







LangGraph是什么?
LangGraph 是由 LangChain 团队开发的 Python 框架,专注于构建基于图结构的Agent和多Agent应用程序。与LangChain 不同,LangGraph 的核心设计理念是帮助开发人员在Agent工作流程中添加更好的精度和控制,以适应现实世界系统的复杂性。
LangGraph通过有状态图(StateGraph)支持循环、分支和动态流程控制,适合需动态流程控制、状态追踪和人机协同的场景。
核心设计理念
图结构建模
LangGraph 的核心思想是图,它将任务流程抽象为节点(Node)和边(Edge)构成的图。这种结构支持循环迭代(如多轮对话、自检纠错)和动态路由(根据上下文选择不同路径)。
- 节点可以是LLM调用、工具执行或自定义函数
- 边分为普通边和条件边,后者通过逻辑判断动态路由流程(如根据LLM输出选择下一步骤)
在处理流程中,程序可以根据不同的条件选择不同的路径执行,并且允许流程在一定条件下重复执行某些部分,最终构成一个有向有环图。
开发者可精确管理每个节点的行为(如工具调用顺序)、边的触发条件(如根据状态字段路由),甚至动态修改图结构。
而且,LangGraph将不同的处理逻辑封装为一个个组件(节点)。这些组件可以在不同的 agent 开发项目或者同一项目中的不同分支路径中复用,大大提高了开发效率。
例如,在一个智能客服 agent 的开发中,当用户询问产品相关信息时,agent可能先进行简单的知识库查询(处理节点1)。
如果查询结果不符合要求或者用户进一步追问产品的使用场景,agent就可以根据这个情况分支到更详细的使用场景说明流程(处理节点2)。
而且如果用户反复询问同一个问题的不同方面,agent还可以循环执行相关说明节点。
状态管理
LangGraph 可以有效地管理 agent 的状态。在与环境交互的过程中,它能够通过状态对象(State)记录 agent 当前所处的状态,包括已经执行过的 action、环境反馈的信息等诸多内容。
比如在一个机器人探索未知环境的 agent 系统中,LangGraph可以记录机器人已经探索过的区域、遇到的障碍物位置等状态信息。
当机器人需要重新规划路径或者再次经过某个区域时,这些状态信息就可以被利用起来,使agent 的决策更加合理。
持久化与可靠性
内置检查点(Checkpoint)机制,自动保存执行状态,支持断点续做、错误恢复和人工介入(Human-in-the-Loop)。
与LangChain生态集成
LangGraph并非完全独立,而是与LangChain生态深度集成:
- LangGraph可复用LangChain的模块(如提示模板、工具库)。
- 复杂场景中,LangGraph负责流程编排,LangChain处理具体任务(如数据加载、模型调用)
优势
在使用大语言模型进行复杂任务处理时,大语言模型的智能化程度通常和其可靠性成反比:大模型可以自主去做的东西越多,就越有可能出错,可靠性越低
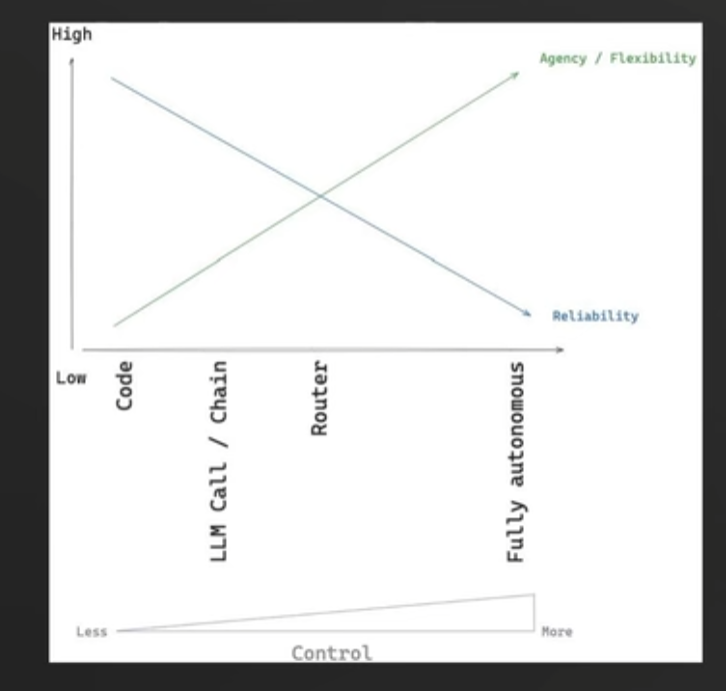
而LangGraph在一定程度上缓解了这个问题:即使我们给大语言模型较高的控制权,依然可以通过LangGraph对底层工作流进行控制,提高agent的可靠性
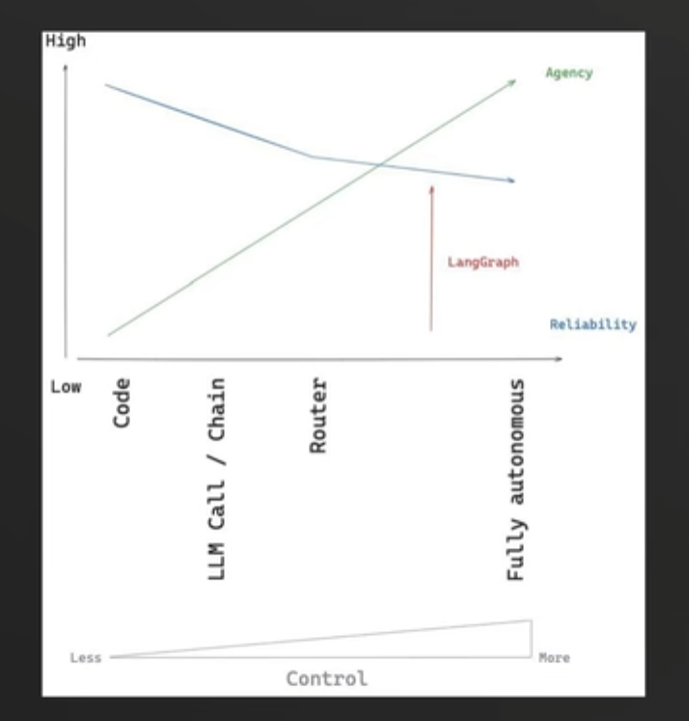
LangChain和LangGraph的区别
LangChain 的设计理念是 ICEL 链:
- Input(输入) :明确任务的初始输入,比如用户提出的一个问题或需要处理的数据等。
- Chain(链条) :包含一系列预定义的处理步骤,每个步骤代表一个特定的功能或操作,如数据检索、文本处理、模型推理等。这些步骤之间按顺序连接,形成一个完整的处理链条。
- Execution(执行) :按照链条的顺序依次执行各个步骤,每个步骤的输出作为下一个步骤的输入,直到整个链条执行完毕。
- Link(链接) :通过 | 符号将不同的处理过程链接起来,形成一个连贯的工作流,实现输入到输出的顺序式处理。
LangChain通过将多个过程用 | 连接起来形成顺序执行的流程,很适合 RAG 这种有明确先后顺序的项目,最终构成一个有向无环图。
然而,当涉及到 agent 开发时,情况就变得复杂了。因为 agent 需要与环境进行多次交互,并且要重复执行 action,如果按照 LangChain 的线性链式结构去开发,会导致链的长度过长,可维护性差,代码结构也不够清晰,所以 LangGraph 就应运而生了。
LangGraph的核心思想是图,支持分支和循环,能最终构成一个有向有环图,更适合 agent 开发等复杂交互场景。
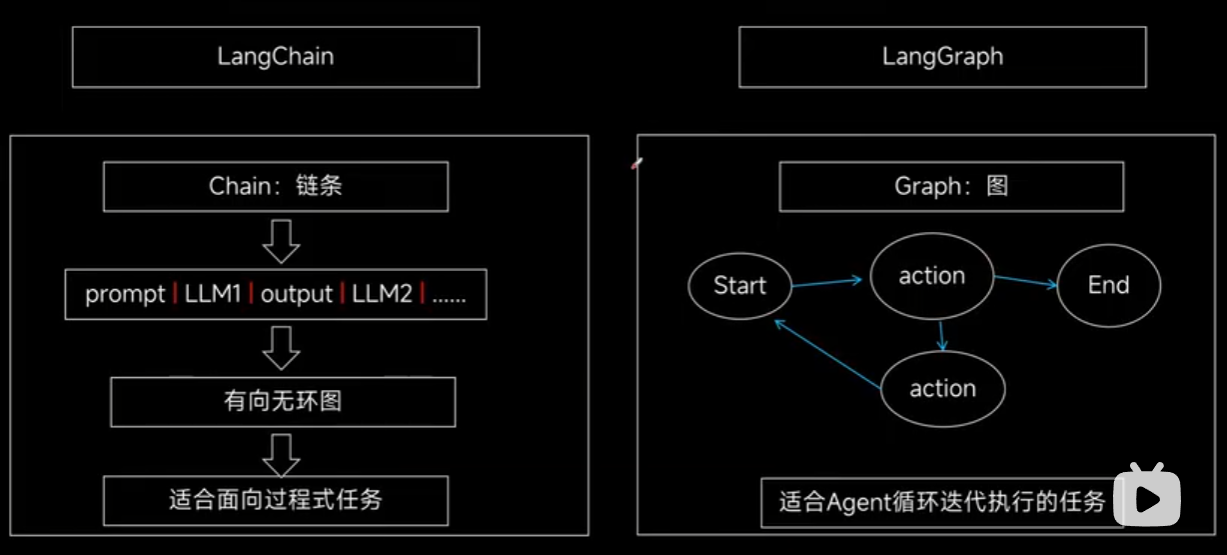
用LangGraph构建基本的聊天机器人
TypedDict 是 Python 中用于定义字典类型结构的工具,它允许你指定字典中每个键的类型。
可以使用 Annotated 来给键的类型添加额外的信息,例如一个 reducer 函数,用于定义如何更新该键的值。
reducer函数用于根据特定规则更新数据,常用于状态管理和函数式编程。它接收当前状态和操作,返回新状态。在这个例子中,add_messages是一个reducer函数,它的作用是将新消息追加到messages列表中,而不是覆盖整个列表。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
class State(TypedDict):
messages:Annotated[list, add_messages]
graph_builder = StateGraph(State)
在 LangGraph中,节点是一个函数(sync 或async ),接收当前State作为输入,执行自定义的计算,并返回更新的State。所以其中第一个位置参数是state 。
from langchain_community.chat_models import ChatOllama
local_llm = "qwen2.5:latest"
llm = ChatOllama(model=local_llm, format="json", temperature=0)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
定义好了节点以后,需要使用add_node方法将这些节点添加到图中。在将节点添加到图中的时候,可以自定义节点的名称。而如果不指定名称,则会为自动指定一个与函数名称等效的默认名称。
# 第一个参数是节点名称,第二个是要调用的函数
graph_builder.add_node("chatbot", chatbot)
接下来,添加一个 entry 点告诉图每次运行它时从哪里开始工作。
类似地,设置一个 finish 点指示图从哪退出。
from langgraph.graph import START, END
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
最后,通过compile编译图。在编译过程中,会对图结构执行一些基本检查(如有没有孤立节点等)。
graph = graph_builder.compile()
要调用图中的方法,可以使用 invoke 方法。
graph.invoke({"messages":"你好"})
完整代码
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
class State(TypedDict):
messages:Annotated[list, add_messages]
graph_builder = StateGraph(State)
from langchain_community.chat_models import ChatOllama
local_llm = "qwen2.5:latest"
llm = ChatOllama(model=local_llm, format="json", temperature=0)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# 第一个参数是节点名称,第二个是要调用的函数
graph_builder.add_node("chatbot", chatbot)
from langgraph.graph import START, END
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
graph.invoke({"messages":"你好"})



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









