






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
基于Linux操作系统下搭建好的Hadoop环境以及Eclipse 开发环境,完成社交好友推荐的 MapReduce程序。
提示:以下是本篇文章正文内容,下面案例可供参考
一、实验原理
1. 如果A和B具有好友关系,B和C具有好友关系,而A和C却不是好友关系,那么我们称A和C这样的关 系为:二度好友关系。
在生活中,二度好友推荐的运用非常广泛,比如某些主流社交产品中都会有"可能认识的人"这样的功 能,一般来说可能认识的人就是通过二度好友关系搜索得到的,在传统的关系型数据库中,可以通过图 的广度优先遍历算法实现,而且深度限定为2,然而在海量的数据中,这样的遍历成本太大,所以有必要 利用MapReduce编程模型来并行化。
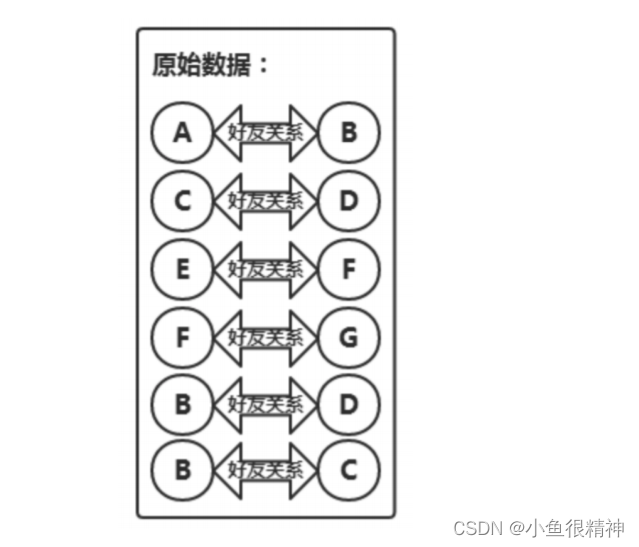
初始数据如下:
A B
C D
E F
F G
B D
B C
map阶段得到的结果为:
Key:A Value:B
Key:B Value:A C D
Key:C Value:B D
Key:D Value:B C
Key:E Value:F
Key:F Value:E G
Key:G Value:F
Reduce阶段再将Value进行笛卡尔积运算就可以得到二度好友关系了
(笛卡尔积公式:A×B={(x,y)|x∈A∧y∈B}
例如,A={a,b}, B={0,1,2},则
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)} B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)})
原理图:
分析结果:
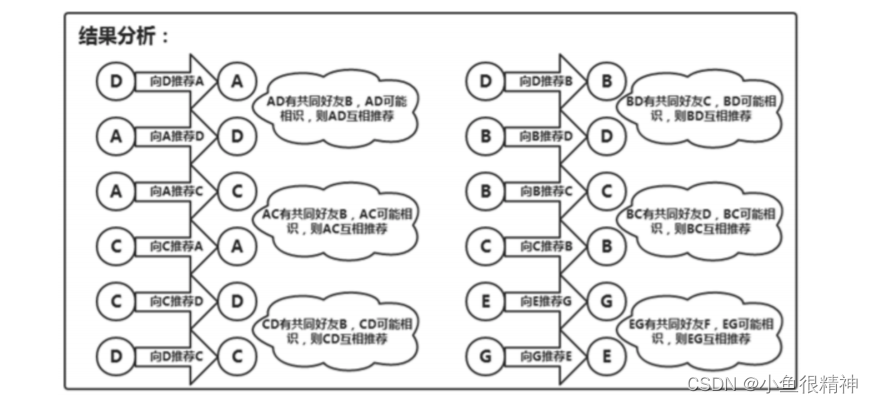
通过初始数据,假设有A、B、C、D、E、F、G七位同学,其中A与B是好友关系,C与D是好友关系,E 与F是好友关系,F与G是好友关系,B与D是好友关系,B与C是好友关系,通过分析A与B是好友,且B与 C也是好友,我们就认为A与C互为可能认识的人,向A与C互相推荐对方。
二、实验步骤
1.准备数据
1.准备数据,新建 friend_data.txt 文件,内容如下(注意数据之间以空格分割)
A B
C D
E F
F G
B D
B C2.编码
1.Mapper代码:
package org.example_1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FriendMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//value 为 A B
String line = value.toString();
String[] split = line.split("\\s+"); //配置任意多个空白字符,包括空格、tab、换行、换页、回车
//输出 A B
context.write(new Text(split[0]),new Text(split[1]));
//输出 B A
context.write(new Text(split[1]),new Text(split[0]));
}
}
2.Reducer代码:
package org.example_1;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import javax.naming.Context;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
public class FriendReducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{
//去重,分析输入数据,其实无重复,防止数据异常,可添加
HashSet<String> set = new HashSet<String>();
for (Text v : values){
set.add(v.toString());
}
if (set.size()>1){
for (Iterator<String> i = set.iterator(); i.hasNext();) {
String qqName = i.next();
for (Iterator<String> j = set.iterator(); j.hasNext();){
String othrQqName = j.next();
if (!qqName.equals(othrQqName)){ //不是同一个账号,可以推荐
context.write(new Text(qqName),new Text(othrQqName));
}
}
}
}
}
}
3.Main代码:
package org.example_1;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendMain {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.创建一个job和任务入口
Job job = Job.getInstance();
//main 方式所在的class
job.setJarByClass(FriendMain.class);
//2。指定job的mapper和输出的类型<k2,v2>
job.setMapperClass(FriendMapper.class); //指定Mapper类
job.setMapOutputKeyClass(Text.class); //k2的类型
job.setMapOutputValueClass(Text.class); //v2的类型
//3.指定job的reducer和输出的类型<k4,v4>
job.setReducerClass(FriendReducer.class); //指定Rapper类
job.setOutputKeyClass(Text.class); //k4的类型
job.setOutputValueClass(Text.class); //v4的类型
//4.指定job的输入和输出
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//本地运行
// FileInputFormat.setInputPaths(job,new Path("D:\\DingDing\\TableHahoop\\input\\data1"));
// FileOutputFormat.setOutputPath(job,new Path("D:\\DingDing\\TableHahoop\\output0000"));
//5.执行job
job.waitForCompletion(true);
}
}4.打包 jar 上传Linux系统
scp local_filename root@remote_ip:remote_folder
remote_ip 填开发板ip地址,remote_folder 填写开发板的目录,例如根目录 /home
5.Linux系统下搭建好的Hadoop环境下运行 jar 包
hadoop jar hdfs-api2012-1.0-SNAPSHOT.jar org.example_1.FriendMain /input/frien_data.txt /output/friend三、查看结果
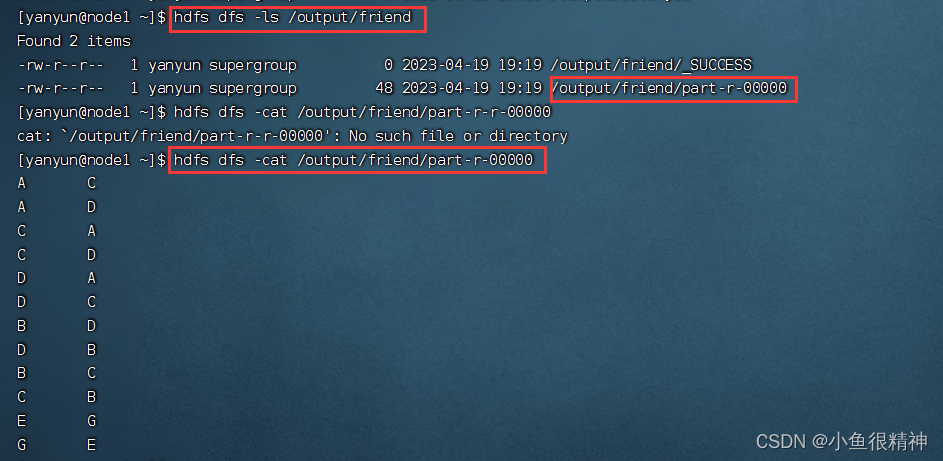
总结
通过编写社交好友推荐的MapReduce程序,加深笛卡尔积以及其结合MapReduce方式的理解,熟 练掌握MapReduce程序在处理企业实际项目问题的方法。

















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









