







 本文详细解释了函数依赖的不同类型,如平凡、非平凡、完全和部分依赖,以及主键、外键、候选码、主码和外码的概念。同时介绍了数据库范式,包括1NF、2NF、3NF、BCNF,以及多值依赖和4NF,强调了规范化在数据存储效率和一致性提升中的作用。
本文详细解释了函数依赖的不同类型,如平凡、非平凡、完全和部分依赖,以及主键、外键、候选码、主码和外码的概念。同时介绍了数据库范式,包括1NF、2NF、3NF、BCNF,以及多值依赖和4NF,强调了规范化在数据存储效率和一致性提升中的作用。
目录
一、函数依赖
假设我们有一个包含学生选课信息的表StudentCourse,其中包含以下字段:
- 学生ID(StudentID)
- 课程号(CourseCode)
- 成绩(Grade)
- 课程名称(CourseName)
- 课程学分(Credits)
- 教师姓名(TeacherName)
- 函数依赖: 在关系模式 StudentCourse 中,可以说学生ID(StudentID)决定了学生的课程号、成绩、课程名称、课程学分、教师姓名,因此有函数依赖关系:StudentID -> {CourseCode, Grade, CourseName, Credits, TeacherName}
- 平凡函数依赖与非平凡函数依赖: 考虑一个平凡函数依赖的情况,如学生ID(StudentID)决定学生的姓名,由于学生ID已经包含了学生的姓名,即存在函数依赖关系:StudentID -> StudentID,是平凡函数依赖。 考虑一个非平凡函数依赖的情况,如学生ID(StudentID)决定学生的成绩(Grade),但成绩(Grade)并不包含学生ID,即存在函数依赖关系:StudentID -> Grade,是非平凡函数依赖。
- 完全函数依赖于部分函数依赖: 在表StudentCourse中,如果学生ID(StudentID)和课程号(CourseCode)共同决定了成绩(Grade),即存在完全函数依赖关系:{StudentID, CourseCode} -> Grade。 如果学生ID(StudentID)和姓名(StudentName)共同决定了专业(Major),但专业(Major)只依赖于学生ID(StudentID),即存在部分函数依赖关系:{StudentID, StudentName} -> Major。
- 传递函数依赖: 假设在表中存在这样的情况:学生ID(StudentID)决定了专业(Major),而专业(Major)又决定了系主任(DepartmentHead),则存在传递函数依赖:StudentID -> Major -> DepartmentHead。
通过上述示例,可以更好地理解函数依赖的概念及不同类型之间的区别。这种数据分析有助于设计出符合数据库范式要求的结构,提高数据存储的效率和一致性。
二、码
| 主键(Primary Key) | 用于唯一标识数据库表中每一行数据的一列或一组列。主键的值必须是唯一的且不为空,用来确保表中的每一行数据都能被唯一标识。 |
| 外键(Foreign Key) | 用来建立表与表之间的关系的一列或一组列。外键包含另一个表(被引用表)的主键的值,从而在两个表之间建立引用关系。 |
| 候选码(Candidate Key) | 在关系中可以唯一标识元组的属性集合称为候选码。候选码是可以作为主键的备选键。 |
| 主码(Primary Key Attribute) | 主码是关系模式的一个属性(或属性组合),用来唯一标识关系中的元组。通常主码是候选码中选择的一个来作为主键。 |
| 外码(Foreign Key Attribute) | 在一个表中,参照另一个表的主码的属性称为外码(也称外键)。外码用来与其他表建立关联关系。 |
| 全码(Super Key) | 指能唯一标识关系中的元组的任意属性组合,包括主键、候选码等。全码包含了候选码和其他能够唯一标识元组的属性,而不仅仅是最小的唯一标识。 |
| 主属性(Primary Attribute) | 主属性是关系模式中的属性,它完全依赖于主键(或整个候选键),是主键的一部分,直接参与形成主键。 |
| 非主属性(Non-primary Attribute) | 非主属性是指不包括在主键中的属性,其取值完全依赖于主键(或整个候选键),但并不是唯一标识元组的关键。非主属性可能是依赖于候选键或主键的其他属性,不直接参与形成主键。 |
| 总的来说,主键用于唯一标识数据行,外键建立表之间的关系,候选码是可以唯一标识元组的属性集合,主码是选定为主键的候选码,外码参考其他表的主键,全码是能够唯一标识元组的任意属性组合,主属性直接参与形成主键,非主属性则不是主键的组成部分。 | |
假设我们有两个数据表:学生表(Students)和课程表(Courses),它们之间建立了一对多的关系,每个学生可以选择多门课程。
- 主键(Primary Key): 在学生表(Students)中,学生ID(StudentID)可能作为主键,确保每个学生都有一个唯一的标识符。 在课程表(Courses)中,课程ID(CourseID)可能作为主键,确保每门课程都有一个唯一的标识符。
- 外键(Foreign Key): 在课程表(Courses)中,可以添加一个外键,指向学生表中的学生ID,以建立学生和课程之间的关系。
- 候选码(Candidate Key): 在学生表(Students)中,学生姓名(StudentName)可能作为一个候选码,也能唯一标识每个学生。 在课程表(Courses)中,课程名称(CourseName)可能作为一个候选码,也能唯一标识每门课程。
- 主码(Primary Key Attribute): 从候选码中选择的学生ID和课程ID可能成为学生表和课程表中的主键。
- 外码(Foreign Key Attribute): 在课程表中的外键(例如学生ID),参照学生表中的主键(StudentID)。
- 全码(Super Key): 假设我们要唯一标识每个学生选课情况,可以使用学生ID和课程ID的组合作为全码。
- 主属性(Primary Attribute): 在学生表中,学生ID和学生姓名可能是主属性,它们是主键的一部分。 在课程表中,课程ID和课程名称可能是主属性,也是主键的一部分。
- 非主属性(Non-primary Attribute): 在学生表中,学生性别(Gender)可能是非主属性,它依赖于主键(学生ID)。 在课程表中,课程学分(Credits)可能是非主属性,它依赖于主键(课程ID)。
综合以上举例,主键用于唯一标识行,外键建立表之间关系,候选码是能唯一标识元组的属性集,主码是选定为主键的候选码,外码参考其他表的主键,全码是能够唯一标识元组的属性组合,主属性是主键的一部分,而非主属性则不是主键的一部分。
三、范式
- 范式是什么?
范式(Normal Forms)是数据库设计中一种标准化的规范,用来规范关系型数据库中表结构的设计,以减少数据冗余,确保数据的一致性和完整性。
- 范式用来做什么?
范式通常用于优化数据库表的结构,以减少数据冗余,提高数据的存储效率和查询性能。范式的提出旨在消除设计中的数据依赖问题,通过将数据分解到不同的表中,保证每个表都只包含一个主题。这样做可以减少数据的冗余,提高数据库的性能,同时保证数据之间的关系清晰明了。
- 范式之间怎们转化?
1)从无到第一范式(1NF):确保每个数据项都是原子性的,不可再分。如果存在多值属性,可以将其拆分成单独的字段或表。
2)从第一范式到第二范式:保证非主键属性完全依赖于主键,如果存在部分依赖,则需要将这些属性移动到单独的表中,以保证每个表都只包含一个主题。
3)从第二范式到第三范式:确保非主键属性不传递依赖于主键,如果存在传递依赖,则需要进一步将相关属性移动到新的表中,以保证每个表都符合第三范式的要求。
4)对于更高级别的范式,如BC范式、四范式等,转化通常需要更细致的分析和设计。需要考虑表与表之间的关系、数据的性质以及应用程序的需求,逐步进行表的拆分、合并和优化。
四、1NF
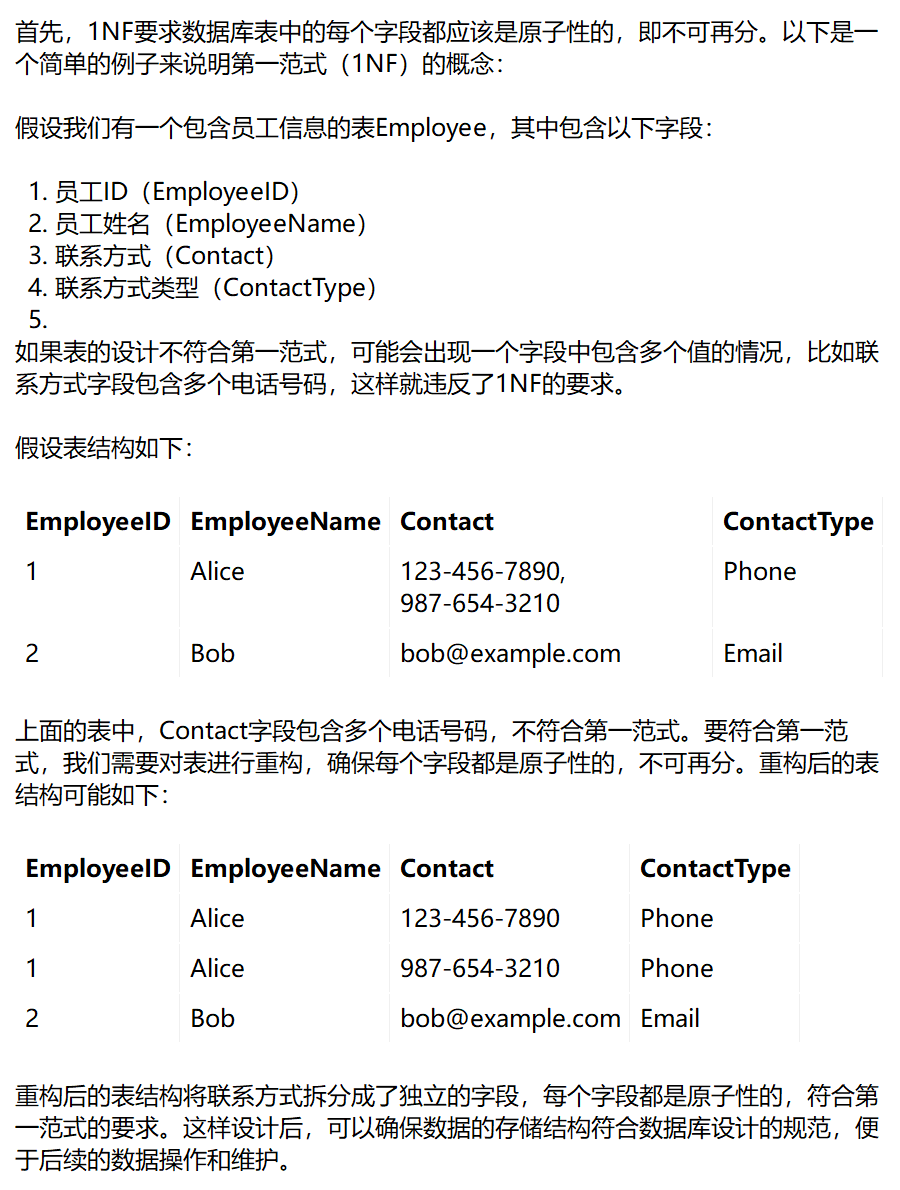
五、2NF
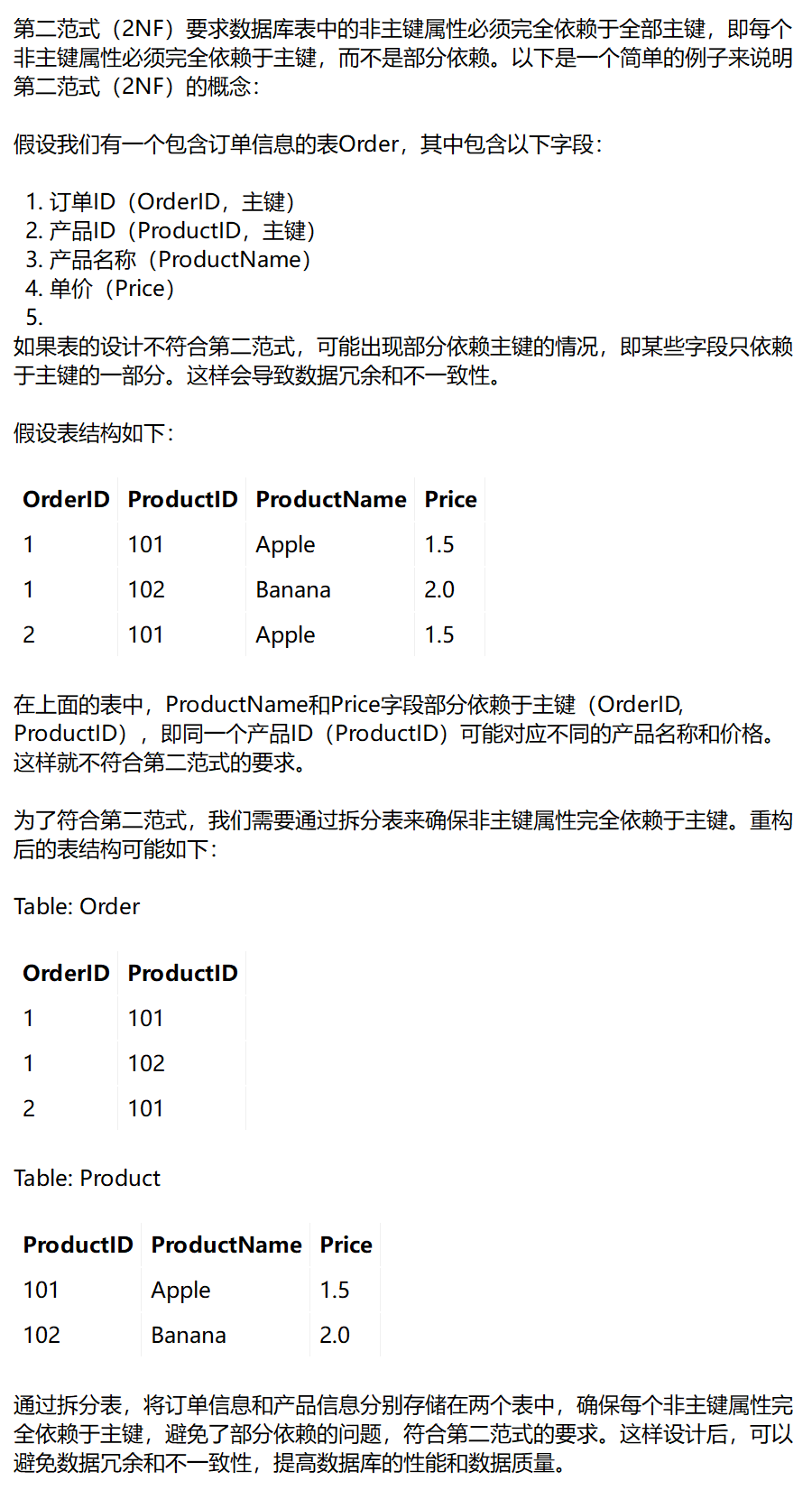
六、3NF

七、BCNF

八、多值依赖
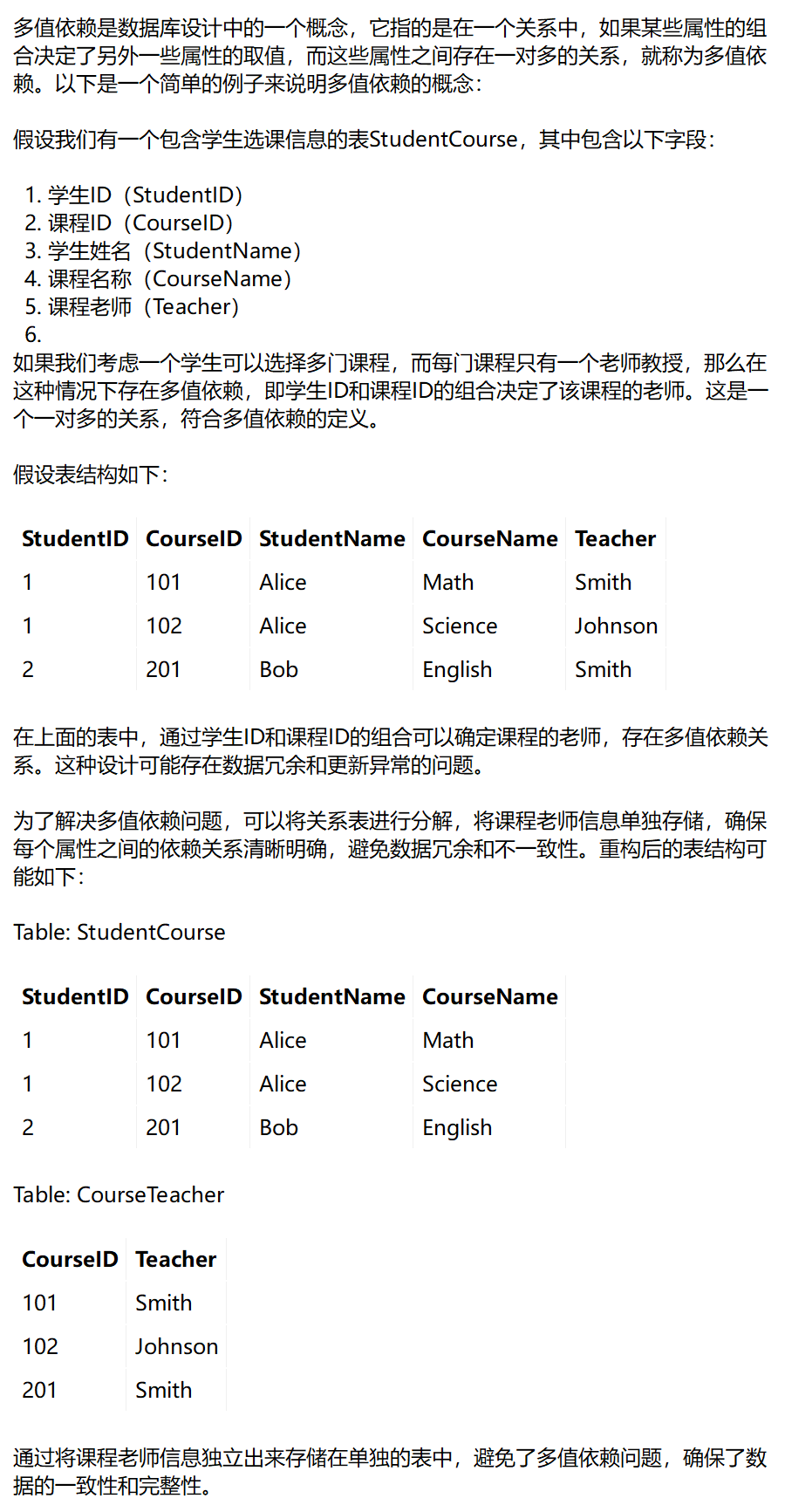
九、4NF

十、规范化小结



















 8020
8020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











