






目标:
爬取携程酒店的信息:将酒店名称,地址,电话,开业时间,客房数,图片链接,点评,图片保存路径生成excel,再将图片保存在对应酒店的image文件夹中
开始动手:
第一步:
需要先对数据进行抓包:
可以用bursuite或者fiddle进行抓包,(bursuite下载教程可以参考此链接BurpSuite全平台破解通用-至今可用 - SaberCC Blog)
那么现在打开bursuite,在携程搜索框输入一个城市点击搜索,再看看bursuite,找到有全部酒店id的包,发现请求数据中有个pageindex,这个就是说你将页面往下滑时会加载出来更多的酒店,那么这个pageidex可以作为参数,同样还有城市参数(cityid)。开始写得到hotelid的代码。写一下请求数据,得到响应数据,先创建一个gethotelid.py
#gethotelid.py
from 检查是否有重复字段 import remove_duplicate_lines
import requests
def get_hotel_list(pageIndex,cityid):
burp0_url = "https://m.ctrip.com:443/restapi/soa2/22370/gethotellist?_fxpcqlniredt=52271165296426527463"
burp0_cookies = {"Union": "OUID=mini1053&AllianceID=1314167&SID=4258862&SourceID=55555549", "DUID": "u=656D90DBCBB453190FC35AE0E82113CC&v=0", "GUID": "52271165296426527463"}
burp0_headers = {"X-Ctx-Locale": "zh-CN", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF XWEB/8447", "X-Ctx-Group": "ctrip", "Content-Type": "application/json", "X-Wx-Openid": "33d6ec3b-d887-4cf8-8fc4-c29c77f47342", "X-Ctx-Personal-Recommend": "1", "Xweb_xhr": "1", "X-Ctx-Region": "CN", "X-Ctx-Currency": "CNY", "Duid": "u=656D90DBCBB453190FC35AE0E82113CC&v=0", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0e6ed4f51db9d078/800/page-frame.html", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9"}
burp0_json={"channel": 1, "checkinDate": "2023-10-18", "checkoutDate": "2023-10-26", "cityId": cityid, "districtId": 0, "filterInfo": {"filterItemList": [], "highestPrice": 0, "keyword": "", "lowestPrice": 0, "starItemList": []}, "head": {"auth": "1369D5C2A3508C1F5B13853ACC15CAEE9FB5FC99929FEB6DA28D19CC13AC3AEB", "cid": "52271165296426527463", "ctok": "", "cver": "1.1.188", "extension": [{"name": "sdkversion", "value": "3.0.0"}, {"name": "openid", "value": "33d6ec3b-d887-4cf8-8fc4-c29c77f47342"}, {"name": "pageid", "value": "10650012159"}, {"name": "supportWebP", "value": "true"}, {"name": "ubt", "value": "{\"vid\":\"1697027931003.8mu33n\",\"sid\":2,\"pvid\":18,\"ts\":1697030756781,\"create\":1697027931003,\"pid\":\"10320613574\"}"}, {"name": "supportFuzzyPrice", "value": "1"}, {"name": "appId", "value": "wx0e6ed4f51db9d078"}, {"name": "scene", "value": "1053"}], "lang": "01", "sauth": "", "sid": "", "syscode": "30"}, "hiddenHotelIds": None, "isHourRoomSearch": False, "isMorning": 0, "nearbySearch": 0, "pageCode": "hotel_miniprogram_list", "pageIndex":pageIndex, "pageSize": 10, "preCount": 0, "preHotelIds": "", "session": {"key": "6bf9afb8c7f191d9e9db936b511103b1386625ab2ab18cf064b7427af73e9077", "sessionKey": "6720161d-0cb7-4dd0-be39-df37110067d0"}, "sessionId": "", "sourceFromTag": "inquire_preload", "topHotelIds": [], "userCoordinate": None}
res = requests.post(burp0_url, headers=burp0_headers, cookies=burp0_cookies, json=burp0_json)
data = res.json()那么我们可以调用函数把这个data给打印一下,分析出这个hotelid在哪里

在控制台看着比较乱,我们可以用json格式化网站(在线JSON校验格式化工具(Be JSON))帮助我们快速找到这个hotelid的位置,可以发现hotellnfoList是个列表,列表里包含字典,每个字典包含每个酒店信息,hotelid就在这个字典里。那么我可以用循环取得每个id。
#gethotelid.py
# print(data)
cityName = data['hotelInfoList'][0]['cityName']
# print(cityName)
hotel_ids = []
for hotel_info in data['hotelInfoList']:
hotel_id = hotel_info['hotelId']
hotel_ids.append(hotel_id)
return hotel_ids, cityName这个cityName拿过来方便用于创建txt名字
然后得到hotelid之后我们可以把它写入txt文件
#gethotelid.py
def save_hotel_ids_to_txt(cityid, max_pages):
all_hotel_ids = []
try:
for page_index in range(1, max_pages + 1):
hotel_ids, cityName = get_hotel_list(page_index, cityid)
print(f"Page {page_index} Hotel Info: {hotel_ids}")
all_hotel_ids.extend(hotel_ids)
except Exception as e:
print("读取完成")
# 将所有的 hotel_ids 写入 txt 文件,以 cityName 命名
txt_file_name = f'{cityName}.txt'
with open(txt_file_name, 'w') as file:
for hotel_id in all_hotel_ids:
file.write(str(hotel_id) + '\n')
file_path = txt_file_name # 使用新生成的 txt 文件的路径
remove_duplicate_lines(file_path)
print(f"Hotel IDs saved to {txt_file_name}")
return txt_file_name这串代码中的remove_duplicate_lines函数的添加是因为我在测试中发现生成的txt文件可能会有一些hotelid重复,于是弄了这个函数来检查txt文件,这个函数是从另外一个叫做“检查是否有重复字段.py”文件中导入的
#检查是否有重复字段.py
def remove_duplicate_lines(file_path):
lines = []
seen = set()
with open(file_path, 'r') as file:
for line in file:
line = line.strip()
if line not in seen:
seen.add(line)
lines.append(line)
else:
print(f"重复字段: {line}")
with open(file_path, 'w') as file:
file.write('\n'.join(lines))
print("重复字段已删除并文件已更新。")现在已经得到hotelid了。那么现在我们取读取酒店的其余信息
现在随便点进一个酒店,我们来抓包分析一下里面内容,用刚刚的方法同样我们去得到响应数据。
找到有hotel 地址的响应包,开始写代码,在新的py文件中写(hotelinfo.py)
def get_addressApic(hotelId):
burp0_url = "https://m.ctrip.com:443/restapi/soa2/26187/graphql?_fxpcqlniredt=52271115296426477628"
burp0_cookies = {"Union": "OUID=&AllianceID=262684&SID=711465&SourceID=55552689", "DUID": "u=B34F49EE0A13E8463539186D23B00A8B&v=0", "GUID": "52271115296426477628"}
burp0_headers = {"X-Ctx-Locale": "zh-CN", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF XWEB/8447", "X-Ctx-Group": "ctrip", "Content-Type": "application/json", "X-Wx-Openid": "b9787617-697b-4fe6-9942-f5fddd4b8063", "X-Ctx-Personal-Recommend": "1", "Xweb_xhr": "1", "X-Ctx-Region": "CN", "X-Ctx-Currency": "CNY", "Duid": "u=B34F49EE0A13E8463539186D23B00A8B&v=0", "Accept": "*/*", "Sec-Fetch-Site": "cross-site", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://servicewechat.com/wx0e6ed4f51db9d078/800/page-frame.html", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9"}
burp0_json={"head": {"auth": "8A38C2D39415D5002658D2670FDD4F8D369AEE5E25A10B5F129505F540395603", "cid": "52271115296426477628", "ctok": "", "cver": "1.1.188", "extension": [{"name": "sdkversion", "value": "3.0.0"}, {"name": "openid", "value": "b9787617-697b-4fe6-9942-f5fddd4b8063"}, {"name": "pageid", "value": "10320654891"}, {"name": "supportWebP", "value": "true"}, {"name": "ubt", "value": "{\"vid\":\"1697008079504.6vx93z\",\"sid\":1,\"pvid\":38,\"ts\":1697011325377,\"create\":1697008079504,\"pid\":\"10320654891\"}"}, {"name": "supportFuzzyPrice", "value": "1"}, {"name": "appId", "value": "wx0e6ed4f51db9d078"}, {"name": "scene", "value": "1007"}], "lang": "01", "sauth": "", "sid": "", "syscode": "30"}, "query": " { hotel(id: "+str(hotelId)+", checkIn: \"2023-10-11\", checkOut: \"2023-10-12\") { getBaseInfo { hotelName hotelEnName zoneName address openYear fitmentYear fuzzyAddressTip commentScore commentDesc commentCount bestCommentSentence isOversea cityId cityName totalPictureCount mgrGroupId hotelCategoryOutlineImages { categoryName pictureList { url urlBody urlExtend } } coordinate { latitude longitude } starInfo { star } topAwardInfo { listSubTitle listUrl awardIconUrl lableId rankId annualListAwardIconUrl annualListTagUrl } } getTrafficDetail(filterValue: \"\") { defaultTrafficText } getDetailTag { starTag { icon } dStarTag { icon } medalTag { icon } primeTag { icon } facilityTags(limit: 3) { title } categoryTag { title } } } } ", "source": "hotel_detail_head"}
res = requests.post(burp0_url, headers=burp0_headers, cookies=burp0_cookies, json=burp0_json)
data = res.json()
print(data)打印data我们发现
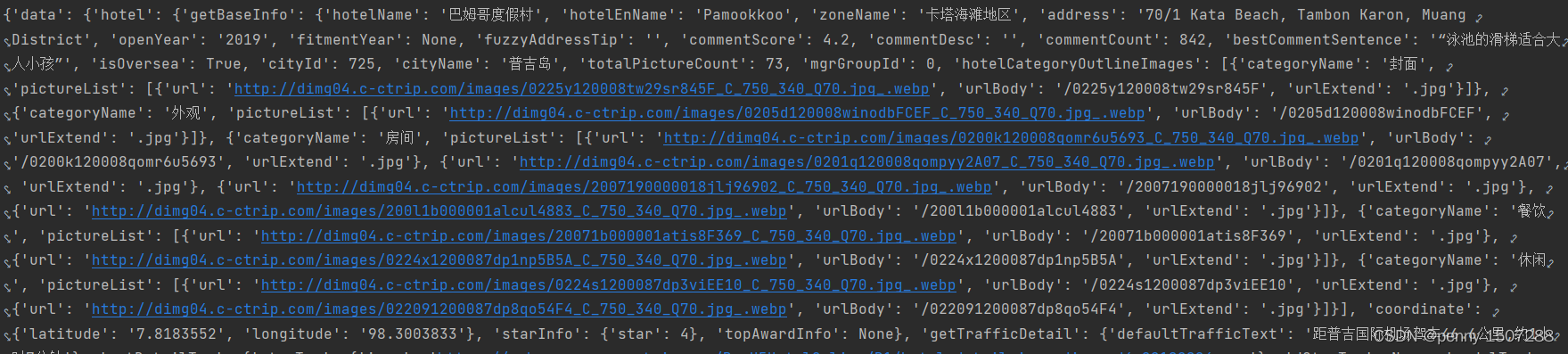
这里有address还有酒店图片。
address = data['data']['hotel']['getBaseInfo']['address']
picList = data['data']['hotel']['getBaseInfo']['hotelCategoryOutlineImages']
cityName = data['data']['hotel']['getBaseInfo']['cityName']
picList = [item['pictureList'] for item in picList if 'pictureList' in item]
pictureUrls = [item['url'] for sublist in picList for item in sublist if 'url' in item]
return address,pictureUrls,cityName接下来接着看包,找到一个有酒店名称,电话,酒店开业,装修时间这些信息的包,用同样的方法。
def get_info(hotelId):
burp0_url = "https://m.ctrip.com:443/webapp/hotels/sellingpoint?hotelid="+str(hotelId)+"&checkin=2023-10-11&checkout=2023-10-12&fromminiapp=weixin&allianceid=262684&sid=711465&sourceid=55552689&_cwxobj=%7B%22cid%22%3A%2252271115296426477628%22%2C%22appid%22%3A%22wx0e6ed4f51db9d078%22%2C%22mpopenid%22%3A%22b9787617-697b-4fe6-9942-f5fddd4b8063%22%2C%22mpunionid%22%3A%22oHkqHt8Zg6-uBtF-Y2UBUVVk1MlM%22%2C%22allianceid%22%3A%22262684%22%2C%22sid%22%3A%22711465%22%2C%22ouid%22%3A%22%22%2C%22sourceid%22%3A%2255552689%22%2C%22exmktID%22%3A%22%7B%5C%22openid%5C%22%3A%5C%22b9787617-697b-4fe6-9942-f5fddd4b8063%5C%22%2C%5C%22unionid%5C%22%3A%5C%22oHkqHt8Zg6-uBtF-Y2UBUVVk1MlM%5C%22%2C%5C%22channelUpdateTime%5C%22%3A%5C%221697011325536%5C%22%2C%5C%22serverFrom%5C%22%3A%5C%22WAP%2FWECHATAPP%5C%22%2C%5C%22innersid%5C%22%3A%5C%22%5C%22%2C%5C%22innerouid%5C%22%3A%5C%22%5C%22%2C%5C%22pushcode%5C%22%3A%5C%22%5C%22%2C%5C%22txCpsId%5C%22%3A%5C%22%5C%22%2C%5C%22amsPid%5C%22%3A%5C%22%5C%22%2C%5C%22gdt_vid%5C%22%3A%5C%22%5C%22%7D%22%2C%22scene%22%3A1007%2C%22personalRecommendSwitch%22%3Atrue%2C%22localRecommendSwitch%22%3Atrue%2C%22marketSwitch%22%3Atrue%2C%22pLen%22%3A3%7D&_obt=1697012693781"
burp0_cookies = {"GUID": "52271115296426477628", "nfes_isSupportWebP": "1", "nfes_isSupportWebP": "1", "UBT_VID": "1697008100680.1e1cmmiBfNEU", "librauuid": "", "_RF1": "111.22.74.62", "_RSG": "2Ha6Cu221L4XAzI9a6MT2B", "_RDG": "282a01bdfbf8df2e6720e1b8de10ac1c86", "_RGUID": "4541082e-0c1a-4442-b09d-5869094bd2a1", "login_type": "0", "login_uid": "B34F49EE0A13E8463539186D23B00A8B", "DUID": "u=B34F49EE0A13E8463539186D23B00A8B&v=0", "IsNonUser": "F", "AHeadUserInfo": "VipGrade=10&VipGradeName=%BB%C6%BD%F0%B9%F3%B1%F6&UserName=&NoReadMessageCount=0", "cticket": "8A38C2D39415D5002658D2670FDD4F8D369AEE5E25A10B5F129505F540395603", "_resDomain": "https%3A%2F%2Fbd-s.tripcdn.cn", "_pd": "%7B%22_o%22%3A4%2C%22s%22%3A13%2C%22_s%22%3A0%7D", "MKT_Pagesource": "H5", "Union": "OUID=&AllianceID=262684&SID=711465&SourceID=55552689&AppID=wx0e6ed4f51db9d078&OpenID=b9787617-697b-4fe6-9942-f5fddd4b8063&exmktID={\"openid\":\"b9787617-697b-4fe6-9942-f5fddd4b8063\",\"unionid\":\"oHkqHt8Zg6-uBtF-Y2UBUVVk1MlM\",\"channelUpdateTime\":\"1697011325536\",\"serverFrom\":\"WAP/WECHATAPP\",\"innersid\":\"\",\"innerouid\":\"\",\"pushcode\":\"\",\"txCpsId\":\"\",\"amsPid\":\"\",\"gdt_vid\":\"\"}&createtime=1697012402&Expires=1697617201862", "MKT_OrderClick": "ASID=262684711465&AID=262684&CSID=711465&OUID=&CT=1697012401865&CURL=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fservicechatv2%2F%3FisHideNavBar%3DYES%26isFreeLogin%3D0%26platform%3Dwechat%26appId%3Dwx0e6ed4f51db9d078%26sceneCode%3D2%26channel%3DEBK%26bizType%3D1356%26isPreSale%3D1%26pageCode%3D10320654891%26thirdPartytoken%3Dae1f21df-6e4b-4473-bcf3-8f19a78ac594%26source%3Dminipro_app%26orderInfo%3D%257B%2522amount%2522%253A%2522%2522%252C%2522bu%2522%253A%2522EBK%2522%252C%2522cid%2522%253A%25220%2522%252C%2522ctype%2522%253A%2522%2522%252C%2522currency%2522%253A%2522%2522%252C%2522supplierId%2522%253A1632483%252C%2522supplierName%2522%253A%2522%25E6%2598%259F%25E8%25BE%25B0%25E9%2585%2592%25E5%25BA%2597(%25E6%25A0%25AA%25E6%25B4%25B2%25E6%25B9%2596%25E5%258D%2597%25E5%25B7%25A5%25E4%25B8%259A%25E5%25A4%25A7%25E5%25AD%25A6%25E5%25BA%2597)%2522%252C%2522title%2522%253A%2522%25E6%2598%259F%25E8%25BE%25B0%25E9%2585%2592%25E5%25BA%2597(%25E6%25A0%25AA%25E6%25B4%25B2%25E6%25B9%2596%25E5%258D%2597%25E5%25B7%25A5%25E4%25B8%259A%25E5%25A4%25A7%25E5%25AD%25A6%25E5%25BA%2597)%2522%257D%26q%3DeyJtaW5lIjowLCJ3ZW1jIwoxfQ%3D%3DTW%26mktopenid%3Db9787617-697b-4fe6-9942-f5fddd4b8063%26fromminiapp%3Dweixin%26allianceid%3D262684%26sid%3D711465%26sourceid%3D55552689%26_cwxobj%3D%257B%2522cid%2522%253A%252252271115296426477628%2522%252C%2522appid%2522%253A%2522wx0e6ed4f51db9d078%2522%252C%2522mpopenid%2522%253A%2522b9787617-697b-4fe6-9942-f5fddd4b8063%2522%252C%2522mpunionid%2522%253A%2522oHkqHt8Zg6-uBtF-Y2UBUVVk1MlM%2522%252C%2522allianceid%2522%253A%2522262684%2522%252C%2522sid%2522%253A%2522711465%2522%252C%2522ouid%2522%253A%2522%2522%252C%2522sourceid%2522%253A%252255552689%2522%252C%2522exmktID%2522%253A%2522%257B%255C%2522openid%255C%2522%253A%255C%2522b9787617-697b-4fe6-9942-f5fddd4b8063%255C%2522%252C%255C%2522unionid%255C%2522%253A%255C%2522oHkqHt8Zg6-uBtF-Y2UBUVVk1MlM%255C%2522%252C%255C%2522channelUpdateTime%255C%2522%253A%255C%25221697011325536%255C%2522%252C%255C%2522serverFrom%255C%2522%253A%255C%2522WAP%252FWECHATAPP%255C%2522%252C%255C%2522innersid%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522innerouid%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522pushcode%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522txCpsId%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522amsPid%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522gdt_vid%255C%2522%253A%255C%2522%255C%2522%257D%2522%252C%2522scene%2522%253A1007%252C%2522personalRecommendSwitch%2522%253Atrue%252C%2522localRecommendSwitch%2522%253Atrue%252C%2522marketSwitch%2522%253Atrue%252C%2522pLen%2522%253A3%257D&VAL={\"h5_vid\":\"1697008100680.1e1cmmiBfNEU\"}", "_bfa": "1.1697008100680.1e1cmmiBfNEU.1.1697010109935.1697012401870.1.20.10650084702", "_ubtstatus": "%7B%22vid%22%3A%221697008100680.1e1cmmiBfNEU%22%2C%22sid%22%3A1%2C%22pvid%22%3A20%2C%22pid%22%3A10650084702%7D"}
burp0_headers = {"Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF XWEB/8447", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Sec-Fetch-Site": "none", "Sec-Fetch-Mode": "navigate", "Sec-Fetch-User": "?1", "Sec-Fetch-Dest": "document", "Sec-Ch-Ua": "\"Chromium\";v=\"107\", \"Not=A?Brand\";v=\"24\"", "Sec-Ch-Ua-Mobile": "?0", "Sec-Ch-Ua-Platform": "\"Windows\"", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9"}
res = requests.get(burp0_url, headers=burp0_headers, cookies=burp0_cookies)
soup = BeautifulSoup(res.text, "html.parser")
script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
json_data = json.loads(script_tag.string)
initialState = json_data["props"]["pageProps"]["initialState"]
hotelName = initialState["hotelEnName"]
tels = [tel["calTel"] for tel in initialState["contactInfo"]["telInfoList"]]
openTime = next(info["text"] for info in initialState["baseInfo"] if info["name"] == "开业时间")
renewTime = next(info["text"] for info in initialState["baseInfo"] if info["name"] == "装修时间")
roomNums = next(info["text"] for info in initialState["baseInfo"] if info["name"] == "房间数量")
return hotelName,tels,openTime,renewTime,roomNums同理得到评论的数据
def get_comments(hotelId, pageIndex):
url = "https://m.ctrip.com/restapi/soa2/24626/commentlist"
headers = {
"User-Agent": "Your User Agent",
}
params = {
"hotelId": hotelId,
"pageIndex": pageIndex,
"pageSize": 20, # 每页20条评论
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
data = response.json()
comment_list = data.get('groupList', [])[0].get('commentList', [])
comments = [comment['content'] for comment in comment_list]
return comments
else:
return []
def get_200_comments(hotelId):
comments = []
total_pages = 10 # 获取10页的评论,每页20条
for page in range(1, total_pages + 1):
comment_list = get_comments(hotelId, page)
comments.extend(comment_list)
if len(comments) >= 200:
break
return comments最后我们来调用以上这些函数,写入excel
def saveE(name, data):
# 创建一个新的文件夹
folder_name = name # 文件夹名称与传入的 name 参数一致
os.makedirs(folder_name, exist_ok=True)
# 创建一个新的Excel文件
workbook = Workbook()
# 创建第一个表
sheet1 = workbook.active
sheet1.title = "表1"
# 设置第一个表的表头标题栏
headers = [
"酒店名称",
"地址",
"电话",
"开业时间",
"装修时间",
"客房数",
"图片",
"点评"
]
sheet1.append(headers)
def add1(x, y, value):
# 在第一个表的表头x列的第y个数据赋值为value (表头算入其中,表头是y=1的位置)
sheet1.cell(row=y, column=x, value=value)
y = 2
for v in data:
x = 1
for vv in v:
add1(x, y, vv)
x += 1
y += 1
# 保存Excel文件
excel_file_path = os.path.join(folder_name, f"{name}.xlsx")
workbook.save(filename=excel_file_path)
return excel_file_path
def read_hotel_ids_from_file(file_path):
hotel_ids = []
with open(file_path, 'r') as file:
for line in file:
hotel_id = int(line.strip())
hotel_ids.append(hotel_id)
return hotel_ids
def process_hotel_data(cityid, max_pages):
# 生成和保存酒店ID到txt文件
txt_file_name = save_hotel_ids_to_txt(cityid, max_pages)
city_name = os.path.splitext(txt_file_name)[0]
# 读取酒店ID
hotel_ids = read_hotel_ids_from_file(txt_file_name)
# 处理酒店信息
data = []
for hotelId in hotel_ids:
try:
errorHotelId = hotelId
hotelName, tels, openTime, renewTime, roomNums = get_info(hotelId)
print(hotelName, tels, openTime, renewTime, roomNums)
address, pics,cityName = get_addressApic(hotelId)
print(address, len(pics), "张图片已经获取")
comments = get200comments(hotelId)
print(len(comments), "条点评已经获取")
data.append([hotelName, address, ",".join(tels), openTime, renewTime, roomNums, "\n".join(pics), "\n".join(comments)])
except Exception as e:
print("发生了一个异常:", str(e))
print("已经紧急保存excel文件", "报错的酒店id:", errorHotelId)
download_images_and_update_excel(saveE(city_name, data))
download_images_and_update_excel(saveE(city_name, data))这个download_images...函数时从excel中下载图片保存到image中,在新的py文件中final.py
import os
import pandas as pd
import requests
from tqdm import tqdm # 导入 tqdm 库
from gethotelid import get_hotel_list
def download_images_and_update_excel(excel_file_path):
# 获取 Excel 文件的目录
excel_dir = os.path.dirname(excel_file_path)
# 读取Excel文件
df = pd.read_excel(excel_file_path)
# 创建 image 文件夹
image_dir = os.path.join(excel_dir, "image")
os.makedirs(image_dir, exist_ok=True)
# 遍历每一行,根据酒店名称和图片链接下载图片
for index, row in df.iterrows():
hotel_name = row[0] # 第一列为酒店名称
image_urls = row[6].split('\n') # 第七列为图片链接,按换行符分割成多个链接
# 遍历图片链接并下载图片
image_paths = []
for i, image_url in enumerate(tqdm(image_urls, desc=f"Downloading {hotel_name} images")):
response = requests.get(image_url, stream=True)
if response.status_code == 200:
# 从链接中提取文件名
filename = image_url.split("/")[-1]
# 构建新文件名
new_filename = f'{hotel_name}_{i + 1}{os.path.splitext(filename)[1]}' # 重命名为酒店名_编号.扩展名
# 构建文件路径
file_path = os.path.join(image_dir, new_filename)
image_paths.append(file_path) # 保存文件路径
# 保存图片
with open(file_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print(f"Downloaded image {i + 1}/{len(image_urls)}")
else:
print(f"Failed to download image {i + 1} for {hotel_name} ({image_url})")
# 将文件路径添加到新的一列
df.at[index, 'Image Paths'] = '\n'.join(image_paths)
# 保存更新后的Excel文件在同一个目录下
updated_excel_file_path = os.path.join(excel_dir, os.path.splitext(os.path.basename(excel_file_path))[0] + '_updated.xlsx')
df.to_excel(updated_excel_file_path, index=False)
# 删除原有的 Excel 文件
os.remove(excel_file_path)
print("Images downloaded and Excel file updated successfully.")
return updated_excel_file_path
最后在main.py运行总程序
from hotelinfo import process_hotel_data
while True:
city_id = int(input("输入city_id:")) # 替换成你的城市ID
max_pages = int(input("输入最大采取页面:")) # 替换成你需要的最大页面数
# 调用处理酒店数据的函数
process_hotel_data(city_id, max_pages)
done = input("是否继续?(y/n)")
if done == 'n':
break
输入城市id和你想要爬取的页数即可
结语
谢谢观看
有疑问请留言
-------------------------------------------分割线-----------------------------------------------------------------------------
更新时间:2024/04/26
重新更新一下:
这个hotelid的提取接口换掉了,然后数据结构也变了,我给重新修改了一下。
需要源码的人可以去我的github里面去提取:GitHub - pennyzhao1507288/xiecheng_crawl

















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









