






MyBatis是持久层框架,用于简化JDBC开发,负责将数据保存到数据库,支持自定义SQL,免除了JDBC代码以及设计参数和获取结果集的工作,通过简单的xml文件和注解来配置sql,映射类型,接口,POJO等等作为数据库的记录。
JDBC的步骤固定,且为硬编码,每次改动时都要修改代码,手动设置参数,封装结果集时繁琐。

MyBatis入门
1.创建Maven项目,在pom.xml中导入坐标
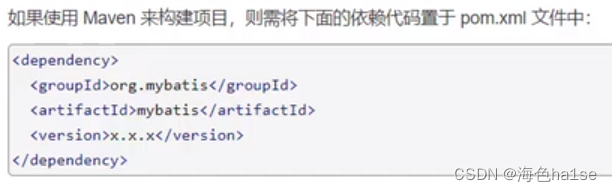
2.从mybatis-config.xml中创建SqlSessionFactory
xml中包含获取数据库连接实例的 数据源datasource ,以及事务管理器transactionManager

<dataSource>中包含数据库连接信息,
driver的value为 com.mysql.jdbc.Driver
url的value为jdbc:mysql://mybatis?useSSL=false
username的value为用户名,value是用户名称
password的value是密码
type是定义数据源类型,pooled表示使用数据库连接池,unpooled表示不使用,jndi表示使用上下文中的数据源。
使用配置文件properties中定义了数据库连接信息的话,在mybatis的核心配置文件就不用再次写出对应的连接信息的value,直接使用${}占位符进行替换
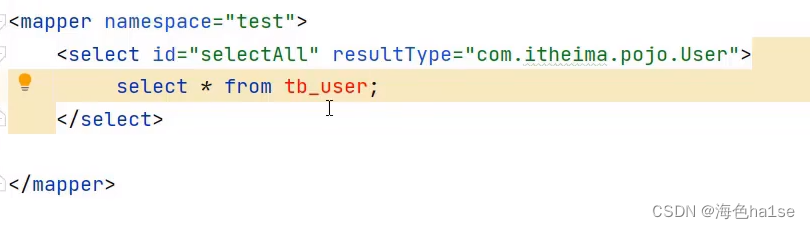
3.写映射的SQL文件 XxxMapper.xml
在mapper标签里定义select,update,delete等标签,其中标签有id属性,resultType属性,id是SQL语句的唯一标识,resultType是返回值要包装的类型。
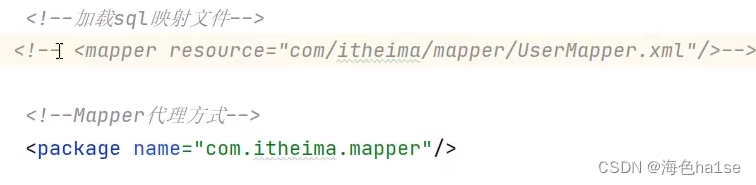
完成后在第二步的mybatis.config.xml中的mapper标签的resource属性中添加XxxMapper.xml构成映射关系,如果使用Mapper代理,则可以使用
4.根据数据库字段,定义对应的POJO类
5.编写mybatis核心测试类
(1).加载mybatis的核心配置文件,获取SqlSessionFactory

(2).通过Factory获取SqlSession对象,用它执行sql


(3).执行sql,参数为对应的 (命名空间.id)

但这样依然避免不了硬编码,所以可以使用以下的Mapper代理
*使用代理时,要先定义一个与SQL映射文件同名的Mapper接口,并放在同一目录下,即在resources目录下创建与Mapper接口同名的路径(用"/"代替"."),然后把XxxMapper.xml放进去。
*然后设置命名空间namespace为Mapper的全限定名。
*在Mapper接口中定义对应的方法,方法名就是sql语句的id,并保持参数类型和返回值类型一致。
*最后通过SqlSession的对象的getMapper方法获取代理实例,执行对应接口中的sql方法。

(4).输出结果集合,并关闭对应的流释放资源
![]()
-------------------------------------------------------------
在核心配置文件mybatis-config.xml中,有许多配置(configuration)信息
1.environments,在其中可以定义<environment>标签,配置多个数据源,其中id不同,通过指定environments的default属性来切换environment
2.dataSource
3.transactionManager,定义事务管理方式,默认使用原生JDBC方式,或者MANAGED被管理
4.typeAliases
(1)在其中定义<typeAliase>标签,type为全限定类名,alias为自己给它起的别名
设置之后在其他地方就可以不再使用繁长的全限定类名,而使用简洁易懂的别名即可。
(2)或者不用定义alias属性,这样默认的属性就是不再区分大小写的类名
比如全限定类名为com.fk.mybatis.pojo.User,配置后使用user或者User都可以替换它了。
可以在resultType中使用。
(3)使用<package>标签,该包下的所有类都将拥有默认的别名,比如设置
<package name= "com.fk.mybatis.pojo"/>
这样pojo包下的所有实体类都拥有了别名,即类名,且不区分大小写。
5.mappers可以通过包来引入mybatis的映射文件,前提是映射文件Xxxmapper.xml的目录和mapper接口的目录相同,且名字一样,才可以完成引入,这样就免于了一个一个引入不同映射文件的麻烦

..
配置标签时需要遵循以下顺序,否则会报错

--------------------------------------------------------------
单独的mybatis中,
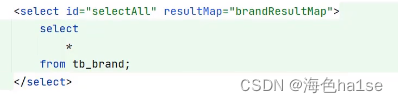
1)一对一的关系,在SQL查询时可能会遇到数据库中字段名称和测试类中字段名称不同的情况,此时会导致查询的数据无法封装,可以使用resultmap标签。

其中column是数据库的列名,property是测试类的属性名称,编写完成后,将sql语句的返回值类型更改为 resultMap = "XxxResultMap"即可
2).多对一的关系(实体类为复杂实体对象,里面封装多个数据类型)
可以有下列三种方式解决:
1.级联
resultMap中继续定义<result>标签,但里面的属性写复杂实体类对象的属性,比如部门对象Dept,里面又有属性deptId,deptName

2.association处理多对一映射关系
在resultMap中不再使用result标签,转而用<association> 代替,里面定义property来确定要处理的实体类中的属性,javaType确定要处理的属性的类型,然后在<association>中继续定义id,result标签完成映射

3.分步查询完成多对一的映射关系
分布查询繁琐,但是存在优点,可以实现懒加载,即获取什么数据,就执行对应的sql,不会全部执行所有的sql
首先在核心配置文件开启全局懒加载的配置
lazyLoadingEnabled=true //开启懒加载
aggressiveLazyLoading=false //按需加载
然后可以在某一个分布查询的association中定义fetchType=eager开启立即加载,或lazy延迟加载。
分步查询将多表联查拆成单表,在resultMap中,依然使用<association>,但多了select属性和column属性
select属性是下一步被拆分的sql查询所在的唯一标识,column是被拆分的sql查询返回的结果类型,这个column要被第一步sql来接收从而进行查询

3)通过collection处理一对多的映射关系(实体类为集合)
1.collection标签
和associaion类似,但这里使用<collection>标签,里面property定义要处理的属性,ofType处理对应属性中,集合里的各种类型,
然后再在其中对应定义id,result标签完成集合里的映射关系

2.分步查询
仍然使用<collection>标签,里面定义peoperty要处理的集合属性,select定义第二步查询的唯一标识,column
是第二步查询需要第一步查询所得到的对应字段名称

未整合的mybatis中,如果你在命名时遵守了实体类命名为驼峰命名,数据库字段为下划线命名方式,需要在核心配置文件中定义
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
而在springboot整合的mybatis中,如果你在命名时遵守了实体类命名为驼峰命名,数据库字段为下划线命名方式,则可以在配置文件中设置
mybatis.configuration.map-underscore-to-camel-case=true
就可以自动完成映射了
或者在定义sql语句时,通过起别名的方式使得名称一致。
或者使用Results注解,里面定义Result标签,指定column,即数据库字段名称,property,即实体类字段名称,使其一一对应,其实和resultMap是类似的

----------------------------------------------------------------

预编译SQL,#{}防止了SQL注入,并且性能更高,因为每条sql语句传入MySQL后,都会进行语法检查,之后优化SQL,编译SQL,然后执行。
使用预编译后,因为使用了?占位符,则只需要编译一次,之后相似的sql语句就可以直接执行了
只需要编译一次



----------------------------------------------------
动态sql,根据用户不同查询需求来改变sql语句,平常sql语句简单,可以使用注解进行配置,当使用比较复杂的动态sql配置,使用注解方式就不太合适,此时就可以使用xml映射文件配置,在里面定义sql语句。
1.因为xml文件放置在resources目录下,所以注意配置xml映射文件时,要使得xml文件和Mapper接口的每次一致,且同包同名

2.xml映射文件中,命名空间namespace的属性与mapper接口的全限定包名(引用路径)一致
![]()
3.xml映射文件中,sql语句的id的属性和mapper接口中的方法名称一致,同时保持resultType返回类型一致,这样才能完成映射,否则会报错。
---------------------------------------------------------
一.多条件动态查询
使用if标签,如果<if>标签的test条件不成立,则里面的语句不会拼接。
但是,容易出现where后多余and,or这样的关键字导致SQL语句出错,这时使用<where>标签即可解决;
在更新时会遇到因为逗号冗余而SQL语句出错问题,可以使用<set>标签解决
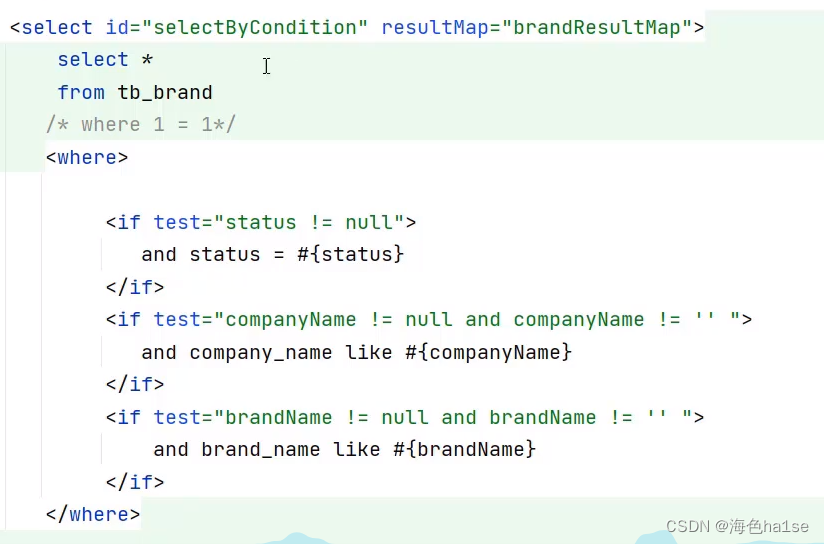

2.单条件动态查询
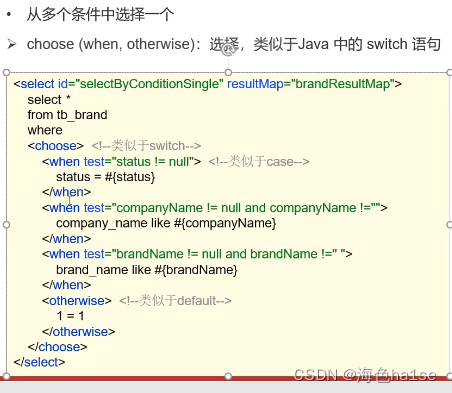
3.<foreach>循环遍历记录,用于批量操作数据,比如批量删除

foreach常用的属性有collection,是要遍历的集合,item是遍历出来的元素,
separator是每个元素之间的分隔符,open是循环开始前的sql片段,
close是循环遍历结束后的sql片段

4.<sql>和<include>标签
当sql语句中有大量重复的sql,每当修改时都会要修改所有相同的sql语句,这时可以像java一样把相同的语句封装起来,等到调用时再使用include,通过指定sql标签的id来引入sql语句

-----------------------------------------------------
主键返回

然后在添加后使用getID返回对应的值。
------------------------------------------------
在springboot中,mybatis已经被整合,创建springboot工程时,只需要勾选mybatis框架
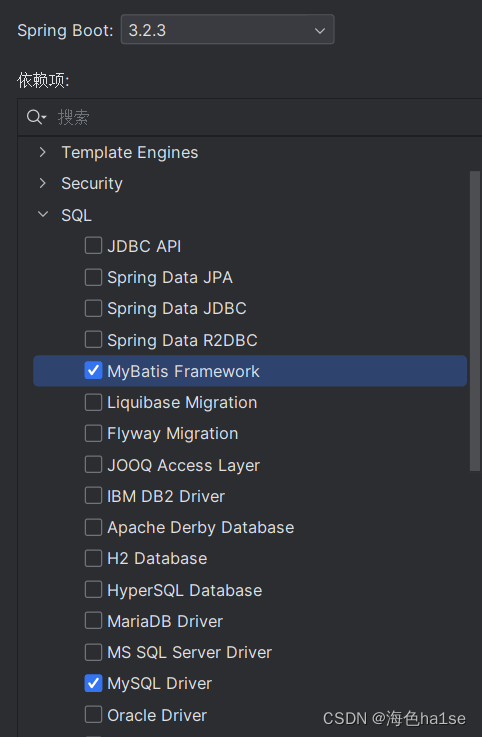
然后在项目的application.properties配置文件中配置数据库连接信息即可,不用在pom文件引入mybatis依赖了
数据源配置:

1.项目创建完成后,在dao层建立mapper包并定义对应的mapper接口(注意添加@mapper注解,这样该接口在运行时会自动生成对应的实现类对象,并通过ioc控制反转,交给spring容器),然后在接口中定义对应的方法,简单的sql语句直接在方法上通过注解完成。

2.根据三层架构的模式,除了mapper层,还需要调用mapper层的service层和控制器controller层,在service层里定义对应的service接口,定义对应的抽象方法,然后在service接口的impl实现类中实现方法,来调用mapper的sql语句,然后进行数据的转换操作。


因为定义的sql语句在接口中,而又不可以直接new一个新的接口对象,但上面提到@mapper注解会在运行时自动生成实现类对象并交给spring容器,成为一个新的bean对象,所以可以通过DI依赖注入的方式完成,即在定义的接口对象前添加@Autowired注解。
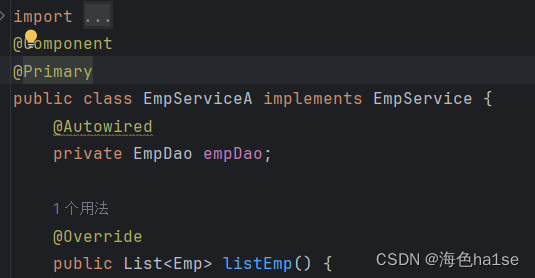
一个项目中有时会有多个实现类,定义了相同类型的bean对象,但spring容器一次只能接收一个同类型的bean对象,多于一个时会报错,所以这时不能再使用@Autowired自动装配了,如图,EmpServiceA,EmpServiceB都使用@Autowired注解修饰了相同的EmpDao对象,就会爆红。

可以在想要使其生效的实现类上使用@Primary注解;
或者在controller层,使用@Qualifier在对应的service前标识bean对象名称

或者@Resource直接替换@Autowired,只要指定注入的bean对象名称即可,因为@Autowired根据bean的类型注入,而@Resource根据bean名称注入,不会出现上述问题

注意在service和dao(mapper)层中,要想使用IOC控制反转,就要使用@component注解,把他们的实现类交给容器管理,又因为controller层需要service层的bean对象、service层又需要dao层的bean对象,所以在相应的对象上再使用@Autowired等注解进行依赖注入,
也可以使用下列的注解,controller层使用@Controller,service层使用@Service,dao层使用@Repository,但后续会使用@Mapper注解代替,其中controller层默认已经使用了@Controller,原因是自带的@RestController注解就是@Controller和@ResponseBody的组合
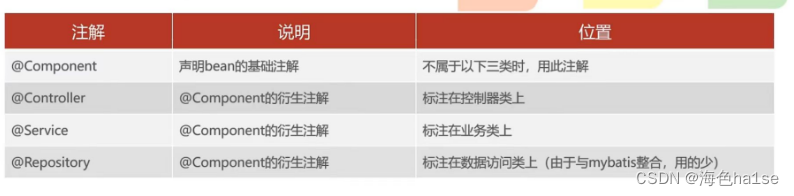
其次,bean对象的名称默认都是实现类的名称的首字母小写;
上述的注解,要想生效,必须遵守三层架构的分层模式,否则无法被扫描到,如果软件包没有分层,还要使用注解,则解决方法是手动添加@ComponentScan注解,指定扫描的包名
----------------------------------------------------------
lombok,是一个简化实体类的插件,可以自动生成pojo实体类的get,set,tostring,equals和hashcode方法,还可以生成无参,全参的构造方法,通过使用注解,免除了手动生成代码的步骤
使用前只要在pom文件添加lombok的依赖,然后添加对应的注解,其中@data是@getter,@setter,@tostring,@equalsandhashcode的综合















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









