







一、引言
通过之前的人工智能架构分析和Transformer模型的原理介绍,读者应该对人工智能有了一个初步的了解。
但是很多读者不是很想知道那么多软件方面的专业知识,通过大家的问题,大家关心的主要是三个方面:
-
ai是怎么学习的,不停的搜网上的信息进行学习,然后人工再问他一些问题,根据答案进行正确错误提示调整吗?
-
在线跟ai的对话会让ai实时学习进步吗?
-
怎么在ai时代下保持自己的竞争力?
作者在这里用一些简单的示例来说说自己的理解和摸索
二、AI怎么学习
以我们学生的时候怎么学习进行类比,首先需要有知识载体也就是书,对ai来说就是数据集。
其次需要大脑记忆和逻辑分析,这就是ai使用大量的硬件资源的原因,但是以前的硬件资源也很多,为什么就达不到现在ai的效果?这是多方面结合的原因,神经网络和深度学习框架的不断迭代让ai对于数据的存储和结合非常类似于人脑,transformer架构的演进对神经网络、卷积等等的应用远超之前。但是这些偏向于技术层,有兴趣的可以看作者之前分析transformer的文章。
还有很重要的,分词断句,学生从小也是学123,再学古诗词的,首先得知道这个字什么意思、这个逻辑公式是什么(比如1+1=2),大家才能继续往下学,所以分词就是一个很重要的事情,对于ai来说也是一样。
所以在作者看来最基础的就是书籍=数据集、大脑=神经网络+深度学习、识字断句=分词器
还有一个很重要的就是考试、考试是为了熟练记忆和知道对错,ai记忆比人狠多了,但是他是不知道对错的,对错都是在数据集里面定好的
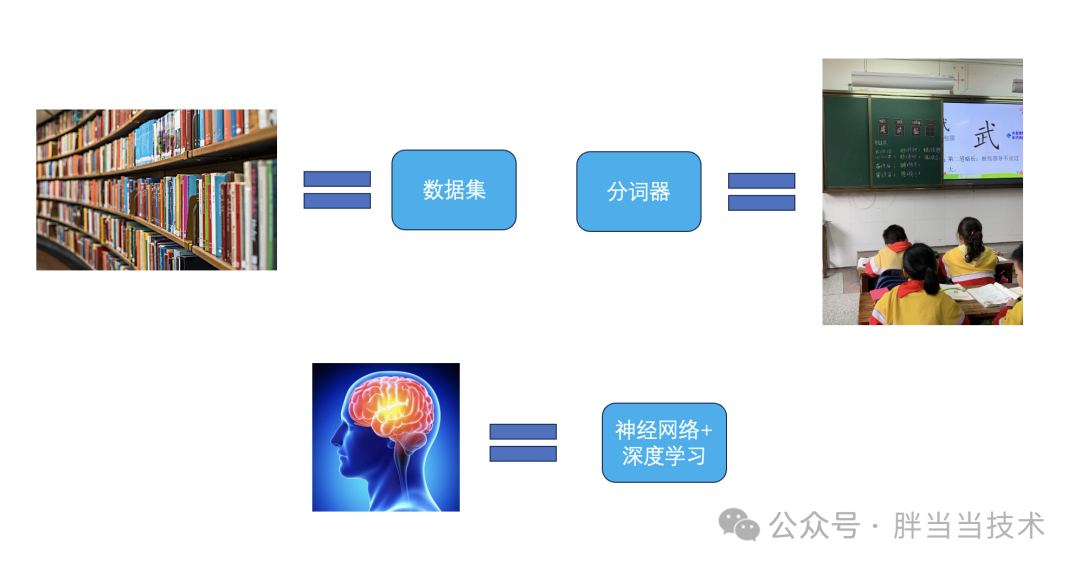
作者在这一章主要通过数据集和分词的剖析来说明ai是怎么学习的!
1、数据集
首先要明确的是,目前的ai不具备实时学习的能力,也就是说你对他的提问和对问题的修正反馈只会被记录,但是不会被ai更新,这也是为什么目前的ai都会有个截止时间,表示他收录了什么时间段的数据。
为什么会这样呢?那就要看他收录的数据了,训练所用的数据集是很严苛的,举个例子:来自零一万物、中科院深圳先进技术研究院,和M-A-P等机构的研究者们制作的一个数据集COIG-CQIA是这样的
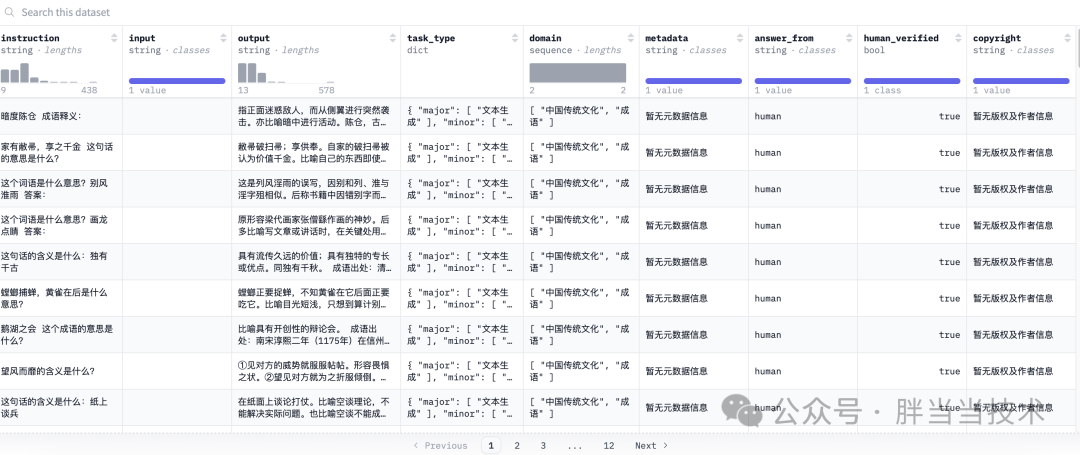
每个列的含义,都有严格的把控,其他数据集也差不多,各种语言、领域的,比如评论电影、感情分析等等,要给出一份合格的数据集不是一个简单的事情:
instruction:指示或指导,描述了给定任务的具体要求或指导。input:输入,表示用户或系统提供给模型的问题或查询。output:输出,表示模型对于给定输入的预测或生成的答案。task_type:任务类型,描述了数据集中的问题类型,例如问答、分类、生成等。dict:字典,表示数据集中可能包含的词典或知识库,用于支持模型的答案生成或推理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











