







目录
根据ID定位 a = wd.find_element(By.ID, '值')
根据NAME定位 a = wd.find_element(By.NAME, '值')
根据CLASS_NAME定位 a = wd.find_element(By.CLASS_NAME, '值')
根据TAG_NAME定位 a = wd.find_elements(By.TAG_NAME, '标签名')
超链接文本定位 a = wd.find_element(By.LINK_TEXT, '')
根据超文本部分内容定位 a = wd.find_element(By.PARTIAL_LINK_TEXT, '')
css表达式 a = find_element(By.CSS_SELECTOR, CSS Selector参数)
五. find_element 和 find_elements 的区别:
一.前序工作
- 安装selenium包: cmd窗口输入命令:pip install selenium
- 安装浏览器 Chrome 和 浏览器驱动
- 安装浏览器驱动:
--浏览器驱动的所在目录加入环境变量 Path ,创建对象时可以省略填写的路径参数 - 安装软件包
二.webdriver测试
from selenium import webdriver --导包
from selenium.webdriver.common.by import By
wd = webdriver.Chrome( ) --创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://www.baidu.com') --调用WebDriver 对象的get方法 可以让浏览器打开指定网址三.元素定位方式
以百度此input元素为例: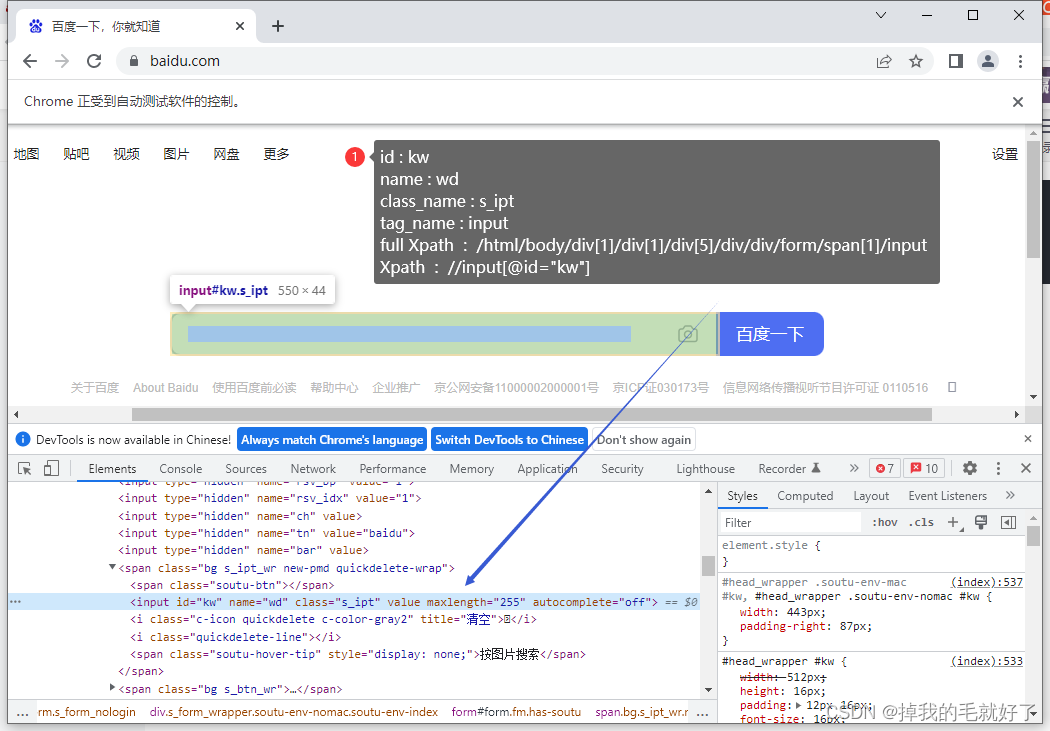
-
根据ID定位 a = wd.find_element(By.ID, '值')
# 根据id定位 a = wd.find_element(By.ID, 'kw') -
根据NAME定位 a = wd.find_element(By.NAME, '值')
# 根据name定位 a = wd.find_element(By.NAME, 'wd') -
根据CLASS_NAME定位 a = wd.find_element(By.CLASS_NAME, '值')
# 根据class_name定位 a = wd.find_element(By.CLASS_NAME, 's_ipt') -
根据TAG_NAME定位 a = wd.find_elements(By.TAG_NAME, '标签名')
# 根据tag_name定位 a = wd.find_elements(By.TAG_NAME, 'input') -
超链接文本定位 a = wd.find_element(By.LINK_TEXT, '')
a = wd.find_element(By.LINK_TEXT, 'hao123') -
根据超文本部分内容定位 a = wd.find_element(By.PARTIAL_LINK_TEXT, '')
a = wd.find_element(By.PARTIAL_LINK_TEXT, 'hao') -
css表达式 a = find_element(By.CSS_SELECTOR, CSS Selector参数)
根据id属性,选择元素的语法id,是在id值前面加上一个井号: #id值a
根据class属性,选择元素的语法,是在 class 值前面加上一个点: .class值aelement = wd.find_element(By.CSS_SELECTOR, '#ID的值') 等价于 element = wd.find_element(By.ID, 'ID的值')elements = wd.find_elements(By.CSS_SELECTOR, '.CLASS的值') 等价于 elements = wd.find_elements(By.CLASS_NAME, 'CLASS的值')
四.Xpath定位方式
以百度此span元素为例:
1.绝对路径 /Element
# 根据Xpath绝对定位
a = wd.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]')2.相对路径 //Element
(1)属性定位
//element [@属性 = 属性值]
//element[@属性 = 属性值 and @属性 = 属性值]
# 属性定位
a = wd.find_element(By.XPATH, '//span[@class = "bg s_ipt_wr new-pmd quickdelete-wrap"]')(2)子元素定位
//element/子元素
//element/child::子元素
# 子元素定位
a = wd.find_element(By.XPATH, '//form[@id="form"]/span[1]')
等价于
a = wd.find_element(By.XPATH, '//form[@id="form"]/child::span')(3)父元素定位
//element/..
//element/parent::子元素
# 父元素定位
a = wd.find_element(By.XPATH, '//span[@class = "soutu-btn"]/..')
等价于
a = wd.find_element(By.XPATH, '//span[@class = "soutu-btn"]/parent::span')(4)节点索引定位
//element[index]
# 索引定位
a = wd.find_element(By.XPATH, '//form[@id="form"]/span[1]')(5)通配符定位
//* [@* = 属性值]
# 通配符定位
a = wd.find_element(By.XPATH, '//*[@class = "bg s_ipt_wr new-pmd quickdelete-wrap"]')
a = wd.find_element(By.XPATH, '//span[@* = "bg s_ipt_wr new-pmd quickdelete-wrap"]')
a = wd.find_element(By.XPATH, '//*[@* = "bg s_ipt_wr new-pmd quickdelete-wrap"]')(6)属性关键字定位
//element[starts-with(@属性,"值" )]
//element[contains(@属性,"值")]
//element[contains(text( ) ="值" )]
# 属性关键字定位
a = wd.find_element(By.XPATH, '')
a = wd.find_element(By.XPATH, '')
a = wd.find_element(By.XPATH, '')五. find_element 和 find_elements 的区别:
1.使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
2.使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常














 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









