






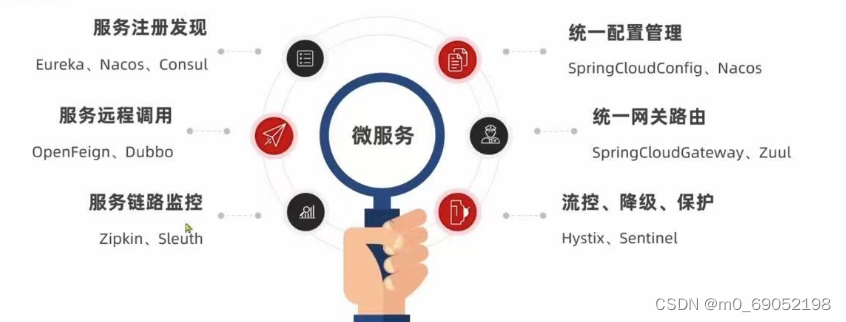
一.Spring Cloud
1.国内使用最广泛的微服务架构,结合的技术栈如下:
2.服务拆分注意事项:
不同微服务,不要重复开发相同业务
微服务数据独立,不可以访问其他微服务的数据库
微服务可以将自己的业务暴露为接口,供其他微服务调用
3.如何调用其他服务请求
在上文中,我们得到在微服务中,每个微服务都有自己的数据库,同时不能直接调用其他微服务的数据库,那么如果我们想要在一个模块中查找另外一个模块的信息,这时候该怎么办呢?
我们前端是通过Restful风格的Http请求来接受数据库信息,那么我们也可以让模块发送这个请求到其他模块来获得我们需要的数据
步骤如下:
3.1、注册RestTemplate
在启动类中,注入以下Bean来得到一个RestTemlate对象
/**
* 创建一个RestTemplate
* @return
*/
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}3.2.在Service层完成功能的完善
package cn.itcast.order.service;
import cn.itcast.order.mapper.OrderMapper;
import cn.itcast.order.pojo.Order;
import cn.itcast.order.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
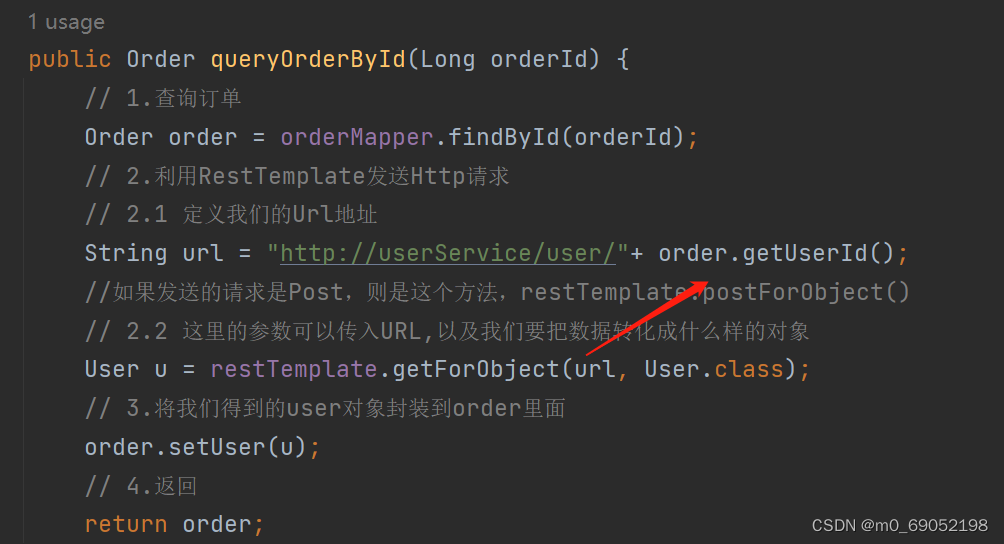
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用RestTemplate发送Http请求
// 2.1 定义我们的Url地址
String url = "http://localhost:8081/user/"+ order.getUserId();
//如果发送的请求是Post,则是这个方法,restTemplate.postForObject()
// 2.2 这里的参数可以传入URL,以及我们要把数据转化成什么样的对象
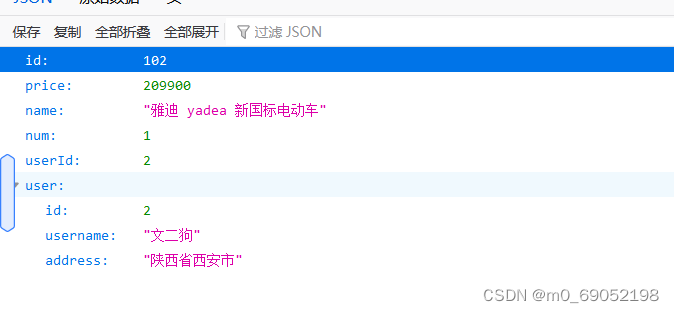
User u = restTemplate.getForObject(url, User.class);
// 3.将我们得到的user对象封装到order里面
order.setUser(u);
// 4.返回
return order;
}
}
4 消费者与提供者
模块提供服务给其他模块调用则称为提供者,模块调用其他模块的服务则为消费者,同时这个身份具有相对性,如果A调用了B的模块,C调用了A的模块,那么A对于B来说是消费者,对于C来说是提供者,所以一个模块既可以是消费者也可以是提供者
1.1.Eureka注册中心
1.1.1 什么是Eureka
当前的问题所在:
1、如上文中使用到的方法,通过Service层调用RestTemplate然后发送Http请求,来调用其他模块中的服务,但是这存在一个问题,即如果我们这个服务的Url是变化的,或者我们的环境发生变化,我们的URL也得跟着变化,我们该怎么解决这个问题?
2. 在实际的开发环境时,我们的模块不一定只有一个,可能是一个集群,那么我们应该调用哪一个来使用?我们又怎么知道他是可以使用的,没有挂呢?
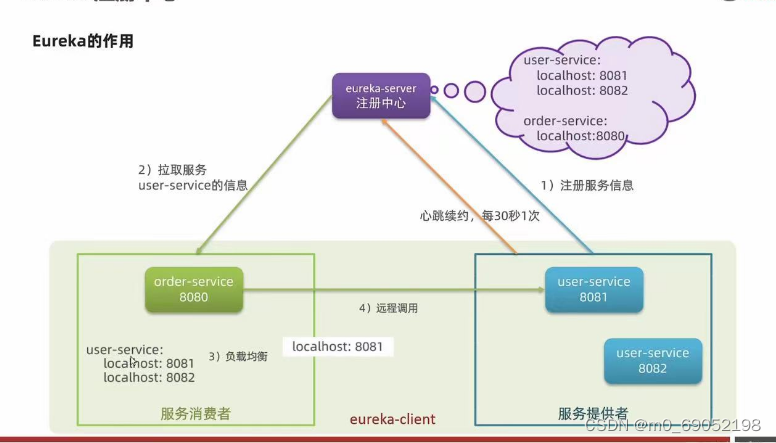
针对以上问题,Eureka注册中心给了我们相应的解决措施:
1.模块会将自己的信息注册到Eureka,包括自己的URL地址,我们的消费者用户只需从这个注册中心取就可以
2.模块会每30秒发送自己的状态,如果模块挂了,那么注册中心会将此信息从注册中心拿走。
相关的步骤如下图
1.1.2 Eureka服务端的搭建
Eureka的搭建步骤如下:
1.在整个项目中,新建一个模块为Eureka的Server端
2.在这个模块中添加对应的Maven坐标,并添加启动类,以及对应的配置文件
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
package cn.itcast.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
// 启动类
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class,args);
}
}
server:
port: 10086
spring:
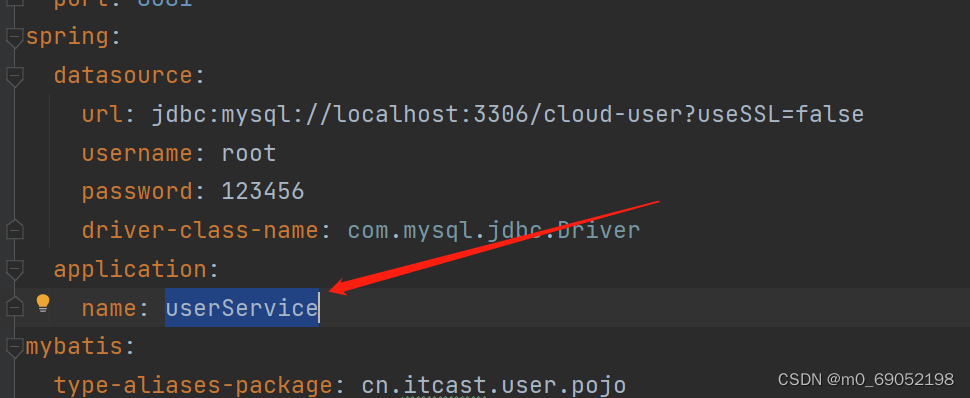
application:
name: eurekaserver
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka/3.启动Eureka,并查看对应的可视化界面
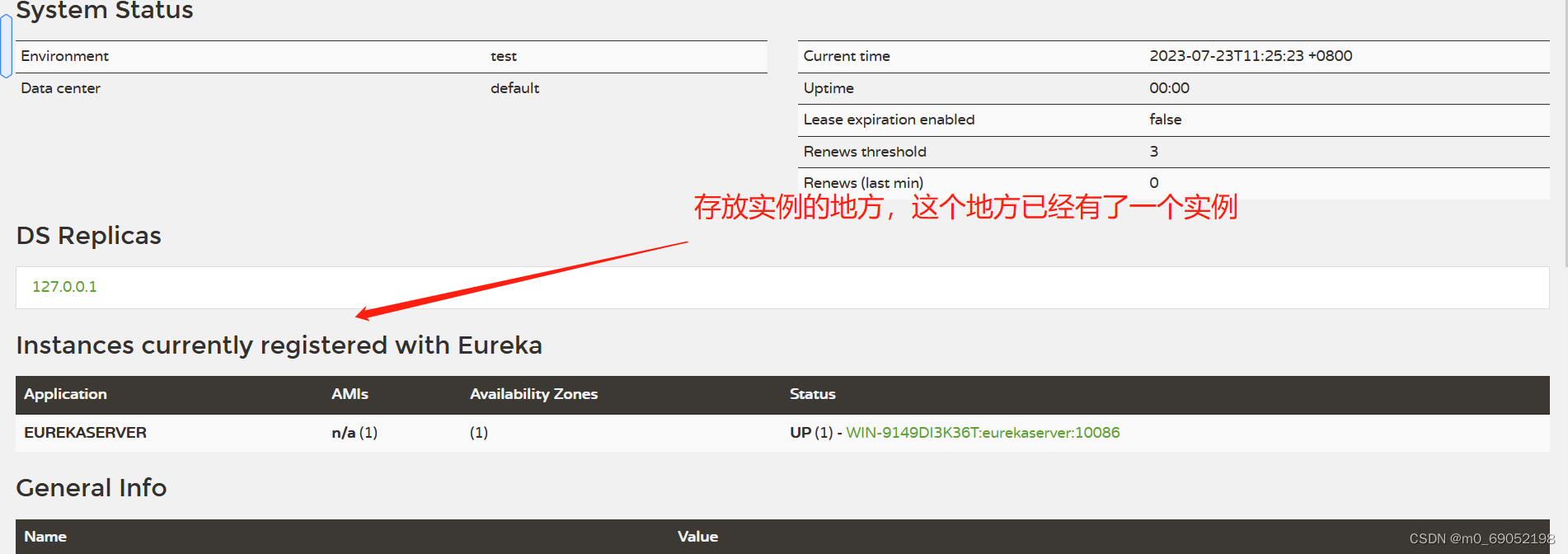
这里的实例就是Eureka本身,他会把自己也注册进去,方便集群管理,信息传输等
1.1.3 Eureka客户端的配置
跟上面的步骤很像:
1.在客户端中导入对应的Maven坐标

2.在配置文件中添加对应配置


结果如下:

1.1.4 Eureka的服务发现
现在服务端和用户端的配置已经构造好了,那么如何使用呢?
1.Template方法上面添加负载均衡的注解
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}2.在Service端更改URL地址
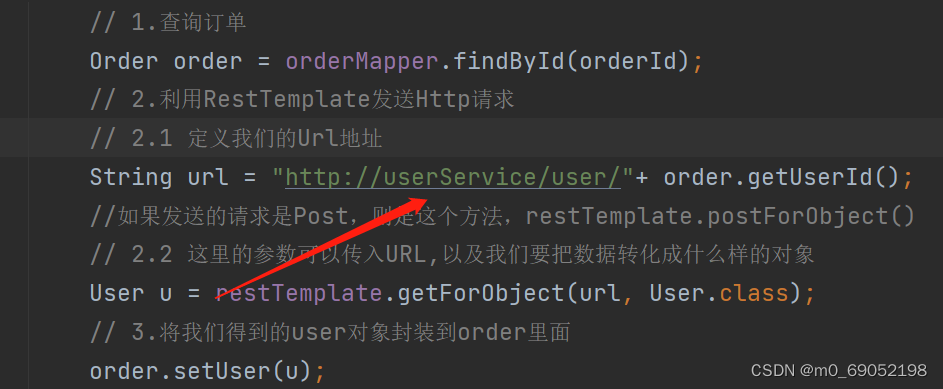
这里更改的就是我们之前配置文件中配置的Eureka的name属性
到此,Eureka的基本使用就完成了
1.2.Ribbon负载均衡
在上面Eureka的学习中,我们可以看出,Eureka可以将服务器端发送的URL地址,解析为IP地址用来访问,那么其中的步骤,以及负载均衡是如何实现的呢?步骤如下图:
1.前端发送URL地址给负载均衡拦截器
2.由Eureka服务端拉取userService,获取其真实url地址
3.再由IRule来分配地址给拦截器
4.最后分发地址
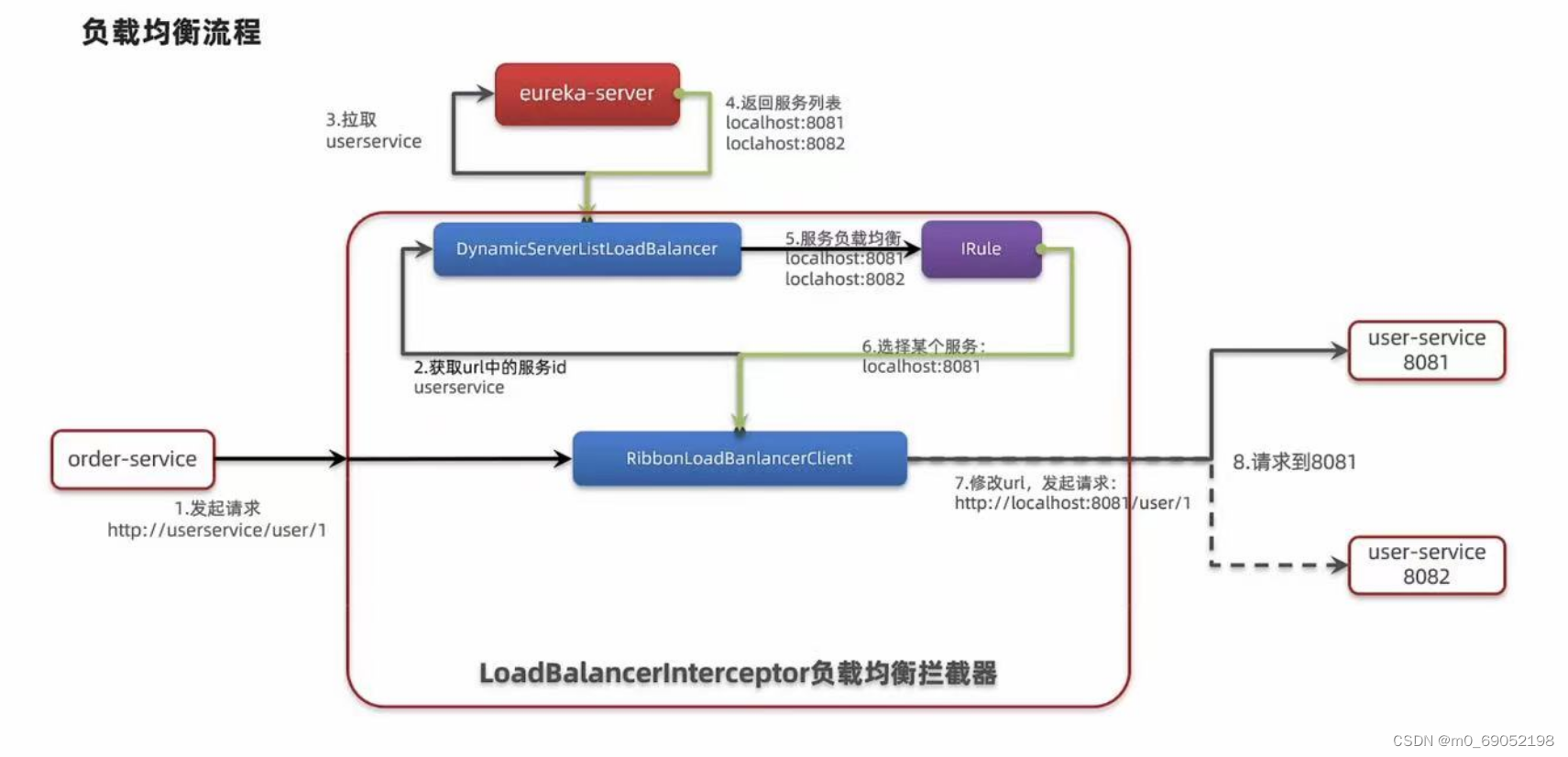
在此处IRule中采取的方法是ZoneAvoidanceRule,也就是一个改良过后的轮询操作
IRule的所有负载均衡的策略如下:

1.2.1 如何修改负载均衡的策略
有两种方法:
1.在Application类中添加Bean,并返回要修改的IRule类型, 这种方式是将该模块中的所有策略都进行修改
package cn.itcast.order;
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("cn.itcast.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
/**
* 创建一个RestTemplate
* @return
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
@Bean
public IRule randomRule(){
return new RandomRule();
}
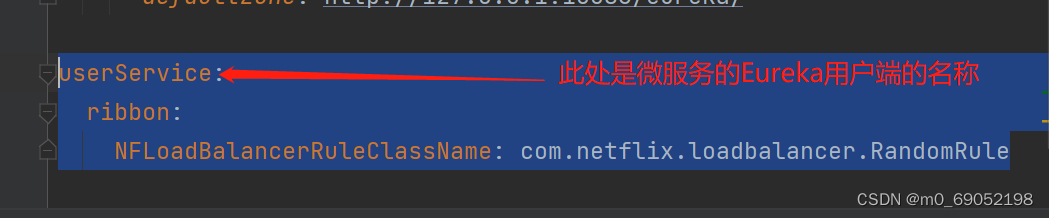
}2.还有一种是只修改一个微服务的策略,这种是在配置文件-application.yml中进行修改添加,
1.2.2 饿汉式与懒汉式加载
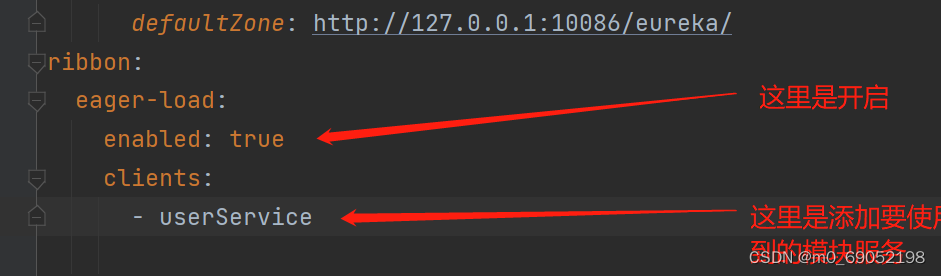
在Ribbon的配置中,默认采取的是懒汉式加载,也就是如果项目启动时,不需要他,就不会加载,这种加载的初始加载时间往往较长

所以我们可以采用另外一种加载方式,饿汉式加载,也就是在项目启动的时候,就把我们需要的负载均衡配置类全部加载上来,速度会快一点,可以在application.yml的配置文件中进行对应的配置
1.3.Nacos注册中心
然后登录,账号密码都是nacos
1.3.1 Nacos的基本使用
1.在父工程的pom文件中导入alibaba的相关依赖
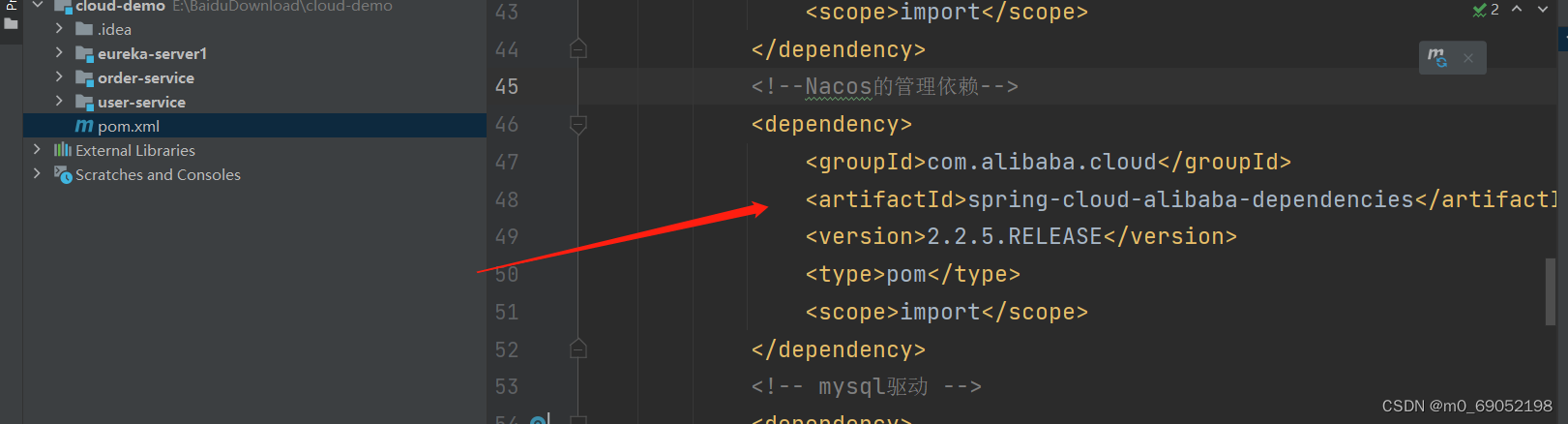
1.3.2.在客户端修改依赖以及配置文件的修改
注意!要将之前的Eureka注释掉
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>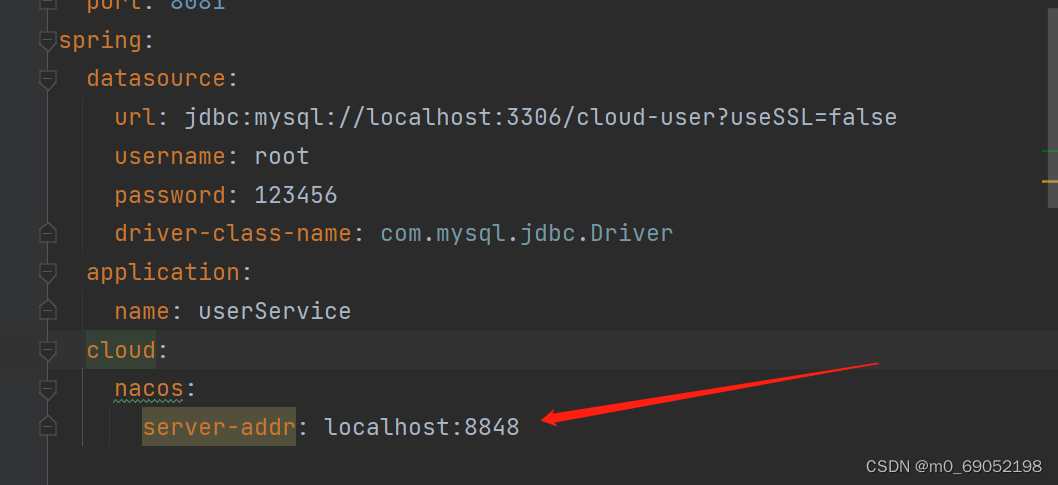
此时没有配服务器端的原因是,已经启动服务器在后台了,也就是上面启动的那个
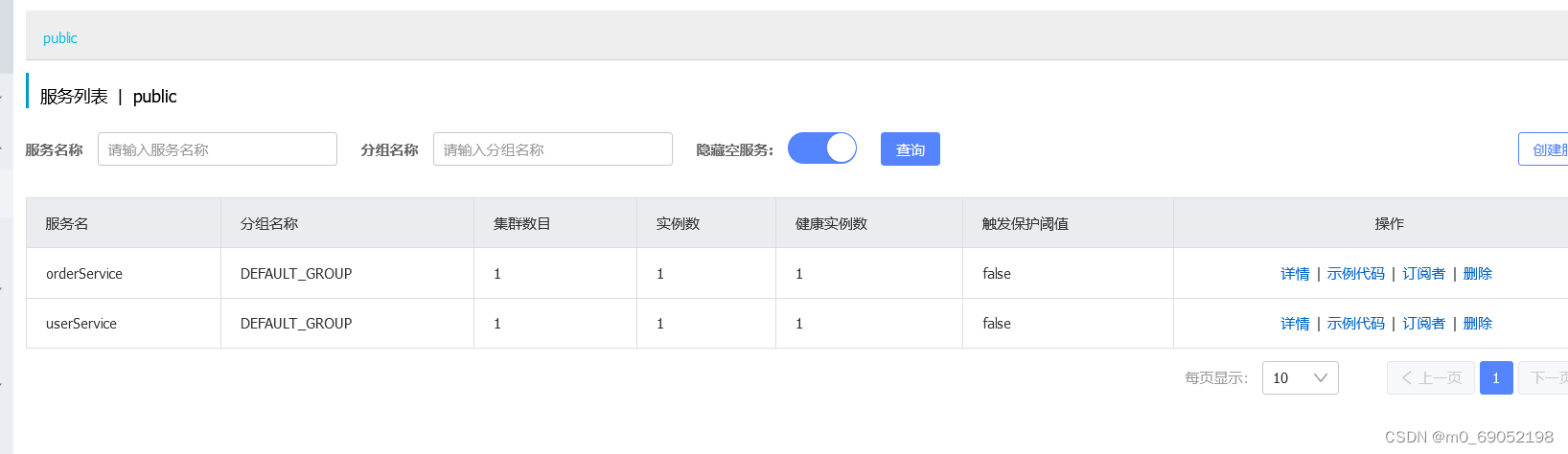
1.3.3 Nacos 服务多级存储模型
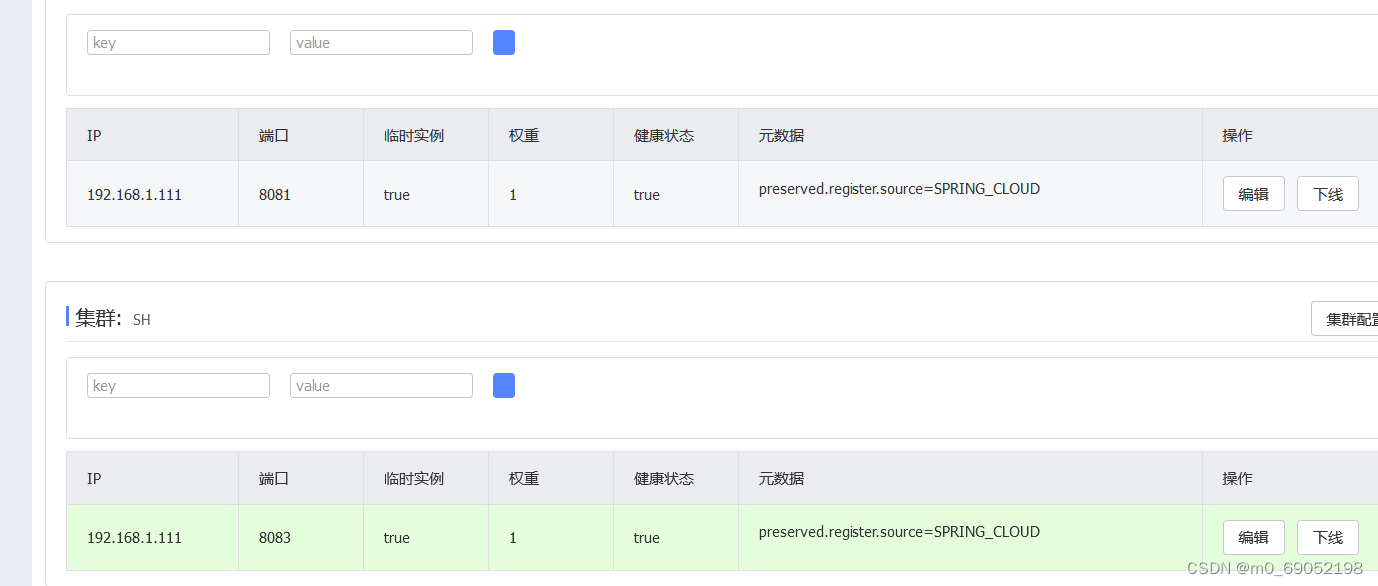
如果有多个实例,那么可以将实例分类,分为不同的集群,这种方式提高了服务的安全性以及可用性,一个集群挂了,另一个集群还可以使用
Nacos的分级为:第一层是服务,也就是Service,第二层是集群,存放着多个实例,第三个是实例。
那么如何设置集群呢?
以UserService为例:
现在在我们的练习项目中,有UserService的两个实例,

在启动之前,现在application.yml环境中修改配置
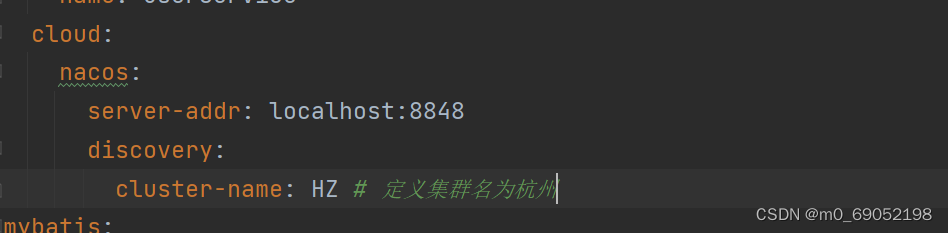
然后运行第一个实例,接着修改Yml文件,然后运行第二个实例
结果如下:
1.3.4 NacosRule负载均衡:
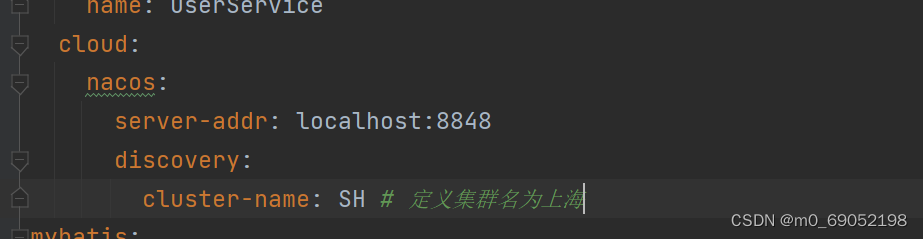
在上一节中,我们将UserService中的实例分为两个集群,如果我们想让OrderService在调用实例时,优先调用同一集群内的实例该怎么做呢?
1.先将OrderService的实例集群设置为HZ,与上面一致,先设置yml文件,然后重新启动
2.在yml文件中,进行负载均衡的配置
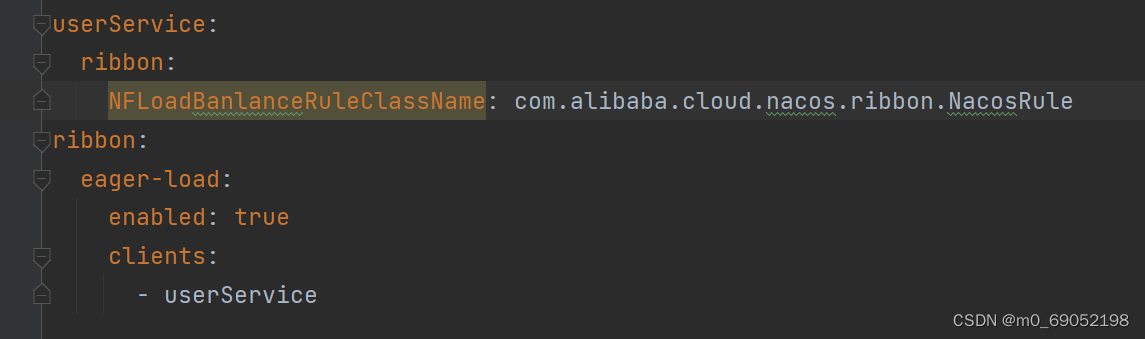
还可以设置权重,在
这个地方,设置权重的好处是,如果我们要进行版本是升级,可以先把部分实例的权重设置为0,然后用户访问其他实例,更新完成之后,再调整权重大小,完成其他实例的升级,实现无感升级。
Nacos的NameSpace
Nacos的NameSpace的结构如下,不同的NameSpace具有隔离性,也就是说,如果不在同一个NameSpace下,就没有办法访问,常用于不同环境的开发,例如生产环境以及开发环境
那么怎么设置NameSpace
1.先在控制台中找到
创建成功之后,在yml配置文件中进行配置

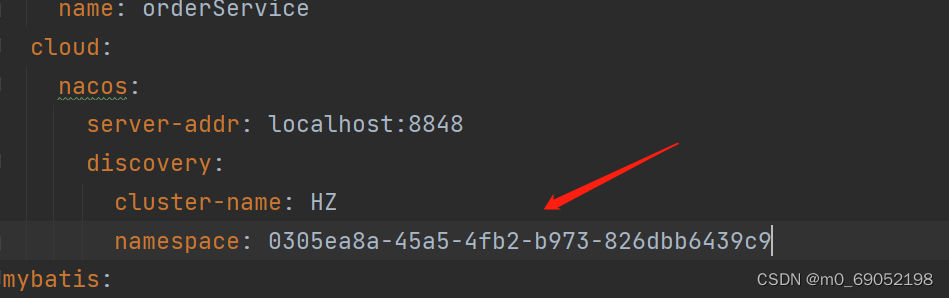
注意这里填的是ID,而不是名字
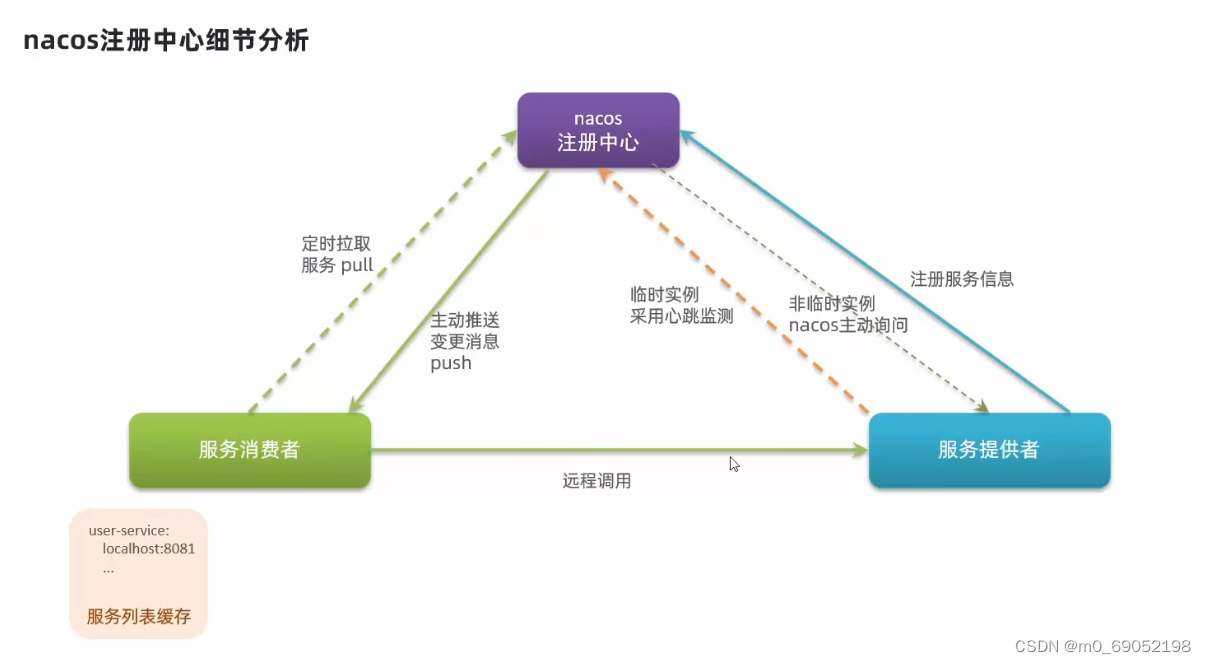
Nacos与Eureak的区别如下:
相同点:
1.两者都是通过心跳检测来判断实例是否存活
2.都是注册中心,提供服务的pull
不同点:
1.Nacos的实例分为临时实例以及非临时实例,他是通过心跳检测来判断临时实例是否可用,如果不可用就直接剔除,而非临时实例则是主动询问是否可用,并且停止就不会剔除
2.当服务实例发生变动时,Nacos会主动发送消息给服务消费者,增强了可用性和安全性。
1.3.5 Nacos的配置中心的功能
在日常开发环境中,我们可能会十到上百个微服务,如果我们需求对其进行全部更新,那么需要全部暂停,然后开始编写配置,过程十分麻烦,而在Nacos中,我们可以将部分配置文件交给他来解决,而一旦配置中心发生变化,微服务就会读取配置中心中的相应配置,实现热更新。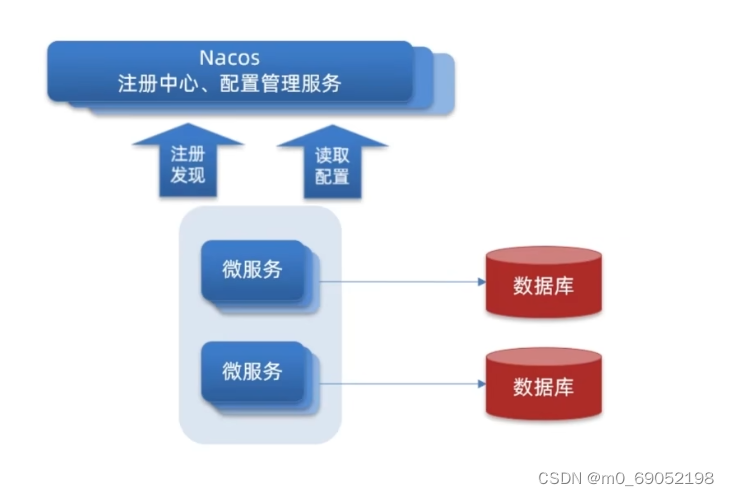
步骤如下:
1.在控制台中添加对应配置文件,文件名的命名规则通常为:微服务名+profile+.yaml,
2.添加配置属性,这里的配置通常是一些可能发生更改的配置,并不是所有的配置信息都要录入,例如数据库信息就不需要录入,因为大部分是不会更改的
Nacos读取到配置文件的步骤如下:
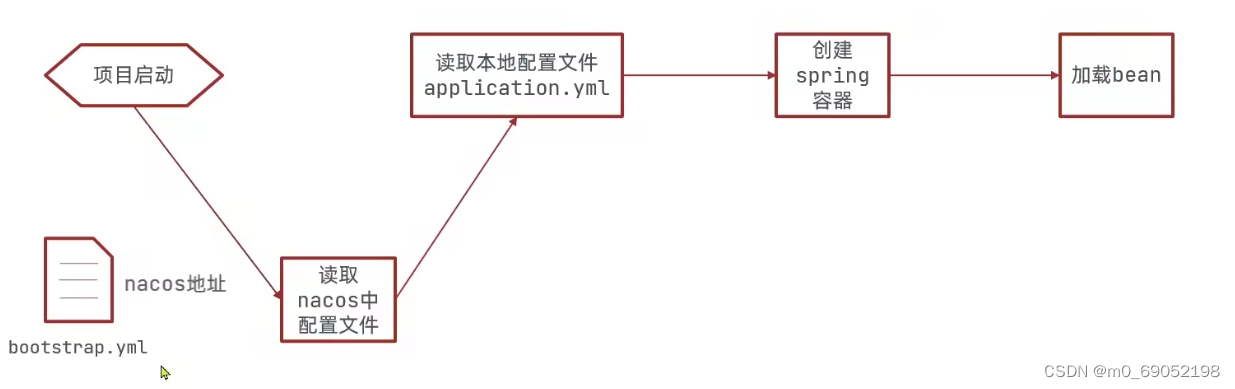
因为我们上一步中定义配置文件时,输入的是服务的名称,但是application的优先级在nacos的配置文件之后,所以会造成我们读不到服务名的情况,所以我们需要创建一个bootstrap.yml文件来存放nacos地址等信息。
具体步骤如下(以userService为例):
1.在pom文件中导入对应的坐标

2.创建bootstrap文件,用于存放nacos地址
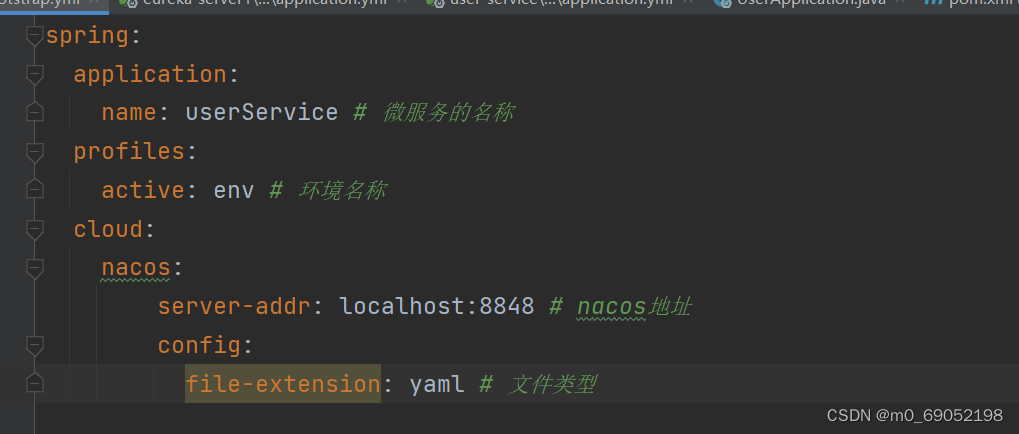
3.同时对application中的配置进行修改和删除
1.3.6 Nacos的配置热更新:
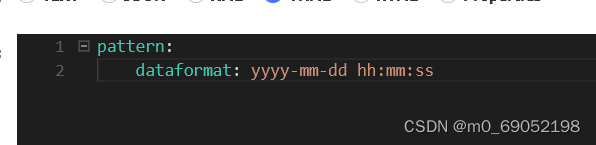
通过我们之前在nacos中的配置文件,我们有两种方法来实现配置的热更新,首先我们需要在controller层编写一个方法来输出这里的日期

此时想要实现热更新,可以直接在该controller层上面添加注释,
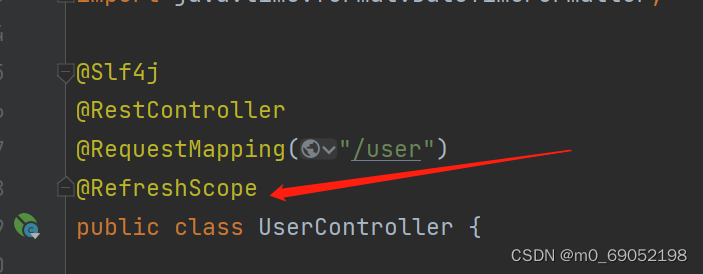
还有一种方式是新建一个配置类,然后通过自动注入的方法来完成更新,步骤如下:
package cn.itcast.user.Config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class patternProperties {
private String dateformat;
}
package cn.itcast.user.web;
import cn.itcast.user.Config.patternProperties;
import cn.itcast.user.pojo.User;
import cn.itcast.user.service.UserService;
import com.alibaba.nacos.api.config.annotation.NacosValue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.*;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
@Slf4j
@RestController
@RequestMapping("/user")
@RefreshScope
public class UserController {
@Autowired
private UserService userService;
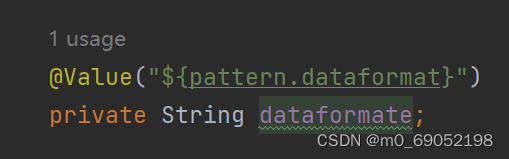
// @Value("${pattern.dateformat}")
// private String dateformat;
@Autowired
private cn.itcast.user.Config.patternProperties patternProperties1;
/**
* 路径: /user/110
*
* @param id 用户id
* @return 用户
*/
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id) {
return userService.queryById(id);
}
@GetMapping("/now")
public String getTime(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties1.getDateformat()));
}
}
1.3.7 Nacos的多环节配置共享
在我们上文中提到的环境配置,如果有一种环境是一个微服务不管是什么环境下都需要的配置,那么我们该如何设置呢?
步骤如下:
只需要在环境配置的控制台中,添加一个环境配置,命名格式如下:

此时,微服务就可以读取到该配置文件。

1.3.8 Nacos的集群搭建

这一步跳过了,之后看其他人的帖子,需要做一个配置的处理,不是很难。
1.4 Feign
1.4.1 Feign的基本使用
Feign是用来简化传递URL步骤的,在公司中的开发环境中,有可能出现有N个参数的情况,那么此时,使用上面的RestTemplate的方法,就很难维护,并且代码的可读性很差
此时我们就可以使用到Feign来简化这一步骤的开发,步骤如下:
1.在Pom文件中导入对应的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
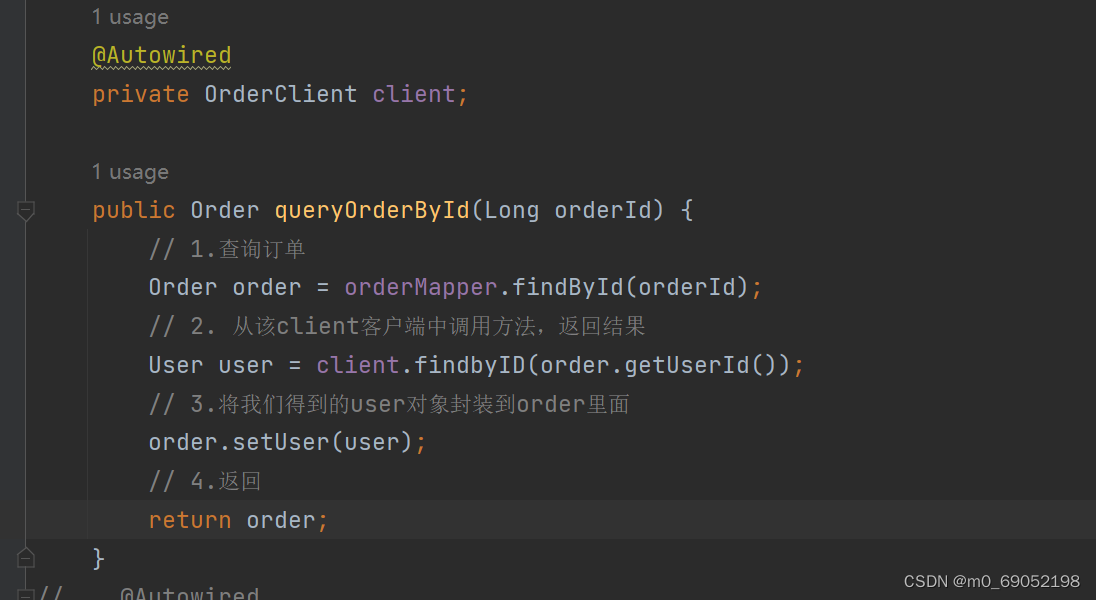
</dependency>2.在启动类加注释,并创建一个接口文件,用于存放上面的URL地址
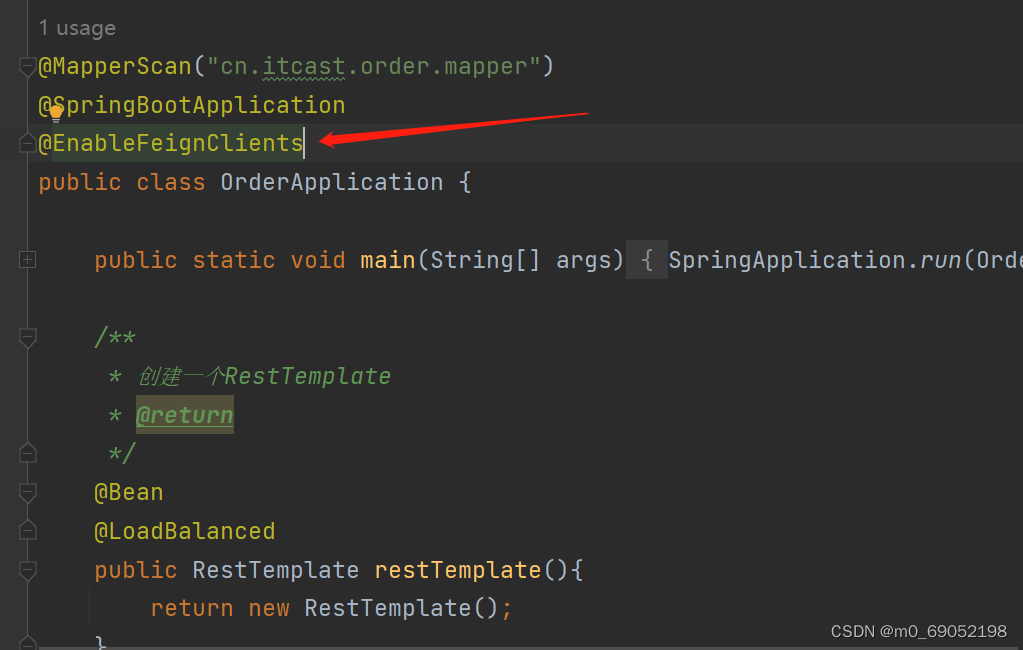
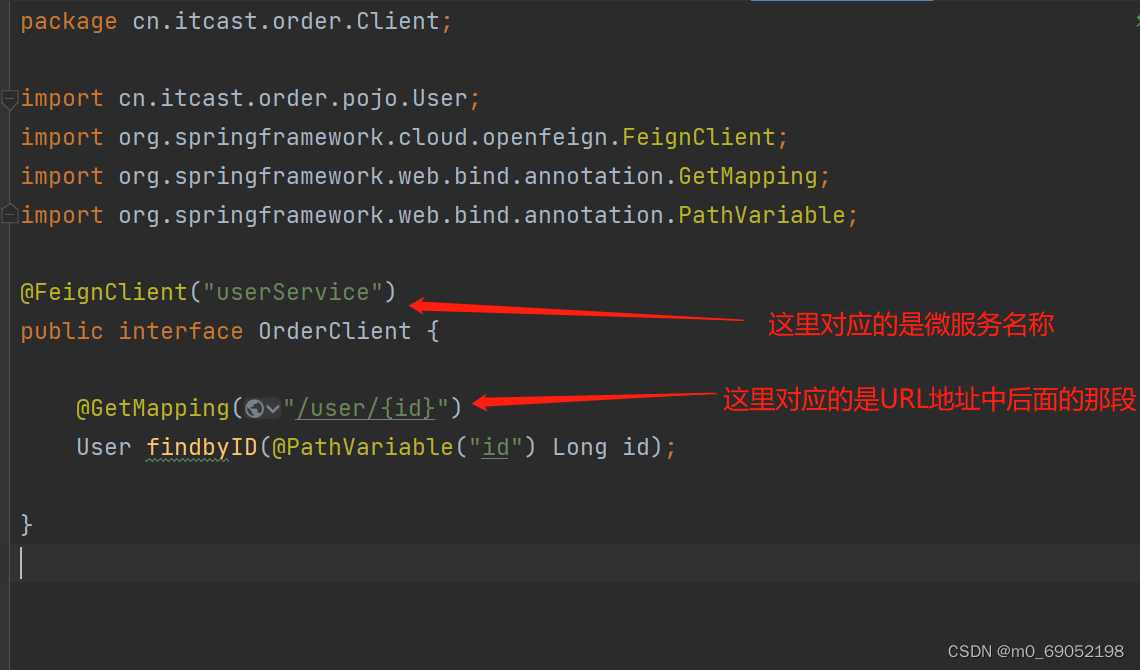
3.最后在Service层中完成调用

1.4.2 Feign的自动配置

我们一般是对日志级别进行配置,所以接下来,我们学习两种对日志文件进行配置的方法:
1.在配置文件中进行配置
feign:
client:
config:
default: # 这里是对全局进行配置
logger-level: full
feign:
client:
config:
userService: # 这里是对某一个微服务进行配置
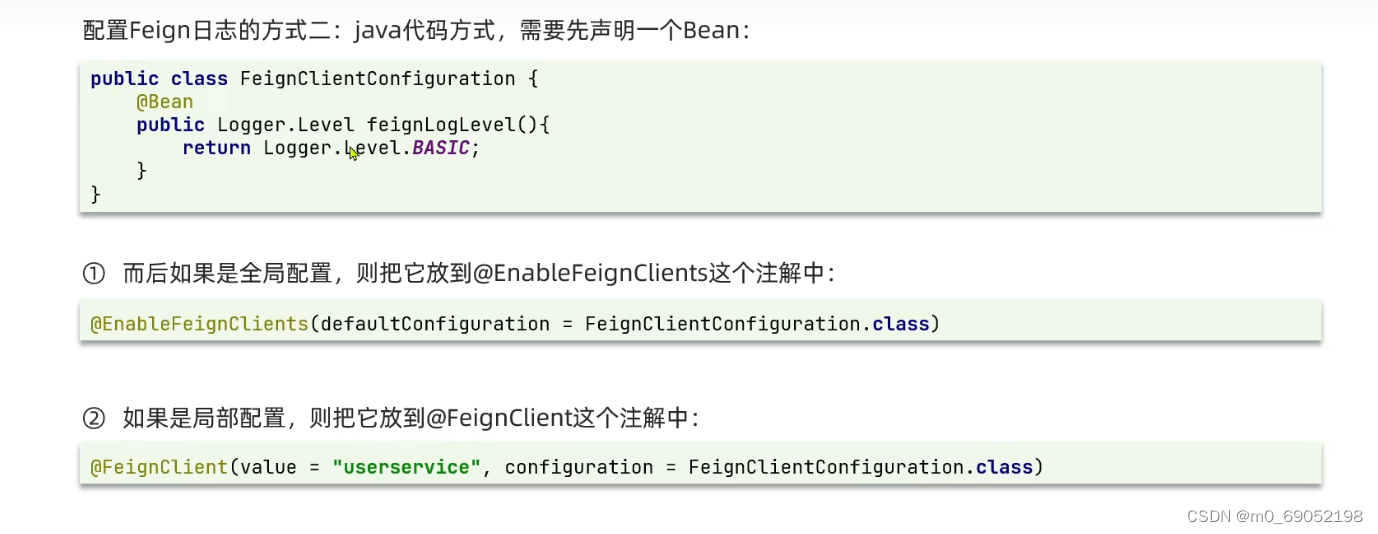
logger-level: full2.在Java代码中进行配置
定义一个类
package cn.itcast.order.Config;
import feign.Logger;
import org.springframework.context.annotation.Bean;
public class FeignClientConfigutarion {
@Bean
public Logger.Level feignLevel(){
return Logger.Level.FULL;
}
}
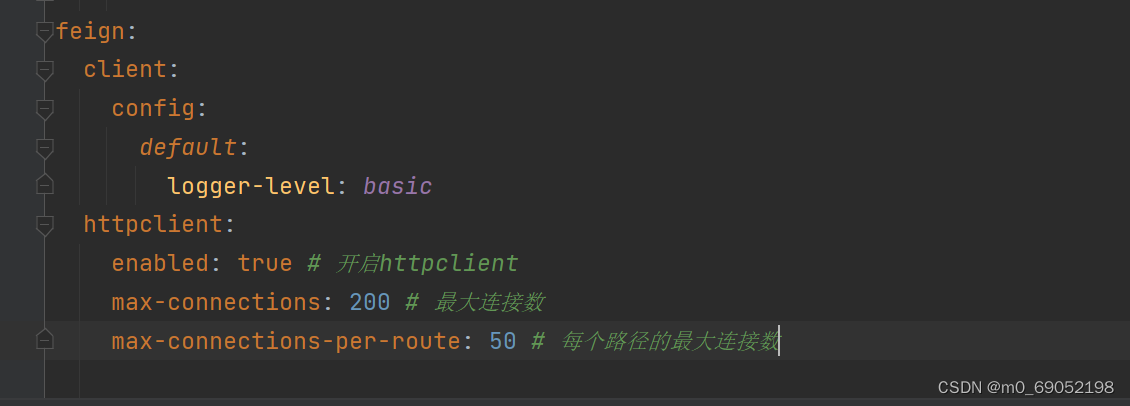
1.4.3 Feign的性能优化

日志调整上面有说,所以这里就不多赘述了,我们主要来看如何完成连接池的设置:
1.在Pom文件中添加坐标

2.在配置文件中添加对应的配置
1.4.4 Feign的最佳实践
在上述操作中, 我们可以看到,是由OrderService发送URL地址给UserService。然后调用UserService中的方法来查询,最后赋值给Order中。这种情况有一种缺点:如果有多个微服务都要查询User中的属性,那么就需要编写多个一样的类来发送URL地址给UserService。针对这种情况,我们可以使用两个方法来解决该问题。
1.写一个UserAPI来定义方法,然后通过继承的方法来继承这个API,减少了很多冗余操作,但是这种继承的方法会导致另外一种问题,就是会造成强耦合,如果进行修改,需要对其他类都进行修改
2.定义一个新的模块,然后将需要接受的POJO对象,FeignClient以及Feign的一些默认配置都定义到这个新的模块中,然后消费者直接调用就可以了。
实现的方法如下:
方式一的步骤:
第一步先定义一个接口文件,编写接口
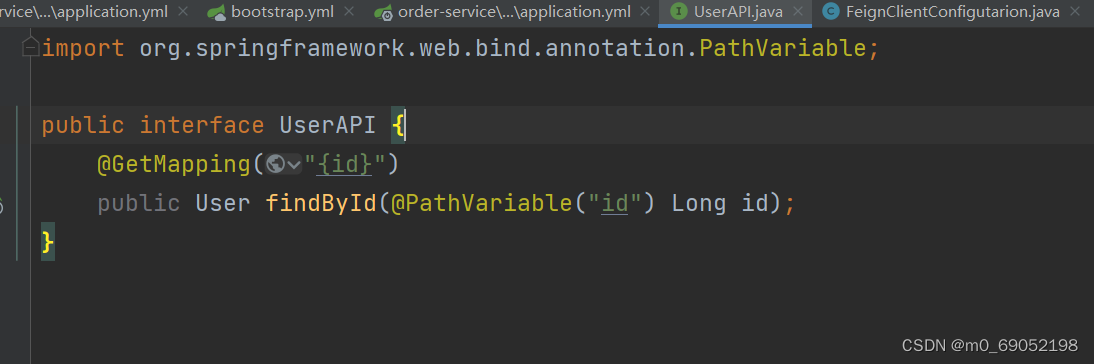
第二步,在Client中继承该接口
第三步,在Controller层编写
package cn.itcast.user.web;
import cn.itcast.user.API.UserAPI;
import cn.itcast.user.Config.patternProperties;
import cn.itcast.user.pojo.User;
import cn.itcast.user.service.UserService;
import com.alibaba.nacos.api.config.annotation.NacosValue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.*;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
@Slf4j
@RestController
@RequestMapping("/user")
@RefreshScope
public class UserController implements UserAPI {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
/**
* 路径: /user/110
*
* @param id 用户id
* @return 用户
*/
@GetMapping("/now")
public String getTime(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
@Override
public User findById(@PathVariable("id") Long id) {
return userService.queryById(id);
}
}
方式二的实现步骤如下:
1.创造一个新的模块,命名为Feign-API,然后将之前代码中跟Feign相关的代码复制粘贴进去。同时将需要用到的Pojo对象也复制进去
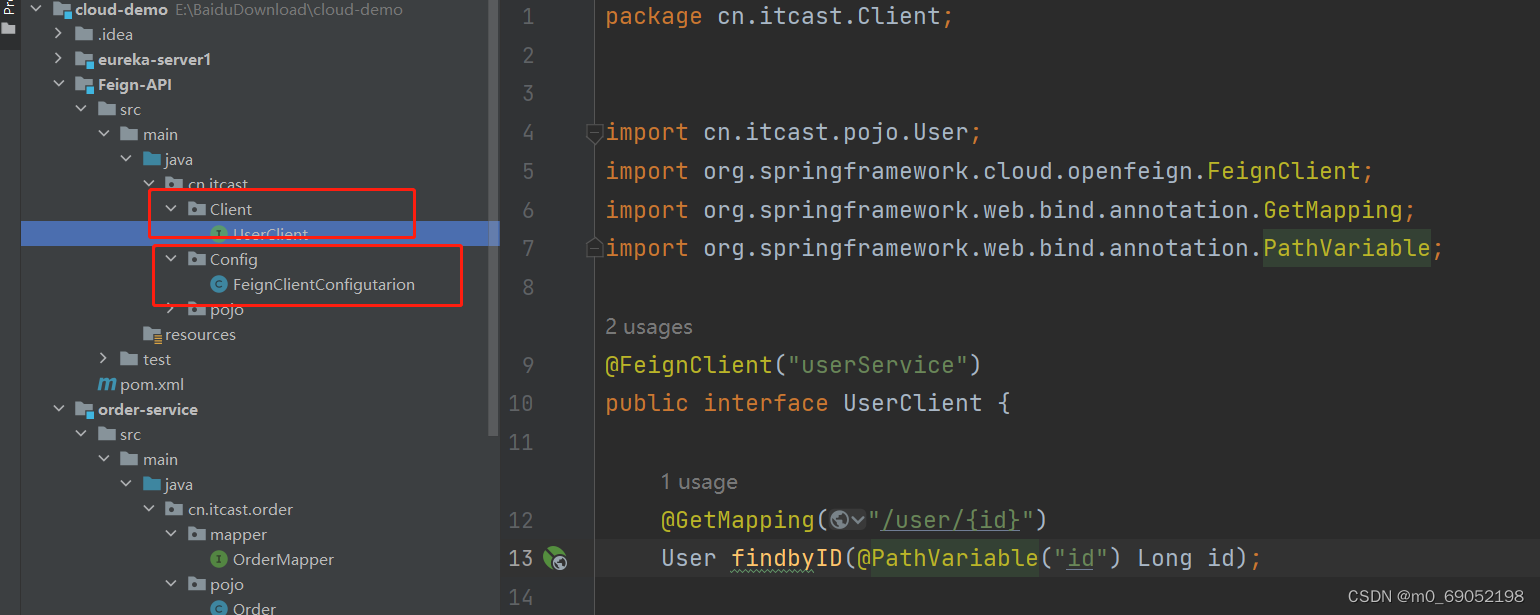
2.此时orderService中的部分相关代码就可以删除了,并且要导入这个Feign-API的坐标

3.把报错的信息重新导包即可。
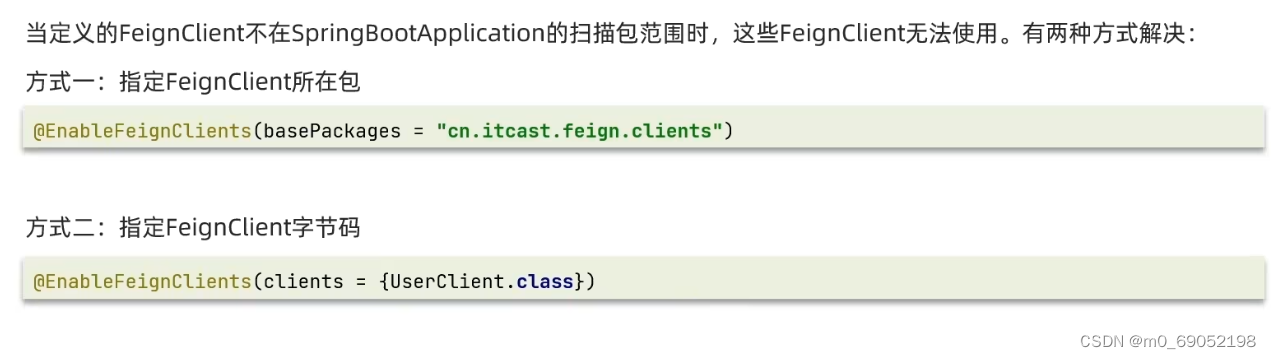
注意!在这里我启动项目时,发现IDEA一直报错, 日志文件显示是因为没有找到对应的Client文件,去找了博客,发现是因为不同的模块,导致启动类不会去主动扫描,所以在这里,我们需要在启动类上面的EnableFeignClients注解中 添加对应的扫描机制,OVER

1.5 GateWay网关
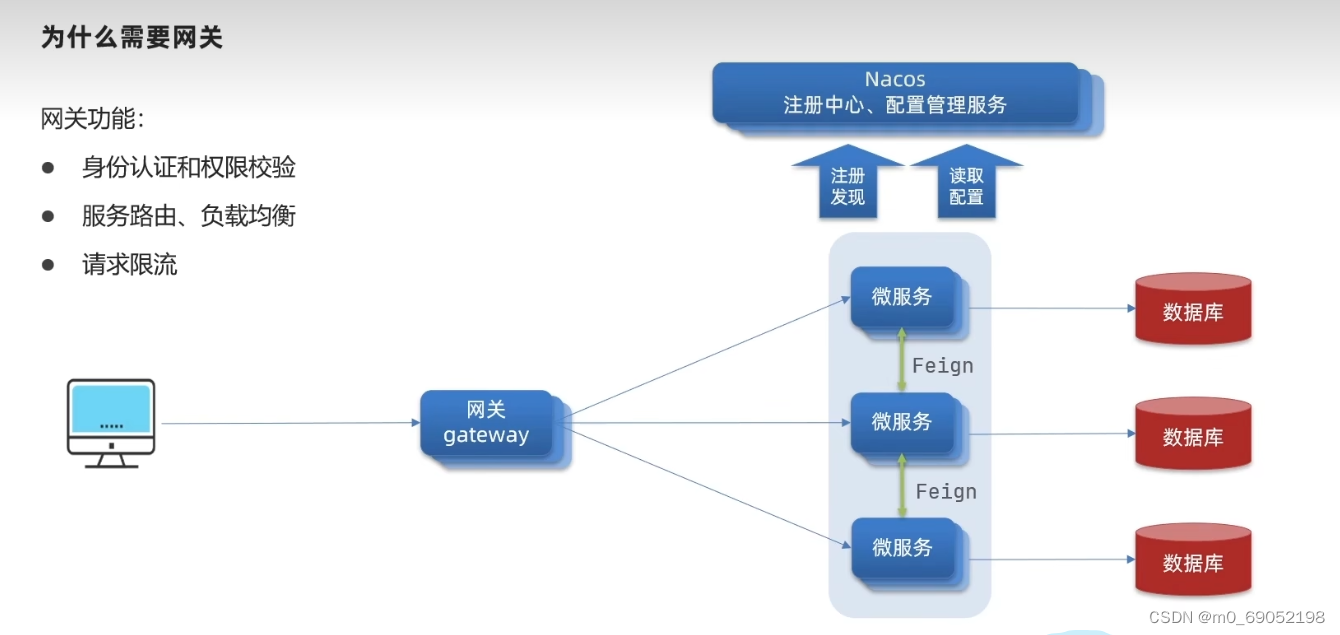
网关的功能主要如下:
1.身份认证:当外网进行用户访问的时候,需要进行身份认证,提高项目的安全性,防止破坏
2.服务路由,负载均衡:用户通过身份验证之后,由网关识别用户请求并纷发给相关的微服务,这一步叫服务路由,由于可能存在多个实例,所以需要负载均衡来进行调节
3.请求限流:当服务过多时,需要进行限流,防止服务崩溃
1.5.1 GateWay快速入门
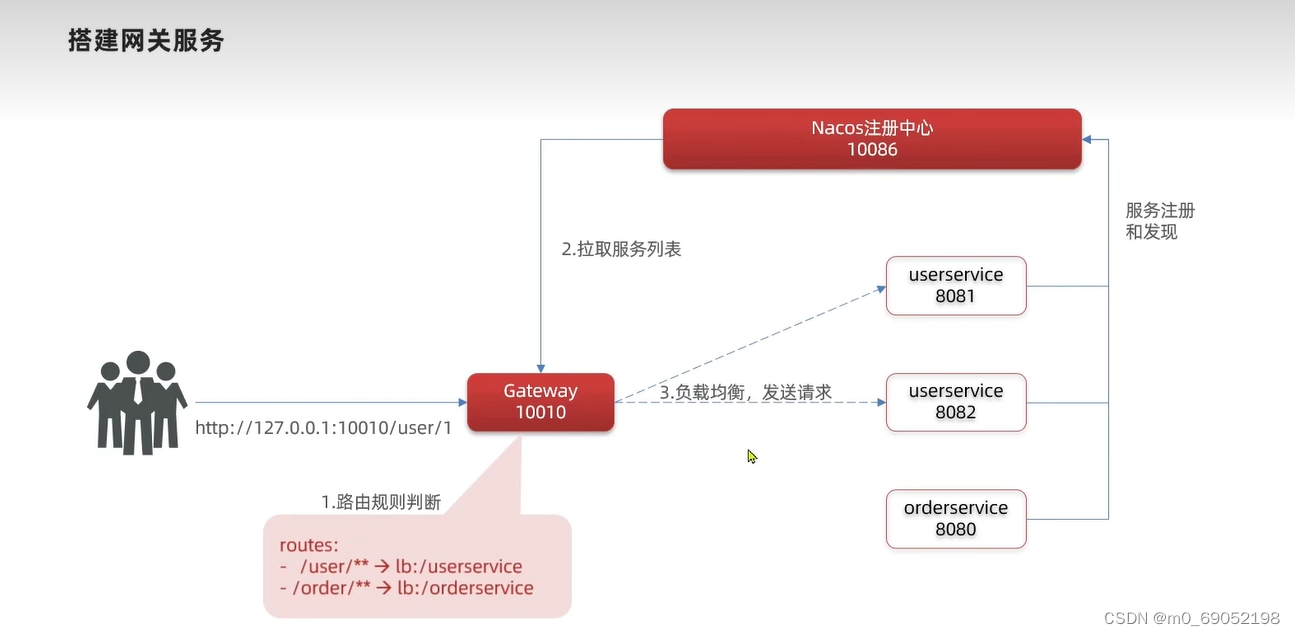
搭建网关服务的步骤:
1.创建新的module,并导入需要的坐标,并编写启动类
<!--网关的依赖-->
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>package cn.itcast.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Applcation {
public static void main(String[] args) {
SpringApplication.run(Applcation.class,args);
}
}2.编写路由配置及nacos地址
server: # 这一步是配置端口
port: 10010
spring:
application:
name: GateWay # 定义GateWay的名称
cloud:
nacos:
server-addr: localhost:8848 # 配置nacos的地址,以提供路由传输
gateway:
routes: # 网关路由的配置,是一个集合,可以有多个微服务
- id: user-service # 路由id(好像不是微服务的名称,只是个ID),必须唯一
uri: lb://UserService # 这一步是配置url地址,lb代表的是load balance
predicates: # 路由断言,类似于一个boolean判断
- Path=/user/** # 如果地址是/user/。。。那么就将地址发给userService这个微服务
3.启动服务
Gateway的步骤如下!!!
1.用户发送请求给网关
2.网关通过nacos注册中心得到对应的微服务IP
3.根据负载均衡规则,发给其中的一个
1.5.2 路由断言工厂
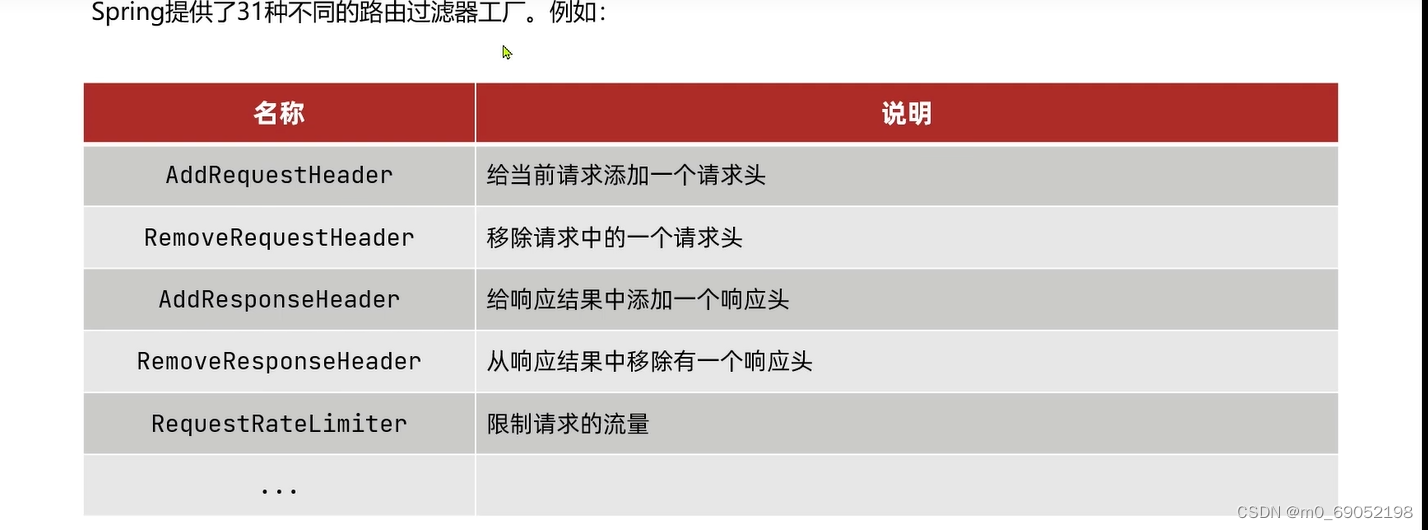
路由断言工厂有很多种,常用的如下表:
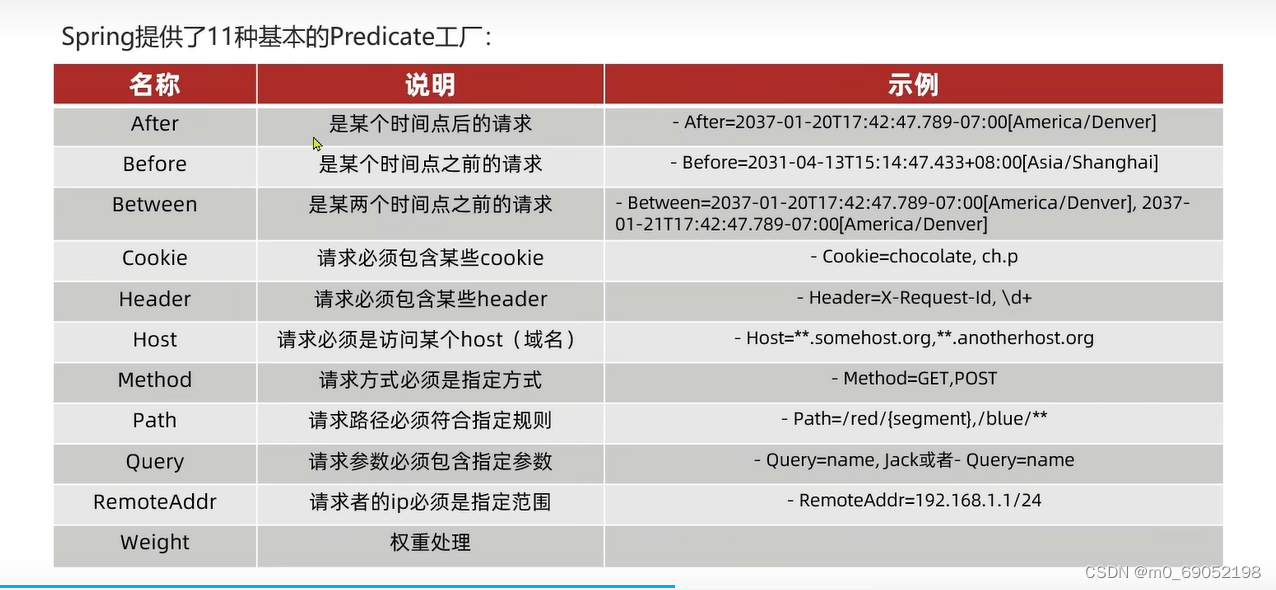
路由断言工厂的目的:
是为了判断用户输入的URL地址,是否符合规则,如果符合就转发给Nacos做处理,如果不符合就报错,其实就是一个if语句
1.5.3 路由过滤器
过滤器的作用主要是通过网关之后可以在响应头做文章,过程如下。用户发送请求通过路由之后,可以由过滤器处理,也可以在微服务返回时,由过滤器处理
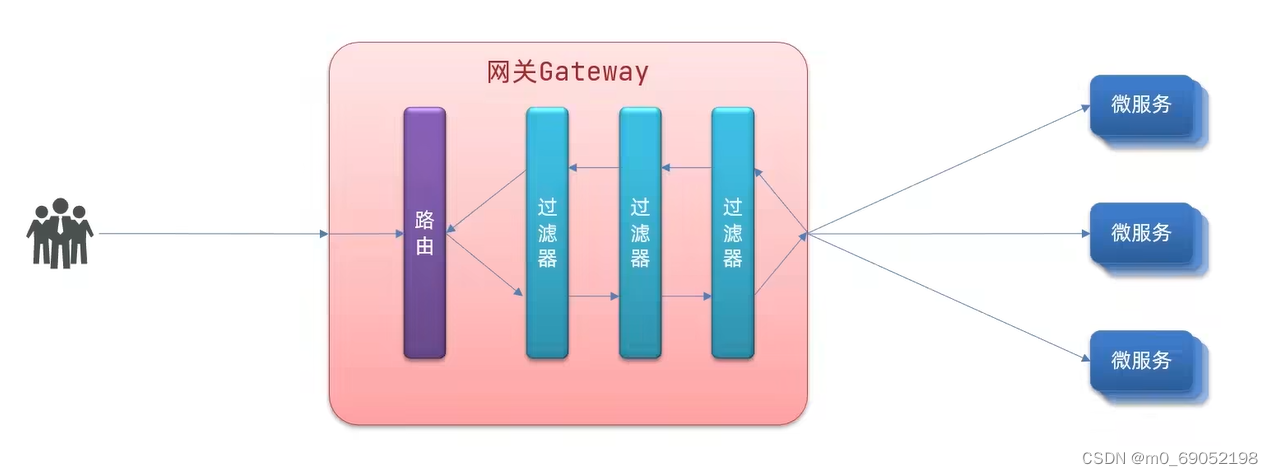
Spring提供了31种过滤器工厂,可在官网查阅详细,演示一个比较简单的AddRequestHeader,添加一个请求头
步骤如下:
1.在application文件添加配置项
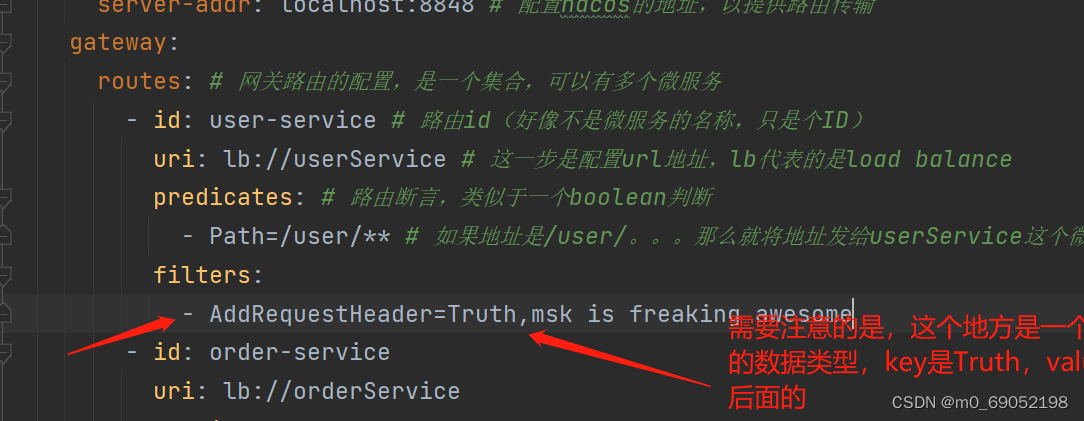
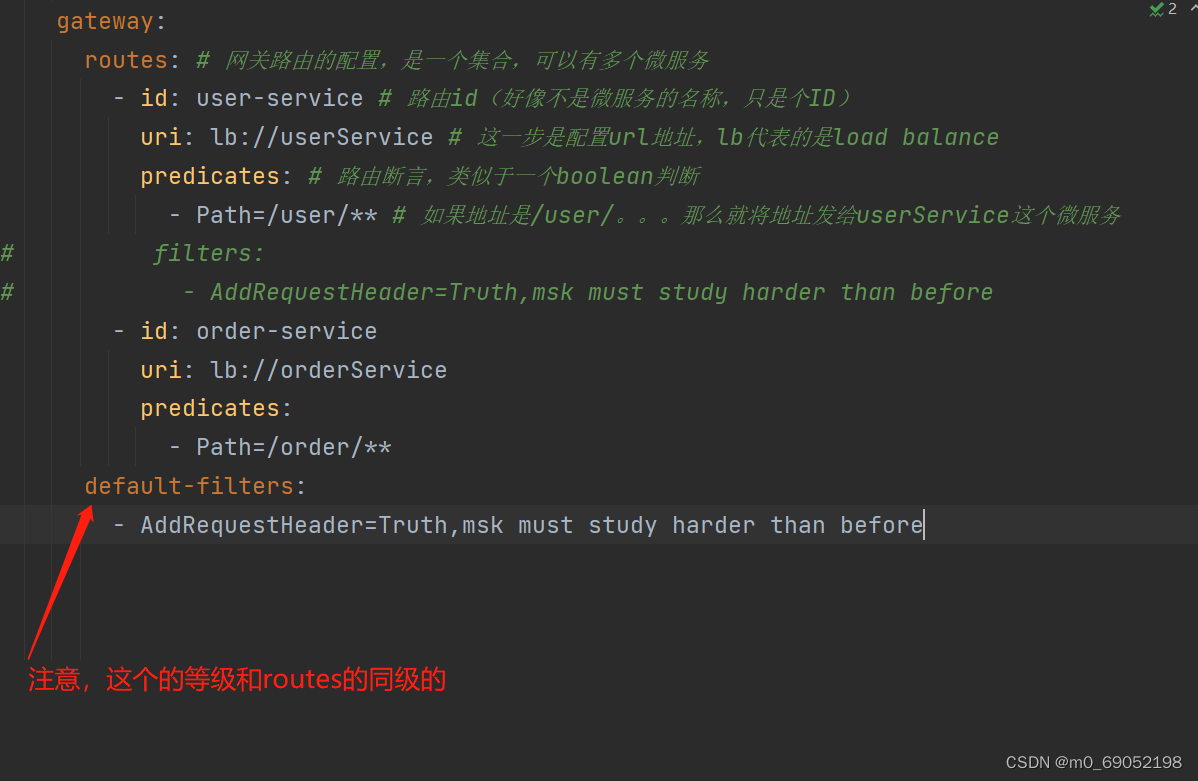
2.修改Service中的方法,来得到这里的value

PS,这种设置的过滤器可以直接设置成全局过滤器,减少重复操作
1.5.4 全局过滤器 Global Filter
我们之前已经学过在全局设置过滤器,但是这个与之前完全不同的是,他可以处理一定的业务逻辑,例如,可以得到访问对象的ID,如果可以访问就放行,不行就拒绝。
步骤如下:
1.在Module中定义一个类,然后实现Global Filter接口
package cn.itcast.gateway;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.util.MultiValueMap;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Order(-1) //这个注解是设置这个过滤器的执行顺序,越小执行优先级越高
@Component
public class First_Filter implements GlobalFilter {
/**
* 这里的exchange可以得到上下文中的Request和Response,chain用于将请求转给下一个服务器
* @param exchange
* @param chain
* @return
*/
//我们要做的是判断,访问中是否存有参数Authorization,Authorization的值是否为admin
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1.获取请求参数
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, String> queryParams = request.getQueryParams();
//2.查询参数的对应值是否为admin
String authorization = queryParams.getFirst("Authorization");
if ("admin".equals(authorization)){
//如果是,则放行,放行的规则就是chain,将exchange传给下一个过滤器
return chain.filter(exchange);
}
//不是的话,就得到response,然后直接返回,并且,设置返回结果
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
}
1.5.4 过滤器排序
在GateWay中,我们有三种过滤器,那么执行顺序是什么样的呢?在路由过滤器和defalut 过滤器中,我们可以清楚的知道他们是一种过滤器,都是GatewayFilter,而GlobalFilter,通过Fileter设配器,最后也会变成GatewayFilter,所以他们最后都是一种过滤器,并且都在一个集合中
在Global中,我们可以定义他的顺序,但是其他俩个的顺序是由Spirng定义的,又该怎么排序呢?
答,按定义先后顺序
那么此时,上面的过滤器的序号和下面都是1,是谁先执行呢?如果GlobalFilter的顺序也是1 的情况下呢?
顺序如下

1.5.5 跨域问题
简单的说,因为域名的不同,可能会导致浏览器禁止跨域,或者是域名相同,但是端口不同的情况下,浏览器也会禁止跨域,这种情况下,就需要由网关来设置相关配置,来与浏览器进行交互
解决方案:CORS方案
配置信息如下:

1.6 Docker
在我们日常开发过程中,需要将开发好的代码部署到服务器上,同时呢,这个代码需要有相关的组件依赖,不同的组件依赖不同,同时版本也需要一致,在这种条件下,环境搭建就是一件很麻烦的事情,所以出现了Docker容器,Docker会将各个组件(Nginx,Mysql,Node,Reddis)等等需要的依赖以及对应的版本,打包起来,在服务器上运行,并且相互独立。

此时就出现了一个新的问题,Linux有很多不同的版本,例如redHat,Centos,Ubuntu等等,这里牵扯到一个内核的问题,他们的内核都是Linux的内核(内核,就是通过使用内核的指令来使用各种硬件,但是这些内核指令往往过于简陋,很难使用),针对内核的问题,这些系统将内核包装成一个个的指令放在库中,通过调用指令来执行内核指令再对硬件做出对应的操作。此时不同的系统版本,指令库也不同,那么现在又该怎么办呢?Docker顺带将需要的函数库打包好,然后通过函数库直接调用内核,再去处理硬件问题,这样就不需要去通过系统来再调用内核了
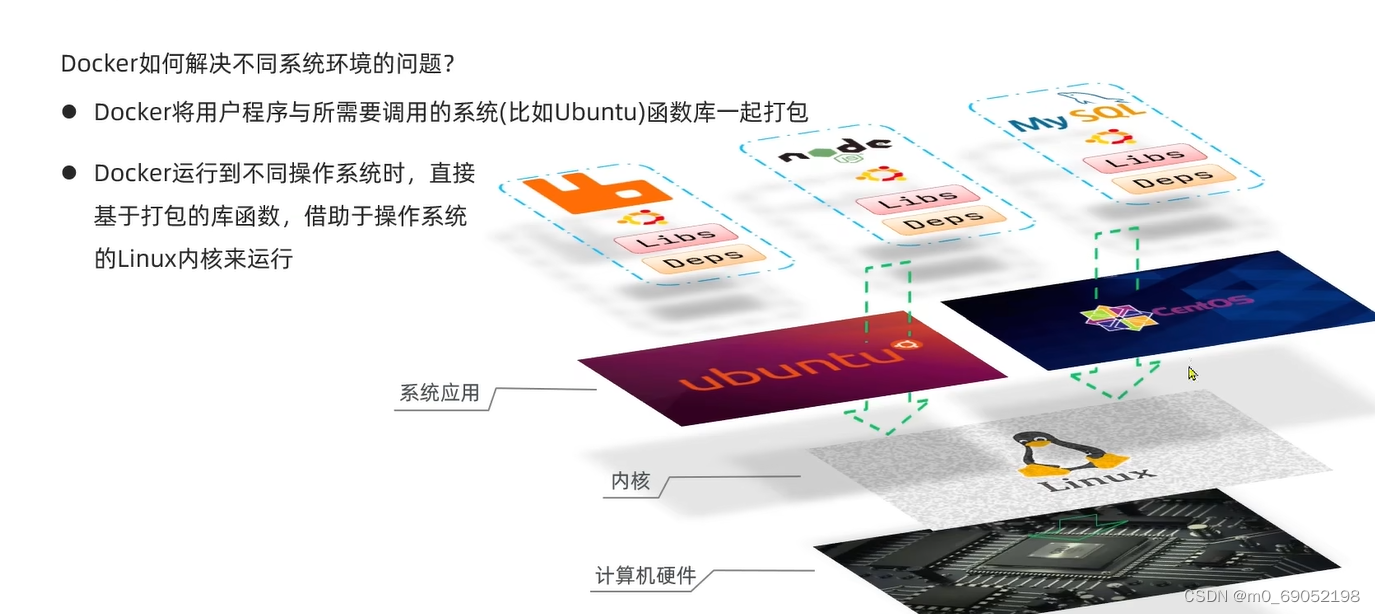
总结:Docker是一个快速完成交付应用,运行应用的技术
1.6.1 Docker与虚拟机的差别
在上述过程中,Docker与虚拟机的感觉有点像,两者都是独立的环境中运行各种程序,但是不同的在于,虚拟机在主机上运行的过程中时,它是事先创建了一个虚拟的硬件环境,然后通过虚拟的硬件环境将函数发给主机的操作系统,再调用真实的操作系统,造成的结果就是运行很慢 ,很占内存。Docker则不同,不同在于它直接调用内核,不需要经过虚拟的硬件环境,所以速度较快。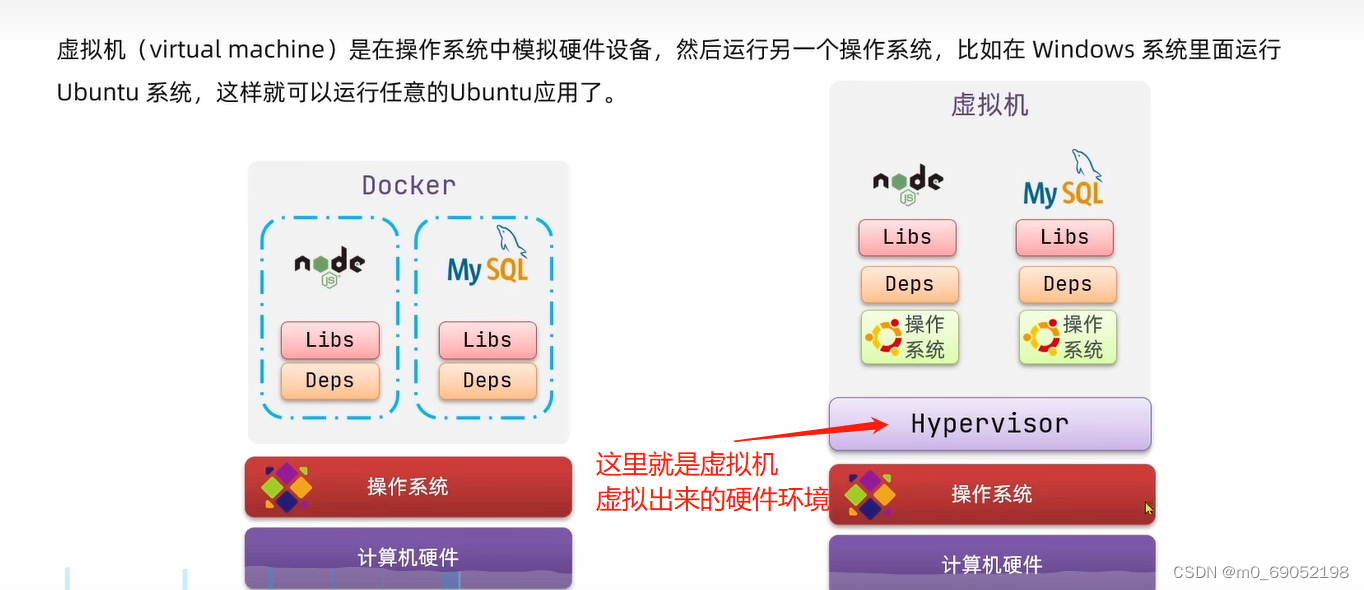
两者的详细对比图如下
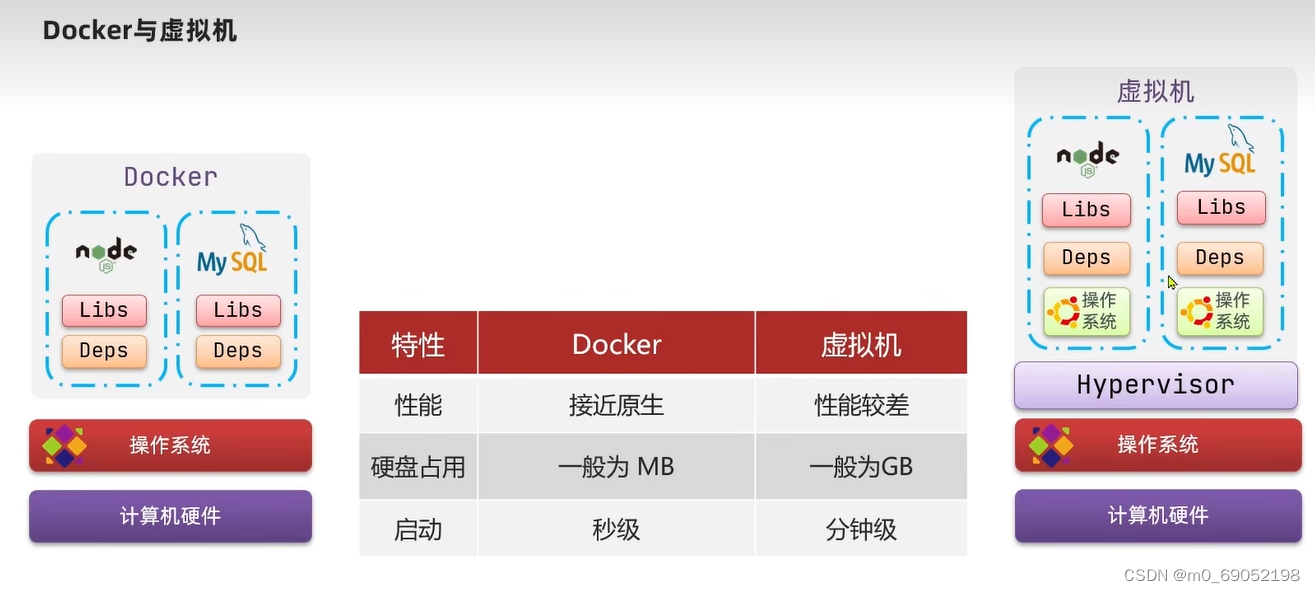
综上所述,Docker其实相当于一个系统进程(个人理解,有点类似与一个软件,运行就完成搭建了),而虚拟机是在一个操作环境中搭建另外一个操作系统
1.6.2 Docker的三大核心
Docker中含有三个核心组成部分:1.镜像 2.容器 3.仓库
镜像,Docker将应用程序及其所需要的依赖,函数库,环境,配置等文件打包在一起,称为镜像(个人理解,类似于一个已经安装好的软件),镜像是可读不可写的!!!
容器,镜像中的应用程序运行起来后形成的进程就是容器,只是Docker会给容器做隔壁,外部不可见,每个容器都有属于自己的硬件部分(个人理解,镜像运行起来以后,形成的进程就是容器,同时每个容器之间都是独立的,互不干预,再简单一点,镜像类似于一个游戏账号,容器就是这个游戏账号的角色,可以有多个角色,多个角色都是独立的,没关系。同时我们可以在这个角色中进行各种操作),容器是可以写的

仓库,就是Github一样的,存放镜像和容器。
Docker架构
Docker是一种CS架构,Client和Server,用户在Client端写指令,然后指令交给Server处理
1.6.3 Docker基本操作
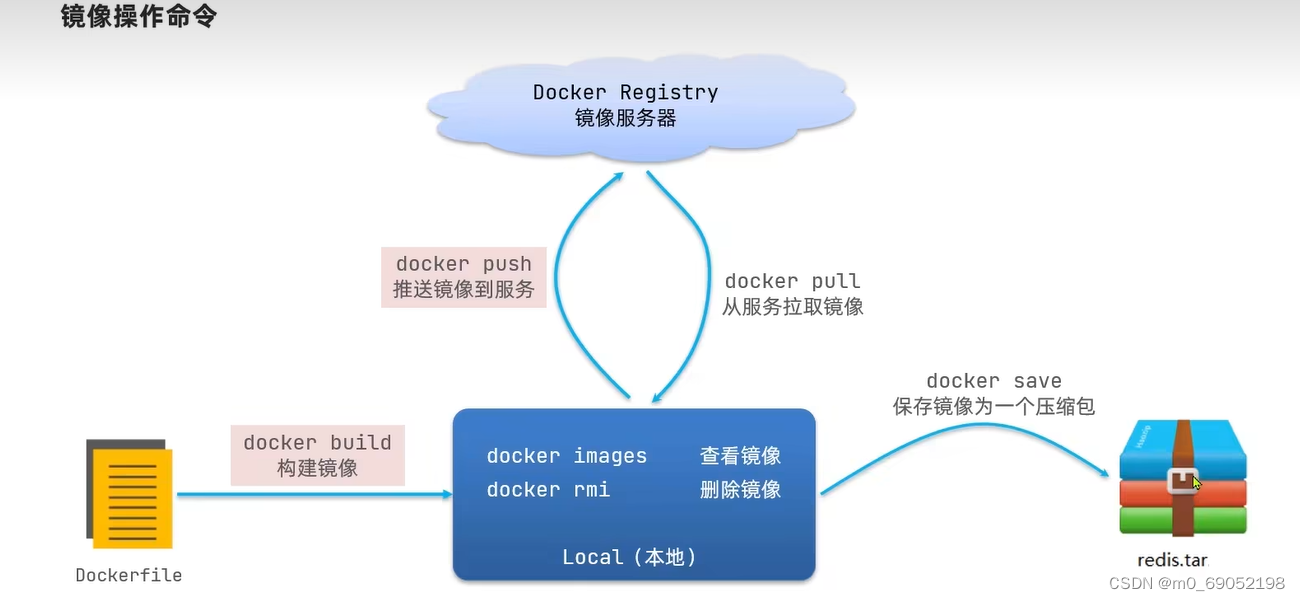
镜像的相关命令,[repository][tag],前面是服务名,后面是版本号
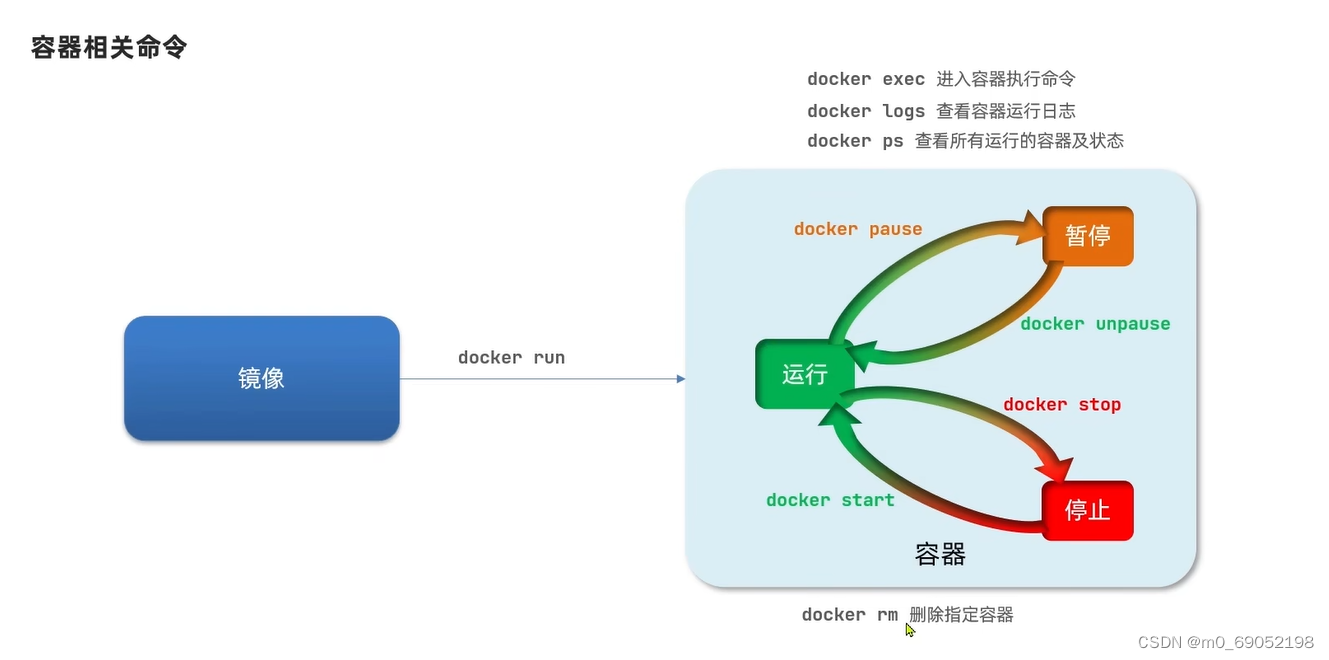
容器的相关命令
那么如何去创建一个容器,步骤如下:
1.在Dockerhub上查看对应的容器运行命令,我们已Nginx为例
docker run --name ContrainerName -d -p 8080:80 nginxdocker run :创建并运行一个容器
--name :给这个容器命名
-d 后台运行的意思
最后的nginx是镜像的名称!
-p 将宿主端口与容器端口进行映射,冒号左侧是宿主机端口,右侧 容器端口
这一步的目的是:因为我们的容器是一个完全隔离的环境,所以外部环境是不可以直接访问容器的,需要做一个映射,外部主机访问宿主机端口,然后由宿主机再转接给容器!!!

最后我的命令就是
运行成功

1.6.4 数据卷
数据卷(volume),在我们之前对Nginx的操作中,都是进入容器,然后在容器内的文件夹内对文件数据进行操作。这就带来了以下的问题:1、每次修改都要进入容器,容易污染容器,同时太多次的修改会导致我们记不住对容器做了哪些修改。2. 在日常开发过程中,我们可能有多个容器,对多个容器进行重复修改的操作很是麻烦,不利于开发。3. 如果我们需要对容器进行迭代升级的话,数据也会跟着旧的容器删除,保存的话,数据量太大了。
针对以上问题,提出了相应的解决方案,数据卷(Volume),它相当于是在宿主主机的文件系统中创建了对应的文件,然后挂载在容器中。简单的说,就是类似于虚拟机中的文件系统,在本地主机中也有,同时这些数据可以共享,也就是多个容器可以使用一个文件。如图:
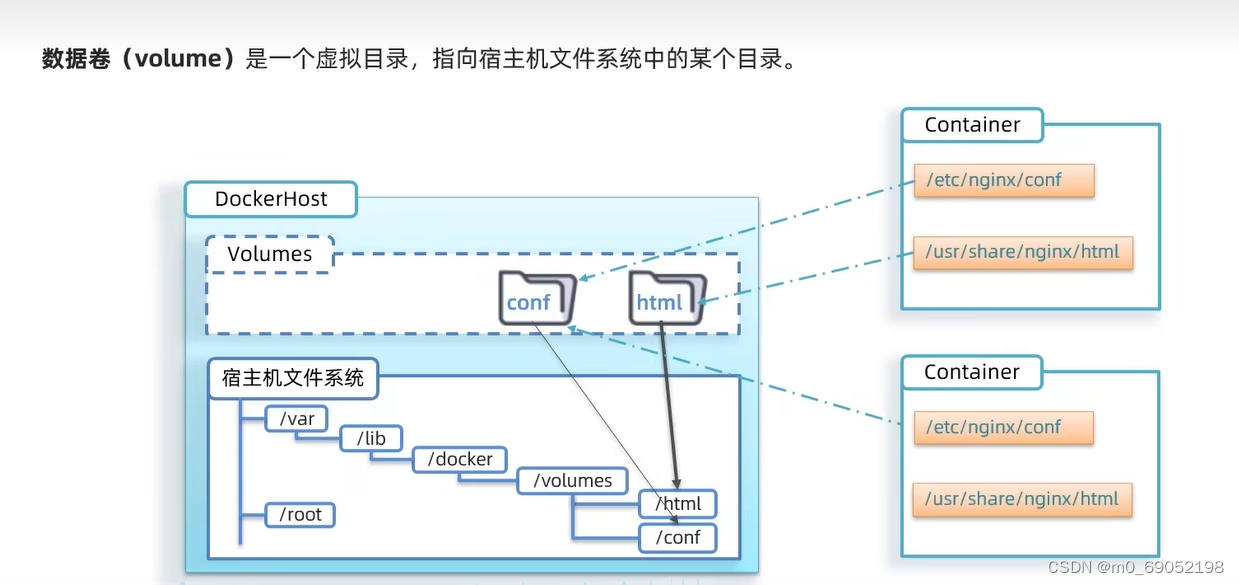
数据卷的相关命令:

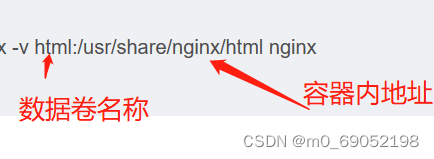
挂载数据卷
在创建容器时,要添加挂载操作的命令如下:
docker run -d -p 80:80 --name MyNginx -v html:/usr/share/nginx/html nginx
1.6.5 自定义镜像
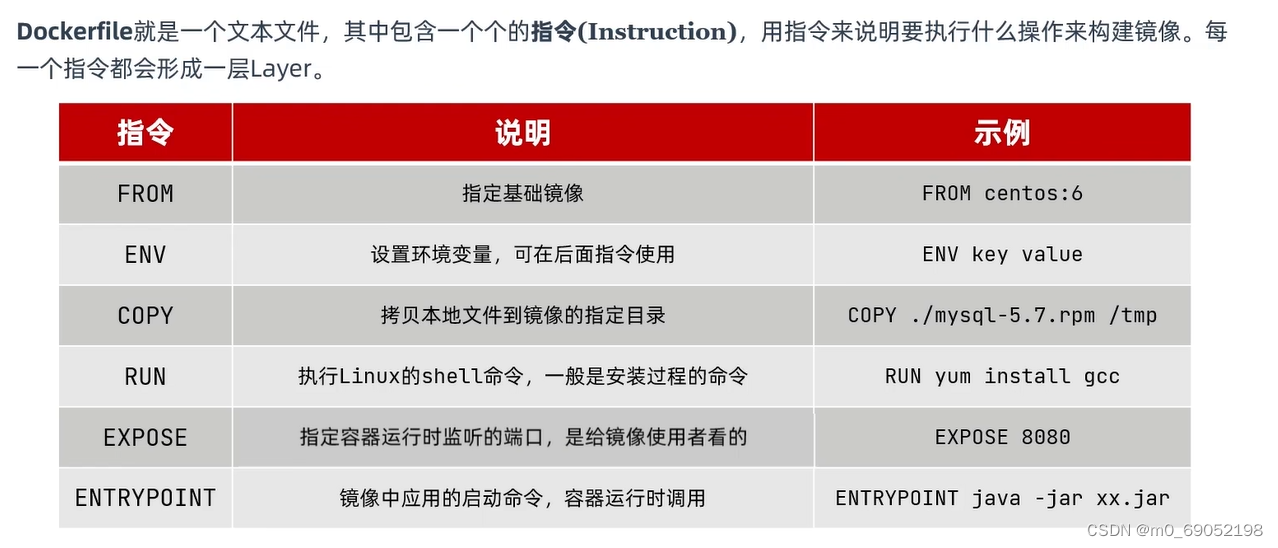
根据DockerFile,来创建镜像,Dockerfile中主要含有的就是一个个的指令,然后Docker解读这些指令,完成创建
根据资料来创建一个基础镜像,以下是DockerFile

最后根据docker build命令,创建镜像
注意!!!最后一个. ,表示是在当前文件夹内!!!
不可以省略
通过分析Dockerfile可以发现,如果我们继续构建jar包的镜像,这一段重复的,所以我们可以直接使用一个封装好的指令库来替代这一层

我们可以使用 java:8-alpine 来创建镜像,步骤如下

1.6.6 DockerCompose
用于部署Docker微服务等(现在主要是使用K8S)
1.7 RabbitMQ消息队列
1.7.1 同异步通信的区别
同步通信的优缺点如下:
同步通信中,就是类似于我们日常生活中的电话,一个人只能与一个用户通讯,并且消息是及时的,异步通信类似于微信,发送之后等待对方回答即可,一个人可以与多个用户通讯。在我们之前的开发中,我们使用的大部分是同步通讯,这就出现了一个问题,如果我们开发了一个支付业务,要通过以下流程
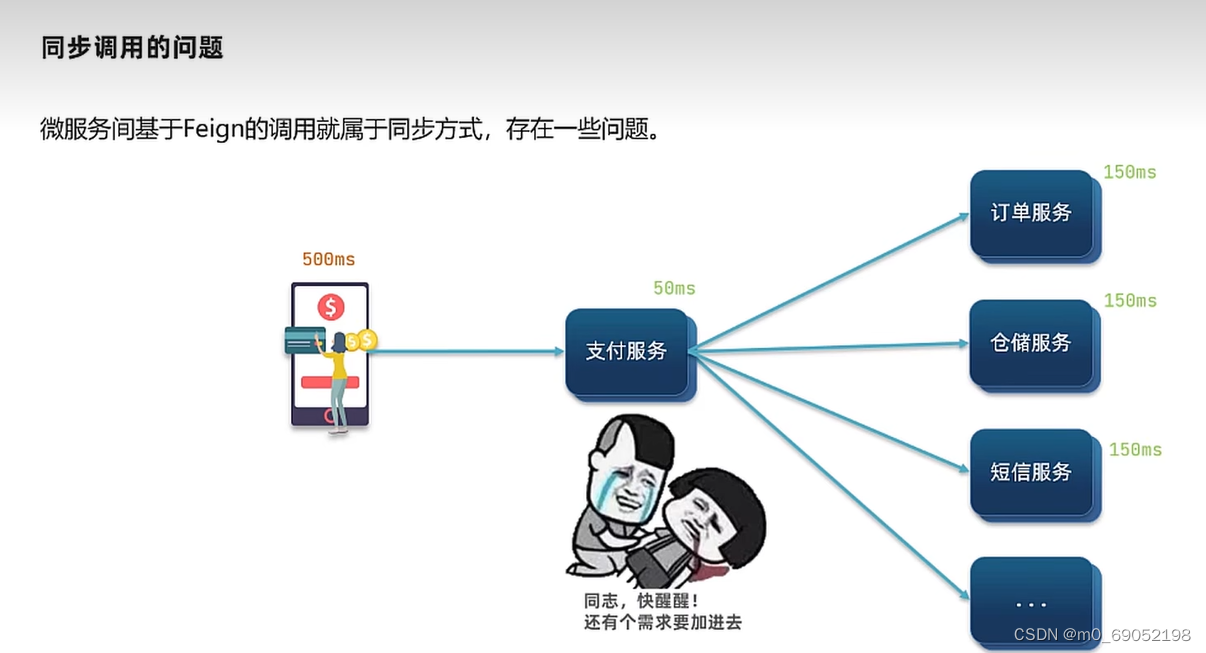
如果使用同步通讯,就是以上问题,资源使用率较低,速度慢,并且处理不了过多的请求。
缺点如下: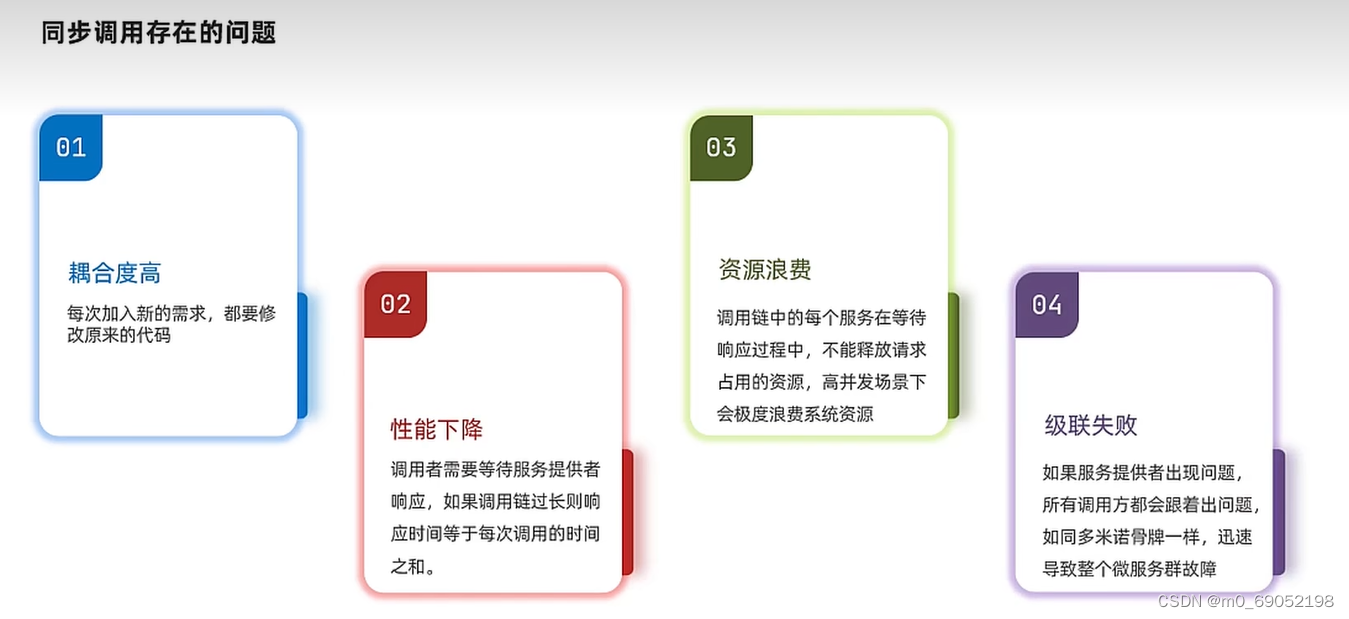
异步通信的优缺点如下:
根据上述问题,我们就可以设置异步通信来解决这些问题,添加一个broker来分发服务,同时这些服务都是并行处理的,这样就解决了上述的几个问题,1.如果要添加业务,只需要将业务添加到Broker中即可,2.性能提升了,因为可以一次处理多个业务,所以资源的利用率也得到了有效提升,3.资源浪费也解决了,4.级联问题,如果有一个业务挂了,也不影响支付和其他业务,只需要重启挂掉的业务就可以了。
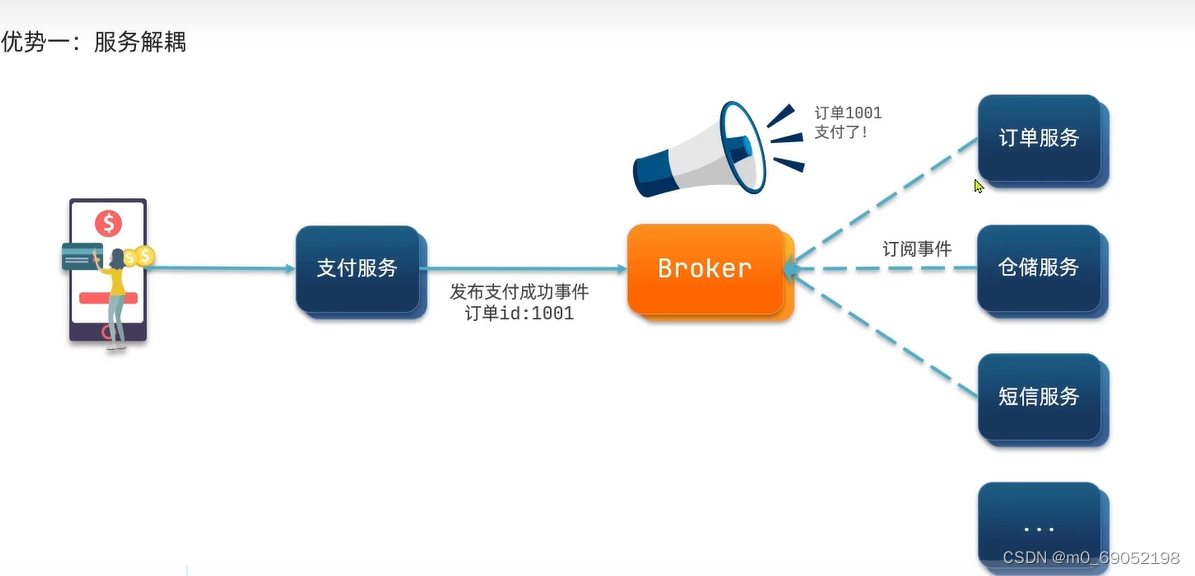
缺点如下,因为异步的关键点是添加了一个Broker,所以非常依赖Broker的可靠性,安全性和吞吐能力,2. 架构复杂,业务没有明显的流程线,不好维护。
1.7.2 MQ消息队列
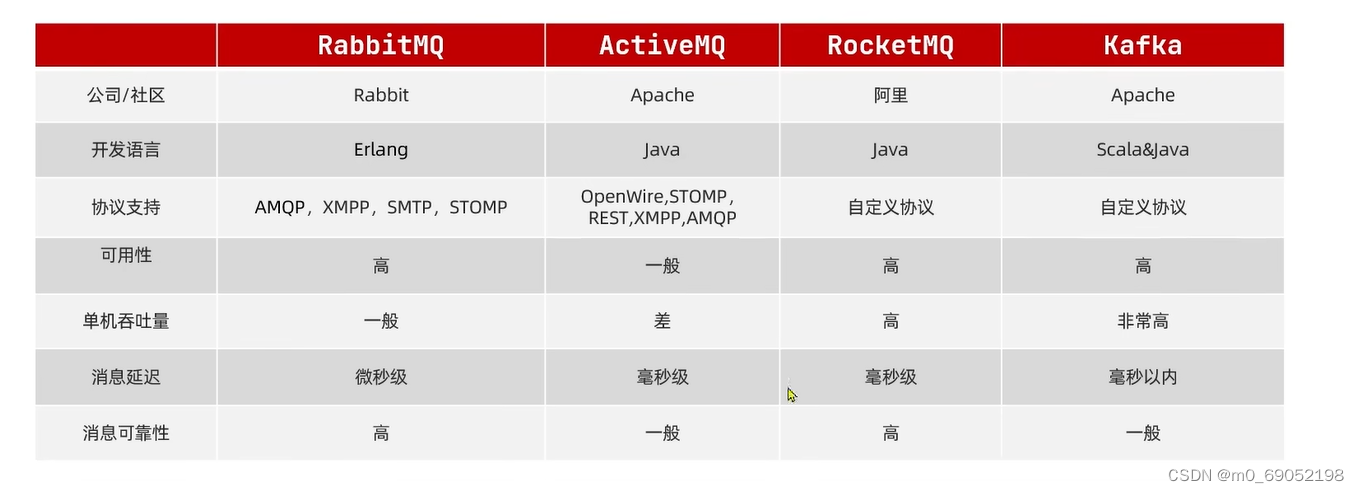
MQ消息队列,也就是上述中提到的Broker,当前市面上常用的几种MQ,分别如下,
1.7.3RabbitMQ
· 首先就是安装与部署,在linux中通过镜像安装与部署RabbitMQ,命令如下
docker pull rabbitmq:3-management // 拉取镜像
run -e -RABBITMQ_DEFAULT_USER=root -e RABBITMQ_DEFAULT_PASS=123123
// --name mq --hostname mq1
// -p 15672:15672 -p 5672:5672 这里设置的两个端口的意义是,15672是服务器端口,5672的客户端端口
// -d rabbitmq:3-management
RabbitMQ的架构如下图,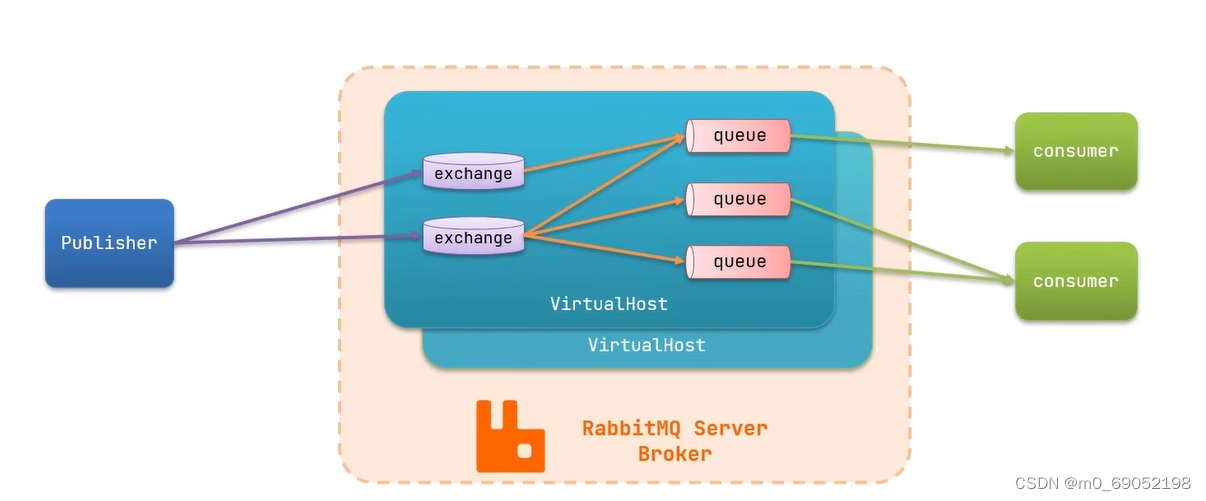
用户发送请求给交换机,再由交换机发送给消息队列,由消息队列分发给消费者,最后完成业务,这里要注意的是,这里用的是虚拟主机,也就是每个用户之间都是隔离独立的。
1.7.4 Spring AMQP
AMQP就是一种消息队列协议,Spring AMQP是基于AMQP的消息传递解决方案的开发,他提供了一个“模块”作为用于发送和接收消息的高级抽象。
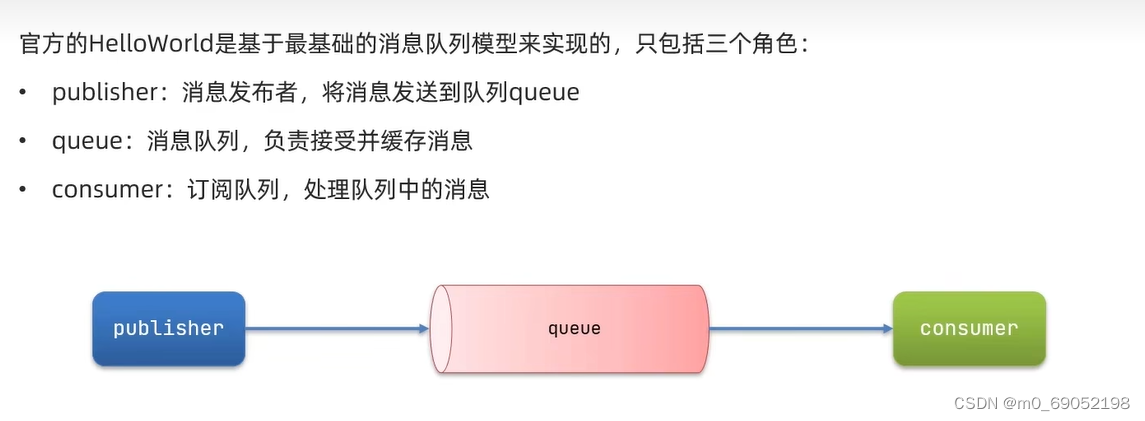
1.7.4.1 基本队列
利用SpringAMQP来实现HelloWorld的基本消息队列
流程如下:
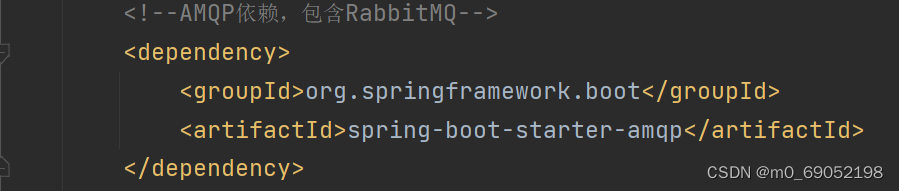
1.引入Spring-AMQP的依赖
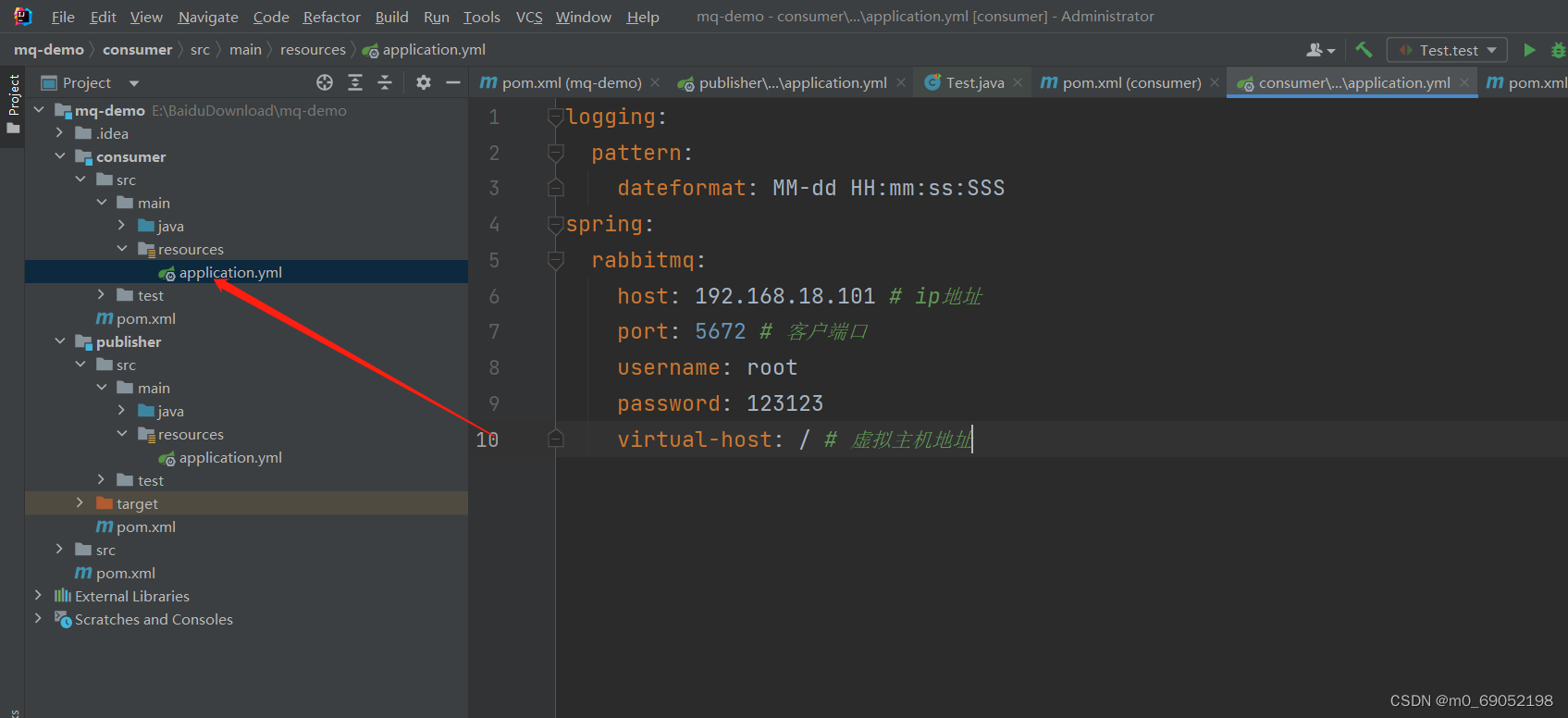
2.在publisher服务器中,完善配置文件,并利用RabbitTemplate将消息发送到队列中 、
logging:
pattern:
dateformat: MM-dd HH:mm:ss:SSS
spring:
rabbitmq:
host: 192.168.18.101 # ip地址
port: 5672 # 客户端口
username: root
password: 123123
virtual-host: / # 虚拟主机地址
package cn.itcast.mq.helloworld;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class Test {
@Autowired
private RabbitTemplate template;
@org.junit.Test
public void test(){
String queueName = "simple.queue";
String Message = "Hello,RabbitMq";
template.convertAndSend(queueName,Message);
}
}
3.在consumer服务器编写消费逻辑,首先是编写配置文件,然后新建类来绑定simple.queue这个队列并编写消费逻辑:
注意!!!Component一定要加,不然Spring扫描不到,同时,因为这是一个bean,所以SPring会自动装配,直接启动Spring就可以接收到了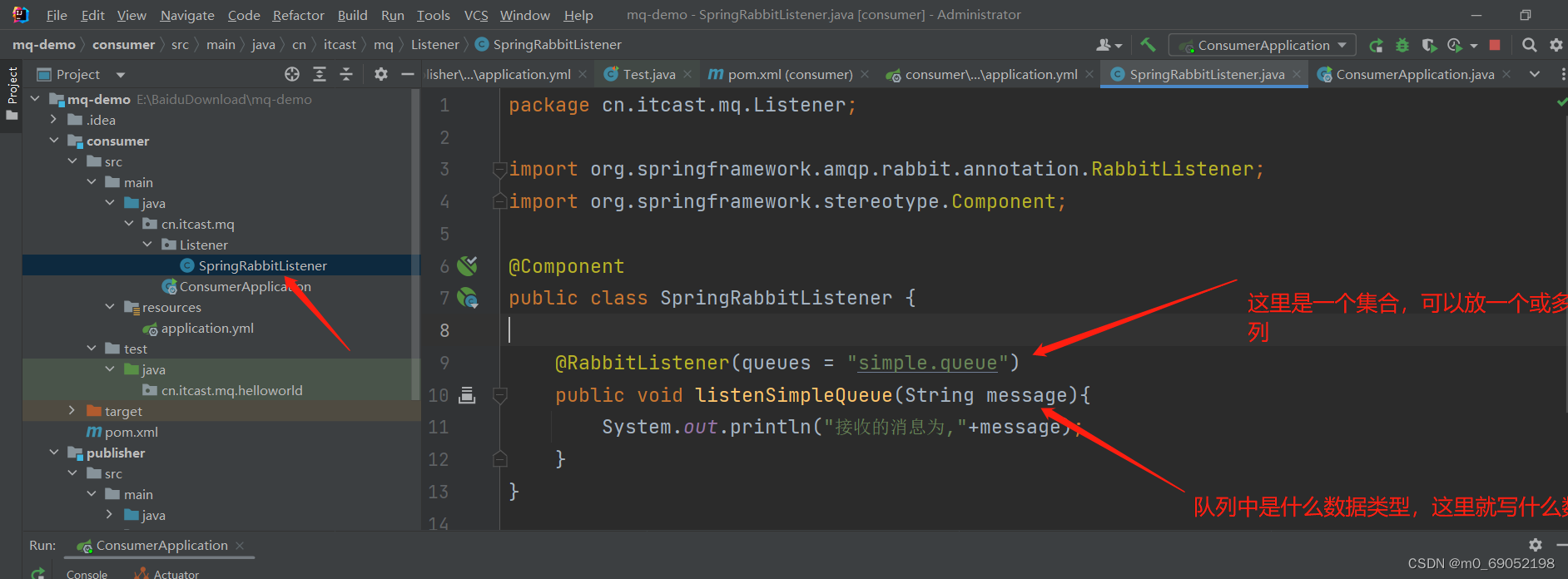
1.7.4.2 工作队列
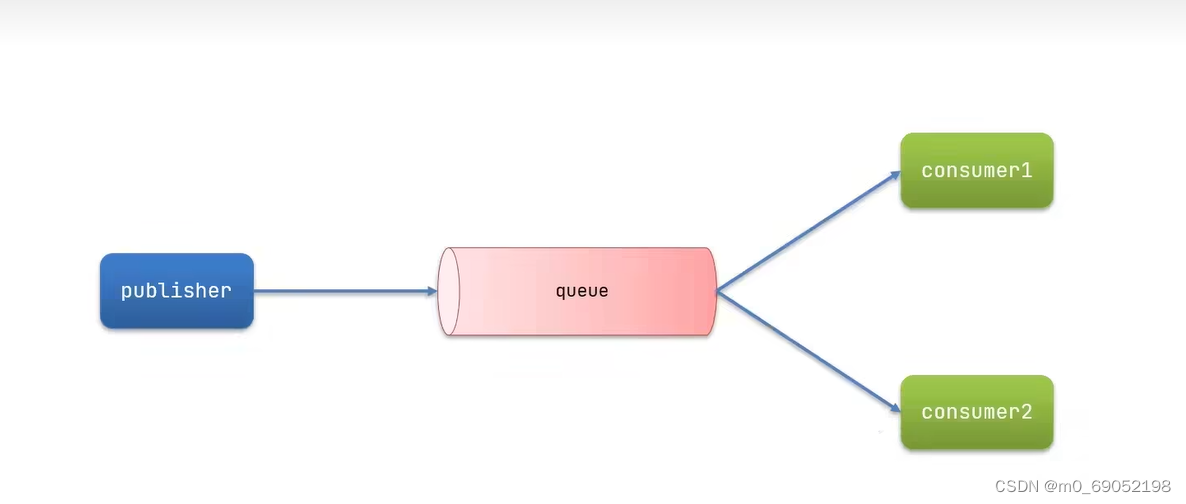
由publisher发送消息给queue,然后由两个consumer处理,代码步骤如下:
1.在publisher端随机生成50条消息给队列
@org.junit.Test
public void test() throws InterruptedException {
String queueName = "simple.queue";
for(int i = 0;i<50;i++) {
String Message = "Hello,RabbitMq"+i;
template.convertAndSend(queueName, Message);
Thread.sleep(20); //1秒生成50个
}2.设置两个监听器,同时监听一个队列,然后处理消息
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue(String message) throws InterruptedException {
System.out.println("Consumer1___接收的消息为,"+message);
Thread.sleep(20); // 1秒能处理50个
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String message) throws InterruptedException {
System.out.println("Consumer2_______接收的消息为,"+message);
Thread.sleep(200);// 1秒能处理5个
}
}这里的逻辑是一个处理的快,一个处理的慢,来模拟生产环境。
然而在运行过程中,发现,两个监听器各执行了25条消息,这和我们的设想并不一致,那为什么会这样?原因是,监听器有一个消费预取机制,原理是,先把所有消息平均分配给所有监听器,然后再一起执行,这样就导致会出现慢的情况,处理方法如下,
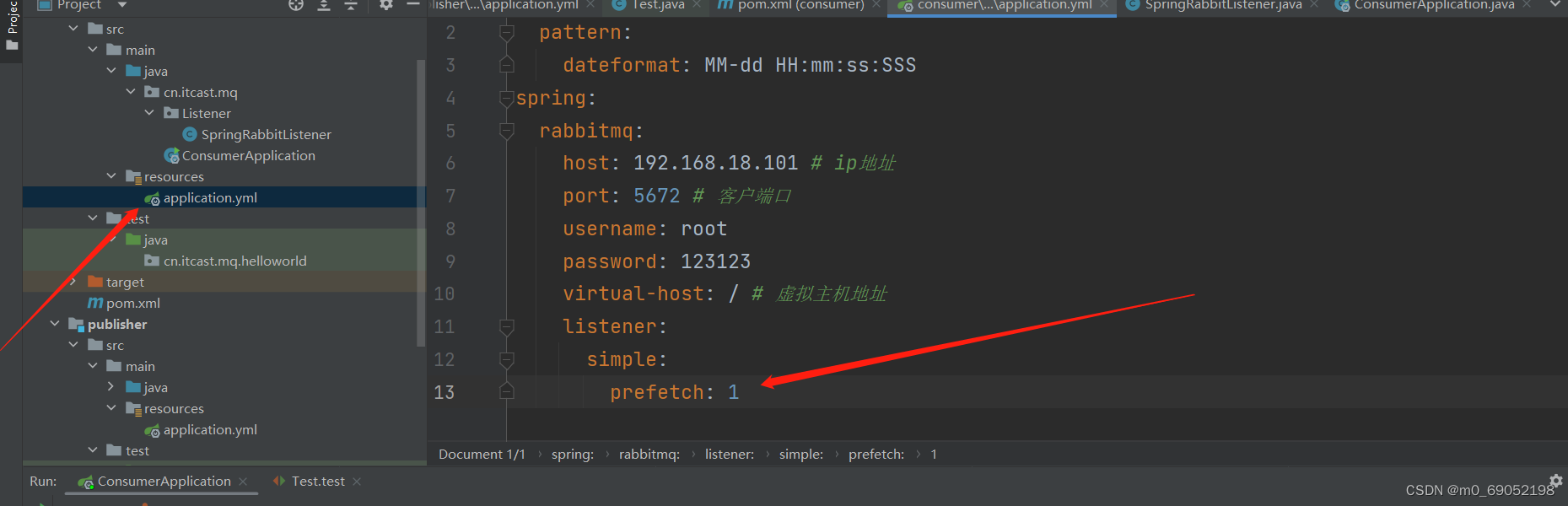
在配置文件中配置接收消息的条数,只能一条一条接收,就不会出现像之前那种情况了。
1.7.4.3 订阅与发布
上文提到的两个队列,都只有一个Consumer端口,但是在我们日常的开发环境中,通常有多个Consumer,这种情况就要加入一个exchange交换机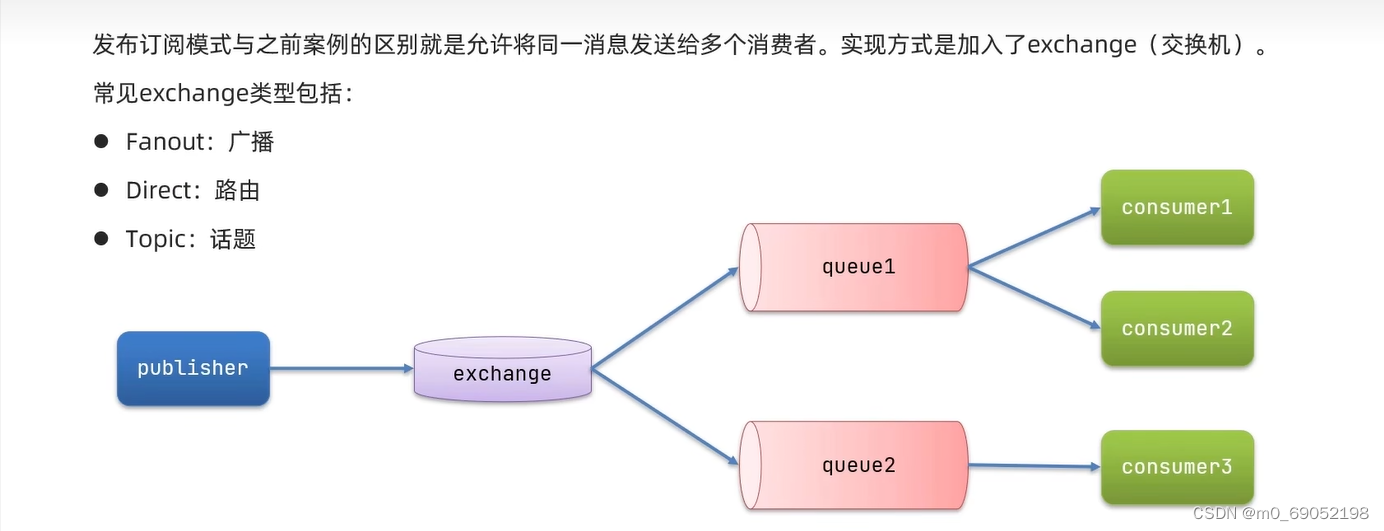
下面进行FanoutExchange的演示
FanoutExchange是一个将消息发送给每一个队列的交换机
步骤如下:
1.编写Publisher端口的配置,并向交换机发送消息
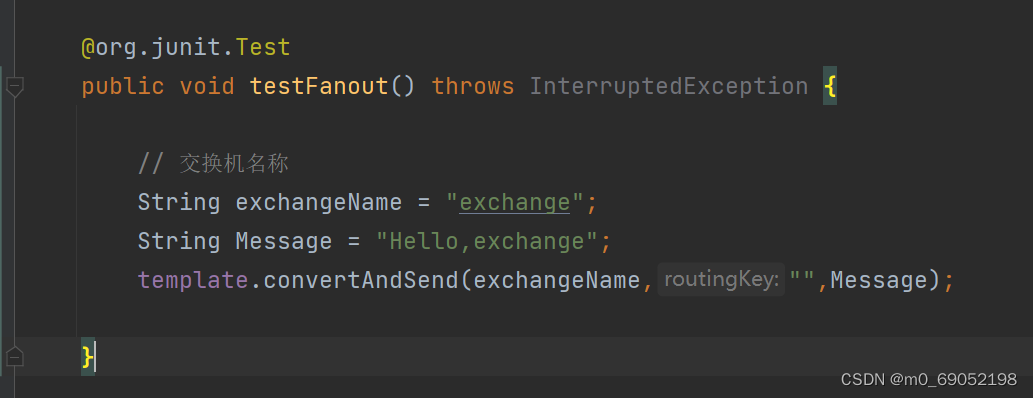
2.在Consumer端口,编写exchange,以及与exchange绑定的queue(这一块是使用Bean注解来进行开发)
package cn.itcast.mq.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfig {
// 新建一个fanout交换机
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("exchage");
}
// 新建一个队列
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.Queue1");
}
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.Queue2");
}
// 绑定交换机和队列1
@Bean
public Binding fanoutBanding1(Queue fanoutQueue1,FanoutExchange fanoutExchange){
return BindingBuilder
.bind(fanoutQueue1)
.to(fanoutExchange);
}
@Bean
public Binding fanoutBanding2(Queue fanoutQueue2,FanoutExchange fanoutExchange){
return BindingBuilder
.bind(fanoutQueue2)
.to(fanoutExchange);
}
}
3.在Consumer层编写监听器的代码,对队列进行监听
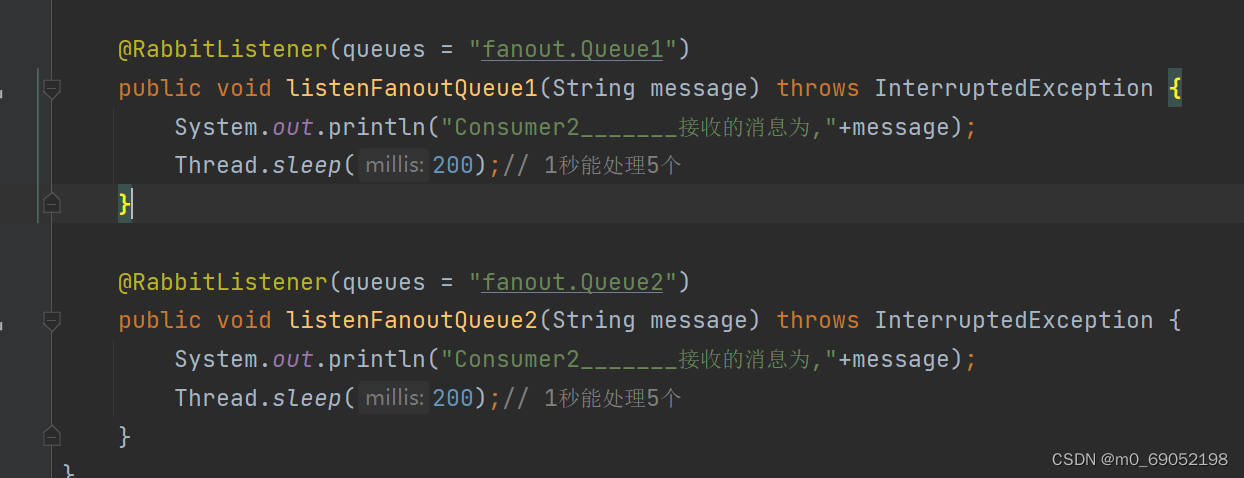
下面是DirectExchange的演示
DirectExchange的作用是,将信息根据队列的ID发送给每一个指定的队列
代码如下:
1.在Consumer层编写队列,交换机,以及监听器(这次使用到的是@RabbitListener),很关键!
代码如下,
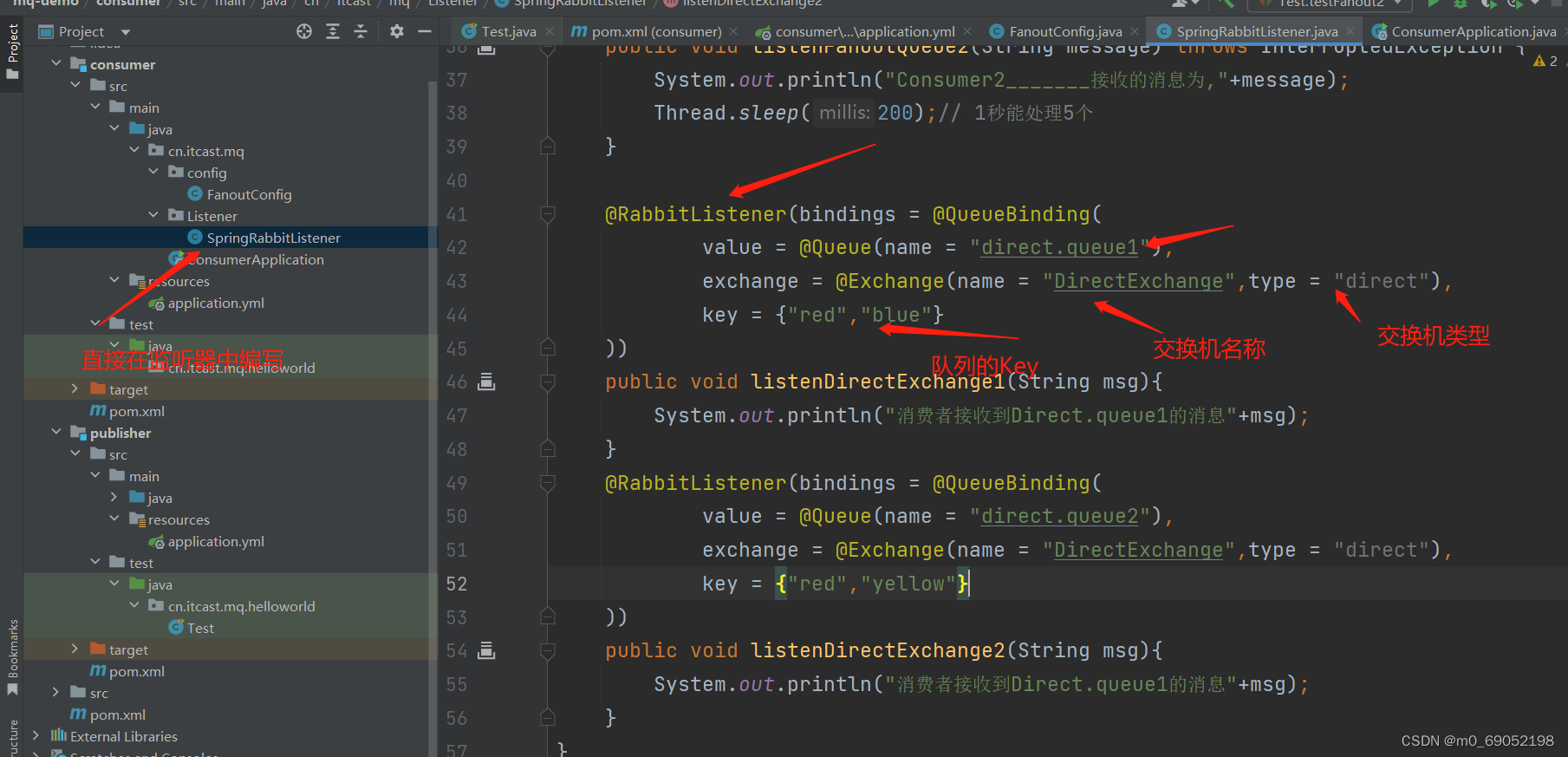
通过key来指定哪个队列来接收消息
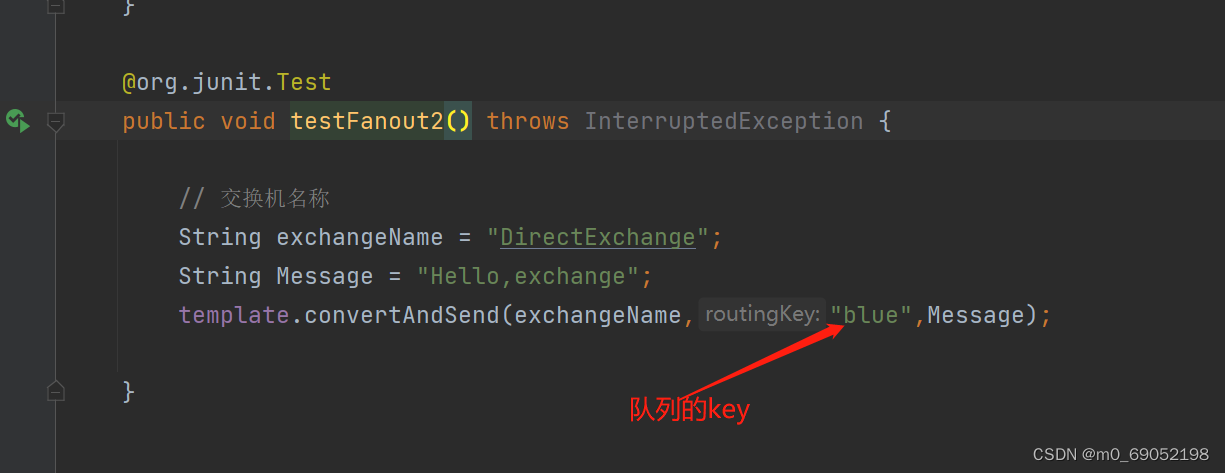
2.在publisher中编写发送消息的代码
代码如下:
最后一个是TopicExchange交换机
TopicExchange的特征与DirectExchange很像,都是像特定的Queue中发送消息,不同的是,TopicExchange的key设置的比较特殊,是用.来分割,
代码如下:
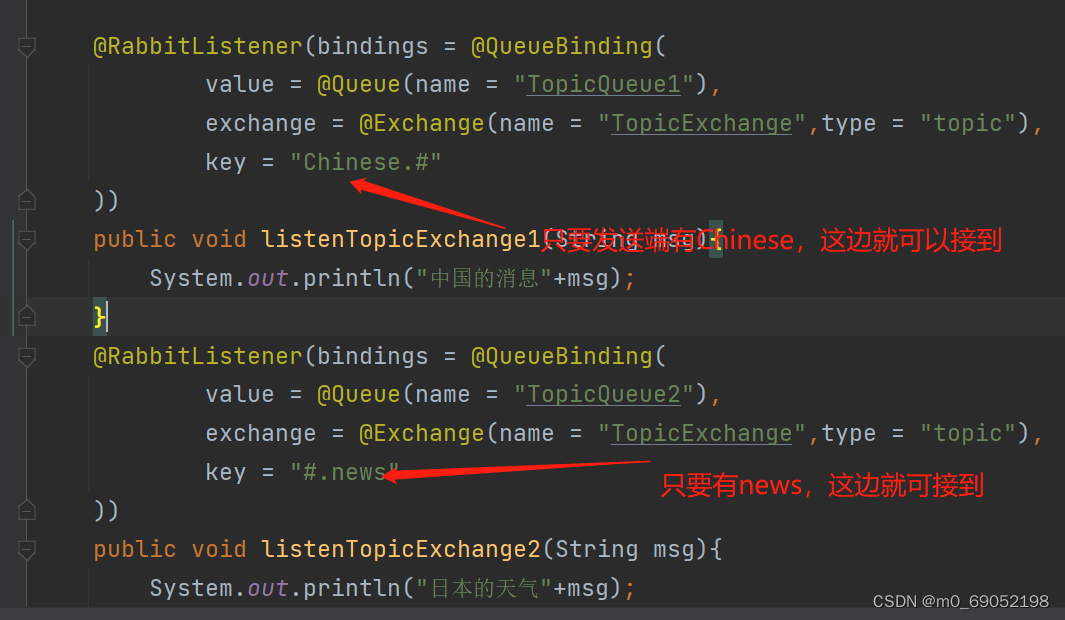
发送端的代码 如下
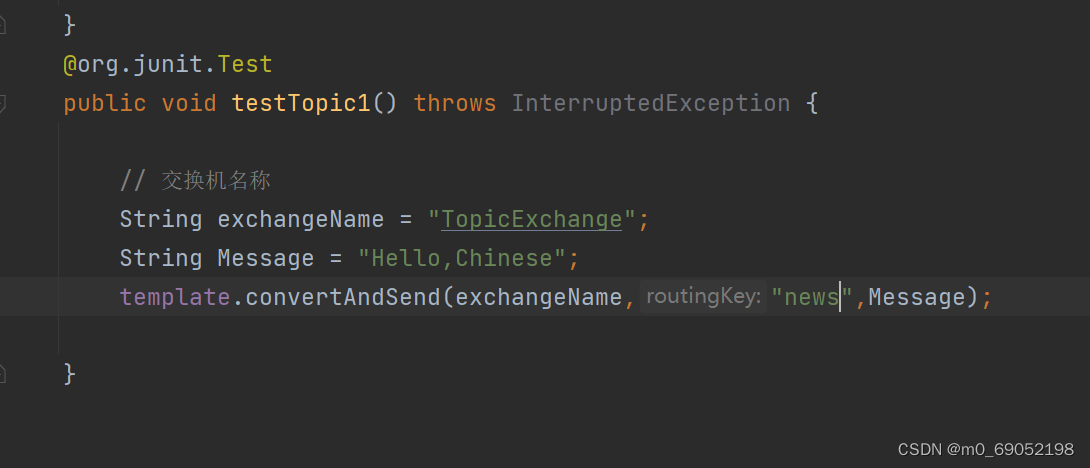
1.7.4.4 消息转化器
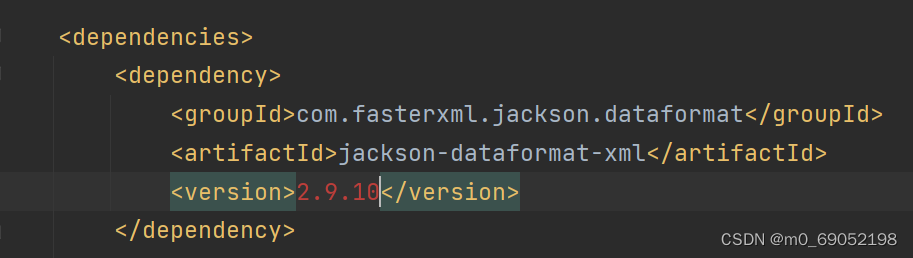
上文中,发送的消息都是String类型,但是其实发送的消息是Object类型,所以可以发任何对象给队列。同时,需要注意的是,发送对象时,Spring将Obejct序列化成一个字符串,这种序列化的方式,效率较低,而且发送的字符可读性差,
所以我们可以设置其他序列化器,Json序列化 方法如下,
1.在父工程中,引入pom坐标
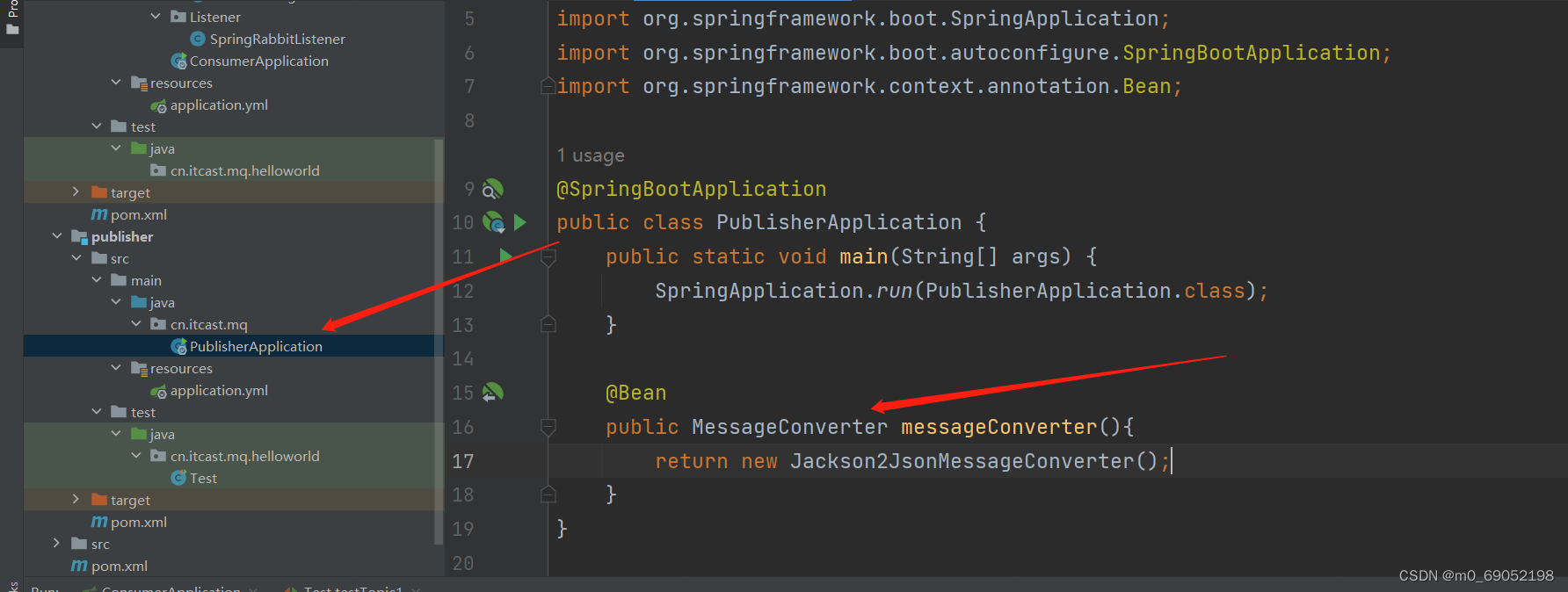
2.在publisher服务声明消息转化器
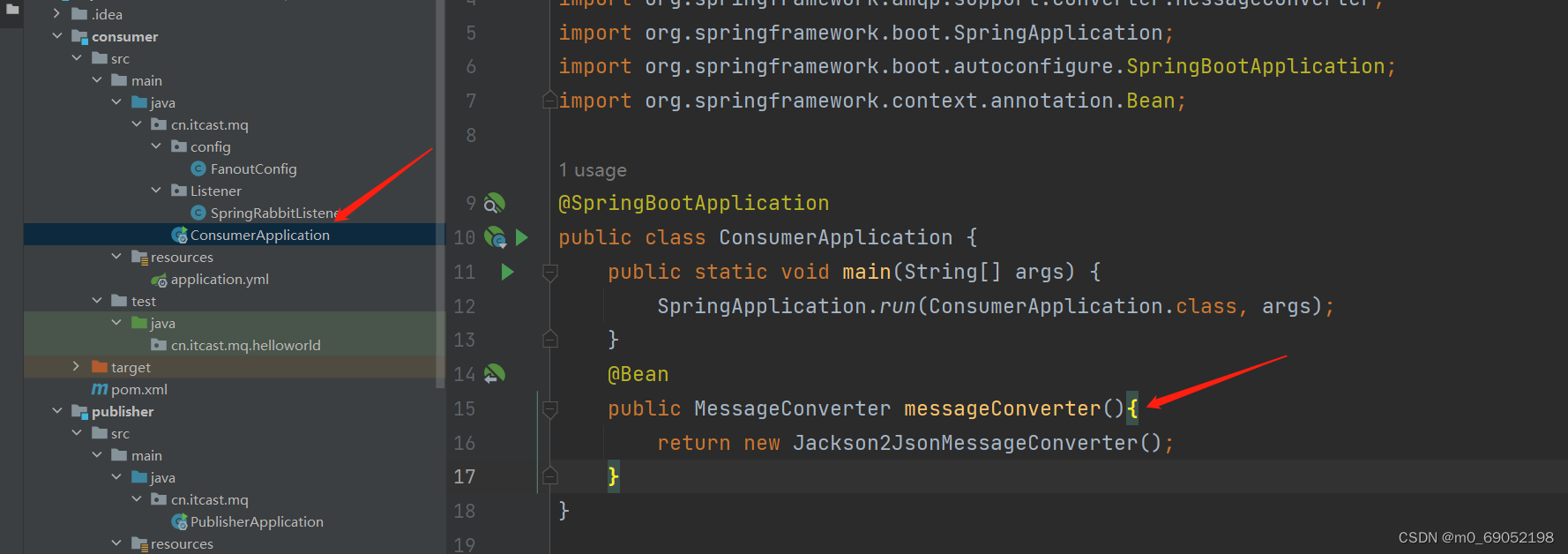
3.在Consumer中设置消息转化器
1.8 分布式搜索(elasticsearch)
1.8.1 Es的基本概念
elasticsearch是一种非常强大的开源搜索引擎,也就是从海量的数据快速查找需要的内容。、
elastic stack(ELK)也就是es的技术栈
1.8.1.1 ES的存储和Mysql的存储方式的区别:
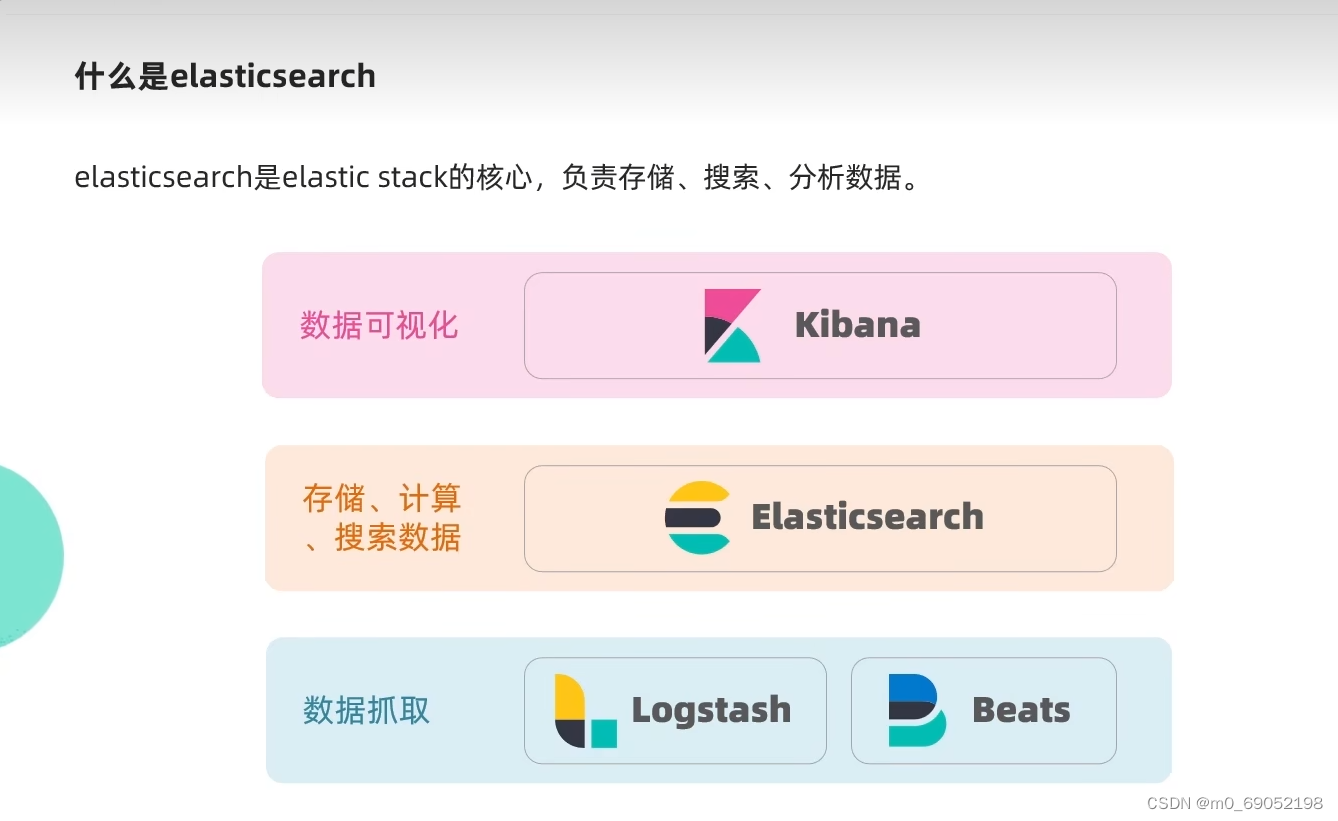
Mysql是正向索引,而Es是使用倒排索引,如图
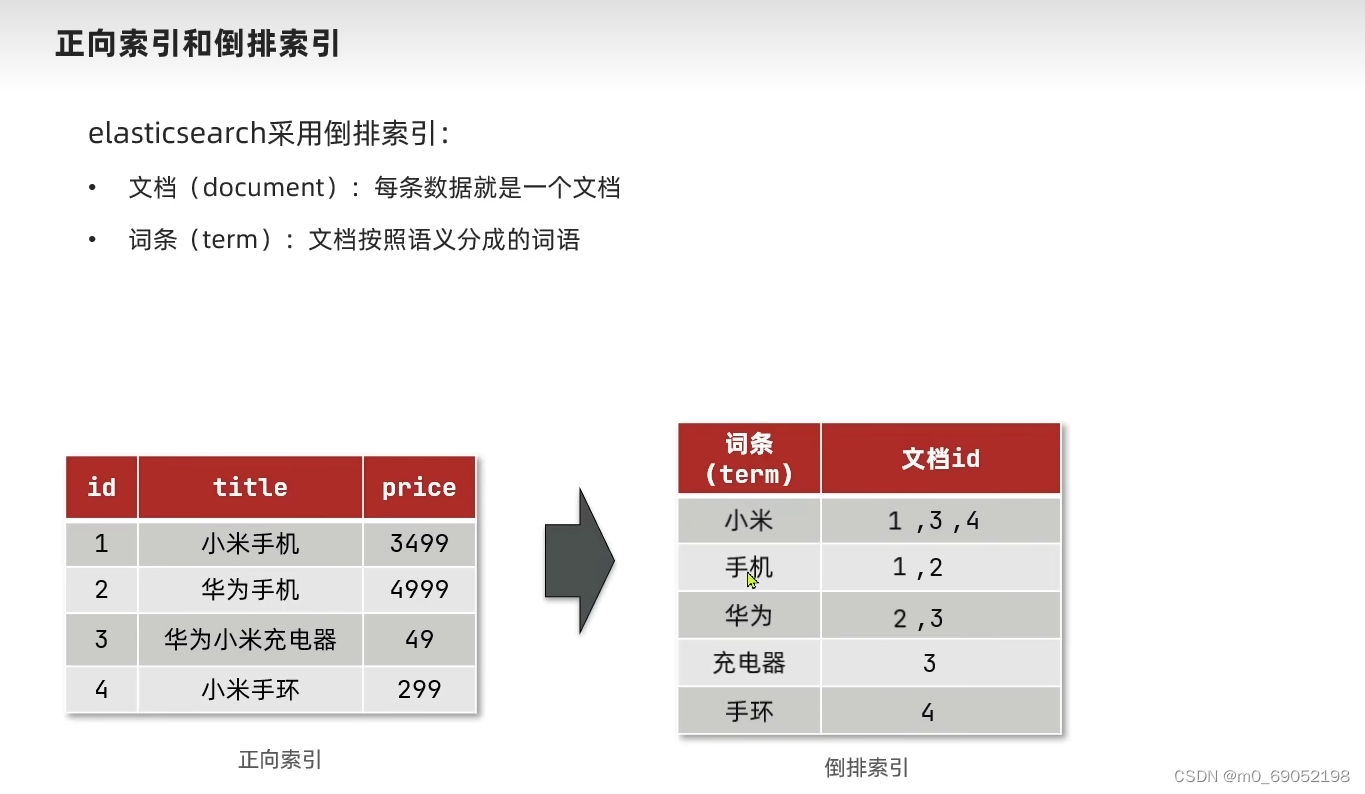
Mysql通常是使用ID的方式来进行查询,而Es会将每一个输出进入的文档(举个例子,就是id = 1,title = 小米手机,price = 3499,这就是一个文档,也就是一条数据),会将文档根据语义分割,分成词语,然后存储到数据库中。
查询的步骤如下:
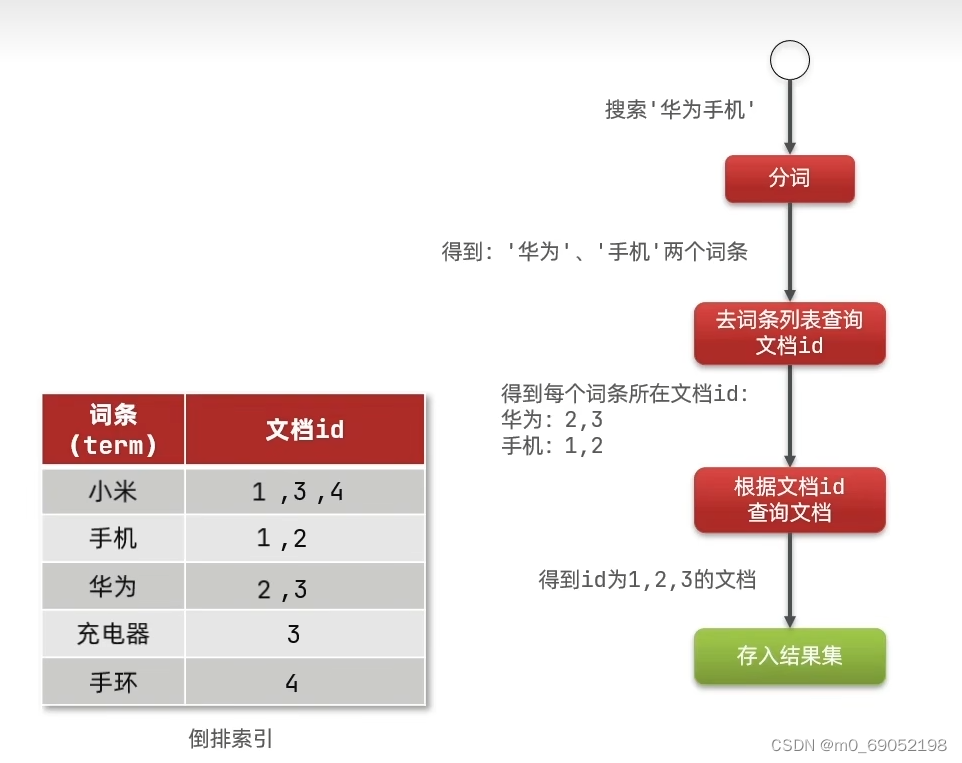
1.8.1.2 Mysql与Es数据库的概念的区别
如图:
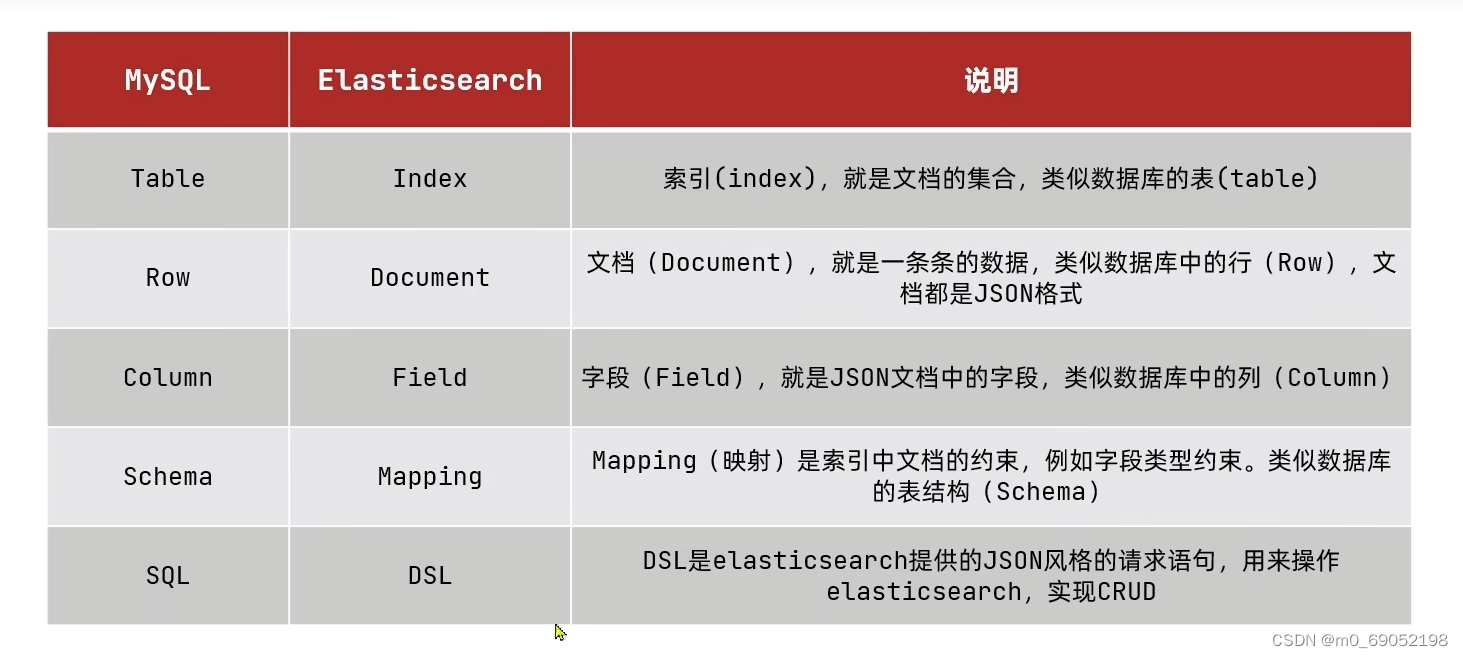
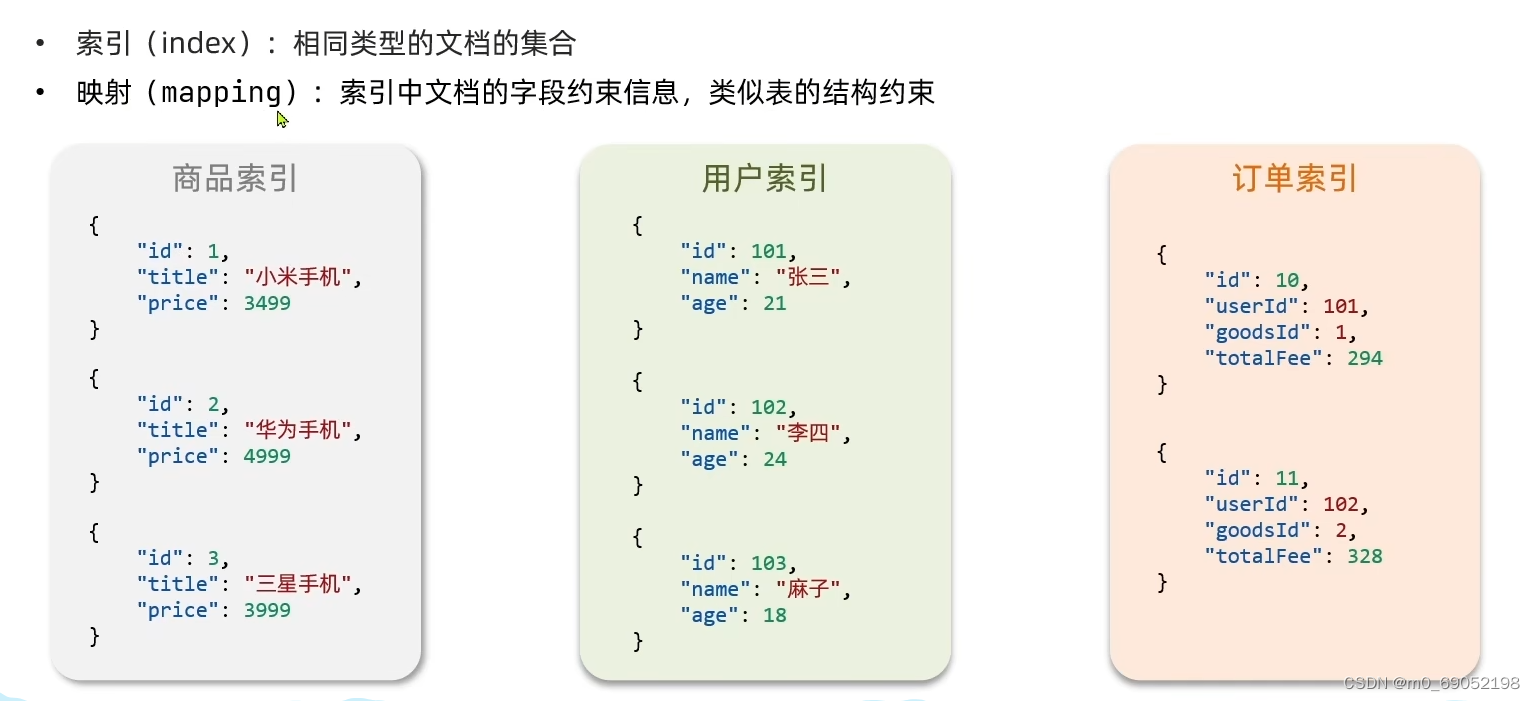
索引就是Mysql中的表的概念,文档就是一条数据,field相当于是一列存储的数据,Mapping是约束,相当于是数据类型等。DSL就是Es的操作数据库的语言
同时,Es存储数据时,数据的格式为JSON格式,然后根据各种JSON数据的格式,再将一样格式的分给同一个Index也就是索引,如图
安装,运行Es与Kibana
这个没啥难度,记录一下运行Es的命令
docker run -d --name MyEs -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -v es-data:/usr/share/elasticsearch/data -v es-plugins:/usr/share/elasticsearch/plugins --privileged --network es-net -p 9200:9200 -p 9300:9300 elasticsearch:7.12.1
Kibana就是Es的一个可视化界面
![]()
这块要写Es的容器名
-e 后面的是es的端口号, --network 是网络空间,必须与es的保持一致
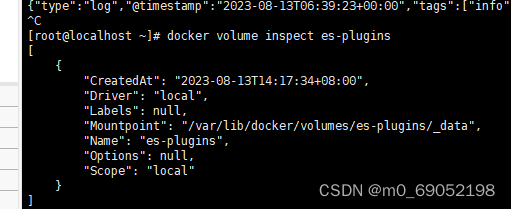
同时,注意这里需要下载一个分词器,因为中文不支持分词,所以需要从Github上pull下来,并安装到Es中,步骤如下
1.下载的插件需要放到Es的plugins文件夹下,我们上一步添加了数据挂载,需要找到对应的文件夹就可以了
2.下载压缩包,解压并放到该文件夹下,重启该容器即可
配置IK分词器
可以在IK的配置文件中,添加对应的新增字典和禁用字典
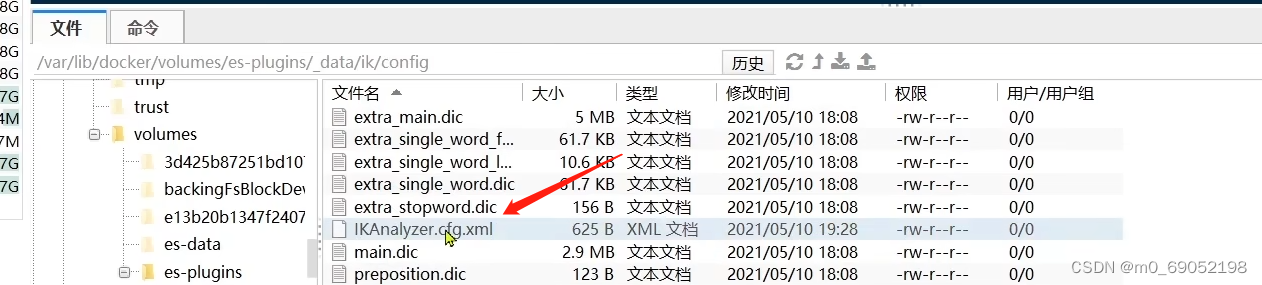
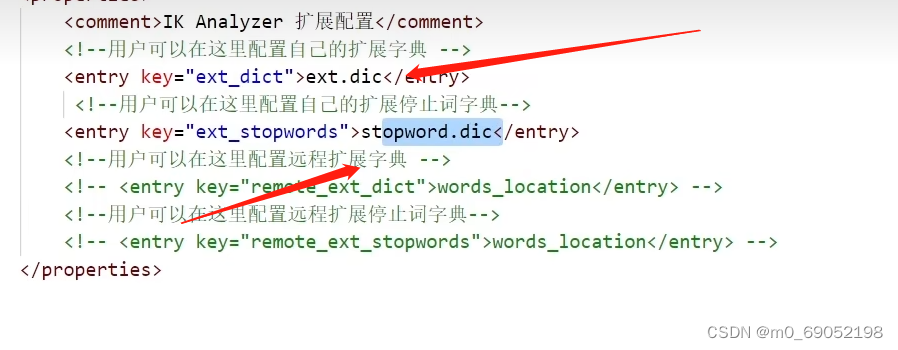
并在该文件夹中找到对应的文件,然后进行编辑添加即可。
1.8.2 Es的基本操作
1.8.2.1 索引库操作
也就是Mysql中的表,先介绍一下索引表中的数据类型,又称为Mapping

创建索引库的操作如下

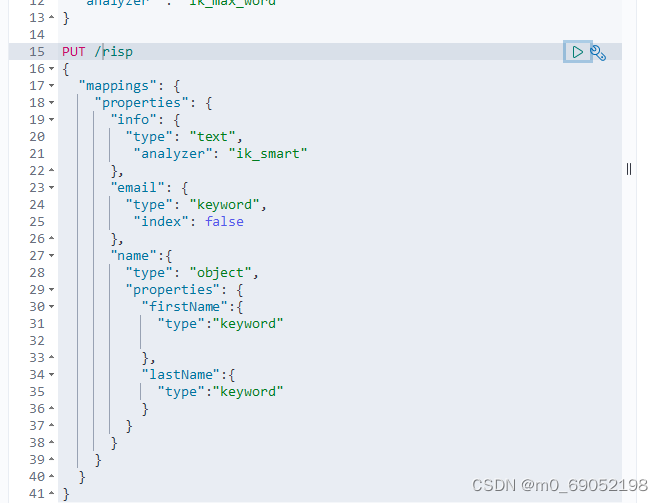
删除索引库是,delete /索引库名
查看索引库是,GET /索引库名
注意!!!索引库不可以修改旧的属性,但是可以添加新字段

1.8.2.2 文档操作
新增文档的语法如下:
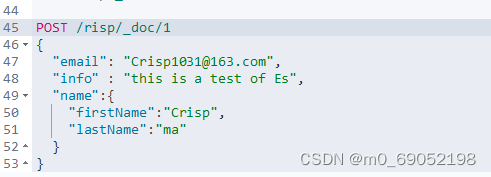
查询与删除文档的语法如下:
GET /risp/_doc/1
DELETE /risp/_doc/1
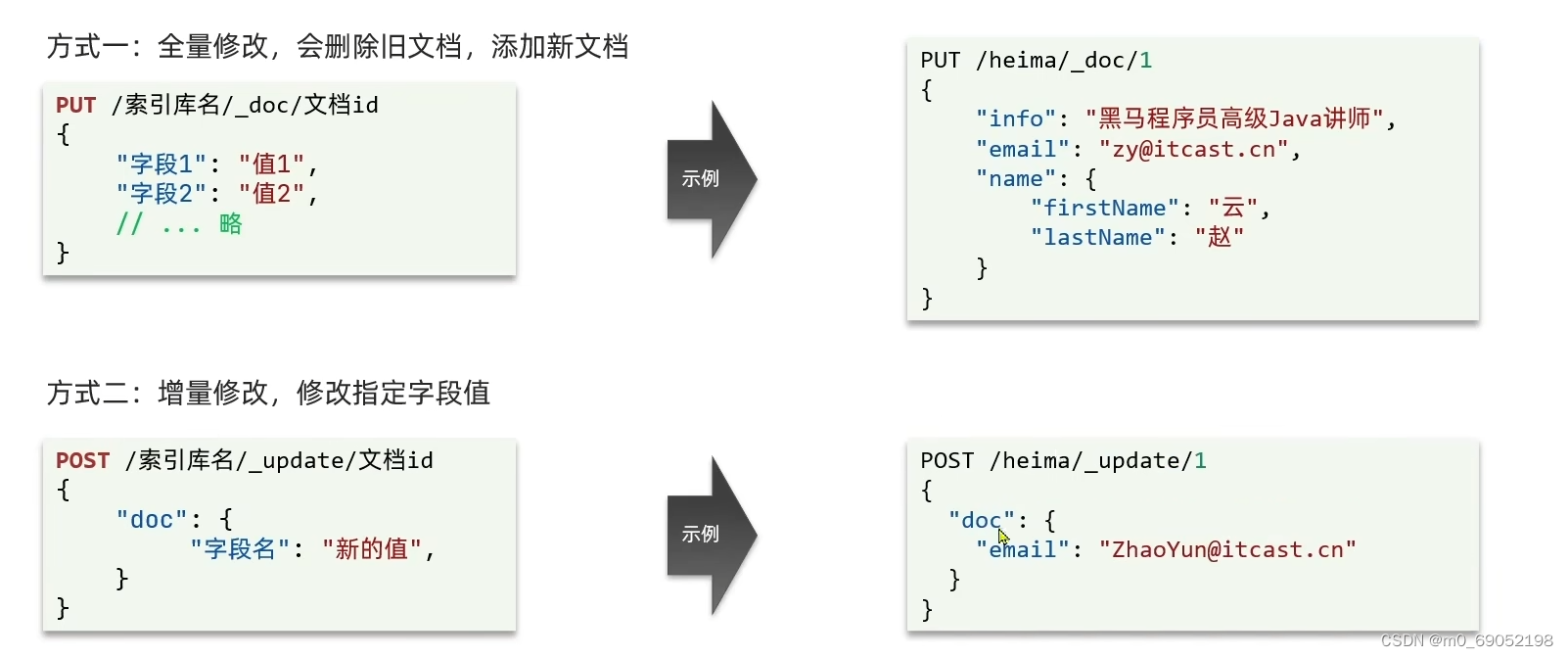
修改文档的语法
方式1既可以修改,也可以是新增,当旧文档不存在时,他会直接新增
1.8.2.3 使用JavaRestClient操作Es
在上文中,我们根据的是Es的图形化界面,Kibana来完成对Es的操作,但是在实际开发中,我们通常使用的是Es提供给我们的Java的Es接口来完成
案例如下:
首先是根据Mysql数据表,创建Es的索引表,如下
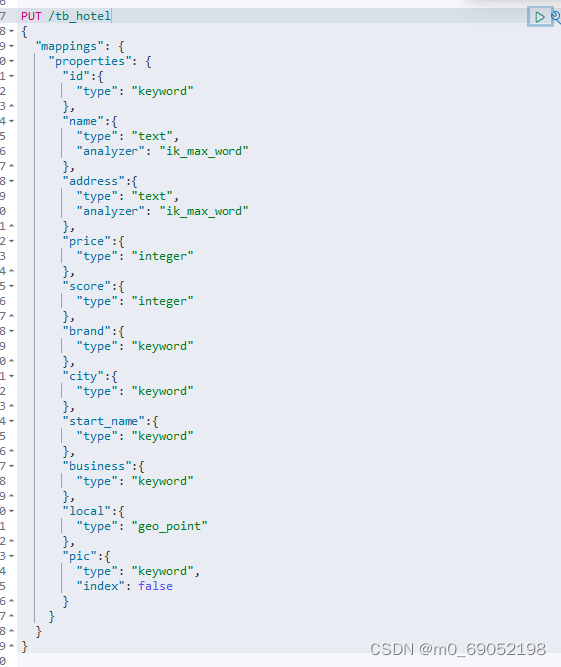
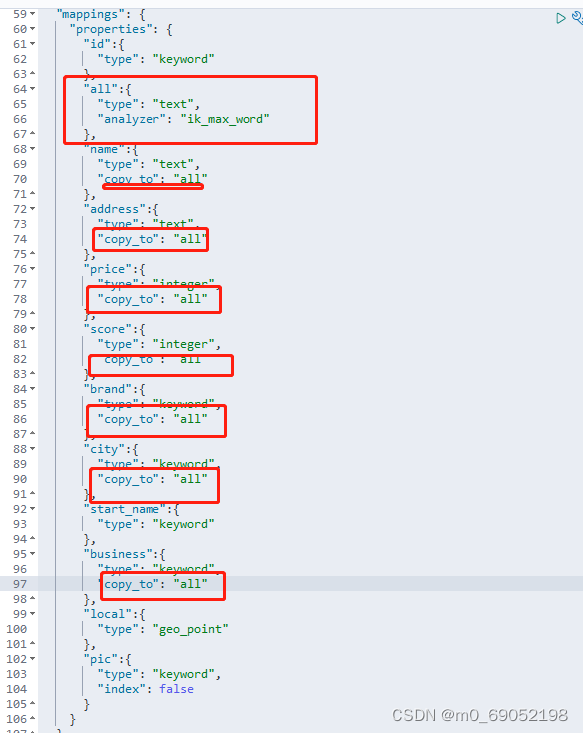
但是,这里牵扯到一个问题,如果用户根据多个字段查询,那该怎么办?这里就用到Es的一个新的操作 ,Copy_to,使用方法如下:创建一个公共字段,将要查询的所有条件都放到这个公共字段,然后根据这个公共字段查询

修改上述代码
现在开始在java中对Es进行操作:
1.导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
注意!!!这里出现了一个问题,因为我用的是Es,7.12.1的版本,但是SpringBoot会对依赖进行自动管理,所以,这里会有7.6.2的版本,这里就需要我们对版本进行设置了

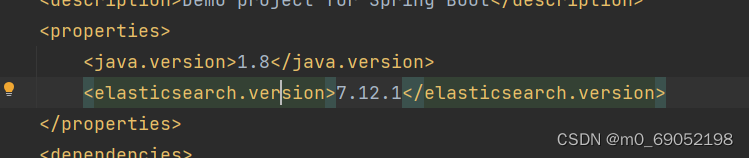
2. 创建RestHighLevelClient对象
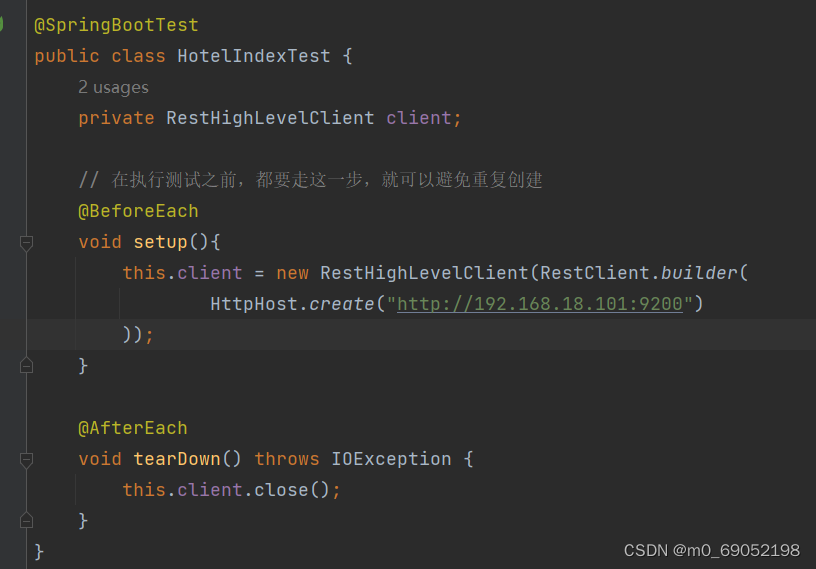
这两个方法是因为在测试中,各个方法都是独立的,所以写,实际开发过程中,可以直接在全局变量中定义。
2.1 使用RestClient创建索引库
结构如下:

代码如下:
@Test
void CreateHotelIndex() throws IOException {
//1 创建request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
//2 准备请求参数,DSL语句,这里的DSL语句,就是上一步创建索引表时的语句
request.source(dsl, XContentType.JSON);
//3 发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}第二步中的,JSON,是指索引库
DSL语句如下
package cn.itcast.hotel.properties;
public class DSL {
public static final String dsl = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"text\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"start_name\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"local\":{\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
这里出了一个问题,问题显示添加索引表失败,错误信息如下,
ElasticsearchStatusException[Elasticsearch exception [type=mapper_parsing_exception, reason=Failed to parse mapping [properties]: Root mapping definition has unsupported parameters: [all : {analyzer=ik_max_word, type=text}] [start_name : {type=keyword}] [score : {copy_to=all, type=integer}] [address : {copy_to=all, type=text}] [business : {copy_to=all, type=keyword}] [city : {copy_to=all, type=keyword}] [price : {copy_to=all, type=integer}] [name : {copy_to=all, type=text}] [id : {type=keyword}] [pic : {index=false, type=keyword}] [brand : {copy_to=all, type=keyword}] [local : {type=geo_point}]]
]; nested: ElasticsearchException[Elasticsearch exception [type=mapper_parsing_exception, reason=Root mapping definition has unsupported parameters: [all : {analyzer=ik_max_word, type=text}] [start_name : {type=keyword}] [score : {copy_to=all, type=integer}] [address : {copy_to=all, type=text}] [business : {copy_to=all, type=keyword}] [city : {copy_to=all, type=keyword}] [price : {copy_to=all, type=integer}] [name : {copy_to=all, type=text}] [id : {type=keyword}] [pic : {index=false, type=keyword}] [brand : {copy_to=all, type=keyword}] [local : {type=geo_point}]]];
查找相关帖子,发现是包导错了,导致create函数已过期。
删除操作如下
@Test
void DeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request,RequestOptions.DEFAULT);
}使用RestClient操作文档
新增操作如下:

代码如下:
@Test
void testAddDocument() throws IOException {
Hotel hotel = service.getById(61083L);
HotelDoc hotelDoc = new HotelDoc(hotel);
//1. 创建request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
//2 准备JSON文件
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//3 发送给Client
client.index(request, RequestOptions.DEFAULT);
}
这里使用到的HotelDoc的用处,主要是因为Hotel的属性与索引表中的属性不一致,所以需要用HotelDoc来做一个转化
查询操作如下:
@Test
void testSelectDocument() throws IOException {
//1. 创建request对象
GetRequest request = new GetRequest("hotel","36934");
//2 发送给Client
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
//3 返回结果
String sourceAsString = documentFields.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
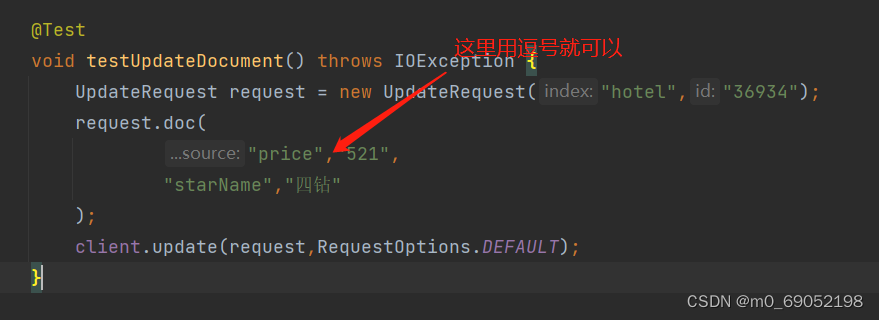
}更新操作如下:
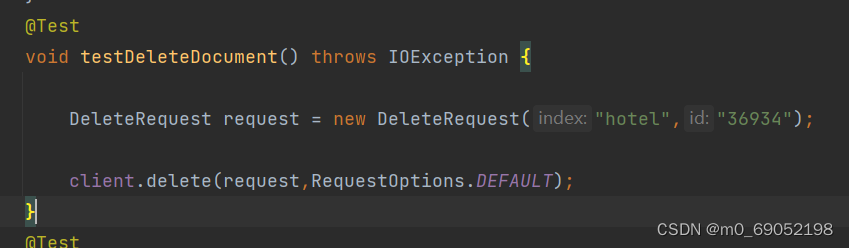
删除操作如下:
批量操作如下:
@Test
void testSelectDocuments() throws IOException {
//批量导入
List<HotelDoc> list = service.list().stream().map(item->{
HotelDoc hotelDoc = new HotelDoc(item);
return hotelDoc;
}).collect(Collectors.toList());
BulkRequest request = new BulkRequest();
for (HotelDoc doc:list) {
request.add(new IndexRequest("hotel").id(doc.getId().toString()).source(JSON.toJSONString(doc),XContentType.JSON));
}
client.bulk(request,RequestOptions.DEFAULT);
}这里用的是bulkRequest
1.8.3 DSL查询文档

格式如下:
1.8.3.1 检索关键字查询:
可以从数据中的关键字进行模糊查询


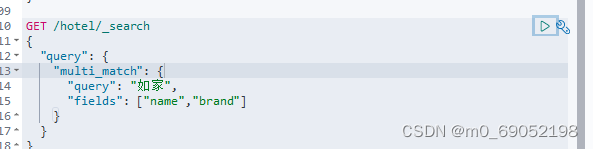
这两个效果一样,所以尽量使用上面的
1.8.3.2 精确查询
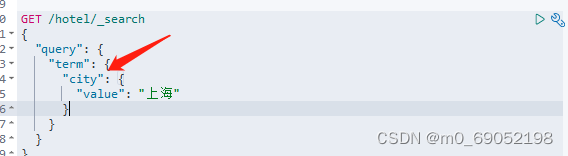
通过是查找keyword,精准查找
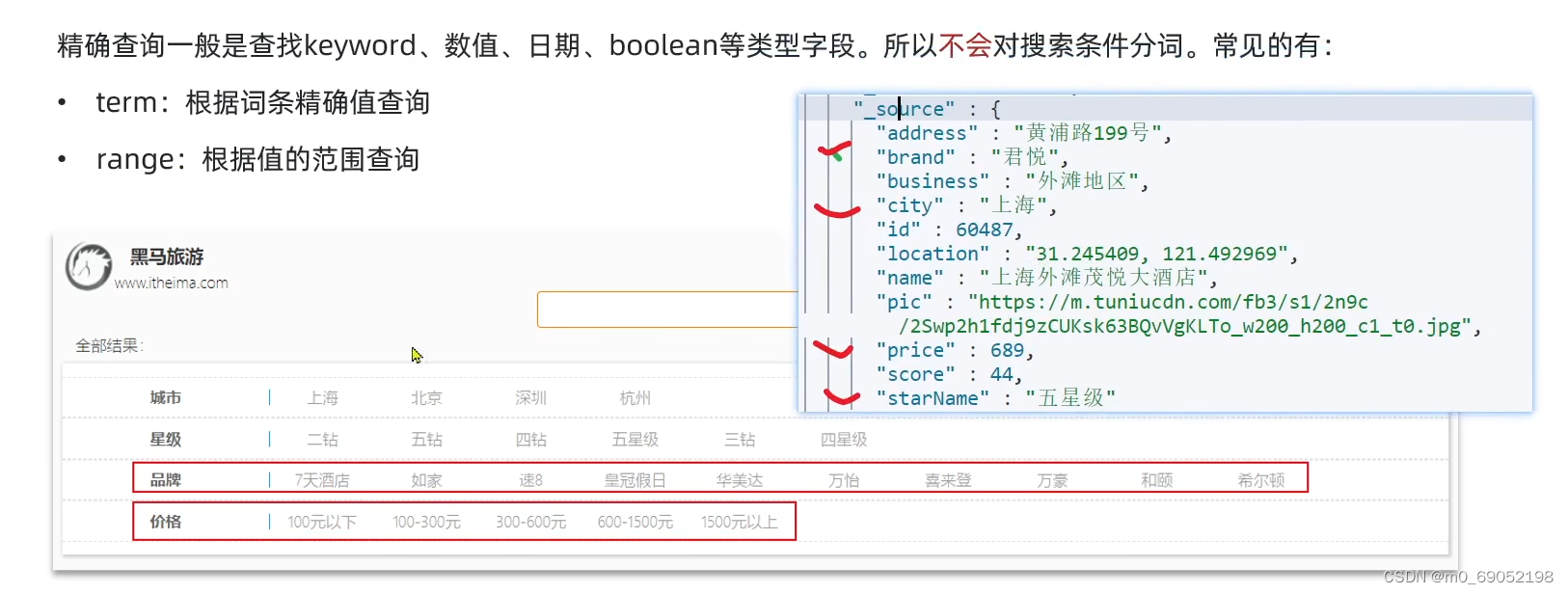
格式如下
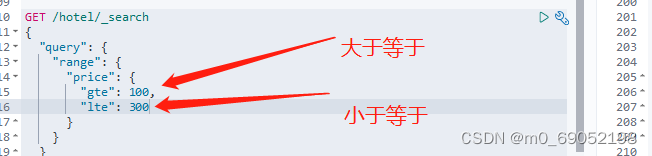
1.8.3.3 地理位置查询
第一种如图,是给一个区域,然后查询这个区域中的信息
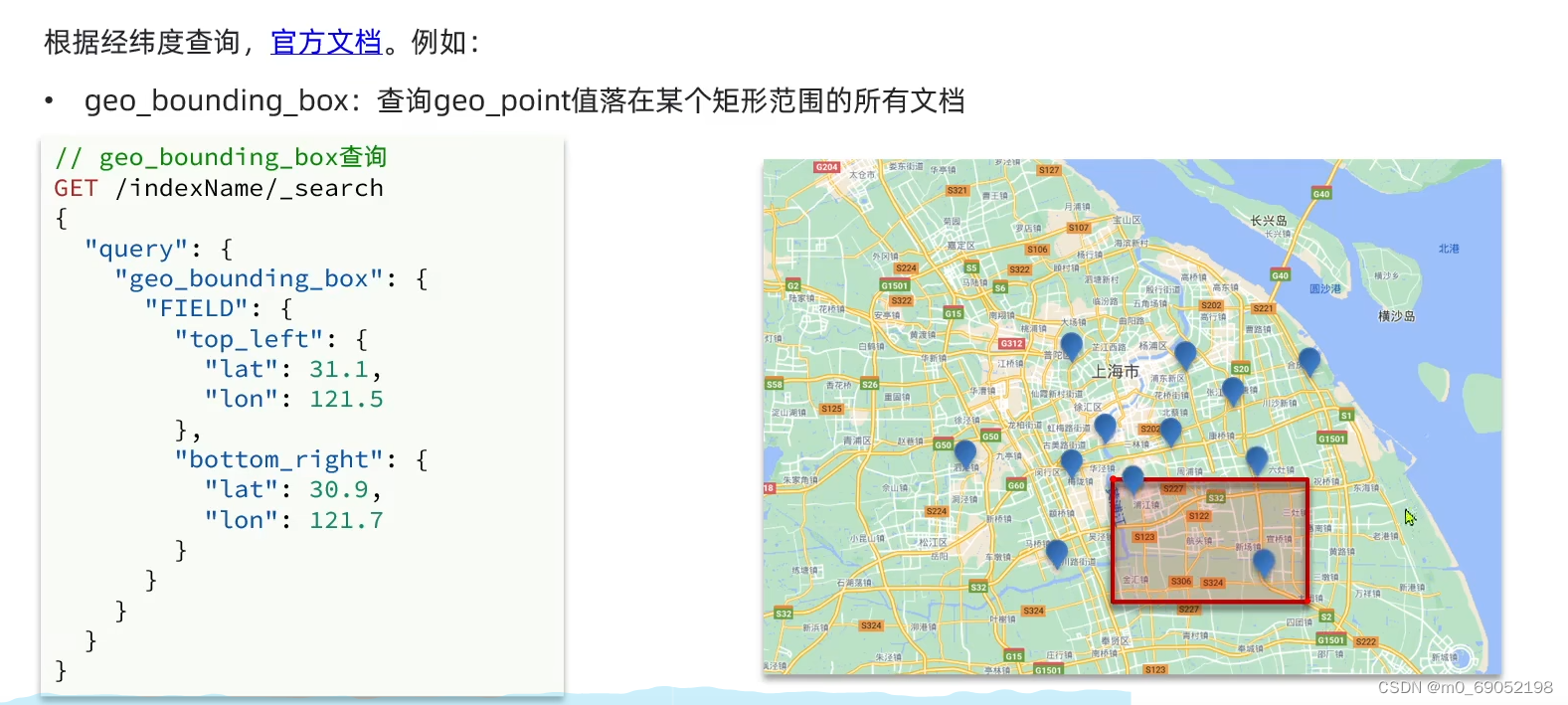
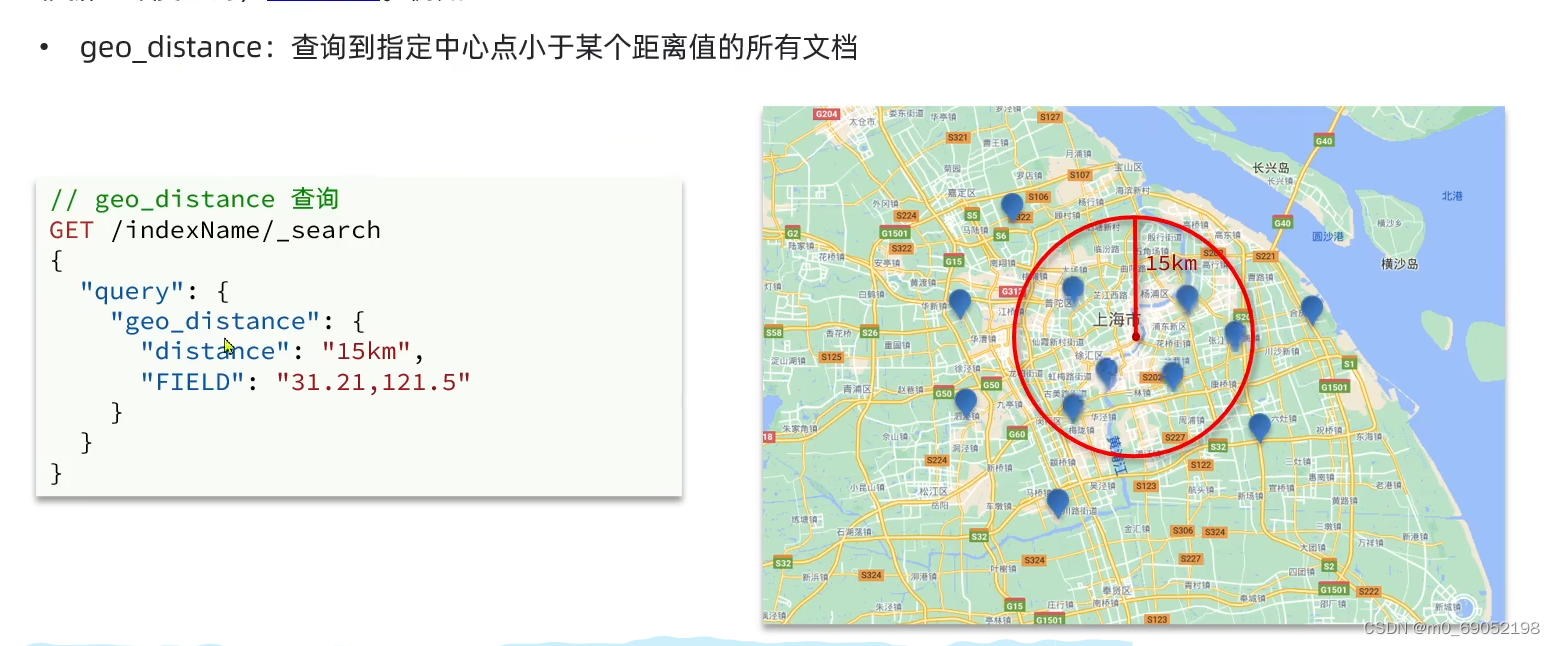
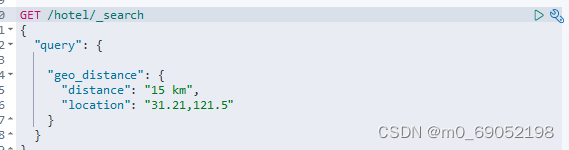
第二种如图,是查询自己身边的所有的点
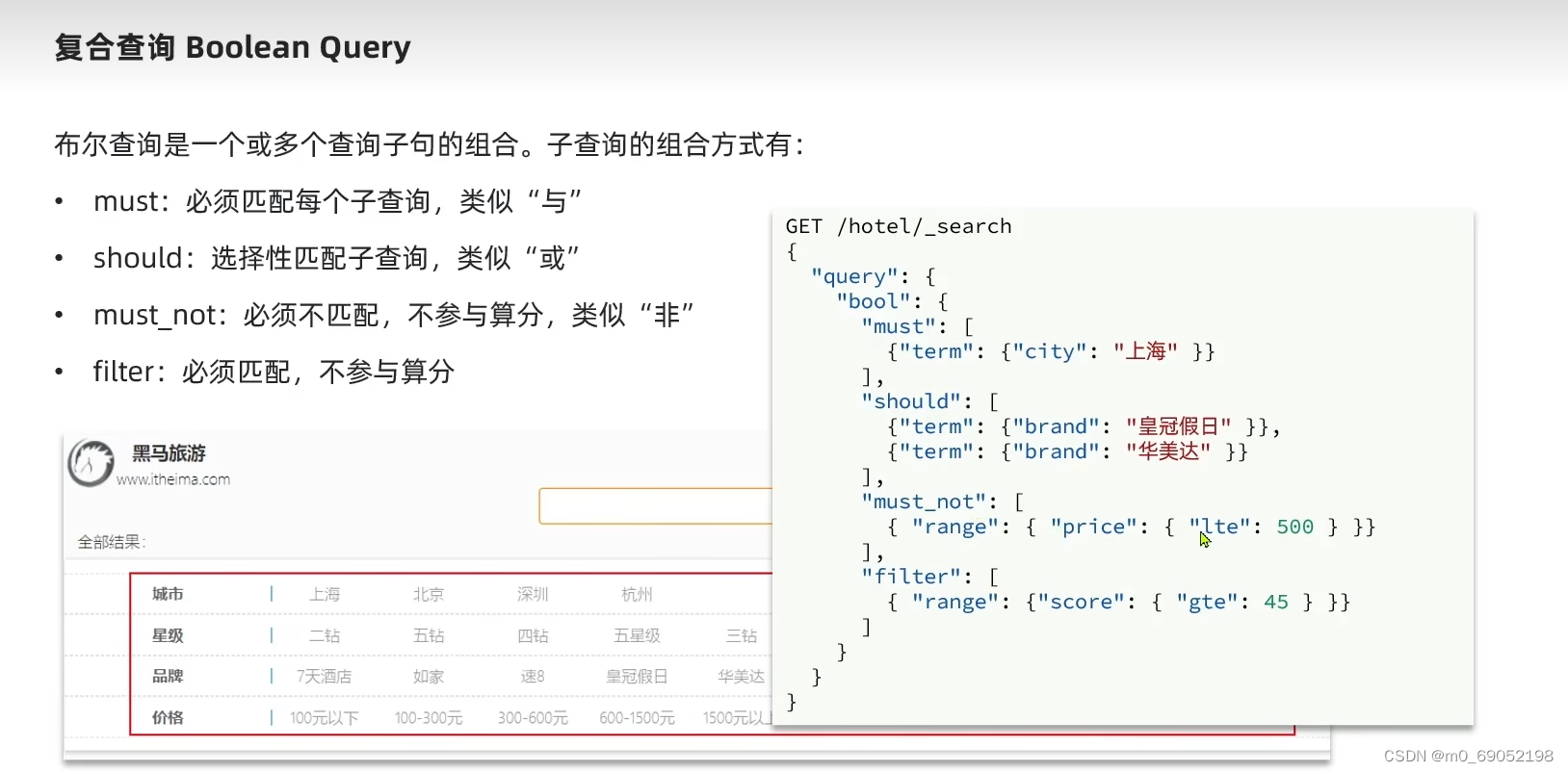
1.8.3.4 复合查询

1.8.3.5 搜索结果处理
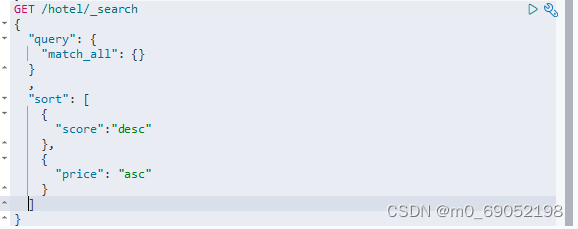
1. 排序

根据酒店的评分降序,如果相同根据价格升序
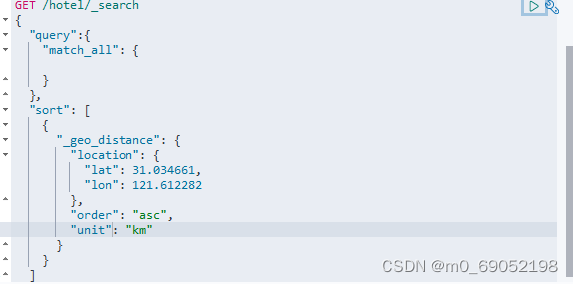
根据自身位置查询排序
2. 分页处理

代码如下

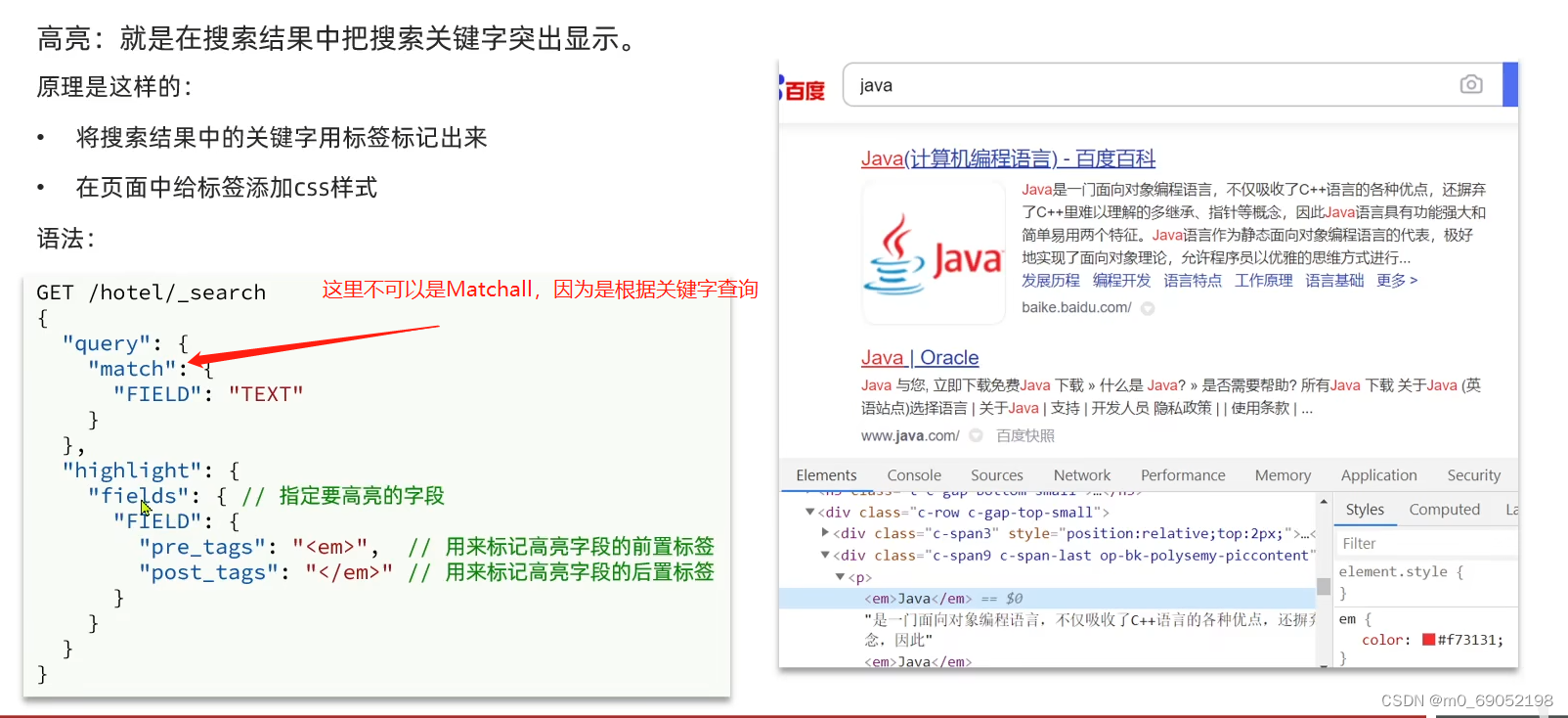
高亮显示:
1.8.4 使用RestClient查询文档
MatchALL代码如下:
@Test
void testSelectDocument() throws IOException {
//1 new一个reuqest对象
SearchRequest request = new SearchRequest("hotel");
//2 用request对象创建查询语句
request.source()
.query(QueryBuilders.matchAllQuery());
//3 用client处理request方法,最后得到返回结果
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//4 根据Kibana可知,数据都在hits中,所以处理数据的操作如下
for (SearchHit hit : search.getHits()) {
String sourceAsString = hit.getSourceAsString();
HotelDoc doc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(doc);
}
}Match代码如下:
@Test
void TestMatchDocument() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().
query(QueryBuilders.matchQuery("all","如家"));
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
System.out.println(hit);
}
}条件查询代码如下:
条件查询的首要就是创建BoolQueryBuilder
@Test
void TestQueryDocument() throws IOException {
SearchRequest request = new SearchRequest("hotel");
// 不一样的地方在于这里,需要加一个boolQuery
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
// 然后再选择是特征查询还是,区间查询等
boolQueryBuilder.must(QueryBuilders.termQuery("city","北京"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lte(200));
request.source().query(boolQueryBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
System.out.println(hit);
}
}分页查询代码如下:
@Test
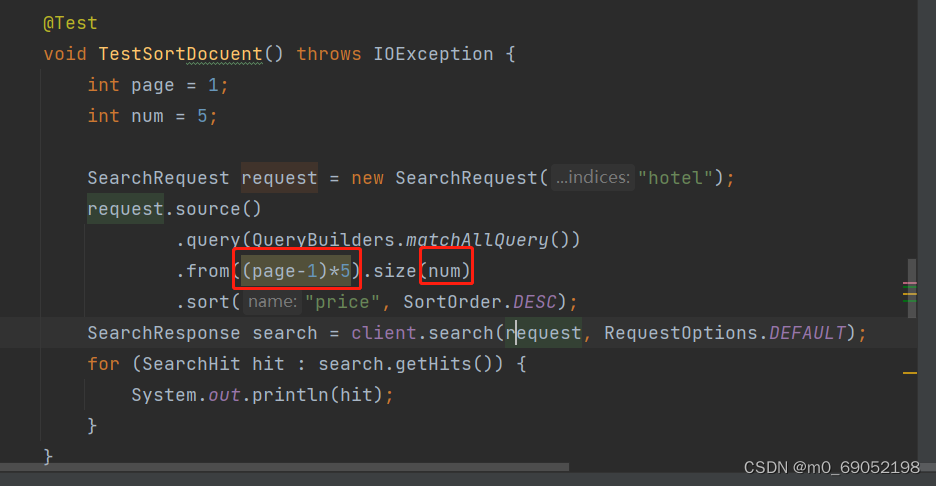
void TestSortDocuent() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source()
.query(QueryBuilders.matchAllQuery())
.from(0).size(5)
.sort("price", SortOrder.DESC);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
System.out.println(hit);
}
}在开发环境中,通常是由前端传过来分页的数据,后端接收并显示,所以对这里进行一个改良,代码如下:
高亮的查询结构如下
@Test
void testHighlight() throws IOException {
SearchRequest request = new SearchRequest("hotel");
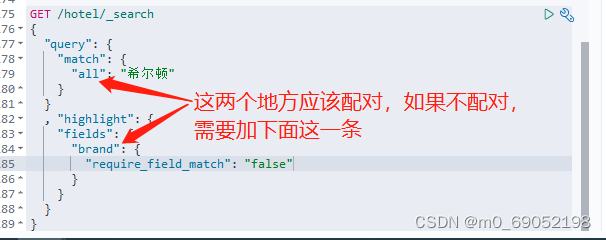
// 查询希尔顿,并且要求高亮显示
request.source()
.query(QueryBuilders.matchQuery("all","希尔顿"))
.highlighter(new HighlightBuilder()
.field("brand")
.requireFieldMatch(false));
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
// 将得到的数据序列化成都对象
String sourceAsString = hit.getSourceAsString();
HotelDoc doc = JSON.parseObject(sourceAsString, HotelDoc.class);
// 这一段得到高亮结果,然后再放到对象中,最后打印对象
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if(highlightFields !=null){
HighlightField brand = highlightFields.get("brand");
Text[] fragments = brand.getFragments();
Text fragment = fragments[0];
doc.setBrand(fragment.string());
}
}
}1.8.5 Es的实操案例
实操如下:
使用一个编写好前端的代码,编写对应的MVC,然后完成查询操作等
第一个功能是完成分页,以及特征值的查询功能
首先通过前端代码可以知道,前端传入的是各种类型的数据,所以我们需要一个类来接收数据,并且需要一个特定的类来输出数据
接收数据的类如下
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
private Integer page;
private Integer size;
private String sortBy;
private String location;
}
返回的数据如下,返回一个集合,以及这个集合中有几个元素
package cn.itcast.hotel.pojo;
import lombok.Data;
import java.util.List;
@Data
public class PageResult {
private Long total;
private List<HotelDoc> hotels;
public PageResult() {
}
public PageResult(Long total, List<HotelDoc> hotels) {
this.total = total;
this.hotels = hotels;
}
}
然后编写MVC
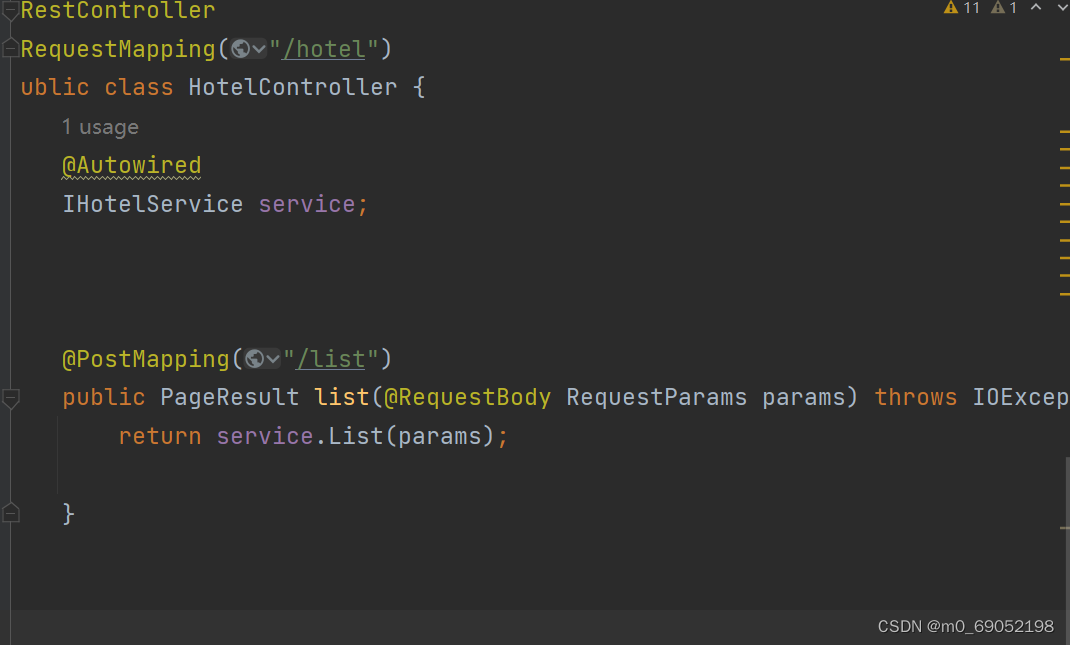
重点在Service层中如何接收数据,查询对应数据,并对返回数据进行一个处理。
代码如下
@Autowired
private RestHighLevelClient client;
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
String key = params.getKey();
// 关键字判断
if (key == null || "".equals(key)) {
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
} else {
boolQueryBuilder.must(QueryBuilders.matchQuery("all", key));
}
request.source().query(boolQueryBuilder);
request.source().from(params.getPage()).size(params.getSize());
SearchResponse search = client.search(request, RequestOptions.DEFAULT);与之前测试类的条件一样,需要先创建一个client对象,然后创建对应的request对象,发送请求参数,然后向Client发送请求就可以了.
需要注意的是这个查询出来的search对象,我们需要对其中的数据进行处理,处理过程如下
简单的说,就是得到一个list列表,然后将列表转化成HotelDoc对象,最后返回一个上文中编写的结果类
private PageResult getResult(SearchResponse response){
PageResult pageResult = new PageResult();
SearchHits hits = response.getHits();
TotalHits size = hits.getTotalHits();
pageResult.setTotal(size.value);
List<HotelDoc> list = Arrays.stream(hits.getHits()).map(item->{
Object[] sortValues = item.getSortValues();
String sourceAsString = item.getSourceAsString();
HotelDoc doc = JSON.parseObject(sourceAsString, HotelDoc.class);
if (sortValues!=null){
doc.setDistance(sortValues[0]);
}
return doc;
}).collect(Collectors.toList());
pageResult.setHotels(list);
return pageResult;
}其他的查询如下:
// 城市判断
if (params.getCity() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 价格判断
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price")
.gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
// 星级判断
if (params.getStarName() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 品牌
if (params.getBrand() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 判断距离
String location = params.getLocation();
if(location!=null){
request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.DESC)
.unit(DistanceUnit.KILOMETERS));
}
完整service层的代码如下:
package cn.itcast.hotel.service.impl;
import ch.qos.logback.classic.pattern.ClassOfCallerConverter;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.apache.http.HttpHost;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.TotalHits;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.Stack;
import java.util.stream.Collectors;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
private RestHighLevelClient client;
@Override
public PageResult List(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
String key = params.getKey();
// 关键字判断
if (key == null || "".equals(key)) {
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
} else {
boolQueryBuilder.must(QueryBuilders.matchQuery("all", key));
}
// 城市判断
if (params.getCity() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 价格判断
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price")
.gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
// 星级判断
if (params.getStarName() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 品牌
if (params.getBrand() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 判断距离
String location = params.getLocation();
if(location!=null){
request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.DESC)
.unit(DistanceUnit.KILOMETERS));
}
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(boolQueryBuilder, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{});
request.source().query(boolQueryBuilder);
request.source().from(params.getPage()).size(params.getSize());
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
PageResult result = getResult(search);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private PageResult getResult(SearchResponse response){
PageResult pageResult = new PageResult();
SearchHits hits = response.getHits();
TotalHits size = hits.getTotalHits();
pageResult.setTotal(size.value);
List<HotelDoc> list = Arrays.stream(hits.getHits()).map(item->{
Object[] sortValues = item.getSortValues();
String sourceAsString = item.getSourceAsString();
HotelDoc doc = JSON.parseObject(sourceAsString, HotelDoc.class);
if (sortValues!=null){
doc.setDistance(sortValues[0]);
}
return doc;
}).collect(Collectors.toList());
pageResult.setHotels(list);
return pageResult;
}
}
1.9 Es的拓展操作
1.9.1 数据聚合
聚合可以实现对文档数据的统计,分析和运算。在Es中常见的聚合有三类:
1.桶(Bucket)聚合,用来对文档做分类
2.度量聚合,用以计算一些值,比如最大值,最小值,平均值等
3.管道聚合,用于对其他聚合的结果为基础做聚合。
1.9.2 使用DSL完成Bucket聚合
使用DSL来完成对品牌的聚合
GET /hotel/_search
{
"size" : 0 //设置size为0,结果中不包含文档,只包含聚合的结果
"aggs": { // 定义聚合的,这一个括号中可以有多个聚合
"brandAgg":{ //聚合的名称
"term" :{ //聚合的类型
"field" :"brand" //根据brand属性聚合
"size" : 20 //希望获得的聚合数量
}
}
}
}同时聚合的同时,还可以添加聚合的范围
GET /hotel/_search
{
"query":{
"range":{
"price":{
"lte":200
}
}
}
"size" : 0 //设置size为0,结果中不包含文档,只包含聚合的结果
"aggs": { // 定义聚合的,这一个括号中可以有多个聚合
"brandAgg":{ //聚合的名称
"term" :{ //聚合的类型
"field" :"brand" //根据brand属性聚合
"size" : 20 //希望获得的聚合数量
}
}
}
}1.9.3 使用DSL完成Metrics聚合
// 嵌套聚合
GET /hotel/_search
{
"size": 0,
"aggs": {
"BrandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"ScoreAgg.avg": "desc" // 按照得分之后的平均分进行一个降序
}
}
, "aggs": { // 在上一个桶聚合的内部定义一个新的聚合
"ScoreAgg": {
"stats": { // 按照得分排序
"field": "score"
}
}
}
}
}
}1.9.4 使用RestClient实现聚合
代码如下:
@Test
public void testAggregation() throws IOException {
//1. 准备request
SearchRequest request = new SearchRequest("hotel");
//2, 接收参数
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(10)
);
//3. 将request发送给client处理
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(search);
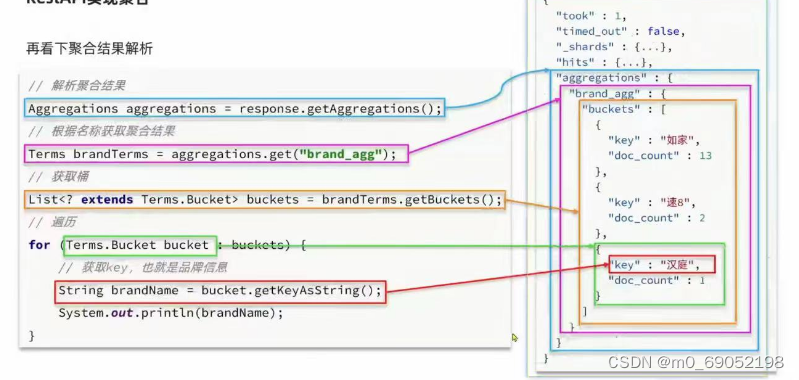
Aggregations aggregations = search.getAggregations();
Terms brandAgg = aggregations.get("brandAgg");
for (Terms.Bucket bucket : brandAgg.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println(keyAsString);
}
}将接收到的参数转化过程如下
上面是比较简单的品牌聚合,实例演示如下
@Override
public Map<String, List<String>> filter() {
try {
Map<String, List<String>> map = new HashMap<>();
List<String> BrandList = new ArrayList<>();
List<String> StarList = new ArrayList<>();
List<String> CityList = new ArrayList<>();
SearchRequest request = new SearchRequest("hotel");
request.source().aggregation(AggregationBuilders
.terms("BrandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("StarAgg")
.field("starName")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("CityAgg")
.field("city")
.size(100)
);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = search.getAggregations();
Terms brandAgg = aggregations.get("BrandAgg");
Terms StarAgg = aggregations.get("StarAgg");
Terms CityAgg = aggregations.get("CityAgg");
for (Terms.Bucket bucket : brandAgg.getBuckets()) {
BrandList.add(bucket.getKeyAsString());
}
for (Terms.Bucket bucket : StarAgg.getBuckets()) {
StarList.add(bucket.getKeyAsString());
}
for (Terms.Bucket bucket : CityAgg.getBuckets()) {
CityList.add(bucket.getKeyAsString());
}
map.put("地点", CityList);
map.put("星级", StarList);
map.put("品牌", BrandList);
return map;
}catch (IOException e){
throw new RuntimeException(e);
}
}
对该部分进行一个改进,即查询关键词,然后根据关键词查询出来的结果进行一个桶聚合
上半部分就是之前用RestClient进行的一个查询操作,然后对查询的结果进行一个聚合
@Override
public Map<String, List<String>> filter(RequestParams params) {
try {
Map<String, List<String>> map = new HashMap<>();
List<String> BrandList = new ArrayList<>();
List<String> StarList = new ArrayList<>();
List<String> CityList = new ArrayList<>();
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
String key = params.getKey();
// 关键字判断
if (key == null || "".equals(key)) {
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
} else {
boolQueryBuilder.must(QueryBuilders.matchQuery("all", key));
}
// 城市判断
if (params.getCity() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 价格判断
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price")
.gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
// 星级判断
if (params.getStarName() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 品牌
if (params.getBrand() != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 判断距离
String location = params.getLocation();
if(location!=null){
request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.DESC)
.unit(DistanceUnit.KILOMETERS));
}
request.source().aggregation(AggregationBuilders
.terms("BrandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("StarAgg")
.field("starName")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("CityAgg")
.field("city")
.size(100)
);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = search.getAggregations();
Terms brandAgg = aggregations.get("BrandAgg");
Terms StarAgg = aggregations.get("StarAgg");
Terms CityAgg = aggregations.get("CityAgg");
for (Terms.Bucket bucket : brandAgg.getBuckets()) {
BrandList.add(bucket.getKeyAsString());
}
for (Terms.Bucket bucket : StarAgg.getBuckets()) {
StarList.add(bucket.getKeyAsString());
}
for (Terms.Bucket bucket : CityAgg.getBuckets()) {
CityList.add(bucket.getKeyAsString());
}
map.put("地点", CityList);
map.put("星级", StarList);
map.put("品牌", BrandList);
return map;
}catch (IOException e){
throw new RuntimeException(e);
}
}1.10 数据同步
1.10.1 数据同步的方案
Es中的数据是由Mysql数据中导入的,因此Mysql中的数据发生变化时,我们希望Es中的数据也发生变化,这就是数据同步。
方案一,同步调用
步骤如下:
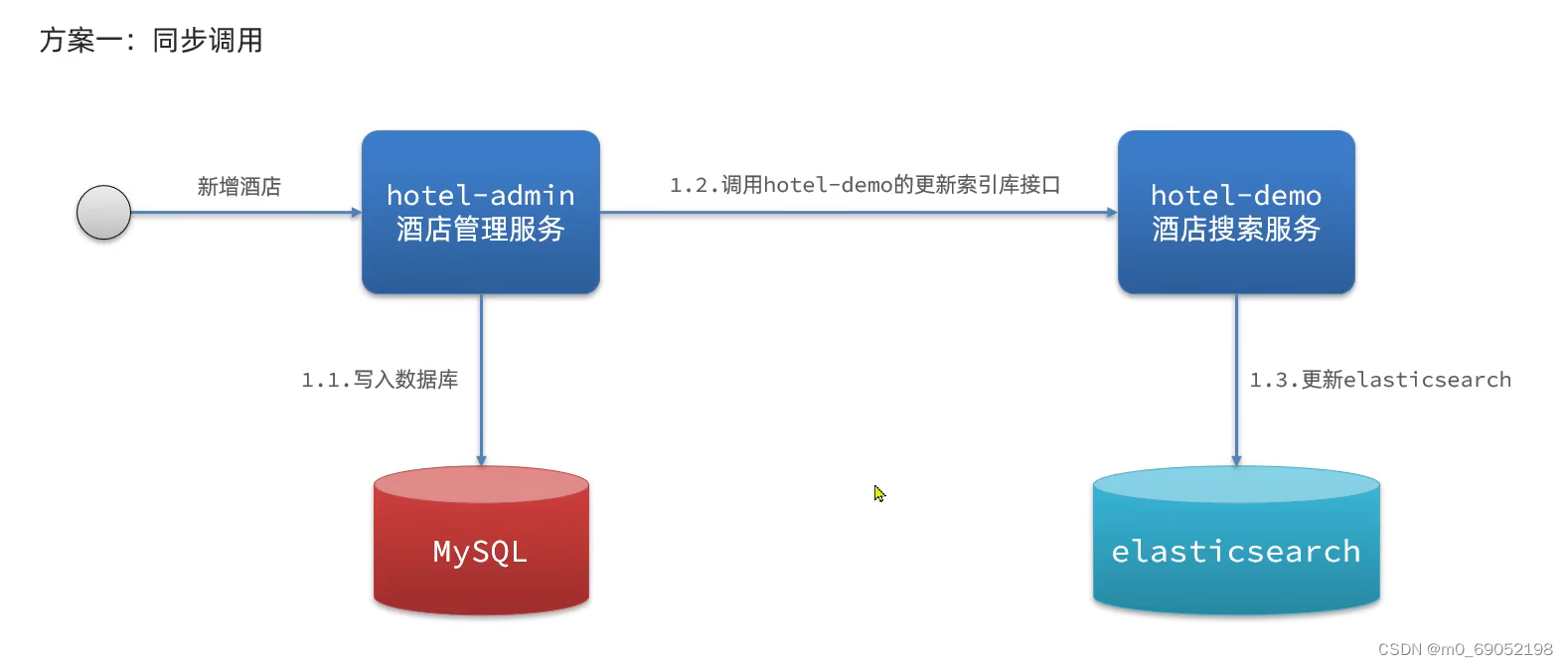
用户发出新增酒店的请求给酒店管理的微服务,通过service层写入Mysql,然后在该微服务中,再调用酒店搜索的微服务,通过RestClient来调用Es完成更新。
方案二:异步通知
步骤如下:
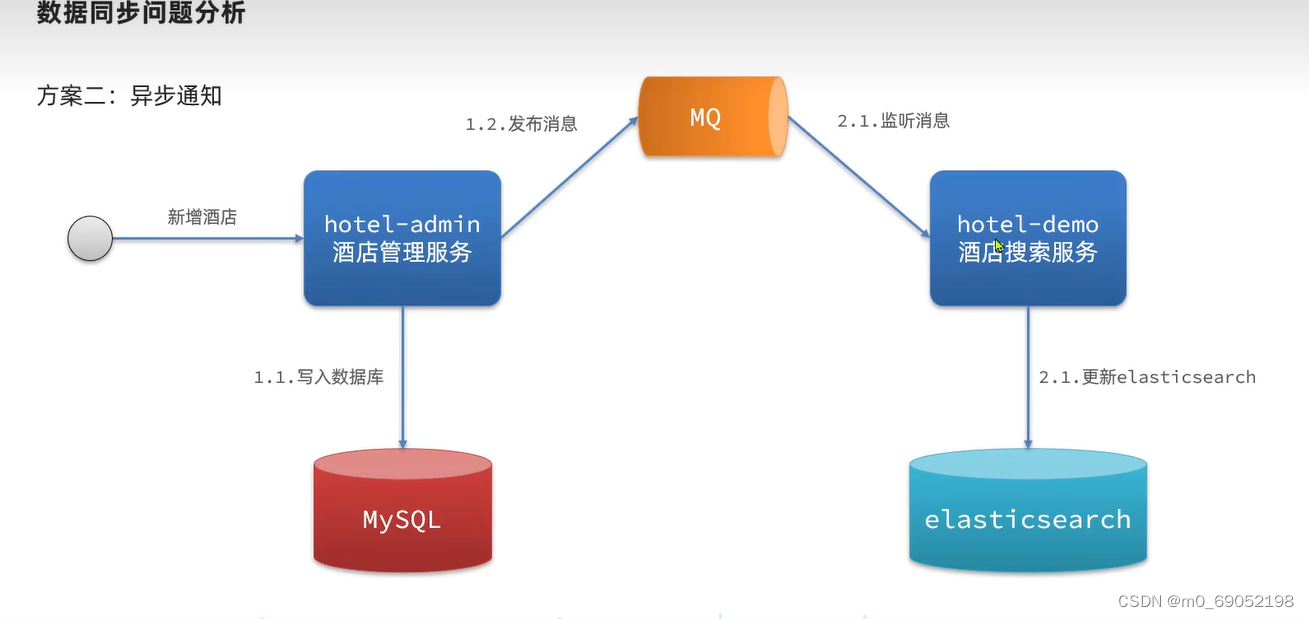
用户发出新增酒店的请求给酒店管理的微服务,通过service层写入Mysql,这时发送信息给MQ消息队列,如果酒店搜索服务监听到该消息,就更新es
1.10.2 数据同步的案例
实例如下:利用MQ实现Mysql与es的数据同步

这时候需要知道的是,增加和修改操作都只需要往Es中添加数据就可以了所以需要一个队列,删除操作需要另外一个队列
所以这里需要的是两个队列。
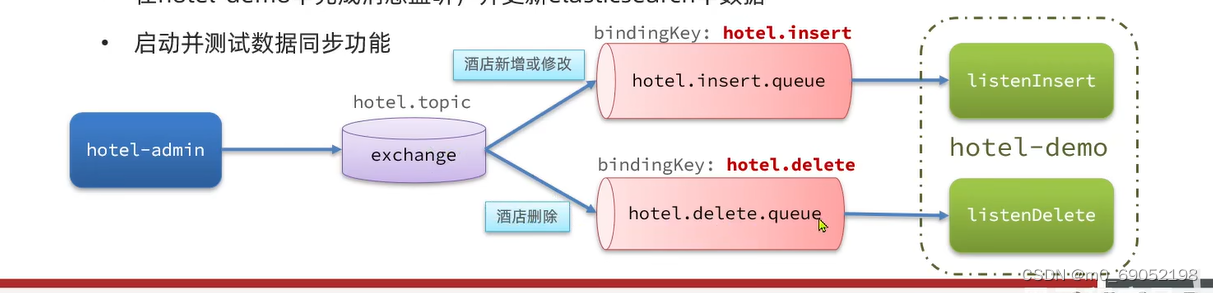
声明消息队列和交换机是在消费者方面做,步骤如下:
1.引入依赖

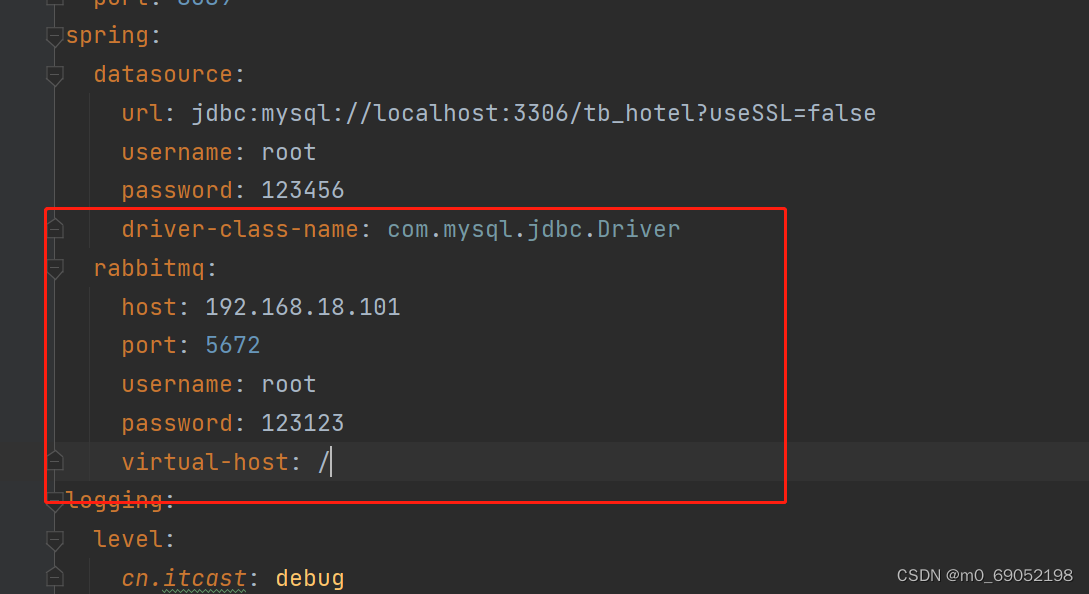
2.修改配置类
3.做Constants常量类
package cn.itcast.hotel.constants;
public class MqConstants {
// 交换机
public final static String Hotel_Exchange = "hotel.topic";
// 监听新增和修改的队列
public final static String Hotel_Insert_Queue = "hotel.insert.queuqe";
// 监听删除的队列
public final static String Hotel_Delete_Queue = "hotel.delete.queue";
// 新增或修改的RoutingKey
public final static String Hotel_Insert_Key = "hotel.insert";
// 删除的RoutingKEY
public final static String Hotel_Delete_Key = "hotel.delete";
}
4.做一个配置类
package cn.itcast.hotel.Config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MqConfig {
/*
交换机
*/
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.Hotel_Exchange,true,false);
}
/**
* 新增的队列
* @return
*/
@Bean
public Queue InsertQueue(){
return new Queue(MqConstants.Hotel_Insert_Queue,true);
}
/**
* 删除的队列
* @return
*/
@Bean
public Queue DeleteQueue(){
return new Queue(MqConstants.Hotel_Delete_Queue,true);
}
/**
* 新增队列和交换机用KEY做绑定
* @return
*/
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(InsertQueue()).to(topicExchange()).with(MqConstants.Hotel_Insert_Key);
}
/**
* 新增队列和交换机用Key做绑定
* @return
*/
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(DeleteQueue()).to(topicExchange()).with(MqConstants.Hotel_Delete_Key);
}
}
之后在提供者方面做以下步骤:
1.新增依赖
2.编写配置文件
3.将之前在消费者中定义好的常量复制过来
4.在Controller层发送消息给Mq
4.1 自动注入Template
4.2 在对应的方法加入要发送的消息
注意:这里发送的只是ID,可以通过ID来查询Es中数据
package cn.itcast.hotel.web;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.service.IHotelService;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.security.InvalidParameterException;
@RestController
@RequestMapping("hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/{id}")
public Hotel queryById(@PathVariable("id") Long id){
return hotelService.getById(id);
}
@GetMapping("/list")
public PageResult hotelList(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "size", defaultValue = "1") Integer size
){
Page<Hotel> result = hotelService.page(new Page<>(page, size));
return new PageResult(result.getTotal(), result.getRecords());
}
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
// convertAndSend(交换机,绑定的Key,以及发送的消息)
rabbitTemplate.convertAndSend(MqConstants.Hotel_Exchange,MqConstants.Hotel_Insert_Key,hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.Hotel_Exchange,MqConstants.Hotel_Insert_Key,hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.Hotel_Exchange,MqConstants.Hotel_Delete_Key,id);
}
}
在消费者完成消息监听,步骤如下:
1.编写监听器类
package cn.itcast.hotel.Mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.impl.HotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class HotelListener {
@Autowired
HotelService service;
/**
* 监听插入队列
* @param id
*/
@RabbitListener(queues = MqConstants.Hotel_Insert_Queue)
public void listenInsertQueue(Long id){
service.insertById(id);
}
/**
* 监听删除的队列
* @param id
*/
@RabbitListener(queues = MqConstants.Hotel_Delete_Queue)
public void listenDeleteQueue(Long id){
service.deleteById(id);
}
}
2.在Service层完成对应的方法的编写
/**
* 监听的删除操作
* @param id
*/
@Override
public void deleteById(Long id) {
// 使用request接收id
DeleteRequest request = new DeleteRequest("hotel");
request.id(String.valueOf(id));
try {
//通过client接收request并删除对应id的数据
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 监听的新增操作
* @param id
*/
@Override
public void insertById(Long id){
try {
// 通过Service通过Mysql查询对应的数据
Hotel hotel = this.getById(id);
HotelDoc doc = new HotelDoc(hotel);
// 使用request接收对应的id
IndexRequest request = new IndexRequest().id(String.valueOf(doc.getId()));
// 并将得到的Mysql中的数据转化为JSON格式,传入Es中
request.source(JSON.toJSONString(doc), XContentType.JSON);
// 交给Client处理
client.index(request, RequestOptions.DEFAULT);
}catch (IOException E){
new RuntimeException(E);
}
}1.11 Es集群
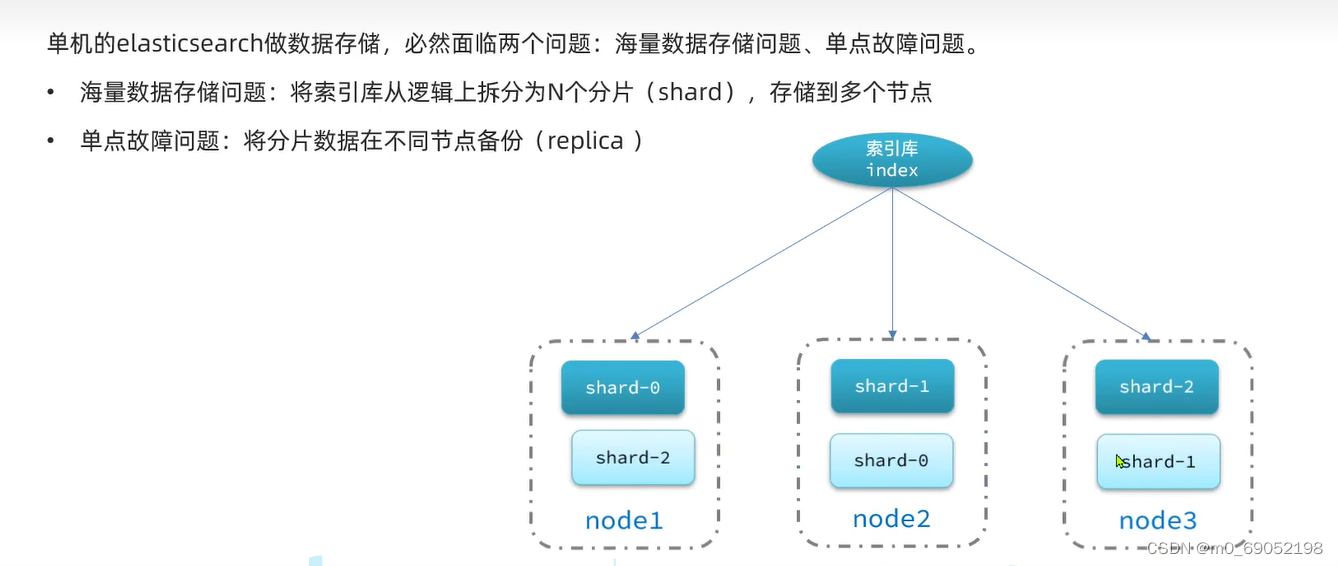
单体的Es做数据存储,可能会两个问题,一个是海量数据存储问题,一个是单点故障问题
如果使用Es集群的方法可以完美的处理这俩问题,使用集群可以使海量数据分开存储,并将数据切分成不同部分的数据,然后将分片数据在不同节点备份
1.11.1 如何搭建Es集群
这个直接跳过了
1.12 Sentinel
雪崩问题
在微服务中,可能会出现,一个微服务依赖其他服务的情况,而其中一个微服务宕机之后,会引发多级问题,最后导致整个微服务都不可以使用,处理的方式如下:
1.超时处理:设定超过时间,请求超过一定时间没有响应就会返回信息,不会无休止等待。
2.舱壁模式,限定每个业务能使用的线程数,避免整个tomcat服务的资源被耗尽,因此也叫线程隔离
3.熔断降级,由断路器统计业务执行的异常比例,如果超出阈值就熔断该业务,拦截访问的所有请求
4.流量控制:限制QPS(一秒的请求数量),避免服务因为流量突增而故障
而Sentinel就是负责用法分发业务请求的,所有请求都发往Sentinel中,然后再由他将合适的请求量发送给受保护的服务

安装Sentinel安装台
1.12.1 如何使用Sentinel
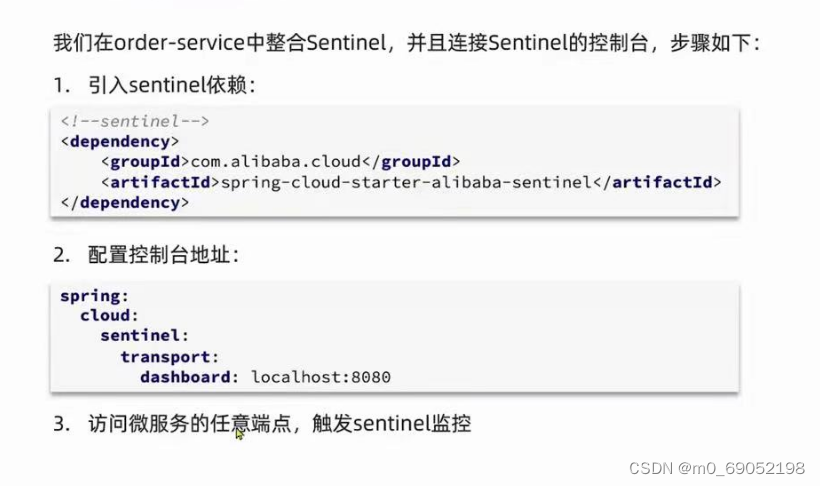
1.12.2 限流规则

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









