






一、数据集及程序功能要求
数据集stock-daily,包含A股近4000只股票的最近30个交易日的日数据,根据此数据实现股票风险监测统计:统计和输出股票代码和风险值,计算出股票下行指数
数据来源:https://www.joinquant.com/help/api/help?name=JQData
风险值统计方法:
- 忽略股票停牌当日数据
- 忽略N/A数据行
- 股价下行指数,(∑▒〖(收盘价-开盘价) / (收盘价 - 最低价+1)〗) / 有效数据总天数
二、MapReduce环境配置(以下配置仅供参考!请根据实际情况进行。如果MapReduce已经完成过以下类似的配置或者曾经成功执行过jar包,请忽略该步骤)
进入hadoop安装目录下的etc/hadoop目录
cd /home/hadoop/hadoop-3.1.2/etc/hadoop
1、在mapred-site.xml配置文件中增加两个配置
vi mapred-site.xml
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
2、在yarn-site.xml配置文件中增加container本地日志查看配置
!!注意:下面配置中的“hadoop安装目录”要替换为自己实际的hadoop安装目录,比如/home/hadoop/hadoop-3.1.2
vi yarn-site.xml
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>hadoop安装目录/logs/userlogs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>108000</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value> <!--此项小于1536,mapreduce程序会报错-->
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value> <!--防止一级调度器请求资源量过大-->
</property>
设置虚拟内存与内存的倍率,防止VM不足Container被kill
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
三、MapReduce 程序设计
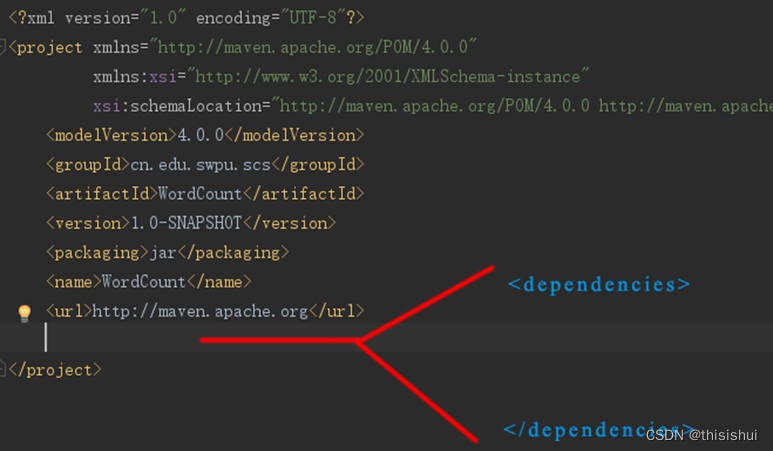
1、在IDEA中新建Maven项目,并修改pom.xml文件,在pom.xml文件中的根节点中,添加一个子节点,如下图:
2、查询maven组件配置https://mvnrepository.com/
需要查询的组件(自己判断合适的版本,以自己安装的hadoop版本为主,以下和hadoop有关的依赖以hadoop-3.1.2版本为例):
junit
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
log4j
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
hadoop-hdfs
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.2</version>
<scope>test</scope>
</dependency>
hadoop-common
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.2</version>
</dependency>
hadoop-mapreduce-client-core
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.2</version>
</dependency>
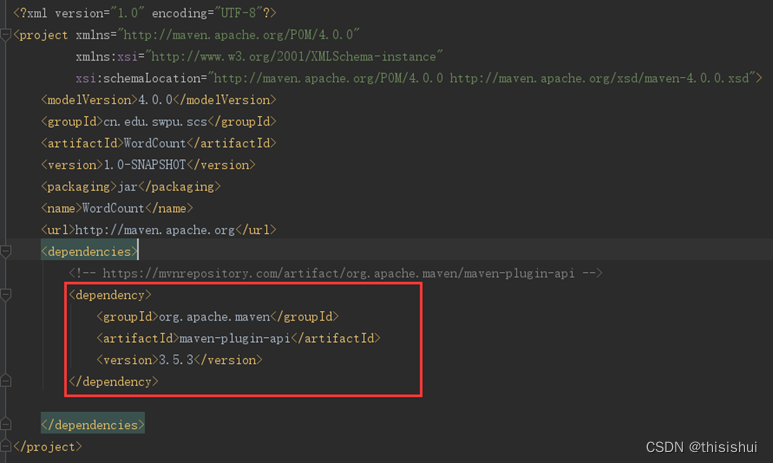
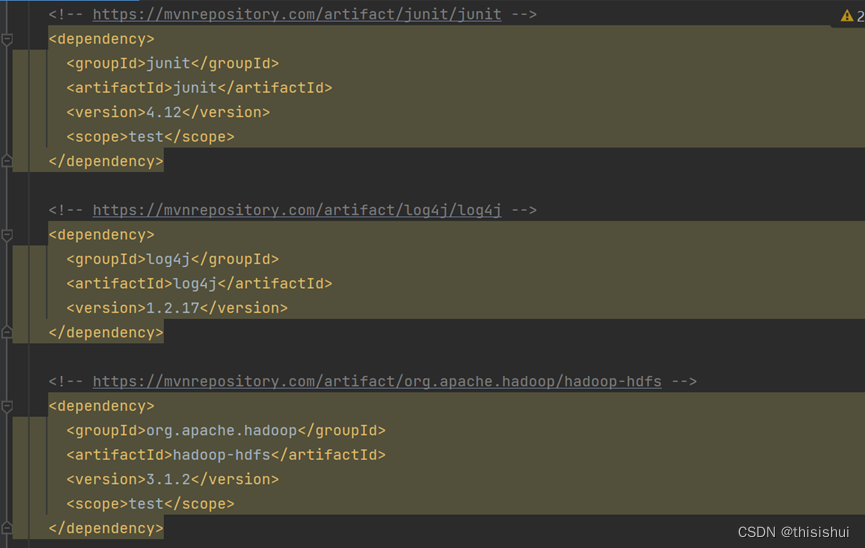
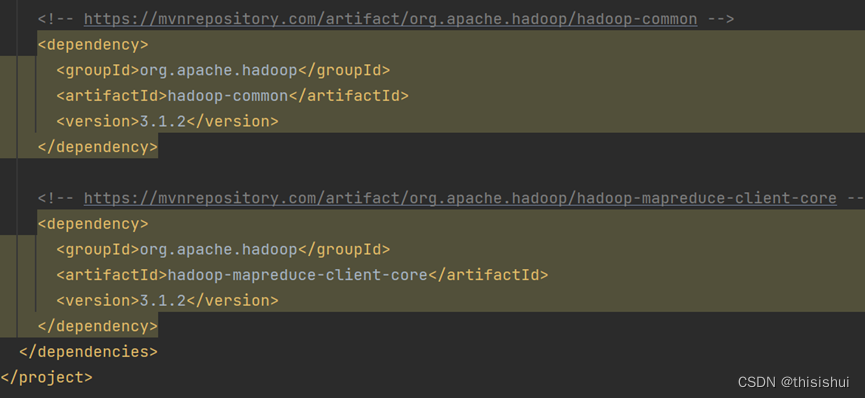
将所有查询到的组件的XML插入到节点中去,如下图:
pom.xml修改完毕后,点击右下角的"Import Changes"即可将MAVEN库中的JAR包下载到项目中,默认情况下,会从MAVEN官网下载,速度比较慢;可事先配置MAVEN淘宝镜像库,基本方法就是在IntelliJ IDEA的安装目录下,找到MAVEN插件的安装目录,修改其配置文件,将镜像设置添加到配置文件中即可
4、根据题目要求的逻辑实现代码
基本代码逻辑:
Map
首先按行通过”\t”分割,在判断不是空置之后提取收盘价、开盘价、最低价,通过(收盘价-开盘价) / (收盘价 - 最低价+1)的公式计算出当日股票下行指数,以股票编号为键,当日股票下行指数为值写入context
输入:一行数据(一只股票的日数据)
处理:使用 \t 将字符串split成数组,提取需要计算的值,并转为浮点数
输出:<股票代码, 股票当日下行指数>
遇到无效数据不输出(停牌股票或有N/A数据无法提取为浮点数)
Map类
package cn.edu.swpu.scs;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Map extends Mapper<Object, Text, Text, FloatWritable> {
private FloatWritable index = new FloatWritable();
private Text code = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] infos = line.split("\t");
if ((infos[12].equals("False")) && (infos[2].equals("N/A") == false)) {
float open = Float.valueOf(infos[2]);
float close = Float.valueOf(infos[3]);
float low = Float.valueOf(infos[5]);
index.set((close-open) / (close - low +1));
code.set(infos[0]);
context.write(code, index);
}
}
}
Reduce:
Reduce传入的键是股票编号,值是每个编号每天的当日股票下行指数。通过(∑▒〖(收盘价-开盘价) / (收盘价 - 最低价+1)〗) / 有效数据总天数,可以计算出每个编号的股票下行指数
输入:<股票代码,[股票每日下行指数]>
处理:计算均值
输出:<股票代码,股票下行指数>
Reduce类
package cn.edu.swpu.scs;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class Reduce extends Reducer<Text, FloatWritable, Text, FloatWritable> {
private FloatWritable fw=new FloatWritable();
@Override
public void reduce(Text key, Iterable<FloatWritable> index, Context context)
throws IOException, InterruptedException {
float sum = 0;
int num = 0;
Iterator<FloatWritable> values = index.iterator();
while (values.hasNext()) {
sum += values.next().get();
num++;
}
System.out.print("code: " + key.toString() + " " + "average decline index: " + sum / num + "\n");
fw.set(sum / num);
context.write(key, fw);
}
}
StockDaily类(主类)
package cn.edu.swpu.scs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class StockDaily {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1、获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2、设置jar包路径
job.setJarByClass(StockDaily.class);
//3、关联Mapper和Reducer
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//4、设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
//5、设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//6、设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7、提交job
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
5、编译代码
编码完成后,先run一次项目,让开发环境将Java代码编译一次,run命令是先编译再执行,这里会报执行错误,只要能编译成功即可;也可运行build --> recompile只执行编译。
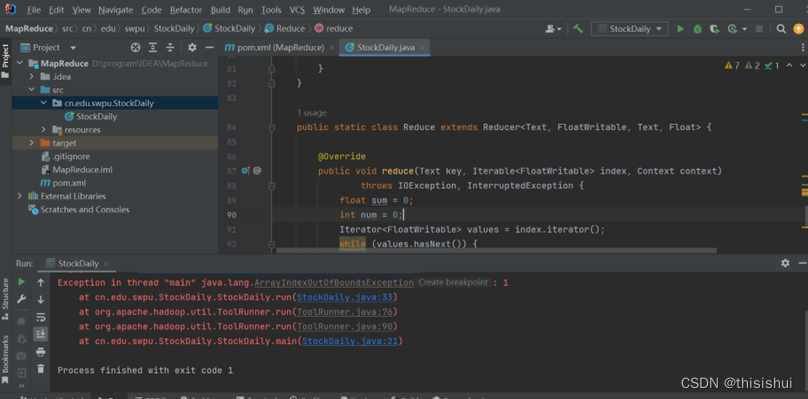
四、导出jar包
1、依次点击File–>Project Structure–>Projec Settings–>Artifacts–>“+”–>Jar–>Empty,创建一个名为unnamed的空JAR包
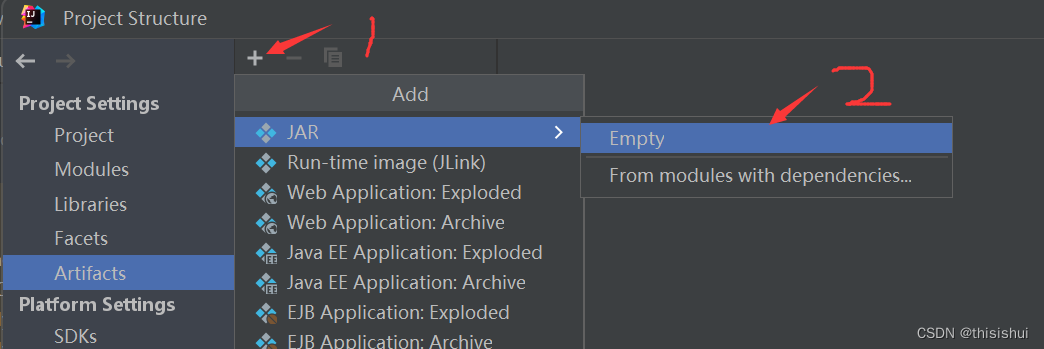
2、为JAR添加目录,目录结构必须与包名一致,如:包名为cn.edu.swpu.scs,那么目录结构就必须为/cn/edu/swpu/scs,如下图:
1为自己命名的的jar包名字,3.为代码所在包的路径,我的代码所在包的路径为cn.edu.swpu.scs,可以通过多次点击2指向的按钮来添加多级路径
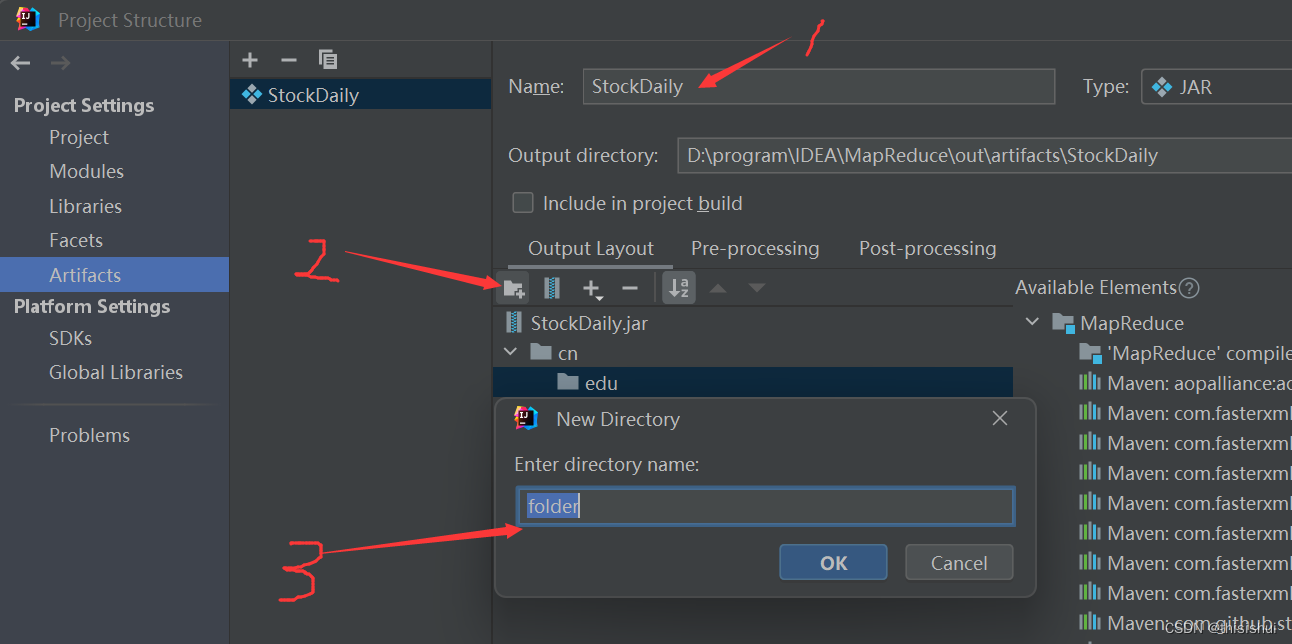
3、在包中添加文件,在刚创建的包目录中添加class文件

选择file后,浏览至项目的class文件处即可完成添加,如下图:
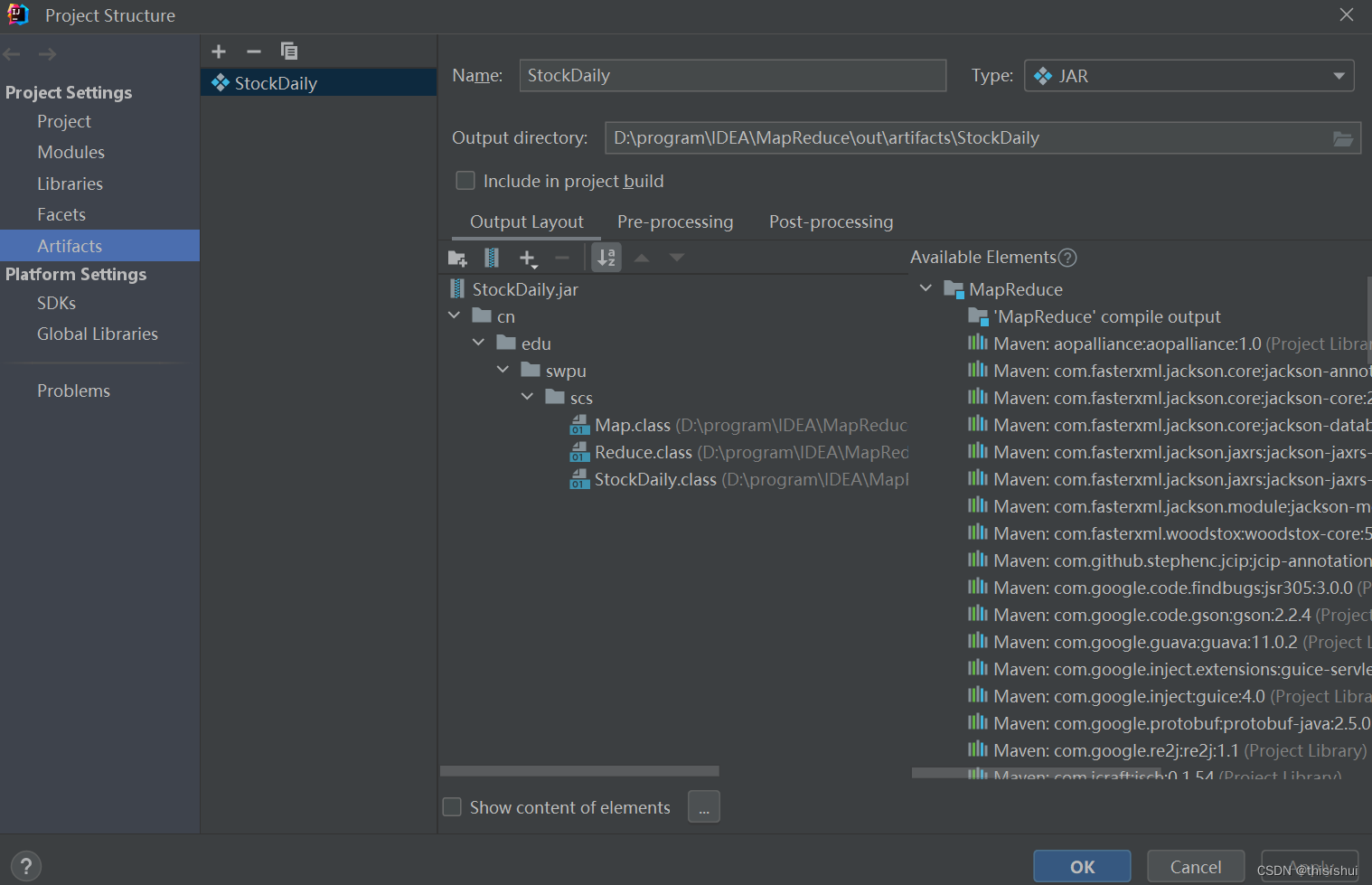
点击OK
注意:要实现编译,才有此class文件,没编译或编译失败都无此文件
至此JAR包的定义完成,可以开始执行打包了
4、执行 Build --> Build Artifacts完成build,完成后,在项目的out目录中可找到创建的JAR包,如下图:
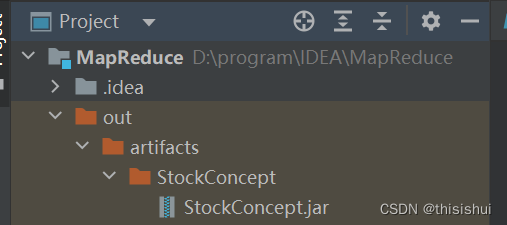
直接用资源管理器打开其目录即可,如下图:
五、将Jar包上传到Linux本地并执行JAR包
1、通过MobaXterm实现上传文件(包括Jar包和数据集文件,注意上传成功后要将stock-daily.zip文件解压使用)
2、在hdfs中创建输入文件夹
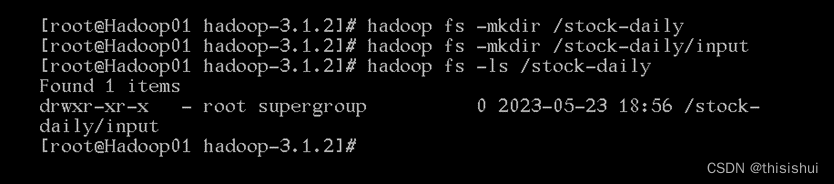
3、把解压后的输入文件stock-daily从Linux本地上传到hdfs的/stock-daily/input中
hadoop fs -put stock-daily /stock-daily/input
4、执行hadoop jar命令:
hadoop jar StockDaily.jar cn.edu.swpu.scs.StockDaily /stock-daily/input/stock-daily /stock-daily/output
StockDaily.jar的位置是通过MobaXterm上传后默认的目录,具体以实际的目录为准
执行时,需要保证MapReduce在HDFS上的输出目录不存在,否则HDFS会报错
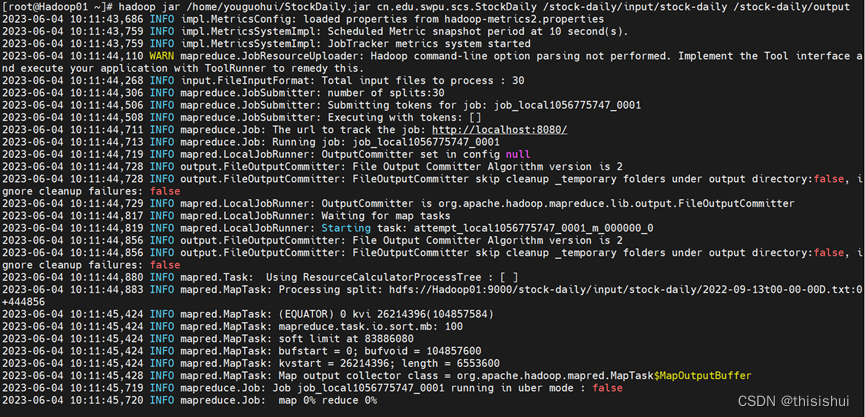
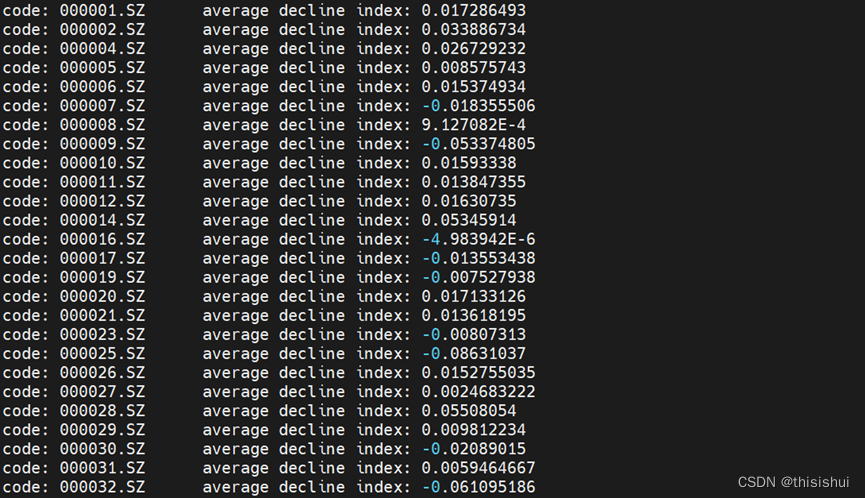

5、查看运行成功后输出的文件
hadoop fs -ls /stock-daily/output

查看运行结果
hadoop fs -cat /stock-daily/output/part-r-00000
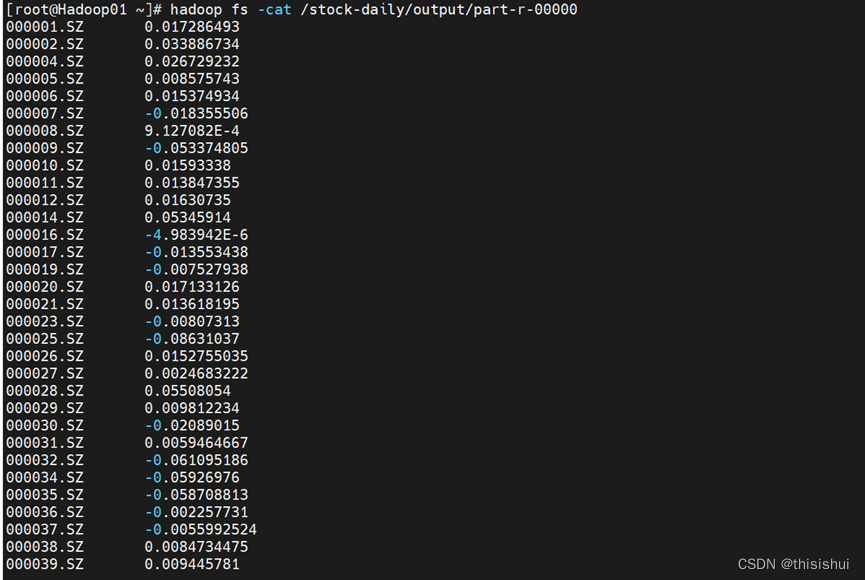
附:
1、stock-daily数据集https://download.csdn.net/download/m0_69488210/87959387
2、stock-daily数据说明
[‘code’,‘isst’,open’, ‘close’, ‘high’, ‘low’, ‘volume’, ‘money’, ‘factor’, ‘high_limit’, ‘low_limit’, ‘avg’, ‘paused’, ‘date’]
code 股票代码
isst 是否ST
open 开盘价
close 收盘价
high 当日最高价
low 当日最低价
volume 交易量(手)
money 交易量(万元)
factor 除权比例
high_limit 涨停价
low_limit 跌停价
avg 每日均价
paused 是否停牌
date 日期















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









