






一、python的基础知识复习
-
数据类型:字符串、列表、字典、元祖、 boolean、num
-
字符串操作:切分、截取、替换
-
列表操作:循环、添加、创建、取值
-
字典操作:创建、取值
-
模块:一个py文件就是一个模块
-
导入:import / import from
-
函数:def 方法名(参数列表):函数体
-
类的声明:class Student:
-
类的方法的声明:def study(self): (方法)
二、爬虫基础
1.导入函数库和读取网址
from lxml import etree
url="https://www.sohu.com/a/334319674_682598"
r = requests.get(url)
body = r.text2.将1.txt文件内容读取出来
f = open("images/1.txt", "r", encoding="utf-8")
body1 = f.read()
f.close()
3.转化为html文档结构
html = etree.HTML(body1)4.解析出title标签的文本值
t = html.xpath("//title/text()")
#xpath解析------》爬取网站的返回值是html结构的字符串5.解析出a标签的文本值
a = html.xpath("//div[1]/a[1]/text()")
a = html.xpath("//div[@class='one']/a[1]/text()")
h = html.xpath("//div[@class='one']/a[1]/@href")#从HTML内容中提取所有class属性值为'one'的div元素中第一个a标签的href属性值三、单个图片爬取
1.导入库并请求地址
import requests
from lxml import etree
url = "https://pic.netbian.com/"2.构建headers,并模拟浏览器访问
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}其中“user-agent”由浏览器-检查-网络-全部-网络-标头查看,如下图所示

3.发送请求(开始爬取)
r = requests.get(url,headers=headers)4.设置编码(跟网页源码保持一致)
r.encoding = "gbk"5.获取爬取的内容(text一般用于返回的字符串格式的html网页结构;content:用于文件爬取返回的是二进制;json():返回的是json格式的数据)
body = r.text6.获取第一个img标签的_src属性的第一个图片
html = etree.HTML(body)
img_urls = html.xpath("//img[1]/@_src")
img_url = img_urls[0]
7.获取该图的二进制内容并写入文件,释放资源
i = requests.get("https://pic.netbian.com"+img_url,headers=headers)
img = i.content
f1 = open("images/1.jpg", "wb")
f1.write(img)
f1.close()8.完整代码如下所示:
import requests
from lxml import etree
url = "https://pic.netbian.com/"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
r = requests.get(url,headers=headers)
r.encoding = "gbk"
body = r.text
print(body)
html = etree.HTML(body)
img_urls = html.xpath("//img[1]/@_src")
# /d/file/2021/04/30/221552RfgA8.jpg
img_url = img_urls[0]
i = requests.get("https://pic.netbian.com"+img_url,headers=headers)
img = i.content
f1 = open("images/1.jpg", "wb")
f1.write(img)
f1.close()
其运行结果如下图所示:
四、批量图片爬取
与单个图片爬取不同的是,批量图片的获取方式要运用循环的语句进行爬取
1.确定爬取的图片范围
img_urls = html.xpath("//ul[@class='clearfix']/li/a/img/@src")2.获取所有图片的url列表,再转为二进制内容,依次写入文件
for x in range(0,len(img_urls)):
img_url = "https://pic.netbian.com/"+img_urls[x]
i = requests.get(img_url, headers=headers)
img = i.content
f = open(str(x)+".jpg", "wb")
f.write(img)
f.close()3.完整代码如下所示:
import requests
from lxml import etree
url="https://pic.netbian.com/index_2.html"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
r = requests.get(url,headers=headers)
r.encoding = "gbk"
body = r.text
print(body)
html = etree.HTML(body)
img_urls = html.xpath("//ul[@class='clearfix']/li/a/img/@src")
print(img_urls)
for x in range(0,len(img_urls)):
img_url = "https://pic.netbian.com/"+img_urls[x]
i = requests.get(img_url, headers=headers)
img = i.content
f = open(str(x)+".jpg", "wb")
f.write(img)
f.close()
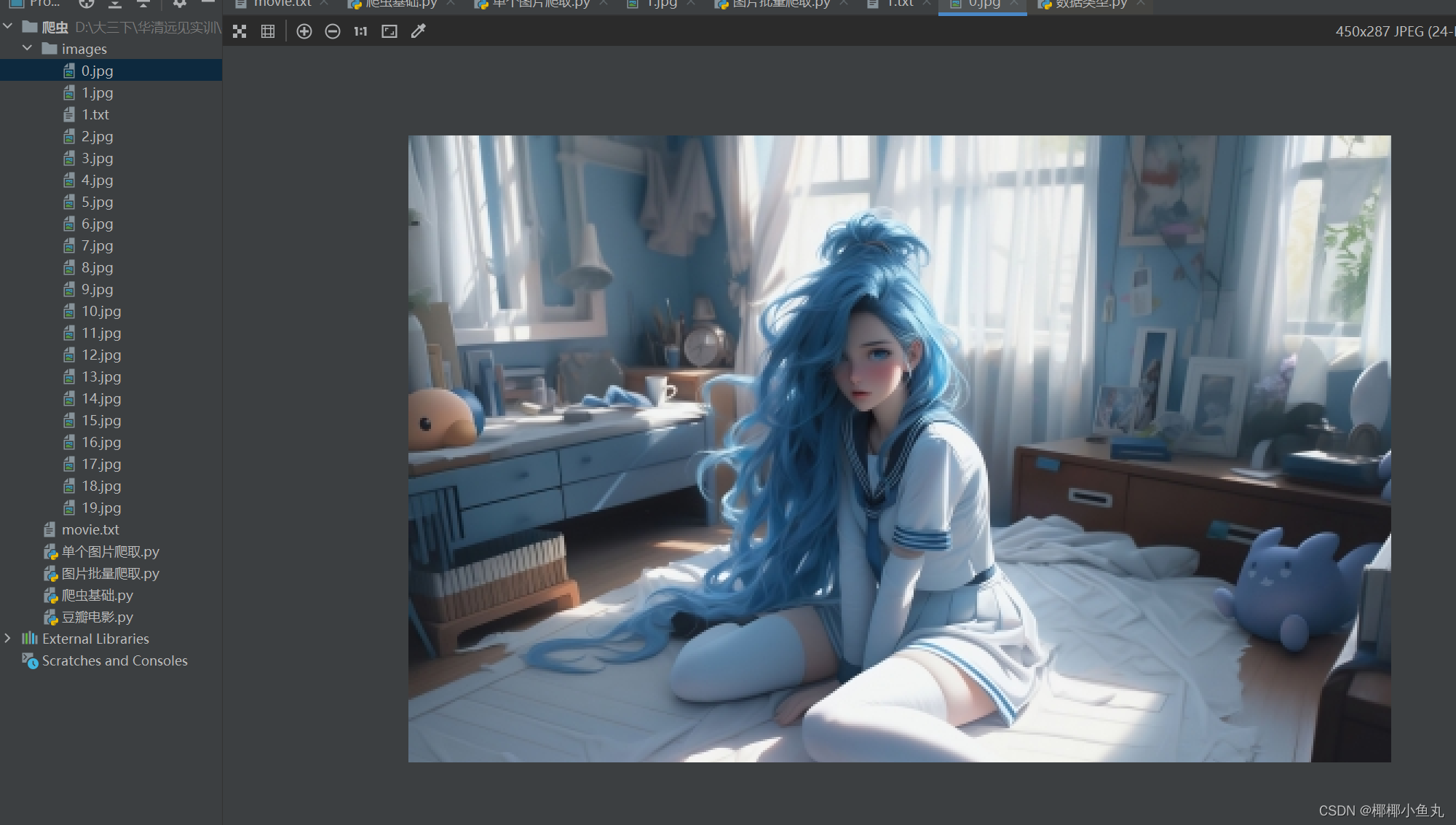
其运行结果如下图所示
五、豆瓣电影网的爬取
1.只爬取一部电影示例:
def single_movie(url,headers): #定义一个函数 single_movie,用于获取一部电影的信息
r = requests.get(url, headers=headers)
ds = r.json() #将响应内容解析为JSON格式
print(ds["items"][0]) #打印第一个电影的信息
movie_info = ds["items"][0] #获取第一个电影的信息2.爬取一页电影示例:
def single_page(index,url,headers):
r = requests.get(url, headers=headers)
ds = r.json()
f = open("movie.txt", "a", encoding="utf-8")
#打开一个文件句柄,用于写入电影信息,以追加模式写入,指定编码为 utf-8。
movies_ls = ds["items"]
if(index==0): #如果是第一页数据,删除列表中的第一个元素
del movies_ls[0]
for movie_info in movies_ls:
#获取电影的名字、上映年份、评分、星级数和评论人数
m_name = movie_info["title"]
m_year = movie_info["year"]
m_score = movie_info["rating"]["value"]
m_star_num = movie_info["rating"]["star_count"]
m_count = movie_info["rating"]["count"]
movieInfo = m_name + " " + m_year + " " + str(m_score) + " " + str(m_star_num) + " " + str(m_count)
#连接每部电影爬取出来的信息
f.write(movieInfo)
f.write("\n")
f.close()3.爬取300页电影示例:
def movies(headers):
#使用循环遍历页数,从 0 开始,每次增加 20,总共遍历 300 页
for x in range(0,300,20):
url="https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start="+str(x)+"&count=20&selected_categories=%7B%22%E7%B1%BB%E5%9E%8B%22:%22%E5%96%9C%E5%89%A7%22%7D&uncollect=false&tags=%E5%96%9C%E5%89%A7"
single_page(x,url,headers)
#在每次爬取完一页后,暂停 1 秒,防止爬取过快被网站封禁或被认定为异常访问
time.sleep(1)
#判断是否为主程序,如果是,则执行下面的代码块
if __name__ == '__main__':
# single_movie(url,headers)
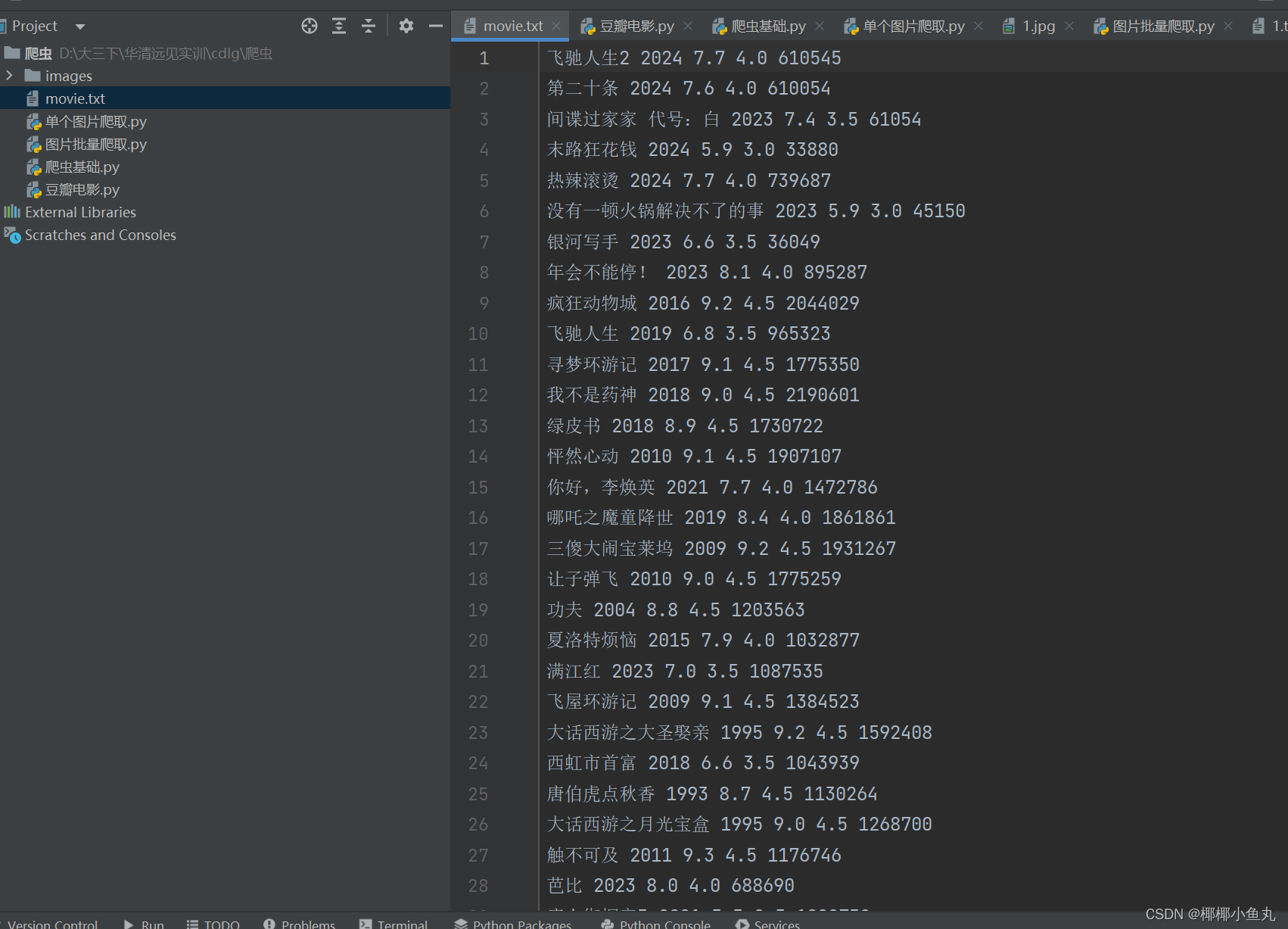
movies(headers)其运行结果如下图所示:















 6300
6300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









