







目录
▷ 初次启动集群需要对主节点进行格式化,指令为:hdfs namenode -format
执行格式化指令后,出现successfully formatted信息表示格式化成功:
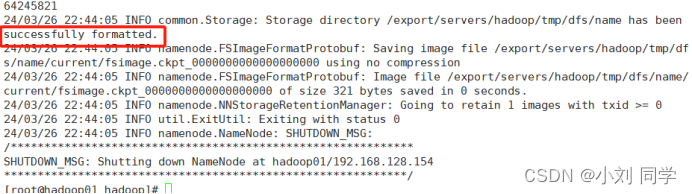
//格式化只需要在Hadoop集群第一次启动前执行即可,后续启动集群不再需要格式化。
单节点逐个启动
1.在主节点上使用以下指令启动HDFS NamaNode进程:
hadoop-daemon.sh start namenode
2.在每个从节点上使用以下指令启动HDFS DataNode进程:
hadoop-daemon.sh start datanode
3.在主节点上使用以下指令启动YARN Resource Manager进程:
yarn-daemon.sh start resourcemanager
4.在每个从节点上使用以下指令启动YARN nodemanager进程:
yarn-daemon.sh start nodenameger
5.在从节点hadoop02使用以下指令启动SecondaryName Node进程:
hadoop-daemon.sh start secondarynamenode
脚本一键启动
使用脚本一键启动集群需要配置slaves配置文件和SSH免密登录hadoop01、hadoop02、hadoop03三台节点(视自身情况而定),为了在任意一台节点上执行脚本一键启动Hadoop服务,需要在三台虚拟机包括自身节点均配置SSH双向免密登录。
1)在主节点hadoop01上使用以下指令启动所有HDFS(分布式文件系统)服务进程:
start-dfs.sh

2) 在主节点hadoop01上使用以下指令启动所有YARN服务进程:
start-yarn.sh

自定义脚本启动
将脚本放在/usr/bin目录下,创建脚本文件:hadoop.sh
添加脚本内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop01 "/export/servers/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop01 "/export/servers/hadoop/sbin/start-yarn.sh"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 yarn ---------------"
ssh hadoop01 "/export/servers/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop01 "/export/servers/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac文件创建好后要给文件执行的权限:chmod +x hadoop.sh / chmod 777 hadoop.sh
启动集群:hadoop.sh start / 关闭集群:hadoop.sh stop
在任意目录下都可以执行脚本文件
效果如图所示:
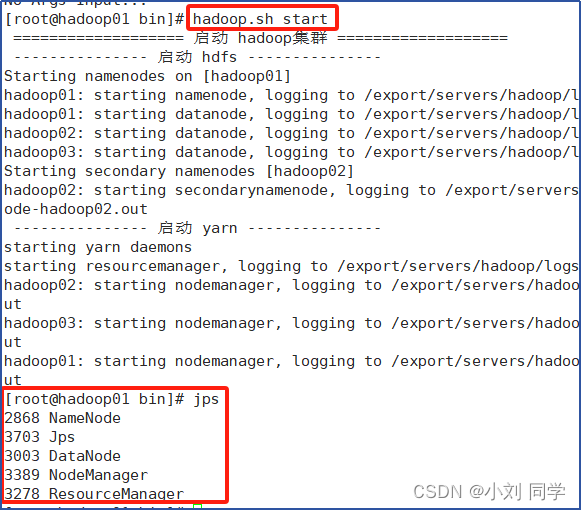
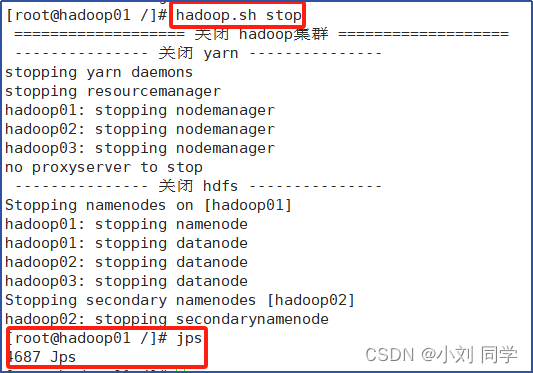
直接启动整个Hadoop集群服务
在主节点上执行 start-all.sh 指令,可以直接启动整个Hadoop集群服务。不过在2.x/3.x版本不推荐使用该指令启动Hadoop集群,并且使用这种指令启动服务会有警告指示。(且后续Spark启动指令也为start-all.sh,故不推荐使用该指令启动Hadoop集群)

















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









