






目录
文献阅读:一种用于室内空气质量预测的新型变分自编码器深度学习框架
摘要
本周我阅读的文献《A novel deep learning framework with variational auto-encoder for indoor air quality prediction》中提出了一种新颖的深度学习框架——PLS-VAER,专门用于室内空气质量预测,特别是针对PM2.5浓度的建模。该框架创新性地融合了偏最小二乘分析(PLS)与变分自编码器(VAE)的技术,旨在提升预测精度和泛化能力。其中PLS被用来对原始数据进行分解,捕捉复杂的非线性特征,而VAE通过变分推理进一步增强了预测性能。模型结构包含四个密集层的编码器和解码器,利用批量归一化和丢弃策略优化训练过程,有效防止过拟合。实验结果显示,当采用7个潜变量(LVs)时,PLS-VAER模型达到最优预测效果。
Abstract
The literature I read this week titled "A novel deep learning framework with variant autoencoder for indoor air quality prediction" proposes a novel deep learning framework - PLS-VAER, specifically designed for indoor air quality prediction, particularly for modeling PM2.5 concentration. This framework innovatively integrates the techniques of partial least squares analysis (PLS) and variational autoencoder (VAE), aiming to improve prediction accuracy and generalization ability. PLS is used to decompose raw data and capture complex nonlinear features, while VAE further enhances predictive performance through variational inference. The model structure consists of four dense layers of encoders and decoders, and the training process is optimized using batch normalization and dropout strategies to effectively prevent overfitting. The experimental results show that when using 7 latent variables (LVs), The PLS-VAER model achieves optimal prediction performance.
文献阅读:一种用于室内空气质量预测的新型变分自编码器深度学习框架
A novel deep learning framework with variational auto- encoder for indoor air quality prediction
2024
现有问题
室内空气质量的劣化对人类健康构成严重威胁,直接关联到疾病发生率和死亡率的增加。传统监测方法在应对室内环境中的微粒物(如PM2.5)浓度变化时,往往因数据的高维度、非线性和动态特性而面临挑战。此外,噪声干扰和数据缺失问题也是影响预测准确性的关键因素。
提出方法
为了解决上述问题,提出了一种创新的深度学习框架——PLS-VAER(偏最小二乘-变分自动编码器回归器),该框架结合了偏最小二乘法(PLS)的特征提取能力和变分自编码器(VAE)的非线性建模能力,通过变分推理改进预测性能,利用深度学习技术提升室内空气质量预测的精确度和稳定性。
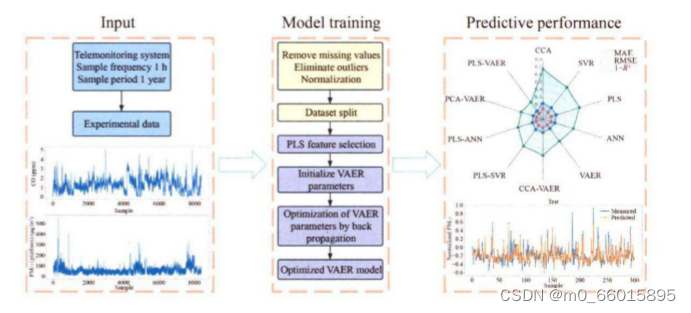
创新点:
- 首次将PLS与VAE相结合,利用PLS降维处理数据,有效去除噪声并提取关键信息,再输入到VAE中,提升了模型对非线性特征的学习能力。
- PLS-VAER模型能够更好地处理室内空气质量数据的非线性、多维和时间变化特性,尤其是在地铁等封闭且人流量大的环境中。
- 提供了处理高维、非线性问题的新思路,展示了在环境科学工程领域中结合统计学方法与深度学习技术的潜力,为室内空气质量监测和改善提供了一种新颖且环境友好的方法。
方法论
1、偏最小二乘(PLS)
偏最小二乘是一种多元统计分析方法,主要用于数据的降维和回归分析。它旨在同时考虑预测变量(自变量)和响应变量(因变量)的结构,通过找到一组低维的潜变量(latent variables)来最大化两者的协方差。PLS通过构建预测变量和响应变量的正交得分(scores)来实现这一点,这些得分能够反映变量的主要变异方向。PLS通过建立独立变量与因变量间的协方差结构模型,有效提取重要特征并减少噪声干扰。它适用于高维数据降维,能处理变量间高度相关性问题,优化数据结构以利于后续分析。PLS过程包括以下几个步骤:
- 数据标准化:首先对预测变量和响应变量分别进行中心化或标准化处理,以消除量纲影响。
- 构造潜变量:寻找第一个潜变量,使得预测变量和响应变量的得分之间的协方差最大。这通常通过迭代计算得到。
- 迭代更新:重复上述过程,每次迭代都构造一个新的潜变量,同时保证新潜变量与已有的潜变量正交(即不相关)。每增加一个潜变量,就相当于在原有的基础上增加一个维度来解释更多的方差。
- 停止准则:当达到预设的潜变量数目或者解释方差达到某一阈值时,迭代停止。
2、变分自动编码器(VAE)
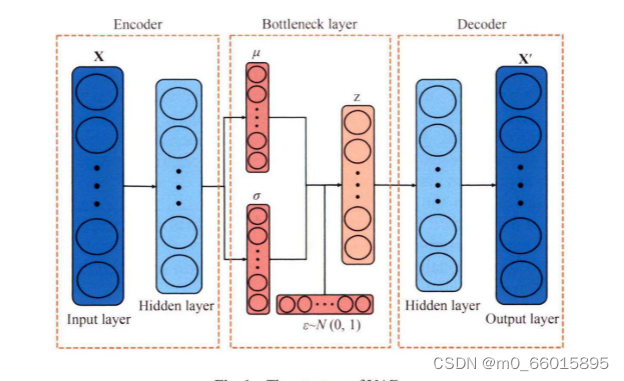
变分自动编码器是一种基于概率生成模型的无监督学习方法,它结合了自动编码器的结构和贝叶斯推断技术。VAE旨在学习数据的有效低维表示(编码),同时能够从这个表示中生成类似原始数据的新样本。VAE通过引入隐变量Z(latent variable),并假设Z服从某种先验分布(如高斯分布),利用变分推断来近似后验分布。 VAE由编码器和解码器两部分组成:
- 编码器:负责将输入数据映射到隐变量Z的概率分布参数(均值μ和方差σ),通常表示为q(Z|X)。
- 解码器:接收隐变量Z,生成重构数据的分布p(X|Z),目标是使重构数据尽可能接近原数据。
- 损失函数:VAE的训练目标是最大化后验分布与先验分布的相似性,通过最小化重构损失(数据与重构数据的差异)和KL散度(后验分布与先验分布的差异)之和。
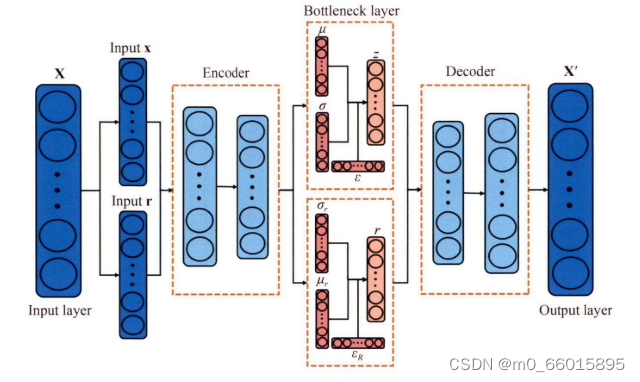
3、变分自动编码器回归器(VAER)
VAER是在VAE的基础上发展起来的一种回归模型,旨在通过学习输入数据的潜在表示来进行连续值的预测。它利用VAE的编码器学习输入数据的潜在表示,然后在这些表示上进行回归预测,而不是直接在原始数据上。
- 特征提取:与标准VAE相同,首先使用编码器从输入数据中提取低维的潜在表示Z。
- 回归预测:与标准VAE不同之处在于,VAER在潜在表示Z上添加一个回归头(额外的网络层或子网络),用来预测目标连续变量Y的值。这要求在训练过程中同时考虑VAE的重构损失和回归预测的损失。
- 损失函数:VAER的损失函数除了包含VAE的重构损失和KL散度外,还会加入一个回归损失项,如均方误差(MSE)或均方根误差(RMSE),来衡量预测值与真实值的差距。
所提出的方法(PLS-VAER)
所提出的PLS-VAER(偏最小二乘变分自编码器回归)方法,旨在通过结合偏最小二乘(PLS)的数据降维能力和变分自编码器(VAE)的非线性表达能力,来提高室内空气质量预测的准确性和稳定性,特别是针对PM2.5浓度的预测。该模型的理论基础建立在两个主要部分之上:数据预处理的PLS和特征学习的VAE。
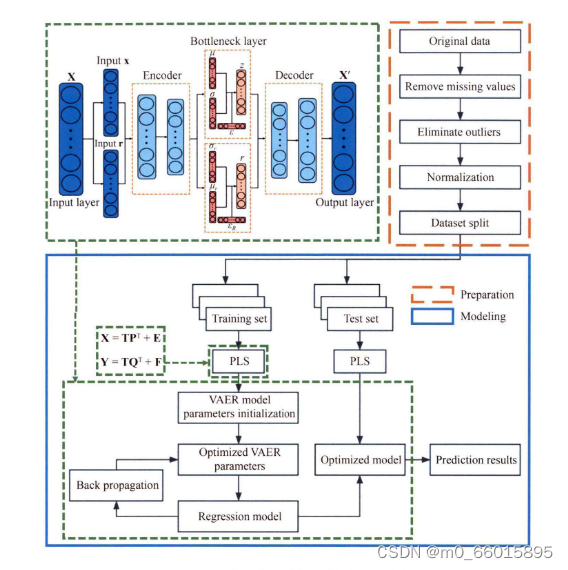
PLS部分:
- PLS算法通过构建预测变量(X)和响应变量(y)的低维线性组合(即潜变量LVs),最大化它们之间的协方差,从而实现对数据的有效降维。这一过程不仅考虑了预测变量内部的结构,也考虑了预测变量与响应变量间的相互关系,非常适合于存在多重共线性的复杂数据集。
- 在PLS-VAER模型中,首先应用PLS处理原始数据,提取出关键的潜变量,这个步骤有助于去除数据中的噪声并提炼出与目标变量(如PM2.5浓度)相关的有效信息。
VAE部分:
- VAE是一个生成模型,它通过学习数据的潜在分布(隐空间),能够生成新的样本并进行有效的特征表示。VAE由编码器和解码器组成,编码器将输入数据映射到潜在空间,解码器则将潜在变量解码回数据空间。这一映射过程伴随着变分推断,其中引入了KL散度来衡量潜在空间分布与先验分布的差异。
- 在PLS-VAER模型中,经过PLS处理后的潜变量作为VAE的输入,编码器进一步将这些潜变量映射到一个更紧凑且具有明确概率解释的隐空间,解码器则试图从这个隐空间重构原始数据。
研究实验
1、数据集
本研究使用的数据集源自首尔地铁站2009年2月至2010年1月的室内空气质量监测记录,采样间隔为1小时。数据集覆盖了氮氧化物(NO)、一氧化碳(CO)、二氧化氮(NO2)、二氧化碳(CO2)、温度、湿度、PM10、PM2.5等环境变量,分为大厅和站台两个不同区域的测量值。整个数据集包含了8580个样本,每个样本含10个变量。数据预处理包括移除缺失值、异常值检测(采用Jolliffe方法)和基于Z-score的标准化处理。经过预处理,最终有8409个有效样本被保留,其中5591个样本用于训练,剩余的2818个样本用于测试。
2、评估指标
评估模型性能主要依据三个指标:平均绝对误差(MAE)、均方根误差(RMSE)和确定系数(R²)。公式如下:
- MAE = Σ|yi - ŷi| / N
- RMSE = sqrt(Σ(yi - ŷi)² / N)
- R² = 1 - Σ(yi - ŷi)² / Σ(yi - y)²
其中,yi为真实值,ŷi为预测值,y为真实值的均值,N为样本数。
3、实验过程
实验过程中,首先对PLS-VAER模型进行了详细的参数配置,包括中间层维度设为28,潜在维度设为5,以及编码器和解码器各含四个全连接层,层内神经元数量分别为160、112、56、28(编码器)和28、56、112、160(解码器)。此外,模型中加入了批量归一化和Dropout层以提升训练效率和泛化能力。
模型训练阶段,采用了梯度下降的反向传播算法进行参数优化,以最小化损失函数,其中包括了重构损失和KL散度损失。
4、实验结果
实验结果显示,PLS-VAER模型在测试集上取得了优异的性能。与单一PLS模型相比,PLS-VAER模型在测试集上的MAE减少了26.09%,RMSE降低了27.27%,R²提升了43.25%。这表明,PLS-VAER模型能更好地处理非线性关系,适合于室内空气质量数据的拟合。
特别地,当采用5个潜在变量时,PLS-VAER模型的测试集性能为MAE=0.098,RMSE=0.150,R²=0.662,表现出良好的预测精度。与VAER模型相比,PLS-VAER模型在测试集上MAE降低了5.43%,RMSE减小了14.71%,R²增长了13.70%,进一步证实了PLS在提取潜在变量方面的优势,对后续模型的预测性能有显著提升。
在对比其他模型(如CCA-VAER、PLS-SVR、PLS-ANN等)时,PLS-VAER同样显示出了更高的预测性能,尤其是在处理时间序列复杂性较高的情况下。虽然R²值较高,但仍有提升空间,未来可通过模型结构优化或引入注意力机制进一步提高预测准确性。
代码实现
- 数据预处理:清洗数据,移除异常值,填充缺失值,对数据进行归一化处理。
- PLS处理:应用PLS算法处理原始数据,选择合适的潜变量数(LVs)以优化模型性能。
- 构建VAE:设计VAE模型,确定中间层、潜在层和神经元数量,加入批量归一化和Dropout层以加速训练和防止过拟合。
- 模型训练:利用PLS提取的潜变量作为输入,训练VAE模型,并通过最小化重构损失和KL散度损失来优化模型参数。
- 预测:在测试集上,使用训练好的PLS-VAER模型对PM2.5浓度进行预测,评估预测性能。
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda, BatchNormalization, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.losses import binary_crossentropy
from tensorflow.keras.optimizers import Adam
import numpy as np
# 定义VAE的超参数
original_dim = 784 # 假设原始数据维度
intermediate_dim = 256
latent_dim = 32
epsilon_std = 1.0
def encoder(input_data, intermediate_dim, latent_dim):
# 编码器
encoded = tf.keras.layers.Dense(intermediate_dim, activation='relu')(input_data)
encoded = tf.keras.layers.BatchNormalization()(encoded) # 批量归一化
encoded = tf.keras.layers.Dropout(0.2)(encoded) # Dropout层防止过拟合
mean = tf.keras.layers.Dense(latent_dim)(encoded)
logvar = tf.keras.layers.Dense(latent_dim)(encoded)
return mean, logvar
def sampling(args):
mean, logvar = args
epsilon = tf.random.normal(shape=tf.shape(logvar))
return mean + tf.exp(0.5 * logvar) * epsilon
def decoder(latent_inputs, original_dim):
# 解码器
decoded = tf.keras.layers.Dense(original_dim, activation='sigmoid')(latent_inputs)
return decoded
# 定义VAE模型
input_data = tf.keras.Input(shape=(input_shape)) # 假定input_shape是PLS处理后数据的形状
mean, logvar = encoder(input_data, intermediate_dim=28, latent_dim=5)
latent_inputs = sampling((mean, logvar))
decoded = decoder(latent_inputs, original_dim=input_shape[-1])
# 构建模型
inputs = Input(shape=(original_dim,))
z_mean, z_log_var = encoder(inputs)
z = Lambda(sampling)([z_mean, z_log_var])
outputs = decoder(z)
vae = tf.keras.Model(input_data, decoded)
#定义损失函数和优化器:VAE的损失函数由重构损失和KL散度两部分组成。
reconstruction_loss = tf.keras.losses.binary_crossentropy(inputs, decoded)
reconstruction_loss *= original_dim
kl_loss = 1 + logvar - tf.square(mean) - tf.exp(logvar)
kl_loss = tf.reduce_mean(kl_loss)
kl_loss *= -0.5
total_loss = reconstruction_loss + kl_loss
vae.compile(optimizer='adam', loss=total_loss)数据预处理与PLS特征提取
scaler = StandardScaler()
# 假设原始数据为data
scaled_data = scaler.fit_transform(data)
pls = PLSRegression(n_components=7)
pls.fit(X=scaled_data, Y=target_variable) # 目标变量Y需替换为实际目标
pls_processed_data = pls.transform(scaled_data)
# 使用处理后的数据训练VAE
vae.fit(pls_processed_data, pls_processed_data, epochs=epochs, batch_size=batch_size)总结
PLS-VAER模型,通过将PLS与VAE技术相结合,为室内空气污染物预测问题提供了一个强有力的解决方案。该模型通过PLS处理原始数据,有效提取关键信息并减少噪音,随后利用VAE对这些特征进行进一步的非线性表达和潜在变量学习。实验验证了模型的有效性,特别是在合理选择LVs数量时,模型的预测性能达到最优,超越了单一VAE模型及其它传统方法。模型的设计和实施过程,包括数据预处理、模型架构的选择、超参数设置以及训练策略,为解决环境监测领域的复杂预测问题提供了一种新途径。该研究不仅在理论上丰富了室内空气质量预测的技术手段,也为实际应用提供了具有实际操作价值的模型框架。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









