乐!</p>
</span>
<span id="text">你好,我是一行文字</span>
</body>
</html>
"""
# 选取所有的p标签
p_tags = selector.css('p')
print(p_tags.get())
# <p>css标签选择器的介绍</p>
print(p_tags.getall())
# 结果
# ['<p>css标签选择器的介绍</p>',
# '<p class="p">标签选择器、类选择器、ID选择器</p>',
# '<p>我是 div > p 标签的文字,我是div 标签的儿子标签</p>',
# '<p class="content">早上祝您端午节快乐!</p>',
# '<p>我是div > span > p 标签中的文字,我是div 标签的孙子标签</p>',
# '<p class="content">晚上祝您端午节快乐!</p>']
# 选择所有class为content的标签
tags = selector.css('.content')
print(type(tags.get()))
# <class 'str'>
print(tags.get())
# <p class="content">早上祝您端午节快乐!</p>
print(type(tags.getall()))
# <class 'list'>
print(tags.getall())
# ['<p class="content">早上祝您端午节快乐!</p>', '<p class="content">晚上祝您端午节快乐!</p>']
# 选取id为text的所有标签
text = selector.css('#text')
print(text.get())
# <span id="text">你好,我是一行文字</span>
# 属性提取器
# 分别提取a标签中的href和title属性值
href_value = selector.css('a::attr(href)').get()
print(href_value)
# https://www.baidu.com
title_value = selector.css('a::attr(title)').get()
print(title_value)
# 百度搜索
# 提取文字
string = selector.css('#text::text').get()
print(string)
# 你好,我是一行文字
# id为map的标签内的p标签,且p标签的class为content,提取出该标签的文字
content = selector.css('#map p.content::text').getall()
print(content)
# ['早上祝您端午节快乐!', '晚上祝您端午节快乐!']
# id为map的span标签,该标签内的p标签,且该p标签的class为content,提取出该标签的文字
content2 = selector.css('span#map p.content::text').getall()
print(content2)
# ['晚上祝您端午节快乐!']
# id为map的标签,该标签内class为content的标签,提取出该标签的文字
content3 = selector.css('#map .content::text').getall()
print(content3)
# ['早上祝您端午节快乐!', '晚上祝您端午节快乐!']
# 子选择器和孙子选择器
son_tags = selector.css('#map > p')
pprint(son_tags.getall())
# ['<p>我是 div > p 标签的文字,我是div 标签的儿子标签</p>',
# '<p class="content">早上祝您端午节快乐!</p>',
# '<p class="content">晚上祝您端午节快乐!</p>']
sunzi_tags = selector.css('#map p')
pprint(sunzi_tags.getall())
# ['<p>我是 div > p 标签的文字,我是div 标签的儿子标签</p>',
# '<p class="content">早上祝您端午节快乐!</p>',
# '<p>我是div > span > p 标签中的文字,我是div 标签的孙子标签</p>',
# '<p class="content">晚上祝您端午节快乐!</p>']
5.高效率爬虫
在爬虫中进程、线程、协程用的其实并不多,在你遇到需要下载图片、视频、文件等操作的时候可以采用进程、线程、协程等方式来加速爬取的需求,但是一般的网站是有访问的限制的,在使用的时候也要注意,在网络编程详细的学过了进程、线程、协程的知识点,其实在爬虫中进程、线程使用的大部分都是线程池、进程池
9.1多线程
多线程的本质就是在程序中开辟多个助手协助运行,所以在下载图片、视频等操作的时候,一个人下载一定是比不上一群人下载的,但是在爬虫的使用场景,因为我们还要涉及到管理线程的问题,所以直接使用线程池即可
from concurrent.futures import ThreadPoolExecutor as ThreadPool
'''
多线程爬取4k壁纸网
'''
import requests
from bs4 import BeautifulSoup
import time
import os
from concurrent.futures import ThreadPoolExecutor as ThreadPool
from urllib.parse import urljoin
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
# 下载图片
def download_image(img_url,title):
try:
resp = requests.get(img_url, headers=headers)
resp.encoding = 'gbk'
filename = title + '.jpg'
if not os.path.exists('./img/'):
os.makedirs('./img/')
with open('./img/' + filename, 'wb') as f:
f.write(resp.content)
print("下载完成:" + filename)
except Exception as e:
print(f"下载失败:{img_url},错误信息:{e}")
# 内部壁纸页面
def process_wallpaper_page(href,title):
try:
response = requests.get(href, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'html.parser')
img_url = soup.find('div', attrs={"class": "photo-pic"}).find("img").get('src')
img_url = urljoin(href, img_url)
download_image(img_url,title)
except Exception as e:
print(f"处理页面失败:{href},错误信息:{e}")
def get_pic(url):
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'html.parser')
a_list = soup.find('ul', attrs={"class": "clearfix"}).find_all("a")
print("共有" + str(len(a_list)) + "张壁纸")
with ThreadPool(max_workers=10) as pool:
for a in a_list:
href = a.get("href")
title = a.find("b").text
href = urljoin(url, href)
pool.submit(process_wallpaper_page, href,title)
if __name__ == '__main__':
start_time = time.time()
for i in range(2, 11):
url = f'https://pic.netbian.com/4kdongman/index_{i}.html'
print(f"正在下载第{i}页")
get_pic(url)
end_time = time.time()
print(f"下载完成,耗时 {end_time - start_time:.2f} 秒")
9.2多进程
因为进程是额外开辟程序,所以一般情况下进程是不单独使用的,会使用上生产消费者模型搭配线程一起使用
'''
多进程爬取4K壁纸网
生产者-消费者模型
'''
import requests
import os
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor
from multiprocessing import Process
from lxml import etree
import time
from multiprocessing import Queue # 进程间通信队列
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
# 生产者
def get_url(q):
for page in range(1, 10):
url = f'https://pic.netbian.com/4kdongman/index_{page}.html'
resp = requests.get(url, headers=headers)
resp.encoding = 'gbk'
html = etree.HTML(resp.text) #type: etree._Element
img_urls = html.xpath('//div[@class="slist"]//a//@href')
# /tupian/34379.html
for img_url in img_urls:
img_url = urljoin('https://pic.netbian.com/', img_url)
q.put(img_url)
print(f'开始下载第{page}页图片')
q.put('没数据了,快走吧') # 通知消费者结束
# 队列中转站
def img_producer(q):
with ThreadPoolExecutor(max_workers=4) as executor:
while True:
img_url = q.get()
if img_url == '没数据了,快走吧':
break
executor.submit(download_img, img_url)
# 消费者
def download_img(img_url):
'''
下载图片
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
resp = requests.get(img_url, headers=headers)
resp.encoding = 'gbk'
html = etree.HTML(resp.text) #type: etree._Element
img_url = html.xpath('//div[@class="photo-pic"]//img//@src')[0]
# 拼接完整的url
img_url = urljoin('https://pic.netbian.com/', img_url)
resp = requests.get(img_url, headers=headers)
# 下载图片
img_name = img_url.split('/')[-1]
if os.path.exists(f'./img/{img_name}'):
print(f'{img_name}已存在')
return
with open(f'./img/{img_name}', 'wb') as f:
f.write(resp.content)
print(f'{img_name}下载完成')
if __name__ == '__main__':
start_time = time.time()
q = Queue() # 准备一个队列
p1 = Process(target=get_url, args=(q,))
p2 = Process(target=img_producer, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
end_time = time.time()
print(f'总共耗时{end_time-start_time:.2f}秒')
# 多进程 总共耗时3.96秒
9.3异步协程
下载图片、最强、最快的一种模式,遇到IO就切换
'''
异步爬取小说网站
1.拿到主页面的源代码(不需要异步)
2.解析主页面的源代码,获取小说的链接
3.建立一个字典、将小说的章节标题、章节、链接作为键值对存入字典
4.根据字典中的链接,异步抓取每个章节的源代码,并解析出章节标题、章节内容
5.异步下载每个章节的内容,并保存到本地
'''
import os
import requests
import asyncio
# ===外部库======
import aiohttp
from lxml import etree
import aiofiles
# ===全局变量====
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# ===函数定义====
def get_novel_url(url):
result = []
resp = requests.get(url, headers=headers)
resp.encoding = 'utf-8'
if resp.status_code == 200:
html = etree.HTML(resp.text) #type: etree._Element
divs = html.xpath("//div[@class='mulu']")
print(f'{url}共有{len(divs)}章') # 打印出小说的章节数
for div in divs:
main_title = div.xpath(".//table//tr")
# 主标题
title = main_title[0].xpath(".//a/text()")
title = ''.join(title).strip().replace(':', '_')
for t in main_title[1:]:
# 这样太乱了,我们改进一下
# text = t.xpath("./td//text()")
# urls = t.xpath("./td//a/@href")
# print(title, text,urls)
tds = t.xpath("./td")
for td in tds:
text = td.xpath(".//text()")
href = td.xpath(".//@href")
text = ''.join(text).replace(' ', '').strip()
href = ''.join(href).strip()
dic = {
'title': title,
'text': text,
'href': href
}
result.append(dic)
return result
async def download_one(url,file_name):
print(f'开始下载{file_name}')
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers) as response:
if response.status == 200:
page_content = await response.text('utf-8')
container = etree.HTML(page_content)
content = container.xpath("//div[@class='content']/p//text()")
content = ''.join(content).strip()
# 写入文件
async with aiofiles.open(file_name,'w',encoding='utf-8') as f:
await f.write(content)
print(f'{file_name}下载完成')
async def download_chapter(url):
tasks = []
for chapter in url:
title = chapter['title'] #文件夹名
text = chapter['text'] #文件名
href = chapter['href'] #用来下载
if not os.path.exists(title):
os.makedirs(title)
file_name = f'{title}/{text}.txt'
t = asyncio.create_task(download_one(href,file_name))
tasks.append(t)
await asyncio.wait(tasks)
def main():
url = 'https://www.mingchaonaxieshier.com/'
novel_list = get_novel_url(url)
print(f'{novel_list}')
# 异步抓取小 说内容
loop = asyncio.get_event_loop()
loop.run_until_complete(download_chapter(novel_list))
loop.close()
if __name__ == '__main__':
main()
6.selenium
selenium本身是一个自动化测试工具。它可以让python代码调用浏览器。并获取到浏览器中加载的各种资源。 我们可以利用selenium提供的各项功能。 帮助我们完成数据的抓取。
我们在抓取一些普通网页的时候requests基本上是可以满足的. 但是, 如果遇到一些特殊的网站. 它的数据是经过加密的. 但是呢, 浏览器却能够正常显示出来. 那我们通过requests抓取到的内容可能就不是我们想要的结果了.
1.对页面进行操作
-
1.1 初始化浏览器对象
get('url'): 启动一个浏览器页面并打开指定的URL。
from selenium.webdriver import Edge import time # 启动Edge引擎 web = Edge() # 访问百度首页 web.get('https://www.baidu.com/') # 关闭浏览器 web.close() # 挂载页面 time.sleep(9999) -
1.2设置浏览器窗口大小
set_window_size(width, height): 设置浏览器窗口的宽度和高度。maximize_window(): 将浏览器窗口最大化。
from selenium import webdriver import time browser = webdriver.Chrome() # 设置浏览器大小:全屏 browser.maximize_window() browser.get('https://www.baidu.com') time.sleep(2) # 设置分辨率 500*500 browser.set_window_size(500,500) time.sleep(2) # 关闭浏览器 browser.close() -
1.3浏览器前进和后退
back(): 后退到浏览历史中的上一个页面。forward(): 前进到浏览历史中的下一个页面。refresh(): 刷新当前页面。
from selenium.webdriver import Edge from time import sleep web = Edge() # 访问b站首页 web.get('https://www.bilibili.com/?spm_id_from=333.999.0.0') sleep(2) # 访问B站个人主页 web.get('https://space.bilibili.com/361040115?spm_id_from=333.788.0.0') sleep(2) # 返回(后退)到b站首页 web.back() sleep(2) web.forward() sleep(2) # 刷新该页面 web.refresh() web.refresh() web.refresh() web.refresh() web.refresh() sleep(999) -
1.4浏览器窗口切换
-
虽然视觉效果上窗口的确有切换,但是selenium内核并没有进行切换操作,所以需要切换句柄来让它能够识别到该页面
window_handles: 获取当前打开的所有窗口句柄。switch_to.window(handle): 切换到指定句柄对应的窗口。
# 获取打开的多个窗口句柄 windows = web.window_handles # 切换到当前最新打开的窗口 web.switch_to.window(windows[-1]) # 切换到第一个打开的页面 web.switch_to.window(windows[0]) -
1.5iframe切换
switch_to.frame(frame_reference): 切换到指定的iframe。
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
web = Chrome()
web.get("http://www.wbdy.tv/play/42491_1_1.html")
# 找到那个iframe
iframe = web.find_element(By.XPATH, '//iframe[@id="mplay"]')
web.switch_to.frame(iframe)
val = web.find_element(By.XPATH, '//input[@class="dplayer-comment-input"]').get_attribute("placeholder")
print(val)
# 调整回上层结构
web.switch_to.parent_frame()
xxx = web.find_element(By.XPATH, '/html/body/div[2]/div[3]/div[2]/div/div[2]/h2').text
print(xxx)
-
1.6获取页面基础属性
-
当我们用selenium打开某个页面,有一些基础属性如网页标题、网址、浏览器名称、页面源码等信息
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.baidu.com') # 网页标题 print(browser.title) # 当前网址 print(browser.current_url) # 浏览器名称 print(browser.name) # 网页源码 print(browser.page_source)
-
2. 常见操作
find_element(by, value): 查找页面上符合条件的第一个元素。find_elements(by, value): 查找页面上符合条件的所有元素,返回列表。- By后的属性如下
| 属性 | 函数 |
|---|---|
| CLASS | find_element(by=By.CLASS_NAME, value=‘’) |
| XPATH | find_element(by=By.XPATH, value=‘’) |
| LINK_TEXT | find_element(by=By.LINK_TEXT, value=‘’) |
| PARTIAL_LINK_TEXT | find_element(by=By.PARTIAL_LINK_TEXT, value=‘’) |
| TAG | find_element(by=By.TAG_NAME, value=‘’) |
| CSS | find_element(by=By.CSS_SELECTOR, value=‘’) |
| ID | find_element(by=By.ID, value=‘’) |
is_displayed(): 判断元素是否可见。send_keys(*value): 向元素发送键盘输入。web.implicitly_wait(10):隐式等待十秒钟
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.keys import Keys
web = webdriver.Edge()
web.get('https://www.bilibili.com/?spm_id_from=333.999.0.0')
sleep(2)
web.implicitly_wait(10)
# 定位搜索输入框
text_label = web.find_element(by='xpath', value='//*[@id="nav-searchform"]/div[1]/input')
# 在搜索框中输入 Dream丶Killer
text_label.send_keys('Dream丶Killer', Keys.ENTER)
sleep(2)
# 输出搜索框元素是否可见
print(text_label.is_displayed()) #return bool
# 输出placeholder(页面上显示的提示信息)的值
print(text_label.get_attribute('placeholder'))
3. 鼠标控制
既然是模拟浏览器操作,自然也就需要能模拟鼠标的一些操作了,这里需要导入ActionChains 类。
from selenium.webdriver.common.action_chains import ActionChains
| 操作 | 函数 |
|---|---|
| 右击 | context_click() |
| 双击 | double_click() |
| 拖拽 | double_and_drop() |
| 悬停 | move_to_element() |
| 执行 | perform() |
-
鼠标移动至元素位置:
-
move_to_element(to_element): 将鼠标移动至指定元素的位置。 -
move_to_element_with_offset(to_element, xoffset, yoffset): 将鼠标移动至指定元素位置的偏移量处。from selenium.webdriver.common.action_chains import ActionChains # 移动至元素位置 element = web.find_element(By.XPATH, '//button[@id="button"]') ActionChains(web).move_to_element(element).perform() #==================适用xy坐抓取b站点选验证码======================================= from selenium.webdriver import Edge from selenium.webdriver.common.by import By # 动作链 from selenium.webdriver.common.action_chains import ActionChains from time import sleep import requests import base64 import json def base64_api(uname, pwd, img, typeid): with open(img, 'rb') as f: base64_data = base64.b64encode(f.read()) b64 = base64_data.decode() data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] web = Edge() web.get('https://www.bilibili.com/?spm_id_from=333.999.0.0') web.implicitly_wait(10) # 隐式等待 web.find_element(By.XPATH,'//*[@class="header-login-entry"]').click() web.find_element(By.XPATH,'/html/body/div[4]/div/div[4]/div[2]/form/div[1]/input').send_keys('2561561') web.find_element(By.XPATH,'/html/body/div[4]/div/div[4]/div[2]/form/div[3]/input').send_keys('123456') # 点击登录按钮 web.find_element(By.XPATH,'/html/body/div[4]/div/div[4]/div[2]/div[2]/div[2]').click() sleep(2) img = web.find_element(By.XPATH,'//*[@class="geetest_widget"]') img.screenshot('captcha.png') result = base64_api('Prorsie', 'Maicol7896', 'captcha.png', 27) print(result) # 101,80|156,236|251,92|165,165 res = result.split('|') for i in res: x, y = i.split(',') print(x,y) x = int(x) y = int(y) # 移动鼠标到验证码位置 ActionChains(web).move_to_element_with_offset(img, x, y).click().perform()
-
-
点击鼠标左键:
-
click(on_element=None): 在当前鼠标位置左键单击。如果提供了元素参数,则在该元素位置左键单击。from selenium.webdriver.common.action_chains import ActionChains # 单击元素 element = web.find_element(By.XPATH, '//button[@id="button"]') ActionChains(web).click(element).perform()
-
-
点击鼠标右键:
-
context_click(on_element=None): 在当前鼠标位置右键单击。如果提供了元素参数,则在该元素位置右键单击。from selenium.webdriver.common.action_chains import ActionChains # 右键单击元素 element = web.find_element(By.XPATH, '//button[@id="button"]') ActionChains(web).context_click(element).perform()
-
-
双击鼠标左键:
-
double_click(on_element=None): 在当前鼠标位置双击左键。如果提供了元素参数,则在该元素位置双击左键。from selenium.webdriver.common.action_chains import ActionChains # 双击元素 element = web.find_element(By.XPATH, '//button[@id="button"]') ActionChains(web).double_click(element).perform()
-
-
拖拽操作:
-
drag_and_drop(source, target): 将源元素拖拽至目标元素。 -
drag_and_drop_by_offset(source, xoffset, yoffset): 将源元素拖拽至指定偏移量处。from selenium.webdriver.common.action_chains import ActionChains # 拖拽元素至指定位置 source_element = web.find_element(By.XPATH, '//div[@id="source"]') target_element = web.find_element(By.XPATH, '//div[@id="target"]') ActionChains(web).drag_and_drop(source_element, target_element).perform()
-
-
长按与释放鼠标:
-
click_and_hold(on_element=None): 在当前鼠标位置按住左键。如果提供了元素参数,则在该元素位置按住左键。 -
release(on_element=None): 释放鼠标左键。如果提供了元素参数,则在该元素位置释放左键。from selenium.webdriver.common.action_chains import ActionChains # 在元素位置释放鼠标左键 element = web.find_element(By.XPATH, '//button[@id="button"]') ActionChains(web).click_and_hold(element).release().perform()
-
4.模拟键盘操作
引入Keys类
from selenium.webdriver.common.keys import Keys
| 操作 | 函数 |
|---|---|
| 删除键 | send_keys(Keys.BACK_SPACE) |
| 空格键 | send_keys(Keys.SPACE) |
| 制表键 | send_keys(Keys.TAB) |
| 回退键 | send_keys(Keys.ESCAPE) |
| 回车 | send_keys(Keys.ENTER) |
| 全选 | send_keys(Keys.CONTRL,‘a’) |
| 复制 | send_keys(Keys.CONTRL,‘c’) |
| 剪切 | send_keys(Keys.CONTRL,‘x’) |
| 粘贴 | send_keys(Keys.CONTRL,‘x’) |
| 键盘F1 | send_keys(Keys.F1) |
5. 延时等待
如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候尝试在get方法执行完成时获取网页源代码可能并非浏览器完全加载完成的页面。所以,这种情况下需要设置延时等待一定时间,确保全部节点都加载出来。 三种方式:强制等待、隐式等待和显式等待。
所需导入的模块和包
-
selenium.webdriver: 包含浏览器驱动程序 -
selenium.webdriver.support.ui.WebDriverWait: 用于显式等待 -
selenium.webdriver.support import expected_conditions as EC: 包含各种预期条件 -
selenium.webdriver.common.by import By: 用于元素定位 -
time: 用于强制等待#包含浏览器驱动程序 from selenium.webdriver import Edge #用于显式等待 from selenium.webdriver.support import expected_conditions as EC #包含各种预期条件 from selenium.webdriver.support.ui import WebDriverWait #用于元素定位 from selenium.webdriver.common.by import By #用于强制等待 import time
5.1 强制等待
直接使用 time.sleep(n) 强制等待n秒,在执行get方法之后执行。
5.2 隐式等待
implicitly_wait() 设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
5.3 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
WebDriverWait的参数说明:WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
-
driver: 浏览器驱动,控制浏览器的操作。
-
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)。
-
poll_frequency: 每次检测的间隔时间,默认是0.5秒。
-
ignored_exceptions: 超时后的异常信息,默认情况下抛出
NoSuchElementException异常。以下的内容直接复制即可
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 示例使用 until 方法等待元素可见
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, 'element_id')),
message='Element not visible within the given timeout'
)
# 示例使用 until_not 方法等待元素消失
WebDriverWait(driver, 10).until_not(
EC.presence_of_element_located((By.ID, 'element_id')),
message='Element still present within the given timeout'
)
5.4判断预期
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
# 判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
# 判断是否有alert出现
alert_is_present
# 判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
# 判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
6.对Cookie操作
cookies 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 cookie持久化,即先用 selenium 模拟登陆获取 cookie ,再通过 requests 携带 cookie 进行请求。
webdriver 提供 cookies 的几种操作:读取、添加删除。
get_cookies:以字典的形式返回当前会话中可见的 cookie 信息。
get_cookie(name):返回 cookie 字典中 key == name 的 cookie 信息
add_cookie(cookie_dict):将 cookie 添加到当前会话中
delete_cookie(name):删除指定名称的单个
cookie delete_all_cookies():删除会话范围内的所有cookie
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
# 总结
7.高级用法
7.1.execute_script方法
比如下拉进度条,模拟javaScript,使用execute_script方法来实现。
1.1 判断元素是否存在
def is_element_exist(browser,xpath):
try:
element=browser.find_element(by=By.XPATH,value=xpath)
flag=True
except:
flag=False
return flag
1.2 滑动滚轮到页面底端
temp_height=0
x=1000
y=1000
while True:
js="var q=document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop={}".format(x)
browser.excute_script(js)
time.sleep(0.5)
x+=y
check_height=browser.excute_script("return document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop;")
if check_height=temp_height:
break
temp_height=check_height
1.3 滑动滚轮至页面元素出现
temp_height=0
x=1000
y=1000
while True:
js="var q=document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop={}".format(x)
browser.excute_script(js)
time.sleep(0.5)
x+=y
check_height=browser.excute_script("return document.getElementsByClassName('cdk-virtual-scroll-viewport')[0].scrollTop;")
if check_height=temp_height:
break
temp_height=check_height
1.4 滑动至动态元素可见
当我们需要定位的元素是动态元素,或者我们不确定它在哪时,可以先找到这个元素然后再使用JS操作
target = driver.find_element_by_id('id')
driver.execute_script("arguments[0].scrollIntoView();", target)
8.无头浏览器
我们已经基本了解了selenium的基本使用了. 但是呢, 不知各位有没有发现, 每次打开浏览器的时间都比较长. 这就比较耗时了. 我们写的是爬虫程序. 目的是数据. 并不是想看网页. 那能不能让浏览器在后台跑呢? 答案是可以的.
需要导入如下的包附上代码:
from selenium.webdriver import Edge
# 专门处理网页的<Select>标签
from selenium.webdriver.support.select import Select
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
# 设置无头模式
opt = Options()
opt.add_argument("--headless")
opt.add_argument('--disable-gpu')
opt.add_argument("--window-size=4000,1600") # 设置窗口大小
web = Edge(options=opt)
web.get('https://www.endata.com.cn/BoxOffice/BO/Year/index.html')
# 切换select
sel = Select(web.find_element(By.XPATH,'//*[@id="OptionDate"]'))
for i in range(len(sel.options)):
sel.select_by_index(i) # 按照索引位置切换
time.sleep(1)
table = web.find_element(By.XPATH,'//*[@id="TableList"]/table')
print("===========================================")
print(table.text)
9.图鉴
图片识别-广告识别-目标检测-图鉴网络科技有限公司 (ttshitu.com)
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg"
result = base64_api(uname='Prorsie', pwd='Maicol7896', img=img_path, typeid=3)
print(result)
10.绕过服务器检测自动化
from selenium.webdriver.chrome.options import Options
# 亲测, 88版本以后可以用.
option = Options()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--disable-blink-features=AutomationControlled')
# 亲测, 88版本之前可以用.
# web = Chrome()
#
# web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
# "source": """
# navigator.webdriver = undefined
# Object.defineProperty(navigator, 'webdriver', {
# get: () => undefined
# })
# """
# })
7.简单的反爬虫机制
反爬虫机制:
- 封IP:监控短时间内同一地址的请求次数过大
- 登录及验证码:对于监控后封IP之后短时间内继续的大量请求,要求登陆或验证码通过验证之后才能继续进行。
- 健全账号体制:即核心数据只能通过账号登录后才能进行访问。
- 动态加载数据:数据通过js进行加载,增加网站分析难度。
应对策略:
- 伪造请求头(伪装浏览器):故意告诉浏览器我不是爬虫程序我是浏览器。
- 代理IP访问:针对同一时间内大量请求网站数据遭到封IP,使用代理IP不断更换请求地址,迷惑网站,躲过反制措施。
- 请求过于频繁会触发验证码,则模拟用户操作,限制爬虫请求次数及频率,降低验证码机制的风险
- 使用对应的验证码识别手段通过网站验证
- 使用第三方工具完全模拟浏览器操作(selenium+webdriver)
常见反爬机制1:代理IP
- 定义及作用
- 定义: 代替你原来的IP地址去对接网络的IP地址
- 作用: 隐藏自身真实IP,避免被封
- 获取代理IP的网站
- 西刺代理、快代理、全网代理、代理精灵、… …
- 代理IP的分类
- 透明代理: 服务端能看到 - (用户真实IP 以及 代理IP)
- 普通代理(匿名代理): - (服务端能知道有人通过此代理IP访问了网站,但不知用户真实IP)
- 高匿代理: - (服务端不能看到代理IP)
- 常用代理IP类型的特点
- 普通代理: 可用率低、速度慢、不稳定、免费或价格便宜
- 私密代理: 可用率高、速度较快、价格适中、爬虫常用
- 独享代理: 可用率极高、速度快、价格贵
默认添加:
1、语法结构
proxies = {
'协议':'协议://IP:端口号'
}
2、示例
proxies = {
'http':'http://IP:端口号',
'https':'https://IP:端口号'
}
# 私密代理+独享代理
1、语法结构
proxies = {
'协议':'协议://用户名:密码@IP:端口号'
}
2、示例
proxies = {
'http':'http://用户名:密码@IP:端口号',
'https':'https://用户名:密码@IP:端口号'
}
# 普通代理
import requests
url = 'http://httpbin.org/get'
headers = {
'User-Agent':'Mozilla/5.0'
}
# 定义代理,在代理IP网站中查找免费代理IP
proxies = {
'http':'http://112.85.164.220:9999',
'https':'https://112.85.164.220:9999'
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
# 私密代理
import requests
url = 'http://httpbin.org/get'
proxies = {
'http': 'http://用户名:密码@106.75.71.140:16816',
'https':'https://用户名:密码@106.75.71.140:16816',
}
headers = {
'User-Agent' : 'Mozilla/5.0',
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
代理IP池
'''
思路:
1. 采集免费代理IP:写爬虫、储存在redis
2. 去验证这些ip是否可用:从redis读取到ip简单发送一个请求测试
如果请求可用那就吧IP的score提升
如果请求不可用,那就把IP的score降低
3. 给用户提供可以访问的api接口:提供可用的ip地址
这是三件事,所以需要用到多进程来分别干这些事情
'''
一些默认的设置:可供用户调整
'''
存放配置的地方
'''
# REDIS配置
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
REDIS_DB = 0
REDIS_PASSWORD = '123456'
# REDIS的KEY
REDIS_KEY = 'proxy_ip'
(1)首先解决redis的逻辑问题,这也是最难的一步
- 1.通过init函数建立数据库连接
- 2.在
add_proxy_ip方法中,通过zscore方法判断数据库中是否存在该IP - 3.在
get_proxy_ip方法中,通过zrange方法获取所有IP - 4.在
set_max_score方法中,通过zadd方法设置IP的最高分值(验证成功) - 5.在
desc_score方法中,通过zincrby方法减少分数,如果分数减少到0或以下,通过zrem方法删除IP - 6.在
get_valid_ip方法中,通过zrangebyscore方法获取分数在80到100之间的IP,然后随机选择一个
'''
提供有关redis操作的方法
1.查询
2.新增、增加分数
3.删除
'''
from redis import Redis
# 导入setting里的默认参数
from settings import *
import random
class ProxyRedis(object):
# self.redis 连接
def __init__(self):
self.redis = Redis(
host=REDIS_HOST,
port=REDIS_PORT,
db=REDIS_DB,
password=REDIS_PASSWORD,
decode_responses=True
)
def add_proxy_ip(self,ip):
# 1.判断是否有ip
if not self.redis.zscore(REDIS_KEY,ip):
self.redis.zadd(REDIS_KEY,{ip:10})
print(f'采集到新的IP地址:{ip} ')
else:
print(f'IP地址已存在:{ip}')
def get_proxy_ip(self):
'''获取所有IP'''
return self.redis.zrange(REDIS_KEY,0,-1)
def set_max_score(self,ip):
'''设置有效IP为最高分数'''
self.redis.zadd(REDIS_KEY,{ip:100})
def desc_score(self,ip):
'''减少分数'''
# 1.判断分数、若扣光了,则删除
score = self.redis.zscore(REDIS_KEY,ip)
if score > 0:
self.redis.zincrby(REDIS_KEY,-2,ip)
else:
self.redis.zrem(REDIS_KEY,ip)
def get_valid_ip(self):
'''获取有效IP'''
ips = self.redis.zrangebyscore(REDIS_KEY, 80, 100, 0, -1)
if ips:
return random.choice(ips)
return None
(2)IP采集
'''
负责IP采集
'''
import time
import requests
from lxml import etree
import re
# 导入Redis的类
from ip_redis import ProxyRedis
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
def get_kuai_ip(url,redis):
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
# 使用XPath找到包含JavaScript数据的<script>标签
script_tag = html.xpath('//script[contains(text(), "var $postBtn")]')
for s in script_tag:
# 提取出IP
ip_list = re.findall(r'"ip": "(.*?)"',s.text)
pors_list = re.findall(r'"port": "(.*?)"',s.text)
if not ip_list and pors_list:
continue
ip = ip_list[0]
port = pors_list[0]
proxy = ip+':'+port
print(proxy)
# 调用redis类的采集方法
redis.add_proxy_ip(proxy)
def run():
red = ProxyRedis()
for u in range(1, 50):
url = 'https://www.kuaidaili.com/free/intr/' + str(u)
get_kuai_ip(url, red)
time.sleep(1)
if __name__ == '__main__' :
run()
(3)IP验证
'''
负责IP的验证工作
'''
from ip_redis import ProxyRedis
import asyncio
import aiohttp
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
async def verify_ip(ip, sem, red):
print(f'开始验证{ip}的可用性....')
timeout = aiohttp.ClientTimeout(total=10)
async with sem:
try:
# 验证IP
async with aiohttp.ClientSession() as session:
async with session.get('https://www.baidu.com/',proxy='http://'+ip,timeout=timeout,headers=headers) as response:
page_source = await response.text()
if response.status in [200,302,301,304]:
# 验证通过
red.set_max_score(ip)
print(f'{ip}验证通过')
else:
red.desc_score(ip)
print(f'{ip}验证失败')
except Exception as e:
red.desc_score(ip)
print(f'{ip}验证有错误',e)
async def main(red):
# 获取所有的IP
all_proxies = red.get_proxy_ip()
sem = asyncio.Semaphore(30)
task = []
for ip in all_proxies:
task.append(asyncio.create_task(verify_ip(ip,sem,red)))
if task:
await asyncio.gather(*task)
def run():
red = ProxyRedis()
# 初始等待
time.sleep(10)
while True:
try:
asyncio.run(main(red))
time.sleep(40)
except Exception as e:
print('在验证IP时出错', e)
time.sleep(10)
if __name__ == '__main__':
run()
主程序:
from ip_collection import run as ip_collection_run
from ip_veryify import run as ip_veryify_run
from ip_redis import ProxyRedis
from msultiprocessing import Process
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'}
def get_proxy():
redis = ProxyRedis()
url = redis.get_valid_ip()
# resp = requests.get(url,headers=headers)
dic = {
'ip': url,
}
proxy = {
'http': 'http://' + str(dic['ip']),
}
return proxy
proxy = get_proxy()
print(f"可用的代理ip:{proxy['http']}")
def run():
p1 = Process(target=ip_collection_run)
p2 = Process(target=ip_veryify_run)
p1.start()
p2.start()
if __name__ == '__main__':
run()
常见反爬机制2:动态页面爬虫技术
控制台抓包思路
-
静态页面
一种常见的网站、网页类型。我们爬虫所关注的特点是:该类网站的一次html请求的response中包含部分或所有所需的目标数据。
注意:静态网页目前来看存在于:
- 确确实实没什么技术含量的小网站…
- 对安全性关注度不高的某些数据,采用静态页面直接渲染出来。
特点:此类静态页面包含的数据对企业或机构来说无关痛痒,即不是那么的重要,而静态页面直接渲染的方式相对来说对技术要求又不高,成本较低,所以直接渲染出来,你爱爬你就爬无所谓
-
动态网页
一种常见的网站、网页类型。此类网页才是WWW中最常见的网页。基本现在但凡是个规模的网站,大部分都采用了动态页面技术。动态页面不会将数据直接渲染在response中,且不会一次刷新就全部加载完毕,而是伴随用户对页面的操作实现局部刷新。
动态页面的核心特点是:
- 数据不会直接渲染于response中;
- 大部分动态页面都会采用AJAX异步请求进行局部刷新;
- 结合以上特点,对响应的数据进行处理,通常采用js进行加载,且处理过程通常伴随着加密。
所以,动态页面在爬取的过程中难度就增大了,不仅要对响应页面做处理,更重要的是要追踪js加载方式甚至追踪js代码,深层次剖析请求及响应的数据体,进而采用Python进行模拟js操作,实现获取真实数据及破解加密。
如何判断一个页面是静态页面还是动态页面?
一般具有以下几个特征的页面,基本就是动态页面了:
- 几乎统一采用json格式字符串传递;
- 往往伴随着用户对网页的某些操作,比如鼠标事件,键盘事件等;
- 几乎无法直接在html的response中直观看到数据;
- html的response中不存在所需数据怎么办?
如果当前页面的html请求的response中不存在所需数据,但elements选项中能够使用re或xpath解析到我们所需要的数据,则所需数据一定是进行了响应处理,则可以通过控制台抓包分析查找所需数据。
控制台抓包分析
- 打开浏览器,F12打开控制台,找到Network选项卡
- 控制台常用选项
- Network: 抓取网络数据包
- ALL: 抓取所有的网络数据包
- XHR:抓取异步加载的网络数据包
- JS : 抓取所有的JS文件
- Sources: 格式化输出并打断点调试JavaScript代码,助于分析爬虫中一些参数
- Console: 交互模式,可对JavaScript中的代码进行测试
- Network: 抓取网络数据包
取具体网络数据包后
- 单击左侧网络数据包地址,进入数据包详情,查看右侧
- 右侧:
- Headers: 整个请求信息:General、Response Headers、Request Headers、Query String、Form Data
- Preview: 对响应内容进行预览
- Response:响应内容
动态加载页面的数据爬取-AJAX
AJAX(Asynchronous JavaScript And XML):异步的JavaScript and XML。通过在后台与服务器进行商量的数据交换,Ajax可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必须重载整个网页页面。又因为传统的数据传输格式使用的是XML语法,因此叫做Ajax。但现如今的数据交互方式,基本上都选择使用JSON格式的字符串,其目的就是为了达到数据传输格式的统一。因为json支持几乎所有编程语言。使用Ajax加载的数据,即使有对应的JS脚本,能够将数据渲染到浏览器中,在查看网页源码时还是不能看到通过Ajax加载的数据,只能看到使用这个url加载的HTML代码。
动态页面数据抓取固定套路
- 请求目标url;
- F12打开控制台进行抓包分析;F12 – network – XHR/JS – 网页操作 – / 查看新增请求项 – 分析数据及规律
- 确定目标数据url/接口
- 发请求,获得response;
- 解析数据(大部分情况下解析的是json数据)
- 持久化存储
总结:常见基本反制爬虫策略(反爬机制)及处理方式
- Headers反爬虫 :Cookie、Referer、User-Agent
- 解决方案: 在浏览器控制台(F12打开)获取请求头(headers)中的对应参数,通过requests库请求该站点时携带这些参数即可
- IP限制 :网站根据IP地址访问频率进行反爬,短时间内限制IP访问
- 解决方案:
- 构造自己IP代理池,每次访问随机选择代理,经常更新代理池
- 购买开放代理或私密代理IP
- 降低爬取的速度
- 解决方案:
- User-Agent限制 :类似于IP限制
- 解决方案: 构造自己的User-Agent池,每次访问随机选择
- 对响应内容做处理
- 解决方案: 打印并查看响应内容,用xpath或正则做处理
- 动态页面技术:采用AJAX异步加载数据包,增加数据获取难度
- 解决方案:借助控制台、fiddler或其他抓包工具抓取XHR数据包,分析其请求URL及参数,最终确定所需数据的获取方式
常见处理方法
1. 通过headers字段来反爬
1.1.通过headers中的user-agent字段来反爬
反爬原理:爬虫默认情况下没有user-agent,而是使用模块默认设置
解决方法:请求之前添加user-agent即可,更好的方式是使用user-agent池来解决(收集一堆的user-agent的方式,或者是随机生成user-agent)
import random
def get_ua():
first_num = random.randint(55, 62)
third_num = random.randint(0, 3200)
fourth_num = random.randint(0, 140)
os_type = [
'(Windows NT 6.1; WOW64)', '(Windows NT 10.0; WOW64)', '(X11; Linux x86_64)',
'(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version = 'Chrome/{}.0.{}.{}'.format(first_num, third_num, fourth_num)
ua = ' '.join(['Mozilla/5.0', random.choice(os_type), 'AppleWebKit/537.36',
'(KHTML, like Gecko)', chrome_version, 'Safari/537.36']
)
return ua
1.2.通过referer字段或者是其他字段来反爬
反爬原理:爬虫默认情况下不会带上referer字段,服务器通过判断请求发起的源头,以此判断请求是否合法
解决方法:添加referer字段 (表示一个来源,告知服务器用户的来源页面)
1.3.通过cookie来反爬
反爬原理:会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份
- session机制:
-
除了使用Cookie,Web应用程序中还经常使用Session来记录客户端状态。Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力
-
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
-
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了
-
**cookie模拟登录适用场景 **: 需要登录验证才能访问的页面
-
cookie模拟登录实现的三种方法
# 方法1(利用cookie) 1、先登录成功1次,获取到携带登陆信息的Cookie(处理headers) 2、利用处理的headers向URL地址发请求 # 方法2(利用requests.get()中cookies参数) 1、先登录成功1次,获取到cookie,处理为字典 2、res=requests.get(xxx,cookies=cookies) # 方法3(利用session会话保持) 1、实例化session对象 session = requests.session() 2、先post : session.post(post_url,data=post_data,headers=headers) 1、登陆,找到POST地址: form -> action对应地址 2、定义字典,创建session实例发送请求 # 字典key :<input>标签中name的值(email,password) # post_data = {'email':'','password':''} 3、再get : session.get(url,headers=headers)方法1(利用cookie)
首先,通过登录获取包含登录信息的Cookie,然后将其包含在headers中向目标URL发请求。
import requests # 1. 登录获取Cookie login_url = "http://example.com/login" login_data = { "username": "your_username", "password": "your_password" } response = requests.post(login_url, data=login_data) # 假设成功登录后,服务器返回的Cookie存储在响应对象的cookies属性中 cookies = response.cookies # 2. 使用获取到的Cookie进行后续请求 url = "http://example.com/protected_page" headers = { "User-Agent": "Mozilla/5.0", "Cookie": f"sessionid={cookies['sessionid']}" } response = requests.get(url, headers=headers) print(response.content)方法2(利用requests.get()中的cookies参数)
通过登录获取Cookie并处理为字典形式,然后在后续请求中使用
cookies参数。import requests # 1. 登录获取Cookie login_url = "http://example.com/login" login_data = { "username": "your_username", "password": "your_password" } response = requests.post(login_url, data=login_data) # 处理为字典形式 cookies_dict = response.cookies.get_dict() # 2. 使用获取到的Cookie进行后续请求 url = "http://example.com/protected_page" response = requests.get(url, cookies=cookies_dict) print(response.content)
-
方法3(利用session会话保持)
使用requests的session对象来保持会话,从而避免在每个请求中手动处理Cookie。
import requests
# 1. 创建session对象
session = requests.session()
# 2. 通过POST请求登录
login_url = "http://example.com/login"
login_data = {
"username": "your_username",
"password": "your_password"
}
headers = {
"User-Agent": "Mozilla/5.0"
}
session.post(login_url, data=login_data, headers=headers)
# 3. 使用session对象进行后续请求
url = "http://example.com/protected_page"
response = session.get(url, headers=headers)
print(response.content)
8.responses模拟请求
responses模块是一个用于测试HTTP请求的Python库。它允许你在不进行实际网络请求的情况下测试和模拟HTTP请求和响应。responses非常适合在单元测试中使用,尤其是当你需要测试与外部API的交互而不想依赖实际的网络请求时
要使用responses库,我们需要:
- 导入
responses库。 - 使用
@responses.activate装饰器来启用模拟。 - 使用
responses.add()方法来添加模拟的请求和响应。
模拟GET请求
import requests
import responses
@responses.activate
def test():
# 模拟一个GET请求
responses.add(
responses.GET, "http://maishu.com/api/data", json={"name": "maishu"}, status=200
)
# 发送实际请求
response = requests.get("http://maishu.com/api/data")
print(response.url)
print(response.status_code)
print(response.json())
if __name__ == "__main__":
test()
============================
http://maishu.com/api/data
200
{'name': 'maishu'}
@responses.activate:这个装饰器用于启用responses库的功能,使其可以拦截和模拟HTTP请求。
responses.add():这个方法用于添加一个模拟的请求和响应。请求方式和响应码也可根据自己需求进行更改。
responses模块还提供了更多高级功能,例如:
模拟不同HTTP方法
你可以模拟各种HTTP方法,如GET、POST、PUT、DELETE等:
@responses.activate
def test_post_example():
responses.add(
responses.POST,
'http://example.com/api',
json={'status': 'success'},
status=201
)
response = requests.post('http://example.com/api', json={'key': 'value'})
assert response.status_code == 201
assert response.json() == {'status': 'success'}
模拟不同状态码
你可以模拟不同的HTTP状态码,以测试你的代码如何处理不同的响应:
@responses.activate
def test_404_example():
responses.add(
responses.GET,
'http://example.com/notfound',
status=404
)
response = requests.get('http://example.com/notfound')
assert response.status_code == 404
模拟延迟响应
你可以模拟延迟响应,以测试你的代码在网络延迟情况下的表现:
@responses.activate
def test_delay_example():
responses.add(
responses.GET,
'http://example.com/delay',
body='Delayed response',
status=200,
adding_headers={'Content-Type': 'text/plain'},
stream=True,
content_type='text/plain',
delay=3 # 延迟3秒
)
response = requests.get('http://example.com/delay')
assert response.status_code == 200
assert response.text == 'Delayed response'
验证请求
你可以验证模拟的请求是否被正确调用:
@responses.activate
def test_request_validation():
responses.add(
responses.GET,
'http://example.com',
json={'message': 'Hello, world!'},
status=200
)
response = requests.get('http://example.com')
assert len(responses.calls) == 1
assert responses.calls[0].request.url == 'http://example.com/'
assert responses.calls[0].response.json() == {'message': 'Hello, world!'}
结论
responses模块是一个强大的工具,可以帮助你在测试中模拟和控制HTTP请求和响应。它允许你在不进行实际网络请求的情况下测试你的代码,从而提高测试的可靠性和速度。通过使用responses,你可以轻松地测试与外部API的交互,确保你的代码在各种网络条件下都能正常运行。
爬虫数据持久化存储
open方法
- 方法名称及参数
**open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)**
**file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)
**mode** 打开的方式(r,w,a,x,b,t,r+,w+,a+,U)
**buffering** 缓冲的buffering大小, 0,就不会有寄存。1,寄存行。大于 1 的整数,寄存区的缓冲大小。负值,寄存区的缓冲大小为系统默认。
**encoding** 文件的编码格式(utf-8,GBK等)
- 常用的文件打开方式
r 以只读方式打开文件。文件的指针会放在文件的开头。
w 以写入方式打开文件。文件存在覆盖文件,文件不存在创建一个新文件。
a 以追加方式打开文件。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。
r+ 打开一个文件用于读写。文件指针会放在文件的开头
w+ 打开一个文件用于读写。文件存在覆盖文件,文件不存在创建一个新文件。
a+ 打开一个文件用于读写。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。
记忆方法:记住r读,w写,a追加,每个模式后加入+号就变成可读写。
文件的读取及写入
- 读取文件
file.read([size]):读取文件(读取size个字节,默认读取全部)
file.readline()):读取一行
file.readlines():读取完整的文件,返回每一行所组成的列表
- 写入文件
file.write(str):将字符串写入文件
file.writelines(lines):将多行文本写入文件中,lines为字符串组成的列表或元组
csv文件
作用:将爬取的数据存放到本地的csv文件中
- 使用流程
1、导入模块
2、打开csv文件
3、初始化写入对象
4、写入数据(参数为列表)
import csv
with open('film.csv','w') as f:
writer = csv.writer(f)
writer.writerow([])
- 示例:创建 test.csv 文件,在文件中写入数据
# 单行写入(writerow([]))
import csv
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerow(['步惊云','36'])
writer.writerow(['超哥哥','25'])
# 多行写入(writerows([(),(),()]
import csv
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerows([('聂风','36'),('秦霜','25'),('孔慈','30')])
pymysql
常用方法
| 方法 | 说明 |
|---|---|
connect() | 建立与数据库的连接 |
cursor() | 创建一个游标对象 |
execute() | 执行 SQL 语句 |
executemany(sql,values) | 批量执行SQL语句 |
fetchone() | 获取查询结果集的下一行 |
fetchall() | 获取查询结果集的所有行 |
fetchmany(size) | 获取指定数量的查询结果行 |
commit() | 提交当前事务 |
rollback() | 回滚当前事务 |
close() | 关闭数据库连接 |
escape_string() | 转义 SQL 语句中的特殊字符 |
ping() | 检查与数据库的连接是否有效 |
pymysql基本使用
# 导入pymysql模块
import pymysql
# 连接database
conn = pymysql.connect(
host=“你的数据库地址”,
user=“用户名”,password=“密码”,
database=“数据库名”,
charset=“utf8”)
# 得到一个可以执行SQL语句的光标对象
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
# 得到一个可以执行SQL语句并且将结果作为字典返回的游标
#cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 定义要执行的SQL语句
sql = """
CREATE TABLE USER1 (
id INT auto_increment PRIMARY KEY ,
name CHAR(10) NOT NULL UNIQUE,
age TINYINT NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8; #注意:charset='utf8' 不能写成utf-8
"""
# 执行SQL语句
cursor.execute(sql)
# 关闭光标对象
cursor.close()
# 关闭数据库连接
conn.close()
增删改查操作
添加一条或多条数据
#假设已有某数据库xing,其中包含姓名及编号两个字段
import pymysql
conn = pymysql.connect(
host='192.168.0.103',
port=3306,
user='root',
password='123',
database='xing',
charset='utf8'
)
# 获取一个光标
cursor = conn.cursor()
# 定义要执行的sql语句
sql = 'insert into userinfo(user,pwd) values(%s,%s);'
data = [
('july', '147'),
('june', '258'),
('marin', '369')
]
# 拼接并执行sql语句
cursor.executemany(sql, data)
# 涉及写操作要注意提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
插入单条数据
import pymysql
conn =pymysql.connect(
host ='192.168.0.103',
port = 3306,
user = 'root',
password ='123',
database ='xing',
charset ='utf8'
)
cursor =conn.cursor() #获取一个光标
sql ='insert into userinfo (user,pwd) values (%s,%s);'
name = 'wuli'
pwd = '123456789'
cursor.execute(sql, [name, pwd])
conn.commit()
cursor.close()
conn.close()
获取最新插入数据
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "insert into userinfo (user, pwd) values (%s, %s);"
name = "wuli"
pwd = "123456789"
# 并执行SQL语句
cursor.execute(sql, [name, pwd])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
# 获取最新的那一条数据的ID
last_id = cursor.lastrowid
print("最后一条数据的ID是:", last_id)
cursor.close()
conn.close()
删除操作
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
更新数据
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
查询数据
# 可以获取指定数量的数据
cursor.fetchmany(3)
# 光标按绝对位置移动1
cursor.scroll(1, mode="absolute")
# 光标按照相对位置(当前位置)移动1
cursor.scroll(1, mode="relative"
不常用方法
数据库连接和管理:
| 方法名 | 简介 |
|---|---|
select_db() | 选择数据库 |
set_charset() | 设置字符集 |
autocommit() | 启用或禁用自动提交模式 |
errorhandler() | 设置错误处理回调函数 |
shutdown(option) | 关闭数据库服务器 |
thread_id() | 获取当前连接的线程ID |
ping(reconnect=True) | 检查与数据库的连接是否活动 |
数据库操作和查询:
| 方法名 | 简介 |
|---|---|
query(q) | 执行SQL查询并返回结果 |
callproc(procname, args) | 调用存储过程 |
rollback_to_savepoint(savepoint) | 回滚到指定保存点 |
savepoint(name) | 设置保存点 |
set_session(options) | 设置会话级别的选项 |
数据库信息获取:
| 方法名 | 简介 |
|---|---|
get_server_info() | 获取服务器信息 |
get_host_info() | 获取主机信息 |
get_proto_info() | 获取协议信息 |
get_server_version() | 获取服务器版本 |
get_warnings() | 获取警告信息 |
show_warnings() | 显示警告信息 |
stat() | 获取数据库服务器状态信息 |
错误处理和状态查询:
| 方法名 | 简介 |
|---|---|
sqlstate() | 获取最近的SQL状态信息 |
errorhandler(callback) | 设置错误处理回调函数 |
warning_count() | 获取警告的数量 |
游标和结果集操作:
| 方法名 | 简介 |
|---|---|
rowcount | 获取最近一次execute()方法影响的行数 |
setinputsizes(sizes) | 设置预处理语句的参数大小 |
setoutputsize(size) | 设置查询结果集的最大行数 |
description | 获取查询结果集的列描述信息 |
nextset() | 跳转到下一个结果集 |
lastrowid | 获取最近一次插入操作的自增ID值 |
cursor(cursorclass=Cursor) | 创建指定类型的游标 |
写入Mysql
- 在数据库中建库建表
# 连接到mysql数据库
mysql -h127.0.0.1 -uroot -p123456
# 建库建表
create database maoyandb charset utf8;
use maoyandb;
create table filmtab(
name varchar(100),
star varchar(300),
time varchar(50)
)charset=utf8;
- 回顾pymysql基本使用
一般方法:
import pymysql
# 创建2个对象
db = pymysql.connect('localhost','root','123456','maoyandb',charset='utf8')
cursor = db.cursor()
# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
ins = 'insert into filmtab values(%s,%s,%s)'
cursor.execute(ins,['霸王别姬','张国荣','1993'])
db.commit()
# 关闭
cursor.close()
db.close()
- 来试试高效的executemany()方法?
import pymysql
# 创建2个对象
db = pymysql.connect('192.168.153.137','tiger','123456','maoyandb',charset='utf8')
cursor = db.cursor()
# 抓取的数据
film_list = [('月光宝盒','周星驰','1994'),('大圣娶亲','周星驰','1994')]
# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
cursor.executemany('insert into filmtab values(%s,%s,%s)',film_list)
db.commit()
# 关闭
cursor.close()
db.close()
MongoDB
MongoDB, redis是一个非关系型数据库(NoSQL). 非常适合超大数据集的存储, 通常我们爬虫工程师使用MongoDB作为数据采集的存储.
一, MongoDB的安装(windows)
首先去官网下载MongoDB的安装包, https://www.mongodb.com/try/download/community
将mongodb目录下的bin文件夹添加到PATH环境变量
对于mac的安装可以使用homebrew安装. 或参考这里https://www.runoob.com/mongodb/mongodb-osx-install.html
MySQL
数据库(database)->表格(table)->数据(data)
MongoDB
数据库(database)->集合(collection)->文档(document)
二, MongoDB的简单使用
db: 当前正在使用的数据库
show dbs: 显示所有数据库
show databases: 显示所有数据库
use xxxx: 调整数据库
db.dropDatabase(): 删除数据库
show collections: 显示当前数据库中所有的集合(表)
db.collection_name.insert({})
db.createCollection(name, {options}) 创建集合 capped:是否卷动, size:大小
db.collection_name.drop() 删除集合
db.collection_name.insert() 向集合中添加数据( 如果该集合不存在, 自动创建)
db.collection_name.isCapped() 判断是否有容量上限(判断该集合是否是固定容量的集合)
三, MongoDB的增删改查
1. mongodb中常见的数据类型(了解):
Object ID: 主键ID
String: 字符串
Boolean: 布尔值
Integer: 数字
Doube: 小数
Arrays: 数组
Object: 文档(关联其他对象) {sname: 李嘉诚, sage: 18, class:{cccc}}
Null : 空值
Timestamp: 时间戳
Date: 时间日期
2. mongodb添加数据
db.collection_name.insert({字段:值,字段:值})
db.collection_name.insertOne({字段:值,字段:值})
db.collection_name.insertMany([{}, {}])
示例:
db.nor_col.insert({name:"樵夫", age:18, hobby:['吃', '喝', '拉撒睡']})
db.nor_col.insertOne({name:"樵夫", "age":18, "hobby":['吃', '喝', '拉撒睡']})
db.nor_col.insertMany([{name:"樵夫", age:18, hobby:['吃', '喝', '拉撒睡']}, {name:"樵夫", age:18, hobby:['吃', '喝', '拉撒睡']}])
注意, 如果集合不存在. 则会自动创建集合
3. MongoDB数据修改
3.1 更新(Update)
db.collection_name.update({查询条件}, {待修改内容}, {multi: 是否多条数据修改, upsert: 是否插入不存在的数据})
示例:
// 更新单条数据并设置多个字段
db.nor_col.update({name:"樵夫"}, {$set:{title:"alex", hobby:['抽烟', '喝酒', '烫头']}}, {multi:true});
// 更新单条数据并替换为新内容
db.nor_col.update({name:"樵夫"}, {title:"alex"});
使用 $set 和不使用 $set 的区别:
- 使用
$set只会修改指定的字段,其他字段保留原值; - 不使用
$set则会替换整个文档,只保留指定字段。
multi: 如果为True,则必须使用 $set,否则会报错。
3.2 保存(Save,了解)
在MongoDB中,save() 方法用于向集合中保存或更新文档数据。具体来说,它的作用包括:
- 插入新数据:如果提供的文档数据中不存在
_id字段或者提供的_id在集合中不存在,则save()方法会将提供的文档数据插入到集合中,并自动生成一个唯一的_id。 - 更新现有数据:如果提供的文档数据中存在
_id字段且该_id在集合中已存在,则save()方法会用提供的文档数据替换集合中对应_id的文档。
db.collection_name.save({待保存数据})
注意:如果 save 的内容中的 _id 已存在,则更新数据;如果不存在,则插入新数据。
示例:
db.nor_col.save({_id:'60fe1c75f76b22511a447852', name:"樵", age:29});
4.mongodb删除数据
4.1 remove()
db.collection_name.remove({条件}, {justOne:true|false})
示例:
db.nor_col.remove({name:"樵夫"}, {justOne:true})
4.2 deleteOne()
db.collection_name.deleteOne({条件})
示例:
db.nor_col.deleteOne({name:"樵夫"})
4.3 deleteMany()
db.collection_name.deleteMany({条件})
示例:
db.nor_col.deleteMany({name:"樵夫"})
5. mongodb查询数据
准备数据:
db.stu.insert([
{name: "朱元璋", age:800, address:'安徽省凤阳', score: 160},
{name: "朱棣", age:750, address:'江苏省南京市', score: 120},
{name: "朱高炽", age:700, address:'北京紫禁城', score: 90},
{name: "李嘉诚", age:38, address:'香港xxx街道', score: 70},
{name: "麻花藤", age:28, address:'广东省xxx市', score: 80},
{name: "大老王", age:33, address:'火星第一卫星', score: -60},
{name: "咩咩", age:33, address:'开普勒225旁边的黑洞', score: -160}
])
5.1 普通查询
db.stu.find({条件}) 查询所有
db.stu.findOne({条件}) 查询一个
db.stu.find().pretty() 将查询出来的结果进行格式化(好看一些)
5.2 比较运算
等于: 默认是等于判断, $eq
小于:$lt (less than) <
小于等于:$lte (less than equal) <=
大于:$gt (greater than)>
大于等于:$gte >=
不等于:$ne !=
db.stu.find({age:28}) 查询年龄是28岁的学生信息
db.stu.find({age: {$eq: 28}}) 查询年龄是28岁的学生信息
db.stu.find({age: {$gt: 30}}) 查询年龄大于30岁的学生
db.stu.find({age: {$lt: 30}}) 查询年龄小于30岁的学生
db.stu.find({age: {$gte: 38}}) 查询年龄大于等于30岁的学生
db.stu.find({age: {$lte: 38}}) 查询年龄小于等于30岁的学生
db.stu.find({age: {$ne: 38}}) 查询年龄不等于38的学生
5.3 逻辑运算符
- and
$and: [条件1, 条件2, 条件3…]
查询年龄等于33, 并且, 名字是"大老王"的学生信息
db.stu.find({$and:[{age: {$eq:33}}, {name:'大老王'}]})
- or
$or: [条件1, 条件2, 条件3]
查询名字叫"李嘉诚"的, 或者, 年龄超过100岁的人
db.stu.find({$or: [{name: '李嘉诚'}, {age: {$gt: 100}}]})
-
nor
$nor: [条件1, 条件2, 条件3]
查询年龄不小于38岁的人, 名字还不能是朱元璋.
db.stu.find({$nor: [{age: {$lt: 38}}, {name: "朱元璋"}]})
5.4 范围运算符
使用$in, $nin判断数据是否在某个数组内
db.stu.find({age: {$in:[28, 38]}}) 年龄是28或者38的人
5.5 正则表达式
使用$regex进行正则表达式匹配
db.stu.find({address: {$regex:'^北京'}}) 查询地址是北京的人的信息
db.stu.find({address: /^北京/}) 效果一样
5.6 自定义查询(了解)
mongo shell 是一个js的执行环境
使用$where 写一个函数, 返回满足条件的数据
db.stu.find({$where: function(){return this.age > 38}})
5.7 skip和limit
db.stu.find().skip(3).limit(3)
跳过3个. 提取3个. 类似limit 3, 3 可以用来做分页
5.8 投影
投影可以控制最终查询的结果(字段筛选)
db.stu.find({}, {字段:1, 字段:1})
需要看的字段给1就可以了.
注意, 除了_id外, 0, 1不能共存.
5.9 排序
sort({字段:1, 字段:-1})
1表示升序
-1表示降序
对查询结果排序, 先按照age升序排列, 相同项再按照score降序排列
db.stu.find().sort({age:1, score: -1})
5.10 统计数量
count(条件) 查询数量
db.stu.count({age:33})
四, MongoDB的管道
MongoDB管道可以将多个操作依次执行, 并将上一次执行的结果传递给下一个管道表达式.
语法: (稍微有点儿恶心)
db.collection_name.aggregate({管道:{表达式}}, {管道:{表达式}}, {管道:{表达式}}....)
管道:
$group , 对数据进行分组
$match, 对数据进行匹配
$project, 对数据进行修改结构, 重命名等
$sort, 将数据记性排序
$limit, 提取固定数量的数据
$skip, 跳过指定数量的数据
表达式:
$sum, 求和
$avg, 计算平均值
$min, 最小值
$max, 最大值
$push, 在结果中插⼊值到⼀个数组中
案例:
db.stu.aggregate({$group:{_id:'$gender'}}) # 根据性别进行分组
db.stu.aggregate({$group:{_id:'$gender', cou: {$sum: 1}}}) # 统计男生和女声的数量
db.stu.aggregate({$group:{_id:'$gender', cou:{$sum:1}, avg_score:{$avg:'$score'}, max_score:{$max: '$score'}}}) # 统计男生女生数量, 平均成绩以及最高分.
关于push, 我们希望得到的结果是这样的: 我想拿到分组后的人员名单, 此时就可以用$push将名称字段整理到一个列表中
db.stu.aggregate({$group:{_id:'$gender', cou:{$sum:1}, avg_score:{$avg:'$score'}, max_score:{$max: '$score'}, name_list:{$push: '$name'}}})
效果:
{ "_id" : false, "cou" : 3, "avg_score" : 123.33333333333333, "max_score" : 160, "name_list" : [ "朱元璋", "朱棣", "朱高炽" ] }
{ "_id" : true, "cou" : 4, "avg_score" : -17.5, "max_score" : 80, "name_list" : [ "李嘉诚", "麻花藤", "大老王", "咩咩" ] }
$match管道可以对数据进行检索, 然后可以进入其它管道
db.stu.aggregate({$match:{age:{$gt:33}}}, {$group:{_id:"$gender", name_list:{$push:"$name"}}})
$project管道可以对管道中的数据进行投影
db.stu.aggregate({$match:{age:{$gt:33}}}, {$group:{_id:"$gender", count:{$sum:1}, name_list:{$push:"$name"}}}, {$project:{_id:0, name_list:1}})
$sort可以对管道中的数据进行排序
db.stu.aggregate({$match:{age:{$gt:33}}}, {$group:{_id:"$gender", count:{$sum:1}, name_list:{$push:"$name"}}}, {$sort:{count: 1}})
$limit和$skip, 可以对管道中的数据进行分页查询
db.stu.aggregate({$match:{age:{$gt:33}}}, {$group:{_id:"$gender", count:{$sum:1}, name_list:{$push:"$name"}}}, {$sort:{count: 1}},{$skip:1}, {$limit:1})
管道这个东西, 我们会用match和group基本上就够用了. 而且, 对于爬虫而言. 上述内容已经严重超纲了…
五, MongoDB的索引操作
索引可以非常明显的提高我们查询的效率. 但是要注意, 创建索引后, 对查询效率是有显著提高的. 但是对增加数据而言效率是会变低的.
索引会带来什么:
数据量上来了. 普通的遍历的方式去找东西. 就很慢了
字典中的目录, 就是索引
索引的作用: 为了快速的查询到数据结果
索引带来的问题:
过分的创建索引. 索引的维护困难
在增删改查数据的时候. 索引可能需要重新建立. 效率会变低
极特殊情况下. 百万级的数据要处理.
-
停服-备用服务器(主从复制)
-
备份
-
撤掉索引
-
处理数据
-
重新建立索引
-
开启测试
-
开服-备用服务器(主从复制)
添加索引:
db.collection_name.ensureIndex({属性:1}) # 1 正序, -1 倒叙
我们多加一些数据到mongodb. 分别看看加索引和不加索引的执行效率.
for(i = 1; i < 100000; i++) db.tt.insert({"test": 'god'+i})
查询:
db.tt.find({test:'god99999'}).explain("executionStats")
查询效率:
“executionTimeMillis” : 64,
加索引:
db.tt.ensureIndex({test:1})
再次查询:
“executionTimeMillis” : 0,
这个有点儿夸张了…但查询效率肯定是提高了不少…
查看所有索引:
db.collection_name.getIndexes()
删除索引:
db.collection_name.dropIndex({属性: 1})
六, MongoDB的权限管理
mongodb的用户权限是跟着数据库走的. 除了超级管理员外. 其他管理员只能管理自己的库.
6.1 创建超级管理员
首先, 将数据库调整到admin库.
use admin
然后, 创建一个root超级管理员账号
db.createUser({user:"用户名", pwd: "密码", roles:['root']})
db.createUser({user:"sylar", pwd: "123456", roles:['root']})
创建完成后. 需要退出mongodb. 然后修改配置文件:
mac和linux:
dbpath=/usr/local/mongodb
port=27017
logpath=/usr/local/var/log/mongodb/mongo.log
fork=true
logappend=true
auth=true # 加上账户认证
windows:
storage:
dbPath: D:\MongoDB\Server\4.4\data
journal:
enabled: true
systemLog:
destination: file
logAppend: true
path: D:\MongoDB\Server\4.4\log\mongod.log
net:
port: 27017
bindIp: 127.0.0.1
# 注意: security要顶格, authorization要空两格, enabled前面要有个空格
security:
authorization: enabled
然后, 需要重新启动mongodb的服务(linux和mac直接杀掉进程, 重新启动即可, windows去系统服务里重启MongoDB的服务).
然后重新打开mongo, 先进入admin, 登录超级管理员账号, 进入到你想要单独创建管理员的数据库. 然后创建出该数据库的管理员账号
> use admin
switched to db admin
> db.auth("sylar","123456")
1
> use ddd
switched to db ddd
> db.createUser({user:"ttt_admin", pwd:"123456", roles:["readWrite"]})
退出管理员账号, 重新登录刚刚创建好的账号
> use ddd
switched to db ddd
> db.auth("ttt_admin", "123456")
1
> db.stu.insert({name: 123, age:3})
WriteResult({ "nInserted" : 1 })
>
注意, 每个账号只能管理自己的数据库(可以是多个).
七, pymongo的使用
python处理mongodb首选就是pymongo. 首先, 安装一下这个模块
pip install pymongo
建立连接
import pymongo
conn = pymongo.MongoClient(host='localhost', port=27017)
# 切换数据库
py = conn['python']
# 登录该数据库(需要的话)
py.authenticate("python_admin", '123456')
# 简单来个查询
result = py["stu"].find()
for r in result:
print(r)
完成增删改查
import pymongo
from pymongo import MongoClient
def get_db(database, user, pwd):
client = MongoClient(host="localhost", port=27017)
db = client[database]
# 有账号就加上验证, 没有账号就不用验证
db.authenticate(user, pwd)
return db
# 增删改查
# 增加数据
def add_one(table, data):
db = get_db("python", "python_admin", "123456")
result = db[table].insert_one(data)
return result
def add_many(table, data_list):
db = get_db("python", "python_admin", "123456")
result = db[table].insert_many(data_list)
return result.inserted_ids
def upd(table, condition, data):
db = get_db("python", "python_admin", "123456")
data = {'hehe': 'hehe', 'meme': 'meme'}
# result = db[table].update_many(condition, {"$set": data})
result = db[table].update_many(condition, {'$set':data})
return result
def delete(table, condition):
db = get_db("python", "python_admin", "123456")
result = db[table].remove(condition)
return result
if __name__ == '__main__':
# r = add_one("stu", {"name": "西瓜", "age":18})
# print(r.inserted_id)
# r = add_many("stu", [{"name": "嘎嘎"},{"name": "咔咔"}])
# print(r.inserted_ids)
# result = upd("stu", {"name": 99999}, {"age": 100})
# print(result)
result = delete("stu", {"name": "哈哈"})
print(result)
抓链家!!!
import requests
from lxml import etree
import mongodb
from concurrent.futures import ThreadPoolExecutor
def get_page_source(url):
resp = requests.get(url)
page_source = resp.text
return page_source
def parse_html(html):
tree = etree.HTML(html)
# print(html)
li_list = tree.xpath("//ul[@class='sellListContent']/li")
print("==>", len(li_list))
try:
lst = []
for li in li_list:
title = li.xpath("./div[1]/div[1]/a/text()")[0]
position_info = "-".join((s.strip() for s in li.xpath("./div[1]/div[2]/div/a/text()")))
temp = li.xpath("./div[1]/div[3]/div/text()")[0].split(" | ")
# 凑出来的数据. 可能会不对
if len(temp) == 6:
temp.insert(5, "")
elif len(temp) == 8:
temp.pop()
huxing, mianji, chaoxiang, zhangxiu, louceng, nianfen, jiegou = temp
guanzhu, fabushijian = li.xpath("./div[1]/div[4]/text()")[0].split(" / ")
tags = li.xpath("./div[1]/div[5]/span/text()")
data = {
"title": title,
"position": position_info,
"huxing": huxing,
"mianji": mianji,
"chaoxiang": chaoxiang,
"zhangxiu": zhangxiu,
"louceng": louceng,
"nianfen": nianfen,
"jiegou": jiegou,
"guanzhu": guanzhu,
"fabushijian": fabushijian,
"tags": tags
}
lst.append(data)
# 一起存入mongodb
print(f"数据量", len(lst))
result = mongodb.add_many("ershoufang", lst)
print(f"插入{len(result)}")
except Exception as e:
print(e)
print(temp)
def main(url):
page_source = get_page_source(url)
parse_html(page_source)
if __name__ == '__main__':
with ThreadPoolExecutor(10) as t:
for i in range(1, 10):
url = f"https://bj.lianjia.com/ershoufang/pg{i}/"
t.submit(main, url)
Redis
Redis作为一款目前这个星球上性能最高的非关系型数据库之一. 拥有每秒近十万次的读写能力. 其实力只能用恐怖来形容
在使用之前需要配置几个参数
mac是: redis.conf, windows是: redis.windows-service.conf)
-
关闭bind(默认关闭)
# bind 127.0.0.1 ::1 # 注释掉它 -
关闭保护模式 windows不用设置
protected-mode no # 设置为no -
设置密码(默认是被注释的状态)
requirepass 123456 # 设置密码 -
将redis安装到windows服务
redis-server.exe --service-install redis.windows.conf --loglevel verbose -
开启服务
redis-server --service-start # 链接服务 redis-cli -h ip地址 -p 端口 --raw # raw可以让redis显示出中文(windows无效) auth 密码 # 如果有密码可以这样来登录 Mac系统每次启动需要输入: redis-server /usr/local/etc/redis.conf -
卸载和暂停服务
# 卸载服务: redis-server --service-uninstall # 停止服务: redis-server --service-stop -
连接到python的redis模块
import redis link = redis.Redis(host='localhost', port=6379, db=0, password='123456', decode_responses=True # 中文自动编码 )
Redis 数据类型
Redis 主要支持以下几种数据类型,其他的剩余类型太少用了:
-
string(字符串): 基本的数据存储单元,可以存储字符串、整数或者浮点数。
-
**hash(哈希)😗*一个键值对集合,可以存储多个字段。
-
**list(列表)😗*一个简单的列表,可以存储一系列的字符串元素。
-
**set(集合)😗*一个无序集合,可以存储不重复的字符串元素。
-
zset(sorted set:有序集合): 类似于集合,但是每个元素都有一个分数(score)与之关联。
String(字符串)
string 是 redis 最基本的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据,比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
常用命令
set key value:设置键的值。get key:获取键的值。append key value:将值追加到键的值之后。incr key:将键的值加 1。decr key:将键的值减 1。incrby key count:让 key 对应的 value 根据 count 的值自增。decrby key count:让 key 对应的 value 根据 count 的值自减。
#set and get
link.set('name', '张三')
print(link.get('name')) # 张三
#APPEND
link.append('name', '李四')
print(link.get('name')) # 张三李四
#ICNR and DECR
link.incr('num')
link.incr('num')
print(link.get('num')) # 每次执行程序都会加2
# INCRBY
link.incrby('num',10)
print(link.get('num')) # 每次执行程序都会加10
# DECRBY
link.decrby('num',10)
print(link.get('num')) # 每次执行程序都会减10
Hash(哈希)
Redis hash 是一个键值(key=>value)对集合,类似于一个小型的 NoSQL 数据库。
Redis hash 是一个 string 类型的 field(字段) 和 value 的映射表,hash 特别适合用于存储对象。
每个哈希最多可以存储 2^32 - 1 个键值对。
-
常用命令
-
hset key field value:设置哈希表中字段的值。 -
hget key field:获取哈希表中字段的值。 -
hgetall key:获取哈希表中所有字段和值。 -
hmset key field value field2 value2....:设置多个值。 -
hmget key field value field2 value2....:获取多个值。 -
hdel key field:删除哈希表中的一个或多个字段。
# # HSET and HGET
link.hset('my_hash', 'name', '张三')
print(link.hget('my_hash', 'name')) # 张三
# HMSET and HMGET(这个方案不知为何莫名其妙被废弃了,但暂时还能用)
# 如果要替换只能这样逐个导入
# link.hset('my_hash', field='name', value='张三')
# link.hset('my_hash', field='age', value=18)
# link.hset('my_hash', field='gender', value='男')
# link.hmset('my_hash', {'name': '张三', 'age': 18, 'gender': '男'})
print(link.hmget('my_hash', 'name', 'age', 'gender'))
# HGETALL
print(link.hgetall('my_hash')) # {'name': '张三', 'age': '18', 'gender': '男'}
# HEDL
link.hdel('my_hash', 'name', '张三')
print(link.hgetall('my_hash')) # {'age': '18', 'gender': '男'} 张三被鲨了
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
列表最多可以存储 2^32 - 1 个元素。
常用命令
lpush key value:将值插入到列表头部。rpush key value:将值插入到列表尾部。lpop key:移出并获取列表的第一个元素。rpop key:移出并获取列表的最后一个元素。lindex key index:在 key 后面传入对应的下标可以取到对应的值。lrange key start stop:获取列表在指定范围内的元素。
# LPUSH AND RPUSH AND LRANGE
link.lpush('my_list', 'a', 'b', 'c')
print(link.rpush('my_list', 'd', 'e', 'f'))
print(link.lrange('my_list', 0, -1)) # ['c', 'b', 'a', 'd', 'e', 'f']
# LPOP AND RPOP
print(link.lpop('my_list')) # c
print(link.rpop('my_list')) # f
print(link.lrange('my_list', 0, -1)) # c和f此时就被删除了['b', 'a', 'd', 'e']
# LINDEX
print(link.lindex('my_list', 0)) # b
Set(集合)
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
常用命令
sadd key value:向集合添加一个或多个成员。srem key value:移除集合中的一个或多个成员。smembers key:返回集合中的所有成员。sismember key value:判断值是否是集合的成员。scard key:获取集合中成员的数量。spop key:随机移除并返回集合中的一个成员。srandmember key [count]:返回集合中一个或多个随机成员。sdiff key1 key2:返回两个集合的差集。sinter key1 key2:返回两个集合的交集。sunion key1 key2:返回两个集合的并集。smove source destination member:将 member 元素从 source 集合移动到 destination 集合。
# sadd and smembers
link.sadd('set_key', 'a', 'b', 'c')
print(link.smembers('set_key')) # {'a', 'c', 'b'} # 每次输入都不一样,但不会重复添加
# scard(相当于其他类型的len)
print(link.scard('set_key')) # 3
# sismember(判断是否在集合中)
print(link.sismember('set_key', 'a')) # 1(True)
# srem(删除集合中的元素)
link.srem('set_key', 'a')
print(link.smembers('set_key')) # {'b', 'c'}
# spop(随机删除一个元素)
print(link.spop('set_key'))
# smove(将一个集合中的元素移动到另一个集合中)
link.smove('set_key', 'set_key2', 'b')
# sinter(求两个集合的交集)
print(link.sinter('set_key', 'set_key2')) # {'b'}
# sunion(求两个集合的并集)
print(link.sunion('set_key', 'set_key2')) # {'a', 'c', 'b'}
# sdiff(求两个集合的差集)
print(link.sdiff('set_key', 'set_key2')) # {'c'}
# srandmember(随机返回集合中的元素,不删除)
print(link.srandmember('set_key'))
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
常用命令
zadd key score member: 向有序集合添加一个或多个成员,每个成员关联一个分数。zrem key member: 从有序集合中移除一个或多个成员。zrange key start stop [withscores]: 返回有序集合中指定索引范围内的成员,可选择是否返回分数。zrevrange key start stop [withscores]: 返回有序集合中指定索引范围内的成员,按照分数从高到低排序。zcard key: 获取有序集合中成员的数量。zscore key member: 获取有序集合中指定成员的分数。zincrby key increment member: 增加有序集合中指定成员的分数。zrank key member: 获取有序集合中指定成员的排名,按照分数从低到高排序。zrevrank key member: 获取有序集合中指定成员的排名,按照分数从高到低排序。zrangebyscore key min max: 返回有序集合中指定分数范围内的成员。zremrangebyscore key min max: 删除有序集合中指定分数范围内的成员。
# zadd and zrange
# 分值越低排行越高
link.zadd('zset', {'a': 1, 'b': 20, 'c': 30})
# 显示分数
print(link.zrange('zset', 0, -1, withscores=True)) # [('a', 1.0), ('b', 20.0), ('c', 30.0)]
# zrevrange(反转有序列表)
print(link.zrevrange('zset', 0, -1, withscores=True)) # [('c', 30.0), ('b', 20.0), ('a', 1.0)]
# zcard(等同于其他的len)
print(link.zcard('zset')) # 3
# zcount(获取指定分值范围内的元素个数)
print(link.zcount('zset', 10, 30)) # 2
# zscore(获取分值)
print(link.zscore('zset', 'a')) # 1.0
# zrem(删除元素)
link.zrem('zset', 'a')
print(link.zrange('zset', 0, -1, withscores=True)) # [('b', 20.0), ('c', 30.0)]
# zincrby(增加分值)
link.zincrby('zset', 200, 'b')
print(link.zrange('zset', 0, -1, withscores=True)) # [('c', 30.0), ('b', 220.0)]
# zadd(修改分值)
link.zadd('zset', {'b': 200})
print(link.zrange('zset', 0, -1, withscores=True)) # [('c', 30.0), ('b', 200.0)]
# zrank(获取排名)
print(link.zrank('zset', 'b')) # 1
# zrevrank(获取排名,反转)
print(link.zrevrank('zset', 'b')) # 0
# zrangebyscore(获取指定分值范围内的元素)
print(link.zrangebyscore('zset', 10, 30)) # ['c']
# zremrangebyscore(删除指定分值范围内的元素)
link.zremrangebyscore('zset', 10, 30)
print(link.zrange('zset', 0, -1, withscores=True)) # [('b', 200.0)]
openpyxl
openpyxl 是一个用于读取和写入Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它提供了丰富的功能,可以创建新的Excel文件、打开现有文件进行修改,并支持样式设置、图表创建、数据透视表、合并单元格、公式计算等高级操作。
使用pip安装openpyxl:
pip install openpyxl
使用指南
1. 创建和保存Excel文件
from openpyxl import Workbook
# 创建一个Workbook对象
wb = Workbook()
# 激活默认的工作表
ws = wb.active
# 写入数据到单元格
ws['A1'] = 'Hello, openpyxl!'
# 保存文件
wb.save('example.xlsx')
2. 打开和修改现有的Excel文件
from openpyxl import load_workbook
# 加载现有的工作簿
wb = load_workbook('example.xlsx')
# 获取默认的工作表
ws = wb.active
# 修改已有单元格的值
ws['A1'] = '被修改了'
# 保存修改
wb.save('example.xlsx')
3. 操作工作表和单元格
# 创建新的工作表
ws2 = wb.create_sheet(title="Sheet2")
# 将数据写入单元格
ws2['A1'] = 42
# 访问单元格的值
cell_value = ws2['A1'].value
# 在工作表之间切换
wb.active = ws2
# 删除工作表
wb.remove(ws2)
4. 样式和格式化
from openpyxl.styles import Font, Alignment
# 设置字体和对齐方式
font = Font(name='Calibri', bold=True, italic=True)
align = Alignment(horizontal='center', vertical='center')
# 应用样式到单元格
cell = ws['A1']
cell.font = font
cell.alignment = align
# 保存文件
wb.save('example.xlsx')
5. 图表创建
from openpyxl.chart import BarChart, Reference
# 创建柱状图
chart = BarChart()
data = Reference(ws, min_col=1, min_row=1, max_col=3, max_row=5)
chart.add_data(data)
ws.add_chart(chart, "E1")
# 保存文件
wb.save('example.xlsx')
6. 数据透视表和合并单元格
当使用 openpyxl 创建和修改数据透视表时,需要注意的是,当前版本的 openpyxl(截至最后一次更新时)并不直接支持数据透视表的创建。但是,你可以通过创建和修改数据,以及在Excel中手动创建数据透视表来实现这一功能。下面是一些关于合并单元格的示例代码:
合并单元格
from openpyxl import Workbook
# 创建一个Workbook对象
wb = Workbook()
# 激活默认的工作表
ws = wb.active
# 合并单元格
ws.merge_cells('A1:D1')
ws['A1'] = 'Merged Cells'
# 保存文件
wb.save('example.xlsx')
创建数据透视表
虽然 openpyxl 不直接支持创建数据透视表,但你可以通过设置数据和在Excel中手动创建数据透视表来实现类似的功能。以下是一个简单的示例,演示如何向Excel文件中写入数据,并手动创建数据透视表:
from openpyxl import Workbook
# 创建一个Workbook对象
wb = Workbook()
# 激活默认的工作表
ws = wb.active
# 写入数据
ws['A1'] = 'Category'
ws['B1'] = 'Amount'
ws['A2'] = 'Apple'
ws['B2'] = 800
ws['A3'] = 'Orange'
ws['B3'] = 1200
ws['A4'] = 'Banana'
ws['B4'] = 600
# 保存文件
wb.save('example.xlsx')
在这个示例中,我们创建了一个包含产品类别和销售金额的简单表格。然后,你可以手动在Excel中使用这些数据创建数据透视表。
注意事项
- 数据透视表的创建需要在Excel中手动完成,
openpyxl目前没有直接支持这一功能的API。 - 合并单元格可以通过
ws.merge_cells()方法实现,但请确保使用合适的单元格坐标和格式。
这些示例可以帮助你了解如何使用 openpyxl 进行合并单元格操作,并提供了一种途径来处理数据以便在Excel中手动创建数据透视表。
7. 公式计算和超链接
# 计算公式
ws['B1'] = '=SUM(A1:A10)'
# 添加超链接
from openpyxl import Workbook
from openpyxl.utils import FORMULAE
wb = Workbook()
ws = wb.active
ws['A1'] = '=HYPERLINK("http://www.example.com", "Link")'
8. 保护工作表和打印设置
# 保护工作表
ws.protection.sheet = True
# 设置打印区域和页边距
ws.print_area = 'A1:E10'
ws.page_setup.orientation = ws.ORIENTATION_LANDSCAPE
ws.page_margins.left = 0.5
总结
以上是 openpyxl 提供的主要功能和一些示例代码。你可以根据具体的需求深入学习和使用这些功能,来处理和操作Excel文件。详细的API文档和更多示例可以参考 openpyxl官方文档。
Markdown库
使用指南
1. 将 Markdown 文本转换为 HTML
import markdown
# 定义一个 Markdown 文本
markdown_text = """
# Heading 1
## Heading 2
This is a paragraph with **bold** and _italic_ text.
- Item 1
- Item 2
"""
# 将 Markdown 转换为 HTML
html_output = markdown.markdown(markdown_text)
print(html_output)
'''
<h1>Heading 1</h1>
<h2>Heading 2</h2>
<p>This is a paragraph with <strong>bold</strong> and <em>italic</em> text.</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
</ul>
'''
2. 扩展语法支持
markdown 库支持多种扩展,如表格、代码块语法高亮等。可以通过在调用 markdown 函数时传递额外的参数来启用这些扩展:
# 启用表格扩展和代码块语法高亮
html_output = markdown.markdown(markdown_text, extensions=['tables', 'fenced_code'])
3. 输出到文件
# 将转换后的 HTML 写入文件
with open('output.html', 'w', encoding='utf-8') as f:
f.write(html_output)
注意事项
- 在将 Markdown 转换为 HTML 时,确保 Markdown 文本的格式正确,以免导致转换错误。
- 可以根据需求选择适合的扩展来满足不同的需求,如数学公式支持、目录生成等。
总结
以上是使用 markdown 库将 Markdown 格式文本转换为 HTML 的基本使用方法和一些注意事项。通过这些方法,你可以方便地处理和展示 Markdown 文档。
详细的 API 文档和更多示例可以参考 markdown PyPI 页面。
tomd库
可以将抓取到的HTML数据转换为Markdown的一个库
常用操作
简单转换
将HTML文本转换为Markdown文本:
html_text = "<p>This is a <strong>paragraph</strong>.</p>"
markdown_text = tomd.convert(html_text)
print(markdown_text)
# This is a **paragraph**.
文件转换
如果您有一个HTML文件,并想将其内容转换为Markdown格式,并将结果保存到另一个文件中,可以执行以下操作:
with open('input.html', 'r') as f:
html_text = f.read()
markdown_text = tomd.convert(html_text)
with open('output.md', 'w') as f:
f.write(markdown_text)
高级选项
tomd 库提供了一些选项来定制转换行为,例如过滤HTML标签、保留链接等。
| 选项 | 描述 |
|---|---|
convert_code_block | 将HTML中的代码块转换为Markdown代码块。默认为 True。 |
preserve_links | 保留HTML中的链接。默认为 False。 |
preserve_images | 保留HTML中的图片。默认为 False。 |
ul_style | 无序列表的样式。可选值为 'asterisk', 'plus', 'dash',默认为 'dash'。 |
ol_style | 有序列表的样式。可选值为 '1', 'a', 'A', 'i', 'I',默认为 '1'。 |
preserve_tables | 保留HTML中的表格。默认为 False。 |
preserve_pre | 保留HTML中的 <pre> 标签。默认为 True。 |
remove_empty_tags | 删除空的HTML标签。默认为 True。 |
例如,如果您希望保留HTML中的链接:
html_text = "<p>This is a <a href='https://example.com'>link</a>.</p>"
markdown_text = tomd.convert(html_text, options={'preserve_links': True})
print(markdown_text)
# This is a <a href='https://example.com'>link</a>.
docx
python-docx 是一个用于创建和修改Microsoft Word文档(.docx文件)的Python库。它使得在Python中可以直接操作文本、表格、图像等内容,同时支持设置样式、插入页眉页脚、创建图表等功能。
使用指南
1. 创建一个新的 Word 文档
from docx import Document
# 创建一个Document对象
doc = Document()
# 添加段落
doc.add_paragraph('Hello, python-docx!')
# 保存文档
doc.save('example.docx')
2. 打开和修改现有的 Word 文档
from docx import Document
# 打开现有的文档
doc = Document('example.docx')
# 获取文档中的段落
for paragraph in doc.paragraphs:
print(paragraph.text)
# 修改第一个段落的内容
doc.paragraphs[0].text = 'Modified content'
print(doc.paragraphs[0].text)
# 保存修改
doc.save('example.docx')
3. 操作文本和样式
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# 添加新段落并设置样式
p = doc.add_paragraph('This is a new paragraph.')
p.add_run(' Bold Text').bold = True
p.add_run(' and ')
p.add_run('Italic Text').italic = True
# 设置段落对齐方式
p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 设置字体大小
run = p.add_run(' Size 14 Font')
font = run.font
font.size = Pt(14)
# 保存文档
doc.save('example.docx')
| 操作 | 方法 | 描述 |
|---|---|---|
| 添加段落 | add_paragraph() | 在文档末尾添加一个新段落 |
| 修改段落内容 | 直接访问 paragraph.text 属性并赋值 | 修改现有段落的文本内容 |
| 添加加粗和斜体文本 | add_run().bold = Trueadd_run().italic = True | 在段落中添加加粗和斜体文本 |
| 设置文本对齐方式 | paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER | 设置段落的对齐方式为居中 |
| 设置字体大小 | run.font.size = Pt(14) | 设置段落中某一部分文本的字体大小 |
| 添加下划线 | run.underline = True | 给文本添加下划线 |
| 设置字体颜色 | run.font.color.rgb = RGBColor(255, 0, 0) | 设置文本的字体颜色为红色 |
| 设置字体类型和样式 | run.font.name = 'Arial'run.font.bold = Truerun.font.italic = True | 设置文本的字体类型为Arial,并加粗和斜体 |
| 设置段落间距 | paragraph.space_before = Pt(12)paragraph.space_after = Pt(12) | 设置段落前后的间距 |
| 添加超链接 | paragraph.add_hyperlink(url, text) | 在文档中添加带有超链接的文本 |
| 设置段落首行缩进 | paragraph.paragraph_format.first_line_indent = Inches(0.5) | 设置段落的首行缩进 |
| 添加脚注和尾注 | section.footer.paragraphs[0].add_run(text) | 在文档底部添加脚注或者页脚 |
| 添加水平线 | document.add_paragraph().add_run('-----------') | 在文档中添加水平线 |
4. 添加表格
# 添加表格
table = doc.add_table(rows=3, cols=3)
# 填充表格数据
for i in range(3):
for j in range(3):
table.cell(i, j).text = f'Cell {i+1},{j+1}'
# 保存文档
doc.save('example.docx')
5. 添加页眉页脚和插入图片
from docx.shared import Inches
from docx.enum.section import WD_SECTION
# 添加页眉
section = doc.sections[0]
header = section.header
paragraph = header.paragraphs[0]
paragraph.text = 'Header'
# 添加页脚
footer = section.footer
paragraph = footer.paragraphs[0]
paragraph.text = 'Footer'
# 插入图片
doc.add_picture('image.jpg', width=Inches(2.0))
# 保存文档
doc.save('example.docx')
结论
以上是使用 python-docx 库操作 Word 文档的基本使用方法和一些示例。通过这些方法,你可以方便地创建、修改和格式化 Microsoft Word 文档。
详细的 API 文档和更多示例可以参考 python-docx GitHub 页面。
爬虫高级框架Scrapy
之前我们所编写的爬虫的逻辑:

- 1.发送request请求到HTML
- 2.得到HTML的response请求以后返回给本地
- 3.解析数据
- 4.存入data数据层
scrapy的工作流程:

-
1.传入起始URL构成request对象,并传递给
调度器(scheduler) -
2.
引擎(engine)从调度器中获取到request对象然后交给下载器(downloader) -
3.由
下载器来获取到页面的源代码,并封装成response对象,并回馈给引擎 -
4.
引擎将获取到的response对象传递给蜘蛛(spider),由spider对数据进行解析并反馈给引擎 -
5.引擎将解析完的数据传递给pipeline进行持久化储存
在储存的期间如果spider提取的不是数据而是子页面url会重复步骤2的操作
各模块的介绍:
-
引擎(engine)
scrapy的核心, 所有模块的衔接, 数据流程梳理.
-
调度器(scheduler)
本质上这东西可以看成是一个集合和队列. 里面存放着一堆我们即将要发送的请求. 可以看成是一个url的容器. 它决定了下一步要去爬取哪一个url. 通常我们在这里可以对url进行去重操作.
-
下载器(downloader)
它的本质就是用来发动请求的一个模块. 小白们完全可以把它理解成是一个requests.get()的功能. 只不过这货返回的是一个response对象.
-
爬虫(spider)
这是我们要写的第一个部分的内容, 负责解析下载器返回的response对象.从中提取到我们需要的数据.
-
管道(pipeline)
这是我们要写的第二个部分的内容, 主要负责数据的存储和各种持久化操作.
# 小总结:
# 引擎,如果接收到request, 走调度器
# 引擎,如果接收到response, 走spider
# 引擎,如果接收到item, dict, 走pipeline
Scrapy初始化
-
1.创建项目
scrapy startproject 项目名称 # scrapy startproject mySpider_2-
创建好项目后, 我们可以在pycharm里观察到scrapy帮我们创建了一个文件夹, 里面的目录结构如下:
mySpider_2 # 项目所在文件夹, 建议用pycharm打开该文件夹 ├── mySpider_2 # 项目跟目录 │ ├── __init__.py │ ├── items.py # 封装数据的格式 │ ├── middlewares.py # 所有中间件 │ ├── pipelines.py # 所有的管道 │ ├── settings.py # 爬虫配置信息 │ └── spiders # 爬虫文件夹, 写入爬虫代码 │ └── __init__.py └── scrapy.cfg # scrapy项目配置信息,不要删它,别动它,善待它.
-
-
2.创建爬虫
cd 文件夹 # 进入项目所在文件夹 scrapy genspider 爬虫名称 允许抓取的域名范围 # cd mySpider_2 # scrapy genspider youxi 4399.com -
3.完善数据过程
import scrapy class YouxiSpider(scrapy.Spider): name = 'youxi' # 该名字非常关键, 我们在启动该爬虫的时候需要这个名字 allowed_domains = ['4399.com'] # 爬虫抓取的域. start_urls = ['http://www.4399.com/flash/'] # 起始页 def parse(self, response, **kwargs): # response.text # 页面源代码 # response.xpath() # 通过xpath方式提取 # response.css() # 通过css方式提取 # response.json() # 提取json数据 # 用我们最熟悉的方式: xpath提取游戏名称, 游戏类别, 发布时间等信息 li_list = response.xpath("//ul[@class='n-game cf']/li") for li in li_list: name = li.xpath("./a/b/text()").extract_first() category = li.xpath("./em/a/text()").extract_first() date = li.xpath("./em/text()").extract_first() dic = { "name": name, "category": category, "date": date } # 将提取到的数据提交到管道内. # 注意, 这里只能返回 request对象, 字典, item数据, or None yield dic # 运行爬虫:scrapy crawl 爬虫名字 -
如果不希望在控制台上输入scrapy crawl来启动爬虫的话也可以定义一个run.py来执行
from scrapy.cmdline import execute
if __name__ == '__main__':
# 一定要split,因为执行接口接收的是一个列表
execute("scrapy crawl baidu".split())
# execute(["scrapy", "crawl", "baidu"]) # 这个也是一样的
- settings.py文件中的一些信息
BOT_NAME = "game" # 机器人名称为 "game"
SPIDER_MODULES = ["game.spiders"] # 爬虫模块为 ["game.spiders"]
NEWSPIDER_MODULE = "game.spiders" # 新爬虫模块为 "game.spiders"
LOG_LEVEL = "WARNING" # 日志级别为 "WARNING" =========# 默认没有这一项,设置有好处
# 通过在用户代理上标识自己(和您的网站),负责任地爬取
# USER_AGENT = "game (+http://www.yourdomain.com)"
ROBOTSTXT_OBEY = False # 不遵守 robots.txt 规则 ======# 默认为True
# 配置 Scrapy 执行的最大并发请求数(默认值为 16)
# CONCURRENT_REQUESTS = 32
# 配置同一网站请求的延迟(默认值为 0)
# DOWNLOAD_DELAY = 3
# 禁用 Cookies(默认情况下启用)
# COOKIES_ENABLED = False
# 禁用 Telnet 控制台(默认情况下启用)
# TELNETCONSOLE_ENABLED = False
# 覆盖默认请求头:
# DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# 启用或禁用爬虫中间件
# SPIDER_MIDDLEWARES = {
# "game.middlewares.GameSpiderMiddleware": 543,
#}
# 启用或禁用下载器中间件
# DOWNLOADER_MIDDLEWARES = {
# "game.middlewares.GameDownloaderMiddleware": 543,
#}
# 启用或禁用扩展
# EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# 配置项目管道
ITEM_PIPELINES = {
"game.pipelines.GamePipeline": 300, ======# 默认禁用
}
# 启用并配置自动限速扩展(默认情况下禁用)
# AUTOTHROTTLE_ENABLED = True
# 初始下载延迟
# AUTOTHROTTLE_START_DELAY = 5
# 在高延迟情况下设置的最大下载延迟
# AUTOTHROTTLE_MAX_DELAY = 60
# Scrapy 每个远程服务器应该并行发送的平均请求数
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 启用显示每个收到的响应的限速统计信息:
# AUTOTHROTTLE_DEBUG = False
# 启用并配置 HTTP 缓存(默认情况下禁用)
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = "httpcache"
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# 将默认值为已弃用的设置设置为未来兼容的值
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
Scrapy 数据存储
1. csv文件写入
写入文件仅需要在pipeline中给定的默认类写入文件即可,但这显得十分的不灵活,在上述的代码里yield返回了一个dic字典,里面包含着
dic = {
"name": name,
"category": category,
"date": date
}
仅需要在默认类里面处理字典,使用with写入即可:
class MyPipeline:
def process_item(self, item, spider):
with open("caipiao.txt", mode="a", encoding='utf-8') as f:
# 写入文件
f.write(f"{item['qihao']}, {'_'.join(item['red_ball'])}, {'_'.join(item['blue_ball'])}\n")
return item
我们希望的是, 在爬虫开始的时候就创建好一个文件,在所有数据爬取完毕后存入文件,scrapy提供了两个默认函数
-
1.
open_spider(), 在爬虫开始的时候执行一次 -
2.
close_spider(), 在爬虫结束的时候执行一次 -
有了这俩货, 我们就可以很简单的去处理这个问题
class MyPipeline: def open_spider(self, spider): self.f = open("caipiao.txt", mode="a", encoding='utf-8') def close_spider(self, spider): if self.f: self.f.close() def process_item(self, item, spider): # 写入文件 self.f.write(f"{item['qihao']}, {'_'.join(item['red_ball'])}, {'_'.join(item['blue_ball'])}\n") return item
2.Mysql 写入
知道了上边的两个函数,想要写入Mysql就简单了~
- 1.新建一个Mysql管道
- 2.在管道定义一个开启函数,开启函数内连接数据库并创建游标
- 3.在主存储函数写入sql语句、事件执行和提交、和报错的事件回滚
- 4.在关闭函数内关闭游标、数据库的连接
# 新定义一个Mysql类
class MysqlPipeline:
# 开启函数
def open_spider(self, spider):
self.conn = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123456',
db='lottery',
charset='utf8')
# 创建游标
self.cursor = self.conn.cursor()
# 主存储函数
def process_item(self, item, spider):
try:
# 存储内容.....
years = item['years']
red_balls = ".".join(item['red_balls'])
blue_balls = item['blue_balls']
sql1 = 'delete from balls where red_balls = %s and blue_balls = %s and years = %s'
sql2 = 'insert into balls(years, red_balls, blue_balls) values(%s, %s, %s)'
# 执行事件
self.cursor.execute(sql1, (red_balls, blue_balls, years))
self.cursor.execute(sql2, (years, red_balls, blue_balls))
# 提交所有事件
self.conn.commit()
except Exception as e:
print(e)
# 回滚所有事件
self.conn.rollback()
return item
# 关闭函数、游标、数据库连接
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
3.mongodb写入
class MongoDBPipeline:
def open_spider(self, spider):
self.conn = pymango.MongoClient(
host='127.0.0.1',
port = 27017)
self.db = self.conn['Python']
def process_item(self, item, spider):
self.db.ssq.insert("years":item['years'],"red_balls":item['red_balls'],"blue_balls":item['blue_balls'])
# 返回给下一个管道
return item
def close_spider(self, spider):
self.conn.close()
4.Redis 写入
class RedisPipeline:
def open_spider(self, spider):
self.redis = redis.Redis(host='127.0.0.1',
port=6379,
db=1,
password='123456',
decode_responses=True
)
def process_item(self, item, spider):
years = item['years']
red_balls = ".".join(item['red_balls'])
blue_balls = item['blue_balls']
self.redis.rpush('years', years)
self.redis.rpush('red_balls', red_balls)
self.redis.rpush('blue_balls', blue_balls)
return item
def close_spider(self, spider):
self.redis.close()
注意:如果有多个管道,一定要return item回去,下个管道就能接到这个管道处理的item数据/在写完管道的类之后要在setting配置一个新管道才能正常执行:
ITEM_PIPELINES = {
"lottery.pipelines.LotteryPipeline": 300,
"lottery.pipelines.MysqlPipeline": 350,
"lottery.pipelines.RedisPipeline": 400,
}
5.爬虫框架爬取4K壁纸网
知识点:
1.使用scrapy的下载图片的方法必须要在setting给定配置
# 下载图片. 必须要给出一个配置、默认不存在此配置
# 总路径配置
IMAGES_STORE = "./img"
2.在需要请求多个子页面时,需要使用scrapy.Request执行回调,定义回调函数再次请求子页面
yield scrapy.Request(
url=url,
method='get',
callback=self.parse_detail,
)
def parse_detail(self,response,**kwargs):
.....子页面的解析内容
3.scrapy的固定图片存取方案:
-
1.导入组件库、定义一个类继承自组件库名
-
2.定义一个固定函数名
get_media_requests():用于发送请求获取图片、视频文件 -
3.定义一个固定函数名
file_path():用于存储图片,仅需给定存储的文件名和路径即可 -
4.定义一个固定函数名
item_completed:用于后续的处理,它会返回固定的一些类型,可以获取到这些类型进行后续操作,比如:存入Mysql数据库[(True, {'url': '.....', 'path': './img/225620-171440258038bf.jpg', 'checksum': 'c4946cd4c03dde45cf8a744f7058873b', 'status': 'uptodate'})]
# 导入必要的组件库
from scrapy.pipelines.images import ImagesPipeline
# 定义一个新的类,继承自组件库的功能
class MyImgPipeline(ImagesPipeline):
# 1.发送请求
def get_media_requests(self, item, info):
url = item['img_url']
yield scrapy.Request(url=url,meta={'url':url})
# 2.图片的存储路径
def file_path(self, request, response=None, info=None, *, item=None):
# 图片的名称
try:
file_name = request.meta['url'].split('/')[-1]
file_path = './img/'+ file_name
except Exception as e:
print(e)
return file_path
# 3.可能要对Item进行更新
def item_completed(self, results, item, info):
print(results)
return item
Scrapy模拟登录以及分页爬取
一. Scrapy处理cookie
在以往处理cookie中是通过第一次登录在网页抓包工具中获取一个cookie,写入headers头部传给requests模块发送出去,也可以通过request.session来维持登录状态
import requests
# 建立session
session = requests.session()
# 准备用户名密码
data = {
"loginName": "16538989670",
"password": "xxxxxx"
}
# UA
headers = {
"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
# 登录后, 服务器会返回set-cookie. 这种直接返回的cookie会被session自动处理
resp = session.post("https://passport.17k.com/ck/user/login", data=data, headers=headers)
# 可以看一眼cookie中的东西
print(session.cookies)
# 带着cookie请求书架
resp = session.get("https://user.17k.com/ck/author/shelf")
print(resp.text)
Scrapy有三个方案可以处理Cookie:
**方案一:**直接从浏览器复制cookie进来、放进setting的默认请求头里面,并关闭中间件检测(不灵活,但最方便)
# 在这里吧注释的代码打开
COOKIES_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
"Cookie":"GUID=bbb5f65a-2fa2-40a0-ac87-49840eae4ad1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1627572532,1627711457,1627898858,1628144975; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E5%25AD%25A4%25E9%25AD%2582%25E9%2587%258E%25E9%25AC%25BCsb%26e%3D1643697376%26s%3D73f8877e452e744c; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217700ba9c71257-035a42ce449776-326d7006-2073600-17700ba9c728de%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bbb5f65a-2fa2-40a0-ac87-49840eae4ad1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1628145672"
}
**方案二:**在主爬虫逻辑页面重写类的start_requests()函数,并处理cookie
def start_requests(self):
# 直接从浏览器复制
cookies = "GUID=bbb5f65a-2fa2-40a0-ac87-49840eae4ad1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1627572532,1627711457,1627898858,1628144975; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E5%25AD%25A4%25E9%25AD%2582%25E9%2587%258E%25E9%25AC%25BCsb%26e%3D1643697376%26s%3D73f8877e452e744c; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217700ba9c71257-035a42ce449776-326d7006-2073600-17700ba9c728de%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bbb5f65a-2fa2-40a0-ac87-49840eae4ad1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1628145672"
# 定义一个空字典
cookie_dic = {}
# 先吧所有的;拆开
for c in cookies.split("; "):
# 处理成键值对
k, v = c.split("=")
# 添加到字典里面
cookie_dic[k] = v
yield Request(
url=LoginSpider.start_urls[0],
cookies=cookie_dic,
callback=self.parse
)
**方案三:**通过yield Request模拟登录
def start_requests(self):
# 登录流程
username = "18614075987"
password = "q6035945"
url = "https://passport.17k.com/ck/user/login"
# 需要在网页抓包工具中获取到view parsed或自己拼接,这个方法并不好用
# 发送post请求
# yield Request(
# url=url,
# method="post",
# body="loginName=18614075987&password=q6035945",
# callback=self.parse
# )
# 发送post请求
yield FormRequest(
url=url,
formdata={
"loginName": username,
"password": password
},
callback=self.parse
)
def parse(self, response):
# 得到响应结果. 直接请求到默认的start_urls
yield Request(
url=LoginSpider.start_urls[0],
callback=self.parse_detail
)
def parse_detail(self, resp):
'''在这里解析操作'''
print(resp.text)
二.分页爬取
普通的分页爬取是这样的
- 一般的网站虽然在访问的时候感觉第一页和第二页的地址不一样,但其实通过第二页的访问方式也是可以访问到第一页的,所以就可以重写
start_requests()函数循环遍历爬取页数,返回给解析函数进行解析爬取
class ShuoSpider(scrapy.Spider):
name = 'shuo'
allowed_domains = ['17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_0_0_0_0_1.html']
def start_requests(self): # scrapy是协程. 太快了
for i in range(1, 10):
url = f"https://www.17k.com/all/book/2_0_0_0_0_0_0_0_{i}.html"
yield scrapy.Request(url=url, callback=self.parse)
更加模块化的分页爬取:
- 1.解析第一页的数据、获取到你需要的数据
def parse(self, resp, **kwargs): # 解析第一页的逻辑
trs = resp.xpath("//table/tbody/tr")
for tr in trs:
leibie = tr.xpath("./td[2]//text()").extract()
mingzi = tr.xpath("./td[3]//text()").extract()
zuozhe = tr.xpath(".//li[@class='zz']/a/text()").extract_first()
print(leibie, mingzi, zuozhe)
-
2.一般来说网页上的分页都会有一个盒子,只要获取到盒子里面的a标签就可以提取分页的url,通过回调第一步操作,让遍历的每一页都进行第一步的操作,也能达到分页爬取的一个效果
# 获取到分页的url hrefs = resp.xpath("//div[@class='page']/a/@href").extract() for href in hrefs: # 2, 3, 4, 5, 2 if href.startswith("javascript"): continue # print(href) # 2, 3, 4, 5, 2 href = resp.urljoin(href) # 这里就会面对一个问题,每一次循环遍历的次数很有可能是这样的: # 如果每一个页面获取到了重复的url,那么就很有可能程序只会获得1,2的url然后无限循环下去 # 1: 2, 3, 4, 5, # 2: 1, 3, 4, 5, 6 # 3: 1, 2, 4, 5, 6, 7 # 所以这时候scrapy的调度器schedule就起作用了,他内部有一个去重的作用可以自动帮我们完成去重 yield scrapy.Request( url=href, # 2, 3, 4, 5, 6 的结果和1一样. 那么解析的时候. 是不是一样的逻辑 ???? callback=self.parse, # 7777 999 引擎 )
Scrapy中间件

回顾这个流程图,在spider第一次发起request请求的时候会提交给schedule进行去重,再返回给引擎送到downloader里面向网站发送响应内容,在引擎送到downloader之间的这段过程有那么一个插件,他负责截取这段数据,对这段数据进行处理之后返回给指定的内容
1. DownloaderMiddleware
下载中间件, 它是介于引擎和下载器之间, 引擎在获取到request对象后, 会交给下载器去下载, 在这之间我们可以设置下载中间件. 它的执行流程:
引擎拿到request -> 中间件1(process_request) -> 中间件2(process_request) …-> 下载器-|
引擎拿到request <- 中间件1(process_response) <- 中间件2(process_response) … <- 下载器-|
可以发现如果有多个中间件的话,给中间件在setting里面设置较小数字的权限,那么那个较小的中间件会先被发送,但是会最晚被返回
1. from_crawler
- 调用时机:Scrapy 用于创建爬虫实例时调用。
- 用途:该方法用于连接信号,确保
spider_opened在爬虫开启时被调用。 - 示例场景:初始化中间件,并连接爬虫开启信号。
@classmethod
def from_crawler(cls, crawler): # 在创建spider的时候. 自动的执行这个函数
# 在创建spider的时候. 自动的执行这个函数
# 初始化类对象
s = cls()
# 第一个参数是需要绑定这个事件的函数,第二个是启动事件
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(s.custom_function, signal=signals.spider_closed)
return s
def custom_function(self, spider):
pass
2. process_request
- 调用时机:请求在发送给下载器时自动执行的函数。
- 用途:处理或修改请求。
- 返回值:
None:继续向后走,走到后面的中间件或下载器。response:交给引擎。request:交给引擎,继续走调度器进行去重解析再重复。raise IgnoreRequest:交给process_exception处理异常(仅做了解)。
- 示例场景:在请求发送之前检查或修改请求信息。
def process_request(self, request, spider):
print("我要处理请求了")
# return Must either: 返回值必须是以下的某一个
# - None: 继续向后走,走到后面的中间件或者走到下载器
# - Response object, 停下来. 这个请求就不会走下载器, 而是直接把响应对象给到引擎
# - Request object, 停下来.这个请求也不会走下载器. 而是直接把请求对象给到引擎. 引擎继续走调度器。。
return None
3. process_response()
- 调用时机:下载器得到响应对象后,反馈给引擎时调用。
- 用途:处理或修改响应。
- 返回值:
response:返回响应对象。request:返回请求对象,交给引擎,继续走调度器进行去重解析再重复。
- 示例场景:在响应对象反馈给引擎时检查或修改响应数据。
def process_response(self, request, response, spider):
print("我要处理响应了")
# 在响应对象反馈给引擎的时候自动执行, 可以判断各种状态码. 判断返回的数据是否正常.
# Must either; 不能返回None
# - return a Response object 把响应对象返回, 继续往回走
# - return a Request object 返回一个请求对象,直接把请求发给引擎, 引擎继续走调度器。。。。
return response
2.Downloader中间件的用法
2.1 动态随机设置UA
在并发访问网页的时候部分网站会判断你是否使用的是正常的浏览器,这时候需要设置USER_AGENT来伪装,可是在高并发的情况下很容易被检测,这时候就需要随机设置UA来过这么一个检测
# 我希望每次请求都更换一个全新的User_agent
def parse(self, resp, **kwargs):
# 打印请求头
print(resp.request.headers)
在setting里面键入如下数据:
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2820.59 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2762.73 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2656.18 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
]
在中间件里面这样设置:
import random
class MyRandomUserAgentMiddleware:
def process_request(self, request, spider):
UA = choice(USER_AGENT_LIST)
request.headers['User-Agent'] = UA
# 不要返回任何东西
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
2.2 处理代理问题
代理问题一直是我们作为一名爬虫工程师很蛋疼的问题. 不加容易被检测, 加了效率低, 免费的可用IP更是凤毛麟角. 没办法, 无论如何还是得面对它. 这里, 我们采用两个方案来给各位展示scrapy中添加代理的逻辑.
免费代理
....通过代理池获取到代理的IP操作,存入setting数据里
class ProxyMiddleware:
def process_request(self, request, spider):
# 在代理列表里面随机抽取出来一个
proxy = choice(PROXY_LIST)
request.meta['proxy'] = "http://"+proxy # 设置代理
return None
def process_response(self, request, response, spider):
if response.status != 200:
print("尝试失败")
request.dont_filter = True # 丢回调度器重新请求
return request
return response
def process_exception(self, request, exception, spider):
print("出错了!")
pass
付费代理
快代理 - 企业级HTTP代理IP云服务_专注IP代理10年 (kuaidaili.com)
class MoneyProxyMiddleware:
def _get_proxy(self):
"""
912831993520336 t12831993520578 每次请求换IP
tps138.kdlapi.com 15818
需实名认证 5次/s 5Mb/s 有效 续费|订单详情|实名认证
隧道用户名密码修改密码
用户名:t12831993520578密码:t72a13xu
:return:
"""
url = "http://tps138.kdlapi.com:15818"
auth = basic_auth_header(username="t12831993520578", password="t72a13xu")
return url, auth
def process_request(self, request, spider):
print("......")
url, auth = self._get_proxy()
request.meta['proxy'] = url
request.headers['Proxy-Authorization'] = auth
request.headers['Connection'] = 'close'
return None
def process_response(self, request, response, spider):
print(response.status, type(response.status))
if response.status != 200:
request.dont_filter = True
return request
return response
def process_exception(self, request, exception, spider):
pass
2.3 使用selenium联合爬取
首先, 我们需要使用selenium作为下载器进行下载. 那么我们的请求应该也是特殊订制的. 所以, 在我的设计里, 我可以重新设计一个请求. 就叫SeleniumRequest、在新建文件内键入如下代码:
from scrapy.http.request import Request
class SeleniumRequest(Request):
pass
完善一下spider,导入自己定义的模块,在中间件里面做判断
from typing import Iterable
import scrapy
from scrapy import Request
from boss.req import SeleniumRequest
class BosszhipinSpider(scrapy.Spider):
name = "bosszhipin"
allowed_domains = ["zhipin.com"]
start_urls = ["https://www.zhipin.com/web/geek/job?query=Python&city=101280100"]
def start_requests(self):
# 方案一:
# yield scrapy.Request(url=self.start_urls[0],meta={'is_seleniumRequest': 'Yes',})
yield SeleniumRequest(url=self.start_urls[0],dont_filter=True)
yield scrapy.Request(url=self.start_urls[0],dont_filter=True)
def parse(self, response,**kwargs):
print(response.text)
中间件
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from scrapy.http.response.html import HtmlResponse # 需要自己编写响应头,就要导入这个包
from boss.req import SeleniumRequest
class BossDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.start, signal=signals.spider_opened)
crawler.signals.connect(s.end,signal=signals.spider_closed)
return s
def start(self,spider):
'''开始的操作'''
self.web = Edge()
self.web.implicitly_wait(10)
def end(self,spider):
'''结束的操作'''
self.web.close()
def process_request(self, request, spider):
# if request.meta['is_seleniumRequest'] == 'Yes': # 方案一:
# 如果响应对象是自定义类型的就会走这个判断
if isinstance(request,SeleniumRequest):
self.web.get(request.url)
self.web.find_element(By.XPATH,'//*[@id="header"]/div[1]/div[3]/div/span/a[1]')
page_source = self.web.page_source
resp = HtmlResponse( # 组装一个请求对象
status=200,
url=request.url,
body=page_source.encode('utf-8'),
request=request,
)
return resp
else:
return None
3.SpiderMiddleware(了解)
爬虫中间件是一个钩子框架,允许开发者处理 Scrapy 爬虫在执行过程中传递的请求和响应。它可以拦截和处理这些对象,以便在它们进入爬虫或从爬虫返回时进行修改。
3.1 from_crawler
- 调用时机:Scrapy 用于创建爬虫实例时调用。
- 用途:该方法用于连接信号,确保
spider_opened在爬虫开启时被调用。 - 示例场景:初始化中间件,并连接爬虫开启信号。
def from_crawler(cls, crawler):
# 这个方法被 Scrapy 用来创建你的爬虫。
s = cls()
# 在这里键入你需要需要的触发时机以及函数
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
3.2 process_spider_input
- 调用时机:每个响应进入爬虫之前调用。
- 用途:处理或修改传入的响应,可以用于过滤掉某些不需要处理的响应。
- 示例场景:在处理响应之前检查响应状态码,如果状态码不符合预期,抛出异常。
def process_spider_input(self, response, spider):
# 对每个通过爬虫中间件并进入爬虫的响应调用。
# 应返回 None 或抛出异常。
if response.status != 200:
raise IgnoreRequest("Response status not OK")
return None
3.3 process_spider_output
- 调用时机:爬虫处理完响应并返回结果后调用。
- 用途:处理或修改爬虫返回的结果,可以对结果进行过滤、修改或增加额外的请求。
- 示例场景:对爬虫返回的 items 进行进一步的处理或清洗。
def process_spider_output(self, response, result, spider):
# 在爬虫处理响应并返回结果后调用。
# 必须返回一个 Request 或 item 对象的可迭代对象。
for i in result:
...处理
3.4 process_spider_exception
- 调用时机:当爬虫或其他中间件中的
process_spider_input方法抛出异常时调用。 - 用途:处理异常情况,可以进行日志记录或返回备用请求。
- 示例场景:记录异常信息,并生成一个备用请求来替代出错的请求。
def process_spider_exception(self, response, exception, spider):
# 当爬虫或 process_spider_input() 方法(来自其他爬虫中间件)
# 抛出异常时调用。
# 应返回 None 或一个 Request 或 item 对象的可迭代对象。
spider.logger.error(f'Error processing response: {response.url} with exception: {exception}')
return None
3.5 process_start_requests
- 调用时机:对爬虫的初始请求进行处理时调用。
- 用途:处理或修改初始请求,可以对初始请求进行预处理。
- 示例场景:勾八用都没有还难用
def process_start_requests(self, start_requests, spider):
# 对爬虫的起始请求进行调用,类似于 process_spider_output() 方法,
# 但没有关联的响应。
# 必须只返回请求(而不是 items)。
for r in start_requests:
spider.logger.info('Starting request: %s' % r.url)
yield r
3.6 spider_opened
这是一个默认函数、在from_crawler默认调用这个函数
- 调用时机:在爬虫开启时调用。
- 用途:执行一些初始化操作,如日志记录或设置爬虫参数。
- 示例场景:记录爬虫
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
Crawl Spider 延伸框架
Crawl Spider是Scrapy框架的一种扩展,专门用于处理复杂的网站爬取任务。与Scrapy中的基本Spider不同,Crawl Spider提供了更高层次的抽象,特别适用于需要遵循多个链接规则进行深度爬取的场景。通过定义一组规则,Crawl Spider可以自动处理链接的提取和页面的爬取,大大简化了复杂网站的爬取工作,但与之对应的就是他的高度封装使得并不是很灵活
所以在使用前还是要了解一下scrapy如何实现这么一个操作,并非只有crawl能够实现
import scrapy
# 原生scrapy抓取汽车之家
class MycarSpider(scrapy.Spider):
name = "mycar"
allowed_domains = ["che168.com"]
start_urls = ["https://www.che168.com/china/list/#pvareaid=110965"]
# 定义一个数据结构
che_biaoqian = {
"表显里程":"licheng",
"上牌时间":"shangpai",
"挡位/排量":"pailiang",
"车辆所在地":"suozaidi",
"查看限迁地":"check",
}
def parse(self, response,**kwargs):
# 找到详情页
li_list = response.xpath('//div[@class="tp-cards-tofu fn-clear"]/ul/li')
for li in li_list:
# 拿到每个详情页的地址
href = li.xpath('a/@href').extract_first()
href = response.urljoin(href)
# print(href)
if href in 'topicm':
continue
yield scrapy.Request(url=href,callback=self.parse_detail)
# 开始分页
hrefs = response.xpath('//div[@class="page fn-clear"]/a/@href').extract()
for href in hrefs:
if href.startswith('javascript'):
continue
divided_href = response.urljoin(href)
print(divided_href)
# 分页后由引擎调用自身再次进行解析操作
yield scrapy.Request(url=divided_href,callback=self.parse)
# 处理一些数据...
def parse_detail(self,response):
dic = {}
li_list = response.xpath('//ul[@class="brand-unit-item fn-clear"]/li')
for li in li_list:
p_name = li.xpath('./p//text()').extract_first()
p_name = p_name.replace(' ','').split()[0]
p_value = li.xpath('./h4//text()').extract_first()
p_value = p_value.replace(' ', '').split()[0]
data_key = self.che_biaoqian.get(p_name)
dic[data_key] = p_value
if dic:
print(dic)
yield dic
Crawl Spider的定义继承自scrapy.spiders.CrawlSpider,并需要定义一些特定的属性和方法:
name:爬虫的名称,用于识别爬虫实例。allowed_domains:允许爬取的域名列表,防止爬虫爬取到不相关的网站。start_urls:初始请求的URL列表,爬虫从这些URL开始抓取数据。rules:爬取规则列表,定义如何提取链接以及如何处理提取到的链接。
# 创建命令
scrapy genspider -t crawl name xxx.com
或新建一个py文件继承自CrawSpider
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MyCrawlSpider(CrawlSpider):
name = 'my_crawl_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
rules = (
Rule(LinkExtractor(allow=r'/category/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = {}
item['url'] = response.url
return item
爬取规则(Rules)
Crawl Spider的核心在于爬取规则的定义。每个规则(Rule)包含以下几个关键部分:
LinkExtractor:链接提取器,用于从页面中提取符合规则的链接。callback:回调函数,当提取到的链接被爬取时,调用该函数处理响应。follow:是否继续跟进提取到的链接,默认为False,即只提取当前页面的链接,不继续递归爬取。
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
rules = (
Rule(LinkExtractor(allow=r'/category/'), callback='parse_item', follow=True),
)
LinkExtractor(链接提取器)
LinkExtractor是Scrapy中用于提取页面中链接的工具。可以通过正则表达式、CSS选择器或XPath表达式来指定需要提取的链接。常见参数包括:
allow:一个或多个正则表达式,匹配要提取的链接。deny:一个或多个正则表达式,匹配要排除的链接。restrict_xpaths:一个或多个XPath表达式,限定提取链接的范围。restrict_css:一个或多个CSS选择器,限定提取链接的范围。
from scrapy.linkextractors import LinkExtractor
# 仅提取包含 '/category/' 的链接
link_extractor = LinkExtractor(allow=r'/category/')
# 提取所有链接,但排除包含 'ignore' 的链接
link_extractor = LinkExtractor(deny=r'ignore')
# 使用XPath限定提取范围
link_extractor = LinkExtractor(restrict_xpaths='//div[@class="content"]')
# 使用CSS选择器限定提取范围
link_extractor = LinkExtractor(restrict_css='.content')
Crawl Spider的高级使用
1.链接去重
在复杂的网站中,可能会遇到重复链接的问题。Crawl Spider可以通过dont_filter参数来控制链接的去重行为:
rules = (
Rule(LinkExtractor(allow=r'/category/'), callback='parse_item', follow=True, process_links='process_links'),
)
def process_links(self, links):
for link in links:
# 去重链接
link.dont_filter = True
return links
2.动态页面的处理
在settings.py添加如下配置:
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800,
}
# 配置Selenium WebDriver
SELENIUM_DRIVER_NAME = 'chrome'
SELENIUM_DRIVER_EXECUTABLE_PATH = '/path/to/chromedriver'
SELENIUM_DRIVER_ARGUMENTS=['--headless'] # 可选参数,运行无头浏览器
修改Crawl Spider,使用SeleniumMiddleware:
from scrapy_selenium import SeleniumRequest
class MyCrawlSpider(CrawlSpider):
name = 'my_crawl_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
rules = (
Rule(LinkExtractor(allow=r'/category/'), callback='parse_item', follow=True),
)
def start_requests(self):
for url in self.start_urls:
yield SeleniumRequest(url=url, callback=self.parse)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = {}
item['url'] = response.url
return item
Scrapy 增量式与分布式爬取
1. 增量式爬取
增量式爬取是一种优化的爬取策略,其核心思想是在数据源更新时,仅抓取新增或变化的数据。通过这种方式,可以大大减少重复抓取已经存在的数据,节省带宽和存储空间,提高爬取效率,在电商平台的数据抓取中,商品信息经常更新。通过增量式爬取,可以只抓取新上架或信息更新的商品,节省了大量的资源。例如,一个大型在线零售商每天都会更新大量商品的价格和库存信息,通过增量式爬取,能够确保爬虫只抓取这些变化的商品信息,显著提高了效率。
实现增量式爬取的策略
- 数据标记法:
- 利用数据源提供的时间戳或唯一标识符,记录上次爬取的位置,下一次爬取时仅抓取之后更新的数据。
- 哈希校验法:
- 对每条数据生成哈希值,存储哈希值以供比对。下一次爬取时,计算新数据的哈希值并与已存储的哈希值进行比较,仅抓取变化的数据。
- 数据库比对法(最常用,好维护,简单易写):
- 将爬取到的数据存储在数据库中,每次爬取时将新数据与数据库中的旧数据进行比对,仅保存变化的数据。
数据库比对法:
spider:
import scrapy
from scrapy import signals
from redis import Redis
class TySpider(scrapy.Spider):
name = "ty"
start_urls = ["https://www.tianya.net.cn/forum-5-1.html"]
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
'''初始化'''
s = cls(*args, **kwargs)
s.crawler = crawler
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def spider_opened(self, spider):
'''爬虫开始时执行'''
self.redis = Redis(host='localhost', port=6379, db=0, password='123456')
def spider_closed(self, spider):
'''爬虫结束时执行'''
if self.redis:
self.redis.close()
def parse(self, response, **kwargs):
url = response.xpath('//*[@id="threadlisttableid"]/li/div/div[2]/h2/a/@href').extract()
title = response.xpath('//*[@id="threadlisttableid"]/li/div/div[2]/h2/a/span/text()').extract()
for u, t in zip(url, title):
herf = response.urljoin(u)
if response.status == 200:
if self.redis.sismember('tianya_url', herf):
print(f'标题:{t},链接:{herf}已存在')
continue
else:
yield scrapy.Request(url=herf, callback=self.parse_detail, meta={"title": t, "herf": herf})
# 翻页
next_url = response.xpath('//*[@class="pg"]/a[text()="下一页"]/@href').extract_first()
for i in range(2, 10):
if next_url:
next_url = response.urljoin(next_url)
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_detail(self, response):
title = response.meta.get("title")
content = response.xpath('//*[@class="pcb"]//text()').extract()
content = "".join(content).strip()
print(f'文章标题:{title}\n文章内容:{content}')
self.redis.sadd('tianya_url', response.meta["herf"])
yield {
'title': title,
'content': content
}
pipeline:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from redis import Redis
class TianyaPipeline:
def open_spider(self, spider):
self.redis = Redis(host='localhost', port=6379, db=0,password='123456')
def close_spider(self, spider):
if self.redis:
self.redis.close()
def process_item(self, item, spider):
content = item['content']
if self.redis.sismember('tianya:content', content):
print('该内容已经存在,不再保存')
else:
self.redis.sadd('tianya:content', content)
print('保存成功')
return item
2. 分布式爬取
分布式爬取是指将爬虫任务分散到多台机器上同时进行,以提高爬取效率和覆盖范围。通过分布式爬取,可以处理更大规模的数据,并且能够应对更复杂的爬取任务,增量式爬取和分布式爬取是提高数据抓取效率和处理大规模数据的两种重要技术。在实际应用中,将这两种技术结合使用,可以最大化地发挥它们的优势,解决复杂的数据抓取问题。
分布式爬取的基本架构包括以下几个部分:
- 调度器:负责分配爬取任务。
- 爬虫节点:实际执行爬取任务的机器。
- 数据存储:集中存储爬取到的数据。
- 任务队列:管理爬取任务的队列。
使用 Scrapy-Redis 实现分布式爬取
分布式爬虫, 就是搭建一个分布式的集群, 让其对一组资源进行分布联合爬取.
既然要集群来抓取. 意味着会有好几个爬虫同时运行. 那此时就非常容易产生这样一个问题. 如果有重复的url怎么办? 在原来的程序中. scrapy中会由调度器来自动完成这个任务. 但是, 此时是多个爬虫一起跑. 而我们又知道不同的机器之间是不能直接共享调度器的. 怎么办? 我们可以采用redis来作为各个爬虫的调度器. 此时我们引出一个新的模块叫scrapy-redis. 在该模块中提供了这样一组操作. 它们重写了scrapy中的调度器. 并将调度队列和去除重复的逻辑全部引入到了redis中. 这样就形成了这样一组结构
- 1.某个爬虫从redis_key获取到起始url. 传递给引擎, 到调度器. 然后把起始url直接丢到redis的请求队列里. 开始了scrapy的爬虫抓取工作.
- 2.如果抓取过程中产生了新的请求. 不论是哪个节点产生的, 最终都会到redis的去重集合中进行判定是否抓取过.
- 3.如果抓取过. 直接就放弃该请求. 如果没有抓取过. 自动丢到redis请求队列中.
- 4.调度器继续从redis请求队列里获取要进行抓取的请求. 完成爬虫后续的工作.
实现操作:
-
1.导包
from scrapy_redis.spiders import RedisSpider -
2.继承自Redis类,并设置启动代码
class TySpider(RedisSpider): redis_key = 'tianya:start_urls' -
3.修改设置setting
REDIS_HOST = "127.0.0.1" REDIS_PORT = 6379 REDIS_DB = 8 REDIS_PARAMS = { "password":"123456" } # scrapy-redis配置信息 # 固定的 SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True # 如果为真. 在关闭时自动保存请求信息, 如果为假, 则不保存请求信息 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 去重的逻辑. 要用redis的 ITEM_PIPELINES = { 'tianya2.pipelines.Tianya2Pipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 301 # 配置redis的pipeline } -
4.在redis内键入启动代码
lpush tianya:start_urls "url"
逆向爬虫
HTTP代理神器Fiddler
Fiddler的简介
Fiddler是位于客户端和服务器端之间的代理,也是目前最常用的抓包工具之一 。它能够记录客户端和服务器之间的所有 请求,可以针对特定的请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
看到这么多的应用,是不是就迫不及待的想要开始你的抓包之旅呢,不要急,俗话说的好:工欲善其事,必先利其器,我们先来安装Fiddler吧。
工作原理
Fiddler 是以代理web服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888
Fiddler的配置
配置连接信息:Tools > Options >Connections
-
端口默认是8888,你可以进行修改。
-
勾选 Allow remote computers to connect 选项,然后重启Fiddler,再次打开时会弹出一个信息,选择ok即可。
-
fiddler默认只抓http请求,若要抓https请求,要进入tools-fiddler options设置
Fiddler界面
设置好后,本机HTTP通信都会经过127.0.0.1:8888代理,也就会被Fiddler拦截到。
fiddler_show (1).png
请求 (Request) 部分详解
- Headers —— 显示客户端发送到服务器的 HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。
- Textview —— 显示 POST 请求的 body 部分为文本。
- WebForms —— 显示请求的 GET 参数 和 POST body 内容。
- HexView —— 用十六进制数据显示请求。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息.
- Raw —— 将整个请求显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果请求的 body 是 XML 格式,就是用分级的 XML 树来显示它。
响应 (Response) 部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的 header。
- TextView —— 使用文本显示相应的 body。
- SyntaxView——响应数据
- ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
- Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密 (P3P) 信息。
- Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
PyExecJS
PyExecJS 是一个强大的工具,允许在 Python 环境中使用 JavaScript 引擎来执行 JavaScript 代码。它支持多种 JavaScript 引擎,提供了灵活的接口和错误处理机制,适用于各种需要在 Python 中运行 JavaScript 的场景。
2. 使用方法
2.1 运行 JavaScript 代码
你可以使用 PyExecJS 来执行 JavaScript 代码字符串,并获取执行结果:
import execjs
# 执行简单的 JavaScript 代码
ctx = execjs.compile('''
function add(x, y) {
return x + y;
}
''')
result = ctx.call('add', 3, 4)
print(result) # 输出 7
在上面的例子中,execjs.compile 方法编译了一个包含 add 函数的 JavaScript 代码块,并且可以通过 ctx.call 方法调用 JavaScript 函数并获取返回值。
2.2 执行外部 JavaScript 文件
除了直接执行字符串中的 JavaScript 代码,你也可以执行外部 JavaScript 文件:
import execjs
# 执行外部 JavaScript 文件
with open('example.js', 'r') as f:
js_code = f.read()
ctx = execjs.compile(js_code)
result = ctx.call('add', 3, 4)
print(result) # 输出 7
在这个示例中,假设 example.js 文件包含了 add 函数的定义,execjs.compile 方法会编译并执行这个文件中的 JavaScript 代码。
2.3 使用不同的 JavaScript 引擎
PyExecJS 支持多种 JavaScript 引擎,你可以选择不同的引擎来执行 JavaScript 代码。例如,可以使用 Node.js、V8 等不同的引擎。以下是一个示例:
import execjs
# 使用 Node.js 引擎
ctx = execjs.get("Node")
result = ctx.eval('1 + 2')
print(result) # 输出 3
在这个例子中,execjs.get("Node") 获取了 Node.js 引擎,然后使用 ctx.eval 方法执行简单的 JavaScript 表达式并获取结果。
2.4 错误处理
在执行 JavaScript 代码时,可能会遇到 JavaScript 运行时的错误。PyExecJS 可以捕获并处理这些错误:
import execjs
try:
ctx = execjs.compile('''
function add(x, y) {
return x + y;
}
add(); // 这里会导致 JavaScript 运行时错误
''')
result = ctx.call('add', 3, 4)
print(result)
except execjs.RuntimeError as e:
print("JavaScript 运行时错误:", e)
在这个示例中,add() 函数调用缺少了必要的参数,会导致 JavaScript 运行时错误,PyExecJS 可以捕获并输出相应的错误信息。
3. Windows环境布设模板
const jsdom = require("D:\\Program Files\\nodejs\\node_global\\node_modules\\jsdom");
const {JSDOM} = jsdom;
const resourceLoader = new jsdom.ResourceLoader({
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36"
});
const html = `<!DOCTYPE html><p>Hello world</p>`;
const dom = new JSDOM(html, {
url: "https://www.toutiao.com",
referrer: "https://example.com/",
contentType: "text/html",
resources: resourceLoader,
});
//window = {}
window = global;
const params = {
location: {
hash: "",
host: "www.toutiao.com",
hostname: "www.toutiao.com",
href: "https://www.toutiao.com",
origin: "https://www.toutiao.com",
pathname: "/",
port: "",
protocol: "https:",
search: "",
},
navigator: {
appCodeName: "Mozilla",
appName: "Netscape",
appVersion: "5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
cookieEnabled: true,
deviceMemory: 8,
doNotTrack: null,
hardwareConcurrency: 4,
language: "zh-CN",
languages: ["zh-CN", "zh"],
maxTouchPoints: 0,
onLine: true,
platform: "MacIntel",
product: "Gecko",
productSub: "20030107",
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
vendor: "Google Inc.",
vendorSub: "",
webdriver: false
}
};
Object.assign(global,params);
document = dom.window.document;
抓包工具Charles
一个HTTP抓包工具,支持 windows Linux Mac
官网:www.charlesproxy.com
下载对应版本:
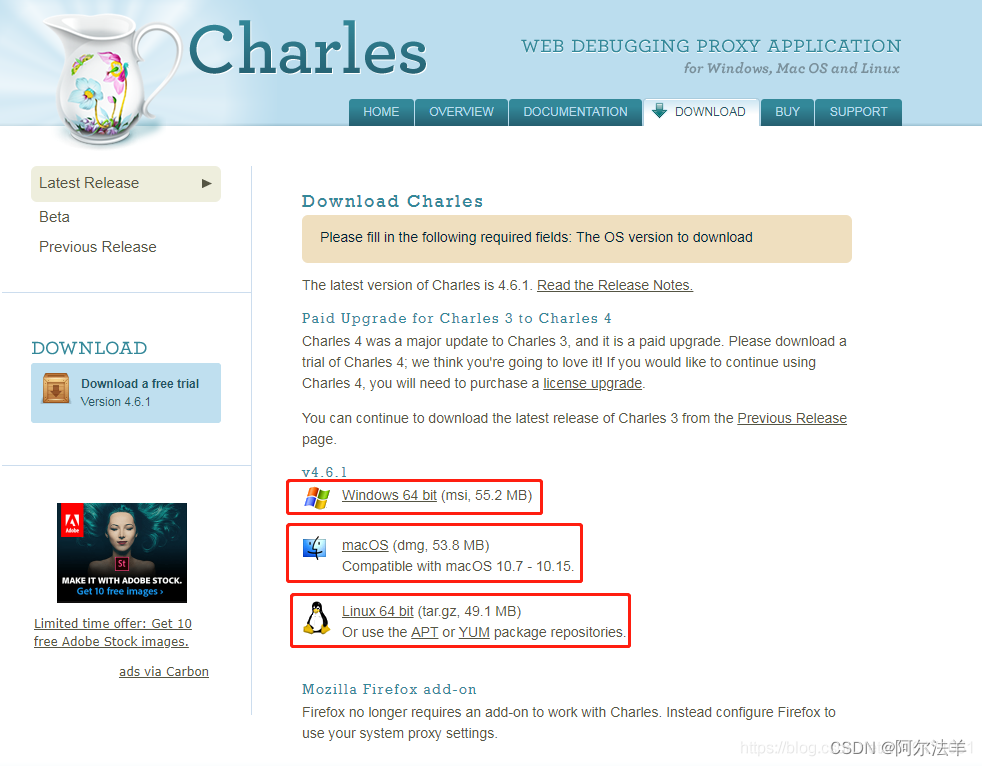
Charles 设置HTTPS代理抓包方法及原理
PC设置https代理抓包第一步:电脑端安装 Charles 的 CA 证书(必须)
在Charles的菜单栏上选择“Help”->“SSL Proxying”->“Install Charles Root Certificact”,
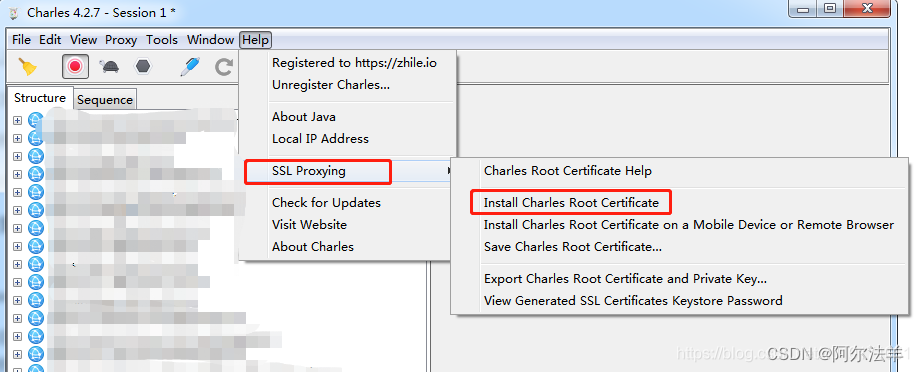
出现证书安装页面,点击“安装证书(I)…”,进入证书导入向导,下一步…完成安装
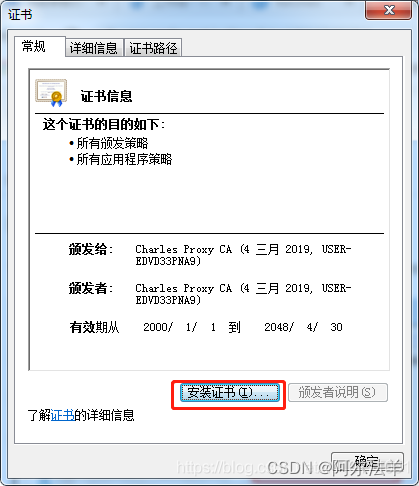
第二步:电脑上charles的SSL抓取设置(必须)
charles并不是默认抓取ssl的,所以即使你安装完证书之后,Charles 默认也并不截取 Https的信息,你需要在SSL proxy里设置需要抓的域名,因为charles的location配置都是支持通配符的,所以在HOST里设置一个”*”就可以了,port不写;
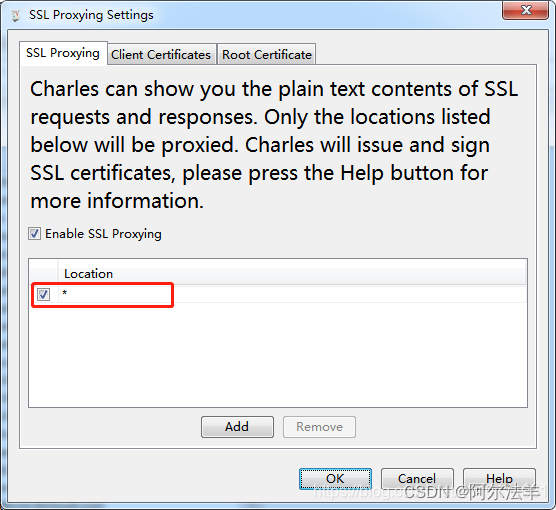
Charles 手机抓包HTTPS设置以及证书安装 手机抓包的原理,和PC类似
第一步:设置charles为允许状态,并设置好接入端口;
在Charles的菜单栏上选择“Proxy”->“Proxy Settings”,填入代理端口8888(注意,这个端口不一定填写8888,也可以写别的端口,但是需要记住这个端口,因为这里设置的允许接入的端口,手机端配置的时候需要用到),并且勾上”Enable transparent HTTP proxying” 就完成了在Charles上的设置。如下图
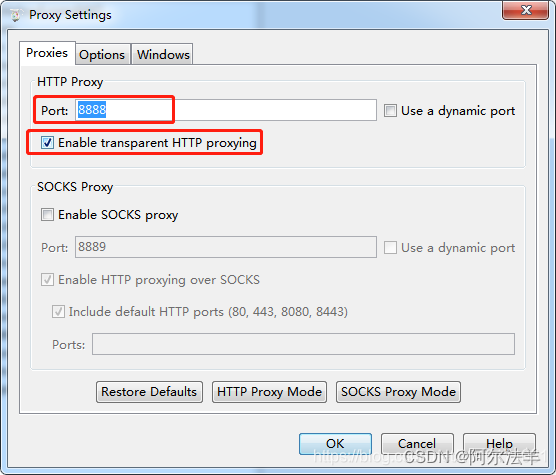
需要找到charles的本机IP;点击HTLP -> local IP Address 可以看到当前的本机IP地址;
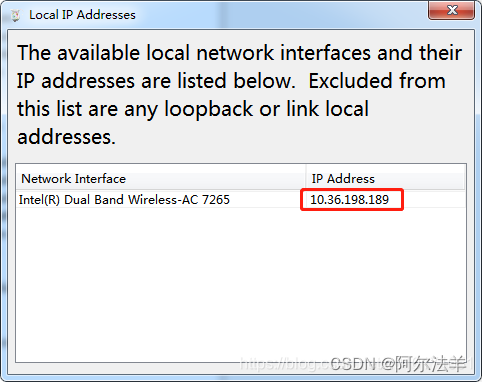
charles允许手机接入的IP和端口是10.36.198.189:8888 在浏览器输入 这个HOST会发现charles会提示一个窗口问你是否允许接入;点击Allow,即可接入代理
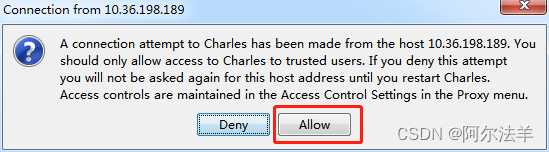
第二步:把手机按照charles的IP和端口进行配置;
手机链接wifi,wifi的HTTP代理选择手动那项(安卓类似)
在iPhone的 “设置”->“无线局域网“中,可以看到当前连接的wifi名,通过点击右边的详情键,可以看到当前连接上的wifi的详细信息,包括IP地址,子网掩码等信息。在其最底部有“HTTP代理”一项,我们将其切换成手动,然后填上Charles运行所在的电脑的IP,以及端口号8888
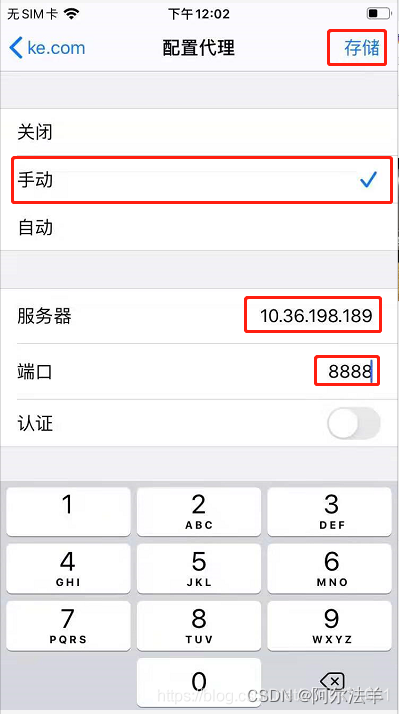
第三步,手机配对成功后,charles弹窗询问是否允许;
设置好之后,我们打开iPhone上的任意需要网络通讯的程序,就可以看到Charles弹出iPhone请求连接的确认菜单
如上图的弹窗,点击Allow即可;此时已经配对成功,开始愉快的抓包吧;
如果您的charles没有配置过,是抓取不到HTTPS这种加密协议的内容的;
如果需要抓取HTTPS网站的资源,请查看 Charles的HTTPS抓包方法及原理
注意:需要明白一个可能存在的弊端,如果你把手机的上网相关事情委托给了charles,那么当charles出错或者没有开启的时候,此时手机必定没有办法正常上网;这个一定要了解,因为很多人把手机的IP委托给charles进行代理后,第二天早晨上本的时候,手机wifi会默认链接你常用的高清度wifi;而此时的wifi的设置里面可能已经委托给charles了,但是此时电脑刚没有开charles或者重启后ip变动等;造成charles无法正常使用;由此而导致了无法上网的问题;
注意charles此种捕获方式,只能捕获发出请求的资源,如果是APP里,内部的代码和资源,因为没有向服务器发情请求,所以这是抓不到的;
判断是不是调用内部资源,你可以把手机的网络给断了,如果此时还可以正常的显示,说明该资源是写在APP内部的,通过代理的方式是抓不到的;
手机抓取https
手机安装SSL证书(如果你需要抓取手机访问的HTTPS网站,需要做此设置,但如果你不需要手机抓取HTTPS,就没有必要安装了)
和上面类似,也是HTLP下面的 SSL Proxying,选择”Install Charles Root Certificate on a Mobile Device or remote Browser” (在移动设备或远程浏览器上安装SSL证书)
然后会看到一个弹窗,提示你该怎么操作
configure your device to use charles as its HTTP proxy on 10.36.198.189.8888,then browse to chls.pro/ssl to download and install the certificate
大概的意思是让你把手机上的wifi信息设置了 HTTP代理,内容是10.36.198.189.8888;然后用浏览器浏览chls.pro/ssl就可以下载并安装证书了
手机安装证书:在浏览器中输入:chls.pro/ssl 下载安装证书即可(安卓建议不要用手机自带浏览器下载,可能会出现安装不上的情况,如果安装不上,找到设置->安全与隐私->加密和凭证->从存储设备安装(安卓下载证书或安装证书有问题建议使用其他浏览器下载)。Ios手机:1.设置->通用->描述文件与设备管理,安装证书;2.通用->关于本机->证书信任设置-开启)
Charles常见操作
过滤域名
方法一:直接过滤域名;
在主界面的中部的 Filter 栏中填入需要过滤出来的关键字。
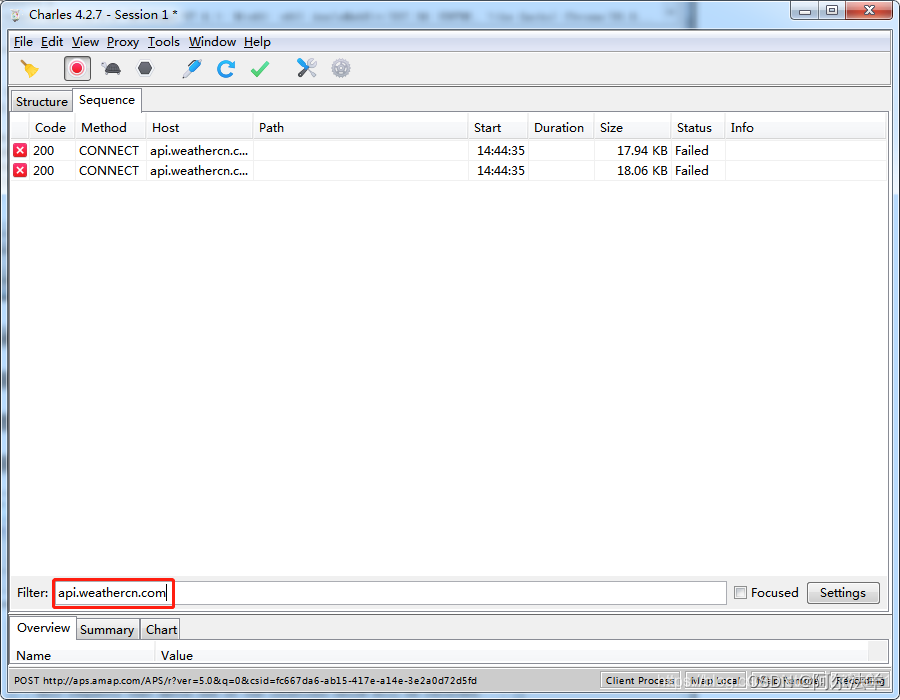
方法二:修改Include的域名和端口
在 Charles 的菜单栏选择 “Proxy”->”Recording Settings”,
然后选择 Include 栏,选择添加一个项目,然后填入需要监控的协议,主机地址,端口号。
这样就可以只截取目标网站的封包了;
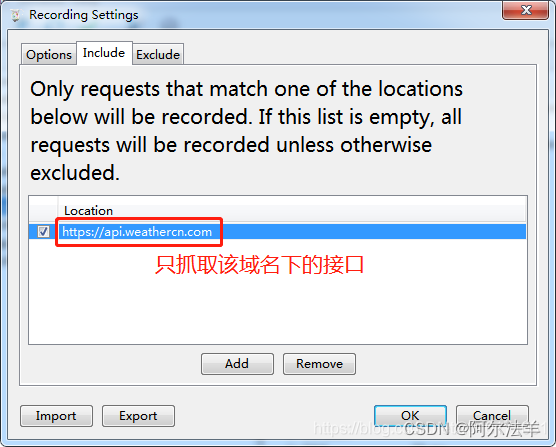
通常情况下,我们使用方法一做封包过滤,方法二做一些唯一的域名抓包,正常情况下,不推荐这种设置方法;
因为这种方法,你的charles只能抓你配置的域名;
如果某天早晨,你的charles一切正常,访问也正常,而且在active commections里也看到了某个域名的请求信息,但是在主界面死活看到获取到的信息;
不用着急,非常有可能是因为你设置了include的指定域名;
而且是设置后你忘记解除了,导致你一脸懵逼;
这种方法非常不推荐,太粗暴了,除非你这半个月都只看某个HOST下的信息,否则千万千万别这么搞,很容易在以后使用时候的忘记解除;
如果你只是为了更清楚的查看某个域名下的请求和响应信息,推荐使用结构视图模式下的焦点域名设置;那种模式比这种方法更好,下面是过滤焦点域名后在序列模式下的调用方法;
方法三:过滤焦点域名
①点击fillter后面的focused来筛选你的做的focus标记文件
②在目标的网络请求上右键,选中focus(此时,该域名已经被设置为一个焦点标记了;
你设置的焦点域名在"View"->”focused Hosts”里面可以查看和管理
结构视图,这种模式下的展现更加人性化;
当你设置某个域名为焦点域名的时候,会把当前域名单独显示在上面,
而其它的非焦点域名,都会在other Hosts里显示;
Chrome插件 EditThisCookie
Chrome浏览器的一个插件,可以方便管理、操作 cookie.
官网:https://www.editthiscookie.com/
也可以直接用Chrome浏览器扩展安装 EditThisCookie是一个cookie管理器。您可以添加,删除,编辑,搜索,锁定和屏蔽cookies! 针对Google Chrome浏览器的第一个也是最棒的cookie管理器。
★ 编辑cookies
★ 删除cookies
★ 添加一个新的cookie
★ 创建cookies
★ 搜索cookies
★ 保护cookies (只读cookies)
★ 拦截cookies (cookie 过滤器)
★ 导出cookies为JSON, Netscape cookie 文档 (非常适合wget及curl), Perl::LPW
★ 导入JSON格式cookies
★ 限制任何cookie的最大有效期
★ 改进性能,移除旧的cookies
★ 导入cookies.txt
功能介绍****cookie 属性 打开控制面板 -> EditThisCookie 就可以很方便的编辑当前页面的cookie
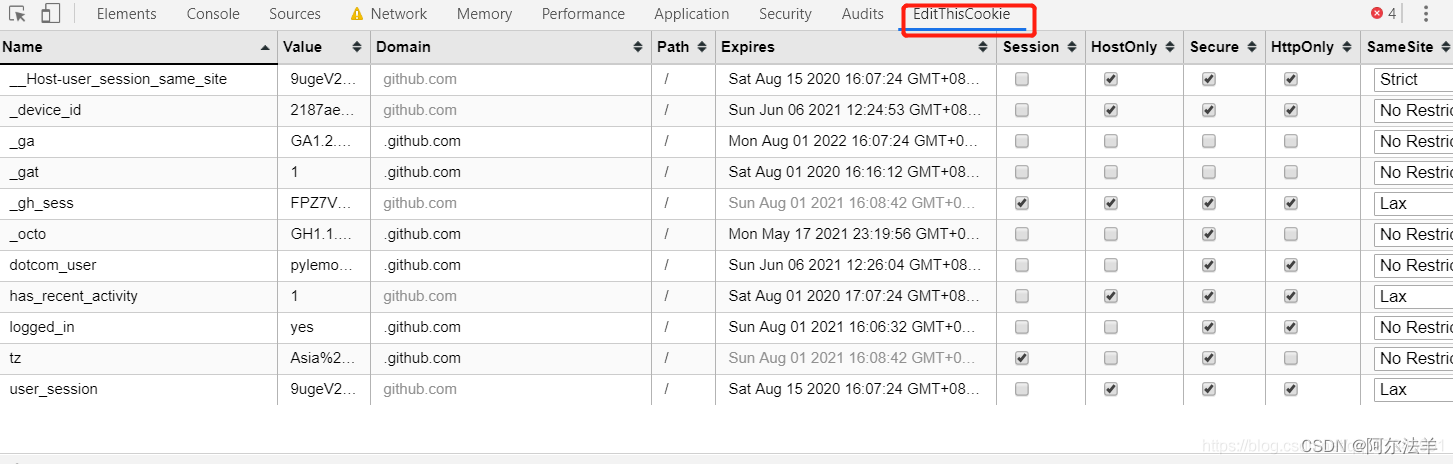
name字段:一个cookie的名称
value字段:一个cookie的值
domain字段:可以访问此cookie的域名
path字段:可以访问此cookie的页面路径
Size字段:此cookie大小
http字段:cookie的httponly属性,若此属性为True,则只有在http请求头中会有此cookie信息,而不能通过document.cookie来访问此cookie。
secure字段:设置是否只能通过https来传递此条cookie。
expires/Max-Age字段:设置cookie超时时间。如果设置的值为一个时间,则当到达该时间时此cookie失效。不设置的话默认是session,意思是cookie会和session一起失效,当浏览器关闭(并不是浏览器标签关闭,而是整个浏览器关闭)后,cookie失效。
host-only:在Cookie中不包含Domain属性,或者Domain属性为空,或者Domain属性不合法(不等于页面url中的Domain部分、也不是页面Domain的大域)时为true。此时,我们把这个Cookie称之为HostOnly Cookie
编辑cookie 示例HttpOnly: 这里我HttpOnly 全部设置为 True,这是js就获取不到cookie
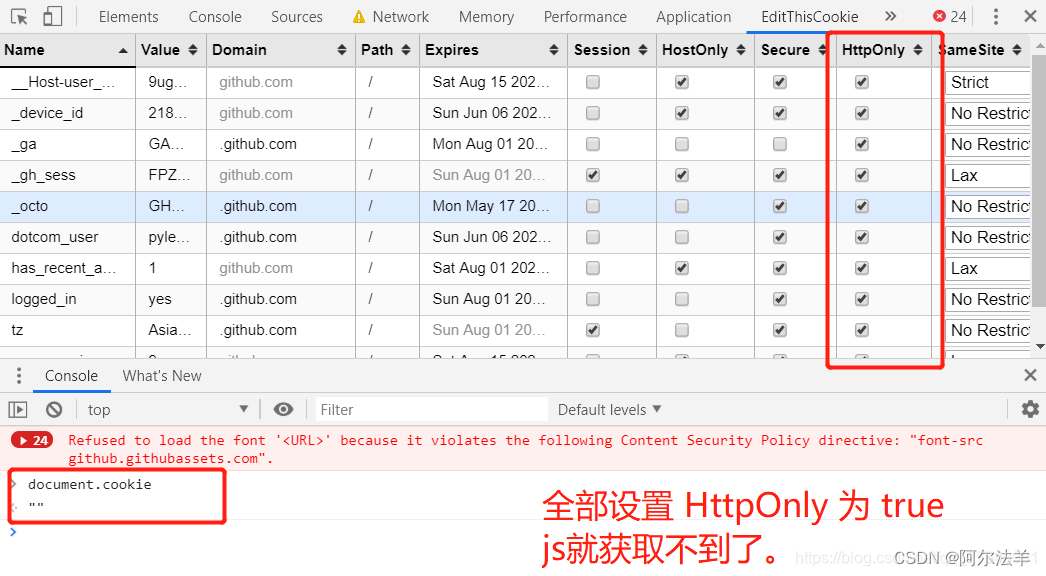
这里 勾选了_device_id 的 HttpOnly属性,这时js就可以获取到该cookie。

其他的属性可以自行设置,自行尝试。
Chrome插件 Tampermonkey
安装:可以从Google商店里面安装
油猴插件是一款用于管理用户脚本的插件,它本身没有什么功能,真正起作用的是它所管理的那些用户脚本。你可以根据需求,利用油猴插件来安装某些特定的用户脚本,从而实现定制化的功能。
安装:
油猴插件是一款用于管理用户脚本的插件,它本身没有什么功能,真正起作用的是它所管理的那些用户脚本。你可以根据需求,利用油猴插件来安装某些特定的用户脚本,从而实现定制化的功能。
用户脚本的安装
以上只是完成了油猴插件的安装,接下来讲述如何将用户脚本集成到油猴插件中。
在扩展程序中选择“篡改猴”以显示其图标,在图标上左键单击,选择“获取新脚本”。
弹出的页面如下,我们一般选择GreasyFork(比较受欢迎的缘故)。
然后在弹出的界面里输入想要的脚本,比如“网盘智能识别助手”。点击某个搜索结果,然后选择“安装此脚本”,完成安装即可。
这个被集成到油猴插件中的脚本,在某种场景下会自动地运行。比如将“网盘智能识别助手”集成到油猴插件中后,当你在某个网页中选中一段带有网盘链接和提取码的文字时,会智能识别选中文字中的网盘链接和提取码,并打开网盘链接并自动填写提取码,省去手动复制提取码再输入的烦恼。
注意事项
window对象
NodeJS中是没有window对象的,如果使用window对象需要自己创建一个或者指向global,使用jsdom之类的库,自己定义window document screen等对象
var window = {}
var document = {}
document = {"location":{"href":"https://bbs.nightteam.cn/member.php?mod=register"}}
var screen = {"width":900,"height":1200}
console.log(screen.width)
网站主要反爬手段梳理
我们学过Python就已经基本掌握了爬虫的技术,那么为啥还要js逆向呢?这里有必要梳理一下js逆向的主要原理。
在Web系统发展早期,Js在Web系统中承担的职责并不多,Js文件比较简单,也不需要任何的保护。
随着Js文件体积的增大和前后端交互增多,为了加快http传输速度并提高接口的安全性出现了很多的压缩工具
和混淆加密工具。
代码混淆的本质是对于代码标识和结构的调整,从而达到不可读不可调用的目的,常用的混淆有字符串、变量名混淆,
比如把字符串转换成_0x,把变量重命名等,从结构的混淆包括控制流平坦化,虚假控制流和指令替换
,代码加密主要有通过eval方法去执行字符串函数,通过escape()等方法编码字符串、通过转义字符加密代码、
自定义加解密方法(RSA、Base64、AES、MD5等),或者通过一些开源的工具进行加密。
另外目前市面上比较常见的混淆还有ob混淆(obfuscator)
,特征是定义数组,数组位移。不仅Js中的变量名混淆,运行逻辑等也高度混淆,
应对这种混淆可以使用已有的工具ob-decrypt或者AST解混淆或者使用第三方提供的反混淆接口。
例如翻看网站的Javascript源代码,可以发现很多压缩或者看不太懂的字符,如javascript文件名被编码,
文件的内容被压缩成几行,变量被修改成单个字符或者一些十六进制的字符——这些导致我们无法轻易根据Javascript
源代码找出某些接口的加密逻辑。
简单说,爬虫获取数据的过程就是爬虫工作者和网站之间的一场攻防战,网站希望真实的用户来访问,
不希望爬虫来访问,所以对爬虫设置了重重障碍,而所用的手段,主要就是利用JS进行处理,
那么JS逆向就是突破网站在JS中设置的重重障碍,拿到想要的数据的过程。
知己知彼百战不殆,我们只有了解网站在反爬方面采用的是哪些手段,才能有针对性地想办法逆向突破。
下面我们就从压缩、混淆、加密/解密 三个方面来梳理一下目前大部分网站的主要反爬手段。
1、压缩
Javascript压缩即去除JavaScript代码中不必要的空格、换行等内容或者把一些可能公用的代码进行
处理实现共享,最后输出的结果都压缩为几行内容,代码的可读性变得很差,同时也能提高网站的加载速度。
如果仅仅是去除空格、换行这样的压缩方式,其实几乎是没有任何防护作用的,
因为这种压缩方式仅仅是降低了代码的直接可读性。因为我们有一些格式化工具可以轻松将JavaScirpt代码
变得易读,比如利用IDE、在线工具或Chrome浏览器都能还原格式化的代码。
这里举一个最简单的JavaScript压缩示例。原来的JavaScript代码是这样的:
function echo(stringA, stringB){
const name = "Germey";
alert("hello " + name);
}
压缩之后就变成这样子:
function echo(d,c){const e="Germey";alert("hello "+e)};
可以看到,这里参数的名称都被简化了,代码中的空格也被去掉了,整个代码也被压缩成了一行,代码的整体可读性降低了。
目前主流的前端开发技术大多都会利用webpack、Rollup等工具进行打包。webpack、Rollup会对源代码进行编译和压缩,输出几个打包好的JavaScript文件,其中我们可以看到输出的JavaScript文件名带有一些不规则的字符串,同时文件内容可能只有几行,变量名都用一些简单字母表示。这其中就包含JavaScript压缩技术,比如一些公共的库输出成bundle文件,一些调用逻辑压缩和转义成冗长的几行代码,这些都属于JavaScript压缩,另外,其中也包含了一些很基础的JavaScript混淆技术,比如把变量名、方法名替换成一些简单的字符,降低代码的可读性。
但整体来说,JavaScript压缩技术只能在很小的程度上起到防护作用,想要真正的提高防护效果,还得依靠JavaScript混淆和加密技术。
对策
使用格式化工具或开发者工具的格式化功能,将压缩的代码还原到可读的形式。例如,在Chrome DevTools中使用Pretty Print功能。
2、混淆
JavaScript混淆完全是在JavaScript上面进行的处理,它的目的就是使得JavaScript变得难以阅读和分析,
大大降低代码的可读性,是一种很实用的JavaScript保护方案。
JavaScript混淆技术主要有以下几种。
变量名混淆:将带有含义的变量名、方法名、常量名随机变为无意义的类乱码字符串,降低代码的可读性,如转换成单个字符或十六进制字符串。
字符串混淆:将字符串阵列化集中并可进行MD5或Base64加密存储,使代码中不出现明文字符串,这样可以避免使用全局搜索字符串的方式定位到入口。
对象键名替换:针对JavaScript对象的属性进行加密转化,隐藏代码之间的调用关系。
控制流平坦化:打乱函数原有代码的执行流程及函数调用关系,使代码逻辑变得混乱无序。
无用代码注入:随机在代码中插入不会被执行到的无用代码,进一步使代码看起来更加混乱。
调试保护:基于调试器特征,对当前运行环境进行检查,加入一些debugger语句,使其在调试模式下难以顺利执行JavaScript代码。
多态变异:使JavaScript代码每次被调用时,将代码自身立刻自动发生变异,变为与之前完全不同的代码,即功能完全不变,只是代码形式变异,以此杜绝代码被动态分析和调试。
域名锁定:使JavaScript代码只能在指定域名下执行。
代码自我保护:如果对JavaScript代码进行格式化,则无法执行,导致浏览器假死。
特殊编码:将JavaScript完全编码为人不可读的代码,如表情符号、特殊表示内容、等等。
总之,以上方案都是JavaScript混淆的实现方式,可以在不同程度上保护JavaScript代码。
在前端开发中,现在JavaScript混淆的主流实现是`javascript-obfuscator`和`terser`这两个库。
它们都能提供一些代码混淆功能,也都有对应的webpack和Rollup打包工具的插件。
利用它们,我们可以非常方便地实现页面的混淆,最终输出压缩和混淆后的JavaScript代码,
使得JavaScript代码的可读性大大降低。
下面我们以javascript-obfuscator为例来介绍一些代码混淆的实现,了解了实现,那么我们自然就对混淆的机制有了更加深刻的认识。
javascript-obfuscator的官方介绍内容如下:
链接:Javascript Obfuscator - Protects JavaScript code from stealing and shrinks size - 100% Free
它是支持ES8的免费、高效的JavaScript混淆库,可以使得JavaScript代码经过混淆后难以被复制、盗用、混淆后的代码具有和原来的代码一模一样的功能。
当然首先要装好nodeJS,然后新建一个文件夹,比如js-ob然后进入该文件夹,初始化工作空间:
npm init
这里会提示我们输入一些信息,然后创建package.json文件,这就完成了项目的初始化了。
接下来,我们来安装javascript-obfuscator这个库:
npm i -D javascript-obfuscator
稍等片刻,即可看到本地js-ob文件下生成了一个node_modules文件夹,里面就包含了javascript-obfuscator这个库,这就说明安装成功了。
2.1 用javascript-obfuscator库实现“控制流平坦化”
新建main.js文件,其内容如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
let x = '1' + 1
console.log('x', x)
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
compact: false, // 设置 `compact` 选项为 `false`,以保持混淆后的代码不压缩
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
这里我们定义了两个变量:一个是code,即需要被混淆的代码;另一个是混淆选项options,是一个Object。接下来,我们引入了javascript-obfuscator这个库,然后定义了一个方法,给其传入code和options来获取混淆之后的代码,最后控制台输出混淆后的代码。
node main.js
输出结果如下:
看到了吧,那么简单的代码,被我们混淆成了这个样子,其实这里我们就是设定了“控制流平坦化”选项。整体看来,代码的可读性大大降低了,JavaScript调试的难度也大大加强了。
对策
手动分析被混淆的控制流,重构原始逻辑。一般来说多个代码的调用会有一个字符数组作为提示,找到字符数组再吧js代码替换为正确的执行顺序执行
2.2 javascript-obfuscator实现变量名混淆
变量名混淆可以通过在javascript-obfuscator中配置identifierNamesGenerator参数来实现。
我们通过这个参数可以控制变量名混淆的方式,如将其设置为hexadecimal,
则会将变量名替换为十六进制形式的字符串。该参数的取值如下。
hexadecimal:将变量名替换为十六进制形式的字符串,如0xabc123。
mangled:将变量名替换为普通的简写字符,如a,b,c等。
该参数的默认值为:hexadecimal
我们将该参数改为:mangled 来试一下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
let x = '1' + 1
console.log('x', x)
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
compact: true, // 设置 `compact` 选项为 `true`,以压缩混淆后的代码。
identifierNamesGenerator: 'mangled' // 使用 `mangled` 模式生成简短、混淆的标识符名称。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下: 另外,我们还可以通过设置identifiersPrefix参数来控制混淆后的变量前缀,示例如下:
另外,我们还可以通过设置identifiersPrefix参数来控制混淆后的变量前缀,示例如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
let x = '1' + 1
console.log('x', x)
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
identifiersPrefix: 'kk', // 设置标识符前缀为 'kk',混淆后的变量名将以 'kk' 开头。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下:
可以看到,混淆后的变量前缀加上了我们自定义的字符串kk。
另外,renameGlobals这个参数还可以指定是否混淆全局变量和函数名称,默认值为false。示例如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
var $ = function(id){
return document.getElementById(id);
};
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
renameGlobals: true, // 设置 `renameGlobals` 选项为 `true`,对全局变量进行重命名。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下:
可以看到,这里我们声明了一个全局变量$,在renameGlobals设置为true之后,
这个变量也被替换了。如果后文用到了这个变量,可能就会有找不到定义的错误,
因此这个参数可能导致代码执行不通。
如果我们不设置 renameGlobals 或者将其设置为false,结果如下:
可以看到,最后还是有$的声明,其全局名称没有被改变。
对策
通过运行时调试和分析变量值来理解变量的真实用途,尽管变量名已被混淆。工具如Chrome DevTools可以帮助在执行过程中检查和修改变量值,在浏览器自带的console窗口执行该变量名,即可看到该值
2.3 javascript-obfuscator字符串混淆
字符串混淆,就是将一个字符串声明放到一个数组里面,
使之无法被直接搜索到。这可以通过stringArray参数来控制,默认为true。
此外,我们还可以通过rotateStringArray参数来控制数组化后结果的元素顺序,默认为true。
示例如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
var a = 'helloworld'
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
stringArray: true, // 启用字符串数组功能,将字符串提取到一个数组中。
rotateStringArray: true, // 启用字符串数组旋转功能,打乱字符串数组的顺序。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下:

另外,我们还可以使用unicodeEscapeSequence这个参数对字符串进行Unicode转码,
使之更加难以辨认,示例如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
var a = 'hello world'
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
compact: false, // 设置 `compact` 选项为 `false`,保留混淆后的代码格式和缩进。
unicodeEscapeSequence: true // 启用 `unicodeEscapeSequence` 选项,将字符串转换为 Unicode 转义序列。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下: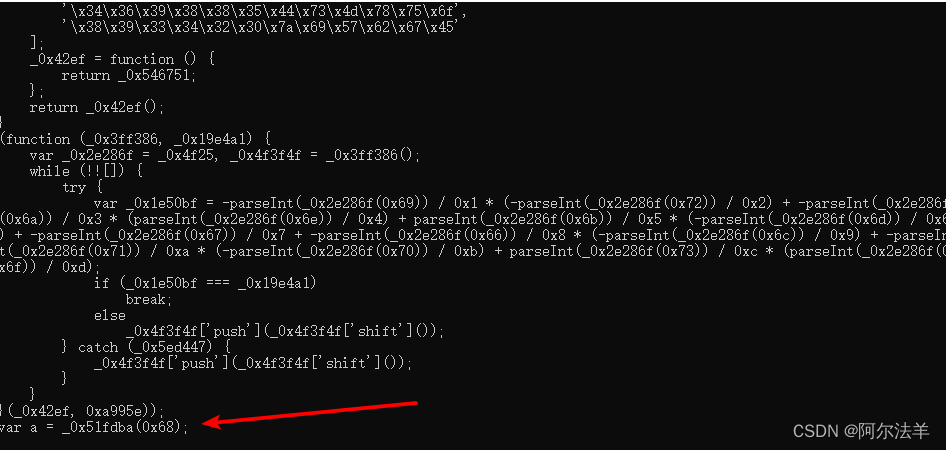
可以看到,这里字符串被数字化和Unicode化,非常难以辨认。
在很多JavaScript逆向过程中,一些关键的字符串可能会作为切入点来查找加密入口
,用了这种混淆之后,如果有人想通过全局搜索的方式搜索hello这样的字符串找加密入口,也就没法搜到了。
对策:
通过逆向工程和代码分析,将字符串从混淆的数组中提取出来。可以使用特定的脚本来自动识别和替换这些字符串。
2.4 代码自我保护
我们可以通过设置selfDefending参数来开启代码自我保护功能。
开启之后混淆后的JavaScript会强制以一行显示。如果我们将混淆后的代码进行格式化或者重命名
,该段代码将无法执行。
示例如下:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
console.log('hello world')
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
selfDefending: true // 启用 `selfDefending` 选项,生成具有自我防护功能的混淆代码,
// 使得混淆后的代码在被修改或格式化后无法运行。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
// 该函数接受两个参数:需要混淆的代码 `code` 和混淆器的配置选项 `options`。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
运行结果如下: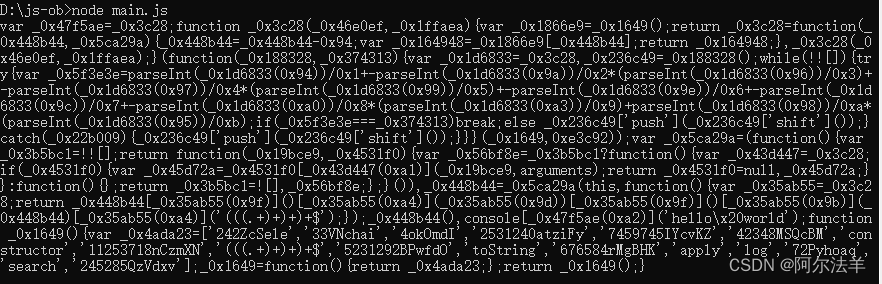
如果我们将上述代码放到控制台,它的执行结果和之前是一模一样的,没有任何问题。
如果我们将其进行格式化,然后粘贴到浏览器控制台里面,浏览器会直接卡死无法运行。这样如果有人对代码进行了格式化,就无法正常对代码进行运行和调试,从而起到了保护作用。
对策:
避免直接格式化或修改混淆代码。使用间接方法观察和修改代码逻辑,如通过代理脚本注入,通过Fiddler或Charles方式抓取到该js文件的加载包,使用功能替换自己编写的JS文件
2.5 无用代码注入
无用代码即不会被执行的代码或对上下文没有任何影响的代码,
注入之后可以对现有的JavaScript代码的阅读形成干扰。
我们可以使用deadCodeInjection参数开启这个选项,其默认值为false。
示例:
// 定义一个字符串 `code`,其中包含需要混淆的 JavaScript 代码。
const code = `
console.log(c);
console.log(a);
console.log(b);
`
// 定义一个对象 `options`,其中包含混淆器的配置选项。
const options = {
compact: false, // 设置 `compact` 选项为 `false`,保留混淆后的代码格式和缩进。
deadCodeInjection: true // 启用 `deadCodeInjection` 选项,插入无用代码以增加混淆性。
}
// 引入 `javascript-obfuscator` 模块,用于混淆 JavaScript 代码。
const obfuscator = require('javascript-obfuscator')
// 定义一个函数 `obfuscate`,用于混淆传入的代码。
function obfuscate(code, options) {
// 调用 `javascript-obfuscator` 的 `obfuscate` 方法,混淆代码并返回混淆后的代码。
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 输出混淆后的代码。调用 `obfuscate` 函数,传入需要混淆的代码 `code` 和混淆器的配置选项 `options`。
console.log(obfuscate(code, options))
这种混淆方式通过混入一些特殊的判断条件并加入一些不会被执行的代码,可以对代码起到一定的干扰作用。
对策:
通过使用静态代码分析工具(如ESLint、JSHint等),可以帮助识别出代码中可能的无用片段,动态分析涉及在运行时分析代码行为。可以通过在浏览器的开发者工具中进行断点调试,观察哪些代码实际被执行。未执行的代码段可能就是无用代码。
此外,一些高级的调试工具(如Chrome DevTools的Coverage工具)可以直接显示页面加载期间哪些JavaScript代码被执行,哪些没有,这可以直接帮助识别无用代码。
2.6 对象键名替换
如果是一个对象,可以使用transformObjectKeys来对对象的键值进行替换,示例如下:
const code = `
(function(){
var object = {
foo: 'test1', // 定义字符串 'test1' 给对象的属性 foo
bar: {
baz: 'test2' // 定义字符串 'test2' 给对象的属性 baz
}
};
})(); // 立即执行函数表达式 (IIFE),用于创建和初始化 object 对象
`;
const options = {
compact: false, // 不压缩代码,保留格式
transformObjectKeys: true // 转换对象键
};
const obfuscator = require('javascript-obfuscator'); // 引入 javascript-obfuscator 库
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode(); // 调用 obfuscator.obfuscate 方法对代码进行混淆,并获取混淆后的代码
}
可以看到,Object的变量名被替换为了特殊的变量,代码的可读性变差,
这样我们就不好直接通过变量名进行搜寻了,这也可以起到一定的防护作用。
对策:
通过运行时调试和分析变量值来理解变量的真实用途,尽管变量名已被混淆。工具如Chrome DevTools可以帮助在执行过程中检查和修改变量值,在浏览器自带的console窗口执行该变量名,即可看到该值
2.7 禁用控制台输出
const code = `
// 定义一个包含控制台输出的字符串常量
console.log('hello world')
`
const options = {
disableConsoleOutput: true // 设置选项对象,禁用控制台输出
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
// 调用 obfuscator.obfuscate 方法对代码进行混淆,并返回混淆后的代码
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
// 调用 obfuscate 函数对代码进行混淆处理,并输出混淆后的代码到控制台
console.log(obfuscate(code, options))
运行结果如下:
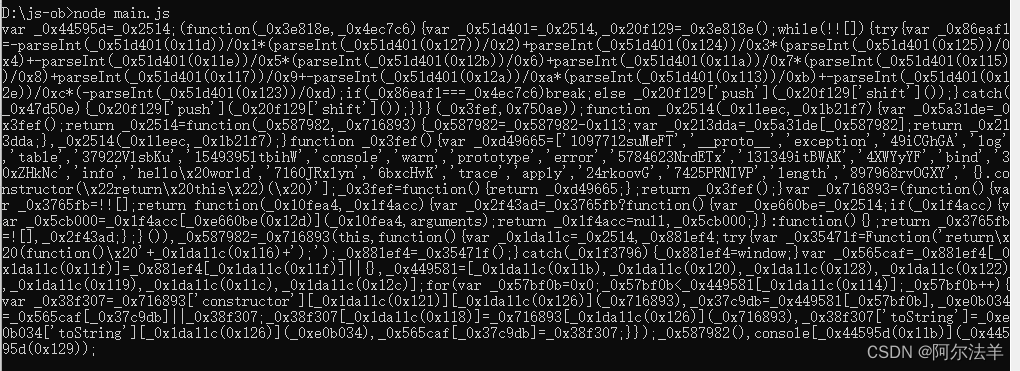
此时,我们如果执行这段代码,发现是没有任何输出的,这里实际上就是将console的一些功能禁用了。
对策:
通过代理脚本注入,通过Fiddler或Charles方式抓取到该js文件的加载包,使用功能替换自己编写的JS文件
2.8 调试保护
我们知道,如果Javascript代码中加入关键字debugger关键字,
那么执行到该位置的时候,就会进入断点调试模式。如果在代码多个位置都加入debugger关键字,
或者定义某个逻辑来反复执行debugger,就会不断进入断点调试模式,原本的代码就无法顺畅执行了。
这个过程可以称为调试保护,即通过反复执行debugger来使得原来的代码无法顺畅执行。
其效果类似于执行了如下代码:
setInterval(() => {debugger;}, 3000)
如果我们把这段代码粘贴到控制台,它就会反复执行debugger语句,进入断点调试模式,
从而干扰正常的调试流程。
在javascript-obfuscator中,我们可以使用debugProtection来启用调试保护机制,
还可以使用debugProtectionInterval来启用无限调试(debug)
,使得代码在调试过程中不断进入断点模式,无法顺畅执行。配置如下:
const options = {
debugProtection: true,
}
混淆后的代码会跳到debugger代码的位置,使得整个代码无法顺畅执行,对JavaScript代码的调试形成干扰。
对策
Never pause here 不在此处下断
在 debugger 位置,点击行号,右键 Never pause here,永远不在此处断下即可:
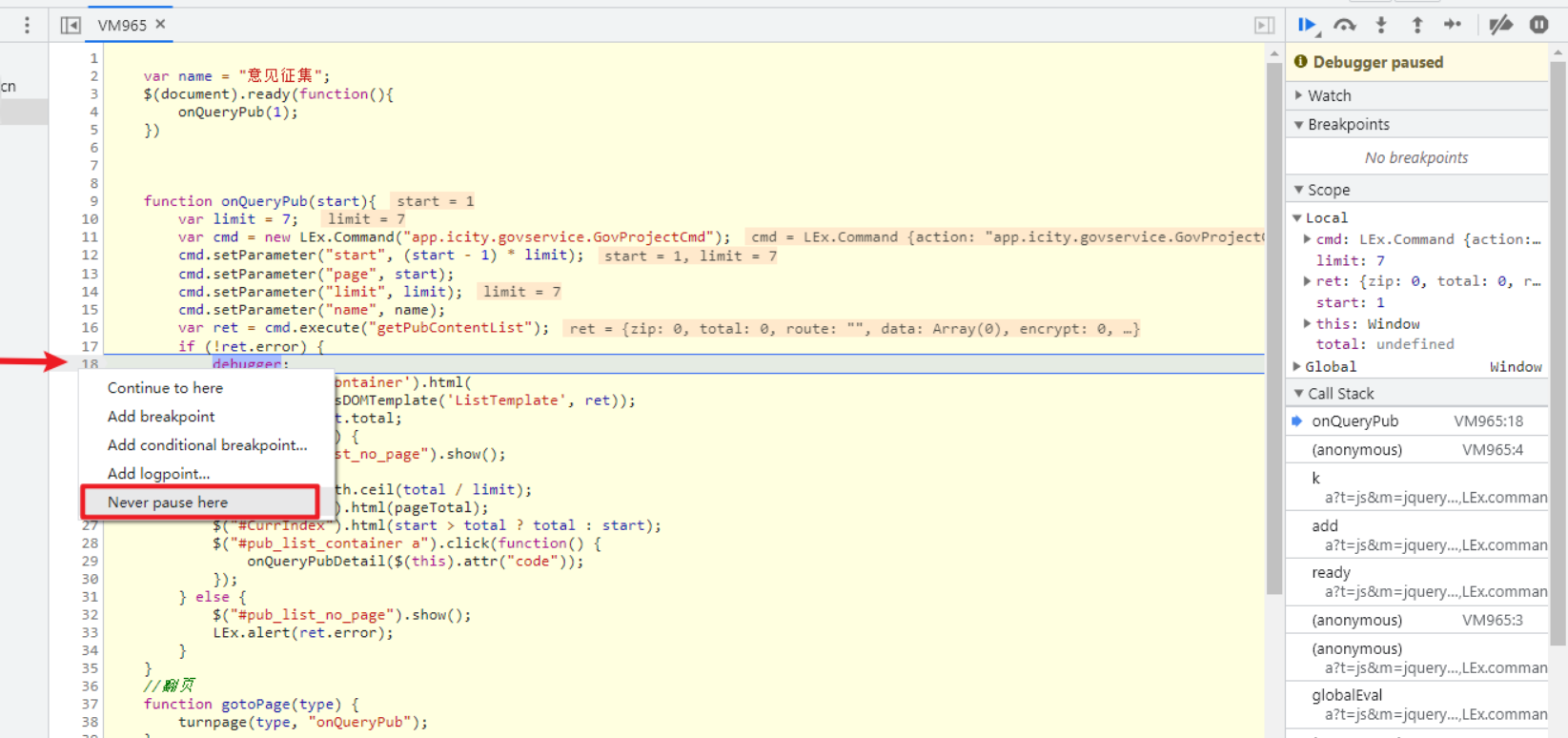
3.2.Add conditional breakpoint 条件断点
不适用于一直新开虚拟机的debugger
同样右键选择 Add conditional breakpoint,输入 false 即可跳过无限 debugger,其原理是添加条件断点,不管前面代码的逻辑是什么,运行到 debugger 的时候必定是 true 才能执行,只需要将其改为 false,那么它就不执行了:
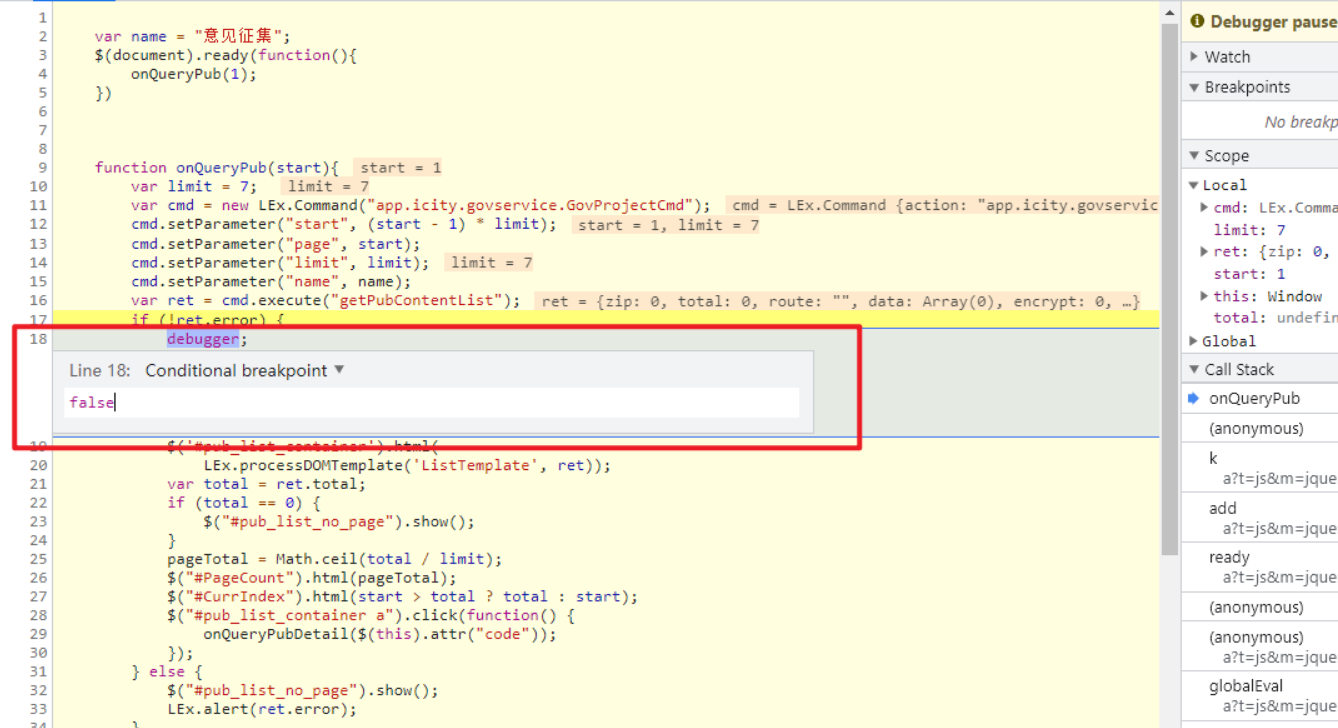
3.3.重写定时器debugger
setInterval这种我们可以通过hook,即重写或者置空的方式过掉
setInterval_back = setInterval;
setInterval = function(a,b){
if(a.toStirng().indexOf('debugger')!= -1){
return setInterval_back;
}
}
3.4.重写constructor的debugger
基本搞Function的通用形式
Function.prototype.constructor_back= Function.prototype.constructor_back;
Function.prototype.constructor_back= function(a,b){
if(arguments==='debugger'){
}else{
// arguments由于不知道多少参数,所以用apply
return Function.prototype.constructor_back.apply(this,arguments);
}
}
3.5.重写eval形式的debugger
eval_back=eval
eval=function(a){
if (a==="debugger"){
}else{
return eval_back(a);
}
}
3.6.中间人拦截替换无限debugger
①简单的静态js可以使用浏览器替换


此时文件变为紫色,此时可以修改该文件,ctrl+s保存刷新可以生效
②通过fiddler替换
fiddler界面右屏幕的AutoResponseder配置好,然后将需要修改的文件拖过来,选择find a file,找到我们已经修改好的源码文件
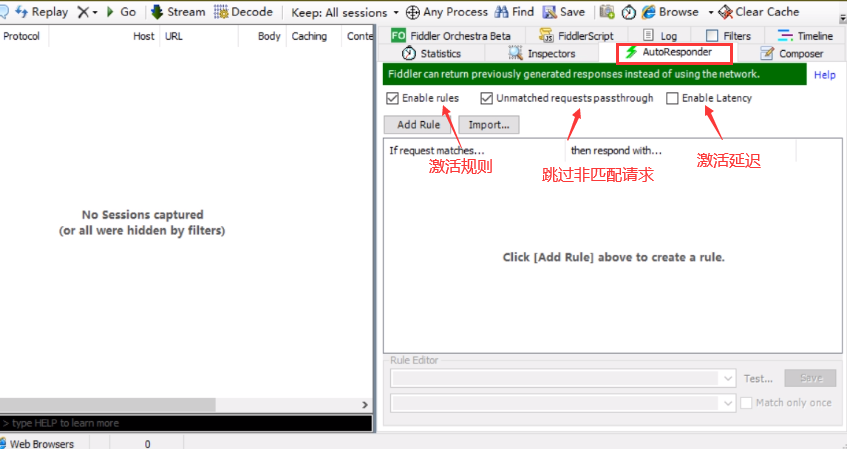
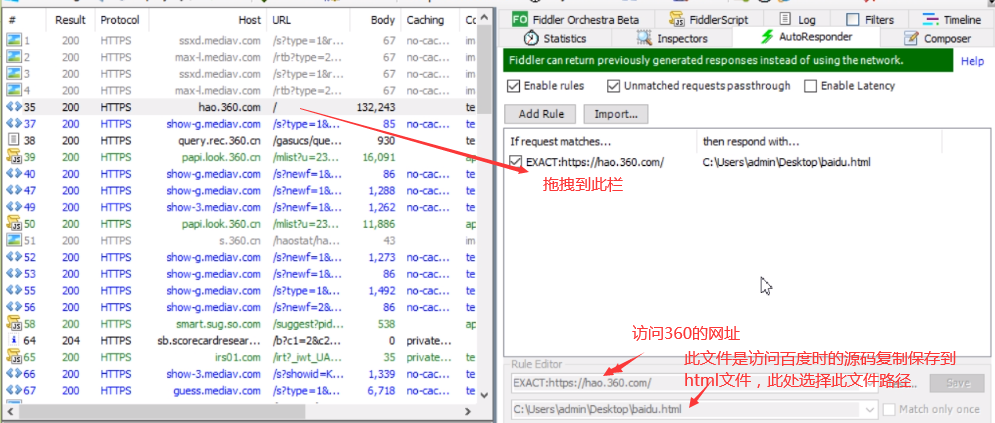
3.7.其他情况
如果上述方法失效,我们断到无限debugger的地方,向上找函数,把包含无限debugger的函数中的触发无限debugger的语句删掉即可。
2.9 域名锁定
我们还可以通过控制domainLock来控制JavaScript代码只能在特定域名下运行,
这样就可以降低代码被模拟或者盗用的风险。
// 定义一个包含控制台输出的字符串常量
console.log('hello world')
// 设置选项对象,禁止使用域名进行混淆
const options = {
domainLock: ['kk.com']
}
// 定义一个生成混淆字符串的方法,传入需要混淆的代码和选项对象
const obfuscator = require('javascript-obfuscator')
// 遍历并替换变量名、方法名和其他敏感信息,使其在混淆后难以猜解
function obfuscate(code, options) {
const obfuscatedCode = obfuscator.obfuscate(code, options)
return obfuscatedCode
}
// 调用 obfuscate 函数对代码进行混淆处理,并输出混淆后的代码到控制台
console.log(obfuscate(code, options))
这段代码就只能在指定的域名kk.com下运行,不能在其他网站运行。这样的话,如果一些相关JavaScript代码被单独剥离出来,想在其他网站运行或者使用程序模拟运行的话,运行结果只有失败,这样就可以有效降低代码被模拟或盗用的风险。
对策
通过修改本地hosts文件或使用开发者工具的覆盖功能,模拟指定的域名环境。
2.10 特殊编码
另外,还有一些特殊的工具包(jjencode,aaencode等)他们可以对代码进行混淆和编码。
加密链接:哈希在线加密|MD5在线解密加密|SHA1在线解密加密|SHA256在线解密加密|SHA512在线加密|GEEKAPP开发者在线工具
解密链接:JSON在线 | JSON解析格式化—SO JSON在线工具
示例如下:
var kk = 100
使用jjencode工具的结果:
使用aaencode工具的结果:
可以看到,通过这些工具,原本非常简单的代码被转化为一些几乎完全不可读的代码
,但实际上运行效果还是相同的。这些混淆方式比较另类,看起来虽然没有什么头绪
,但实际上找到规律是非常好还原的,并没有真正达到强力混淆的效果。
对策
关于这种混淆代码的解码方法,一般直接复制到控制台运行或者用解码工具进行转换,
如果运行失败,就需要按分号分割语句,逐行调试分析源码。
加密算法
MD5加密
1. MD5简介
MD5(Message Digest Algorithm 5)是一种常见的哈希函数,用于产生128位(16字节)的哈希值,通常以32位十六进制数表示。它由Ronald Rivest在1991年设计,用于替代较旧的MD4算法。尽管MD5以前广泛用于加密和数字签名,但由于安全性问题,现在主要用于校验数据完整性。
2. MD5算法步骤
MD5算法的计算过程包括以下几个步骤:
- 初始化变量
- 填充消息
- 处理消息分块
- 输出结果
3. Python中使用MD5
Python标准库中提供了hashlib模块,用于计算各种哈希算法,包括MD5。使用MD5算法的基本步骤如下:
import hashlib
# 创建MD5对象
md5_hash = hashlib.md5()
# 更新数据
md5_hash.update(b"your_message_here")
# 获取摘要
digest = md5_hash.hexdigest()
4. MD5的应用场景
MD5广泛应用于数据完整性校验、密码存储(已被更安全的算法替代)、数字签名和散列映射表等领域。尽管MD5已不适合加密应用,但在合适的场景下仍然有其用武之地。
5. MD5的安全性问题
由于MD5算法的设计缺陷,已经被证明存在多种安全问题,包括碰撞攻击和预映射攻击。因此,不推荐在安全相关的应用中使用MD5进行加密或签名。
SHA加密
1. SHA算法简介
SHA(Secure Hash Algorithm)是一系列密码散列函数,设计用于产生固定大小的哈希值。SHA系列包括多个变体,如SHA-1、SHA-224、SHA-256、SHA-384和SHA-512等,它们产生的哈希值长度从160位到512位不等。SHA系列算法由美国国家安全局(NSA)设计,目前广泛用于数据完整性校验、数字签名、消息认证码等领域。
2. SHA算法步骤
SHA算法的计算过程包括以下几个主要步骤:
- 初始化变量
- 填充消息
- 处理消息分块
- 输出结果
3. Python中使用SHA算法
Python标准库中的hashlib模块支持多种SHA算法的计算。使用SHA-256算法的基本步骤如下:
import hashlib
# 创建SHA-256对象
sha256_hash = hashlib.sha256()
# 更新数据
sha256_hash.update(b"your_message_here")
# 获取摘要
digest = sha256_hash.hexdigest()
print(digest) # e1b0b5173c972e8b6a08eb7b4f9e1ccba1717217c4c9353f2d3f9e3d8e7a0ceb
4. SHA的应用场景
SHA算法在信息安全中有广泛应用,特别是在密码学、数字签名、SSL/TLS协议中。SHA-256作为SHA系列中的主流算法,被广泛用于替代MD5和SHA-1,以提高数据完整性校验的安全性。
5. SHA的安全性
SHA-1已经被证明存在碰撞攻击的漏洞,因此不再推荐在安全相关的应用中使用。SHA-256及其更高变体(如SHA-384、SHA-512)目前被认为安全,但随着计算能力的增强和密码分析技术的进步,未来可能需要迁移到更安全的算法。
URLEncode加密
1. URLEncode简介
URLEncode(URL编码)是一种将数据从字符串形式转换为可在URL中传输的安全形式的方法。它将特殊字符转换为特定的格式,以便在URL中进行传输和解析。在Python中,URLEncode通常用于构建查询字符串或编码特定的URL参数。
2. URLEncode的作用
URLEncode主要用于以下几个方面:
- URL参数传递:将参数编码为URL中的一部分,以避免特殊字符和保留字符对URL解析造成的影响。
- 安全性:防止特殊字符被误解为URL中的控制字符,从而提高数据传输的安全性。
- 跨平台兼容性:确保不同系统和编程语言之间传输数据的一致性和可解析性。
在一些网站的地址栏总是能看见https://www.sogou.com/web?query=%E5%90%83%E9%A5%AD%E7%9D%A1%E8%A7%89%E6%89%93%E8%B1%86%E8%B1%86 这些数据,他们都代表着什么?
scheme://host:port/dir/file?p1=v1&p2=v2#anchor
http ://www.baidu.com/tieba/index.html?name=alex&age=18
参数: key=value
服务器可以通过key拿value
3. Python中的URLEncode
Python标准库中的urllib.parse模块提供了对URL的编码和解码功能,其中urlencode()函数用于将字典或元组形式的参数编码为URL查询字符串 quote则是只接受一个字符串作为对象,进行编码
from urllib.parse import urlencode,quote
# 把数据转换成url编码格式 ==> 处理的只能是字典
dic = {'name': '张三', 'age': 20}
r = urlencode(dic)
print(r) # 输出:name=%E5%BC%A0%E4%B8%89&age=20
# quote把数据转换成url编码格式 ==> 处理的只能是字符串
s = '我爱你'
res = quote(s)
print(res) # 输出:%E6%88%91%E7%88%B1%E4%BD%A0
4. URLEncode与URLDecode
URLEncode用于将数据编码为URL安全的形式,而URLDecode则用于将URL编码的数据解码回原始格式。Python中可以使用urllib.parse模块中的quote()和unquote()函数进行编码和解码操作。
from urllib.parse import quote, unquote
original_string = "Hello, World!"
encoded_string = quote(original_string)
decoded_string = unquote(encoded_string)
print("解码前的字符串:", encoded_string)
print("解码后的字符串:", decoded_string)
# Output:
# Encoded string: Hello%2C%20World%21
# Decoded string: Hello, World!
5. 注意事项
- 字符集:在进行URLEncode时,应注意使用适当的字符集进行编码,通常是UTF-8。
- 保留字符:某些字符在URL中具有特殊含义(如
/,?,&等),在构建URL时需要特别注意它们的处理。
Base64加密
1. Base64简介
Base64是一种用于将二进制数据编码为ASCII字符的编码方案。它通常用于在需要以文本形式传输二进制数据的场景中,例如在电子邮件、HTTP协议和数据存储中。Base64编码将每三个字节的二进制数据转化为四个可打印的字符,确保数据在传输过程中不被修改。
2. Base64编码的原理
Base64编码通过以下步骤将二进制数据转化为文本:
- 将输入数据按每3字节分组。
- 将每3字节的24位数据按6位一组,转化为4个Base64字符。
- 使用Base64字符集编码6位数据,字符集包括A-Z, a-z, 0-9, +, /。
- 不足3字节的数据使用
=填充,以保证编码后的数据长度是4的倍数。
3. Python中的Base64编码
Python标准库中的base64模块提供了对Base64编码和解码的支持。下面是使用Python进行Base64编码和解码的示例:
import base64
# 原始数据
data = "Hello, World!"
# 编码
encoded_data = base64.b64encode(data.encode('utf-8'))
print("Encoded data:", encoded_data)
# 解码
decoded_data = base64.b64decode(encoded_data).decode('utf-8')
print("Decoded data:", decoded_data)
4. Base64编码和解码函数
base64.b64encode(data): 接收字节数据并返回Base64编码的字节数据。base64.b64decode(encoded_data): 接收Base64编码的字节数据并返回解码后的字节数据。
5. 示例与应用
Base64编码广泛应用于各种需要将二进制数据转化为文本的场景,例如嵌入图像数据、处理网络传输的数据和存储复杂的二进制对象。
示例1:编码图像文件
import base64
# 读取图像文件
with open("example.png", "rb") as image_file:
image_data = image_file.read()
# 编码图像数据
encoded_image = base64.b64encode(image_data)
print("Encoded image data:", encoded_image)
# 将编码后的图像数据写入文件
with open("encoded_image.txt", "wb") as encoded_file:
encoded_file.write(encoded_image)
示例2:解码Base64编码的图像文件
import base64
# 从文件中读取编码后的图像数据
with open("encoded_image.txt", "rb") as encoded_file:
encoded_image = encoded_file.read()
# 解码图像数据
decoded_image = base64.b64decode(encoded_image)
# 将解码后的图像数据写入文件
with open("decoded_example.png", "wb") as image_file:
image_file.write(decoded_image)
6. Base64与URL安全的Base64
为了在URL中安全传输Base64编码的数据,Base64的一个变体被引入,即URL安全的Base64编码。URL安全的Base64编码将+和/替换为-和_,以避免URL中的特殊字符。
import base64
# URL安全的Base64编码
url_safe_encoded = base64.urlsafe_b64encode(data.encode('utf-8'))
print("URL-safe Encoded data:", url_safe_encoded)
# URL安全的Base64解码
decoded_url_safe_data = base64.urlsafe_b64decode(url_safe_encoded).decode('utf-8')
print("Decoded URL-safe data:", decoded_url_safe_data)
7. 注意事项
- 填充字符:Base64编码的数据长度总是4的倍数,如果不足,则使用
=进行填充。 - 编码和解码时的数据类型:Base64编码和解码函数接收和返回的都是字节数据,需要进行编码和解码字符串的转换。
- 安全性:Base64编码不是加密方法,只是一种数据表示形式,不能用于保护敏感数据。
8. 结语
Base64编码是处理二进制数据的常用工具,通过将数据转换为文本形式,使其能够在文本协议中传输。在实际应用中,应根据需要选择合适的编码和解码方法,并注意数据类型的转换。Base64虽然便捷,但不具备安全性,需要结合其他安全措施来保护敏感数据。
DES加密
1. DES简介
DES(Data Encryption Standard,数据加密标准)是一种对称加密算法,由IBM开发,并于1977年被美国国家标准局(NBS,现为NIST)作为联邦信息处理标准(FIPS)发布。DES使用56位密钥,对数据进行64位分组加密。然而,随着计算能力的提升,DES的安全性已不再足够,逐渐被更安全的算法(如AES)取代。
2. DES算法工作原理
DES加密过程包括以下主要步骤:
- 密钥生成:生成16个子密钥,每个子密钥48位。
- 初始置换(IP):对64位明文进行初始置换。
- 16轮迭代加密:
- 分组:将数据分为左右两部分。
- 函数运算:使用子密钥和Feistel结构进行复杂的加密运算。
- 逆初始置换(IP-1):对加密后的数据进行逆初始置换,得到最终的密文。
DES解密过程是加密过程的逆过程,使用相同的密钥进行解密。
3. Python中的DES加密
Python中可以使用pycryptodome库来实现DES加密和解密。pycryptodome库提供了DES算法的实现。
安装pycryptodome库:
pip install pycryptodome
4. DES加密和解密示例
以下是使用Python进行DES加密和解密的示例代码:
from Crypto.Cipher import DES
from Crypto.Random import get_random_bytes
# 自动填充
from Crypto.Util.Padding import pad,unpad
import base64
# DES加密
def des_encrypt(plaintext, key):
# 创建DES加密器,ECB模式不需要给IV偏移量
cipher = DES.new(key, DES.MODE_ECB)
# 填充数据到8字节的倍数
# 假设len(plaintext)的值为11,那么:
# len(plaintext) % 8 的结果为 11 % 8 = 3,即余数为3。
# 因此,8 - (len(plaintext) % 8) 的结果为 8 - 3 = 5,即需要填充5个字节。
# padding_length = 8 - len(plaintext) % 8
# padded_plaintext = plaintext + chr(padding_length) * padding_length
# 通过自动填充来解决问题
padded_plaintext = pad(plaintext.encode('utf-8'), 8)
ciphertext = cipher.encrypt(padded_plaintext)
return base64.b64encode(ciphertext).decode('utf-8')
# DES解密
def des_decrypt(ciphertext, key):
cipher = DES.new(key, DES.MODE_ECB)
encrypted_message = base64.b64decode(ciphertext)
padded_plaintext = cipher.decrypt(encrypted_message).decode('utf-8')
# 移除填充
# 假设最后一个字符为填充字符,通过ord()函数可以获取ASCII码,最后得出来的结果是3
# 通过原字符串从0下标开始,切掉-3位的字符串即为解密结果
# padding_length = ord(padded_plaintext[-1])
# plaintext = padded_plaintext[:-padding_length]
# 通过自动填充来解决问题
plaintext = unpad(padded_plaintext.encode('utf-8'), 8).decode('utf-8')
return plaintext
# 示例使用
if __name__ == "__main__":
key = get_random_bytes(8) # DES使用8字节密钥
plaintext = "Hello, DES!"
# 加密
encrypted_text = des_encrypt(plaintext, key)
print("加密的结果:", encrypted_text)
# 解密
decrypted_text = des_decrypt(encrypted_text, key)
print("解密的结果:", decrypted_text)
5. DES加密模式
DES支持多种加密模式,包括:
- ECB(电子密码本模式):每个分组独立加密,不推荐使用,因其不具备良好的安全性。
- CBC(密码分组链接模式):每个明文分组与前一个密文分组进行异或操作,常用且安全。
- CFB(密码反馈模式):将前一个密文分组的加密结果与当前明文分组进行异或操作。
- OFB(输出反馈模式):类似于CFB,但使用加密的输出作为下一个分组的输入。
以下是使用CBC模式的示例:
from Crypto.Cipher import DES
from Crypto.Random import get_random_bytes
import base64
# DES加密(CBC模式)
def des_encrypt_cbc(plaintext, key):
iv = get_random_bytes(8) # CBC模式需要初始化向量IV
cipher = DES.new(key, DES.MODE_CBC, iv)
padding_length = 8 - len(plaintext) % 8
padded_plaintext = plaintext + chr(padding_length) * padding_length
ciphertext = cipher.encrypt(padded_plaintext.encode('utf-8'))
return base64.b64encode(iv + ciphertext).decode('utf-8')
# DES解密(CBC模式)
def des_decrypt_cbc(ciphertext, key):
raw_data = base64.b64decode(ciphertext)
# 取前8字节为IV
iv = raw_data[:8]
# 取后8位的字节为密文
encrypted_message = raw_data[8:]
cipher = DES.new(key, DES.MODE_CBC, iv)
padded_plaintext = cipher.decrypt(encrypted_message).decode('utf-8')
padding_length = ord(padded_plaintext[-1])
plaintext = padded_plaintext[:-padding_length]
return plaintext
# 示例使用
if __name__ == "__main__":
key = get_random_bytes(8) # DES使用8字节密钥
plaintext = "Hello, DES with CBC mode!"
# 加密
encrypted_text = des_encrypt_cbc(plaintext, key)
print("加密后的结果:", encrypted_text)
# 解密
decrypted_text = des_decrypt_cbc(encrypted_text, key)
print("解密后的结果:", decrypted_text)
6. DES的安全性
尽管DES在其发布时是安全的,但随着计算能力的提高,DES逐渐暴露出以下安全性问题:
- 密钥长度:DES的56位密钥长度相对较短,容易受到暴力破解攻击。
- 已知攻击:DES已被多种已知攻击(如差分密码分析)破译。
- 替代方案:由于上述问题,NIST在2001年推荐使用AES替代DES。3DES(Triple DES)作为DES的加强版本,通过多次应用DES来提高安全性,但也逐渐被AES取代。
7. 注意事项
- 密钥管理:确保密钥的安全存储和管理,不要将密钥硬编码在代码中。
- 填充方式:确保使用适当的填充方式(如PKCS#7),以处理不满一个分组的数据。
- 初始向量(IV):在使用CBC和其他模式时,确保IV的生成和使用正确,以保证加密安全性。
8. 结语
DES作为一种早期的对称加密算法,尽管在现代信息安全中已被更安全的算法(如AES)取代,但它仍然是理解加密算法工作原理的基础。在实际应用中,应选择更为安全的加密算法,并确保合理的密钥管理和数据保护策略。
AES加密
1. AES简介
AES(Advanced Encryption Standard,高级加密标准)是一种对称加密算法,由美国国家标准与技术研究院(NIST)于2001年发布。AES取代了之前的DES算法,成为新的数据加密标准。AES支持128位、192位和256位密钥长度,常用于保护电子数据。
2. AES算法工作原理
AES加密过程包括以下几个主要步骤:
- 密钥扩展:将初始密钥扩展为多个轮密钥。
- 初始轮:初始轮密钥加。
- 轮操作:包括SubBytes、ShiftRows、MixColumns和AddRoundKey四个步骤(最后一轮没有MixColumns)。
- 终止轮:应用最后一个轮密钥。
AES解密过程是加密过程的逆过程,使用相同的密钥进行解密。
3. Python中的AES加密
Python中可以使用pycryptodome库来实现AES加密和解密。pycryptodome库是一个功能强大的加密库,提供了AES算法的实现。
安装pycryptodome库:
pip install pycryptodome
4. AES加密和解密示例
以下是使用Python进行AES加密和解密的示例代码:
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from Crypto.Util.Padding import pad,unpad
import base64
# AES加密
def aes_encrypt(plaintext, key):
# 生成随机的初始向量(IV)
iv = get_random_bytes(16)
cipher = AES.new(key, AES.MODE_CBC, iv)
# 填充数据到16字节的倍数
# padding_length = 16 - len(plaintext) % 16
# padded_plaintext = plaintext + chr(padding_length) * padding_length
# 一键搞定
padded_plaintext = pad(plaintext.encode('utf-8'),16)
ciphertext = cipher.encrypt(padded_plaintext)
# 返回IV和密文
return base64.b64encode(iv + ciphertext).decode('utf-8')
# AES解密
def aes_decrypt(ciphertext, key):
raw_data = base64.b64decode(ciphertext)
# 取前16位作为IV的偏移量
iv = raw_data[:16]
# 取后16位作为密文
encrypted_message = raw_data[16:]
cipher = AES.new(key, AES.MODE_CBC, iv)
padded_plaintext = cipher.decrypt(encrypted_message).decode('utf-8')
# # 移除填充
# padding_length = ord(padded_plaintext[-1])
# plaintext = padded_plaintext[:-padding_length]
plaintext = unpad(padded_plaintext.encode('utf-8'),16).decode('utf-8')
return plaintext
# 示例使用
if __name__ == "__main__":
key = get_random_bytes(32) # 使用256位密钥
plaintext = "Hello, AES!"
# 加密
encrypted_text = aes_encrypt(plaintext, key)
print("Encrypted:", encrypted_text)
# 解密
decrypted_text = aes_decrypt(encrypted_text, key)
print("Decrypted:", decrypted_text)
5. AES加密模式
AES支持多种加密模式,包括:
- ECB(电子密码本模式):每个分组独立加密,不推荐使用,因其不具备良好的安全性。
- CBC(密码分组链接模式):每个明文分组与前一个密文分组进行异或操作,常用且安全。
- CFB(密码反馈模式):将前一个密文分组的加密结果与当前明文分组进行异或操作。
- OFB(输出反馈模式):类似于CFB,但使用加密的输出作为下一个分组的输入。
- CTR(计数器模式):将一个计数器的加密结果与明文分组进行异或操作,支持并行处理。
以下是使用CTR模式的示例:
from Crypto.Cipher import AES
from Crypto.Util import Counter
import base64
# AES加密(CTR模式)
def aes_encrypt_ctr(plaintext, key):
ctr = Counter.new(128)
cipher = AES.new(key, AES.MODE_CTR, counter=ctr)
ciphertext = cipher.encrypt(plaintext.encode('utf-8'))
return base64.b64encode(ciphertext).decode('utf-8')
# AES解密(CTR模式)
def aes_decrypt_ctr(ciphertext, key):
ctr = Counter.new(128)
cipher = AES.new(key, AES.MODE_CTR, counter=ctr)
encrypted_message = base64.b64decode(ciphertext)
plaintext = cipher.decrypt(encrypted_message).decode('utf-8')
return plaintext
# 示例使用
if __name__ == "__main__":
key = get_random_bytes(32) # 使用256位密钥
plaintext = "Hello, AES in CTR mode!"
# 加密
encrypted_text = aes_encrypt_ctr(plaintext, key)
print("Encrypted:", encrypted_text)
# 解密
decrypted_text = aes_decrypt_ctr(encrypted_text, key)
print("Decrypted:", decrypted_text)
6. 注意事项
- 密钥管理:密钥的安全存储和管理是加密系统安全的关键,避免将密钥硬编码在代码中。
- 填充方式:确保使用合适的填充方式(如PKCS#7),以处理不满一个分组的数据。
- 初始向量(IV):在使用CBC、CFB、OFB和CTR模式时,初始向量的生成和使用必须正确,以确保加密安全性。
7. 结语
AES作为一种高级加密标准,在信息安全中扮演着重要角色。使用Python的pycryptodome库,可以方便地实现AES加密和解密。在实际应用中,应选择合适的加密模式,并注意密钥和初始向量的安全管理,确保数据的安全性。
RAS加密
RSA(Rivest-Shamir-Adleman)是一种非对称加密算法,广泛用于加密通信中的密钥交换、数字签名等安全应用。在实现RSA加密时,需要使用大数运算来处理其特有的密钥生成、加密和解密过程。需要两把钥匙. 一个公钥, 一个私钥. 公钥发送给客户端. 发送端用公钥对数据进行加密. 再发送给接收端, 接收端使用私钥来对数据解密. 由于私钥只存放在接收端这边. 所以即使数据被截获了. 也是无法进行解密的.
公钥(Public Key)和私钥(Private Key)是非对称加密算法(如RSA)中的两个关键概念,它们各自拥有不同的作用和应用场景:
公钥(Public Key)
-
加密:
- 公钥用于加密数据。任何人都可以使用公钥对数据进行加密,加密后的数据只能由对应的私钥解密。
- 例如,在数字通信中,发送方使用接收方的公钥加密数据,确保只有接收方能够解密。
-
验证签名:
- 公钥用于验证数字签名的真实性。数字签名是通过私钥生成的,任何人都可以使用与签名对应的公钥来验证签名是否有效和数据是否完整。
- 这在确保数据完整性和验证身份方面非常重要,如在数字证书、HTTPS连接中常见。
私钥(Private Key)
-
解密:
- **私钥用于解密被公钥加密过的数据。**只有持有私钥的一方才能解密由公钥加密的数据。
- 在加密通信中,接收方使用自己的私钥解密发送方使用其公钥加密的数据。
-
生成数字签名:
- 私钥用于生成数字签名。数字签名是用私钥对数据进行加密,确保数据的完整性和真实性。
- 只有持有私钥的一方才能生成与其签名对应的数字签名。
总结
- 公钥用于加密数据和验证签名,公开给其他人使用。
- 私钥用于解密数据和生成签名,必须严格保密,只有拥有者知道。
公钥和私钥的安全性和正确性是非对称加密算法的核心,保证了加密通信的隐私和数据完整性。
1. 导入库和生成密钥对
from Crypto.PublicKey import RSA
# 加密器
from Crypto.Cipher import PKCS1_OAEP
# 随机值
from Crypto import Random
import base64
2. 生成RSA密钥对
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
import base64
# 随机
gen_random = Random.new
# 生成秘钥
rsakey = RSA.generate(1024)
# 由于不可能说是用户发起一次请求新建一次密钥,所以要写入文件定期刷新来管理加密密钥
with open("rsa.public.pem", mode="wb") as f:
f.write(rsakey.publickey().exportKey())
with open("rsa.private.pem", mode="wb") as f:
f.write(rsakey.exportKey())
3. 加密函数
# 加密函数
def encrypt(data):
# 读取公钥
with open('public_key.pem', 'rb') as f:
pk = f.read()
# 声明一个对象
ras_pk = RSA.import_key(pk)
# 使用加密器创建声明对象
ras = PKCS1_OAEP.new(ras_pk)
result = ras.encrypt(data.encode('utf-8'))
# 处理成b64方便传输
b64_result = base64.b64encode(result).decode("utf-8")
return b64_result
4. 解密函数
# 解密函数
def decrypt(data):
# 读取私钥
with open('private_key.pem', 'rb') as f:
pk = f.read()
rsa_pk = RSA.importKey(pk)
rsa = PKCS1_OAEP.new(rsa_pk)
# 处理成b64方便传输
result = rsa.decrypt(base64.b64decode(data)).decode('utf-8')
return result
5. 示例使用
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_OAEP
import base64
# 生成密钥对
key = RSA.generate(1024)
# 由于不可能说是用户发起一次请求新建一次密钥,所以要写入文件定期刷新来管理加密密钥
# 私钥
with open('private_key.pem', 'wb') as f:
f.write(key.export_key('PEM'))
# 公钥
with open('public_key.pem', 'wb') as f:
f.write(key.publickey().export_key('PEM'))
# 加密函数
def encrypt(data):
# 读取公钥
with open('public_key.pem', 'rb') as f:
pk = f.read()
ras_pk = RSA.import_key(pk)
ras = PKCS1_OAEP.new(ras_pk)
result = ras.encrypt(data.encode('utf-8'))
# 处理成b64方便传输
b64_result = base64.b64encode(result).decode("utf-8")
return b64_result
# 解密函数
def decrypt(data):
# 读取私钥
with open('private_key.pem', 'rb') as f:
pk = f.read()
rsa_pk = RSA.importKey(pk)
rsa = PKCS1_OAEP.new(rsa_pk)
# 处理成b64方便传输
result = rsa.decrypt(base64.b64decode(data)).decode('utf-8')
return result
if __name__ == '__main__':
# 测试
data = 'hello world'
encrypted_data = encrypt(data)
print(f'加密后数据:{encrypted_data}')
decrypted_data = decrypt(encrypted_data)
print(f'解密后数据:{decrypted_data}')
6.结语
- RSA算法中,密钥的长度通常为1024位到4096位,2048位是目前较常见的安全强度选择。
- 使用
PKCS1_OAEP填充方案进行加密,保证了安全性和填充的正确性。 - 密文通常会进行Base64编码,以便于在网络上传输。
HMAC加密
HMAC(Hash-based Message Authentication Code,基于哈希的消息认证码)是一种基于密钥的消息认证码,通过特定的哈希函数与密钥的结合来保证数据的完整性和真实性。HMAC广泛应用于验证消息的完整性和认证,确保数据在传输过程中未被篡改。
HMAC的工作原理
- 密钥:HMAC需要一个密钥,通常长度与哈希函数输出长度相同。
- 消息:需要进行认证的消息。
- 哈希函数:例如SHA-256或SHA-1。
- 算法:HMAC算法将密钥和消息结合,并使用哈希函数进行运算,生成一个固定长度的消息摘要。
HMAC的主要步骤
- 如果密钥长度超过哈希函数的块大小,则先对密钥进行哈希运算。
- 将密钥填充到块大小(通常是哈希函数块大小)。
- 密钥与内填充值(ipad)和外填充值(opad)进行异或运算。
- 将内异或结果与消息连接,进行哈希运算。
- 将外异或结果与内哈希结果连接,再次进行哈希运算。
HMAC的应用场景
- API验证:在API调用中,使用HMAC验证请求的真实性和完整性。
- 数据完整性验证:在数据传输中,确保数据未被篡改。
- 身份认证:在用户认证中,验证用户身份的真实性。
实现HMAC加密
1. 导入库
import hmac
import hashlib
import base64
2. HMAC加密函数
def hmac_encrypt(key, message, hash_func=hashlib.sha256):
hmac_obj = hmac.new(key.encode(), message.encode(), hash_func)
return base64.b64encode(hmac_obj.digest()).decode()
3. HMAC验证函数
def hmac_verify(key, message, hash_func, signature):
hmac_obj = hmac.new(key.encode(), message.encode(), hash_func)
expected_signature = base64.b64encode(hmac_obj.digest()).decode()
return hmac.compare_digest(expected_signature, signature)
4. 示例使用
import hmac
import hashlib
import base64
def hmac_encrypt(key, message, hash_func):
'''
形参:密钥,加密信息,sha256方法
返回值:加密后的字符串
'''
hmac_obj = hmac.new(key.encode(), message.encode(), hash_func)
return base64.b64encode(hmac_obj.digest()).decode()
def hmac_verify(key, message, hash_func, signature):
'''
形参:密钥,加密信息,sha256方法,加密后的字符串
返回值:是否验证成功
'''
hmac_obj = hmac.new(key.encode(), message.encode(), hash_func)
expected_signature = base64.b64encode(hmac_obj.digest()).decode()
return hmac.compare_digest(expected_signature, signature)
if __name__ == '__main__':
key = "secret_key"
message = "我是对的"
hash_func = hashlib.sha256
# 生成HMAC
signature = hmac_encrypt(key, message, hash_func)
print(f"HMAC: {signature}") # HMAC: A9ZyT9rdV2359GFkxYsppbPifstK2V3cn8QZHXkusok=
# 验证HMAC
is_valid = hmac_verify(key, message, hash_func, signature)
print(f"是否验证成功? {is_valid}") # 是否验证成功? True
# 验证错误消息的HMAC
wrong_message = "我是错的"
is_valid = hmac_verify(key, wrong_message, hash_func, signature)
print(f"是否验证成功? {is_valid}") # 是否验证成功? False
结语
- HMAC确保了消息在传输中的完整性和真实性。
- HMAC需要密钥来进行运算,因此密钥的安全性非常重要。
- 常见的哈希函数如SHA-256或SHA-1可以用于HMAC,SHA-256通常更安全。
- HMAC的实现相对简单,易于集成到各种应用中。
APP逆向
1.Java常见加密
1.1 隐藏字节
TreeMap map = new TreeMap();
map.put("sign",x);
# 搜索关键字 sign是可以搜索出来的,但是如果替换成如下的代码,就没有办法搜索出来了
import java.util.Arrays;
import java.util.TreeMap;
public class Hello {
public static void main(String[] args) {
// 1.字节数组(转换为字符串) [字节,字节,字节]
byte[] dataList = {115, 105, 103, 110};
String dataString = new String(dataList);
System.out.println("字符串是:" + dataString); // 字符串是:sign
// 2.字符串->字节数组
try {
// Python中的 name.encode("gbk")
String data = "sign";
byte[] v1 = data.getBytes("utf-8");
System.out.println(Arrays.toString(v1)); // [115, 105, 103, 110]
TreeMap map = new TreeMap();
map.put("name", "sign");
} catch (Exception e) {
}
}
}
1.2 密码加盐
// 定义一个随机字符串
String salt = "xxssasdfasdfadsf";
// 在java中可以将字节转回字符串
String v4 = new String(new byte[]{115, 105, 103, 110});
注意一点!在java中字节是有负数的,会从负的128到127之间轮换,但如果要在python还原,只需要在每一个负数
前面加上一个255就能够解决问题,比如-152+255=103
// # java字节:有符号 -128 ~ 127
// python:无符号 0 ~ 255
在python中还原这个操作
-
示例1:
byte_list = [-26, -83, -90, -26, -78, -101, -23, -67, -112] bs = bytearray() # python字节数组 for item in byte_list: if item < 0: item = item + 256 bs.append(item) str_data = bs.decode('utf-8') # data = bytes(bs) print(str_data)
1.2 uuid
// 一般来讲uuid会有一个-分隔,如果在逆向的时候见到斜杠可以判断是否是uuid、以下是java的实现代码
import java.util.UUID;
public class Hello {
public static void main(String[] args){
String uid = UUID.randomUUID().toString();
System.out.println(uid); //94321247-9b94-4faa-8e36-a964ec8297e3
}
}
# python实现代码
import uuid
uid = str(uuid.uuid4())
print(uid) #29cd5f50-4b4c-457b-9a59-33a12e3edd10
1.第一类使用uuid
抓包发现,每次请求值不一样:d7cb3695-5105-4aaa-b0a8-8188e0977143
2.第一次运行生成UUID
- 刚开始运行:调用uuid算法生成一个值。
- 写入XML文件
- 再使用
- 优先去XML文件中找
- uuid算法
此时测试应该做的操作:
- 清除app数据
- 必须卸载app,重新安装
1.3 随机值
import java.math.BigInteger;
import java.security.SecureRandom;
public class Hello {
public static void main(String[] args) {
// 随机生成80位,10个字节
BigInteger v4 = new BigInteger(80, new SecureRandom());
// 让字节以16进制展示
String res = v4.toString(16);
System.out.println(res); // 50892802fe9745acb94a
}
}
python还原
import random
# pytho3.9
# data = random.randbytes(10) # 随机生成10个字节
data = random.sample(range(256), 10) # 随机生成10个0-255的整数
ele_list = []
for item in data:
# 原生的hex函数会在前面加上'0x',这里去掉
ele = hex(item)[2:]
# 长度不够两位,前面补0
element = ele.rjust(2, '0')
# 添加进列表
ele_list.append(ele)
# 打印结果
print(''.join(ele_list)) # b7ece4948632c7f8
# 写成一行
data = ''.join([hex(random.sample(range(256), 1)[0])[2:].rjust(2, '0') for _ in range(10)])
print(data) # 67a4495c3768219c276e
1.4 时间戳
public class Hello {
public static void main(String[] args) {
// 秒级时间戳
String t1 = String.valueOf(System.currentTimeMillis() / 1000);
// 毫秒级时间戳
String t2 = String.valueOf(System.currentTimeMillis());
System.out.println(t1); // 1719837639
System.out.println(t2); // 1719837639177
}
}
import time
# 这里如果不转int的话会有小数点,转完int之后还要转为str来保证发送请求的时候不会出错
v1 = str(int(time.time()))
v2 = str(int(time.time()*1000))
print(v1)
print(v2)
1.5 md5加密
抖音:X-SS-STUB
每次发送POST请求时,抖音都会携带一些请求头:
X-SS-STUB = "fjaku9asdf"
读取请求体中的数据,对请求体中的数据进行md5加密。
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Arrays;
import java.util.Base64;
public class Hello {
public static void main(String[] args) throws NoSuchAlgorithmException {
String name = "X-SS-STUB";
// MD5加密
MessageDigest instance = MessageDigest.getInstance("MD5");
byte[] nameBytes = instance.digest(name.getBytes());
// System.out.println(Arrays.toString(nameBytes));
// String res = new String(nameBytes);
// System.out.println(res);
// 十六进制展示
StringBuilder sb = new StringBuilder();
for(int i=0;i<nameBytes.length;i++){
int val = nameBytes[i] & 255; // 负数转换为正数
if (val<16){
sb.append("0");
}
sb.append(Integer.toHexString(val));
}
String hexData = sb.toString();
System.out.println(hexData); // e6ada6e6b29be9bd90
}
}
python还原
import hashlib
obj = hashlib.md5()
obj.update('xxxxx'.encode('utf-8'))
# java中没有这个功能。
v1 = obj.hexdigest()
print(v1) # fb0e22c79ac75679e9881e6ba183b354
v2 = obj.digest()
print(v2) # b'\xfb\x0e"\xc7\x9a\xc7Vy\xe9\x88\x1ek\xa1\x83\xb3T'
1.6 sha-256加密
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Arrays;
import java.util.Base64;
public class Hello {
public static void main(String[] args) throws NoSuchAlgorithmException {
String name = "Prorise";
MessageDigest instance = MessageDigest.getInstance("SHA-256");
byte[] nameBytes = instance.digest(name.getBytes());
// System.out.println(Arrays.toString(nameBytes));
// String res = new String(nameBytes);
// System.out.println(res);
// 十六进制展示
StringBuilder sb = new StringBuilder();
for(int i=0;i<nameBytes.length;i++){
int val = nameBytes[i] & 255; // 负数转换为正数
if (val<16){
sb.append("0");
}
sb.append(Integer.toHexString(val));
}
String hexData = sb.toString();
System.out.println(hexData); // e6ada6e6b29be9bd90
}
}
import hashlib
m = hashlib.sha256()
m.update("Prorise".encode("utf-8"))
v2 = m.hexdigest()
print(v2)
1.7 AES加密
对称加密
- key & iv ,明文加密。【app端】
- key & iv ,解密。【API】
情况A: 请求体密文(抓包乱码)
情况B: sign,AES加密+base64编码
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import java.util.Arrays;
public class Hello {
public static void main(String[] args) throws Exception {
String data = "Prorise";
String key = "fd6b639dbcff0c2a1b03b389ec763c4b";
String iv = "77b07a672d57d64c";
// 加密
byte[] raw = key.getBytes();
SecretKeySpec skeySpec = new SecretKeySpec(raw, "AES");
IvParameterSpec ivSpec = new IvParameterSpec(iv.getBytes());
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, skeySpec, ivSpec);
byte[] encrypted = cipher.doFinal(data.getBytes());
System.out.println(Arrays.toString(encrypted)); // [-3, -116, -97, 69, 52, 48, 65, 79, -29, 7, 121, -125, 20, 57, -63, -32]
}
}
# pip install pycryptodome
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
KEY = "fd6b639dbcff0c2a1b03b389ec763c4b"
IV = "77b07a672d57d64c"
def aes_encrypt(data_string):
aes = AES.new(
key=KEY.encode('utf-8'),
mode=AES.MODE_CBC,
iv=IV.encode('utf-8')
)
raw = pad(data_string.encode('utf-8'), 16)
return aes.encrypt(raw)
data = aes_encrypt("Prorise")
print(data)
print([ i for i in data]) # [253, 140, 159, 69, 52, 48, 65, 79, 227, 7, 121, 131, 20, 57, 193, 224]
1.8 gzip压缩
抖音注册设备:设备。
注册设备:生成一些值,值中包括: (cdid、手机型号、手机品牌…) 后端读取到时候,发现cdid是一个全新的请求。那么抖音就会生成
device_id、install_id、tt
(cdid、手机型号、手机品牌....) --> gzip压缩(字节) --> 加密 --> 密文
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.security.SecureRandom;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.io.OutputStream;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
public class Hello {
public static void main(String[] args) throws IOException {
// 压缩
String data = "Prorise";
// System.out.println(Arrays.toString(data.getBytes()));
ByteArrayOutputStream v0_1 = new ByteArrayOutputStream();
GZIPOutputStream v1 = new GZIPOutputStream((v0_1));
v1.write(data.getBytes());
v1.close();
// [11,22,31,14,45]
byte[] arg6 = v0_1.toByteArray(); //gzip压缩后:arg6
System.out.println(Arrays.toString(arg6)); // [31, -117, 8, 0, 0, 0, 0, 0, 0, -1, 11, 40, -54, 47, -54, 44, 78, 5, 0, -59, 93, -53, 92, 7, 0, 0, 0]
// 解压缩
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = new ByteArrayInputStream(arg6);
GZIPInputStream ungzip = new GZIPInputStream(in);
byte[] buffer = new byte[256];
int n;
while ((n = ungzip.read(buffer)) >= 0) {
out.write(buffer, 0, n);
}
byte[] res = out.toByteArray();
// System.out.println(Arrays.toString(res));
System.out.println(out.toString("UTF-8"));
}
}
import gzip
# 压缩
s_in = "Prorise".encode('utf-8')
s_out = gzip.compress(s_in)
print([i for i in s_out]) # [31, 139, 8, 0, 164, 168, 130, 102, 2, 255, 11, 40, 202, 47, 202, 44, 78, 5, 0, 197, 93, 203, 92, 7, 0, 0, 0]
# 解压缩
res = gzip.decompress(s_out)
print(res) # b'Prorise'
print(res.decode('utf-8')) # Prorise
提醒:java、Python语言区别。(个人字节是不同,不影响整个的结果),。
1.9 base64编码
import java.util.Base64;
public class Hello {
public static void main(String[] args) {
String name = "Prorise";
// 加密
Base64.Encoder encoder = Base64.getEncoder();
String res = encoder.encodeToString(name.getBytes());
System.out.println(res); // "5q2m5rKb6b2Q"
// 解密
Base64.Decoder decoder = Base64.getDecoder();
byte[] origin = decoder.decode(res);
String data = new String(origin);
System.out.println(data); // 武沛齐
}
}
import base64
name = "Prorise"
# 编码
res = base64.b64encode(name.encode('utf-8'))
print(res) #b'UHJvcmlzZQ=='
# 解码
data = base64.b64decode(res)
origin = data.decode('utf-8')
print(origin) # Prorise
2.客户端请求全流程

2.1.安卓UI和后台逻辑
安卓UI

<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<LinearLayout
android:layout_width="match_parent"
android:layout_height="200dp"
android:layout_marginTop="150dp"
android:background="#ddd"
android:orientation="vertical">
<TextView
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_marginTop="10dp"
android:text="用户登录"
android:textAlignment="center"
android:textSize="20dp" />
<LinearLayout
android:layout_width="match_parent"
android:layout_height="50dp"
android:paddingLeft="50dp"
android:paddingRight="50dp">
<TextView
android:layout_width="60dp"
android:layout_height="wrap_content"
android:gravity="right"
android:text="用户名:" />
<EditText
android:layout_width="match_parent"
android:layout_height="match_parent"
android:inputType="text"></EditText>
</LinearLayout>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="50dp"
android:paddingLeft="50dp"
android:paddingRight="50dp">
<TextView
android:layout_width="60dp"
android:layout_height="wrap_content"
android:gravity="right"
android:text="密码:" />
<EditText
android:layout_width="match_parent"
android:layout_height="match_parent"
android:inputType="textPassword"></EditText>
</LinearLayout>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="50dp"
android:gravity="center">
<Button
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginRight="10dp"
android:text="登 录"></Button>
<Button
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginLeft="10dp"
android:text="重 置"></Button>
</LinearLayout>
</LinearLayout>
</LinearLayout>
后台逻辑
package com.nb.liyang;
import androidx.appcompat.app.AppCompatActivity;
import android.content.SharedPreferences;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import com.google.gson.Gson;
import java.io.IOException;
import java.net.Proxy;
import java.security.MessageDigest;
import java.util.HashMap;
import java.util.Map;
import okhttp3.Call;
import okhttp3.FormBody;
import okhttp3.Interceptor;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import okhttp3.ResponseBody;
public class MainActivity extends AppCompatActivity {
// 拿到后台的ID,设置为私有变量供MainActivity访问
private TextView txtUser, txtPwd;
private Button btnLogin, btnReset;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 调用视图层和监听器函数
initView();
initListener();
}
// 视图层(实例化标签函数)
private void initView() {
// 先找到所有的有用的标签
txtUser = findViewById(R.id.txt_user);
txtPwd = findViewById(R.id.txt_pwd);
btnLogin = findViewById(R.id.btn_login);
btnReset = findViewById(R.id.btn_reset);
}
// 监听函数
private void initListener() {
btnReset.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// 点击btn_reset标签,执行方法
txtUser.setText("");
txtPwd.setText("");
}
});
// 登录按钮,用户点击进入登录逻辑
btnLogin.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
loginForm();
}
});
}
// 登录主逻辑
private void loginForm() {
/** 1.拿到用户名和密码
String username = String.valueOf(txtUser.getText());
String password = String.valueOf(txtPwd.getText());**/
// 2.校验用户名和密码不能为空
StringBuilder sb = new StringBuilder();
HashMap<String, String> dataMap = new HashMap<String, String>();
boolean hasEmpty = false;
// 更复杂的处理逻辑
HashMap<String, TextView> mapping = new HashMap<String, TextView>();
mapping.put("username", txtUser);
mapping.put("password", txtPwd);
for (Map.Entry<String, TextView> entry : mapping.entrySet()) {
String key = entry.getKey();
TextView obj = entry.getValue();
String value = String.valueOf(obj.getText());
if (value.trim().isEmpty()) {
hasEmpty = true;
break;
}
dataMap.put(key, value);
sb.append(value);
}
if (hasEmpty) {
Toast.makeText(this, "输入内容不能为空", Toast.LENGTH_SHORT).show();
return;
}
// 3.用md5做一个签名
String signString = md5(sb.toString());
dataMap.put("sign", signString);
Log.e("加密后的结果:", signString);
// 通过线程发送网络请求
new Thread() {
@Override
public void run() {
// 线程执行的内容
// user=xxx&pwd=xxx&sign=xxxx
OkHttpClient client = new OkHttpClient.Builder().build();
// OkHttpClient client = new OkHttpClient.Builder().proxy(Proxy.NO_PROXY).build();
FormBody form = new FormBody.Builder()
.add("user", dataMap.get("username"))
.add("pwd", dataMap.get("password"))
.add("sign", dataMap.get("sign")).build();
Request req = new Request.Builder().url("http://192.168.0.6:9999/login").post(form).build();
Call call = client.newCall(req);
try {
Response res = call.execute();
ResponseBody body = res.body();
String dataString = body.string();
// {"status": true, "token": "dafkauekjsoiuksjdfuxdf", "name": "武沛齐"}
// 反序列化
HttpResponse obj = new Gson().fromJson(dataString,HttpResponse.class);
if(obj.status){
// token保存本地xml文件
// /data/data/com.nb.liyang
SharedPreferences sp = getSharedPreferences("sp_city", MODE_PRIVATE);
SharedPreferences.Editor editor = sp.edit();
editor.putString("token",obj.token);
editor.commit();
}
Log.e("请求发送成功", dataString);
} catch (IOException ex) {
Log.e("Main", "网络请求异常");
}
}
}.start();
}
/**
* md5加密
*
* @param dataString 待加密的字符串
* @return 加密结果
*/
private String md5(String dataString) {
try {
MessageDigest instance = MessageDigest.getInstance("MD5");
byte[] nameBytes = instance.digest(dataString.getBytes());
// 十六进制展示
StringBuilder sb = new StringBuilder();
for (int i = 0; i < nameBytes.length; i++) {
int val = nameBytes[i] & 255; // 负数转换为正数
if (val < 16) {
sb.append("0");
}
sb.append(Integer.toHexString(val));
}
return sb.toString();
} catch (Exception e) {
return null;
}
}
}
API
import flask
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/login', methods=["POST"])
def login():
# 1.接收请求数据
print(request.form)
# 2.校验签名
# 3.校验用户名和密码是否正确
# 4.返回值
return jsonify({"status": True, 'token': "dafkauekjsoiuksjdfuxdf"})
if __name__ == '__main__':
app.run(host="0.0.0.0", port=9999)
2.2 网络请求
- 1.引入,在build.gradle中 implementation "com.squareup.okhttp3:okhttp:4.9.1"
- 2.配置,在AndroidManifest.xml中 <uses-permission android:name="android.permission.INTERNET"/>
发送表单数据
new Thread() {
@Override
public void run() {
OkHttpClient client = new OkHttpClient();
// 将表单数据提取
FormBody form = new FormBody.Builder()
.add("user", dataMap.get("username"))
.add("pwd", dataMap.get("password"))
.add("sign", dataMap.get("sign")).build();
// 发送到服务端
Request req = new Request.Builder().url("http://192.168.0.6:9999/login").post(form).build();
Call call = client.newCall(req);
try {
Response res = call.execute();
ResponseBody body = res.body();
// 字符串={"status": true, "token": "fffk91234ksdujsdsd", "name": "xxx"}
String dataString = body.string();
// Log.e("MDS", "请求成功获取返回值=" + dataString);
} catch (IOException ex) {
Log.e("MDS", "网络请求错误");
}
}
}.start();
发送json数据
new Thread() {
@Override
public void run() {
OkHttpClient client = new OkHttpClient();
// dataMap = {"username":"wupeiqi","password":"123","sign":"用户名和密码的md5值"}
JSONObject json = new JSONObject(dataMap);
String jsonString = json.toString();
// RequestBody form = RequestBody.create(MediaType.parse("application/json;charset=utf-8"),jsonString);
RequestBody form = RequestBody.create(MediaType.parse("application/json;charset=utf-8"),jsonString);
Request req = new Request.Builder().url("http://192.168.0.6:9999/login").post(form).build();
Call call = client.newCall(req);
try {
Response res = call.execute();
ResponseBody body = res.body();
String dataString = body.string();
Log.i("登录", dataString);
} catch (IOException e) {
e.printStackTrace();
}
}
}.start();
2.3反序列化
Gson组件
implementation 'com.google.code.gson:gson:2.8.6'
-
序列化,对象 -> 字符串类型
class HttpContext{ public int code; public String message; public HttpContext(int code,String msg){ this.code = code; this.message = msg; } } HttpContext obj = new HttpContext(1000,"成功"); # json.dumps String dataString = new Gson().toJson(obj); // '{"code":1000,"Message":"成功"}' -
反序列化,字符串 -> 对象
python的字符串 v = '{"code":1000,"Message":"成功"}'
java的字符串
String v = “{“code”:1000,“Message”:“成功”}”
```java
// JSON格式
String dataString = "{\"status\": true, \"token\": \"fffk91234ksd\", \"name\": \"Prorise\"}";
class HttpResponse{
public boolean status;
public String token;
public String name;
}
HttpResponse obj = new Gson().fromJson(dataString,HttpResponse.class);
obj.status
obj.name
obj.token
复杂化处理
String responseString = "{
\"origin\": \"110.248.149.62\",
\"url\": \"https://www.httpbin.org/post\",
\"dataList\":[
{\"id\":1,\"name\":\"Prorise\"},
{\"id\":2,\"name\":\"eric\"}]
}";
class Item {
public int id;
public String name;
}
public class HttpResponse {
public String url;
public String origin;
public ArrayList<Item> dataList;
}
HttpResponse obj = new Gson().fromJson(dataString,HttpResponse.class);
obj.url
obj.origin
Item objItem = obj.dataList.get(1);
objItem.name
发送请求
class HttpResponse{
public boolean status;
public String token;
}
String dataString = "{"status":true,"token":"b96efd24-e323-4efd-8813-659570619cde"}";
HttpResponse obj = new Gson().fromJson(dataString,HttpResponse.class);
obj.status
obj.token
2.4请求拦截器
假设开发app,发送10个请求,每个请求中需要携带特殊的请求头:xxxx。
将所有请求公共的操作都放在拦截器里面,在每次请求成功以后会走拦截器里的逻辑,在绝大多数情况下加密逻辑也会在拦截器里面执行
// 创建拦截器
Interceptor interceptor = new Interceptor() {
@Override
public Response intercept(Chain chain) throws IOException {
// 1988812212 + 固定字符串 => md5加密
Request request = chain.request().newBuilder().addHeader("ts", "1988812212").addHeader("sign", "xxxx").build();
// 请求前
Response response = chain.proceed(request);
// 请求后
return response;
}
};
// 4.将三个值:用户名、密码、签名 网络请求发送API(校验)
// okhttp,安装 & 引入 & 使用(创建一个线程去执行)
// 5.获取返回值
new Thread() {
@Override
public void run() {
// 线程执行的内容
// user=xxx&pwd=xxx&sign=xxxx
// OkHttpClient client = new OkHttpClient.Builder().build();
OkHttpClient client = new OkHttpClient.Builder().addInterceptor(interceptor).build();
FormBody form = new FormBody.Builder()
.add("user", dataMap.get("username"))
.add("pwd", dataMap.get("password"))
.add("sign", dataMap.get("sign")).build();
Request req = new Request.Builder().url("http://192.168.0.6:9999/login").post(form).build();
Call call = client.newCall(req);
try {
Response res = call.execute();
ResponseBody body = res.body();
String dataString = body.string();
Log.e("请求发送成功", dataString);
} catch (IOException ex) {
Log.e("Main", "网络请求异常");
}
}
}.start();
2.5 NO_PROXY
在okhttp包里,防止系统代理抓包的一个选项,在开发时设置该方法,在抓取app时通过代理转接到服务器就无法通过抓包软件去抓取到数据
new Thread() {
@Override
public void run() {
OkHttpClient client = new OkHttpClient.Builder().proxy(Proxy.NO_PROXY).build();
// OkHttpClient client = new OkHttpClient.Builder().build();
FormBody form = new FormBody.Builder()
.add("user", dataMap.get("username"))
.add("pwd", dataMap.get("password"))
.add("sign", dataMap.get("sign")).build();
Request req = new Request.Builder().url("http://192.168.0.6:9999/login").post(form).build();
Call call = client.newCall(req);
try {
Response res = call.execute();
ResponseBody body = res.body();
// 字符串={"status": true, "token": "fffk91234ksdujsdsd", "name": "武沛齐"}
String dataString = body.string();
// Log.e("MDS", "请求成功获取返回值=" + dataString);
} catch (IOException ex) {
Log.e("MDS", "网络请求错误");
}
}
}.start();
2.6 retrofit
内部封装了okhttp,让你用的更加的简单(B站算法)。
-
引入
// implementation "com.squareup.okhttp3:okhttp:4.9.1" implementation "com.squareup.retrofit2:retrofit:2.9.0" -
写接口,声明网络请求
package com.nb.mds; import okhttp3.RequestBody; import okhttp3.ResponseBody; import retrofit2.Call; import retrofit2.http.Body; import retrofit2.http.Field; import retrofit2.http.FormUrlEncoded; import retrofit2.http.POST; import retrofit2.http.GET; import retrofit2.http.Query; public interface HttpReq { // 向/api/v1/post 发送POST请求 name=xx&pwd=xxx @POST("/api/v1/post") @FormUrlEncoded Call<ResponseBody> postLogin(@Field("name") String userName, @Field("pwd") String password); // ->/api/v2/xxx?age=999 @GET("/api/v2/xxx") Call<ResponseBody> getInfo(@Query("age") String age); // 向/post/users 发送POST请求 {name:xxxx,age:123} @POST("/post/users") Call<ResponseBody> postLoginJson(@Body RequestBody body); @GET("/index") Call<ResponseBody> getIndex(@Query("age") String age); } -
发送请求
new Thread() { @Override public void run() { // http://api.baidu.com/api/v2/xxx?age=123 Retrofit retrofit = new Retrofit.Builder().baseUrl("http://api.baidu.com/").build(); HttpReq req = retrofit.create(HttpReq.class); Call<ResponseBody> call = req.getInfo("123"); try { ResponseBody responseBody = call.execute().body(); String responseString = responseBody.string(); Log.e("Retrofit返回的结果", responseString); } catch (Exception e) { e.printStackTrace(); } } }.start();new Thread() { @Override public void run() { Retrofit retrofit = new Retrofit.Builder().baseUrl("https://www.httpbin.org/").build(); HttpRequest httpRequest = retrofit.create(HttpRequest.class); // https://www.httpbin.org/api/v1/post // name=xx&pwd=xxx Call<ResponseBody> call = httpRequest.postLogin("wupeiqi", "666"); try { ResponseBody responseBody = call.execute().body(); String responseString = responseBody.string(); Log.i("登录", responseString); } catch (Exception e) { e.printStackTrace(); } } }.start();new Thread() { @Override public void run() { Retrofit retrofit = new Retrofit.Builder().baseUrl("https://www.httpbin.org/").build(); HttpRequest httpRequest = retrofit.create(HttpRequest.class); JSONObject json = new JSONObject(dataMap); String jsonString = json.toString(); RequestBody form = RequestBody.create(MediaType.parse("application/json;charset=utf-8"),jsonString); // https://www.httpbin.org/post/users // {username:"root",password:"123","sign":"xxxxdfsdfsdfsdfdfd"} Call<ResponseBody> call = httpRequest.postLoginJson(form); try { ResponseBody responseBody = call.execute().body(); String responseString = responseBody.string(); Log.i("登录", responseString); } catch (Exception e) { e.printStackTrace(); } } }.start();
2.7 保存XML文件
一般来讲,代码的主要逻辑默认是保存在手机本地上的/data/com.xxx.xxx里面的xml文件上的,放在xml中的一般都是app刚启动时、刚登录时生成,所以有时候一些数据只会存在于第一次抓包的时候
APP刚启动
- 发送网络请求,返回 xxxid=123123123
- 保存XML
xxxid=123123123
再次启动APP
- 抓其他的包,携带了参数 xxxid=123123123
------------------------------------------
- 将app数据清除,xml也会被清除(重装)
- 启动app
- 发送网络请求,返回 xxxid=123123123
- 抓其他的包,携带了参数 xxxid=123123123
逆向过程中的思路:udid
- udid找到代码位置
- 先去内存中获取
- 去XML文件中获取 SharedPreferences sp
- 写入内存
- 算法生成
- 写入XML
- 写入内存
返回
------------------------------------------
- udid找到代码位置
- 先去内存中获取
- 去XML文件中获取 SharedPreferences sp
- 写入内存
没代码了....
这种情况一般都是在程序刚启动时,发送了请求,获取值,写入XML
保存
SharedPreferences sp = getSharedPreferences("sp_city", MODE_PRIVATE);
SharedPreferences.Editor editor = sp.edit();
editor.putString("token","111111");
editor.commit();
删除
SharedPreferences sp = getSharedPreferences("sp_city", MODE_PRIVATE);
SharedPreferences.Editor editor = sp.edit();
editor.remove("token");
editor.commit();
读取
SharedPreferences sp = getSharedPreferences("sp_city", MODE_PRIVATE);
String token = sp.getString("token","");
3.JNI开发
3.1 NDK
NDK(Native Development Kit)是Android的一个工具集,允许开发者使用C和C++等原生编程语言编写Android应用的一部分代码。主要用途包括提高性能、访问硬件功能和移植现有C/C++代码到Android平台。NDK需要与Java开发的Android SDK结合使用,提供了更多灵活性和控制权。
- 普通项目:Empty Activity(Java)
- jni项目:Native C++(Java + C)
创建的项目多了一些内容和配置(基于C++实现了一个算法,并在Java中进行了调用)。
- 有了默认配置后,我们就不需要自己的手动配置了。
- 会生成一些我们用不到的默认文件,等我们学会自己再回来删除他默认的这些文件。
在Android里面新建一个C模板
3.2快速上手
新建Java类
新建一个java的类,模拟实现项目中的核心算法。
- v0,用Java实现的算法
- v1,用C实现算法
在Java的类里面调用这功能
package com.nb.Prorise
public class{
// 加载c文件
static {
System.loadLibrary("enc")
}
// java方法
public static int v0(int a,int b){
return a +b
}
// c语言方法
public static native int v1(int a,int b);
}
创建一个c语言文件,键入如下代码进行连接
#include <jni.h>
JNIEXPORT jint
JNICALL Java_com_nb_s4luffy_EncryptUtils_v1(JNIEnv* env,jclass clazz, jint v1,jint v2) {
// 编写C语言的代码
return v1 + v2;
}
不想手动编写的话,可以用命令自动生成:
>>>cd app/src/main/java
>>>javah com.nb.Prorise.EncryptUtils (java 8)
>>>javac -h com.nb.Prorise.EncryptUtils (java 11+)
进入CMakeLists.txt编辑代码配置,更新C文件

再次回到 enc.c 文件中,再点击sync now就不再提示错误了。
最后回到MianActivity.java里面键入如下代码,进行调用
int value = EncryptUtils.v2(1,20)
Log.e(“====>”,String.valueOf(value))
3.3 逆向和反编译




3.4关于类型
C语言和Java之间互相调用需要进过JNI的中间转换,JNI将他们的类型转换为jstring,jint类型等等

















 58万+
58万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









