






1.爬取简单数据网站
运用昨天所学知识,我们将爬取该网站1960年世界各国GDP数据 -- 快易数据 (kylc.com)所展示的各国在1960年的GDP数据,如下图所示:
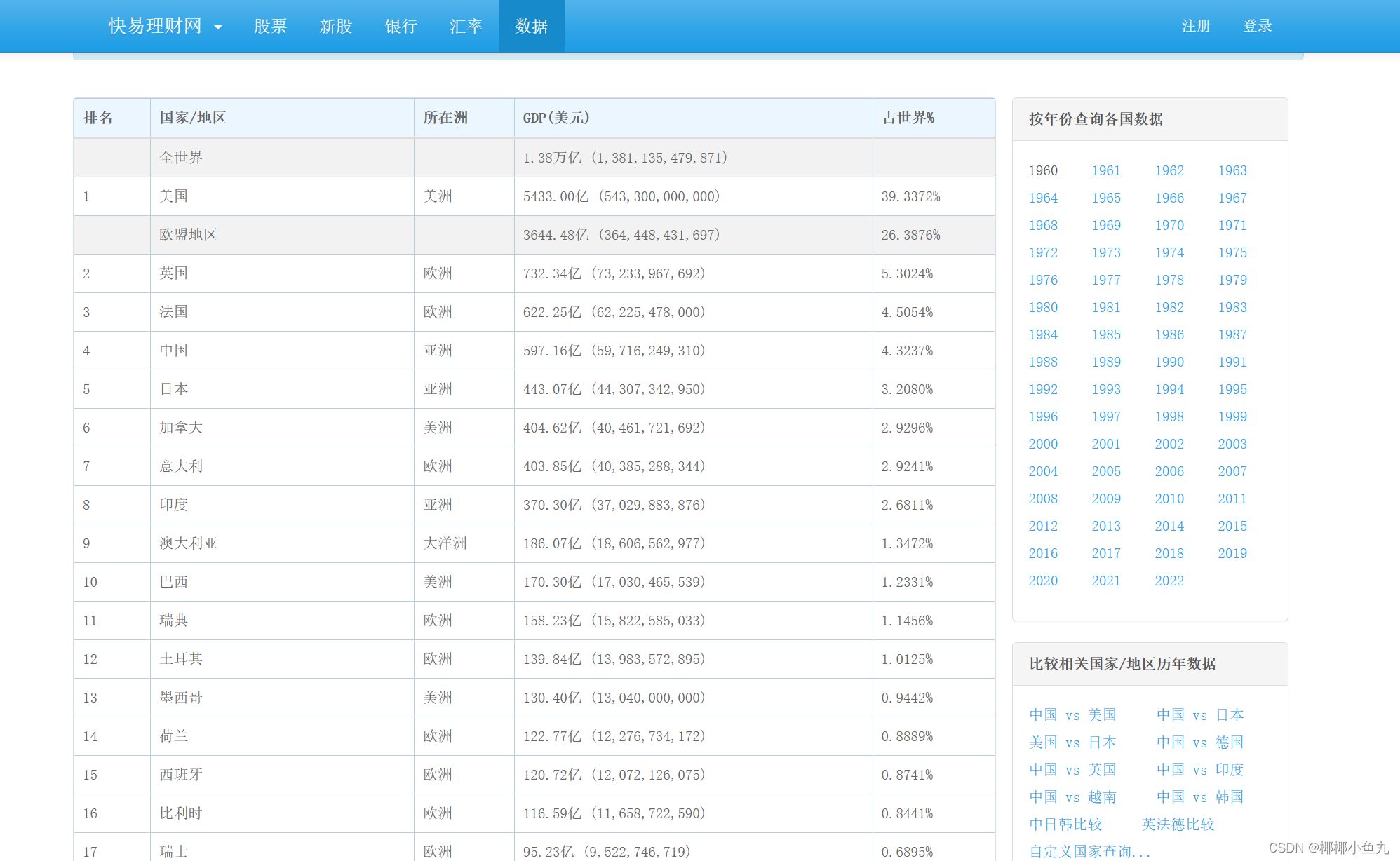
1.1首先导入所需的requests库和lxml模块,请求地址并模拟浏览器进行访问
import requests
from lxml import etree
url = "https://www.kylc.com/stats/global/yearly/g_gdp/1960.html"
headers = {
# 模拟浏览器访问
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
}
r = requests.get(url,headers=headers)
# 设置编码(跟网页源码保持一致)
r.encoding = "utf-8"
body = r.text
html = etree.HTML(body)1.2根据网站所展示的信息,我们依次按表格的字段进行信息的爬取,首先是爬取排名
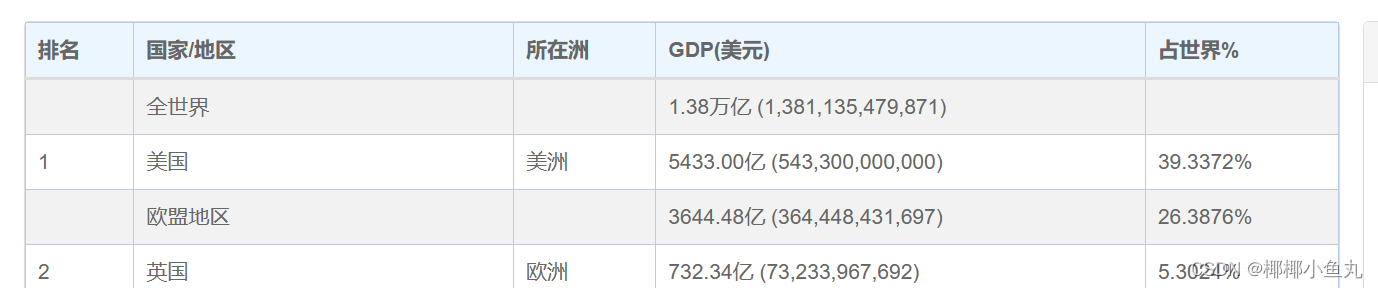
rank = html.xpath("//table/tbody/tr/td[1]/text()")由于该网页中有两处行之间有空白间隔,如下图所示:


所以需对空白行进行删除
new_rank = []
for x in range(0, len(rank)):
if (x == 39 or x == 40 or x == 81 or x == 82):
continue
new_rank.append(rank[x])1.3同理爬取国家代码如下所示:
country = html.xpath("//table/tbody/tr/td[2]/text()")
new_country = []
for x in range(0, len(country)):
if (x == 0 or x == 2):
continue
new_country.append(country[x])
其中第2行和第4行非国家信息,所以需要进行删除
1.4同理爬取GDP信息代码如下:
gdp = html.xpath("//table/tbody/tr/td[3]/text()")
new_gdp = []
for x in range(0, len(gdp)):
if (x == 0 or x == 2):
continue
new_gdp.append(gdp[x])
1.5同理爬取各国GDP占比信息代码如下:
rate = html.xpath("//table/tbody/tr/td[5]/text()")
new_rate = []
for x in range(0, len(rate)):
if (x == 0 or x == 2):
continue
new_rate.append(rate[x])
1.6如需进行多个年份的信息爬取,即多页爬取,则需定义函数和建立循环来实现,执行代码如下所示:
def gdp(url, headers):
r = requests.get(url, headers=headers)
r.encoding = "utf-8"
body = r.text
html = etree.HTML(body)
for x in range(1960, 1965):
url = "https://www.kylc.com/stats/global/yearly/g gdp/" + str(x) + ".html'
gdp(url, headers)
time.sleep(2)
2.对唯品会网站的商品信息爬取(部分内容)
2.1首先要在商品信息页面的网站通过浏览器-检查找出真正的网页网址
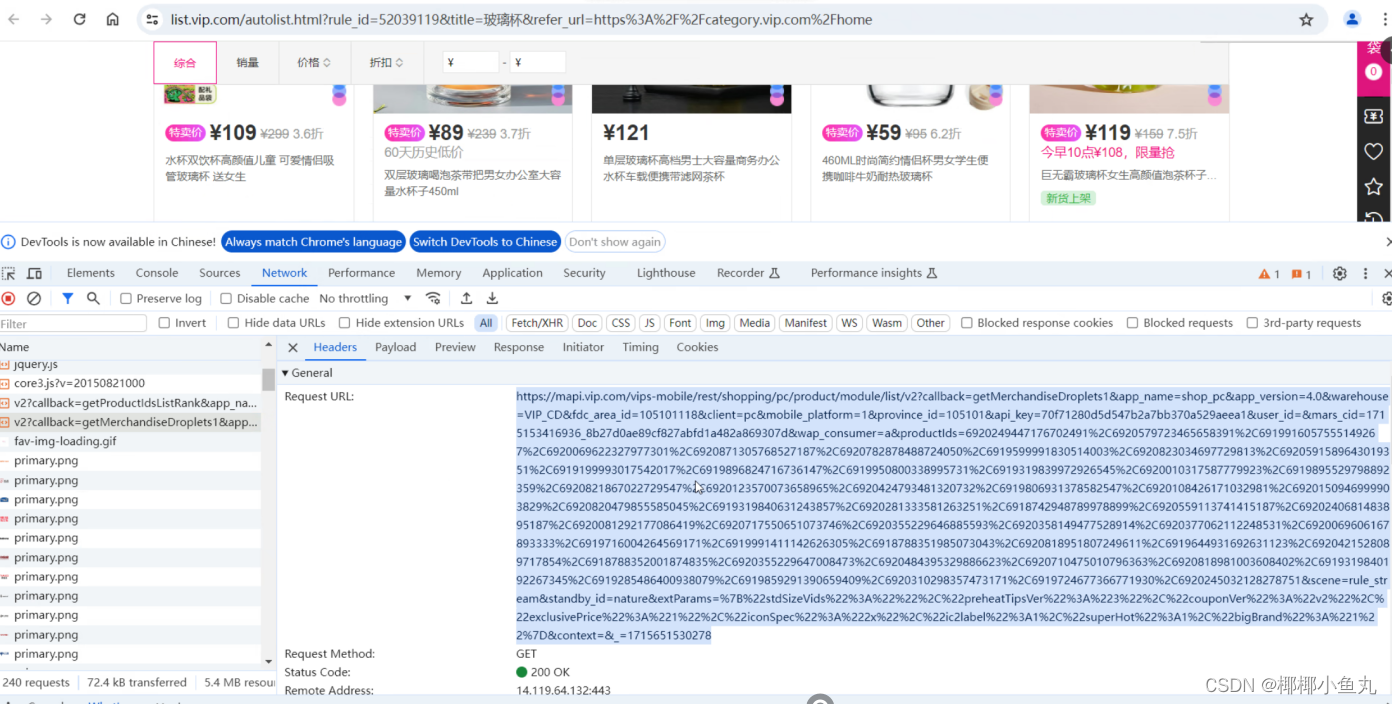
然后写入代码:
import requests
from lxml import etree
# 请求地址
url = https:./mapi.vip.comips-mobile/restshoppina/oc productmodulelisth2?calback=aetMerchandiseDroplets1&app name=shop pc&apo version=4.0&warehouseVIP CD&fdc area id=105101118&client=pc&mobile platform=1&provinceid=105101&api key=70f71280d5d547b2a7bb370a529aeea1&user id=&mars cid=1715153416936 8b27d0ae89cf827abfd1a482a869307d&wap consumer-a&produclds-692024947176702491%2C6920579723465658391%2C691991605755514926T2C6920696223279773019%2C6920871305768527187%2C6920782878488724050%2C691959991830514003%2C69208230346977298139%2C6920591589643019351%2C6919199993017542017%2C6919896824716736147%2C6919950800338995731%2C6919319839972926545%2C69200103175879923%2C6919895529798892359%2C6920821867022729547%1692012357073658965%2C6920424793481320732%2C6919806931378582547%2C6920108426171032981%2C69201509469993829%2C6920820479855585045%2C6919319840631243857%2C692028133581263251%26918742948789978899%2C6920559113741415187%2C69202406814838893333%2C69197160042645699717854%62C6918788352001874835%2C6920355229647008492267345%2C6919285486400938079%2C6919859291390659am&standbvid=nature&extParams=978966206919644931692631123%62C6920421528081818981003608402962C6919319840C6920245032128278751&scene=rulest2counonVer962296349622v29622%2C%22excusvePrice%22%3A%221%22%2C%2iconspec%22%63A9%222x9%22%2C%22ic2label9%2%3A1%62C9%22supeHot9%22%63A1%2C%622biaBrand9622%3A%21%22%7D&context=&=1715651530278"
# 构建headers
headers = {
# 模拟浏览器访问
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
# 发送请求(开始爬取)
r = requests.get(url,headers=headers)
# 设置编码(跟网页源码保持一致)
r.encoding = "gbk"
body = r.text2.2取出所获取内容的字典
print(body)
info = json.loads(body[24:-1])
print(info)
其运行结果如下图所示:

2.3在商品界面第一页时如下图所示,红框为时间戳

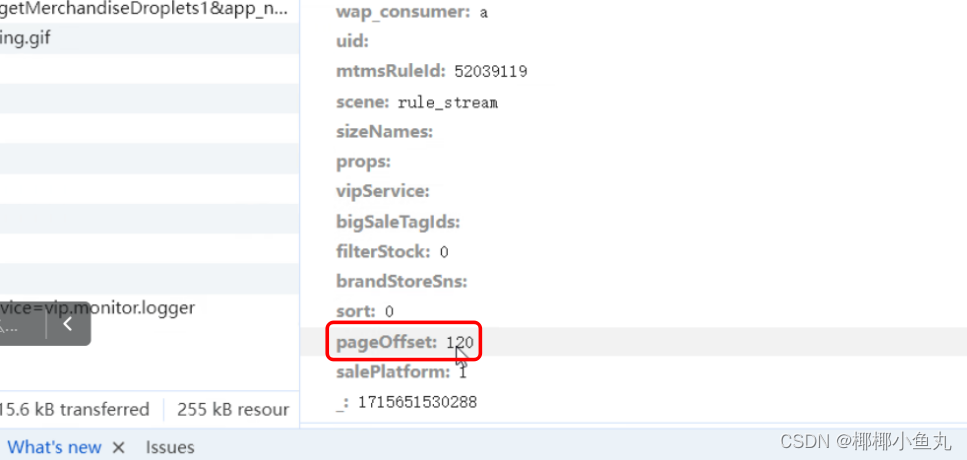
2.4在商品界面第二页时如下图所示,pageoffset对应每一页的商品陈列数















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









