






一、实验目的
- 掌握基于SVM算法构建手写数字识别模型
- 熟悉支持向量机算法的调用
- 熟悉支持向量机算法的主要参数
二、代码及结果
1.加载查看Digits数据集,使用matshow方法将像素矩阵显示为图片。
代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score, KFold
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np
### 导入数据
digits=load_digits()
print(digits.data.shape)
# 可视化数据集中的数字图像
plt.matshow(digits.images[6])
运行结果:
2.使用不同核函数的支持向量机分类模型进行分类
2.1.正则化系数C的修改:
使用网格搜索选择出最佳的模型参数和得分
代码:
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=42)
kernels = ['rbf', 'linear', 'poly', 'sigmoid']
C_values = [0.01, 0.05, 0.1, 0.5, 1]
# 网格搜索寻找最优参数模型
accuracies = {}
best_score =0
for k in kernels:
accuracies[k]= []
for c in C_values:
svm = SVC(kernel = k, C = c)
svm.fit(X_train,y_train)
score = svm.score(X_test,y_test)
accuracies[k].append(score)
if score > best_score:
best_score = score
best_parameters = {'kernel':k,'C':c}
print(best_score,best_parameters)
运行结果:
请分别记录四种核函数在正则化参数C分别为0.01, 0.05, 0.1, 0.5, 1时的模型准确率。
代码:
# 网格搜索寻找最优参数模型
accuracies = {}
best_score =0
for k in kernels:
accuracies[k]= []
for c in C_values:
svm = SVC(kernel = k, C = c)
svm.fit(X_train,y_train)
score = svm.score(X_test,y_test)
accuracies[k].append(score)
print(f"SVM-{k}-C: {c}, accuracy: {score}")
if score > best_score:
best_score = score
best_parameters = {'kernel':k,'C':c}
运行结果:

执行交叉验证并计算模型的性能指标
代码:
#进行十折交叉验证
kf = KFold(n_splits=10)
kernels = ['rbf', 'linear', 'poly', 'sigmoid']
C_values = [0.01, 0.05, 0.1, 0.5, 1]
# 网格搜索
accuracies = {}
best_score =0
for k in kernels:
accuracies[k]= []
for c in C_values:
svm = SVC(kernel = k, C = c)
svm.fit(X_train,y_train)
accuracy_scores = cross_val_score(svm, X,y, cv=kf, scoring='accuracy')
r2_scores = cross_val_score(svm, X,y, cv=kf, scoring='r2')
mse_scores = cross_val_score(svm, X,y, cv=kf, scoring='neg_mean_squared_error')
mae_scores = cross_val_score(svm, X,y, cv=kf, scoring='neg_mean_absolute_error')
score = np.mean(accuracy_scores)
r2 = np.mean(r2_scores)
mse = np.mean(mse_scores)
mae = np.mean(mae_scores)
print(f"{k}-{c}-accuracy:{score} ,MSE: {mse}, MAE: {mae}, R-squared: {r2}")
accuracies[k].append(score)
if score > best_score:
best_score = score
best_parameters = {'kernel':k,'C':c}
运行结果:
2.2.多项式核下多项式维度参数degree的修改:
请分别记录多项式核函数下维度参数为1, 3, 5, 7, 9时的模型准确率。
代码:
degrees = [1,3,5,7,9]
C_values = [0.01, 0.05, 0.1, 0.5, 1]
# 网格搜索寻找最优参数模型
accuracies = {}
best_score =0
for d in degrees:
accuracies[d]= []
for c in C_values:
svm = SVC( C = c,degree = d)
svm.fit(X_train,y_train)
score = svm.score(X_test,y_test)
print(f"SVM-degree:{d}-C: {c}, accuracy: {score}")
accuracies[d].append(score)
if score > best_score:
best_score = score
best_parameters = {'C':c,'degree':d}
运行结果:

3.sklearn中SVC函数相关参数的修改
3.1.正则化系数C的修改
请分别记录四种核函数在正则化参数C分别为0.01, 0.05, 0.1, 0.5, 1时的模型准确率。
正则化参数C 0.01 0.05 0.1 0.5 1
rbf核 0.13055556 0.92222223 0.95 0.9805555 0.986111
linear核 0.9805555 0.9777777 0.97777777 0.97777777 0.97777777
poly核 0.9138888 0.9638888 0.975 0.9888889 0.99166667
sigmoid核 0.077778 0.45555 0.7888889 0.91111111, 0.9
3.2.多项式核下多项式维度参数degree的修改
请分别记录多项式核函数下维度参数为1, 3, 5, 7, 9时的模型准确率。
维度degree 1 3 5 7 9
C=0.01 0.130555 0.130555 0.130555 0.130555 0.130555
C=0.05 0.922222 0.922222 0.922222 0.922222 0.92222222
C=0.1 0.95 0.95 0.95 0.95 0.95
C=0.5 0.980555 0.98055 0.98055 0.98055 0.98055
4.绘制ROC曲线
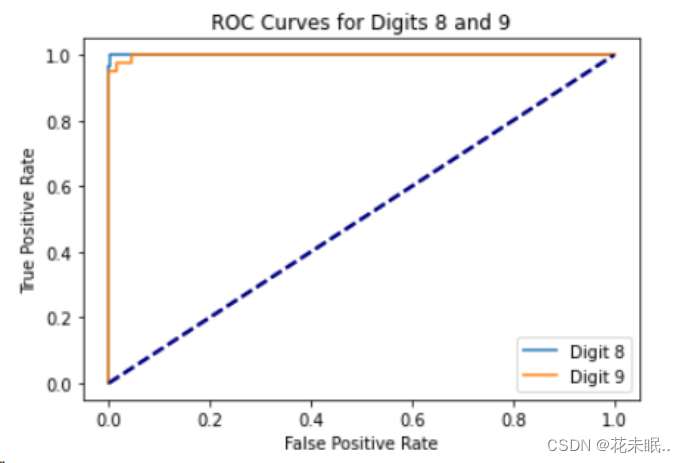
请按照给出的代码示例编写代码,绘制数字8和9对应的两条ROC曲线。
代码:
# 4. 绘制ROC曲线
def plot_roc_curve(model, X_test, y_test, label):
y_scores = model.decision_function(X_test)
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
plt.plot(fpr, tpr, label=label)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# 训练模型并绘制ROC曲线
model_8 = SVC(kernel='rbf', C=1) # 这里假设8对应的标签为1
model_9 = SVC(kernel='rbf', C=1) # 这里假设9对应的标签为0
model_8.fit(X_train, y_train == 8)
model_9.fit(X_train, y_train == 9)
plot_roc_curve(model_8, X_test, y_test == 8, 'Digit 8')
plot_roc_curve(model_9, X_test, y_test == 9, 'Digit 9')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curves for Digits 8 and 9')
plt.legend()
plt.show()
运行结果:
5.保存模型,使用加载的模型进行预测
代码:
model = SVC(kernel = 'poly', C = 1)
model.fit(X_train,y_train)
# 保存模型
import joblib
joblib.dump(model, 'svm_model.pkl')
# 加载模型并进行预测
loaded_model = joblib.load('svm_model.pkl')
prediction = loaded_model.predict(X_test) # 在测试集上进行预测
score = loaded_model.score(X_test,y_test)
print("true value:",y_test)
print("predict:",prediction)
print("accuracy:",score)
运行结果:

三、结果分析
-
不同核函数对模型精度的影响
影响因素: 在支持向量机(SVM)中,核函数的选择对模型的性能有显著影响。实验中尝试了四种核函数:rbf、linear、poly和sigmoid。
结果分析: 核函数的选择对模型的表现产生显著影响。rbf核在高正则化参数C下(接近1),得到了相对较高的准确率。而linear核在不同的正则化参数下表现相对稳定,但在较高的正则化参数下准确率有所下降。poly核在高阶数下得到了较高的准确率,在正则化参数C接近1时表现最佳。sigmoid核表现较差,在较高的正则化参数下也未能达到较高准确率。 -
正则化参数对模型精度的影响
影响因素: 正则化参数C控制着模型的复杂度,较小的C会导致模型较简单,可能出现欠拟合,而较大的C可能导致过拟合。
结果分析: 不同核函数下,随着正则化参数C的增加,模型的准确率普遍有提升的趋势。但在一定范围内,提高C值并不总能提高模型性能,可能导致过拟合问题。 -
多项式阶数对模型精度的影响
影响因素: 多项式核函数中的阶数degree会影响模型的拟合能力,高阶数可能导致模型复杂度过高,产生过拟合。
结果分析: 在多项式核函数中,随着阶数的增加,模型的准确率会先增加后趋于稳定。较低阶数下模型拟合能力不足,准确率较低,而过高阶数可能会导致过拟合。 -
ROC曲线
ROC曲线展示了针对不同类别(这里为数字8和9)的分类器在不同阈值下的性能。曲线越靠近左上角,代表模型性能越好。
实验展示了针对数字8和9的分类器的ROC曲线,可用于比较不同模型或不同参数下模型的性能。
四、实验总结
- 建模流程
实验中使用支持向量机(SVM)构建了手写数字识别模型,通过加载数据集、划分训练集和测试集、调参等步骤完成建模过程。 - 模型参数理解
了解了SVM中常用的参数,如核函数类型(rbf、linear、poly、sigmoid)、正则化参数C和多项式核函数的阶数degree等参数对模型性能的影响。 - 新掌握的函数
实验中使用了Sklearn中的多个函数和工具,如SVC、train_test_split、cross_val_score、roc_curve、joblib.dump和joblib.load等,加深了对这些函数的理解和应用。 - 结论
模型的性能受到多个因素的影响,包括核函数的选择、正则化参数的调节和多项式阶数的设定。优化模型性能需要综合考虑这些因素,并通过交叉验证等方法来评估模型的泛化能力。















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









