






命名管道
| 特性 | 命名管道(Named Pipe) | 匿名管道(Anonymous Pipe) |
|---|---|---|
| 标识方式 | 文件系统中的特殊文件(如 /tmp/my_pipe) | 仅存在于内存,无文件系统路径 |
| 进程关系 | 可被任意进程访问(需权限) | 仅限父子进程或同源进程 |
| 生命周期 | 持久化(除非显式删除) | 随进程结束自动销毁 |
| 跨主机通信 | 支持(如Windows的SMB协议) | 不支持 |
Linux中的命名管道 (named pipe) 是一种特殊类型的文件,又称为FIFO。
它外的外在表现好像是一个磁盘文件,实际上本质只是一个数据流或缓冲区。
管道允许一个进程的输出直接作为另一个进程的输入,在Linux系统中是一种重要的实现进程间通信(IPC)的机制。
命名管道创建的管道文件不是普通的磁盘文件。这个文件本身不存储数据(它不占用磁盘空间来存储长期数据),而是作为一个通信接口存在 (它是一个文件系统标识, 方便我们以操作文件系统的方式读写管道的缓冲区)。
命名管道, 从一端读取数据, 从另一端写入数据。使用命名管道, 必须读端写端同时打开, 无法单独去打开读端或者写端。
命名管道是一种半双工通信, 但是我们一般把它当作单工管道使用( 即: 一个进程只打开它的写端写数据, 另一个进程只打开它的读端读数据)。
当管道缓冲区无数据, 读管道的操作将被阻塞。
当管道缓冲区写满, 写管道将被阻塞。
在管道操作中, 如果写端关闭, 读端可以继续读取缓冲区的剩余数据, 如果缓冲区没有剩余数据, 读取操作(read)直接返回0。
在管道操作中, 如果读端关闭, 写端继续向管道中写数据的时候, 会导致写操作(write)触发SIGPIPE信号, 进而导致进程异常终止。
一般我们会使用两根管道构建两个进程间的全双工通信。
如何创建管道?
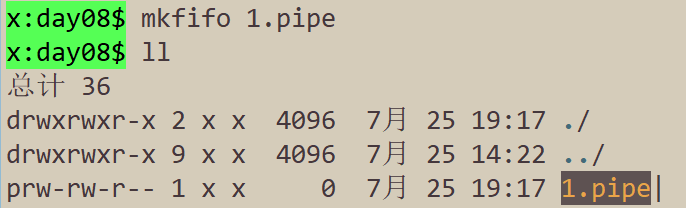

- 通过
echo hello > 1.pipe向管道缓冲区写入数据, 我们会发现这个写入操作会直接写阻塞; 这是因为使用命名管道 , 是从一端读取数据, 从另一端写入数据, 必须读端写端同时打开, 无法单独去打开读端或者写端。- 当我们另开一个窗口(新的进程)使用
cat 1.pipe读取管道数据, 相当于开启了管道的读端, 这可以使之前打开的写端正常写入, 从阻塞态变为非阻塞态写入; 等写端写入完成之后, 读端读出写入数据。
当然也可以通过代码实现
写端
#include <header.h>
int main(int argc,char*argv[]){
int fd_write = open("1.pipe", O_WRONLY);
char buf[4096] = {0};
int times = 0;
while(1){
ssize_t ret= read(STDIN_FILENO,buf,4096);
write(fd_write, buf, ret);
}
close(fd_write);
return 0;
}
读端
#include <header.h>
int main(int argc,char*argv[]){
int fd_read = open("1.pipe", O_RDONLY);
char buf[4096] = {0};
while(1){
ssize_t ret= read(fd_read, buf, sizeof(buf));
if(ret!=0){
printf("read:%s \n",buf);}
}
close(fd_read);
return 0;
}
假设我们通过pipe实现一个通信, 写端一直在写, 读端不读, 会发生什么? 会发生写阻塞; 因为管道的大小是有限制的。
管道的真实可用缓冲区的大小取决于单个单个管道缓冲区大小和管道缓冲区的数目共同决定。而且在不同的操作系统设置是不一样的。
ulimit -a

512 bytes:表示单个数据块的单位大小。
8:表示块数量,因此总缓冲区大小为 512 * 8 = 4096 bytes(4KB)。
我们也可以从操作系统的源码中查看, 管道缓冲区个数为16
假设我们创建一个1.pipe的管道, 我们在不读的情况下可以连续写入16个4096, 即可把管道写满, 再试图写就会写阻塞; 写满之后, 假设又读出4096字节,我们可以再接着写4096个字节
现在我们有一份新的需求,实现一份代码, 让两个程序基于基于pipe管道的双工通信。工作流程图如下:
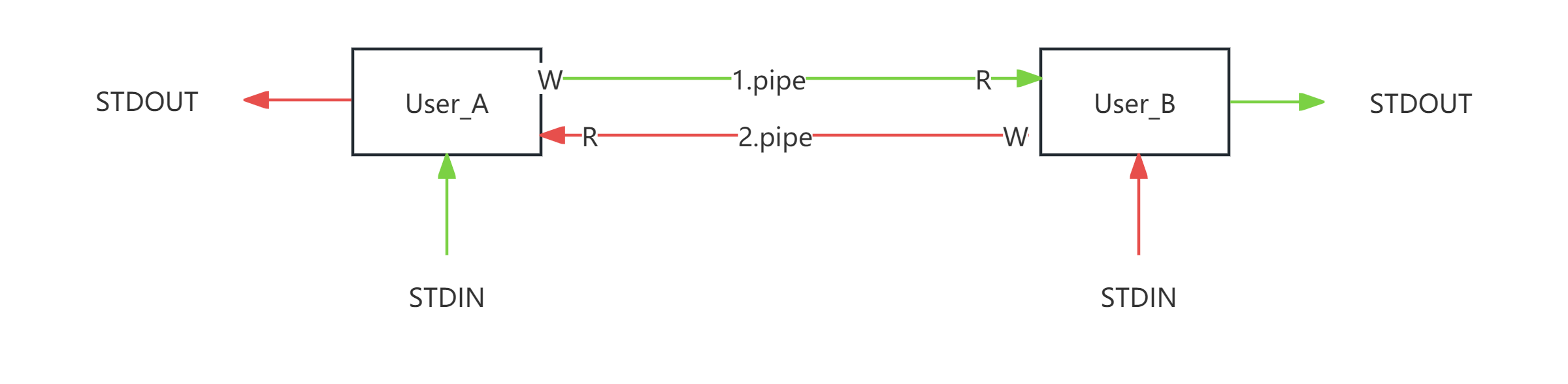
A程序
int main() {
int fd_write = open("1.pipe", O_WRONLY);
int fd_read = open("2.pipe", O_RDONLY);
while (1) {
// 先读取标准输入并发送
char buf[60];
bzero(buf, sizeof(buf));
int read_stdin = read(STDIN_FILENO, buf, sizeof(buf));
if (read_stdin == 0) break;
write(fd_write, buf, read_stdin); // 仅写入实际读取的字节数
// 然后读取对方回复
bzero(buf, sizeof(buf));
int read_num = read(fd_read, buf, sizeof(buf));
if (read_num == 0) {
printf("对方断开链接\n");
break;
}
printf("UserB: %s", buf); // 假设对方发送的数据已包含换行
}
close(fd_write);
close(fd_read);
return 0;
}
B程序
int main() {
int fd_read = open("1.pipe", O_RDONLY);
int fd_write = open("2.pipe", O_WRONLY);
while (1) {
// 先读取对方消息
char buf[60];
bzero(buf, sizeof(buf));
int read_num = read(fd_read, buf, sizeof(buf));
if (read_num == 0) {
printf("对方断开链接\n");
break;
}
printf("UserA: %s", buf);
// 然后读取标准输入并回复
bzero(buf, sizeof(buf));
int read_stdin = read(STDIN_FILENO, buf, sizeof(buf));
if (read_stdin == 0) break;
write(fd_write, buf, read_stdin);
}
close(fd_write);
close(fd_read);
return 0;
}
在上面的代码过程中, 我们需要注意一些问题:
- 1.pipe和2.pipe在A和B中的打开顺序, 有可能导致产生竞争条件导致死锁。
- 上面的对答流程属于一问一答式的模式, 需要由A发起聊天。连续发送多条数据对面无法立即显示。
- 你要先创建1.pipe和2.pipe
上面流程明显不符合实际生活对话流程, 该怎么改进这个过程?
上面一问一答式的对话流程, 是因为在上面代码执行中, 它是一个串行执行的逻辑, 如果模拟现实情况, 我们更希望要做的是怎么把这个串行逻辑改为并行逻辑。这里我们就可以用到IO多路复用技术。
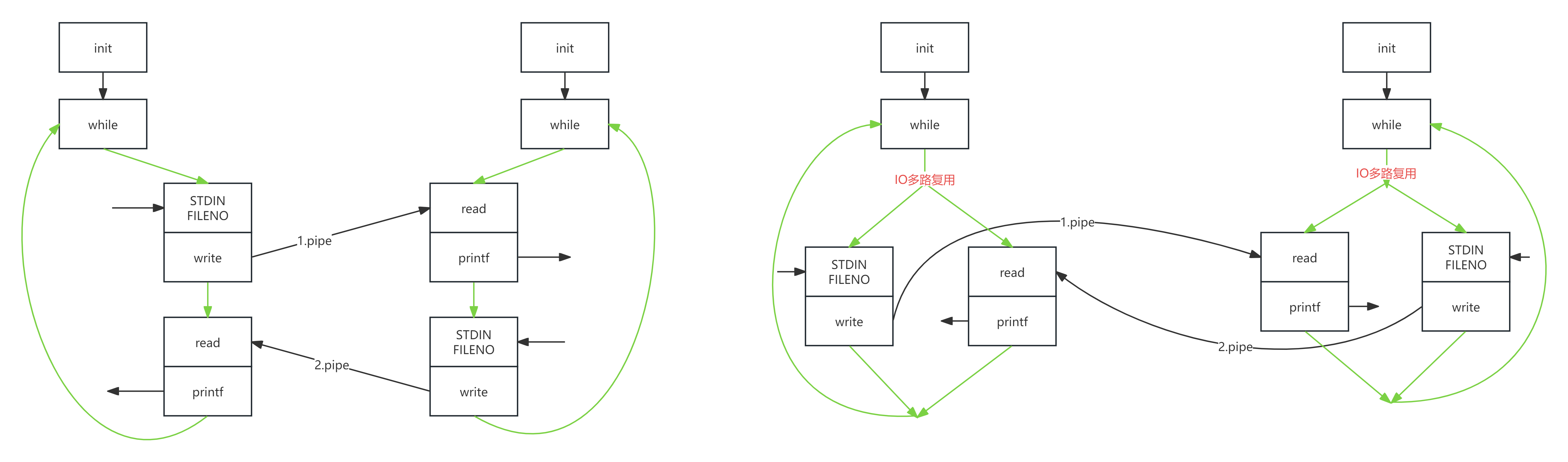
IO多路复用
操作系统允许单个进程或线程同时监视多个文件描述符的一种技术。
当其中的一个或多个文件状态变为非阻塞状态(例如: 文件由阻塞态, 变得可读、可写或有异常待处理)时,该进程或线程会收到一个对应通知。
而我们的逻辑中收到这个通知, 就可以根据对应变得可读的文件描述符处理是读取标准输入, 还是接收对端数据, 还是都处理。
这样, 就允许程序同时处理多个文件就绪, 或者称为谁就绪就处理谁,而不是只能按照固定处理顺序处理每一个任务,从而提高效率。
select函数
select是实现IO多路复用的一种方式。(其他的还有poll, epoll)
select的最基本的原理, 就是把要监视的文件描述符, 构建一个文件描述符监听集合。这个集合交给select, select促使操作系统内核, 通过轮询的方式监听这个文件描述符集合。直到监听集合中, 至少有一个文件按照条件就绪(条件:预设的监听是读就绪OR写就绪...), 这一次的select监听宣告结束, 并携带就绪的文件描述符集合返回, 继续执行用户书写的代码逻辑。
select是一个在Unix系统中就已经出现了的, 传统的IO多路复用接口。(man select)
#include <sys/select.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
// synchronous I/O multiplexing
// 同步 I/O 多路复用
int select(
int nfds, // 被监听文件描述符集合最大的文件描述符+1 (最大的文件描述符+1)
fd_set *readfds, // 要监听的: 读操作文件描述符集合
fd_set *writefds, // 要监听的: 写操作文件描述符集合
fd_set *exceptfds, // 要监听的: 异常操作文件描述符集合
struct timeval *timeout // 监听时候的阻塞时间:NULL代表一直等待直到指定就绪,0代表不等待检查文件描述符立即返回
);
// 返回值: 正数表示就绪的文件描述符数量; 0表示监听超时; -1表示是失败
// 构建监听文件描述符:
void FD_ZERO(fd_set *set); // 初始化文件描述符集合
void FD_SET(int fd, fd_set *set); // 向文件描述符集合添加要监听的文件描述符
void FD_CLR(int fd, fd_set *set); // 从文件描述符集合移除一个文件描述符,不再监听移除项
int FD_ISSET(int fd, fd_set *set); // 判断某个文件描述符, 是否在文件描述符集合中
调用select之后, select会阻塞进程, 去监听设置的文件描述符状态; 直到监听到至少一个文件描述符就绪, select解除阻塞状态, 并携带就绪的文件描述符返回。
监听集合和监听完毕之后携带的就绪集合, 是同一个fd_set存储。(传入传出参数, 非const指针) (意味着在循环中, 每次都要重置监听集合set)
我们可以在select函数中设置指定的时间, 来限制select的阻塞时间。
// (man select )
struct timeval {
long tv_sec; // seconds: 秒
long tv_usec; // microseconds: 微秒 (1秒 = 1000 000微秒)
};
select底层顺序
- 创建监听集合fd_set, 并初始化
- 把要监听的文件描述符加到fd_set集合中
- 调用select开始监听
- select函数, 把处于用户态的监听集合拷贝到内核态空间
- 内核进程根据拷贝到内核态的监听集合, 轮询访问文件描述符对象, 监听状态变化 (轮询范围,根据select的最大文件描述符参数)
- 在一次轮询过程中, 发现有文件状态就绪, 把就绪状态文件描述符放回拷贝到内核态的监听集合中, 并触发select结束阻塞
- 把内核态的存储就绪的文件描述符集合, 拷贝回用户态
- select结束
select的缺陷
// ps: 了解
// 虽然我们通过ulimit -a看到的open files 大小因为是1024, 意味着操作系统的一个进程可以打开的文件对象也是1024, 看上去和select监听最大范围相匹配, 但是进程可以打开的文件对象是可以修改的, 而select监听的最大文件描述符为1024是没办法修改的(要想修改只能重新编译操作系统了)
// 我们可以找到fd_set类型, 进而确定它的监听的最大文件描述符为1024
gcc -E 文件.c -o 文件.i
vim 文件.i
// 查找: fd_set
typedef struct{
__fd_mask __fds_bits[1024 / (8 * (int) sizeof (__fd_mask))];
} fd_set;
- 监听集合和就绪集合, 需要反复从内核态空间和用户态空间来回拷贝(再需要循环监听的时候: 还需要反复设置监听集合)
- 监听和就绪不分离, 每次需要充值监听集合
- 不适合海量监听, 少量就绪的情况 (需要遍历每个被监听的文件描述符, 确定是否就绪)
select监听的最大文件描述符为1024 (靠位图实现)
UserA:
int main(int argc,char*argv[]){
int fd_write = open("1.pipe", O_WRONLY);
int fd_read = open("2.pipe", O_RDONLY);
char buf[60];
// 监听集合
fd_set set;
while(1){
// 初始化集合
FD_ZERO(&set);
// 添加要监听的文件描述符
FD_SET(STDIN_FILENO, &set);
FD_SET(fd_read, &set);
struct timeval time_val;
time_val.tv_sec = 10;
time_val.tv_usec = 0;
// 调用select: 监听就绪
int res_select = select(10, &set, NULL,NULL, &time_val);
// 打印剩余时间
printf("tv_sec: %ld \n", time_val.tv_sec);
if(FD_ISSET(fd_read, &set)){
bzero(buf, sizeof(buf));
int read_num = read(fd_read, buf, sizeof(buf));
if(read_num == 0){
printf("对方断开链接 \n");
break;
}
printf("UserA: %s", buf);
}
if(FD_ISSET(STDIN_FILENO, &set)){
bzero(buf, sizeof(buf));
int read_stdin = read(STDIN_FILENO, buf, sizeof(buf));
if(read_stdin == 0){
// 用户按下ctrl+d; 输入文件终止符; 终止标准输入; read返回0
break;
}
write(fd_write, buf, sizeof(buf));
}
}
close(fd_write);
close(fd_read);
return 0;
}
UserB:
当UserA用户10秒未发生信息, UserB关闭连接。
int main(int argc,char*argv[]){
int fd_read = open("1.pipe", O_RDONLY);
int fd_write = open("2.pipe", O_WRONLY);
char buf[60];
fd_set set;
struct timeval time_val;
time_val.tv_sec = 10;
time_val.tv_usec = 0;
while(1){
FD_ZERO(&set);
FD_SET(STDIN_FILENO, &set);
FD_SET(fd_read, &set);
int res_select = select(10, &set, NULL, NULL, &time_val);
if(FD_ISSET(fd_read, &set)){
bzero(buf, sizeof(buf));
int read_num = read(fd_read, buf, sizeof(buf));
if(read_num == 0){
printf("对方断开链接 \n");
break;
}
printf("UserA: %s", buf);
time_val.tv_sec = 10;
time_val.tv_usec = 0;
}else{
if(time_val.tv_sec <= 0){
printf("对方十秒未说话 \n");
break;
}
}
if(FD_ISSET(STDIN_FILENO, &set)){
bzero(buf, sizeof(buf));
int read_stdin = read(STDIN_FILENO, buf, sizeof(buf));
if(read_stdin == 0){
// 用户按下ctrl+d; 输入文件终止符; 终止标准输入; read返回0
break;
}
write(fd_write, buf, sizeof(buf));
}
}
close(fd_write);
close(fd_read);
return 0;
}
匿名管道
匿名管道/pipe函数是Linux系统中用于实现父子进程间通信的一种简单方式。 (man pipe)
- 管道是单向的,数据从一端流入,从另一端流出,因此它们是半双工的。(这就意味着: 使用匿名管道,一个进程将数据写入管道pipe[1],而另一个进程则可以从管道读取数据pipe[0])
- 匿名管道只使用于存在亲缘关系的进程之间进行通信(Eg: 父子进程)。
- 先在一个进程中创建一个管道,然后再利用fork, 可以让父子进程同时持有管道, 就可以实现进程间通信了。(单个进程的管道的是没有什么价值的)
- 如果要实现父子进程之间全双工通信,需要调用pipe函数两次来创建两条管道。而且, fork的次数和管道的数量无关,每一次使用 pipe函数就会在内核创建一个管道缓冲区。
此函数的声明如下:
#include <unistd.h>
// create pipe
int pipe(
int pipefd[2]//包含两个文件描述符的整型数组。pipefd[0]读取端文件描述符,pipefd[1]写端文件描述符。
);
// 返回值: 成功0, 失败-1
实现原理图如下图所示:
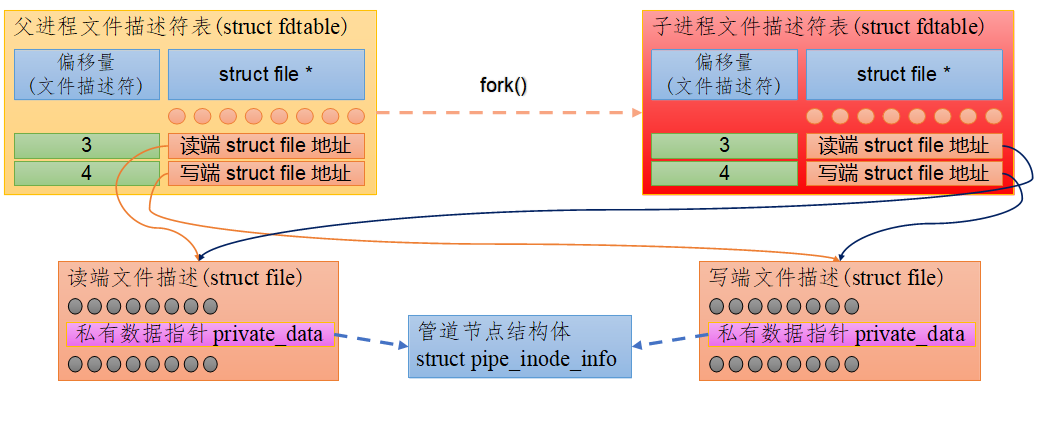
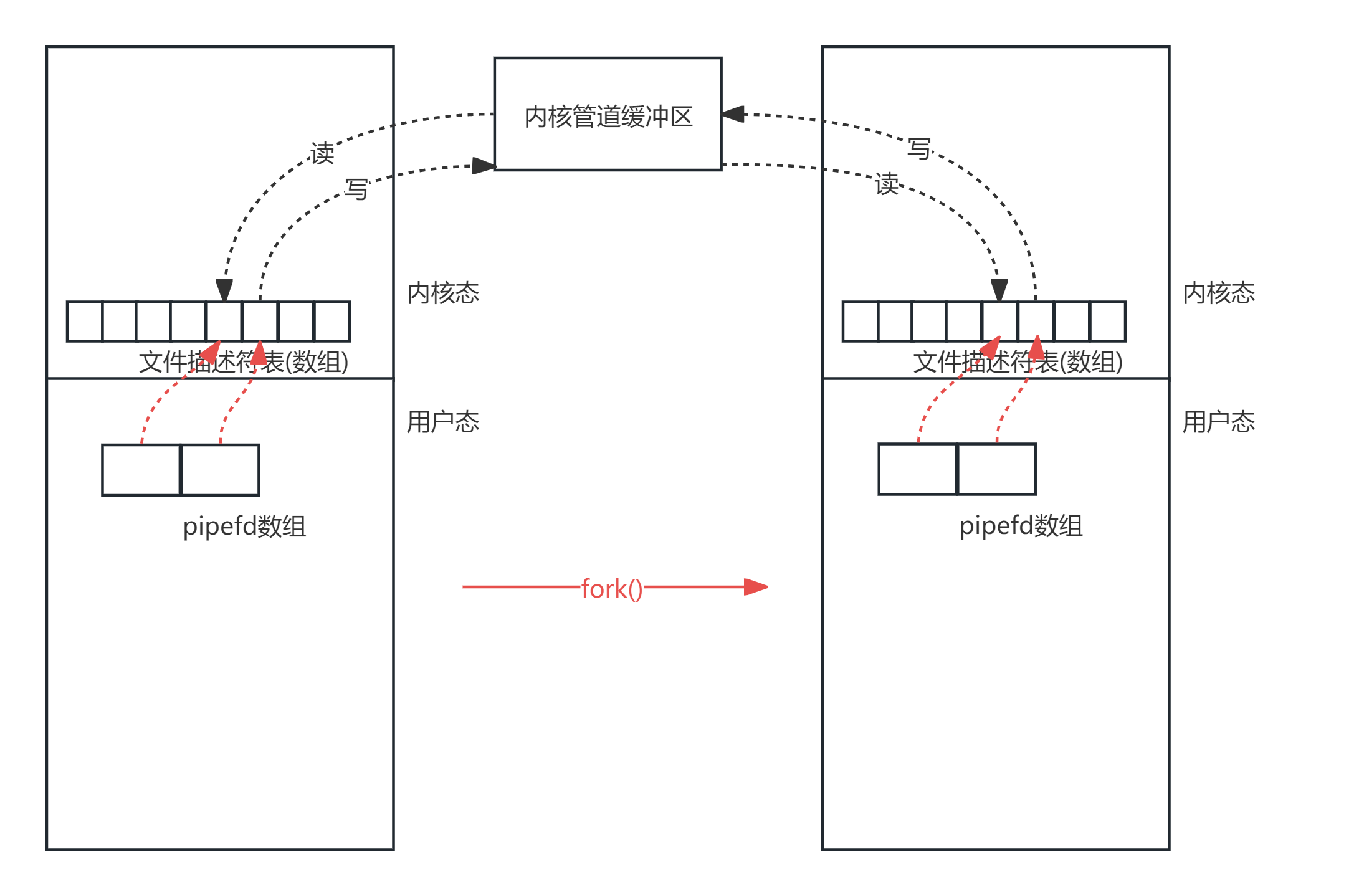
#include <unistd.h> // 提供 pipe(), fork(), read(), write(), close() 等系统调用
#include <stdio.h> // 提供 printf() 函数
#include <sys/wait.h> // 提供 wait() 函数
int main(int argc, char* argv[]) {
// 1. 创建管道
int pipefd[2]; // pipefd[0]是读端,pipefd[1]是写端
pipe(pipefd); // 创建无名管道,成功返回0,失败返回-1
// 2. 创建子进程
if (fork() == 0) { // 子进程进入该分支(fork返回0)
// 子进程:负责从管道读取数据
close(pipefd[1]); // 关闭写端(子进程只需要读)
char buf[5]; // 定义缓冲区
read(pipefd[0], buf, 5); // 从管道读取5字节数据(阻塞直到有数据)
printf("child get message: %s \n", buf); // 打印读取的数据
} else { // 父进程进入该分支(fork返回子进程PID)
// 父进程:负责向管道写入数据
close(pipefd[0]); // 关闭读端(父进程只需要写)
write(pipefd[1], "hello", 5); // 向管道写入5字节数据("hello")
wait(NULL); // 等待子进程结束(避免僵尸进程)
}
return 0; // 父子进程都会执行(但子进程在printf后已退出)
}

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









