







了解
通过HDB info命令可以看到hana的一些服务进程,这里面包括一些hana一些服务,也可以说是组件,叫法不同。

从HDB进程信息中可以看出,hana有几个核心服务(参考文献:[SAP HANA]SAP HANA的组件)
| 服务组件 | 系统进程名 | 服务名字 | 说明 |
|---|---|---|---|
| Name Server | hdbnameserver | nameserver | name server只运行在系统数据库上,拥有SAP HANA系统的拓扑结构信息,包括系统里租户数据库的存储信息。表和表分区的位置信息存储在相关租户数据库的catalog中。 |
| Index Server | hdbindexserver | indexserver | index server 运行在租户数据库上,不包括系统数据库,负责实际的数据存储和数据的处理。 |
| Compile Server | hdbcompileserver | compileserver | 编译服务负责执行存储过程和程序的编译,例如sql脚本。它运行在系统数据库上,为所有租户数据库提供服务。它不负责持久化数据, |
| Preprocessor Server | hdbpreprocessor | preprocessor | preprocessor server供index server使用,用于分析文本数据和提取基于文本搜索能力的信息。它运行在系统数据库上,为所有租户数据库提供服务。 |
| SAP Web Dispatcher | hdbwebdispatcher | webdispatcher | web dispatcher 处理 HTTP和HTTPS连接服务。 |
| SAP Start Service | sapstartsrv | sapstartsrv | SAP start server负责按正确的顺序启动或停止其他服务。它也有其他功能,例如监控其他服务的运行时状态。 |
SAP HANA还有一些其他服务,暂时没用到。
基础命令
数据库
连接数据库
hdbsql -u system -p '{passwd}' -i 02 -d {dbname}
查询所有数据库
SELECT DATABASE_NAME, ACTIVE_STATUS FROM M_DATABASES;
停止数据库,会修改数据库状态为No
ALTER SYSTEM STOP DATABASE testdb;
每个租户数据库对应一个hdbindexserver服务,停止数据库后发现hdbindexserver 进程少了一个。
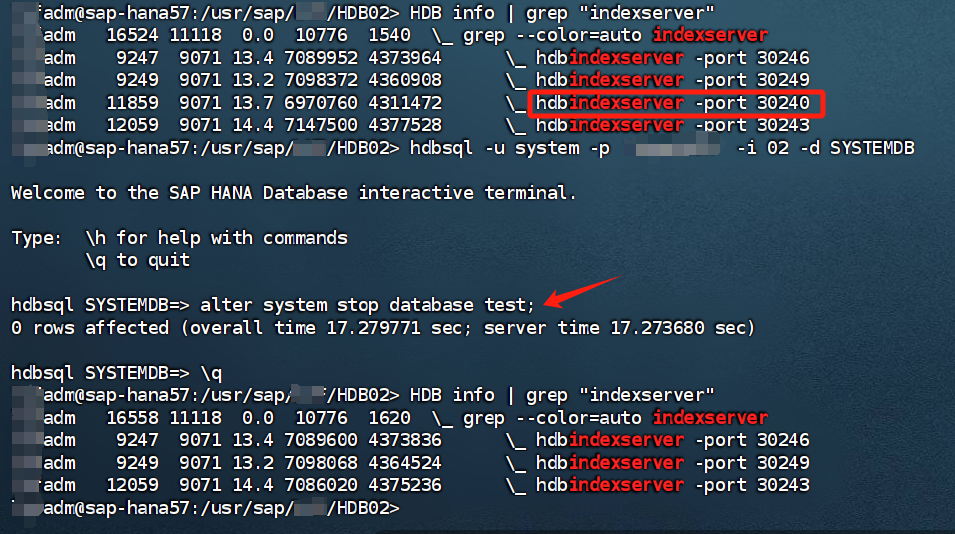
启动数据库,会修改数据库状态为Yes
ALTER SYSTEM START DATABASE testdb;
模式
查询所有模式
SELECT SCHEMA_NAME FROM SYS.SCHEMAS;
表
查看所有表
SELECT * FROM SYS.TABLES WHERE SCHEMA_NAME = '{schema_name}';
配置
查看数据库的卷VOLUMN信息
SELECT * FROM M_DISKS;

USAGE_TYPE值说明:
| 值 | 含义 |
|---|---|
| DATA | 数据文件路径,包括表数据、索引数据等。 |
| DATA_BACKUP | 数据备份文件路径,用于数据恢复和灾难恢复。 |
| LOG | 事务日志文件,事务日志记录了数据库中发生的所有事务操作,以确保数据库的一致性和持久性。 |
| LOG_BACKUP | 存储事务日志的备份文件,事务日志备份文件用于恢复数据库到某个特定时间点之后的状态。 |
| TRACE | 存储数据库的跟踪文件。跟踪文件记录了数据库系统中各种活动的详细信息,如 SQL 查询、性能统计等。跟踪文件通常用于故障排查和性能优化。 |
获取数据库的日志归档模式,获取到的数据库名字全部都为空。
SELECT DATABASE_NAME,KEY,VALUE FROM SYS_DATABASES.M_INIFILE_CONTENTS WHERE FILE_NAME = 'global.ini' AND KEY='log_mode'
获取归档日志目录
SELECT DATABASE_NAME, SECTION, KEY, VALUE from SYS_DATABASES.M_INIFILE_CONTENTS where FILE_NAME='global.ini' and (key='basepath_logbackup' or key='basepath_catalogbackup');
修改全局的日志归档目录
alter system alter configuration ('global.ini', 'SYSTEM') set ('persistence', 'basepath_logbackup') = '/usr/sap/LYF/HDB02/backup/log_test' WITH RECONFIGURE
修改单个库的日志归档目录,观察发现单个库的日志归档目录优先级比全局那个要高
alter system alter configuration ('global.ini', 'DATABASE', 'TEST') set ('persistence', 'basepath_logbackup') = '/usr/sap/LYF/HDB02/backup/log_test' WITH RECONFIGURE
修改数据库隔离级别为低,修改后还需要重启HDB: HDB stop/ HDB start,否则创建不了数据库
alter system alter configuration ('global.ini', 'SYSTEM') set ('multidb', 'database_isolation') = 'low' with reconfigure;
修改数据库隔离级别为高,修改后还需要重启HDB: HDB stop/ HDB start,否则还能创建数据库
alter system alter configuration ('global.ini', 'SYSTEM') set ('multidb', 'database_isolation') = 'high' with reconfigure;
查看数据库连接端口
\s
备份
hana1.0 备份参数中不支持添加COMMENT参数
BACKUP DATA FOR {database_name} USING FILE ('/data/backup_hana1','xxxxx')
查询数据备份记录
select * from sys_databases.m_backup_catalog WHERE (ENTRY_TYPE_NAME='complete data backup' OR ENTRY_TYPE_NAME='incremental data backup' OR ENTRY_TYPE_NAME='differential data backup');
备份报错
* 447: backup could not be completed: [7010001] Data with name ‘topology’ not found. SQLSTATE: HY000.
[2949]{-1}[-1/-1] 2024-05-15 14:10:28.597118 e NameServer TREXNameServer.cpp(01494) :
topology exception: exception 7010105: FTreeContainter: out of memory:
allocation failed, method=getTopologyAsString, request=(I)databaseId=3|
参考文档
-
[SAP HANA]SAP HANA的组件
https://www.cnblogs.com/tingxin/p/12623551.html -
Catalog与Schema:数据库中的命名空间与层级管理
https://developer.baidu.com/article/details/3229223
术语
- Catalog
catalog是一个数据库对象的容器或命名空间,它可以包含多个Schema。每个Catalog都是数据库系统中的一个独立层级,用于解决命名冲突问题。















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









