







1 C语言文件操作的回顾
这块博主在讲解C语言时就已经做了很详细的讲解,这里就不详细讲了,直接给出代码。
写操作:
#include<stdio.h>
#include<stdlib.h>
#include<errno.h>
#define LOG "log.txt"
int main()
{
FILE* fw=fopen("LOG","w");
if(fw==NULL)
{
perror("fopen:");
exit(1);
}
const char* str="hello file\n";
fputs(str,fw);
fputs(str,fw);
fputs(str,fw);
fclose(fw);
return 0;
}
读操作:
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<errno.h>
4
5 #define LOG "log.txt"
6 int main()
7 {
8 FILE* fr=fopen("LOG","r");
9 if(fr==NULL)
10 {
11 perror("fopen:");
12 exit(1);
13 }
14
15 char buffer[256];
16 fgets(buffer,sizeof(buffer),fr);
17 printf("%s\n",buffer);
18 fclose(fr);
19 return 0;
20 }
除了用上面的方法外C语言我们还可以用fprintf/fscanf, fwrite/fread等等。输出到显示器有哪些方法呢?除了用printf外,我们还可以用fprintf参数给stdout,这是由于Linux下一切皆文件的准则,至于为啥我们在后面会给出解释。
在C语言我们知道C会默认打开三个流:标准输入(stdin),标准输出(stdout),标准错误(stderr),而这三个流的返回指针都是FILE*类型。
打开文件的方式:
r Open text file for reading.
The stream is positioned at the beginning of the file.
r+ Open for reading and writing.
The stream is positioned at the beginning of the file.
w Truncate(缩短) file to zero length or create text file for writing.
The stream is positioned at the beginning of the file.
w+ Open for reading and writing.
The file is created if it does not exist, otherwise it is truncated.
The stream is positioned at the beginning of the file.
a Open for appending (writing at end of file).
The file is created if it does not exist.
The stream is positioned at the end of the file.
a+ Open for reading and appending (writing at end of file).
The file is created if it does not exist. The initial file position
for reading is at the beginning of the file,
but output is always appended to the end of the file如上,是我们之前学的文件相关操作。还有 fseek ftell rewind 的函数,有兴趣的老哥可以取移步博主讲解文件操作那里。
2 系统文件I/O
上面我们介绍的是语言层面的文件操作,但是系统层面的该如何操作呢?我们一个一个来介绍。
2.1 open
我们可以通过man手册查询:
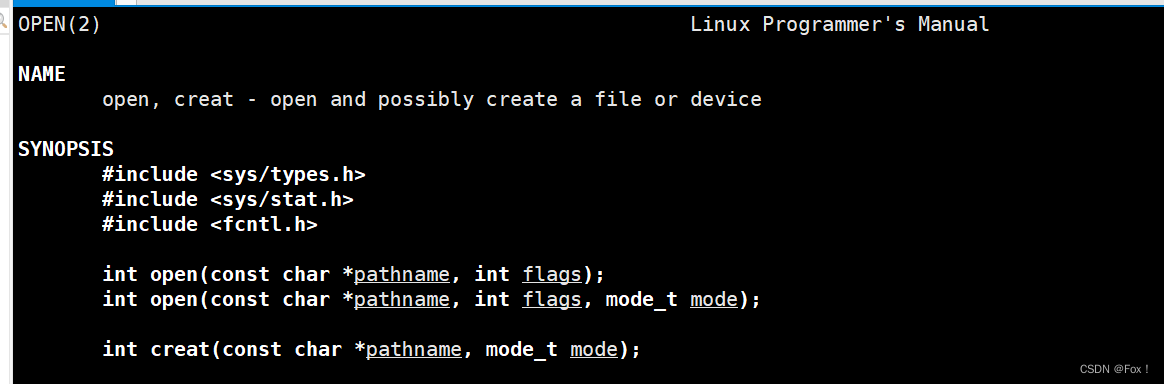
我们来看看第一个参数:就是要打开文件的名字;第二个参数:这个要重点讲解。
我们翻到手册后面:

这里面出现了一堆宏,究竟是什么鬼呢?其实open的第二个参数是一个位图结构,里面每一个比特位对应这一个宏,如何通过比特位将宏联系起来可以参考这种方式:
#define ONE 0x1
#define TWO 0x2
#define THREE 0x4
#define FOUR 0x8
#define FIVE 0x10
// 0000 0000 0000 0000 0000 0000 0000 0000
void Print(int flags)
{
if(flags & ONE) printf("hello 1\n"); //充当不同的行为
if(flags & TWO) printf("hello 2\n");
if(flags & THREE) printf("hello 3\n");
if(flags & FOUR) printf("hello 4\n");
if(flags & FIVE) printf("hello 5\n");
}
int main()
{
printf("--------------------------\n");
Print(ONE);
printf("--------------------------\n");
Print(TWO);
printf("--------------------------\n");
Print(FOUR);
printf("--------------------------\n");
Print(ONE|TWO);
printf("--------------------------\n");
Print(ONE|TWO|THREE);
printf("--------------------------\n");
Print(ONE|TWO|THREE|FOUR|FIVE);
printf("--------------------------\n");
return 0;
}open接口的详细介绍:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个,并且默认是不会清空文件的。
O_TRUNC:清空文件
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1若要使用mode选项,这里文件的权限还要受umask的影响,如果想要自己在参数中设置的就是文件权限,可以直接用umask(0)来设置文件的默认掩码。
2.2 write

我们可以来试试:
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
这里问一下大家,这里strlen(msg)是否要+1?我们想想如果是要拷贝\0的话那的确是要加,但是别忘了现在我们是系统调用接口,我们并不想要\0进入到文件中,换一种说法就是在给文件中根本就不认识什么\0,因为\0是由C语言给我们提供的,系统根本就不认识,那上面还有个\n呢?\n文件系统是可以识别到的能够自动换行。所以这里就不要加上\0了。
2.3 read

我们可以来试试:
char buffer[1024];
// 这里我们无法做到按行读取,我们是整体读取的。
ssize_t n = read(fd, buffer, sizeof(buffer)-1); //使用系统接口来进行IO的时候,一定要注意\0问题
if(n > 0)
{
buffer[n] = '\0';
printf("%s\n", buffer);
}这里还是有一样的问题,我们将文件中的内容读到字符串中由于文件中是没有\0的,所以需要我们自己手动增加\0.(当然你调用C语言的接口是不会出现这些问题的)
2.4 close
这个很简单,大家自己看看文档就懂了。
之前我们讲了C语言会默认打开3个文件流(stdin,stdout,stderr),那么我们是不是就可以合理猜测我们继续打开文件会与我们默认打开的文件之间有什么关系?
我们上手来验证验证:
int fd1=open(LOG,O_WRONLY | O_CREAT ,0666);
27 int fd2=open(LOG,O_WRONLY | O_CREAT ,0666);
28 int fd3=open(LOG,O_WRONLY | O_CREAT ,0666);
29 int fd4=open(LOG,O_WRONLY | O_CREAT ,0666);
30 int fd5=open(LOG,O_WRONLY | O_CREAT ,0666);
31
32 printf("%d %d %d %d %d\n",fd1,fd2,fd3,fd4,fd5);
33 close(fd1);
34 close(fd2);
35 close(fd3);
36 close(fd4);
37 close(fd5);
运行结果:

我们发现打印的文件描述符是从3开始打印的,并没有从下标0开始打印,这也正好解释了系统默认给我们打开了三个文件,这三个文件的描述符恰好是0 1 2。
那如果在打开新的文件之前我们关闭标准输入和标准错误会发生什么呢?😝😝
fclose(stdin);//close(0)
fclose(stderr);//close(2)
int fd1=open(LOG,O_WRONLY | O_CREAT ,0666);
int fd2=open(LOG,O_WRONLY | O_CREAT ,0666);
int fd3=open(LOG,O_WRONLY | O_CREAT ,0666);
int fd4=open(LOG,O_WRONLY | O_CREAT ,0666);
int fd5=open(LOG,O_WRONLY | O_CREAT ,0666);
printf("%d %d %d %d %d\n",fd1,fd2,fd3,fd4,fd5);
close(fd1);
close(fd2);
close(fd3);
close(fd4);
close(fd5);
运行结果:

不难发现此时新打开的文件描述符已经从0开始了。
文件描述符的分配规则是:在文件描述符的表中最小的没有被使用的数组下标分配给新文件。
2.5文件描述符fd
通过对open函数的学习,我们知道了文件描述符就是一个小整数。
0 & 1 & 2
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2。0,1,2对应的物理设备一般是:键盘,显示器,显示器。
😝😝😝😝谈谈你对文件描述符的理解?
在进程中每打开一个文件,都会创建有相应的文件描述信息struct file,这个描述信息被添加在pcb的struct files_struct中,以数组的形式进行管理,随即向用户返回数组的下标作为文件描述符,用于操作文件
3 各种问题的引入
1 如何理解C语言文件操作和系统调用?
通过上面对C语言文件操作的回顾以及对系统文件调用方法的学习,我们不难知道其实C语言的文件操作必定是封装了系统调用的,还记得在给大家讲解进程时给大家看的这样一张图吗?
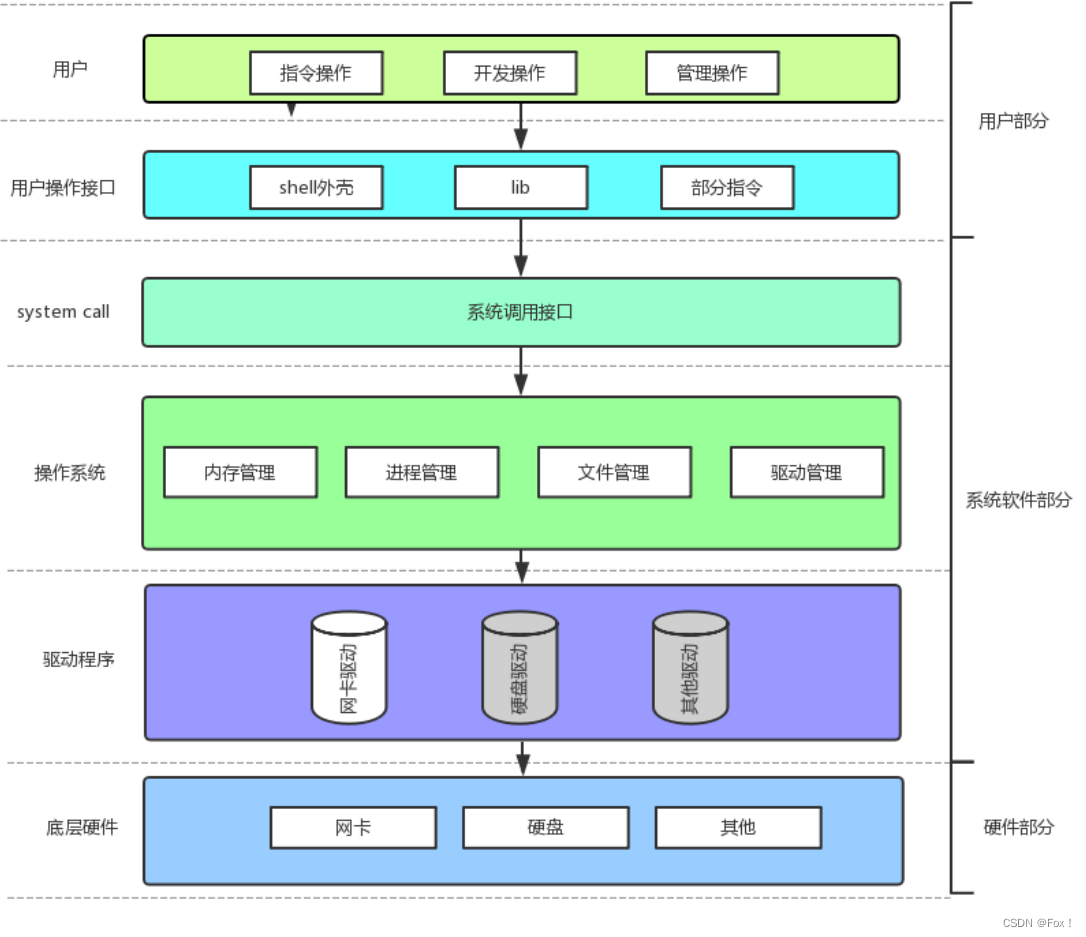
我们调用的库函数其实是对系统调用的封装,是为了方便用户使用而进行的二次开发。不仅仅是C语言包括C++/java/python等语言只要想在Linux平台下跑,进行文件操作时必定封装了系统调用。
2 文件操作时第一步是打开文件,为什么要打开文件呢?文件没有被操作时在什么位置?被操作时又在什么位置?文件load到内存load的是文件内容还是属性?
打开文件的目的是将文件load到内存,文件没有被操作时应该在磁盘,操作时应该在内存中,文件load到内存操作系统为了高效会将文件属性load到内存中。
3 是谁打开文件的?
很显然是OS打开文件的(OS是系统的管理者),那么问题来了是谁让OS打开文件的呢?
是不是因为我们创建了一个进程,让进程请求OS帮助我们打开文件,而进程打开文件很显然不只是打开一个文件,那么如何将这些文件管理起来呢?答案是先描述再组织。
操作系统管理所有文件时是通过file结构体来进行管理的,而进程为了管理文件是在进程的task_struck中又增加了一个files_struct来管理本进程中的文件,具体关系如下图所示:
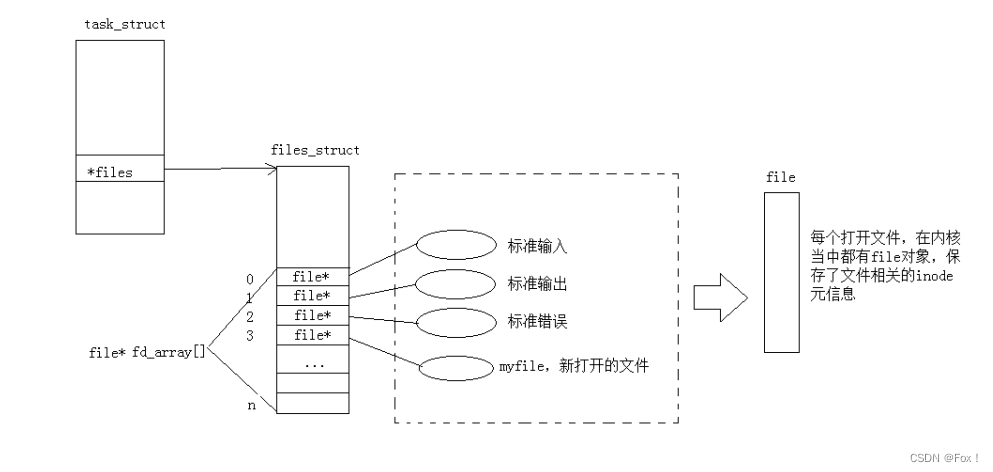
其中files_struct结构体又指向了一个指针数组,指针数组中存放着进程所管理文件的地址,通过下标索引就能够轻易的找到文件,对文件进行操作。而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
所以此时我们就能够更加清晰的解释为啥在上面我们关闭标准输入和标准错误后文件描述符发生的改变,本质就是0下标映射的标准输入文件和2下标映射的标准错误文件指向发生了改变。
这样通过映射关系建立连接还有一个好处就是将进程管理和文件管理进行了解耦合,将进程管理与文件管理分别管理了起来。
4 重定向
大家来看下面这个代码:
close(1);
int fd=open(LOG,O_WRONLY | O_CREAT | O_APPEND,0666);
if(fd<0)
{
perror("open:");
exit(1);
}
umask(0);
printf("printf:hello linux\n");
printf("printf:hello linux\n");
printf("printf:hello linux\n");
fprintf(stdout,"fprintf:hello linux\n");
fprintf(stdout,"fprintf:hello linux\n");
fprintf(stdout,"fprintf:hello linux\n");
fprintf(stderr,"stderr:hello linux\n");
fprintf(stderr,"stderr:hello linux\n");
fprintf(stderr,"stderr:hello linux\n");
大家猜猜运行后结果是啥?
我们运行试试:

我们发现了屏幕中只输出打印了stderr的内容,却没有输出stdout以及用printf打印的内容。
我们查看log.txt中内容:
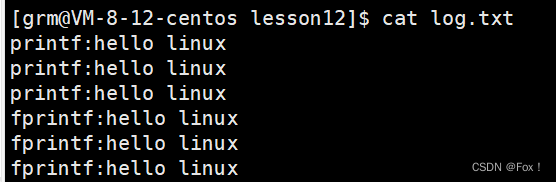
我们发现内容居然输出到了log.txt文件中,这种现象我们在讲解指令时已经说过了,叫做输出重定向(由于我们打开文件用的O_APPEND,所以叫做追加重定向更加合理)
那么这种重定向的原理是什么呢?
我们画个图来分析分析:
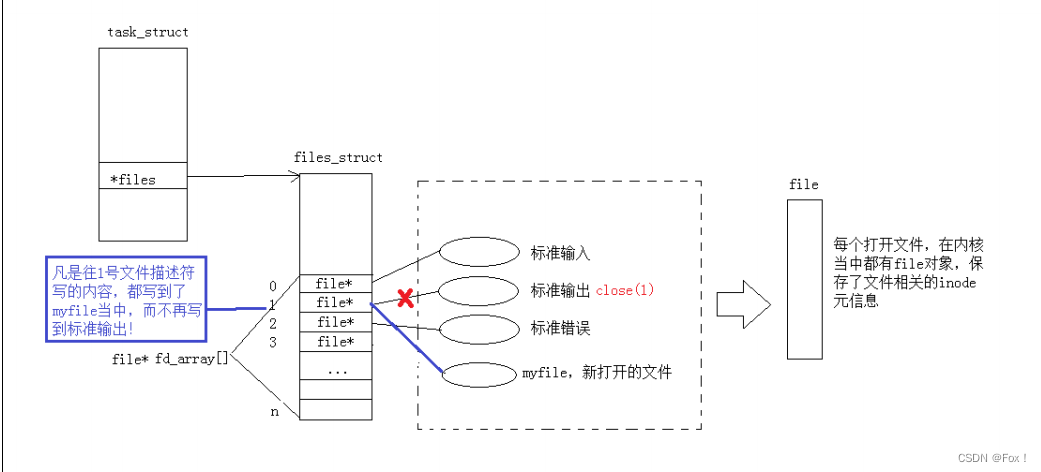
从图中我们清晰的看出由于我们先关闭了文件描述符为1的文件(也就是标准输出文件),当我们打开新文件时就将新文件的地址填充到下标为1的数组中,但是操作系统是不会关注下标为1的数组究竟指向的是谁,他只是负责执行。所以当我们使用printf以及fprintf的标准输出时并不会输出到标准输出文件(屏幕),而是重定向到了log.txt文件中。
同理当我们关闭了标准输入文件时,我们进行标准输入文件的读取时(也就是在键盘上读取)变成了从另外一个文件(此时文件下标为0指向的文件)中读取数据。
有了上面的理解,我们立即实操一下:要求将普通信息输出到nor.txt中,将错误信息输出到err.txt
参考代码:
close(1);
umask(0);
int fd1=open("nor.txt",O_CREAT | O_WRONLY | O_TRUNC,0666);
close(2);
int fd2=open("err.txt",O_CREAT | O_WRONLY | O_TRUNC,0666);
printf("normal file\n");
printf("normal file\n");
printf("normal file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n");
这样我们就将普通信息输出到nor.txt中,将错误信息输出到err.txt中了。除了这种方式,我们还可以使用命令行的方式来操作:在file.c中没有关闭标准输出和标准错误文件,我们通过命令行方式来进行分类:
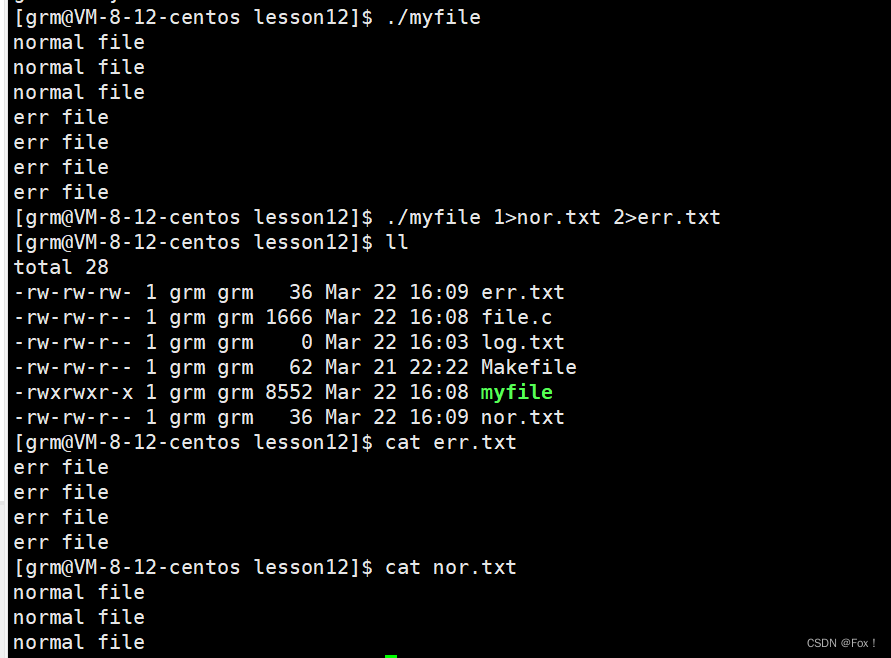
通过这种方式也能够将文件信息正确的分类,那如果我们想要将错误信息也打印到log.txt中呢?
可以通过下面这种方式:

其实实际上这里是省略了一个1的,完整写法可以是这样:

在平时练习时我们无论使用命令行还是在代码中实现都是可以的。
但是我们想想在代码中关闭文件的写法是不是有点太挫了,明明只需要替换一下文件地址就可以了为啥还要整一个关闭文件的操作呢?所以系统又给我们提供了另外一个接口:dup2
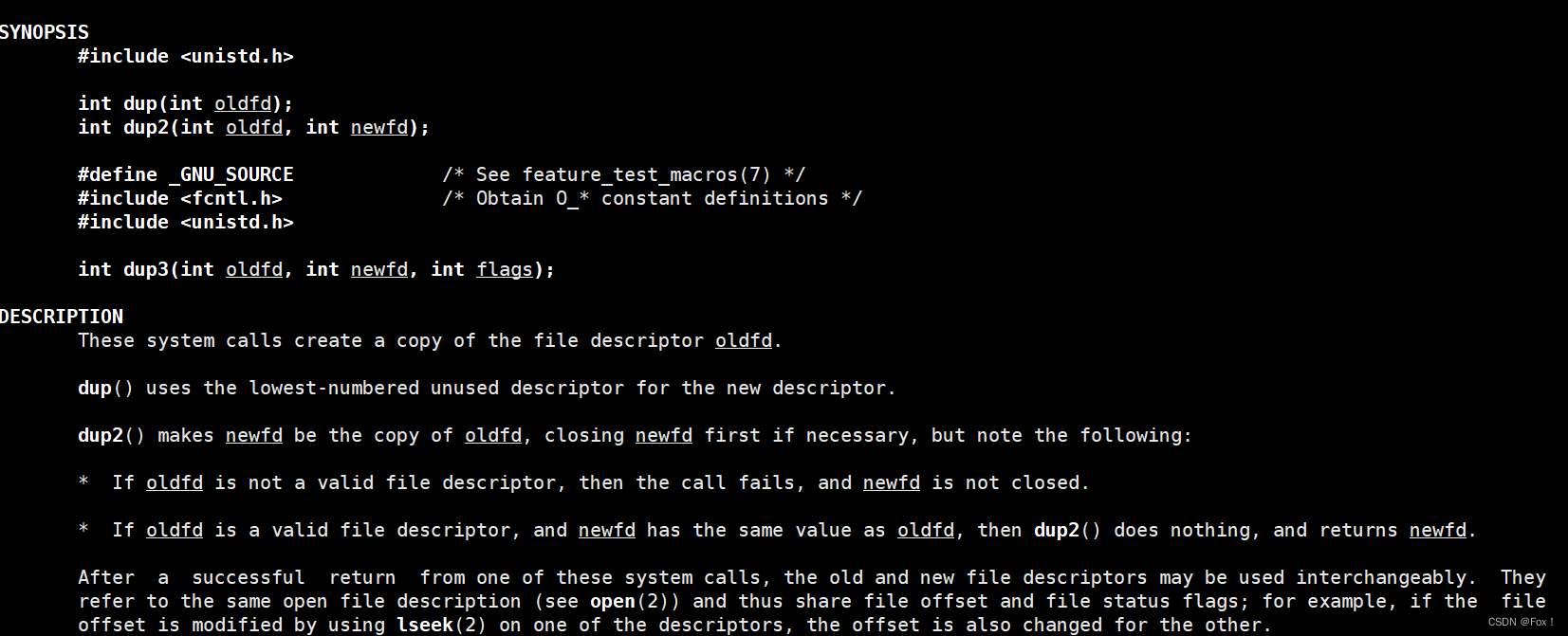
一般我们经常使用dup2这个接口。
我们来看看它的参数:
int dup2(int oldfd, int newfd);
第一个参数是oldfd,第二个参数是newfd,那么假如我们将标准输出文件关闭(1)打开了一个新文件,新文件的文件描述符是fd,那么1和fd谁是oldfd?谁是newfd?
我相信很多人都会说1是oldfd,fd是newfd(也包括我自己刚分析也是这样的)
但是大家一定要认真读读官方文档:

官方文档中是这么说的:newfd是oldfd的一份拷贝,换句话说就是最后只剩下了oldfd,newfd被oldfd所覆盖了。那么我们在回归话题,被覆盖的是谁?很明显是1被覆盖了,所以1就是newfd,那么
fd就是oldfd。参数顺序可不能够写反,不然就达不到我们想要的效果。
所以此时我们可以这样写代码:
//close(1);
umask(0);
int fd1=open("nor.txt",O_CREAT | O_WRONLY | O_TRUNC,0666);
dup2(fd1,1);
//close(2);
umask(0);
int fd2=open("err.txt",O_CREAT | O_WRONLY | O_TRUNC,0666);
dup2(fd2,2);
printf("normal file\n");
printf("normal file\n");
printf("normal file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n");
fprintf(stderr,"err file\n"); 这样也能够很方便的完成我们的需求。
😝😝😝😝谈谈重定向的实现原理?
每个文件描述符都是一个内核中文件描述信息数组的下标,对应有一个文件的描述信息用于操作文件,而重定向就是在不改变所操作的文件描述符的情况下,通过改变描述符对应的文件描述信息进而实现改变所操作的文件
5 缓冲区
在讲述struct file时还有一个小细节要提出,就是OS在维护的struct file时每一个struct都对应着一个缓冲区,可以理解为内核级别的缓冲区,那么这个缓冲区是有何作用?
这个其实是我们进行文件读写操作时将用户空间与内核空间的数据进行来回拷贝,至于何时刷新到用户磁盘中是由操作系统所决定的。
C语言提供的FILE与struct file有关吗?
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。所以C库当中的FILE结构体内部,必定封装了fd。这个我们之前都已经提及过。
FILE与struct file本质上是没啥关系的,非要扯一个关系的话就是一种上下层的关系。
来看这样的一段程序:
close(1);
int fd= open(LOG,O_CREAT | O_APPEND | O_WRONLY,0666);
umask(0);
printf("hello file\n");
fprintf(stdout,"stdout,hello file\n");
close(fd); 当我们运行时:
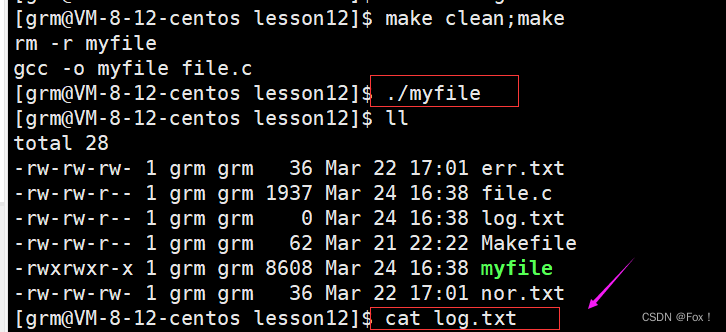
这好像跟我们之前讲的不符合吧?我们关闭了标准输出,打开了新文件后应该将数据重定向到了log.txt中呀,为啥log.txt中还是没有数据?
原因其实就是我们代码在之前的基础上在最后一行写了一句close(fd)
写了这一句为啥会造成这样的结果呢?我们来分析分析。
我们用C语言进行文件操作,在语言层面上会给我们提供一个缓冲区,就像之前我们讲解一个进度条一样,语言会提供一个缓冲区给用户,当我们关闭该文件时缓冲区的内容还没有被刷新到文件中,至于为啥此时不刷新呢?是因为一个规定:显示器刷新采用的是行缓冲,而普通文件刷新采用的是全缓冲,全缓冲表示必须将缓冲区填满才能够刷新,而显然我们刚才写入的那点儿字符是不足以将缓冲区填满的,所以此时我们在关闭文件前刷新一下缓冲区,数据就能够被正确写入了,我们可以来试试:
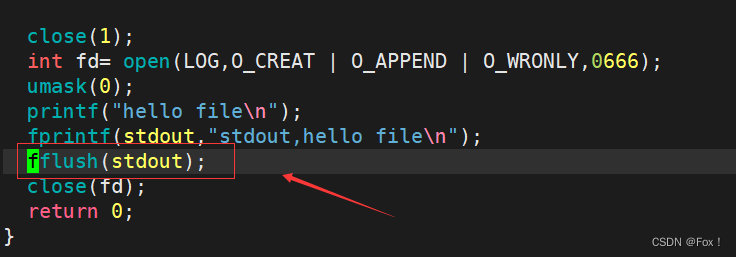
运行结果:

这样就得到了我们想要的结果了。
那么我们可能还会思考这个缓冲区是在哪儿的呢?其实该缓冲区是在FILE结构体中的,当我们用fopen打开文件时得到的FILE结构体,而缓冲区就在FILE结构体中。
我们可以看看FILE结构体的源码:
//在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
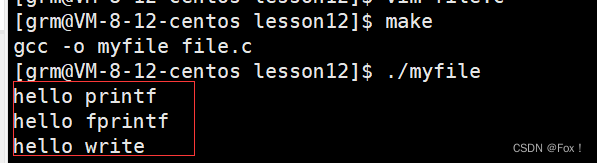
};我们再来看一段有趣的代码:
const char* str="hello write\n";
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
write(1,str,strlen(str));
fork();
当我们运行时:
可以当我们重定向到另外一个文件中时:
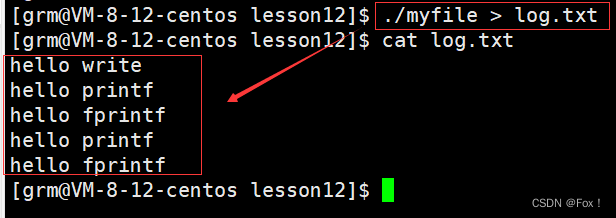
奇怪的现象发生了,为啥会比之前多打印两行?为啥hello write没有多打印一行呢?
我们结合上面的思考再来分析分析:我们调用printf和fprintf时是自带缓冲区的,但是当我们重定向到文件中时缓冲区的刷新方式由行缓冲变成了全缓冲,我们放在缓冲区的数据就不会被立即刷新,当我们进行fork之后,由于缓冲区的数据也是数据,所以缓冲区的数据也会发生写时拷贝,而当我们退出进程时缓冲区的数据就会被刷新出来,这也就很好的的解释了为啥会多打印两行hello printf和hell fprintf。
至于为啥没有多打印hello write,别忘了write可是系统调用接口,是不会存在什么缓冲区的,会直接将数据刷新到文件对应的缓冲区,所以fork之后就不会存在什么缓冲区数据拷贝的概念了。
综上: printf/fprintf 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。那这个缓冲区谁提供呢? printf/fprint 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fprintf 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。















 3968
3968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









