






MyBatisPlus是mybatis的增强,mybatis是数据库持久化的框架,但mybatisplus并不是替代mybatis,而是相辅相成的关系
MyBatisPlus不会对以前使用mybatis开发的项目进行影响,引入后仍然正常运行。
使用方法:
1.在引入了对应依赖mybatis-plus-boot-starter之后,该依赖包括了原本mybatis的依赖,所以原本的依赖完全可以删掉,之后就可以免除mybatis中,使用注解,xml定义单表查询的语句的操作。省时省力,只要直接调用mp中封装的大量方法即可,见名知意。
2.把项目中的mapper接口继承mp提供的父接口BaseMapper,因为这个接口中封装了大量方法,只有继承了该接口,才能调用mp的方法开简化书写sql语句,但是必须注意,继承接口时一定要指定泛型为你mapper对应实体类的类型,这样,mp才知道执行crud时,操作的是哪一个实体

3.mp是通过扫描实体类,然后通过反射,获取实体类的class文件,从而得到实体类对象,然后根据里面的对象转化为数据库表信息
有一些约定是:
实体类中驼峰命名的对象名转化为数据库表结构字段名的下划线命名法(userName -> user_name)
id名称的字段视为主键
类名驼峰转化为下划线表名
按照上述配置,在运行时mp还会自动完成相应的转换,但有时遇到名称不按规范定义的情况,就需要手动进行配置,来让mp能够识别。
4.有3个常用的注解帮助mp来指定信息
@TableName:用于指定表名,当数据库表名称和实体类名称不一致,需要在实体类上通过来主键指定
例如数据库表名为:tb_user,实体类名称:User
就要在实体类User上添加注解@TableName("tb_user")
@TableId:用于指定表中主键的字段信息
主键属性一般设置为自动增长(AUTO)autoIncrement,但也可以设置其他属性
有INPUT:即通过实体类的set方法进行手动赋值

ASSIGN_ID:分配id,基于接口IdentifyGenerator的方法nextid来动态生成id,根据雪花算法实现,生成的id为20位Long类型整数
设置type为自增长后,添加id时可以不用指定id,系统会自动进行增加,但如果没有指定type类型
那么注意,此时默认类型是使用雪花算法自动分配的id值

@TableField:指定表中的普通字段信息
如果字段名不一致需要指定,和TableName用法类似
但是有时遇到实体类字段名是is开头的,且位布尔类型,因为mp底层转换时会忽略is,所以配置时相当于is开头的字段名与数据库字段名不一致,手动配置即可
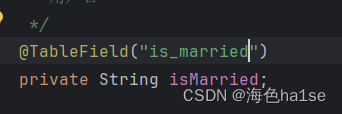
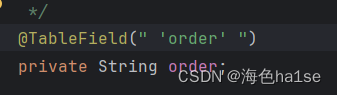
再或者实体类对象名称是数据库的关键字,得配置转义字符以免发生错误,即加上一个点
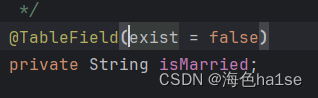
有时实体类中存在数据库表结构中不存在的字段类型,那还有种特殊用法,即指定@TableField(exist = false)
-----------------------------------------------
条件构造器:Basewrapper提供了大量方法,传入wrapper完成复杂where条件的构建

见名知意QueryWrapper用于定义查询语句,UpdateWrapper定义更新语句,使用前注意指定泛型。
wrapper支持链式编程,所以不用new一个wrapper,直接依次调用

基于updateWrapper的方法

setSql可以自定义set后面的语句
lambdaQueryWrapper和lambdaUpdateWrapper功能和上述类似,但是避免了硬编码

在lambda的方法里,接收的是一个方法,实际上还是参数,比如User::getId其实是通过user实体类的get方法获取id值
-----------------------------------------------------
自定义SQL:有时光使用mp提供的方法不足以构建某些复杂的语句,因为mp只擅长编写where部分的条件,所以我们把剩下的sql语句手动编写,where部分留给mp完成。

 在mapper层自定义sql方法,通过注解或xml书写sql语句,where后面的语句因为是mp生成,此处如图示有固定用法,然后指定id为自定义sql的方法名。
在mapper层自定义sql方法,通过注解或xml书写sql语句,where后面的语句因为是mp生成,此处如图示有固定用法,然后指定id为自定义sql的方法名。
然后在service层的实现类编写service接口方法的重写,添加业务逻辑,然后调用mapper层的sql。
在service接口定义抽象方法;
在controller层定义方法来调用service层的方法,依次调用,最后访问到mapper层,操作数据库,sql结束后返回

------------------------------------------------------
IService接口类似BaseMapper,也提供了大量方法,但多了批处理功能,提供了批量操作时的效率,同时可以查询数量,分页查询,也支持lambda
在使用时,需要先继承IService的一个实现类 ServiceImpl,并且指定对应的mapper名称和实体类然后再实现自己定义的Service接口,自己定义的接口也必须继承Iservice,才能使用IService'里的所有方法

IService的lambda方法里不但可以通过上述BaseMapper的方式避免硬编码,还可以再传入一个参数作为where语句中的if判断标签,如果这个参数为true,则再执行

比如like是模糊匹配,参数condition表示:当name不为空是,再根据获取的name信息进行匹配。此时还没有进行查询,还要调用one来查询单个,list查询多个,count查询总数,exist查询是否存在。
同理,lambdaUpdate在构建完sql语句后,也需要调用update方法才能执行。
批处理-批量新增:
首先在配置文件yaml中,在数据库url后,拼接参数rewriteBatchedStatement=true,表示开启重写批处理语句,这样可以提高性能,然后再调用saveBatch方法
--------------------------------------------------------
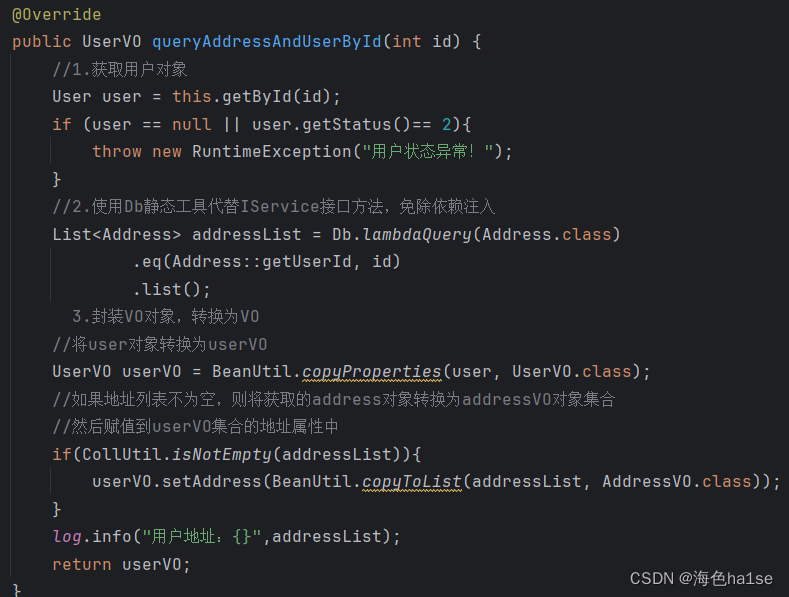
Db静态工具,它提供的方法和IService几乎一样,但都是静态方法,所以使用时不用像IService那样要自定义接口同时指定泛型来继承IService。
但是Db的方法都要额外传入一个对应类的字节码作为参数,这样才能通过反射获取数据库对应的字段和数据
--------------------------------------------------------
逻辑删除,在数据库字段中添加一个字段标记是否被删除,当删除时把字段标记为true或1,查询时只查询标记为false或0的数据即可。
这时的删除语句就不是delete,而是update了,逻辑删除的数据实际上还在数据库中存储
使用逻辑删除,在配置文件配置逻辑删除的字段名称和值就可以了

但是逻辑删除会导致数据库的垃圾数据越来越多,也可以推荐把删除的数据提前备份到其他数据表中,然后正常删除,也是一种解决方法
----------------------------------------------------------
枚举处理器
以往对状态字段的操作,都基于对状态字段赋值的数字进行判断,比如0为正常,1为冻结等等。
但不同的数字多了,光看数字很难记得对应了什么状态,就可以使用枚举来表示,枚举可以定义value数字值,也可以定义字符串来对状态进行描述

在以前的状态都是Integer类型,现在直接换成枚举类型,业务逻辑中比较状态时,也不用调用getStatus来获取状态,而是直接和枚举类中变量的用双等号进行判断即可
但数据库中状态字段还是int类型,怎么进行二者的类型转换?
mybatis通过底层的typeHandler来进行自动转换,mp也进行了‘扩展,可以把枚举类和json类都进行转换,然后存到数据库。
那么怎么使用,
1.通过注解@EnumValue来把和数据库字段类型匹配的值标记出来,这样底层就知道枚举中value的值和数据库状态字段对应,在执行sql语句就会自动完成
2.在配置文件配置以下:

3.枚举在给前端返回数据时,默认返回枚举项的名称,如果想指定枚举类返回的变量,可以在对应的变量前条件@JsonValue注解来进行标记
----------------------------------------------------
JSON处理器,mp提供了AbstractJsonHandelr来处理数据库中json类型数据和其他类型间的相互转换,而java中没有json数据类型,一般都会用string类型接收,底层也会自动完成。
但如果想从string字符串中获取里面的信息,就很麻烦,所以根据json类的形式,我们可以自定义一个类,里面的属性就是json中的键值对,将该类代替string,之后获取数据只要用get方法就好

这个过程需要自己实现,因为springmvc底层默认使用jackson,不引入额外依赖就能直接用
使用时通过@TableField(typeHandler = JacksonTypeHandler.class)来对指定的字段进行标记,上述对info进行标记,然后在User类上添加autoResultMap完成自动映射关系,完成json和java对象的转换
---------------------------------------------------------
分页插件,之前使用pagehelper进行分页,效果不错
mp中使用拦截器来进行分页操作,首先要定义一个配置类,加上configuration注解,里面new一个MybatisPlusInterceptor
然后new一个分页插件PaginationInnerInterceptor,参数指定数据库类型
setMaxLimit可以设置每次分页上限
然后把分页插件通过add方法添加到拦截器中,并返回该拦截器就完成了

之后就可以使用分页的api了,分页的api在IService接口中,lambdaQuery,Db中都有

page方法的参数:
page是分页参数
wrapper就是查询条件

在自定义的page方法就可以使用了这里模拟前端传参获得pageNo和pageSize,分别为当前页码和每页展示的条数,通过Page.of方法传参,然后addOrder添加排序条件,查询完毕后得到page对象,通过getTotal,getPages获取总记录条数和总页数,getRecords获取分页数据
2.带过滤条件的分页查询




----------------------------------------------------














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









