






目录
摘要
本周我阅读了一篇题目为Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations的论文,文章中主要解决了两个问题,即数据驱动解决方案和偏微分方程的数据驱动发现。第一个问题是偏微分方程的解,在给定参数λ,求系统解,第二个问题是已知系统
,求λ能描述观察数据。其次,跑了一下论文中的NS方程,对其两个偏微分方程公式进行了更进一步的理解。
ABSTRACT
This week I read a paper titled “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations”. The paper mainly solves two problems, namely data-driven solutions and data-driven discovery of partial differential equations. The first problem is the solution of partial differential equations, which is to find the system solution given the parameter λ. The second problem is to describe the observed data by knowing the system and finding λ. Secondly, I ran the NS equation in the paper and further understood the two partial differential equation formulas.
一、文献阅读
一、题目
1、题目:Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
2、期刊会议:Journal of Computational Physics
3、论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0021999118307125
二、摘要
作者在本篇文章中引入了基于物理的神经网络(即经过训练来解决监督学习任务的神经网络),作者设计了两种不同类型的算法,即连续时间模型和离散时间模型,连续时间模型形成了新的数据高效时空函数逼近器,离散时间模型允许使用具有无限数量级的Runge–Kutta时间步进方案。
In this article, the author introduces physics-based neural networks, which are neural networks trained to solve supervised learning tasks. The author designs two different types of algorithms: continuous-time models and discrete-time models. The continuous-time models create a novel data-efficient spatiotemporal function approximator, while the discrete-time models allow the use of Runge-Kutta time-stepping schemes with an infinite number of levels.
三、Introduction
在分析复杂的物理、生物或工程系统时,数据采集成本通常不可承受,我们不可避免地面临在部分信息下得出结论和做出决策的挑战。在这小数据范畴中,大多数先进的机器学习技术(如深度/卷积/循环神经网络)缺乏鲁棒性,未提供任何收敛保证。本篇论文采用深度神经网络并利用其作为通用函数逼近器的能力,利用这种方法,研究者直接处理非线性问题,通过利用自动微分技术,对神经网络进行微分,文章引入了偏微分方程的新类数值解算器,以及用于模型反演和系统识别的新的数据驱动方法,文章分为两部分:数据驱动解决方案和偏微分方程的数据驱动发现。第一个问题是偏微分方程的解,在给定参数λ,求系统解,第二个问题是已知系统
,求λ能描述观察数据。
四、模型
一、连续时间模型

对于上述两个损失函数:
第一项趋于0,说明神经网络,能很好求出PDE的解,很好拟合了微分方程;第二项趋于0,说明训练集上每个点都有
创新
所有之前内嵌物理知识的机器学习算法,例如支持向量机,随机森林,高斯过程以及前馈/卷积/递归神经网络,仅作为黑盒工具。这里是通过重新修改针对基础微分算子“自定义”激活和损失函数来进一步研究。本文通过将其导数相对于其输入坐标(即空间和时间)取导数,从而将物理信息嵌入神经网络,期中物理由偏微分方程描述。
薛定谔方程

求解:使用五层神经网络,每层有100个神经元,激活函数为tanh函数,来估计the latent function
结果如下:
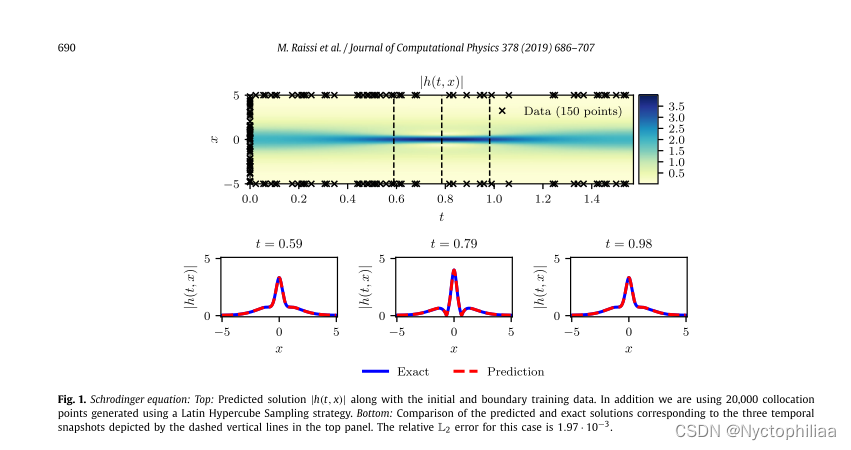
图1的顶部面板显示了预测的时空解的幅度以及初始和边界训练数据的位置。该问题的预测误差针对测试数据进行了验证,底部的图显示了我们在不同的时间瞬间t = 0.59、0.79、0.98处呈现了精确解和预测解之间的比较。仅使用少量初始数据,物理信息神经网络可以准确地捕捉薛定谔方程的复杂非线性行为。
二、离散时间模型

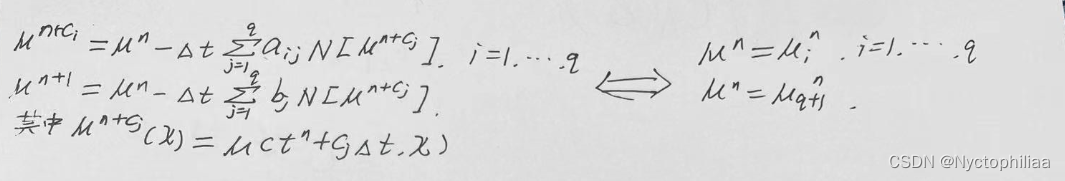

结果如下:
 Burger’s equation 连续模型
Burger’s equation 连续模型
对比了取值与error关系,参与训练数据越多,得到的误差越小。(但是,训练数据相比于常见网络训练已经很少了)。同时也对比了不同网络层和神经元数目对error影响,网络越复杂相对来说还是error小一些的。

Burger’s equation 离散模型
影响离散模型算法的关键参数是q,,测试了训练样本与error关系,训练样本越多,error越小。

五、结论
这篇论文的结论指出了一种新的方法,即基于物理的神经网络,它是一类通用的函数逼近器。这种网络能够编码和控制给定数据集中的潜在物理定律,并使用偏微分方程来描述这些定律。在这项工作中,研究人员设计了数据驱动的算法,用于推断一般非线性偏微分方程的解,并构建了计算效率高的物理信息代理模型。这一方法为计算科学中的各种问题提供了有前途的结果,并为深度学习赋予了强大的数学物理能力,使其能够模拟我们周围的世界。
二、实验代码
Navier–Stokes equation

1、定义class PhysicsInformedNN
Initialize the class:
def __init__(self, x, y, t, u, v, layers):
# 将输入的 x, y, t 沿第二个轴(axis=1)拼接成一个矩阵 X。
X = np.concatenate([x, y, t], 1)
# 计算矩阵 X 沿第 0 轴的最小值,得到一个包含每列最小值的向量,用于归一化。
self.lb = X.min(0)
# 计算矩阵 X 沿第 0 轴的最大值,得到一个包含每列最大值的向量,用于归一化。
self.ub = X.max(0)
# 将拼接后的矩阵 X 赋值给类属性 self.X。
self.X = X
# 从矩阵 X 中取出第一列,得到列向量 self.x。
self.x = X[:,0:1]
# 从矩阵 X 中取出第二列,得到列向量 self.y。
self.y = X[:,1:2]
# 从矩阵 X 中取出第三列,得到列向量 self.z。
self.t = X[:,2:3]
# 将输入的u和v赋值给类属性self.u和self.v
self.u = u
self.v = v
# 将输入的layers给到self.layers
self.layers = layers
# Initialize NN
# 用 initialize_NN 方法初始化神经网络的权重和偏置,并将结果赋值给类属性 self.weights 和 self.biases。
self.weights, self.biases = self.initialize_NN(layers)
# Initialize parameters
# 创建 TensorFlow 变量 lambda_1和2,初始化为0.0。
self.lambda_1 = tf.Variable([0.0], dtype=tf.float32)
self.lambda_2 = tf.Variable([0.0], dtype=tf.float32)
# tf placeholders and graph
# 创建 TensorFlow 会话 sess,配置允许软放置和设备日志。
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
# 创建 TensorFlow 占位符 ,用于输入 x,y,t,u,v 的数据。
self.x_tf = tf.placeholder(tf.float32, shape=[None, self.x.shape[1]])
self.y_tf = tf.placeholder(tf.float32, shape=[None, self.y.shape[1]])
self.t_tf = tf.placeholder(tf.float32, shape=[None, self.t.shape[1]])
self.u_tf = tf.placeholder(tf.float32, shape=[None, self.u.shape[1]])
self.v_tf = tf.placeholder(tf.float32, shape=[None, self.v.shape[1]])
# 调用 net_NS 方法,得到神经网络的预测值和方程残差。
self.u_pred, self.v_pred, self.p_pred, self.f_u_pred, self.f_v_pred = self.net_NS(self.x_tf, self.y_tf, self.t_tf)
# 计算损失函数,包括速度场预测误差、方程残差等。
self.loss = tf.reduce_sum(tf.square(self.u_tf - self.u_pred)) + \
tf.reduce_sum(tf.square(self.v_tf - self.v_pred)) + \
tf.reduce_sum(tf.square(self.f_u_pred)) + \
tf.reduce_sum(tf.square(self.f_v_pred))
#创建 L-BFGS-B 优化器,用于最小化损失函数。
self.optimizer = tf.contrib.opt.ScipyOptimizerInterface(self.loss,
method = 'L-BFGS-B',
options = {'maxiter': 50000,
'maxfun': 50000,
'maxcor': 50,
'maxls': 50,
'ftol' : 1.0 * np.finfo(float).eps})
# 创建 Adam 优化器
self.optimizer_Adam = tf.train.AdamOptimizer()
# 使用 Adam 优化器最小化损失函数
self.train_op_Adam = self.optimizer_Adam.minimize(self.loss)
# 创建 TensorFlow 初始化操作
init = tf.global_variables_initializer()
self.sess.run(init)2、 该方法通过 Xavier 初始化方法初始化权重,而偏置初始化为零向量。
def initialize_NN(self, layers):
weights = []
biases = []
num_layers = len(layers)
for l in range(0,num_layers-1):
W = self.xavier_init(size=[layers[l], layers[l+1]])
b = tf.Variable(tf.zeros([1,layers[l+1]], dtype=tf.float32), dtype=tf.float32)
weights.append(W)
biases.append(b)
return weights, biases3、通过使用 Xavier 初始化,该方法旨在为神经网络的权重提供合适的初始值,有助于提高训练效果。
def xavier_init(self, size):
# 获取输入维度,即权重矩阵的行数。
in_dim = size[0]
# 获取输出维度,即权重矩阵的列数。
out_dim = size[1]
# 计算 Xavier 初始化中使用的标准差。Xavier 初始化的标准差通常取决于输入和输出维度,
xavier_stddev = np.sqrt(2/(in_dim + out_dim))
return tf.Variable(tf.compat.v1.random.truncated_normal([in_dim, out_dim], stddev=xavier_stddev), dtype=tf.float32)
# 定义了一个类方法 neural_net,用于进行神经网络的前向传播。
# 接受输入 X、权重 weights 和偏置 biases 作为参数。4、 定义了一个类方法 neural_net,用于进行神经网络的前向传播。
def neural_net(self, X, weights, biases):
num_layers = len(weights) + 1
# 对输入 X 进行归一化,将其映射到范围 [-1, 1]。这里使用线性变换将输入特征归一化。
H = 2.0*(X - self.lb)/(self.ub - self.lb) - 1.0
for l in range(0,num_layers-2):
W = weights[l]
b = biases[l]
H = tf.tanh(tf.add(tf.matmul(H, W), b))
W = weights[-1]
b = biases[-1]
# 计算神经网络的输出,即最后一层隐藏层的输出乘以输出层的权重加上输出层的偏置。
Y = tf.add(tf.matmul(H, W), b)
return Y5、定义NS方程
def net_NS(self, x, y, t):
# 接受三个输入变量 x、y、t,分别表示空间坐标(二维平面上的 x 和 y)和时间坐标。
# 从模型的实例中获取两个超参数 lambda_1 和 lambda_2。
lambda_1 = self.lambda_1
lambda_2 = self.lambda_2
# 将输入 x、y、t 连接成一个输入向量,传递给神经网络模型 neural_net,得到包含流函数 psi 和压力 p 的输出。
psi_and_p = self.neural_net(tf.concat([x,y,t], 1), self.weights, self.biases)
psi = psi_and_p[:,0:1]
p = psi_and_p[:,1:2]
# 通过对流函数求关于空间坐标 y 的梯度得到水平方向速度 u。
# 通过对流函数求关于空间坐标 x 的梯度得到垂直方向速度 v。
u = tf.gradients(psi, y)[0]
v = -tf.gradients(psi, x)[0]
u_t = tf.gradients(u, t)[0]
u_x = tf.gradients(u, x)[0]
u_y = tf.gradients(u, y)[0]
u_xx = tf.gradients(u_x, x)[0]
u_yy = tf.gradients(u_y, y)[0]
v_t = tf.gradients(v, t)[0]
v_x = tf.gradients(v, x)[0]
v_y = tf.gradients(v, y)[0]
v_xx = tf.gradients(v_x, x)[0]
v_yy = tf.gradients(v_y, y)[0]
# 对流函数 psi 和压力 p 关于空间坐标 x 和 y 求梯度,得到压力梯度 p_x 和 p_y。
p_x = tf.gradients(p, x)[0]
p_y = tf.gradients(p, y)[0]
# 类似地,计算速度场 v 关于时间 t 的导数 v_t,以及关于空间坐标 x 和 y 的一阶和二阶导数。
f_u = u_t + lambda_1*(u*u_x + v*u_y) + p_x - lambda_2*(u_xx + u_yy)
f_v = v_t + lambda_1*(u*v_x + v*v_y) + p_y - lambda_2*(v_xx + v_yy)
return u, v, p, f_u, f_v6、定义打印输出函数
def callback(self, loss, lambda_1, lambda_2):
print('Loss: %.3e, l1: %.3f, l2: %.5f' % (loss, lambda_1, lambda_2))7、train
def train(self, nIter):
tf_dict = {self.x_tf: self.x, self.y_tf: self.y, self.t_tf: self.t,
self.u_tf: self.u, self.v_tf: self.v}
start_time = time.time()
for it in range(nIter):
self.sess.run(self.train_op_Adam, tf_dict)
# Print
if it % 10 == 0:
elapsed = time.time() - start_time
loss_value = self.sess.run(self.loss, tf_dict)
lambda_1_value = self.sess.run(self.lambda_1)
lambda_2_value = self.sess.run(self.lambda_2)
print('It: %d, Loss: %.3e, l1: %.3f, l2: %.5f, Time: %.2f' %
(it, loss_value, lambda_1_value, lambda_2_value, elapsed))
start_time = time.time()
self.optimizer.minimize(self.sess,
feed_dict = tf_dict,
fetches = [self.loss, self.lambda_1, self.lambda_2],
loss_callback = self.callback)8、predict
def predict(self, x_star, y_star, t_star):
tf_dict = {self.x_tf: x_star, self.y_tf: y_star, self.t_tf: t_star}
u_star = self.sess.run(self.u_pred, tf_dict)
v_star = self.sess.run(self.v_pred, tf_dict)
p_star = self.sess.run(self.p_pred, tf_dict)
return u_star, v_star, p_star9、绘图函数
def plot_solution(X_star, u_star, index):
lb = X_star.min(0)
ub = X_star.max(0)
nn = 200
x = np.linspace(lb[0], ub[0], nn)
y = np.linspace(lb[1], ub[1], nn)
X, Y = np.meshgrid(x,y)
U_star = griddata(X_star, u_star.flatten(), (X, Y), method='cubic')
plt.figure(index)
plt.pcolor(X,Y,U_star, cmap = 'jet')
plt.colorbar()10、调整3D坐标轴,使其在三个维度上具有相同的比例,从而保持数据的等比例缩放
def axisEqual3D(ax):
extents = np.array([getattr(ax, 'get_{}lim'.format(dim))() for dim in 'xyz'])
sz = extents[:,1] - extents[:,0]
centers = np.mean(extents, axis=1)
maxsize = max(abs(sz))
r = maxsize/4
for ctr, dim in zip(centers, 'xyz'):
getattr(ax, 'set_{}lim'.format(dim))(ctr - r, ctr + r)总结
深度学习神经网络求解偏微分方程可以大幅度提高效率,比传统的偏微分方程求解器更快地求出近似解。目前该方向主要分为 3 大类:数据驱动、物理约束、物理驱动。下周继续学习PINN的内容,多了解一些偏微分方程,补一些知识。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









