







目录
前言
上一篇文章中,我们介绍了许多有关于字符、字符串和内存操作的函数,现在我们就来模拟实现一下其中的部分函数,更有助于我们对这些函数的认识和使用过程。
一、模拟实现 strlen
模拟实现 strlen 还是比较容易的,并且有多种设计的思路。
第一种,是最容易想到的:定义一个计数变量统计“ \0 ”之前的字符个数即可。
int my_strlen(const char* str)
{
int count = 0;
while (*str)
{
count++;
str++;
}
return count;
} 第二种,是采用递归的形式:如果指针解引用之后的字符不是“ \0 ”,就说明该字符串的长度至少是1,所以整个字符串的长度就可以看作是 1 加上该指针之后的字符串的长度,然后指针 +1 之后继续递归下去;如果是“ \0 ”,就说明该字符串长度是 0 ,直接返回 0 即可。
int my_strlen(const char* str)
{
if (*str == '\0')
{
return 0;
}
else
{
return my_strlen(str + 1) + 1;
}
}第三种,是利用指针 - 指针的结果是中间元素的个数的绝对值:先通过循环找到该字符串“ \0 ”处的地址,然后将其与字符串的起始地址相减即为中间字符的个数。
int my_strlen(char* s)
{
char* p = s;
while (*p != '\0')
{
p++;
}
return p - s;
}二、模拟实现 strcpy
上面的 strlen 实现,我们写的也比较粗略,如果要注重规范的写法的话,需要注意 const 和 assert 的使用。使用 const 修饰无需修改的指针参数,来避免误操作而被修改,使用 assert 断言避免出现接收了空指针。(assert 使用时需要包含头文件。 <assert.h> )
strcpy 的模拟方法:将源字符串的指针解引用之后,赋值给目标字符串的指针解引用,然后两个指针都 +1 ,继续赋值,直至全部拷贝到目标空间,然后返回目标空间的起始地址。
char* my_strcpy(char* dest, const char* src)
{
char* ret = dest;
assert(dest && src);
while ((*dest++ = *src++))
{
;
}
return ret;
}如上面的代码,先创建一个 ret 变量保存目标空间的起始地址,因为后续拷贝过程中,dest 的地址就不再是字符串的起始地址,已经发生改变了。所以要先用一个变量保存起来,可以在最后作为返回值返回。
while 部分这样写是一种极为简洁的写法,这种写法的作用是:先将源指针解引用之后,赋值给目标指针的解引用,然后左右两个指针都自增,即为指针指向的内存空间向后走,指向下一个字符,然后继续赋值,直至 src 指向“ \0 ”的地址时,此时解引用赋值给 dest 解引用,此时括号内整个表达式的值为 0 ,循环停止,拷贝完成。
三、模拟实现 strcmp
strcmp 的实现也是比较简单,只需将指针解引用后的对应位置的字符进行比较即可,如果有一组不同即可比较出大小。为了简便,我们采用 VS 的设计,大于返回 1 ,小于返回 -1 。如果直至源指针指向“ \0 ”时,都没有比出大小,那么就是两个字符串完全相同,返回 0 。
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);
while (*str1 == *str2)
{
if (*str1 == '\0')
{
return 0;
}
str1++;
str2++;
}
if (*str1 > *str2)
{
return 1;
}
else
{
return -1;
}
}如上面代码中,我们循环条件设置为两个指针解引用后的内容是否相等,如果不等即可判断大小然后返回数值;如果相等则判断源指针是否此时已经到达“ \0 ”处,如果不是,说明还需进行比较,那么就两个指针 +1 之后继续比较;如果已经源指针已经到达“ \0 ”处,则说明比较过程结束了,而且两个字符串完全相等,则返回 0 。
四、模拟实现 strcat
strcat 为追加字符串,这个函数的实现也不难。由于追加源字符串是在目标字符串的末尾进行追加,所以我们首先要找到目标字符串的末尾,然后再进行追加。追加过程就如同 strcpy 一样,直接将源字符串拷贝到目标字符串即可。
char* my_strcat(char* str1, char* str2)
{
assert(str1 && str2);
char* ret = str1;
while (*str1)
{
str1++;
}
while (*str1++ = *str2++)
{
;
}
return ret;
}
五、模拟实现 strstr
strstr 这个函数是判断一个字符串是否是另一个字符串的子串。这个函数的设计思路也比较难一些,所以我们需要先理顺整体的思路然后再进行代码的书写。
首先,先代入一种比较简单的情况:
第一个字符串是“ abcdef ”,第二个字符串是“ bcd ”,判断第二个字符串是不是第一个字符串的子串。那么我们首先先匹配第二个字符串中的首字符,匹配上了才能进行后续的匹配。匹配之后,发现第一个字符串的第二个字符匹配上了,那么就继续匹配。然后就发现后续也都匹配上了,那么就证明了第二个字符串确实是第二个字符串的子串,那么就返回第二个字符串在第一个字符串中第一次出现的位置的地址。
然后,我们再来看一种比较复杂的情况:
第一个字符串是“ abbbcde ”,第二个字符串是“ bbc ”,然后同样进行匹配。我们发现第一个字符串的第二个字符匹配上了,那么就继续进行第二个字符串的后续字符的匹配。但是我们会发现第一个字符串后面的一个字符并没有匹配上,所以从第一个字符串中的第二个字符开始匹配的话,并没有找到“ bbc ”,所以应该跳过这个字符了,因为已经匹配不上了,应该从第一个字符串的第三个字符开始匹配了。所以我们会发现,我们需要一个另外的指针记录一下第一个字符串一开始匹配字符的位置,方便后续匹配不上之后返回寻找下一个开始匹配的字符。接下来就是从第一个字符串中的第三个字符开始匹配,后续匹配上了,就说明了第三个字符的地址就是第一个字符串中“ bbc ”第一次出现(也是唯一一次)出现的位置的地址。
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
if (*str2 == '\0')
{
return (char*)str1;
}
const char* s1 = NULL;
const char* s2 = NULL;
const char* cp = str1;
while (*cp)
{
s1 = cp;
s2 = str2;
while (*s1 != '\0' && *s2 != '\0' && *s1 == *s2)
{
s1++;
s2++;
}
if (*s2 == '\0')
{
return (char*)cp;
}
if (*s1 == '\0')
{
break;
}
cp++;
}
return NULL;
}例如上述代码,我们使用 s1 和 s2 分别作为 str1 和 str2 进行字符匹配的指针,进行后续自增操作后进行匹配,并再用一个指针 cp 记录一下 str1 每次进行匹配的字符的位置的地址,如若该字符刚好匹配上了第二个字符的首字符(那么就可能后续字符完全匹配上),但是后续字符匹配不上了,再通过 cp++ 跳过该字符,然后令 s1 = cp ,进行下一个字符的匹配。
代码中首先还写到了一种特殊情况,如果 str2 是“ \0 ”,那么就直接返回 str1 的地址,因为此时 str2 必定是 str1 的子串。
外层循环的循环条件为 *cp 解引用的内容,即为 str1 中的每个字符都作为起始位置进行判断是否后续字符能够与 str2 中剩余的字符匹配上,遍历整个字符串,直至 cp 到达“ \0 ”处。
内层循环的循环条件除了判断 s1 和 s2 解引用后的内容是否相同之外,还需判断此时 s1 和 s2 是否已经到达了“ \0 ”,如果此时 s2 已经到达了“ \0 ”,那么就说明此时 str2 是 str1 的子串,如果是 s1 已经到达了“ \0 ”但是 s2 还未到达“ \0 ”,那就说明 str2 已经不可能是 str1 的子串,直接跳出循环。
如果直至 cp 到达“ \0 ”处时,还没有能够在 str1 中找到 str2 ,那么就返回一个空指针。
六、模拟实现 memcpy
memcpy 是进行对一块内存空间的内容的拷贝,无论是什么类型的数据都要能进行拷贝,那么这时候的参数部分的指针就要设置为 void* ,因为 void* 是无具体指向类型的指针变量,可以接收任意类型的指针变量。由于我们无法确认该函数的使用者想要拷贝什么类型的数据,所以只能用这个能够接收任意类型数据的指针。同样地,该函数的返回值是目标空间的指针,由于我们仍旧无法确认目标空间数据的类型,所以我们还是使用 void* 作为返回值。
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
此处由于 dest 和 src 都为 void* ,不能直接解引用后赋值,所以我们需要将它们都先强制转化为字符类型。这样做的原因是:由于我们无法知道传递过来的参数是什么类型的数据,因为不同类型的数据,个数相同的情况下所占内存空间不同,如果是 int ,每个数据占 4 个字节,如果是 short 则每个数据占 2 个字节,如果是结构体类型,则字节数不统一。为了解决这些复杂情况,我们就需要使用者根据自己想要传递的数据个数,统计需要拷贝的字节数,然后作为参数传递给函数。(我们作为函数设计者无法知道使用者想要传递什么样的数据,但是使用者自己肯定知道)然后我们将两个指针转换为 char* 类型,因为 char 只占一个字节,我们就可以将内存中的数据逐一字节地进行拷贝,确保万无一失地将所有数据都完整拷贝到目标空间中。因此我们也可以看到上面代码中的循环条件也是代表需要拷贝的字节数,参数 num 。num 进行判断是否为 0 之后,然后再进行自减,这样循环 num 次之后,即为 num 个字节都已经拷贝到目标空间中了,循环停止。
由于 dest 和 src 都为 void* ,所以也不能够直接进行自增操作(在 VS 环境下,实际为不能够后置自增,但是前置自增仍可以,其他平台下不确定)所以我们采用上面代码中的做法:先将 dest (src)转换为 char* 然后 +1 再赋值给 dest (src)。这种做法在任何平台下都是可行的。
七、模拟实现 memmove
memmove 的实现就比较困难一点了,我们同样先理顺了思路之后再开始动手。
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr + 2, arr, 20);
return 0;
}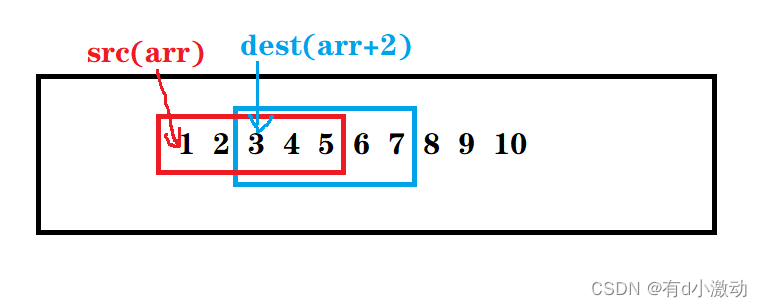
我们把第一个参数设为 dest ,表示目标空间; 第二个为 src ,表示源空间。
上面代码中就相当于(1,2,3,4,5)拷贝到(3,4,5,6,7)的位置上,结果就相当于变成了(1,2,1,2,3,4,5,8,9,10),我们可以先用 memmove 验证一下结果。
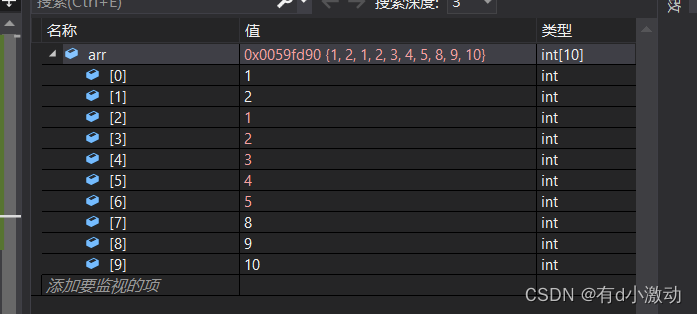
通过调试中的监视窗口可以看到确实如此。接下来我们就来整理一下代码的书写思路:
如果按照一般情况,我们肯定是想着把一个个数字进行拷贝:先把 1 拷贝到 3 的位置上,然后 3 的位置就变成了 1 ,然后再陆续拷贝(2,3,4,5)到(4,5,6,7)的位置即可。
但是如果按照这样的思路的时候,我们就会发现:当我们想要把 3 拷贝 原先为 5 的位置上时,此时原先为 3 的位置上的 3 已经被前面第一次拷贝之后了的 1 覆盖掉了,这样就变成了原本为 3 的位置上变成了 1 ,如果再进行拷贝就是将 1 拷贝到 原本为 5 的位置上了。后面拷贝也会出现的这样的情况。所以这种做法不可取。
上面是把数据从前往后进行拷贝,既然此路不通,我们就来尝试反着来,将数据从后往前进行拷贝:
先将 5 拷贝到 7 的位置上,然后将 4 拷贝到 6 的位置上,再将 3 拷贝到 5 的位置上……这样最终会发现并不会出现上面的情况了。然后我们再总结一下就会发现,即使 dest 为 arr+3、arr+4 ,这样做都是可取的,但是使用上面的方法就不一定了。而这些情况都有一个共同的特点:目标空间地址大于源空间地址(上图中左边为低地址,右边为高地址),即 dest > src 。
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr, arr+2, 20);
return 0;
}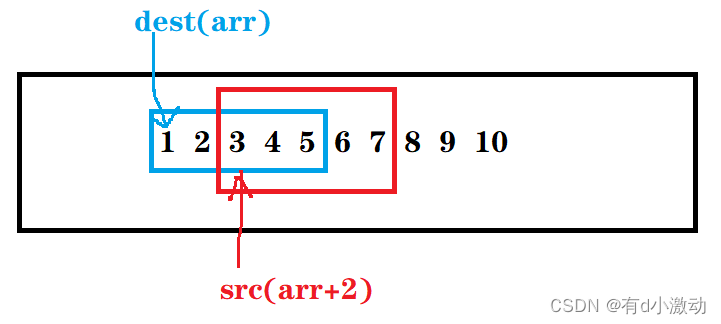
如果是上面这种情况下的话,相当于想要把(3,4,5,6,7)拷贝到(1,2,3,4,5),相当于拷贝后是(3,4,5,6,7,6,7,8,9,10)。如果还是采用从后向前拷贝就反倒行不通了。设想一下,如果采用上面的做法:先把 7 拷贝到 5 的位置上,再把 6 拷贝到 4 的位置上,接着需要把 5 拷贝到 3 的位置上,此时会发现原先为 5 的位置上的 5 已经被前面拷贝过来的 7 所覆盖了,后续的拷贝也是出现这样的情况,所以此时就又需要从前往后拷贝,这样才不会出现上述的情况。即便此时的 src 换成了 arr+3、arr+4 也无妨,依旧是从前往后拷贝,这些情况也有一个共同点:目标空间地址小于源空间地址,即:dest < src 。
总结上面两种情况,我们会发现似乎这两种情况是有一条分隔线分开的,那就是两块空间刚开始重叠之处,如下图:
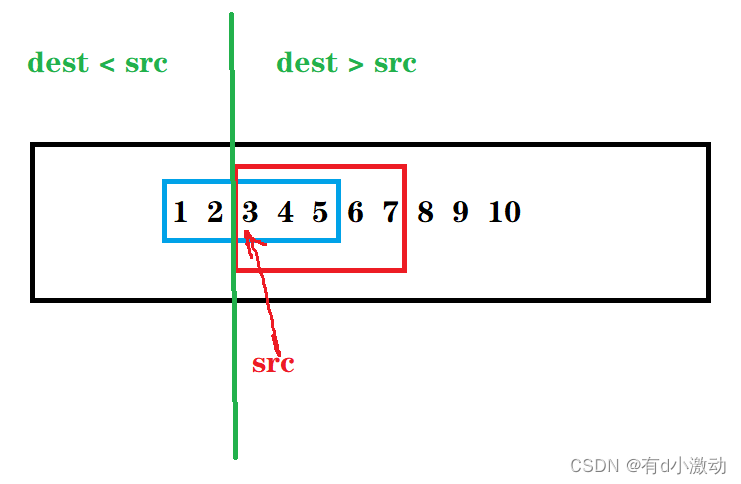
如果假定 src 不变,如果 dest 落在 src 的左侧,则为 dest < src ,需要从前向后拷贝;如果 dest 落在 src 的右侧,则为 dest > src ,需要从后向前拷贝。如果两块内存空间没有重叠部分或者完全相同,那么两种方法都可以。所以我们可以将分割线前面的部分用从前往后的拷贝方法,分隔线之后的部分使用从后往前的拷贝方法,这样就可以完美实现 memmove 的功能了。
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
//从后向前拷贝
if (dest > src)
{
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
}
//从前往后拷贝
else
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
return ret;
}上面代码中,从前往后拷贝部分实际就是上面实现 memcpy 的方法。
而从后往前拷贝,需要我们先找到最后一个字符的地址,然后再逐一字符向前跳。而 dest 和 src 的地址就是这两个字符串首字符的地址,再加上 num 就正好是它们最后一个字符的地址。此部分中,循环的迭代条件直接由 num 自减控制即可,不必再由 dest 和 src 进行操作而控制。
总结
这些函数的实现过程但是利用基础知识就可以解决的,难点在于我们是否理解了这些函数的作用、运行时的整个过程以及细节处等多个需要注意的地方,如果真正动手去实现这些函数,创造出属于我们自己的函数,定会大大加深我们对这些函数的印象,使用起来也更是得心应手了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









