






不说了,贪婪算法还有案例再写一遍吧
过了一遍挂不了科了吧
应该不会挂吧,临时抱佛脚专业户
真的服了,我就玩了两把元梦之星结果没保存
吐了
第四章
正则表达式
老师的代码:
#——————re.search——————
import re
a='student'
str1='teacherandstudent'
ret=re.search(a,str1)
print(ret)
# ——————【例1】compile的使用——————
import re
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……'
regex = re.compile('\w*o\w*')
x = regex.findall(content)
print(x)
import re
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……'
x = re.findall('\w*o\w*', content)
print(x)
#——————【例1】匹配所有以“my_”开头的字符串——————
import re
pattern = 'my_\w+' # 模式字符串
string = 'MY_HOME my_home' # 要匹配的字符串
match1 = re.findall(pattern,string,re.I) # 搜索字符串,不区分大小写
match2 = re.findall(pattern,string) # 搜索字符串,区分大小写
print(match1, match2) # 输出匹配结果一些基础规则及解释:
基础概念
-
正则表达式(Regular Expressions,简称Regex):一种文本模式描述的标准化语法,它允许你检查一个字符串是否与某种模式匹配。
-
文本匹配(Matching):使用正则表达式在文本中查找与该表达式匹配的部分。
正则表达式的基本元素
-
字面量(Literals):普通字符,如
a、b、1,在正则表达式中表示他们自己。 -
元字符(Metacharacters):具有特殊含义的字符,如
.、*、?、+等。 -
转义字符(Escape Character):反斜杠
\用于转义元字符,使其失去特殊意义,例如\.表示字面量点。
常用元字符及其含义
.:匹配任意单个字符(除了换行符)。*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。^:匹配输入的开始。$:匹配输入的结束。[]:字符集,匹配括号内的任意字符。{}:量词,指定前面元素的出现次数。():分组,将多个元素视为一个单元。|:选择,匹配符号左边或右边的元素。
基本规则
-
直接字符匹配:你可以直接使用字面量字符进行匹配。例如,
abc会匹配 "abc"。 -
使用元字符:利用元字符创建更复杂的模式。例如,
a.c可以匹配 "abc"、"axc" 等。 -
组合使用:可以将多个元字符组合使用。例如,
ab*c匹配 "ac"、"abc"、"abbc" 等。 -
转义特殊字符:如果你想匹配元字符本身,比如
.,你需要使用转义符\,如\.。
示例
基础元字符
- 匹配任意数字:
\d相当于[0-9]。 - 匹配非数字字符:
\D相当于[^0-9]。 - 匹配任意单词字符(字母、数字或下划线):
\w。 - 匹配任意非单词字符:
\W。 - 匹配任意空白字符(如空格、制表符):
\s。 - 匹配任意非空白字符:
\S。 - 匹配特定字符集:例如
[a-zA-Z]匹配任意字母。 -
\d{5,12}:这个表达式匹配连续的5到12位数字。\d代表数字(0-9)。{5,12}表明前面的元素(这里是\d)必须连续出现至少5次,但不超过12次。
-
^\d{5,12}$:这个表达式匹配整个字符串必须是5到12位的数字。^表示匹配的字符串必须从行首开始。\d{5,12}如上所述。$表示匹配的字符串必须在这些数字之后立即结束。
-
Windows\d+:匹配以 "Windows" 开头,后面跟随至少一个数字的字符串。Windows是一个普通的字符序列。\d+表示一个或多个数字。+是一个量词,表示前面的元素(这里是\d)至少出现一次。
-
(?0\d{2}[) -]?\d{8}:这个表达式看起来有些问题,可能是(?0\d{2}[) -]?\d{8}的变体。如果是这样,它代表:0\d{2}匹配以0开头的两位数字。[) -]?匹配一个右括号)、空格或者连字符-中的任意一个,出现0次或1次。\d{8}匹配连续的8位数字。
-
(\d{1,3}\.){3}\d{1,3}:这个表达式用于匹配简单的IP地址格式。\d{1,3}匹配1到3位的数字。\.匹配一个点(.在正则表达式中是一个特殊字符,所以用\进行转义)。(\d{1,3}\.){3}表示一组1到3位数字后跟一个点,这组模式重复3次。- 最后的
\d{1,3}匹配IP地址的最后一部分。
-
0\d{2}-\d{8}|0\d{3}-\d{7}:这个表达式匹配两种格式的电话号码。0\d{2}-\d{8}匹配以0开头的两位区号,后面跟着一个连字符和8位数字。|是一个或运算符,表示匹配左边或右边的模式。0\d{3}-\d{7}匹配以0开头的三位区号,后面跟着一个连字符和7位数字。
测试文本,上面的都能用来测试:
Hello, this is an example text to test various regex patterns.
Numbers in sequence: 1234567890, and with range: 123-456-7890.
Sample IP addresses: 192.168.1.1, 10.0.0.1, 172.16.254.1.
Phone numbers in different formats: 012-3456789, 987-654-3210, (080) 12345678.
Hexadecimal numbers: 1a2b3c, 00FF00, 7f8e9d.
Random characters: abcdefghijklmnopqrstuvwxyz, ABCDEFGHIJKLMNOPQRSTUVWXYZ.
Special sequence: Windows10, Windows95, Windows7.
Dates in various formats: 2023/04/01, 01-04-2023, 04.01.23.
A block of random text:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus lacinia odio vitae vestibulum.
Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium.
Email addresses: example@example.com, test123@test.net, user_name@domain.org.
ASCII symbols: !@#$%^&*()_+|}{":?><,./;'[]\=-`
Repeated patterns: ababab, 123123123, xyxyxyxy.
{} - 量词
{m,n}用于指定前面的字符或组合出现的次数。m是最小出现次数,n是最大出现次数。- 例如:
\d{2,4}匹配2到4位的数字。a{3}则只匹配连续出现三次的 'a'。
[] - 字符集
[]定义一个字符集。在字符集中的任何一个字符都可以在这个位置匹配。- 可以包含范围,例如
[a-z]匹配任何小写字母,[0-9]匹配任何数字。 - 特殊字符在字符集中通常失去其特殊含义,例如
[.]将匹配字面上的点(.)。
() - 分组
()用于将正则表达式的一部分组合在一起,可以作为一个单元进行操作。- 分组可以应用量词,例如
(ab){2}会匹配 "abab"。 - 分组也可以用于捕获(在某些正则表达式引擎中),用于从匹配的文本中提取或引用部分文本。
组合规律
-
量词和字符集:
- 量词可以直接应用于字符集,例如
[a-z]{2,4}匹配2到4个任意小写字母的序列。
- 量词可以直接应用于字符集,例如
-
量词和分组:
- 分组后的整体可以使用量词,例如
(abc){2}表示 "abcabc"。 (0\d{2})-\d{8}分组匹配以0开头的两位数字,然后是8位数字,它们之间有一个连字符。
- 分组后的整体可以使用量词,例如
-
嵌套使用:
- 分组内可以包含字符集,量词也可以应用于整个分组。例如
([0-9a-fA-F]{2}:){5}[0-9a-fA-F]{2}可以用来匹配MAC地址。
- 分组内可以包含字符集,量词也可以应用于整个分组。例如
-
结合使用:
- 不同的元素可以自由组合以形成复杂的模式。例如
(\d{1,3}\.){3}\d{1,3}用于匹配简单的IP地址,其中\d{1,3}匹配1到3位数字,然后是一个点,整个模式重复3次,后跟1到3位数字。
- 不同的元素可以自由组合以形成复杂的模式。例如
贪婪与非贪婪匹配
贪婪匹配(Greedy Matching)
贪婪匹配,顾名思义,会尝试匹配尽可能多的字符。它是正则表达式中的默认行为。当使用贪婪量词(如 *, +, ? 或 {n,m})时,正则表达式引擎会尽量匹配符合模式的最长字符串。
举例:
- 在表达式
a.*b中,假设有字符串"aabab",贪婪匹配会尽量匹配最长的字符串,结果是整个"aabab",而不仅仅是"aab"。
非贪婪匹配(Non-Greedy Matching)
非贪婪匹配,相反,会尝试匹配尽可能少的字符。要实现非贪婪匹配,需要在量词后面添加一个 ?。这告诉正则表达式引擎在满足最小数量要求的情况下就停止匹配。
举例:
- 在表达式
a.*?b中,对于同样的字符串"aabab",非贪婪匹配的结果会是"aab",因为它在满足模式a后跟任意数量字符然后是b的最小要求后就停止了匹配。
匹配规则
-
贪婪量词:
*(零次或更多次)+(一次或更多次){n,m}(至少 n 次,至多 m 次)- 这些量词在没有限制的情况下会尽量匹配更多的字符。
-
非贪婪量词:
*?(零次或更多次,但尽可能少)+?(一次或更多次,但尽可能少){n,m}?(至少 n 次,至多 m 次,但尽可能少)- 在遇到满足条件的最短可能匹配后,这些量词会停止匹配。
实际应用
在实际应用中,选择贪婪匹配或非贪婪匹配取决于你的具体需求。如果你想要匹配尽可能多的字符,贪婪匹配是合适的;如果你想要最短的匹配,那么应该使用非贪婪匹配。非贪婪匹配在处理包含嵌套元素的字符串时特别有用,因为它可以防止正则表达式匹配超过预期的部分。
#——————【例2】贪婪匹配:匹配网络地址的中间部分——————
import re # 导入re模块
pattern = 'https://.*/' # 表达式,“.*”获取www.hao123.com
match = re.findall(pattern,'https://www.hao123.com/') # 匹配字符串
print(match) # 打印匹配结果:https://www.hao123.com
import re
pattern = 'https://(.*)/' # 只匹配.*的中间内容
match = re.findall(pattern,'https://www.hao123.com/')
print(match) # 结果:www.hao123.com
import re
pattern = 'https://.*(\d+).com/' # 获取网络地址中的123
match = re.findall(pattern,'https://www.hao123.com/')
print(match) #发现只匹配了一个3捕获组:pattern = 'https://(.*)/':这个正则表达式包含一个捕获组 (.*)。这里,.* 匹配任何字符(除了换行符),() 将这部分表达式标记为一个组。re.findall() 函数返回所有非重叠匹配的列表。由于 (.*) 是一个捕获组,findall 返回的是捕获组内的内容,而不是整个匹配。因此,输出结果是捕获组中的内容,即 ['www.hao123.com']。这里,捕获组匹配了 https:// 之后和最后一个 / 之前的所有内容。
第三段代码中,问题在于 .* 的贪婪性质。在正则表达式中,* 是一个贪婪量词,会匹配尽可能多的字符。因此,.* 部分匹配了尽可能多的字符,直到字符串的最后一个数字之前。这意味着 (\d+) 只能匹配字符串中的最后一个数字 3。为了正确匹配整个数字序列 123,我们需要让 .* 部分不那么贪婪。这可以通过使用非贪婪量词 *? 实现,它匹配尽可能少的字符。
import re
pattern = 'https://.*?(\d+).com/'
match = re.findall(pattern, 'https://www.hao123.com/')
print(match)
仔细解释一下为什么会输出3
-
贪婪匹配的工作原理:
.*是一个贪婪匹配,它会尽可能多地匹配字符。在这个例子中,.*匹配了尽可能多的字符,直到字符串的末尾,然后开始回溯(往回看),以找到剩余部分的匹配。
-
回溯:
- 由于正则表达式后面还有
(\d+).com/需要匹配,正则表达式引擎开始从字符串的末尾往回寻找,以满足这部分的匹配需求。 (\d+)需要匹配一个或多个数字。由于.*已经占据了尽可能多的空间,它最终只能让出一个字符的位置,以满足\d+的最低要求(即匹配至少一个数字)。
-
为什么只匹配到 '3':
- 在这个过程中,
.*首先匹配了整个字符串https://www.hao123.com/,然后逐渐回溯,最终让出最后一个字符 '3',以便\d+至少有一个字符可以匹配。 - 因此,
(\d+)只匹配到了 '3',因为它是字符串中最后一个数字,也是在.*贪婪匹配之后唯一剩下的位置。
老师的代码:
#——————【例3】非贪婪匹配:获取网络地址中的123——————
import re
pattern = 'https://.*?(\d+).com/'
match = re.findall(pattern,'https://www.hao123.com/')
print(match) # 返回['123']
import re
pattern = 'https://(.*?)' # 非贪婪匹配放在结尾
match = re.findall(pattern,'https://www.hao123.com/')
print(match) # 结果为空
正则表达式解析
'https://(.*?)':https://是固定的字符串匹配部分。(.*?)是一个非贪婪匹配组,它匹配任意字符(.),尽可能少的次数(*?)。这意味着它可以匹配零个或更多字符,但优先匹配更少的字符。
匹配过程
- 当正则表达式引擎处理
'https://www.hao123.com/'时:- 首先,它匹配固定的字符串
https://。 - 接着,引擎检查非贪婪匹配组
(.*?)。由于这个组是非贪婪的,并且后面没有其他字符或条件来限制它,它就匹配零个字符(这是满足条件的最少字符数)。
- 首先,它匹配固定的字符串
结果
- 因此,捕获组
(.*?)在这个例子中实际上没有捕获任何字符,从而导致findall返回一个空列表。
为了让这个正则表达式工作并捕获期望的内容,需要添加一些限制条件来指定何时结束匹配。例如,如果想捕获 https:// 之后直到下一个 / 之前的所有内容,可以这样修改正则表达式:
pattern = 'https://(.*?)/'
match = re.findall(pattern, 'https://www.hao123.com/')
print(match) # 结果将不再为空
案例:彼岸图网
import requests
url = "https://pic.netbian.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) /'
'AppleWebKit/537.36 (KHTML, like Gecko) /'
'Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0'}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
import re
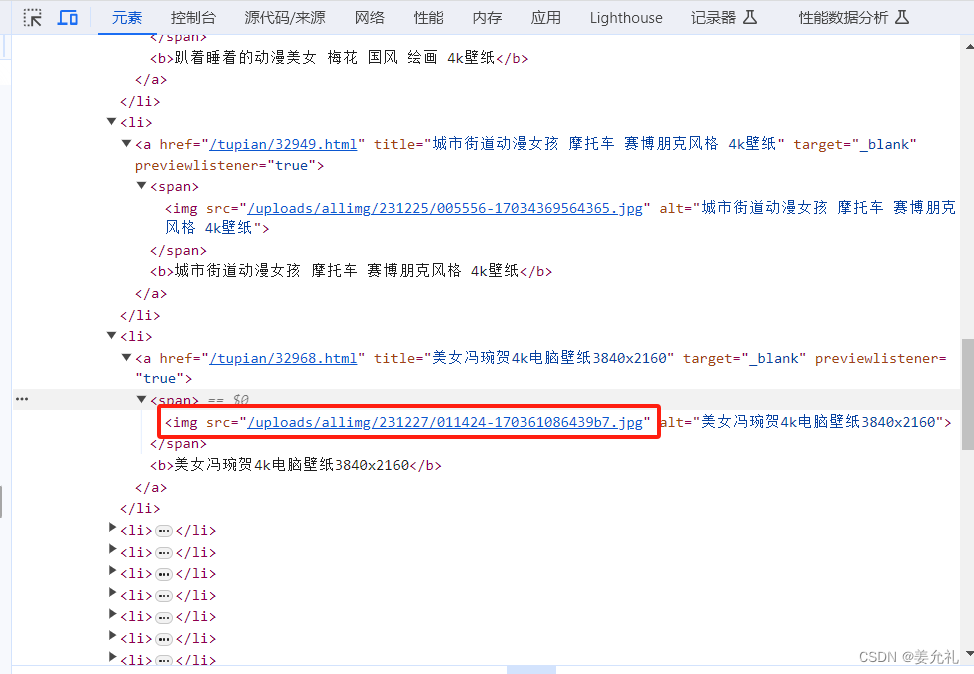
parr = re.compile('src="(/u.*?)".alt="(.*?)"')
image = re.findall(parr,response.text)
for content in image:
print(content)
import os
path = "彼岸图网图片获取"
if not os.path.isdir(path):
os.mkdir(path)
for i in image:
link = i[0]
name = i[1]
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get('https://pic.netbian.com'+link)
img.write(res.content)
img.close()
print(name+".jpg 获取成功!")
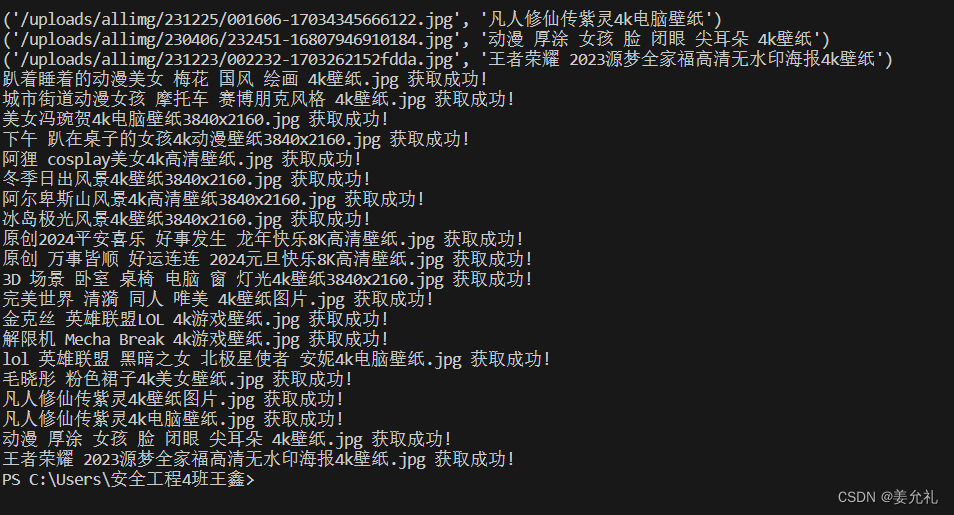
详细解释一下这段代码哈:
+
1.【查看网页】
2.【相关参数】
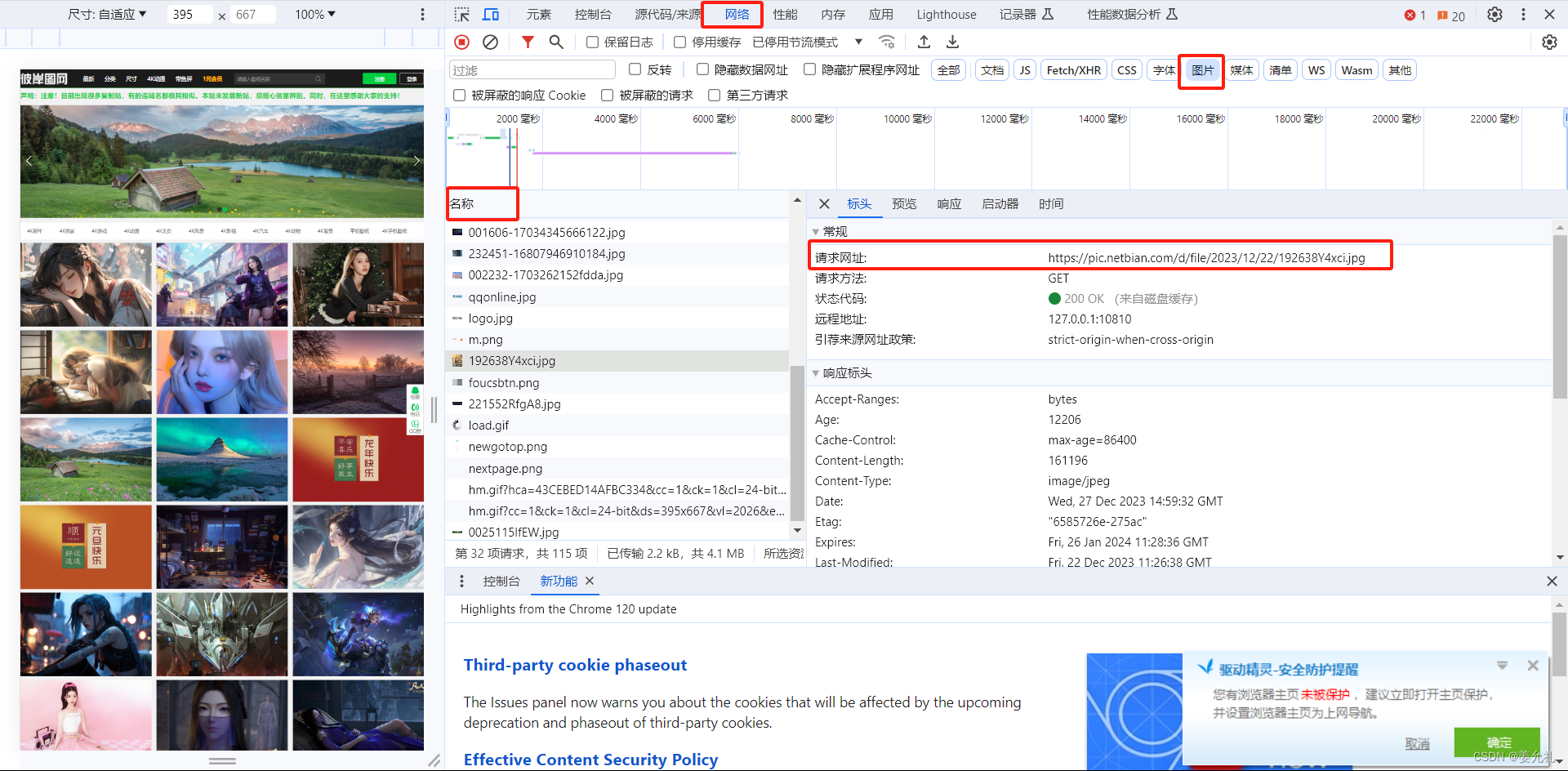
3.【发送请求:requests库】
import requests # 导入网络请求模块requests
response = requests.get('https://pic.netbian.com/uploads/allimg/230922/165917-16953731571c11.jpg')
print(response.content) # 打印二进制数据
with open('单个图片.png','wb') as f: # 通过open函数将二进制数据写入本地文件
f.write(response.content) # 写入
现在再来详细解读一下老师的代码:
import requests
url = "https://pic.netbian.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) /'
'AppleWebKit/537.36 (KHTML, like Gecko) /'
'Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0'}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
import re
parr = re.compile('src="(/u.*?)".alt="(.*?)"')
image = re.findall(parr,response.text)
for content in image:
print(content)
import os
path = "彼岸图网图片获取"
if not os.path.isdir(path):
os.mkdir(path)
for i in image:
link = i[0]
name = i[1]
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get('https://pic.netbian.com'+link)
img.write(res.content)
img.close()
print(name+".jpg 获取成功!")
- 导入
requests库用于发起网络请求。 - 导入
re库用于正则表达式匹配。 - 导入
os库用于操作文件系统 - 设置目标网站的URL。
- 定义请求头
headers,其中包含User-Agent,这在请求网页时用于模拟浏览器行为,有时候可以避免被网站的反爬虫策略所阻止。 - 使用
requests.get发送请求,并将响应对象赋值给response。 - 将响应的编码设置为
response.apparent_encoding,以确保正确处理响应内容。 - 编译一个正则表达式,用来匹配图片的源地址(src)和图片的alt文本(通常是图片的描述或标题)。
- 使用
re.findall在响应的文本中查找所有符合该模式的内容。 - 遍历所有匹配项并打印它们。每个
content是一个元组,包含图片的URL路径和alt文本。 - 设置一个路径名
path。 - 如果该路径不是一个现有目录,就创建一个新目录。
- 遍历所有找到的图片。
- 对于每个图片,构建完整的URL(由基础URL和提取的路径组成)并发起请求。
- 打开一个文件以二进制写入模式 (
"wb"),并将下载的图片内容写入该文件。 - 保存文件并输出下载成功的信息。
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}