







 本文介绍了使用tensorflow2进行深度学习,通过InceptionV3和DenseNet201模型对Cub200-2011数据集进行分类的过程。文章详细阐述了模型结构、参数调整策略,展示了数据增强和模型训练的实验流程,以及迁移学习优化带来的显著提升。
本文介绍了使用tensorflow2进行深度学习,通过InceptionV3和DenseNet201模型对Cub200-2011数据集进行分类的过程。文章详细阐述了模型结构、参数调整策略,展示了数据增强和模型训练的实验流程,以及迁移学习优化带来的显著提升。
一、前言
本文章使用tensorflow2深度学习框架,并使用迁移学习,将cub200-2011数据集进行分类。主要使用的模型为InceptionV3以及DenseNet201。本文章将体现调整参数和未调整参数的对比。
本文章为我的部分期末论文,希望大家可以相互学习,一起交流!!
二、InceptionV3模型介绍
InceptionV3 网络是由 Google 开发的一个非常深的卷积网络。2015年 12 月, Inception V3 在论文《Rethinking the Inception Architecture forComputer Vision》中被提出,Inception V3 在 Inception V2 的基础上继续将 top-5的错误率降低至 3.5% 。Inception V3对 Inception V2 主要进行了两个方面的改进。首先,Inception V3 对 Inception Module 的结构进行了优化,现在 Inception Module有了更多的种类(有 35 × 35 、 1 7× 17 和 8× 8 三种不同结构),并且 Inception V3 还在 Inception Module 的分支中使用了分支(主要体现在 8x8 的结构中)。
其次,在 Inception V3 中还引入了将一个较大的维卷积拆成两个较小的一维卷积的做法。例如, 7× 7 卷积可以拆成 1×7 卷积和7 × l卷积。当然3x3 卷积也可以拆成 Ix3 卷积和 3 × l卷积。这被称为Factorizationinto small convolutions 思想。在论文中作者指出,这种非对称的卷积结构拆分在处理更多、更丰富的空间特征以及增加特征多样性等方面的效果能够比对称的卷积结构拆分更好,同时能减少计算量。例如,2个3*3代替1个5*5减少28%的计算量。
三、DenseNet系列模型介绍
比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个L层的网络,DenseNet共包含L(L+1)2个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。DenseNet的主要特点如下:
(1)密集连接:每个卷积层都与前面所有层相连,增加了信息流通的路径,使得网络具有更强的特征提取能力和鲁棒性。
(2)残差学习:DenseNet中还采用了残差学习的思想,即每个卷积层的输出不仅传递给后续层,还会直接连接到后续层之后的层中,从而更充分地利用之前层的信息。
(3)参数共享:在DenseNet中,不同层之间的卷积核是共享的,这可以减少模型参数数量,提高了模型的效率。
(4)瓶颈结构:DenseNet中使用了瓶颈结构(Bottleneck layer)来减少计算量和模型参数。瓶颈结构包括一个1x1卷积层和一个3x3卷积层,可以将输入特征图降维,从而减少计算量和内存消耗。
四、实验流程
实验环境为GPU:RTX3080,显卡内存10GB,使用tensorflow2.13.0。
四种模型训练的实验流程如下:
(1).数据集导入以及数据集增强。导入的数据集共有鸟类类别200个,训练集图片数有8232,验证集图片数有3556。数据增强策略有图像旋转、图像平移、图像灰度值变换和图像裁剪等。
代码如下,
import tensorflow as tf
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255, # 像素值归一化
rotation_range=20, # 随机旋转角度范围
width_shift_range=0.1, # 水平平移范围
height_shift_range=0.1, # 垂直平移范围
shear_range=0.2, # 剪切变换范围
zoom_range=0.2, # 随机缩放范围
horizontal_flip=True, # 水平翻转
fill_mode='nearest'
)
# 加载训练数据集
train_generator = train_datagen.flow_from_directory(
'/home/user/data_vgg/train', # 训练数据集所在路径
target_size=(512, 512), # 图片大小统一
batch_size=8,
class_mode='categorical'
)
# 加载验证数据集
validation_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_directory(
'/home/user/data_vgg/test',
target_size=(512, 512),
batch_size=8,
class_mode='categorical'
)
import matplotlib.pyplot as plt
train_images, train_labels = next(train_generator)
# 显示训练数据集中的几张图像
plt.figure(figsize=(10, 10))
for i in range(6):
plt.subplot(2, 2, i+1)
plt.imshow(train_images[i])
# plt.title('Label: {}'.format(train_labels[i]))
plt.axis('off')
plt.show()读入图片展示,

(2).模型选择以及构建。实验选择了VGG19、ResNet50、DenseNet121、DenseNet201、InceptionV3以及EfficientNetV2L,并选择了迁移学习的方式训练模型。
(3).模型参数的选择。对于优化器,选择SGD或Adam。对于损失函数,选择CategoricalCrossentropy。对于学习率使用合适的学习率衰减策略。
(4).模型的训练。选择合适的epoch训练模型,防止模型过拟合。训练结束后呈现训练曲线图,进行实验结果的分析。
4.1、InceptionV3第一次训练
batchsize=8,imgsize=224*224,epochs=70,optimixer=adam,lr=0.001-0.00001,代码如下,
import tensorflow as tf
from keras.callbacks import LearningRateScheduler
base_model = tf.keras.applications.InceptionV3(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(512, activation='relu')(x)
predictions = tf.keras.layers.Dense(200, activation='softmax')(x)
model2 = tf.keras.Model(inputs=base_model.input, outputs=predictions)
def lr_schedule(epoch):
if epoch < 30:
return 0.001
elif epoch < 60:
return 0.0001
elif epoch < 90:
return 0.00001
lr_callback = LearningRateScheduler(lr_schedule)
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model2.fit(train_generator, validation_data=validation_generator, epochs=70,callbacks=[lr_callback])训练曲线如下,
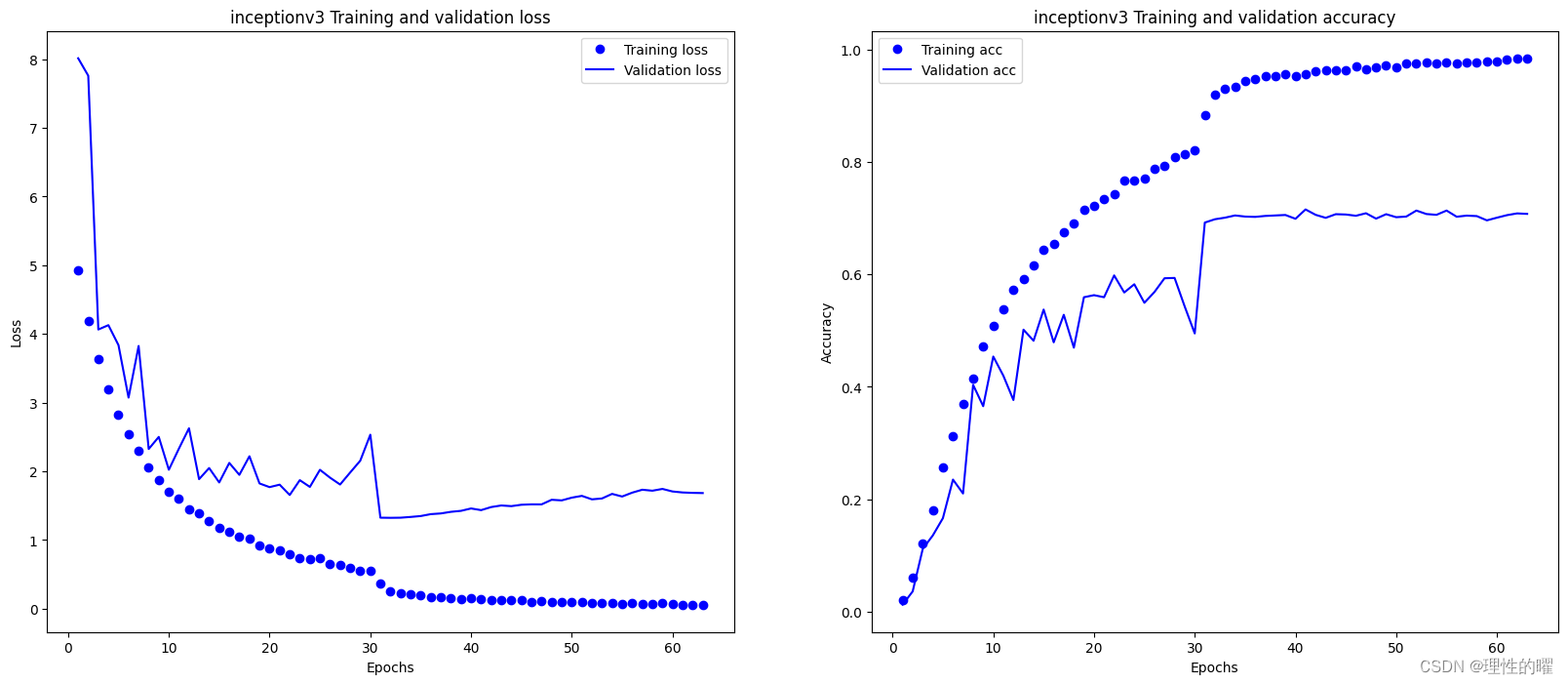
在验证集上最高的准确率为0.708。模型效果及格,出现了细微的过拟合现象。
4.2、DenseNet201第一次训练
batchsize=8,imgsize=224*224,epochs=60,optimixer=sgd,lr=0.01-0.001,代码如下,
base_model = tf.keras.applications.DenseNet201(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(512, activation='relu')(x)
predictions = tf.keras.layers.Dense(200, activation='softmax')(x)
model2 = tf.keras.Model(inputs=base_model.input, outputs=predictions)
def lr_schedule(epoch):
if epoch < 20:
return 0.01
elif epoch < 40:
return 0.005
elif epoch < 60:
return 0.001
lr_callback = LearningRateScheduler(lr_schedule)
model2.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model2.fit(train_generator, validation_data=validation_generator, epochs=70,callbacks=[lr_callback])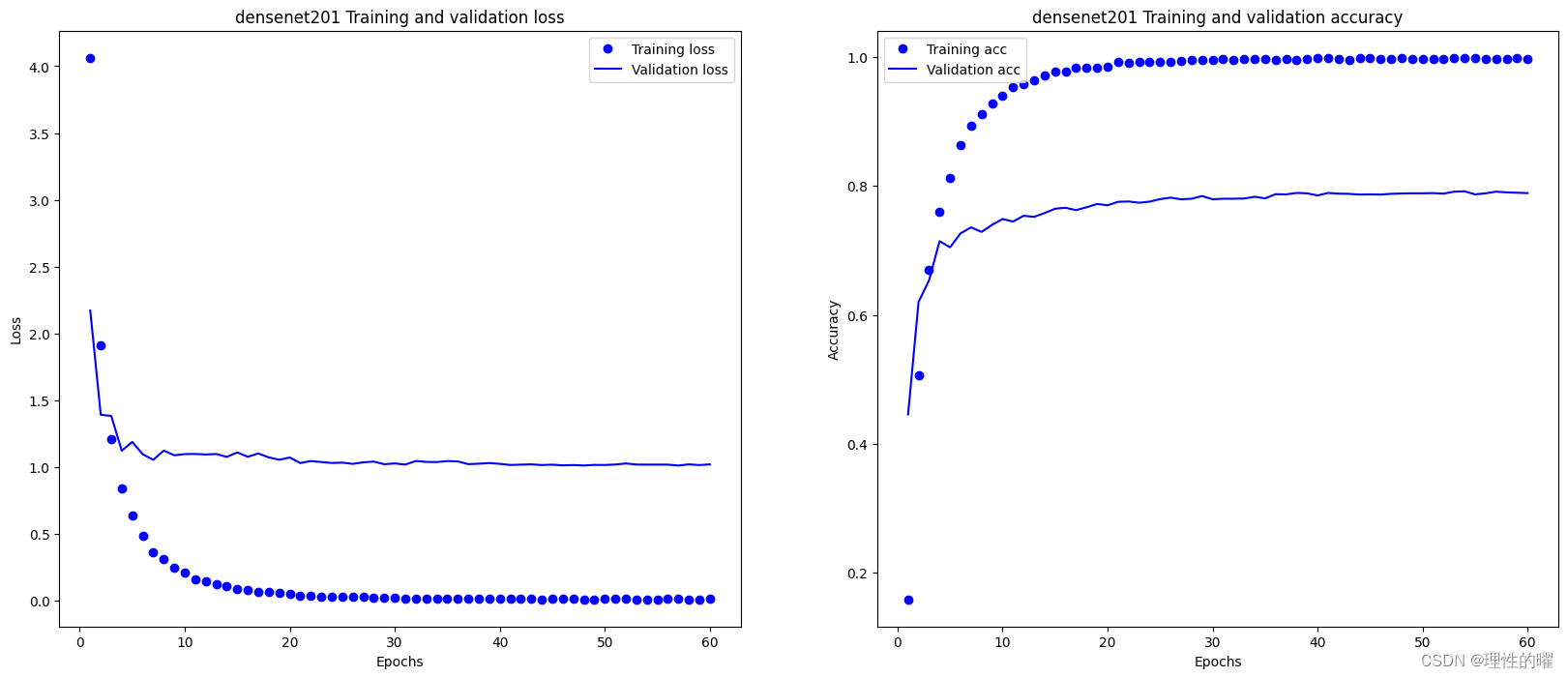
在验证集上最高的准确率为0.792。模型效果较好,且没有严重的过拟合现象。
4.3、InceptionV3第二次训练
查阅了相关资料,参考了某篇论文,InceptionV3模型的上限很高,对该模型的参数进行微调,再次训练。
batchsize=12,imgsize=512*512,epochs=50,optimixer=sgd(动量0.9,衰减权重0.00001),lr=0.001,每隔两个epoch指数衰减,代码如下,
base_model = tf.keras.applications.InceptionV3(weights='imagenet', include_top=False, input_shape=(512, 512, 3))
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(2048, activation='relu')(x)
x = tf.keras.layers.Dropout(0.3)(x)
x = tf.keras.layers.Dense(512, activation='relu')(x)
predictions = tf.keras.layers.Dense(200, activation='softmax')(x)
model2 = tf.keras.Model(inputs=base_model.input, outputs=predictions)
initial_lr = 0.001
decay_rate = 0.9
decay_step = 2
def lr_scheduler(epoch, lr):
if epoch % decay_step == 0 and epoch > 0:
return lr * decay_rate
return lr
# 定义优化器
optimizer = tf.keras.optimizers.legacy.SGD(learning_rate=initial_lr, momentum=0.9, decay=1e-5)
# 定义学习率衰减回调函数
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_scheduler)
# 编译模型并添加学习率衰减回调函数
model2.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])训练结果如下,
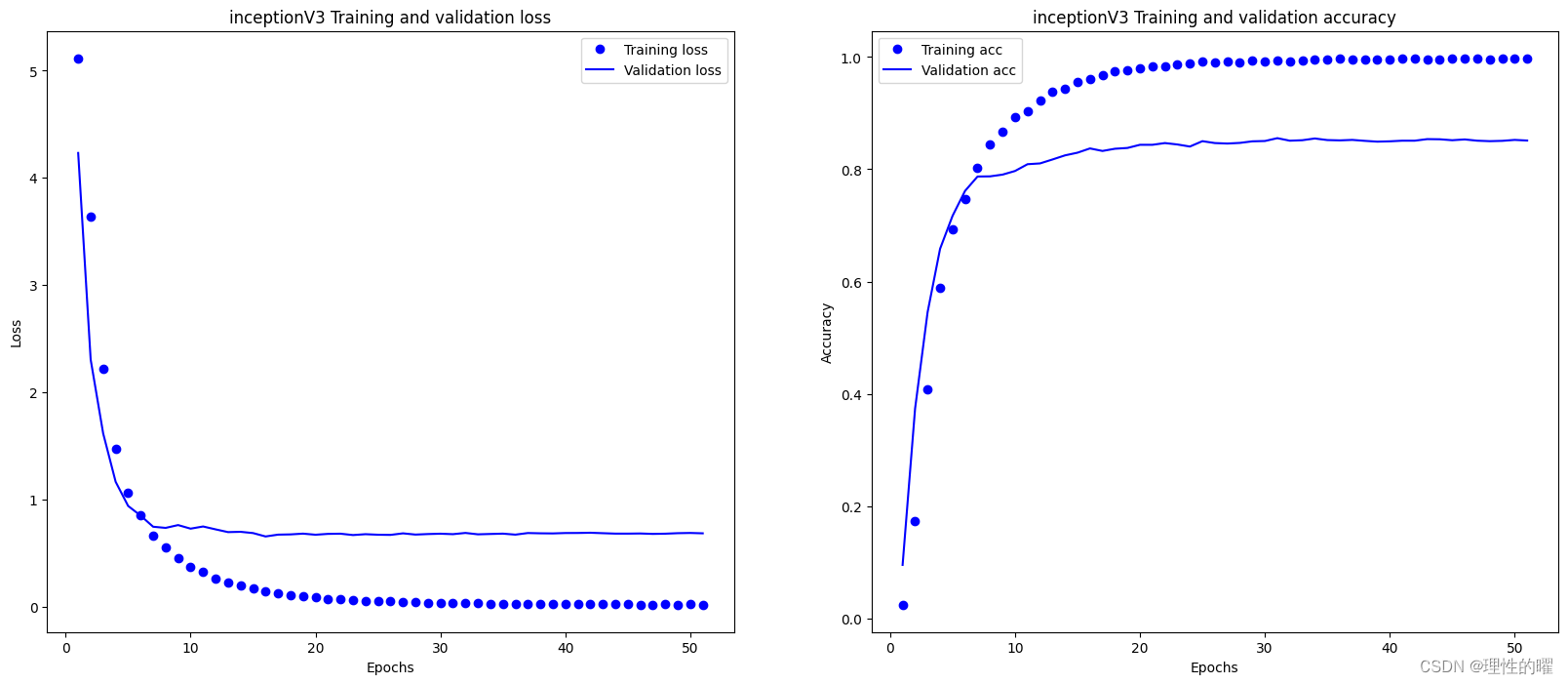
在验证集上最高的准确率为0.856。模型效果较好,损失值下降得较快,且没有过拟合现象,比未优化时的模型更加稳定和准确。
此次调参主要是图片输入大小、优化器的配置、学习率衰减策略的调整。
decay是一个用于学习率衰减的参数。decay控制每个参数更新时学习率的衰减程度。具体来说,每次进行参数更新时,学习率会按照以下公式进行衰减:
learning_rate = initial_learning_rate / (1 + decay * epoch)
其中,initial_learning_rate是初始学习率,epoch表示当前的训练轮数。通过设置decay参数,可以使学习率随着训练轮数的增加而逐渐减小。这在训练过程中有助于实现学习率的自适应调整,提高模型的收敛性和稳定性。
momentum是一个用于控制参数更新方向的动量(momentum)系数。动量是一种用于加速模型训练的技巧。在每次参数更新时,动量会根据上一次的参数更新方向和当前的梯度方向来计算出一个新的参数更新方向,从而使参数更新更加稳定和连续。通过使用动量,可以加速模型的收敛速度,并且减小参数更新的方差,提高模型的泛化能力。
具体来说,在SGD优化器中,动量系数会对梯度进行加权平均,并将这个平均值作为模型参数的更新方向。在每次迭代中,动量系数会根据以下公式进行更新:
v = momentum * v - learning_rate * gradientparameter = parameter + v
其中,v表示当前的动量向量,momentum是动量系数,gradient是当前的梯度,learning_rate是学习率,parameter是当前的模型参数。
4.4、DenseNet201第二次训练
优化的InceptionV3提升效果不错,尝试将优化后的InceptionV3的参数迁移到DenseNet上。
batchsize=4,imgsize=512*512,epochs=50,optimixer=sgd(动量0.9,衰减权重0.00001),lr=0.001,每隔两个epoch指数衰减,代码如下,
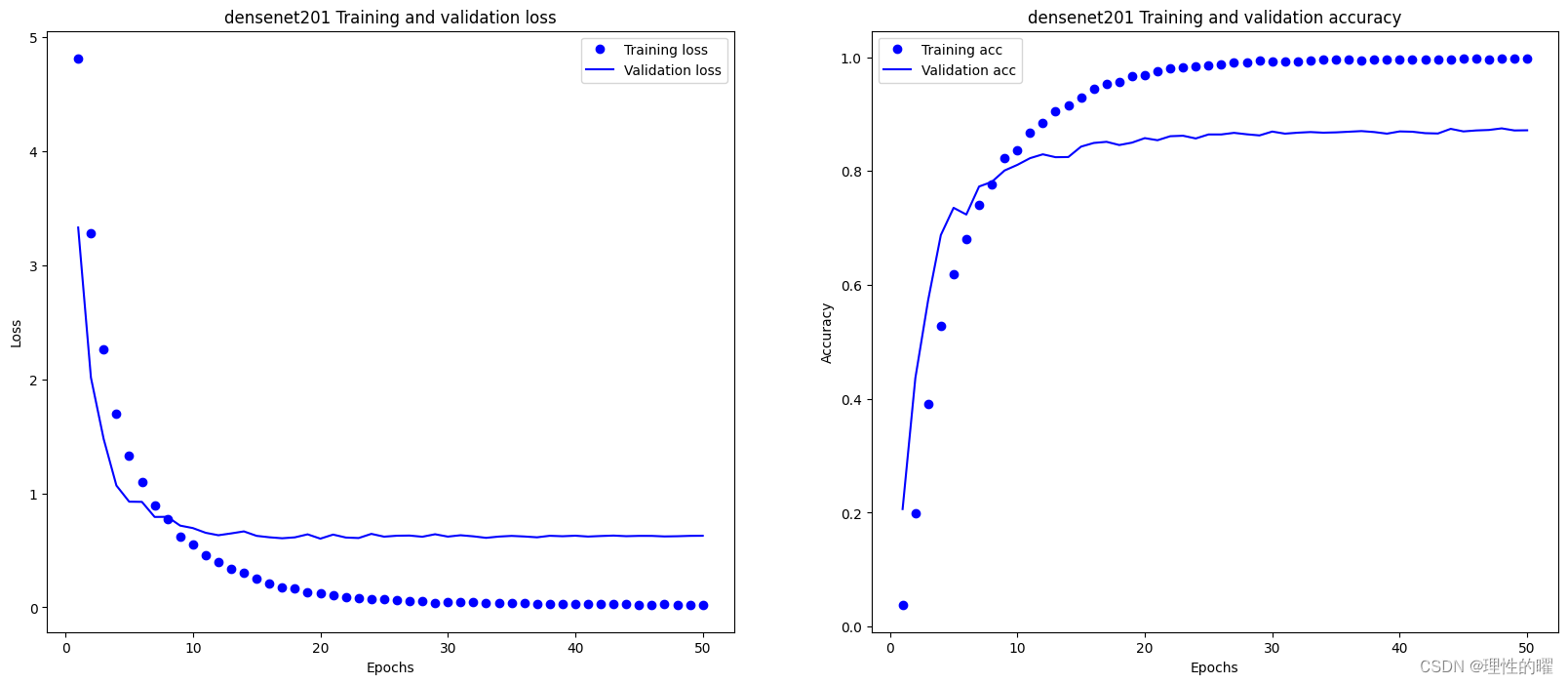
在验证集上最高的准确率为0.875。模型效果较好,训练过程中没有出现过拟合现象,比未优化前的损失值下降得快。
五、总结
顶级炼丹师不是靠自己一个人摸索的,要学会找别人已经研究出来的模型或优化策略机制,并且复现出来,在去把好的东西迁移到其他的模型,或许有更好的结果。
本片文章到此为止,希望大家能在评论区和我一起交流!!!

















 9117
9117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









