






分析要爬取的网页
网易云歌单网址:https://music.163.com/#/discover/playlist
分析页面的url变化:
第一页:https://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=0
第二页:https://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=35
第一页offset为0,第二页的offset是35
找到歌单详细页面的链接: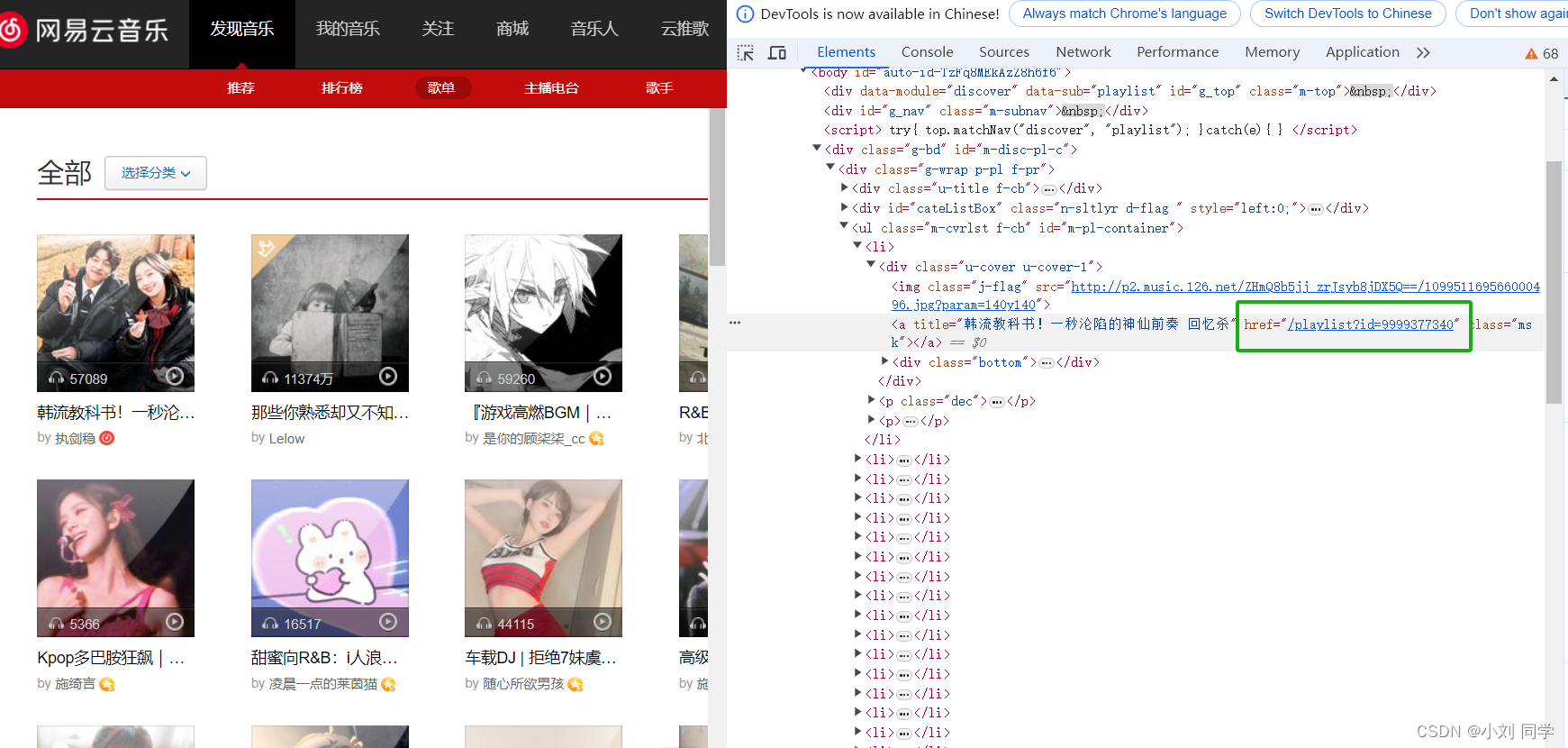
然后到详细页面分析要爬取的数据
接下来开始写代码
一、使用Scrapy采集、解析
在此之前需要了解如何使用scrapy
创建爬虫项目:scrapy startproject Music #项目名称可自定义
进入Music/Music/spiders创建爬虫:scrapy genspider musicList "music.163.com" (创建好后会有一个musicList.py文件)
1.配置settings.py文件
#下载延迟,可以设为每下载一次暂停1秒,以防下载过快被禁止访问
DOWNLOAD_DELAY = 1
#添加请求头
USER_AGENT = {}
2.设置item.py
Scrapy使用Item(实体)来表示要爬取的数据。
Scrapy框架提供了基类scrapy.Item用来表示实体数据。一般需要创建一个继承自scrapy.Item的子类,并为该子类添加类型为scrapy.Field的类属性来表示爬虫项目的实体数据。
在PyCharm中打开Music目录下的item.py文件,可以看到Scrapy框架已经在items.py文件中自动生成了继承字scrapy.Item的MusicItem类。只需修改MusicItem类的定义,为它添加属性即可。
代码如下:
import scrapy
class MusicItem(scrapy.Item):
SongsListID = scrapy.Field() # 歌单id号
SongListName = scrapy.Field() # 歌单名
AuthorName = scrapy.Field() # 作者名
CreationDate = scrapy.Field() # 歌单创建日期
PlayCount = scrapy.Field() # 播放量
Tags = scrapy.Field() # 标签名
SongsUrl = scrapy.Field() # 歌单域名,为下一次详细爬取留备份
Collection = scrapy.Field() # 歌单收藏量
Forwarding = scrapy.Field() # 转发量
Comment = scrapy.Field() # 评论量
SongsCount = scrapy.Field() # 歌曲数量
PicUrl = scrapy.Field() #图片url
Pic = scrapy.Field() #图片
PicName = scrapy.Field() #图片名称
ImagePath = scrapy.Field() #图片路径
Tag1 = scrapy.Field()
Tag2 = scrapy.Field()
Tag3 = scrapy.Field()3.编辑musicList.py文件(采集、解析数据部分)
import scrapy
from ..items import MusicItem
from copy import deepcopy
import re
class MusiclistSpider(scrapy.Spider):
name = "musicList"
allowed_domains = ["music.163.com"]
start_urls = ["https://music.163.com/discover/playlist"] #初始url
offset = 0 #用于记录当前爬取的页数
def parse(self, response):
#获取到一页的全部歌单
liList = response.xpath("//div[@id='m-disc-pl-c']/div/ul[@id='m-pl-container']/li")
#遍历一页的所有歌单,获取到歌单详细页面的信息
for li in liList:
musicItem = MusicItem()
#歌单的id
a_href = li.xpath("./div/a[@class = 'msk']/@href").extract_first()
musicItem["SongsListID"] = a_href[13:]
#详细页面url
songs_Url = "https://music.163.com/" + a_href
musicItem["SongsUrl"] = songs_Url
# 调用SongsListPageParse来获取歌单详细页面的信息
yield scrapy.Request(songs_Url,meta={"musicItem": deepcopy(musicItem)},
callback=self.SongsListPageParse,)
if self.offset < 6: #设置offset为最后的页数-1,因为第一页的offset为0
self.offset += 1
# 获取下一页的Url地址 offset为(页数-1)*35
nextpage_a_url = "https://music.163.com/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=" + str(
self.offset * 35)
# print('正在爬取第' + str(self.offset + 1) + '页')
yield scrapy.Request(nextpage_a_url, callback=self.parse)
def SongsListPageParse(self,response):
cntc = response.xpath("//div[@class='cntc']")
musicItem = response.meta['musicItem']
#歌单名
songsListName = cntc.xpath("./div[@class='hd f-cb']/div/h2//text()").extract_first()
musicItem["SongListName"] = songsListName
# 歌单作者名
user_name = cntc.xpath("././div[@class='user f-cb']/span[@class='name']/a/text()").extract_first()
musicItem["AuthorName"] = user_name
#歌单创建日期
time = cntc.xpath("./div[@class='user f-cb']/span[@class='time s-fc4']/text()").extract_first()
musicItem["CreationDate"] = time[0:10]
#歌单收藏量
aList = cntc.xpath("./div[@id='content-operation']/a")
Collection = aList[2].xpath("./@data-count").extract_first()
musicItem["Collection"] = Collection
#转发量
Forwarding = aList[3].xpath("./@data-count").extract_first()
musicItem["Forwarding"] = Forwarding
#评论量
Comment = aList[5].xpath("./i/span[@id='cnt_comment_count']/text()").extract_first()
musicItem["Comment"] = Comment
#歌曲数量
songtbList = response.xpath("//div[@class='n-songtb']/div")
songsCount = songtbList[0].xpath("./span[@class='sub s-fc3']/span[@id='playlist-track-count']/text()").extract_first()
musicItem["SongsCount"] = songsCount
#播放量
playCount = songtbList[0].xpath("./div[@class='more s-fc3']/strong[@id='play-count']/text()").extract_first()
musicItem["PlayCount"] = playCount
#歌单标签 获取到歌单的每一个标签
tags = ""
tagList = cntc.xpath("./div[@class='tags f-cb']/a")
for a in tagList:
tags = tags + a.xpath("./i/text()").extract_first() + ","
tag1 = tags.split(",")[0]
tag2 = tags.split(",")[1]
tag3 = tags.split(",")[2]
# musicItem["Tags"] = tags
musicItem["Tag1"] = tag1
musicItem["Tag2"] = tag2
musicItem["Tag3"] = tag3
#图片名称
pic_name = "歌单 《"+songsListName + "》 封面"
#去除图片名称中的特殊字符,以确保在保存图片时能够正确地给图片重命名并保存
cleaned_filename = re.sub(r'[\\/:"*?<>/【】|]', '', pic_name)
musicItem["PicName"] = cleaned_filename
# 图片链接
pic_url = response.xpath("//div[@class='cover u-cover u-cover-dj']/img/@src").extract_first()
musicItem["PicUrl"] = response.urljoin(pic_url)
yield musicItem
二、使用管道存储数据
1.创建图片存储文件夹
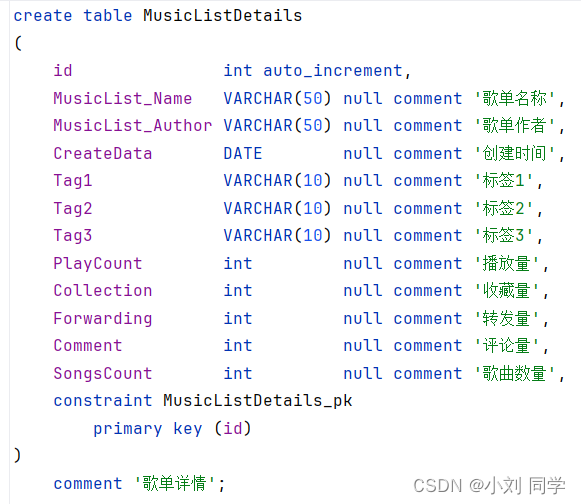
2.创建存储数据的数据表
表结构如下:
3.编写pipelines.py文件
import os
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.utils.project import get_project_settings
import pymysql
class ImagePipeline(ImagesPipeline):
IMAGES_STORE = get_project_settings().get("IMAGES_STORE")
def get_media_requests(self,item,info):
pic_url = item['PicUrl']
yield scrapy.Request(pic_url) #发送请求下载图片 yield返回请求
def item_completed(self, results, item, info):
#获取图片路径同时判断这个路径是否正确,如果正确放到image_path里
#遍历results,ok表示图片下载成功
image_path = [x["path"] for ok, x in results if ok]
# 重命名图片文件 os.rename(old_image_path, new_image_path)
os.rename(os.path.join(self.IMAGES_STORE + "/" + image_path[0]),
os.path.join(self.IMAGES_STORE+ "/" + item["PicName"] + ".jpg"))
return item
#更新item中图片路径的字段
# item["ImagePath"] = os.path.join(self.IMAGES_STORE + "/" + item["PicName"])
#数据库存储管道
class MySQLPipeline:
def __init__(self):
self.conn = pymysql.Connect(
host='localhost',
port=3306,
user='root',
password='123456',
db='musiclist'
)
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
sql = ("insert into `musiclistdetails`(`Musiclist_name`,`Musiclist_Author`,`CreateDate`,"
"`Tag1`,`Tag2`,`Tag3`,`PlayCount`,`Collection`,`Forwarding`,`Comment`,`SongsCount`) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")
self.cursor.execute(sql,[item['SongListName'],item['AuthorName'],
item['CreationDate'],item['Tag1'],item['Tag2'],item['Tag3'],item['PlayCount'],
item['Collection'],item['Forwarding'],item['Comment'],item['SongsCount']])
self.conn.commit()
return item
def close_spider(self,spider):
#关闭游标
self.cursor.close()
#关闭连接
self.conn.close()
print('MySQL数据写入完成')
4.在settings.py中设置图片存储路径和管道的执行顺序
#图片存储路径
IMAGES_STORE = "填写自己的本地存储路径"
#管道执行顺序 (数值小的先执行)
ITEM_PIPELINES = {
'Music.pipelines.ImagePipeline': 1, #图片存储管道
'Music.pipelines.MySQLPipeline':2, #详细数据MySQL存储管道
}三、启动爬虫程序
有两种启动的方式:
1、在命令行输入spider crawl musicList
2、创建一个执行/调试文件:execute.py
在里面添加:
from scrapy.cmdline import execute
execute("scrapy crawl musicList".split())然后run该文件
四、爬虫结果
1.图片存储结果:

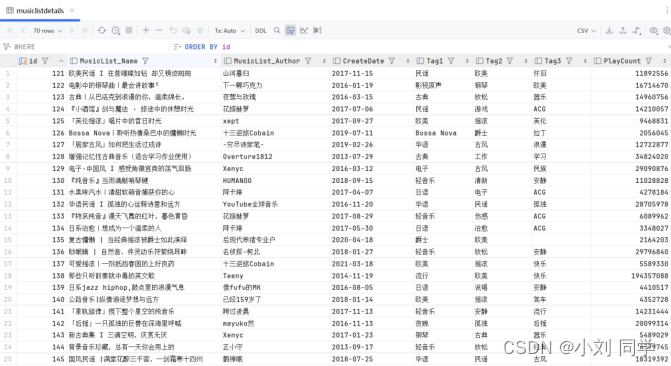
2.详细数据存储结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









