import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 设置中文字体为黑体,确保能正确显示中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 解决负号显示问题,使负号能正确显示
plt.rcParams["axes.unicode_minus"] = False
# 从当前目录下的source.xlsx文件中读取数据到DataFrame
df = pd.read_excel('./source.xlsx')
# 将数据中的缺失值填充为0
df = df.fillna(0)
# 计算总成绩,使用向量化操作,比逐个元素计算效率高
# 平时成绩占30%,考试成绩占70%
df['总成绩'] = df['平时成绩'] * 0.3 + df['考试成绩'] * 0.7
# 利用numpy的向量化操作判断是否及格,而不是使用apply方法
# 如果总成绩大于等于60,则为'及格',否则为'不及格'
pass_status = np.where(df['总成绩'] >= 60, '及格', '不及格')
# 计算及格率,直接利用布尔数组计算均值
# 将及格的布尔数组转换为数值(True为1,False为0),再求均值得到及格率
pass_rate = (pass_status == '及格').mean()
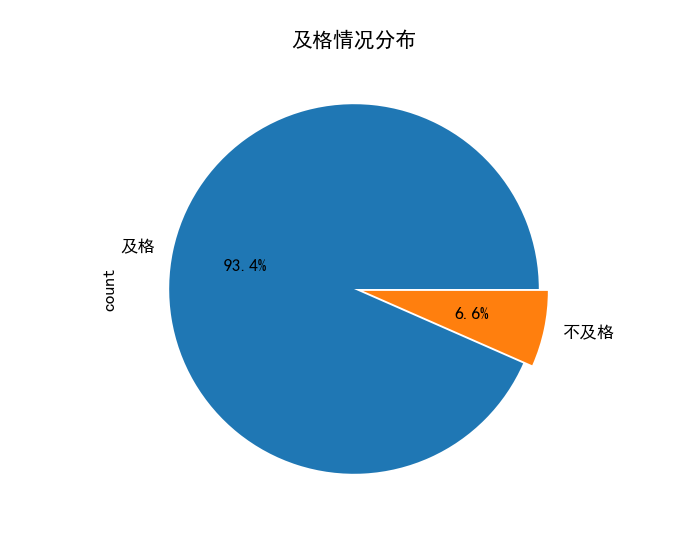
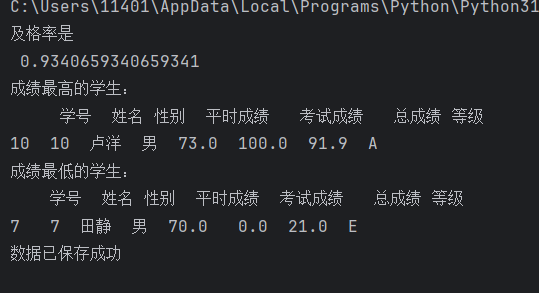
print("及格率是\n", pass_rate)
# 统计及格和不及格的人数
# 使用pandas的Series.value_counts()方法统计每个类别出现的次数
pass_count = pd.Series(pass_status).value_counts()
# 绘制饼图
# 如果'不及格'在统计结果的索引中,则设置explode参数使'不及格'部分稍微突出显示
explode = (0, 0.05) if '不及格' in pass_count.index else (0, 0)
# 绘制饼图,显示百分比,保留一位小数
pass_count.plot(kind="pie", autopct="%1.1f%%", explode=explode)
plt.title('及格情况分布')
plt.show()
# 成绩等级划分函数
def grade_division(score):
if score >= 90:
return 'A'
elif score >= 80:
return 'B'
elif score >= 70:
return 'C'
elif score >= 60:
return 'D'
else:
return 'E'
# 对总成绩应用成绩等级划分函数,生成'等级'列
df['等级'] = df['总成绩'].apply(grade_division)
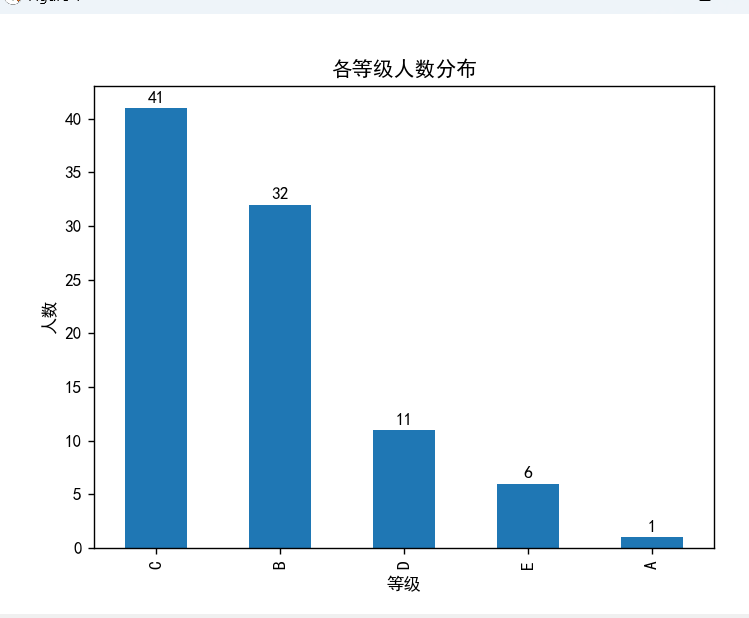
# 统计各等级人数
grade_count = df['等级'].value_counts()
# 绘制各等级人数柱状图
grade_count.plot(kind='bar')
plt.title('各等级人数分布')
plt.xlabel('等级')
plt.ylabel('人数')
# 在柱状图上添加人数标注
for i, v in enumerate(grade_count):
plt.text(i, v + 0.5, str(v), ha='center')
# 找出成绩最高和最低的学生
# 通过比较总成绩,筛选出总成绩等于最大值的行
max_score_student = df[df['总成绩'] == df['总成绩'].max()]
# 通过比较总成绩,筛选出总成绩等于最小值的行
min_score_student = df[df['总成绩'] == df['总成绩'].min()]
print("成绩最高的学生:\n", max_score_student)
print("成绩最低的学生:\n", min_score_student)
# 保存结果到Excel文件,不保存索引
df['是否及格'] = pass_status
df.to_excel("处理后的学生成绩表.xlsx", index=False)
print("数据已保存成功")
plt.show()
























 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









