







第二章 web相关技术
HTML语言规范
超文本标记语言
超文本:使用超链接的方法,把文字和图片信息相互链接,形成具有相关信息的体系。页面内可以包含图片、链接、音乐、视频、程序等非文字元素;
标记语言:在文档内使用标记标签来定义页面内容的语言
超文本标记语言:在文档内使用标记标签来定义页面内容多语言;使用标签来描述网页,适用于创建网页的标记语言,不是一种编程语言。
HTML的最初构想是作为一种交换科学和其他技术文档的一种语言,共那些不熟悉书写文档的专家使用。HTML规定一小套结构语义标签,食欲书写相对简单的文档,从而解决了标准通用标记语言复杂性的问题。除了简化了文档结构外,HTML还加入了对超文本的支持,还增加了媒体功能。
网页文件的扩展名为.html或.htm。一个网页对应着一个或者多个HTML文档,web浏览器读取HTML文档后将其以网页的形式显示。
HTML文档整体结构
标记标签
是组成HTML页面的基本内容,由尖括号包括关键词,关键词可以忽略大小写。标签属性作用下,文档可以改变样式、实现插入图片、链接、表格等。
标签的种类
闭合标签
是指开始标签和结束标签组成的一对标签,带斜杠的元素表示结束。例如<body>,</body>,这种标签允许嵌套和承载内容。
元素:从开始标签到闭合标签之间的代码为元素。
块级标签
单独占一行的标签,并且标签间的元素能够随时摄者宽度、高度、顶部和底部边距等。
例如p、h1、div、ul
空标签
没有内容的标签通常用来占位,在开始标签中自动闭合,
例如br,link,meta
行内(内嵌)标签
行内标签间的元素和其他元素在同一行上,二元素的宽度、高度、顶部和底部的边距不可设置
例如span、a、label
行内-块级标签
多个行内-块级标签的元素可以显示在同一行,可以设置宽度、高度、顶部和底部边距等
例如input、img
HTML文档都是以<htmI>开头,以</html>表示文档结尾,即根标签。
头部(head):描述浏览器所需的信息,如页面标题、关键词、说明等,开始标签,结束标签。
主体(body):包含网页所要展示的具体内容,以开始,以<body>开始,以</body>结束。
树形结构:整个文档通过标签嵌套形成一个树形结构。网络爬虫进行信息提取时,通常将HTML文档转换成树结构再进行选择。


• <html>:文件开始标签,表示该文件是以超文本标识语言(HTML)编写的。 <html>标签是成对出现的,首标签<html>和尾标签</html>分别位于文件的 最前面和最后面,文件中的所有文件和HTML标签都包含在其中。
• <head>:文件头部标签。习惯上,把HTML文件分为文件头和文件主体两个部 分。文件主体部分就是在Web浏览器窗口的用户区内看到的内容,而文件头部分 用来规定该文件的标题(出现在Web浏览器窗口的标题栏中) 和HTML文件的一 些属性,包含文件的标题、 编码方式及URL等信息。这些信息大部分是用于提供 索引、辨认或其他方面的应用。
• <body>:页面的主体标签,包含很多属性,如text设定页面文字颜色、bgcolor 设定页面背景颜色、background设定页面背景图像、bgproperties设定页面背景图 像为固定(不随页面的滚动而滚动)、link设定页面默认的链接颜色、alink设定鼠标正在单击时的链接颜色、vlink设定访问过后的链接颜色、topmargin设定页面的 上边距、leftmargin设定页面的左边距;等等。
• <title>:文件标题标签,表示该网页的名称,写在<head>与</head>中间的文本,作为窗口的名称显示在这个网页窗口的最上方。
• <meta>:元信息标签,提供关于HTML文档的元数据,一般用来定义页面信息 的名称、关键字、作者、字符编码、关键词、页面描述、最后修改时间等。meta 标签提供的信息是用户不可见的,不显示在页面中,不需要设置结束标签,在一 个尖括号内就是一个meta内容, 而在一个HTML头页面中可以有多个<meta>标签。 <meta>标签使用charset属性声明Web文档的字符编码。例如:<meta charset =utf-8>

<base>:用来指定页面中所有超链接的基准路径,
简化包含相对路径的超链接的转换过程。
例如,如果在p.html中有如下的<base>标签,
<base href="http://www.a.b.c/aaa/" />
那么,<img src="images/p2.gif">表示从
http://www.a.b.c/aaa/images/p2.gif
获得图片文件。
<link>:用于链接外部css样式表等其他相关外部资源。
包含属性:rel 必填,表明当前文档和外部资源的关系;
href 指明外部资源文件的路径,即告诉浏览器外部资源的位置;
type 说明外部资源的MIME 类型,如text/css;
title属性:ref=stylesheet时css样式会作为默认样式加载并渲染
<p>:定义段落。可以将要显示的文章内容放在<p>与</p>标签之间。
该标签会自动在段落前后添加一些空白,可以使用CSS来进行调整。
通常在Web页面中正文部分的各个段落都是通过该标签来表示。
例如:<p>This is a para.</p>•
<a> :定义超链接,用于从一张页面链接到另一张页面,
其最重要的属性是href,它指示链接的目标。
href是Hypertext Reference的缩写,意思是指定超链接目标的URL。a标签的target属性:
① _self:默认值,在相同的框架或者当前窗口中打开链接
② _blank:在一个新的窗口中打开链接
③ _parent:在上一层窗口中打开链接
④ _top:会清除所有被包含的框架,并打开链接
<a href='http://www.baidu.com/' target='_blank'>跳转到baidu</a> <img>:向网页中嵌入一幅图像,没有结束标签•两个必需属性:
• src 属性:规定显示图像的URL;
•绝对 URL:指向以Web站点根目录为参考基础的目录路径或者其他站点
•相对 URL:指向站点内的文件
• alt 属性:规定在图像无法显示时的替代文本,如
<img src="imgs/computer.jpg" alt="笔记本电脑" />,
若地址错误则显示为: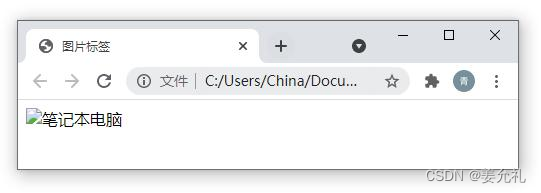

• <ul>:无序列表标签,表示无序列表的整体,用于包裹li标签;ul标签中只允许包含li标签;
• <ol>:有序列表标签,表示有序列表的整体,用于包裹li标签;ol标签中只允许包含li标签;
• <li>:表示无序列表的每一项,用于包含每一行的内容;li标签可以包含任何内容;列表每一行前默认显示圆点
•
<div>:用来定义文档中的分区或节,把文档分割成为独立的部分,经常用于网页布局。div是division的简写,意为分割、区域、分组。
•该标签通常会使用id 或 class 属性设计额外的样式,
• id用于标识单独的唯一的元素,在页面里面只能出现一次,不能重复使用。定义id的css是用#号
• class用于元素组(理解为某一类元素),是一种全局属性,可用于任何HTML元素。其主要目的是为元素提供一个或多个类名,这些类名可以在CSS中引用,以添加样式,或者在JavaScript中引用,以操纵元素。可以在页面里面重复使用。定义class的css是用点。例如,在CSS中,可通过.classname选择器来应用样式:
<div class="red-text">Hello,World!</div>
.red-text {
color:red;
}script>:用于在html页面内插入脚本。其type属性为必选的属性,用来指示脚本的 MIME 类型。下面的代码在html页面内插入javascript脚本,在网页中输出“HelloWorld!”。
<script type="text/javascript">document.write("Hello World!")</script>CSS层叠样式表
层叠样式表单(Cascading Style Sheet):是一种标记语言,用于为HTML文档定 义布局。例如,CSS涉及字体、颜色、边距、高度、宽度、背景图像、高级定位等方面。运用CSS样式可以让页面变得美观。
从HTML 4开始使用,定义如何显示HTML元素。即使是相同的HTML文档,应用不同的CSS,从浏览器看到的页面外观也会不同。

属性选择器:通过属性来选择标签。这些属性既可以是标准属性(HTML中默认该有的属性, 例如input标签中的type属性),也可以是自定义属性。
在HTML中,通过各种各样的属性,可以给元素增加很多附加信息。例如,在一个HTML页面 中,插入了多个标签,并且为每个标签设定了如字体大小、颜色等。示例代码如下:

在HTML中为标签添加属性之后,就可以在CSS中使用属性选择器选择对应的标签,来改变样式。在使用属性选择器时,需要声明属性与属性值,声明方法如下:

其中att代表属性;val代表属性值。给标签定义属性和属性值时,可以任意定义属性。
如下代码就可以实现为相应的标签设置样式。

ID选择器:通过 HTML页面中的ID属性来选择增添样式,与类选择器的基本相同,但需要注意的是由于HTML页面 不能包含有两个相同的id标签,因此定义的ID选择器也就只能被使用一次。
![]() ID选择器前面有一个 “#”号。其语法如下:
ID选择器前面有一个 “#”号。其语法如下:

类选择器:名称由用户自己定义,并以“.”号开头,定义的属性与属性值也要遵循css规范。要应用类别选择器的HTML标签,只需使用class属性来声明即可。其语法如下:

ID选择器引用id属性的值,而类选择器引用的是class属性的值。
在一个网页中标签的class属性可以定义多个,而ID属性只能定义一个。比如一个页面中只能有一个标签的ID的属性值为“intro”。
添加到HTML中的方式
•(1)内联样式:在相关的标签中使用样式属性,当特殊的样式需要应用到个别元素时可以使用;样式属性可以是任何CSS属性,主要使用的属性为style。例如:
<p style="color:blue">This is a paragraph.</p> 设置段落颜色。
•(2)内部样式表:头部通过标签定义内部样式表
•(3)外部引用:当样式需要被很多页面引用时,可以使用独立的外部CSS文件,这样可以简单页面模式的设计。
<head>
<link rel="stylesheet" type="text/css" href="css/mystyle.css">
</head><link>标签中,“rel=stylesheet”,rel是relations的缩写,关联的意思,关联的是一个样式表(stylesheet)文档,它表示这个link在html文档初始化时将被使用。rel是指关联到一个stylesheet(样式表单)。这句话的意思就是在html文件里边引入了一个css的外部样式链接,type说的是类型是css,href是链接的地址,这个css文件叫做mystyle,在css这个文件夹里边。
Web页面的组织方式
• a1.html页面中超链接的3种写法:(当前目录为aaa) • (1)采用相对链接,访问a2.html
<p><img SRC="images/p1.gif"> <a href="a2.html"> a2</a></p>• (2)采用相对链接,访问b1.html,..表示上级目录,此处即为虚拟根目录
<p><img SRC="images/p2.gif"><a href="..\bbb\b1.html"> b1</a></p>• (3)采用http开始的完整URL绝对链接,访问b1.html
<p><img SRC="images/p3.gif">
<a href="http://127.0.0.1:8080\bbb\b1.html"> b1</a> </p>对于爬虫来说,在获取a1.html页面之后,要寻找其中的href超链接。对于绝对链接,只需要把href=后面的字符串提取出来即可。而对于相对超链接,没有完整的http,单纯从这个href所指定的链接是无法知道其真正的结果,需要进行超链接的转换。爬虫程序应该检查HTML文档中是否存在标签。 为了简化相对路径转换,用标签指定所有超链接基准路径。如在a1.html 中增加如下:
<base href=”http://127.0.0.1:8080/aaa/”/>编码体系与规范(了解)
• 网页编码:编码就是按照规则对字符进行翻译成对应的二进制数,在计算器中运行 存储,用户看的时候(比如浏览器),在用对应的编码解析出来用户能看懂的;
• (1)ASCII:一个英文字母(不分大小写)占一个字节的空间。标准ASCII码使用 七位二进制编码(扩展的是用一个字节),表示美式英语中的可打印字符(例如数 字0-9、大小写英文字母、标点符号、运算符号、美元符号)以及控制字符(例如退 格、空格),编码范围为0~127。汉字等不能被表示。
• (2)中文字符编码。主要有gb2312、gbk以及gb18030。gb2312使用两个字节连 在一起表示一个汉字,两个字节中前一个称为高字节(范围0xA1-0xF7),后一个 为低字节(范围0xA1-0xFE)。gb2312共收录6763个汉字,每个汉字占两个字节。 gbk编码只识别中文,是gb2312的扩展,gbk兼容gb2312的所有内容同时又增加了 近20000个新的汉字(包括繁体字)和符号。
• (3)unicode:容纳世界上所有语言字符和符号的集合; 通常使用两个字节来编码, 称为UCS-2(Universal Character Set coded in 2 octets)。为了使unicode能表示更多的文字,人们提出了UCS-4使用四个字节编码。 unicode编码范围为0- 0x10FFFF,最大的字符需要至少三个字节来表示。为了解决编码字符集unicode在 网页中使用的效率问题,utf-8、utf-16等编码方式被提出。
• (4)utf-8(8-bit unicode Transformation Format)是一种针对unicode字符集的可变长度字符编码方式。utf-8对不同范围的字符使用不同长度的编码。其中,1个英 文字符 = 英文标点 = 1个字节,1个中文(含繁体) =中文标
• Python 3中的字符串默认的编码为unicode,因此,gbk、gb2312等字符编码与utf-8 编码之间都必须通过unicode编码才能互相转换。即在python中,使用encode()将 unicode编码为utf-8、gbk等,而使用decode()将utf-8、gbk等字符编码解码为 unicode
• >>> n='大数据' #unicode
• >>> g=n.encode('gbk') #gbk
• >>> u=n.encode('utf-8') #utf-8
• >>> g2=n.encode('gb2312') #gb2312
• >>> g2u=g.decode("gbk").encode("utf-8") #gbk转成utf-8网络通讯
web服务器工作原理
• ( 1 ) 建 立 连 接 : 客 户 端 通 过 T C P / I P 协 议 建 立 到 服 务 器 的 T C P 连 接 。
• ( 2 ) 请 求 过 程 ( R e q u e s t ) : 客 户 端 向 服 务 器 发 送 H T T P 协 议 请 求 包 , 请 求 服 务 器 里 的 资 源 文 档 。 每 一 个 用 户 打 开 的 网 页 都 必 须 在 最 开 始 由 用 户 向 服 务 器 发 送 访 问 的 请 求 。 当 在 浏 览 器 输 入 U R L 后 , 浏 览 器 会 先 请 求 D N S 服 务 器 , 获 得 请 求 站 点 的 I P 地 址 ( 即 根 据 U R L 地 址 “ w w w . m i n g r i s o f t . c o m ” 获 取 其 对 应 的 I P 地 址 如 1 0 1 . 2 0 1 . 1 2 0 . 8 5 ) , 然 后 发 送 一 个 H T T P R e q u e s t ( 请 求 ) 给 拥 有 该 I P 的 主 机 。
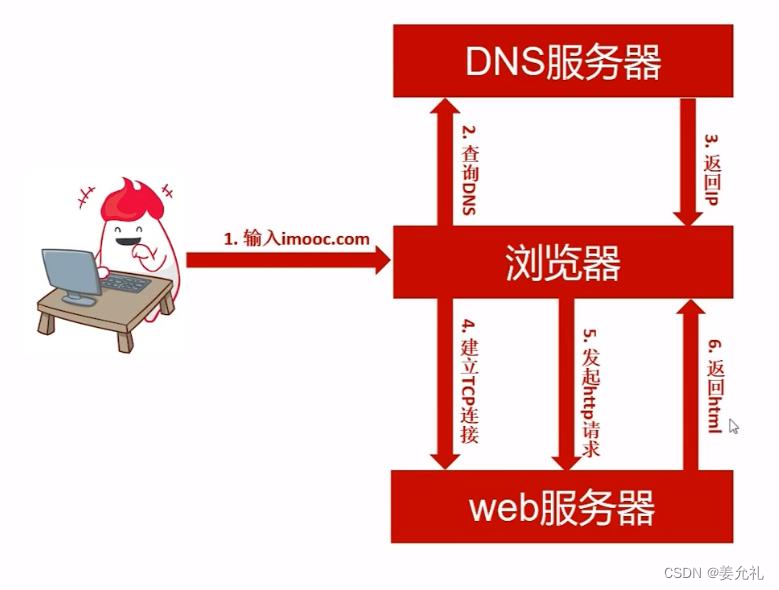
• ( 3 ) 响 应 过 程 ( R e s p o n s e ) : 服 务 器 在 接 收 到 用 户 的 请 求 后 , 会 验 证 请 求的 有 效 性 , 然 后 向 用 户 发 送 相 应 的 内 容 。 即 为 网 页 服 务 器 接 收 用 户 访 问 请 求, 处 理 请 求 , 产 生 响 应 ( 即 把 处 理 结 果 以 H T M L 文 档 形 式 返 回 给 浏 览 器 ) , 客 户 端 接 收 到 服 务 器 的 相 应 内 容 后 , 浏 览 器 经 过 C S S 渲 染 , 以 一 种 较 好 的 效 果 呈 现 给 用 户 , 以 供 用 户 浏 览 。
• ( 4 ) 关 闭 连 接 : 客 户 端 与 服 务 器 断 开 。
robots协议(了解)
• 为了给Web网站提供灵活的控制方式来决定页面是否能够被爬虫采集,1994年搜索行业正式发布了一份行业规范,即Robots协议。
• Robots协议又称为爬虫协议、机器人协议等,其全称是Robots Exclusion Protocol, 即“网络爬虫排除协议”。是互联网爬虫的一项公认的道德规范。
• 访问许可策略:网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不能抓 取。该协议指定了某种标识的爬虫能够抓取的目录或不能抓取的目录。
• 具体约定:文件中包含一个或多个记录,每个记录由一行或多行空白行隔开。Useragent的使用方式是User-agent [agent_name],其中agent_name典型的有两种,即 *和具体的爬虫标识。Disallow和Allow的使用决定了不同的访问许可。一个目录如果没有显式声明为Disallow时,它是允许访问的。
• 在编写爬虫程序时,了解robots的拓展功能,对于设计更加友好的爬虫是非常有益的。这些拓展功能主要有:通配符的使用、抓取延时、访问时段、抓取频率和 Robots版本号。
robots.txt文件:访问许可写在robots.txt文件中,该文件放在网站的虚拟根目录中, 可以公开访问,即在浏览器打开网站后,在网站首页的地址后面添加“/robots.txt”。
• 超文本传输协议(Hyper Text Transfer Protocol):基于TCP/IP协议的应用层协议, 采用请求/响应模型,通过使用Web浏览器、网络爬虫或其他工具,客户端向服务器 上的指定端口(默认端口为80)发送一个HTTP请求,服务器根据接收到的请求向 客户端发送响应信息。
• HTTP是由万维网协会(World Wide Web Consortium)和Internet工作小组 IETF(Internet Engineering Task Force)共同制定的规范。
• HTTP/1.1是目前使用最广泛的HTTP协议版本,于1997年发布。HTTP/1.1与之前的 版本相比,改进主要集中在提高性能、安全性以及数据类型处理等方面。
• HTTP协议是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证高效 而准确地传送超文本内容。
• HTTP是基于"客户端/服务器"架构进行通信的,HTTP的服务器端实现程序有httpd、 nginx等,客户端的实现程序主要是Web浏览器,例如Firefox、Internet Explorer、 Google Chrome、Safari、Opera等。此外,客户端的命令行工具还有elink、curl等。 Web服务是基于TCP的,因此为了能够随时响应客户端的请求,Web服务器需要监 听在80/TCP端口。这样客户端浏览器和Web服务器之间就可通过HTTP进行通信了。
• 请求方法:GET、POST、HEAD,规定客户端和服务器之间的通信类型。
• GET:最常见,一般用于获取或者查询资源信息;
• POST:多了以表单形式上传参数的功能(如登录),除了查询信息还可以修改信息。

HTTP报文
. request Message(请求报文):
客户端 → 服务器端
<method> <request-URL> <version> #请求方法、请求URL、协议版本
<headers> #头部、请求头、标头
#回车换行,请求结束
<entity-body> #实体,请求体请求体通过“param1=value1¶m2=value2”的键值对形式,将要传递的请求 参数(通常是一个页面表单中的组件值)编码成一个格式化串。
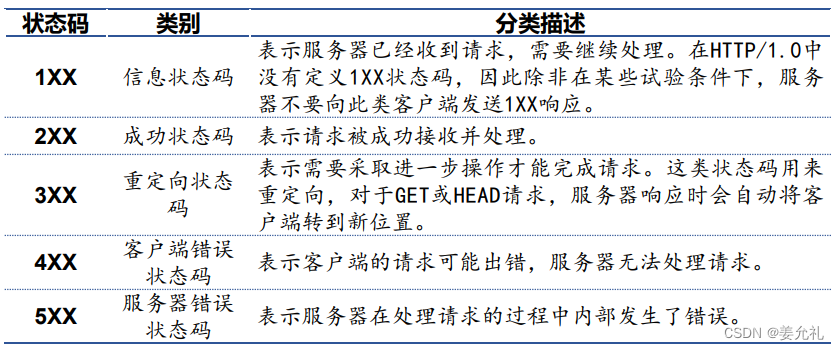
• 起始行、响应行:版本协议、状态码、原因短语;
• 响应头:包含服务器响应的各种信息,也是“属性名:属性值”形式;
• 响应体:是HTTP要传输的内容。根据响应信息的不同,响应体可以为多种类型的 数字数据,比如图片、视频、CSS、JS、HTML页面或者应用程序等。
一些常用的HTTP头部属性名:
• (1)Accept请求头表示可接受的响应内容。同时,与Accept首部类似的还有 Accept-Charset 、Accept-Encoding、Accept-Language等首部,分别表示客户端可接受的字符集、可接受的编码方式和可接受的语言。
• (2)User-Agent属性表示客户端的身份标识字符串。通过该字符串使得服务器能 够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、 浏览器语言、浏览器插件等信息。
• (3)Content-Type:标明MIME类型。
• (4)Cookie:是请求报文中可用的属性,也是客户端最重要的请求头。Cookie存储了客户端的一些重要信息,例如身份标识、所在地区等,通常是一个文本文件。 在向服务器发送URL请求时,可以将文件内容读出,附加在HTTP的请求头中,可 以免去用户输入信息的麻烦。
• 超文本传输安全协议(Hypertext Transfer Protocol Secure):通过计算机网络进 行安全通信的传输协议,即是HTTP协议的安全版本,使用SSL/TLS加密。

URL
• uniform resource locator:统一资源定位符,是因特网的万维网服务程序上用于 指定信息位置的表示方法。
• 每一个URL指向一个独特的资源,可以是一个html页面,一个CSS文档,一个图 片、文件等 • URL的一般格式为(带方括号[]的为可选项):protocol://hostname[port]/path/[; parameters][?query]#fragment,即如"协议://授权/路径?查询" ,或者“协议://用户 名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志” • 三个部分:前两部分用“://”隔开,2和3部分用“/”隔开;
• 绝对URL:URL显示文件的完整路径,这意味着绝对URL本身所在的位置与被引 用的实际文件的位置无关。 [2]
• 相对URL: 相对URL以包含URL本身的文件夹的位置为参考点,描述目标文件夹 的位置。如果目标文件与当前页面(也就是包含URL的页面)在同一个目录,那 么这个文件的相对URL仅仅是文件名和扩展名,如果目标文件在当前目录的子目 录中,那么它的相对URL是子目录名,后面是斜杠,然后是目标文件的文件名和 扩展名。 65 p URL 51
• HTTP URL的形式如下
http://<host>:<port>/<path>?<searchpart>
第三章
网络爬虫概述
爬虫概念
网络爬虫(Web Spider)又称之为网络机器人、网络蜘蛛,是一种通过既定规则(网络爬虫算法),能够自动(浏览 或者)抓取互联网信息的程序。
反爬机制
为什么会有反爬机制?原因主要有两点:
• 第一,在大数据时代,数据是十分宝贵的财富,很多企业不愿意让自己的数据被别人免费获取,因此,很多企业 都为自己的网站运用了反爬机制,防止网页上的数据被爬走;
• 第二,简单低级的网络爬虫,数据采集速度快,伪装度低,如果没有反爬机制,它们可以很快地抓取大量数据, 甚至因为请求过多,造成网站服务器不能正常工作,影响了企业的业务开展。
爬虫工作基本原理
• 网络爬虫的基本工作流程如下:
• (1)获取初始的 URL,该 URL 地址是用户自己制订的初始爬取的网页。
• (2)爬取对应 URL 地址的网页时,获取新的 URL 地址。
• (3)将新的 URL 地址放入 URL 队列中。
• (4)从 URL 队列中读取新的 URL,然后依据新的 URL 爬取网页,同时从新的网页中获取新的 URL 地址,重复上 述的爬取过程。
• (5)设置停止条件,如果没有设置停止条件时,爬虫会一直爬取下去,直到无法获取新的 URL 地 址为止。设置了 停止条件后,爬虫将会在满足停止条件时停止爬取。


用Python实现http请求
Python实现HTTP请求有以下的3种常用的库
(1)urllib库
• urllib是Python标准库中用于网络请求的库,该库有四个模块,分别是
urllib.request,
urllib.error,
urllib.parse,
urllib.robotparser。
(2)urllib3库
• urllib3提供了很多python标准库里所没有的重要特性,如线程安全、连接池、客户端SSL/TLS验证、文件编码上传、HTTP重定向、压缩编码、HTTP/SOCKS代理等。
(3)requests库
第三方库requests自称"HTTP for Humans",使用更简洁更方便。requests继承了urlib2的所有特性,requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和POST数据自动编码。
urllib模块
• 解决:Python如何访问互联网
• urllib是URL和lib两个单词共同构成的,URL就是网页的地址,lib是library(库)缩写。
• urllib是Python自带模块,用于操作网页URL,并对网页的内容进行抓取处理。(测试连通性)
• 严格地讲,urllib并不是一个模块,它其实是一个包(package),包含四个模块,对服务器请求的发出、跳转、代理 和安全等内容:
• urllib.request:用于实现基本 HTTP 请求的模块,提供打开和读取URL,如身份验证、重定向和cookie等。
• urllib.error:异常处理模块,如果在发送网络请求时出现了错误,可以捕获异常进行异常的有 效处理。包含 urllib.request抛出的异常,其中最基本的异常类是URLError • urllib.parse:提供URL解析和URL引用 • urllib.robotparser:解析robots.txt文件,判断网站是否可以爬取信息。
• urllib.parse:提供URL解析和URL引用。
• urllib.robotparser:解析robots.txt文件,判断网站是否可以爬取信息。
urllib模块发送请求:urlopen()
• urllib模块的request子模块,提供了一个urlopen()方法,通过该方法指定URL发送HTTP请求来获取数据。
• 访问网页的函数:urllib.request.urlopen( )
参数说明:
• url:需要访问网站的URL完整地址。
• data:该参数默认为 None ,通过该参数确认请求方式。如果是None,表示请求方式为GET,否则请求方式为POST。 在发送 POST请求时,参数data需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型 的数据才可以实现POST请求。(没有设置data参数时就是get请求)
• timeout:以秒为单位,设置超时。
①发送 GET 请求,读取文件

#导入库
import urllib.request
#爬取网页并赋值给变量
response = urllib.request.urlopen("http://www.jd.com")
#读取网页全部内容
#read()会把读取到的内容赋给一个字符串变量,无参数时表示读 取至文件结束为止
html = response.read()
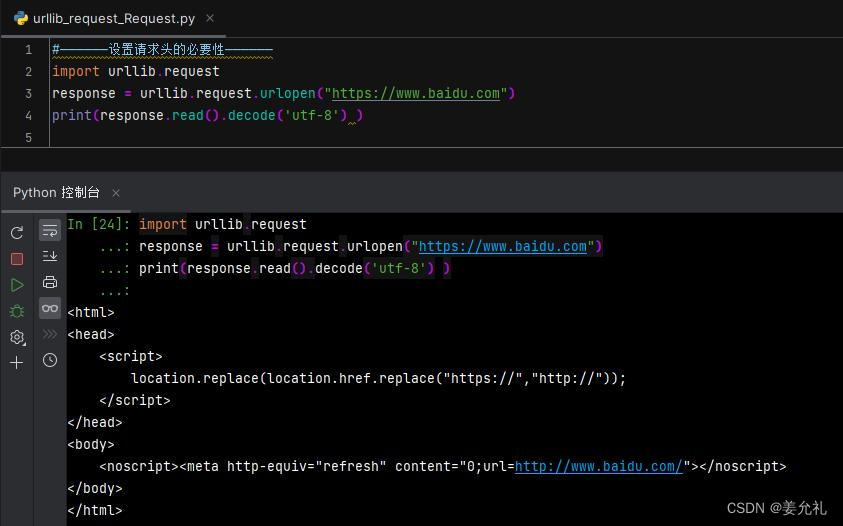
print(html)这跟在浏览器上使用“检查”功能看到的的内容是不一样的,因 为Python爬取的内容是以UTF-8编码的bytes对象,要还原为带中 文的HTML代码,需要对其进行解码,将它变成Unicode编码。
②转码:utf-8到unicode
import urllib.request
response = urllib.request.urlopen("http://www.jd.com")
#以utf-8的编码对response.read()进行解码,以获取unicode
html = response.read().decode("utf-8")
print(html)

③查看响应数据类型
import urllib.request
response = urllib.request.urlopen("http://www.jd.com")
print('响应数据类型为:',type(response))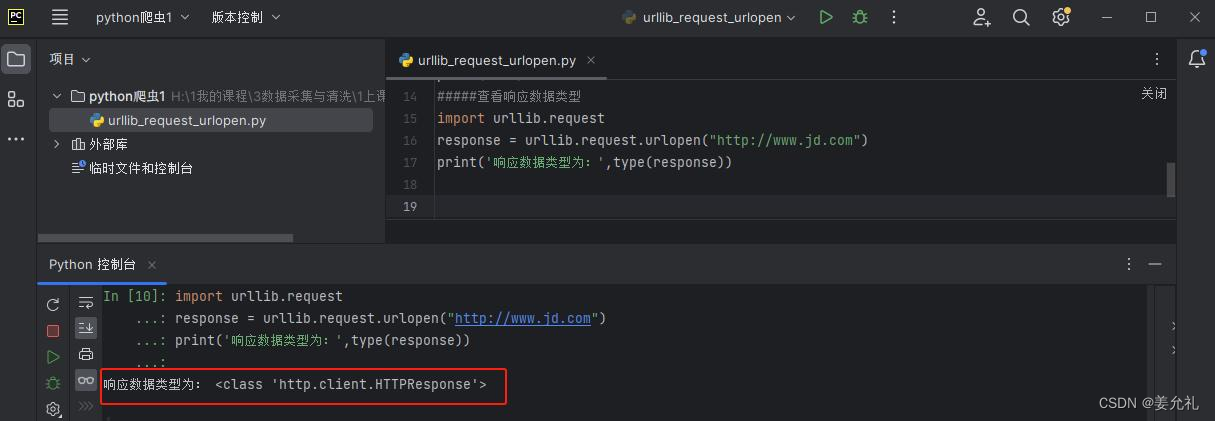
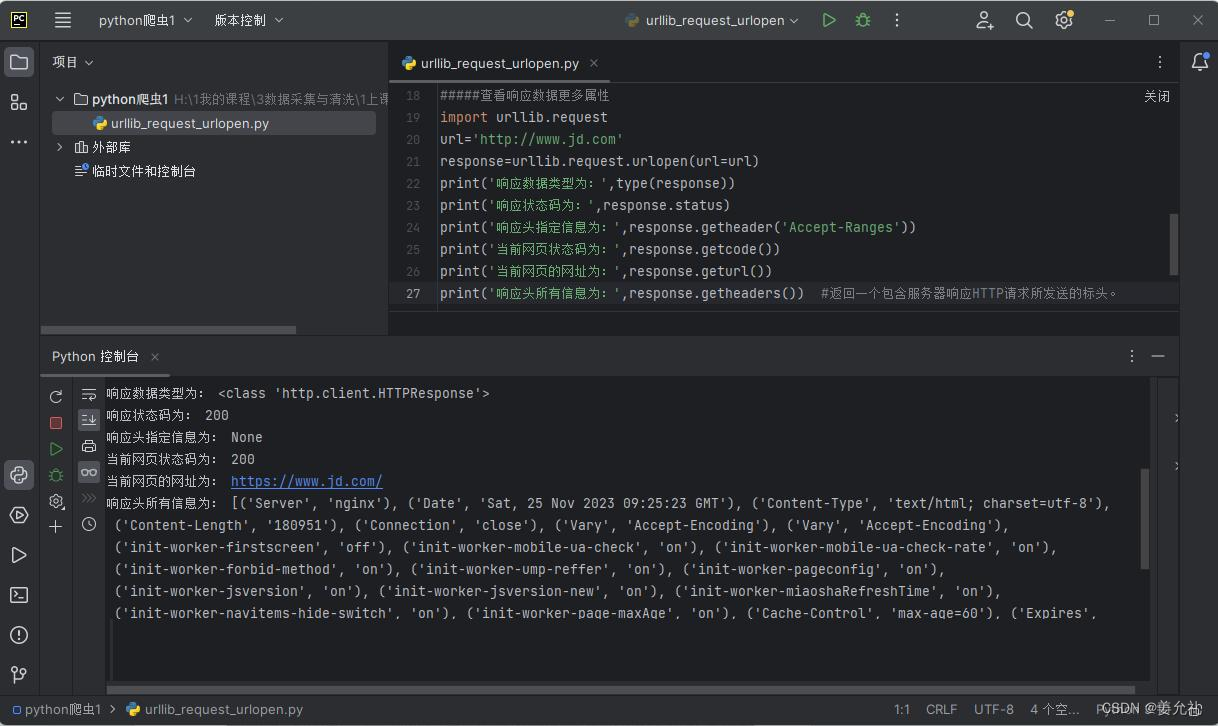
④查看响应数据更多属性
import urllib.request
url ='http://www.jd.com'
response=urllib.request.urlopen(url=url)
print('响应数据类型为:',type(response))
print('响应状态码为:',response.status)
#Accept-Ranges表示服务器是否支持以byte为单位的一定资源范围的请求
print('响应头指定信息为:',response.getheader('Accept-Ranges'))
print('当前网页状态码为:',response.getcode())
print('当前网页的网址为:',response.geturl())
print('响应头所有信息为:',response.getheaders()) #返回一个包含服务器响应HTTP请求所发送的标头。在使用 urlopen() 方法实现一个网络请求时,所返回的是一个“http.client.HTTPResponse” 对象。在 HTTPResponse 对象中包含可以获取信息的方法以及属性。
•例如请求一个文件的200byte—400byte的数据:
• Accept-Ranges:bytes 表示该资源支持byteurl='http://www.jd.com'形式资源范围请求
• Accept-Ranges:none则表示不支持
发送 POST 请求 (疑惑)
urllib.request.urlopen
( url, data=None, [ timeout,]*, cafile=None, capath=None,cadefault=False, context=None)• urlopen()方法在发送 POST请求时,参数data需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据。
•发送POST请求,需要设置data参数,该参数是bytes类型,所以需要使用bytes()方法,将原始字典形式数据的参数值,进行数据类型的转换。
•配合parse.urlencode。
•原始参数值为表单数据,是指通过表单让用户填写内容,然后提交到服务器上

• Urllib模块中提供了 parse子模块,主要用于解析URL,可以实现URL的拆分或者是组合。
• 支持多种协议的 URL 处理,如 file、ftp、gopher、 hdl、http、https
• urlencode()方法:接收一个字典类型的值
• 所以要想将URL进行编码需要先将请求参数定义为字典类型,然后再调用urlencode()方法进行请求参数的编码

• 编码后的请求地址为: http://httpbin.org/get?name=Jack&country=%E4%B8%AD%E5%9B%BD&age=30
• 地址中“%E4%B8%AD%E5%9B%BD&”内容为中文(中国)转码后的效果。

import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url= 'https://www.httpbin.org/post' # POST请求测试地址
# 将表单数据转换为bytes类型,并设置编码方式为UTF-8
data = bytes(urllib.parse.urlencode({'hello' :'python'}),encoding='utf-8')
response= urllib.request.urlopen(url=url,data=data) #发送网络请求
print(response.read().decode('utf-8')) # 读取HTML代码并进行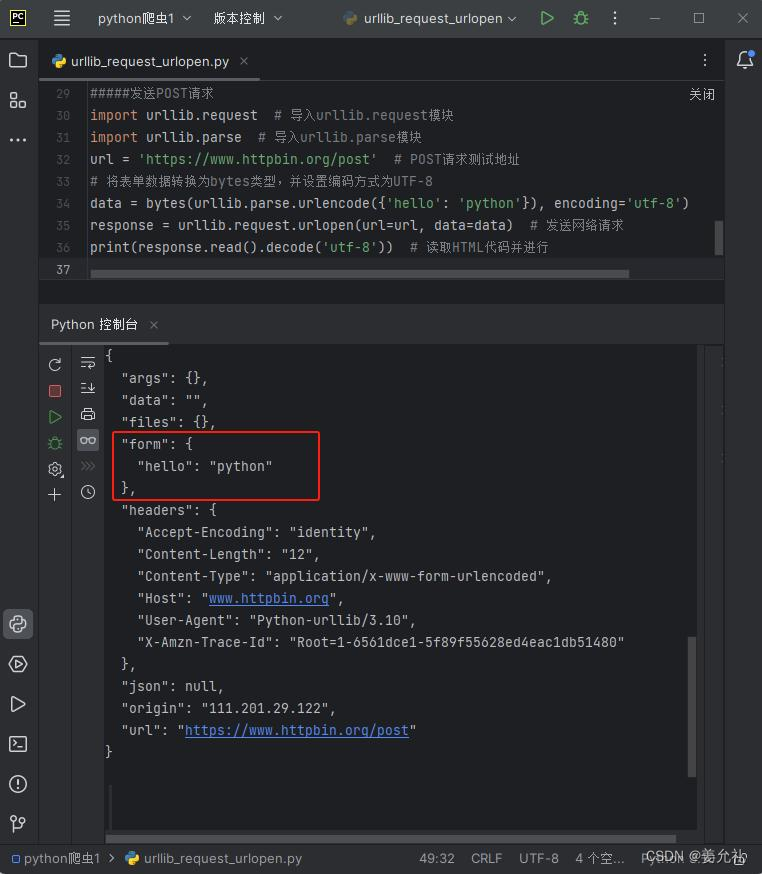
Request类
• 有时在请求一个网页内容时,会发现无论通过GET、 POST以及其他请求方式,都会出现403或者404错误。
• 这种现象多数为服务器拒绝了您的访问,那是因为这 些网页为了防止恶意采集信息,所使用的反爬虫设置。
• 此时可以通过模拟浏览器的头部信息来进行访问,这样就能解决以上反爬设置的问题。
• 设置请求头是爬虫程序中必不可少的一项设置,大多 数网站都会根据请求头内容制订一些反爬策略。
• 如果要构建一个完整的网络请求,还需要在请求中添加Headers 、Cookies 以及代理 IP 等内容,这样才能更好的模拟一个浏览器所发送的网络请求。Request 类则可以构建一个多种功能的请求对象。
urllib.request.Request
(url,data=None, headers={},
origin_req_host=None,
unverifiable=False,
method=None)参数说明:
• url:需要访问网站的URL完整地址。
• data:该参数默认为None,通过该参数确认请求方式,
如果是None,表示请求方式为GET,否则请求方式为 POST。
在发送POST请求时,参数data需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据才可以实现POST请求。
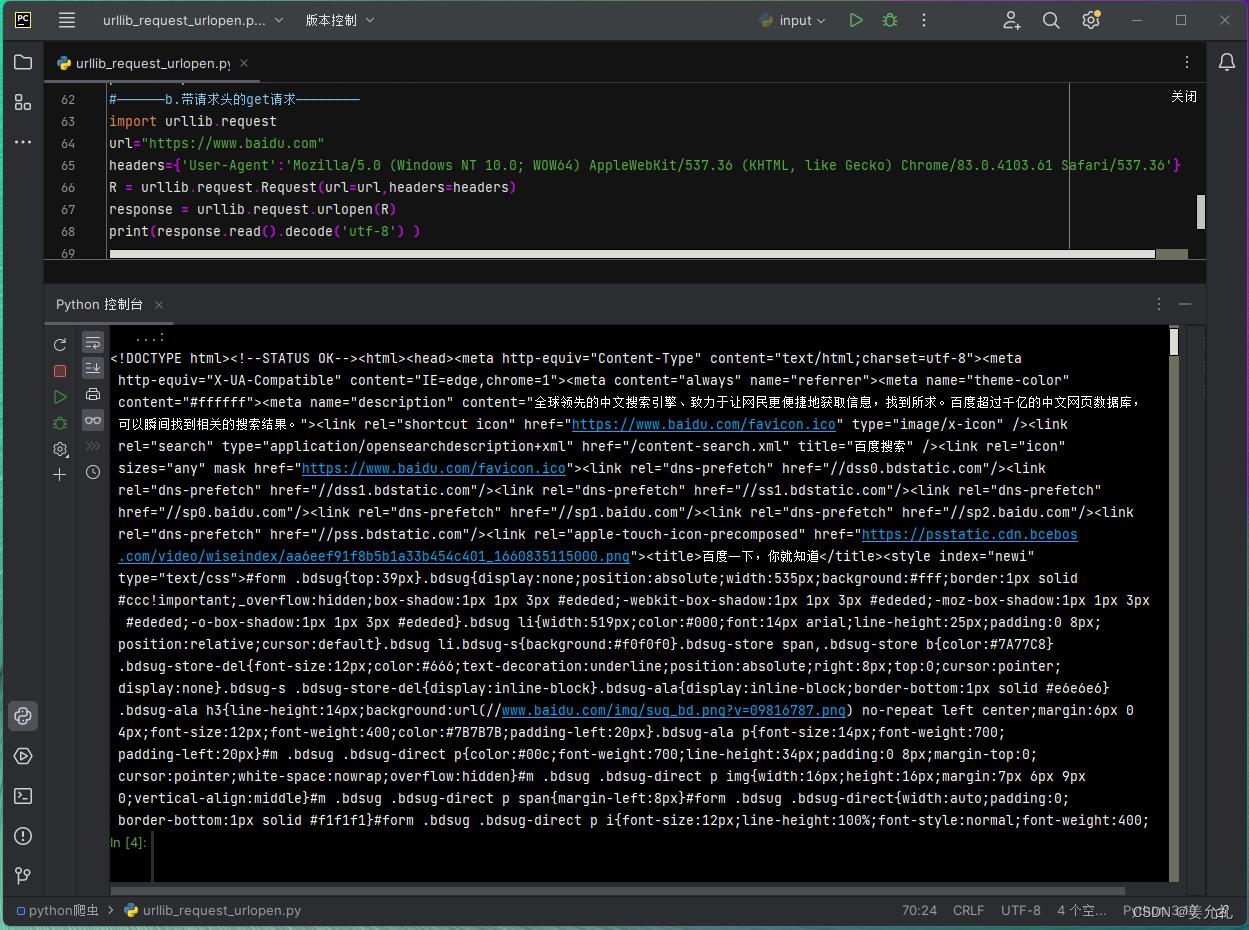
• headers:设置请求头部信息,该参数为字典类型。添加请求头信息最常见的用法就是修改User-Agent来伪装成浏览器。
例如,
headers={'UserAgent':'Mozilla/5.0(WindowsNT10.0;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/83.0.4103.61Sa fari/537.36'},表示伪装谷歌浏览器进行网络请求。
• method:用于设置请求方式,如GET、POST等,默认为GET请求(POST除了设置data,还需要再次明确method)
urllib.request.urlopen ( url, data=None, [ timeout,]*, cafile=None, capath=None, cadefault=False, context=None)设置请求头
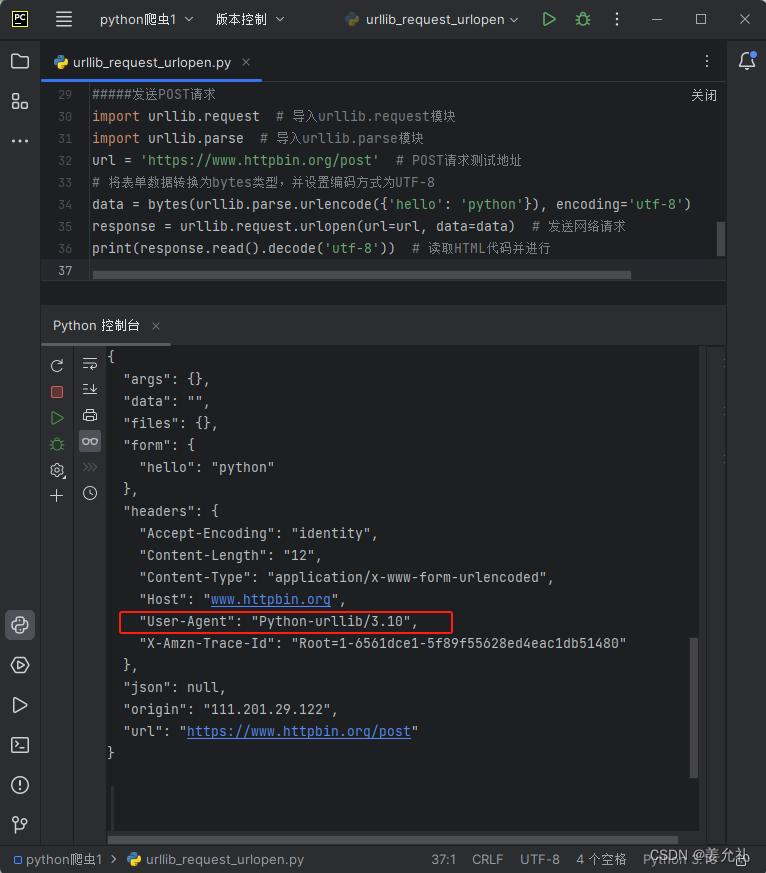
• 设置请求头参数是为了模拟浏览器向网页后台发送网络请求,这样可以避免服务器的反爬措施。
• 使用urlopen()方法发送网络请求时,其本身并没有设置 请求头参数,所以以https://www.httpbin.org/post请求测试地址发送请求时,返回的信息中headers将显示如图所示的默认值。
• User-Agent:中文名为用户代理,简称 UA,是一个特 殊字符串头,使得服务器能够识别客户使用的操作系统 及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、 浏览器语言、浏览器插件等。
• 常常要用server抓资料时,都会碰到直接使用wget和curl 被服务器拒绝的状况。通常简单加个user-agent伪装一 下就会过了。
•所以在设置请求头信息前,需要在浏览器中找到一个有效的请求
头信息。
•【方法1】在浏览器地址栏输入
about:version
•显示:用户代理 Mozilla/5.0
(Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML,
like Gecko)
Chrome/94.0.4606.71
Safari/537.36 SE 2.X MetaSr 1.0

•【方法2】以谷歌浏览器为例,键盘中按下快捷键打开“开发者工具”,或者右键“检查”,然后选择Network选项,在请求列表Name中选择一项请求信息(如对应网),最后在Headers选项中找到请求头信息。

•如果需要设置请求头信息,首先通过Request类构造一个带有headers请求头信息的Request对象,然后为urlopen()方法传入Request对象,再进行网络请求的发送。
•【例】设置请求头的必要性
• 如果需要设置请求头信息,首先通过Request类构造一个带有headers请求头信息的Request对象,然后为urlopen() 方法传入Request对象,再进行网络请求的发送。
【例】Request类设置请求头发送POST请求
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
# 设定请求网址
url = 'https://www.httpbin.org/post'
# 将表单数据转换为bytes类型,并设置编码方式为utf-8
data = bytes(urllib.parse.urlencode({'hello': 'python'}), encoding='utf-8')
# 设定请求头信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
# 创建Request对象
R = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
# 发送网络请求
response = urllib.request.urlopen(R)
# 读取HTML代码并进行utf-8解码
print(response.read().decode('utf-8'))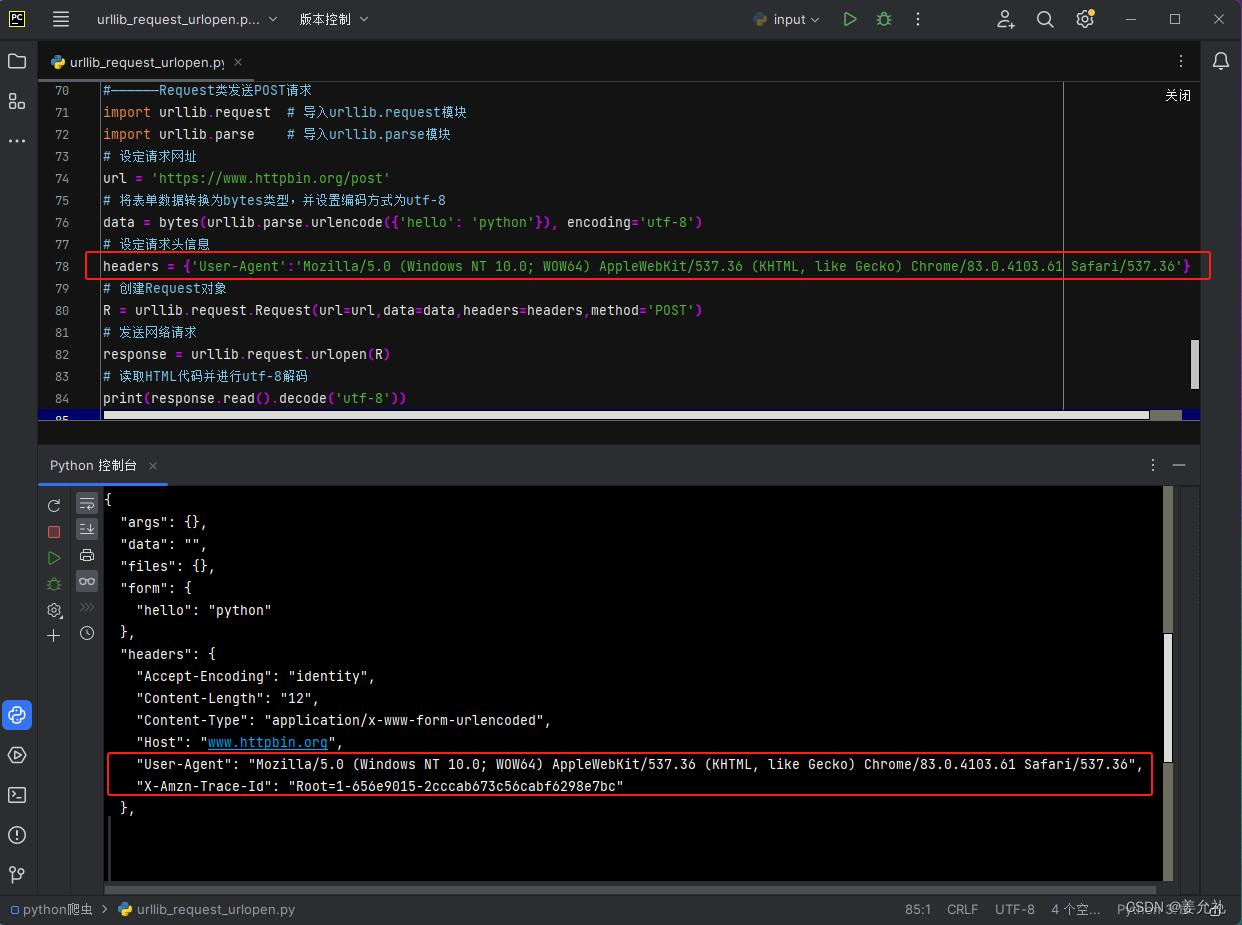
urllib3模块
urllib3模块发送请求:request()
• 使用urllib3模块发送网络请求时,首先需要创建PoolManager对象,通过该对象调用request()方法来实现网络请求的发送。
request (method, url, fields = None, headers = None )常用参数说明:
• method :必选参数,用于指定请求方式,如GET、POST、PUT等。使用urllib3模块向服务器发送POST请求时并不 复杂,与发送GET请求相似,只是需要在request()方法中将method参数设置为“POST” ,然后将fields参数设 置为字典类型的表单参数。
• url :必选参数,用于设置需要请求的URL地址。
• fields :可选参数,用于设置请求参数。
• headers :可选参数,用于设置请求头
GET请求
• 用urllib3发送请求,所返回的是一个“urllib3.response.HTTPResponse” 对象。
import urllib3 # 导入urllib3模块
url = "http://www.jd.com"
PM = urllib3.PoolManager() # 创建连接池管理对象
r = PM.request('GET',url) # 发送GET请求
print(r.status) # 打印请求状态码
print('响应数据类型为:',type(r)) # 查看返回对象
#——————例1:可以合并,可设置参数——————
import urllib3 # 导入urllib3模块
url = "http://www.jd.com"
r = urllib3.PoolManager().request(method='GET',url=url) # 创建连接池管理对象,发送get请求
# print(r.status) # 打印请求状态码
# print('响应数据类型为:',type(r)) # 查看返回对象
print('响应对象的属性包括:',dir(r))
print('返回结果:',r.data.decode('utf-8'))一个PoolManager对象就是一个连接池管理对象,通过该对象可以实现向多个服务器发送请求。
urlib3.disable_wamnings() 是一个Python库中的函数, 用于禁用SSL证书验证警告。 在使用urlib3库发送HTTPS 请求时,如果目标网站的 SSL证书不受信任,会出现 警告信息。使用该函数可以 禁用这些警告信息,但同时也会降低安全性。
#——————例2:使用PoolManager对象向多个服务器发送GET请求——————
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
jingdong_url = 'https://www.jd.com/' # 京东url地址
python_url = 'https://www.python.org/' # Python url地址
baidu_url = 'https://www.baidu.com/' # 百度url地址
PM = urllib3.PoolManager() # 创建连接池管理对象
r1 = PM.request('GET',jingdong_url) # 向京东地址发送GET请求
r2 = PM.request('GET',python_url) # 向python地址发送GET请求
r3 = PM.request('GET',baidu_url) # 向百度地址发送GET请求
print('京东请求状态码:',r1.status)
print('python请求状态码:',r2.status)
print('百度请求状态码:',r3.status)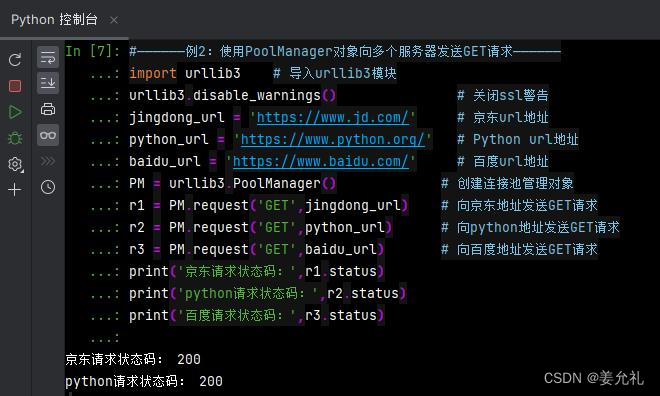
POST请求
发送post请求同样使用request方法,只需要将request方法中的method参数设置为POST,将fields参数设置为 字典类型的表单参数。
#——————例3:使用request方法实现POST请求——————
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/post' # post请求测试地址
params = {'name':'Jack','country':'中国','age':30} # 定义字典类型的请求参数(随意写)
PM = urllib3.PoolManager() # 创建连接池管理对象
r = PM.request('POST',url,fields=params) # 发送POST请求
print('返回结果:',r.data.decode('utf-8')) # 中国显示的是Unicode编码
print('返回结果:',r.data.decode('unicode_escape'))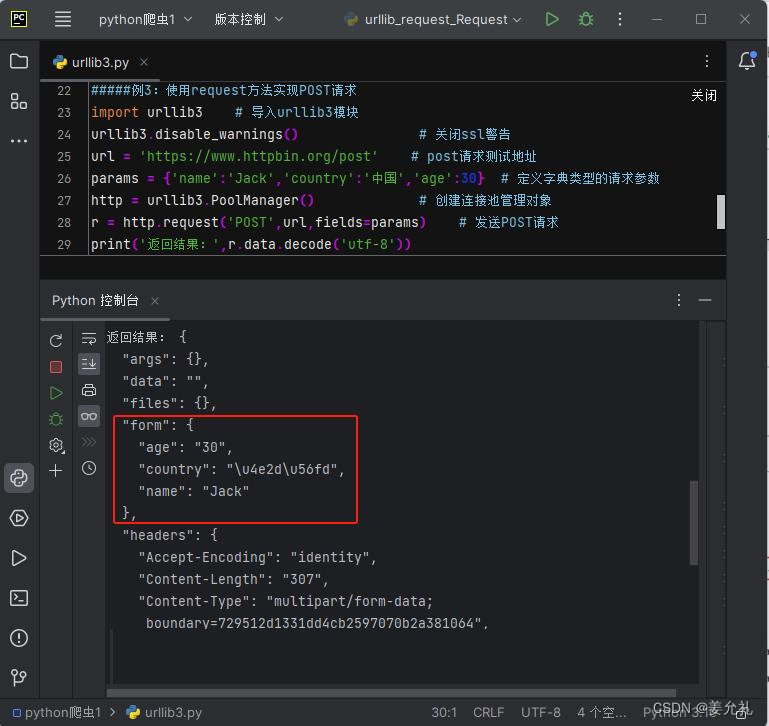
使用request方法实现POST请求 • 发现:JSON信息中的form对应的数据为表单 参数,只是country所对应的并不是“中国” 而是一段Unicode编码,对于这样的情况,可 以将请求结果的编码方式设置为 “unicode_escape”。关键代码如下:
![]()
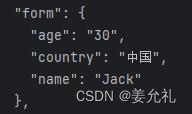
任意编码的字符串,如果内容是unicode码, 如:’\u53eb\u6211’ ,注意看乱码前面有个u, 这表示使用的unicode编码字符。使用 decode('unicode_escape')命令,对字符串内容 按照unicode解码后得到其对应的汉字。
重试请求
urllib3模块可以自动重试请求,这种相同的机制还可以处理重定向。在默认情况下request方法的请求重试次数为 3次,如果需要修改重试次数可以设置retries参数。
#——————例4:通过retries参数设置重试请求——————
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
PM = urllib3.PoolManager() # 创建连接池管理对象
r = PM.request('GET',url) # 发送GET请求,默认重试请求
r1 = PM.request('GET',url,retries=5) # 发送GET请求,设置5次重试请求
r2 = PM.request('GET',url,retries=False) # 发送GET请求,关闭重试请求
print('默认重试请求次数:',r.retries.total)
print('设置重试请求次数:',r1.retries.total)
print('关闭重试请求次数:',r2.retries.total)
处理响应信息
发送网络请求后,将返回一个 HTTPResponse对象,通过该对象中的info()方法即可获取HTTP 响应头信息,该信息为字典(diet) 类型的数据,所以需要通过for循 环进行遍历才可清晰的看到每条 响应头信息内容。
• https://www.httpbin.org/get
• 查看网页的响应头,发现共有7项
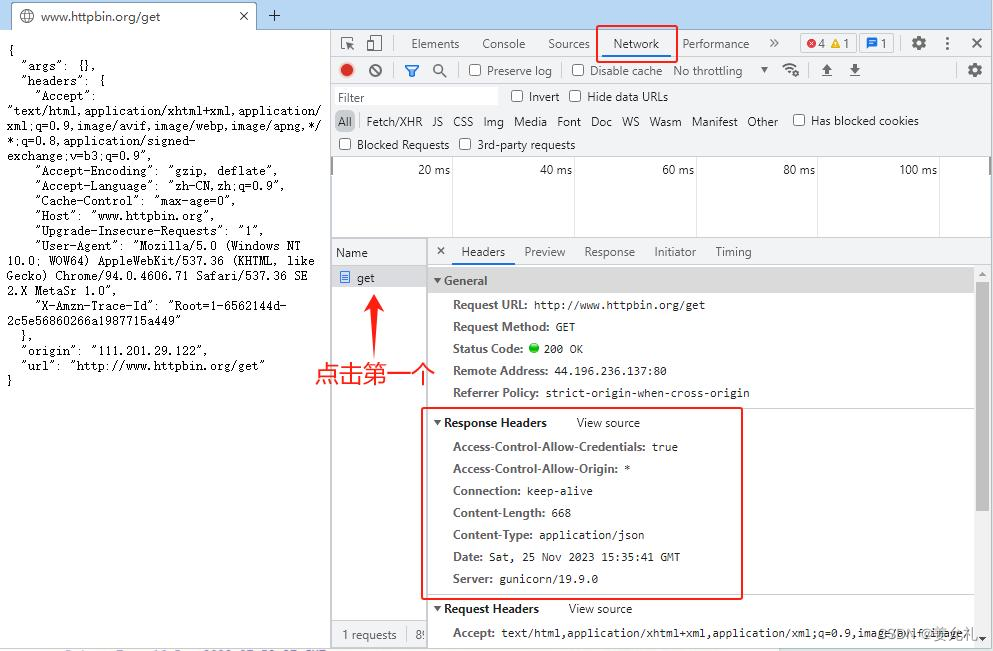
#——————例5:通过info()方法获取响应头信息——————
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
PM = urllib3.PoolManager() # 创建连接池管理对象
r = PM.request('GET',url) # 发送GET请求,默认重试请求
response_header = r.info() # 获取响应头
print(response_header.keys())
for key in response_header.keys(): # 循环遍历打印响应头信息
print(key,':',response_header.get(key))

for key in response_header.keys(): # 循环遍历打印响应头信息
print(key,':',response_header.get(key))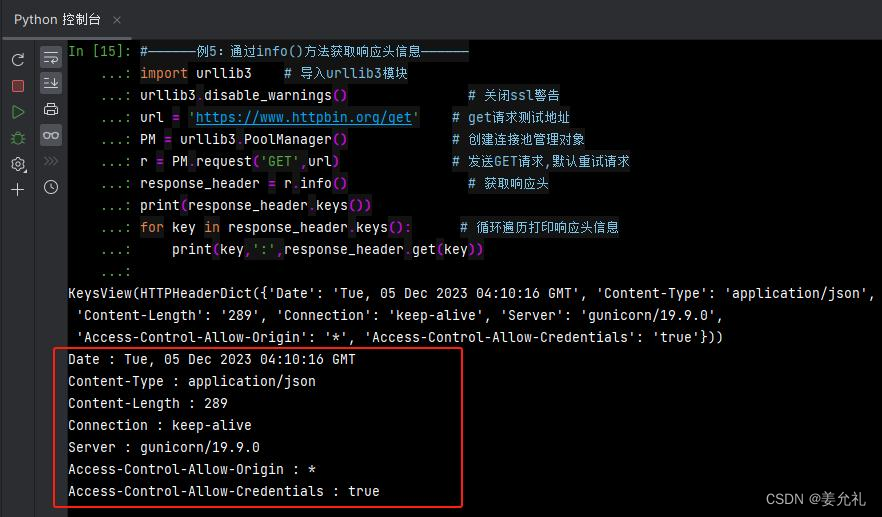
设置请求头
请求头信息获取完成以后,将“User-Agent”设置为字典(dict)数据中的键,后面的数据设置为字典(dict)中value。
#——————例6:设置请求头信息——————
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
# 定义火狐浏览器请求头信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
PM = urllib3.PoolManager() # 创建连接池管理对象
r = PM.request('GET',url,headers=headers) # 发送GET请求
print(r.data.decode('utf-8')) # 打印返回内容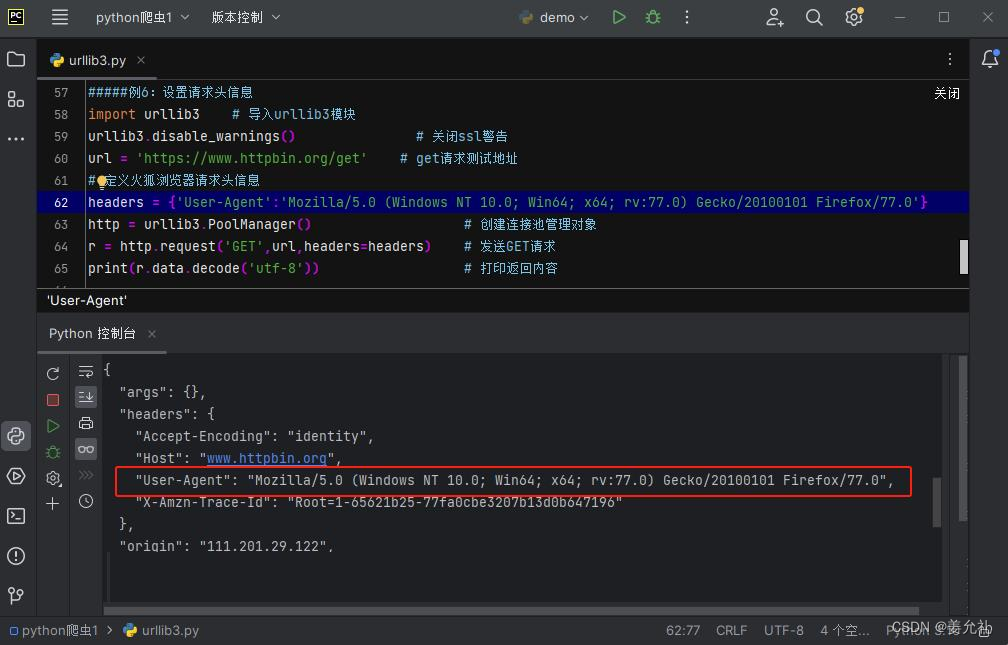
requests模块
由于requests模块为第三方模块,所以在使用requests模块时需要通过执行命令“pip install requests” 进行该 模块的安装。如果使用了 Anaconda则不需要单独安装requests模块。
使用requests模块实现GET请求时可以使用两种方式来实现,一种是带参数,另一种为不带参数。
requests.get (url, params=None, **kwargs)参数说明:
• url:需要访问网站的URL完整地址
• params:该参数默认为 None ,是请求 url 时的额外参数,可以是字典或者字节流格式
• **kwargs:用于控制请求的一些附属特性,包括headers、cookies、params、proxies等,总共有12个控制参数。
(1) headers: Python 中的字典型变量,可以模拟任何浏览器标识来发起url。
(2) cookies :字典或CookieJar ,指的是从HTTP中解析 Cookie
(3) timeout :用于设定超时时间,单位为秒。当发起 GET请求时可以设置timeout 时间,如果在timeout时间内 请求内容没有返回,将产生一个timeout异常
(4) proxies :字典,用来设置访问代理服务器
(5) params :字典或字节序列,作为参数添加到url中,可以把一些键值对以?key1=value1& key2=value2式添加到url
【例1】以京东为例,实现不带参数的GET网络请求
#——————例1:不带参数的get请求——————
import requests # 导入网络请求模块request
response = requests.get('http://www.jd.com') # 发送网络请求
response.encoding = 'utf-8' # 对响应结果进行UTF-8编码
# print(response.text) # 以文本形式打印网页源码
print('网页源码为:',response.content) # 以字节流形式打印
print(dir(response))
# html = response.read() #报错,没有read方法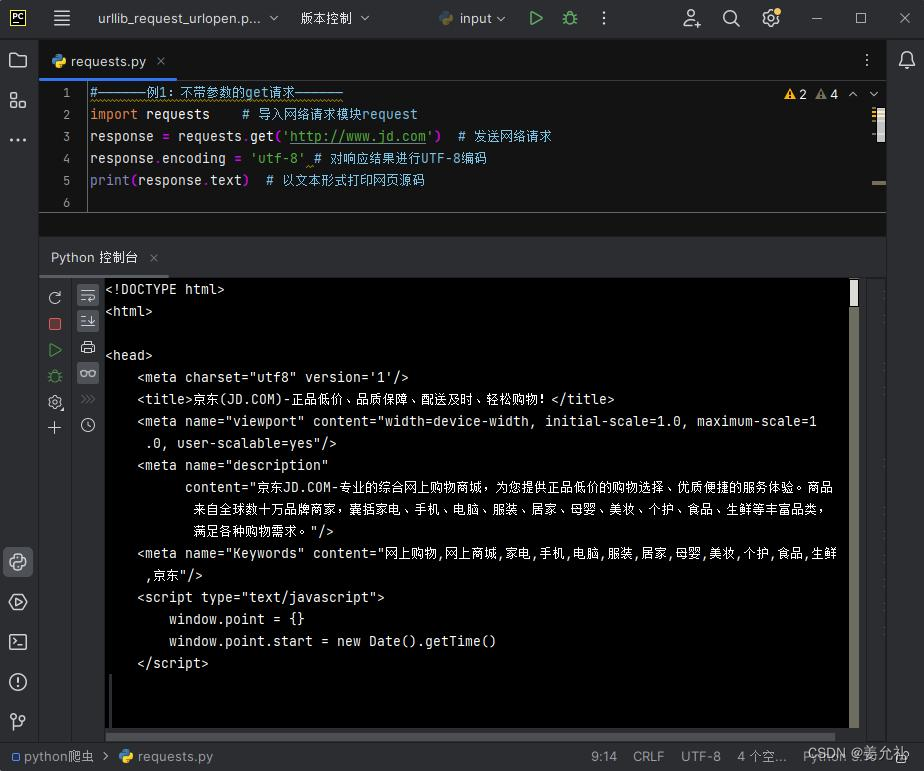
注意:需要设定为页面的编码,即页面源代码中的charset的值。只有当设定编码和页面本身的编码方式一致时,通过 Response对象的text属性才能获得没有乱码的HTML文本信息。在没有对响应内容进行UTF-8编码时,网页源码中的中文信息可能会出现如图所示的乱码。
import requests # 导入网络请求模块request
response = requests.get('http://www.jd.com') # 发送网络请求
print('响应数据类型为:', type(response)) # 获取响应类型
print('响应状态码为:', response.status_code) # 打印状态码
print('请求的网络地址为:', response.url) # 打印请求url
print('头部信息为:', response.headers) # 打印头部信息
print('cookie信息为:', response.cookies) # 打印cookie信息
import requests
url='http://www.jd.com' #设置url变量方式也可以
response = requests.get(url)
print('响应状态码为:', response.status_code)【例2】下载百度首页中的Logo图片
• 使用requests模块中的get()函数不仅可以获取网页中的源码信息,还可以获取二进制文件。但是获取二进制文件时,需要使用Response.content属性获取bytes类型的数据,然后将数据保存在本地文件中。
#——————例2:下载百度首页中的Logo图片——————
import requests # 导入网络请求模块requests
response = requests.get('https://www.baidu.com/img/bd_logo1.png?where=super')
print(response.content) # 打印二进制数据
with open('百度logo.png','wb')as f: # 通过open函数将二进制数据写入本地文件
f.write(response.content) 
实现请求地址带参:如果需要为GET请求指定参数时,可以直接将参数添加在请求地址URL的后面,然后用问号 (?) 进行分隔,如果一个URL地址中有多个参数,参数之间用“&”进行连接
URL参数:查询字符串
• 查询字符串(URL参数)是指在URL的末尾加上用于向服务器发送信息的字符串(变量)。
• 将英文的'?'放在URL的末尾,然后再加上键值对'参数=值',可以使用'&'符号进行分隔加多个参数。
• 在网页开发和设计过程中,URL字符串参数的应用非常广泛,它们可以提供很多有用的信息,例如搜索关键字, 用户身份验证信息等。可以帮助网页开发者和设计者更好地控制和管理网页的呈现。通过合理使用URL字符串参 数,可以让用户更方便地找到想要的内容,提升用户体验和网页的可用性。

配置params参数:requests模块提供了传递参数的方法,允许使用params关键字参数以一个字符串字典来提供这些参数。
#——————例3:实现GET请求地址带参——————
import requests # 导入网络请求模块requests
response = requests.get('http://httpbin.org/get?name=Jack&age=30')
print(response.text)
#——————例4:实现GET请求地址带参——————
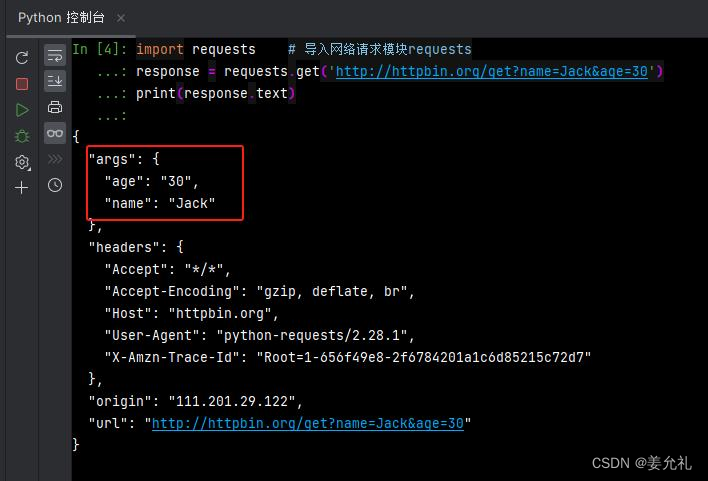
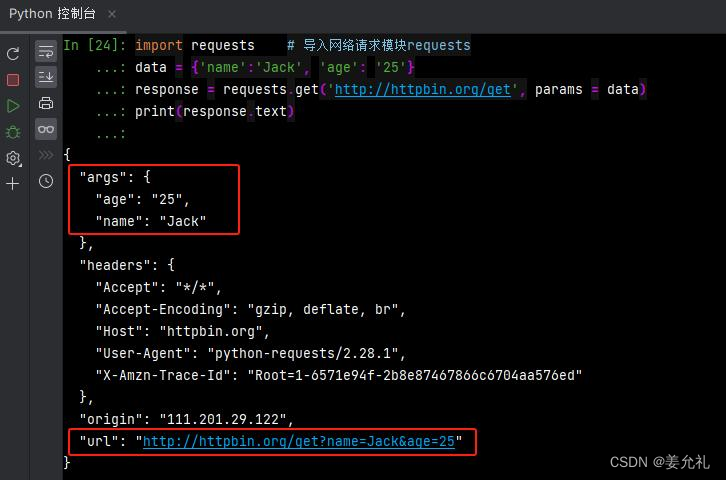
import requests # 导入网络请求模块requests
data = {'name':'Jack', 'age': '25'}
response = requests.get('http://httpbin.org/get', params = data)
print(response.text)
【例4】实现GET请求地址带参
import requests # 导入网络请求模块requests
url = 'http://httpbin.org/get'
data = {'name':'Jack', 'age': '25'}
response = requests.get(url=url, params = data)
print(response.text)
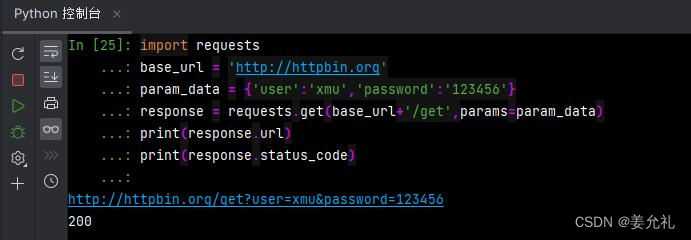
import requests
base_url = 'http://httpbin.org'
param_data = {'user':'xmu','password':'123456'}
response = requests.get(base_url+'/get',params=param_data)
print(response.url)
print(response.status_code)

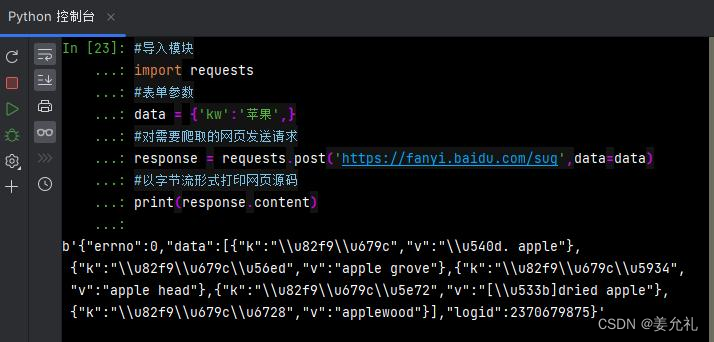
【例5】实现POST请求
POST请求:POST请求方式也叫作提交表单,表单中的数据内容就是对应的请求参数。

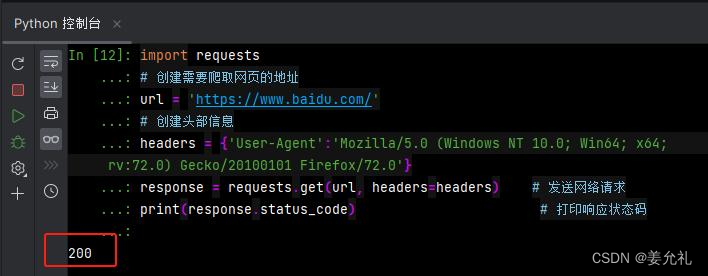
【例6】添加请求头模拟浏览器头部信息访问网页
复杂的网络请求:requests模块将这一系列复杂的请求方式进行了简化,只要在发送请求时设置 应的参数即可实 现复杂的网络请求。
【例7】爬取百度新闻
① 获取网页源代码
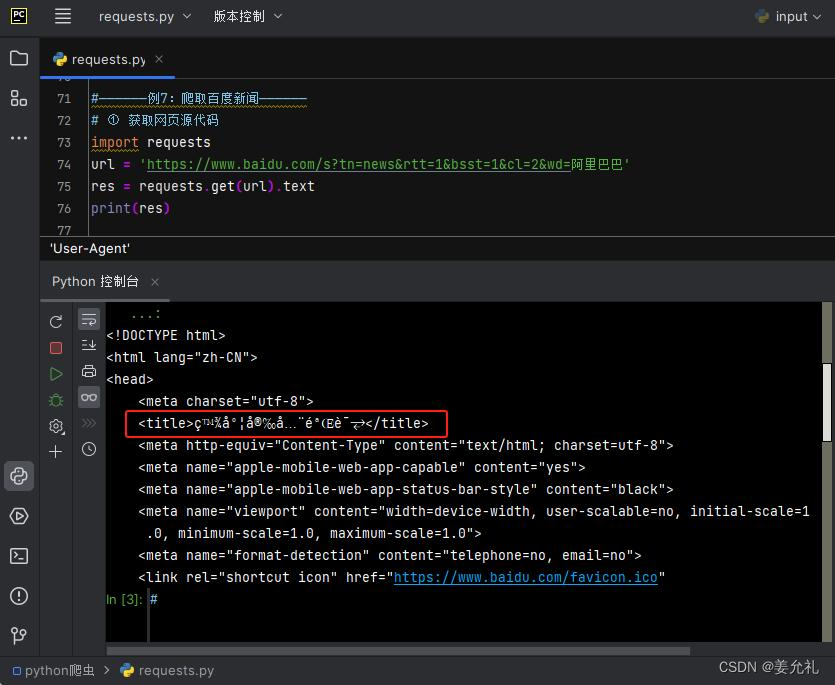
可以看到其并没有获取到真正的网页 源代码,这是因为这里的百度资讯网 站只认可浏览器发送过去的访问,而 不认可直接通过Python发送过去的访 问请求——需要设置下requests.get()中的 headers参数,用来模拟浏览器进行访 问。
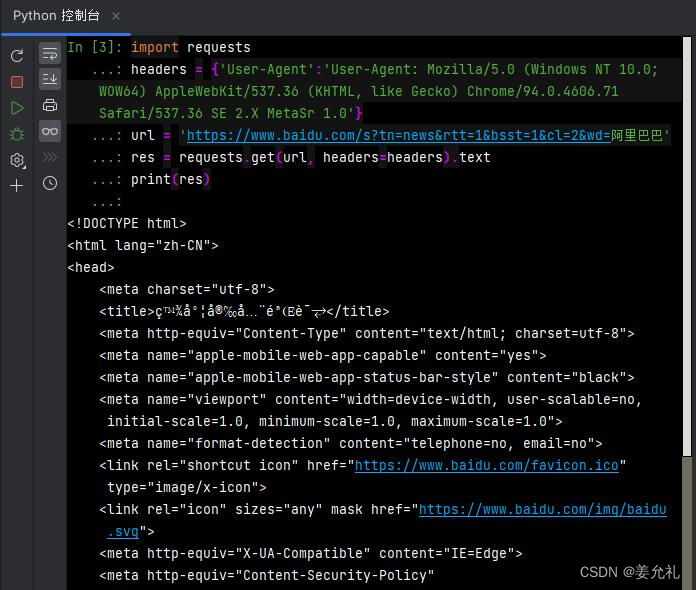
②设置headers
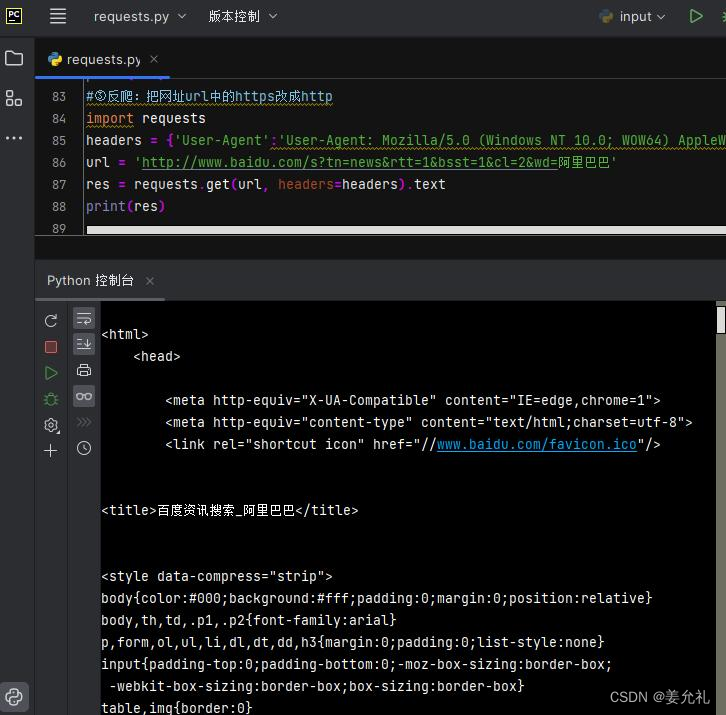
③反爬:2022.8以来,百度新闻通过requests库不好爬了,此时可以把网址url中的https改成http(ssl证书认证问 题),或者使用selenium库,或者加上ip代理反爬
















 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









