






“隐语”是开源的可信隐私计算框架,内置 MPC、TEE、同态等多种密态计算虚拟设备供灵活选择,提供丰富的联邦学习算法和差分隐私机制
开源项目

本文根据隐语开源社区 Contributor 西安电子科技大学网络与信息安全学院硕士研究生宋月冉 在「隐语开源社区 Meetup · 西安站」分享整理。
本次活动更多分享实录可点击这里查看
大家下午好,我是宋月冉,今天分享的是《大数据下的联邦学习隐私安全问题》,我的老师是王子龙教授,我的研究方向是联邦学习隐私安全问题,我也是隐语开源社区的 Contributor 。
今天我的分享将从以下三个方面展开:
- 联邦学习隐私保护的课题背景与研究意义
- 我的隐语开源之旅
- SecretNote——基于隐语的 Notebook
联邦学习隐私保护的课题背景与研究意义
世界范围内越来越严格的大数据法律使得隐私安全成为世界焦点,欧盟通用数据保护条例全面禁止用户数据离开欧盟,而中国的数据监管条例也越来越严格,数据不能出域的现状使得数据宛如陷入一个个孤岛,想要实现数据融合几乎不可能。
然而 AI 的高性能训练依赖于各方的小数据聚合而成的大数据,数据的聚合需求与数据的隐私性要求两者之间产生了冲突,成为了 AI 模型发展的重要瓶颈。基于此现状,联邦学习应运而生,成为了一种可以让 AI 高效准确的使用,不同用户的各自数据的关键范式。

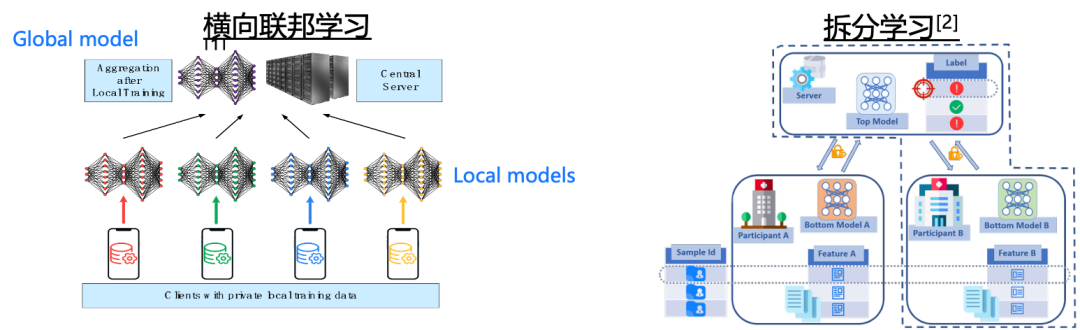
联邦学习主要可以分为横向和纵向两个场景,横向联邦学习主要是由一组互不信任的客户端和一个中央服务器所构成。其目标则为在中央服务器的辅助下,所有的客户端利用自己的本地数据协同完成一个模型的训练。纵向联邦学习主要分为拆分模型及不拆分模型仅拆分数据特征两种。在这里我主要介绍一下拆分模型的纵向联邦学习,其核心思想是切割网络结构,每个设备都只保留部分网的结构,在训练过程之中不同的设备训练自己的子网络结构进行前向传播或反向传播计算,并将计算结果传递至下个设备,多个设备进行联合模型来完成训练,直至全局模型实现收敛。
主要难点与科学问题
- 难点1:模型参数维度高、数据分布不均,如何平衡模型的隐私保护能力及其训练精度与效率?
- 难点2:通信量和复杂度要求严格,如何实现轻量、高效的联邦学习隐私保护算法?
- 难点3:训练场景多样且需求复杂,如何是现在异构数据源下的通用联邦学习隐私保护框架?

虽然联邦学习避免了我们直接暴露可信数据给可疑的第三方,但其仍然带来了大量的隐私泄露的潜在风险。联邦学习中其数据分布复杂,训练场景多样,我们需要经过多次的数据交换,这也为隐私保护带来了一系列的挑战。
- 第一,联邦学习中模型参数维度高、数据分布不均,且参与联邦学习的参数数量不定,数据集大小也不一,因此如何平衡模型的原始任务训练精度,在同时保护模型的隐私保护能力,是联邦学习隐私保护的重要难点。
- 第二,联邦学习本身的通信并不稳定,且进行本地模型计算的开销也较大。因而对联邦学习隐私保护机制的通信量和复杂度要求十分严格。而研究时限轻量级和高效率的联邦学习隐私保护算法降低其额外开销,也是联邦学习必须面对的挑战。
- 第三,联邦学习的训练场景多样,且需求复杂。当前的隐私保护方案都是不能通用的,而我们如何实现满足在不同场景以及不同需求下的通用联邦学习隐私保护框架,同时可以抵御系统外部和系统内部的攻击,这也是一个巨大的难点。
我的隐语开源之旅
目标与挑战
2022年10月,我很荣幸的参与了隐语社区支持的网信办学生创新资助计划,并在其中承担了联邦学习安全聚合与拆分学习攻防这两个项目。我的隐语开源之旅也正式开始。
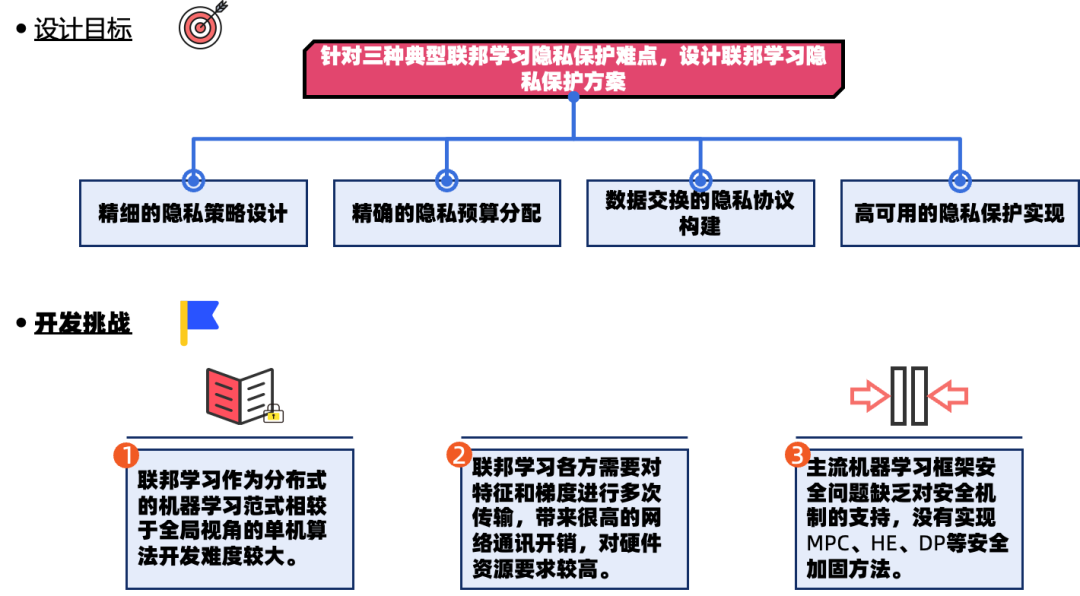
从理论层面上更加精细的隐私策略设计,更加精确的隐私计算分配,更加适应数据交换的隐私协议构建以及高可用的隐私保护实现,是我们设计联邦学习隐私保护方案必须面对的议题。
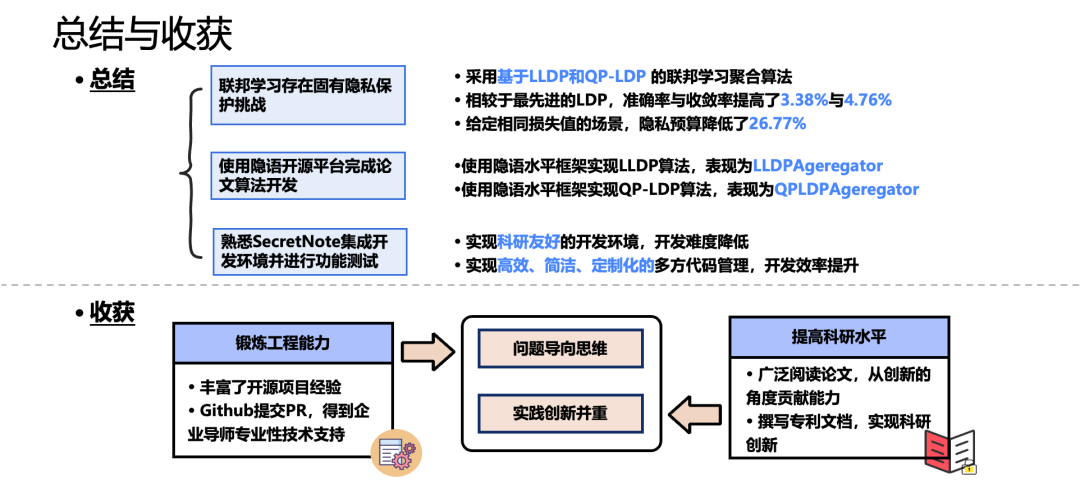
现有学者已经提出,将可信执行环境,安全攻防计算,同态加密,差分隐私与联邦学习相结合的解决方案,然而同态加密和安全多方计算,会导致计算开销大与通信开销高等缺点。而现有的较为成熟的 TEE 大多数支持在 CPU 上进行部署,在 GPU 上部署的实现尚不成熟,因此差分隐私作为具有隐私保护能力,且计算机通信效率较高的隐私保护方案得到了广泛应用。而现有的差分隐私方案,它基于模型进行添加扰动噪声的做法,会导致全局模型的训练精度下降,收敛速度降低。而给予它较大的隐私计算会导致隐私性能造成下降。基于此研究现状,我们则提出了 LLDP 和 QPLDP 两种基于本地差分隐私的联邦学习聚合方案,以上所提方案均已发表在近期的国际会议中。
而确定好了我们理论实践,接下来在进行我们的算法开发的过程中,也遇到了一系列的挑战。
- 首先就是联邦学习作为分布式的机器学习框架,我们能否可以实现像传统的集中机器学习那样单机版的轻松开发模式。
- 其次联邦学习各方需要对本地的进行多次传输,这对实验室的硬件通信开销造成很大制约。
- 最后当前主流机器学习框架缺乏安全模块,且不能进行模型代码的互通。
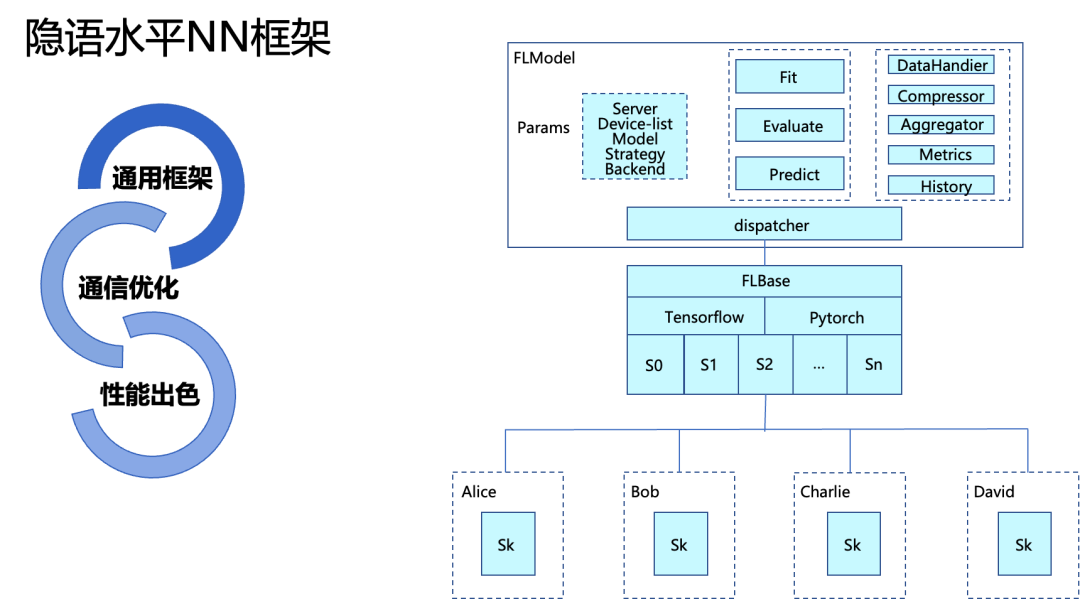
在我们项目组进行了前期框架调研之后,我们决定选择隐语水平 NN 框架来进行我们的开发。在我们大家实现论文实验以及想要复现他人论文结果的时候,我们往往会遇到选择什么样的框架,或者我们如何移植别人框架下的代码等问题。
隐语水平的框架已经实现了将主流机器学习框架,可以供我们直接进行调用,他可以保证我们代码的结构非常统一,且方便我们的调试和修改。
除此之外 NN 框架还提供了很多联邦学习隐私计算的功能性实现,例如 TEE 和 MPC,以及同态加密差分隐私等技术。在通信层面上,其也内置了稀疏与通信的算法优化,他可以保证我们代码的运行速度加快和训练流程减慢。
隐语 FLModel 开发实践--Aggregator
以我的工作 LLDP Aggregator 与 QPLDP Aggregator 为例,介绍我的开发过程。
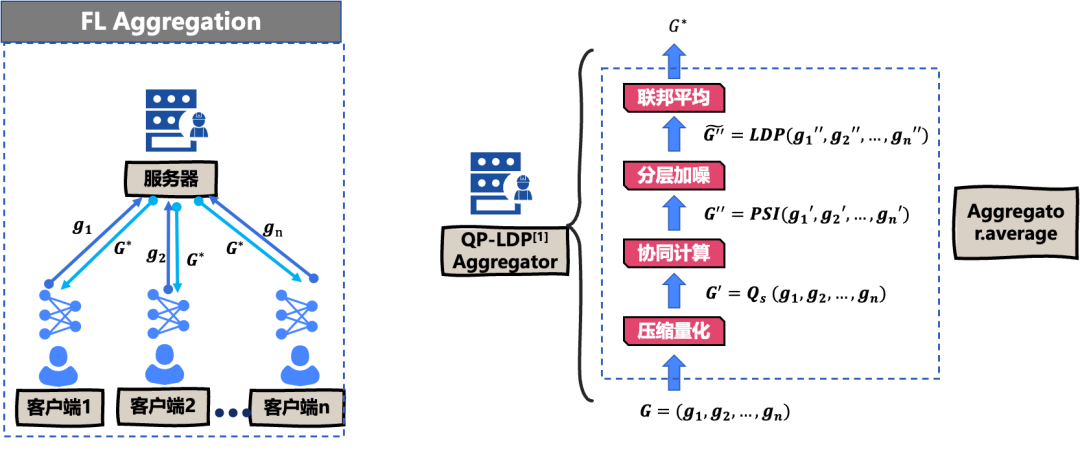
首先介绍联邦聚合过程,联邦 Aggregation 是联邦学习中最核心的步骤,在联邦学习中,各个客户用自己本地隐私数据完成对相同本地模型更新,并上传至服务器,服务器对于接收到的本地模型的参数与梯度,使用相对应的 Aggregation 算法来对其进行聚合,进而达到全局模型参数或者梯度,再将全局模型参数或梯度下发至各客户端,该过程会循环往复进行,直至全局模型达到收敛。
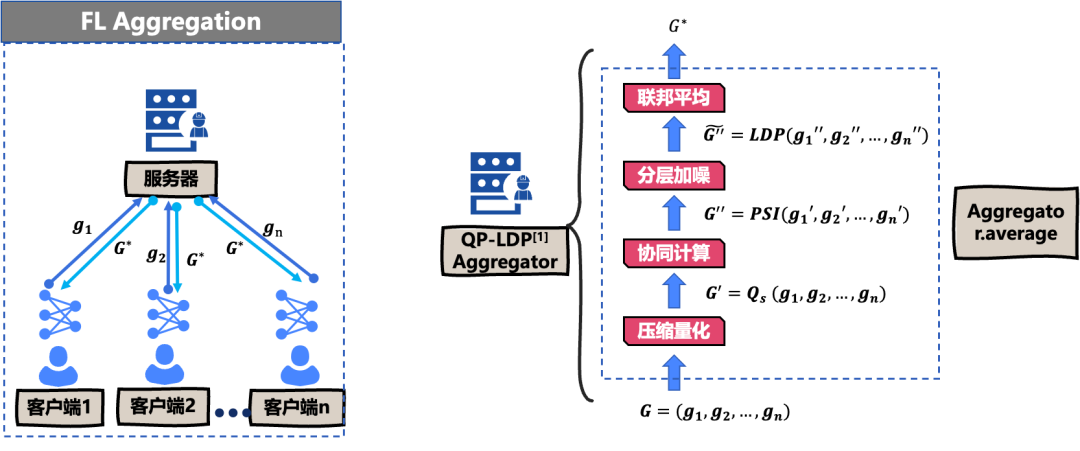
如果我们想用水平 NN 框架来实现我们自己所设计的算法,我们则需要新建一个 Aggregator 类,在 Aggregator 类中实现我们所设计的聚合算法,而在这里我们使用的是隐语已经内置好的联邦平均方法,该方法的输入是各客户端所上传其本地模型参数 W1 到 WN,这个方法输出是经过安全聚合计算之后的全局模型参数 WC,以 LLDP Aggregatc 为例,在我们接收到所有的客户端上传的本地模型参数,W1 到 WN 后,我们先对这些参数进行裁减操作,目的则是为了减少这些参数对噪声的敏感程度。
我们接着基于高斯机制对这些参数计算不同尺寸的扰动噪声,将扰动噪声和裁减后的模型参数相加,最后将扰动过后的模型参数输入隐语内置好的联邦平均算法之中,我们即可完成一个完整的联邦学习聚合过程。
接下来我用一段代码来直观展示我对 FLmodel 开发。
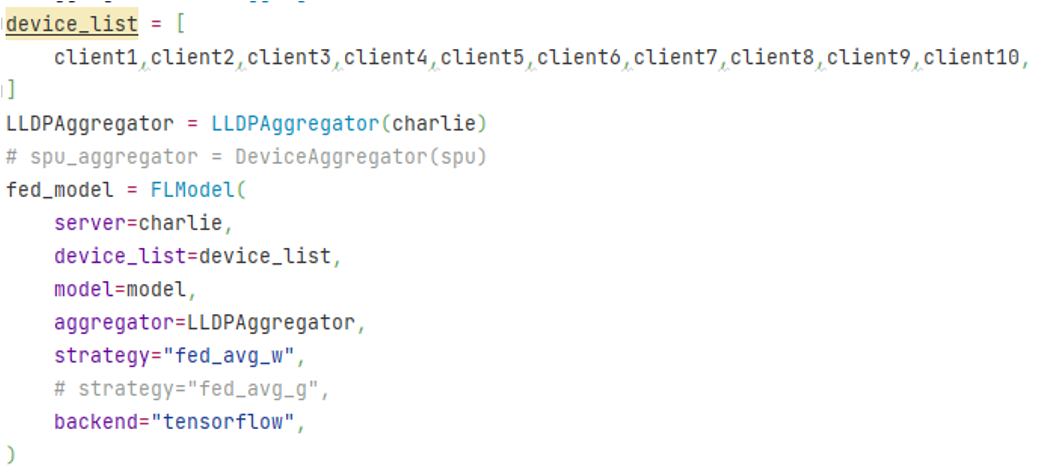
这张代码的展现通过 FLmodel 参数化配置来实现现在十个客户端联合训练的场景下使用 LLDP 安全聚合算法进行参数加权平均的联邦学习。图中可以很清楚的看到 device list 我们定义了客户端的数量,server = charlie 是指定插入用户最为我们的服务器,其中 Aggregator=LLDPAggregator 在这里指定使用的聚合算法是我们所新建的 Aggregator 类,backend=tensorflow 我们底层是 TensorFlow 机器学习框架,我们直接将已经实现好的单机模型代码调用进来,由此可见,这个代码的实现也是比较简单的。
下面介绍一下另一实现类 QPLDPAggregatcr,与前面 LLDP 不同的地方,我们这里新引入了一种压缩量化和一个可信的 PSI 服务器,目的是为了实现以一种通信高效的方式,来筛选相同的元素,我们只对不同的元素添加 LDP 噪声。值得注意的是,这里的方案是使用的梯度加权平均联邦学习,在这里只需要很简单将 FL 模型类来参数化配置,而不用像传统的机器学习框架,我们需要花大量时间来完全改写我们的联邦学习框架。
SecretNote--基于隐语的 Notebook
在进行算法开发和测试过程当中,我们在使用主流的一些开发集成环境,往往很多具有很多局限性,我在这里给大家介绍一下 Notebook 集成开发环境。
我在开发使用主流的开发环境过程中遇到了很多问题。
而其中可以主要概括如下三类:
- 首先:我们要在开发中配置好隐语环境,必须要灵活的切换不同的环境来完成开发。
- 其次:现有的 AI 模型参数和通用数据集大小在不断增加,当前一个服务器设备已经很难满足我们论文实现需求,我们往往需要多个服务器设备来协同调度完成一个联合模型的训练任务。而在多方设备执行多方模型过程当中,这里面执行的流程非常纷繁复杂。
- 最后:我们在进行算法开发的过程中,我们是需要自己去实现类似于数据交换,服务器部署,还有通信优化,这一系列开发门槛较高的代码组件,并且进行功能验证也是较为困难的。

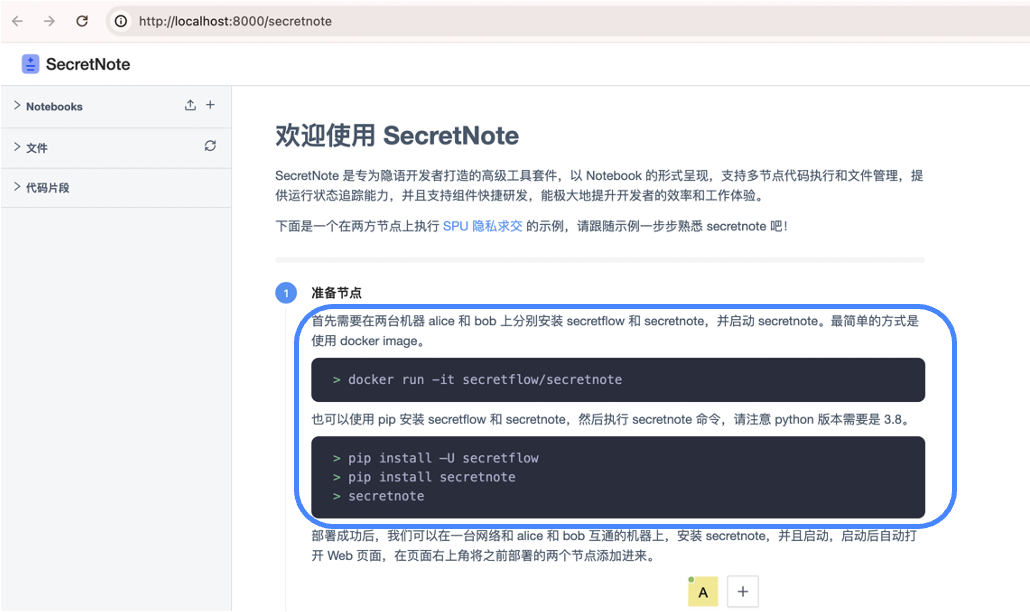
功能特点共有三点如下:我们在启动 SecretNote 开发环境时,它的环境部署是非常简单的,我们只需要在所有服务器设备使用一行代码就可一键式启用 SecretNote。
- 集成 Secretflow 环境可一键启动
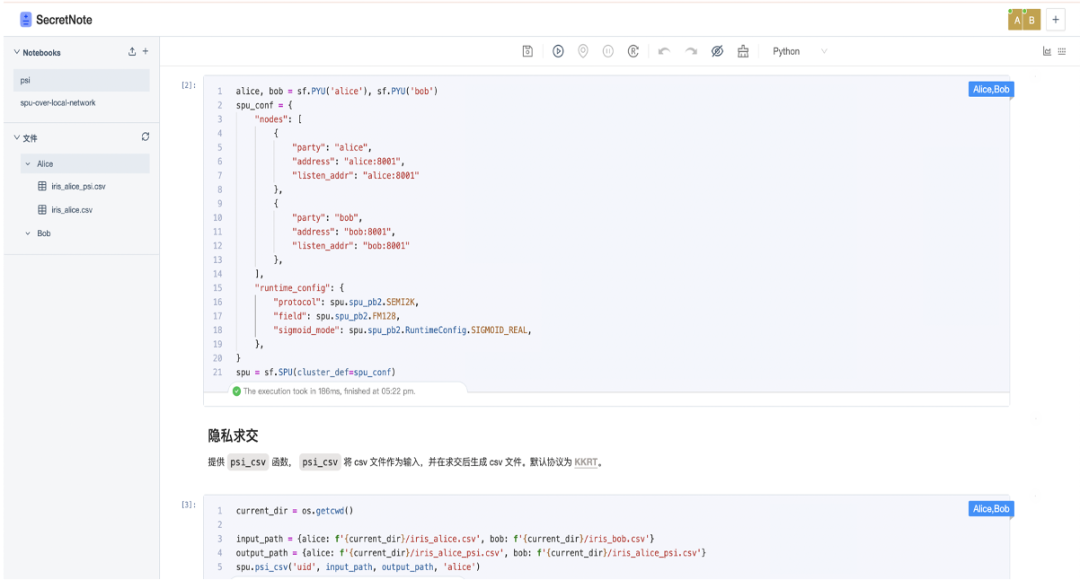
我们假如以联邦学习的场景为例,我们将不同的客户端分配给不同的计算资源,并对这些计算资源实现文件和代码的调度,如果使用的是传统的开发集成环境,我们是需要打开多个页面,对不同的设备进行文件和代码调度。如果我们使用 SecretNote 执行环境,我们只用打开一个页面,就可以实现多方文件的输入和输出和多方代码的运行和调控。
- 支持多方代码执行和文件管理
SecretNote 可以可视化我们代码的运行流程,正如上图所示,我们可以非常清晰看到数据的归属方以及数据的处理流程。它可以将我们的功能验证变得非常直观,也大大降低了我们开发流程的门槛。
- 一键式展示多方代码执行中的数据归属性与联系

总结与收获
我在隐语开源社区的总结和收获,迄今为止,我在隐语框架上提交三个方案,其中包括两个联邦学习安全聚合算法,LLDPAggregatcr 和 QPLDPAggregatcr,以及将 LLDP 和拆分学习相结合的防御算法。在进行联邦学习安全聚合与拆分学习攻防项目中我得到了来自隐语开源社区的大力支持,非常感谢各位老师对我技术上的指导,也非常感谢隐语开源社区给予我此次技术分享的机会。
正出隐语开源社区的口号所说,科技护航数据安全,开源加速数据流通,在未来我也想与隐语开源社区携手共同研究隐私计算问题、共同丰富隐私计算场景、共同推进隐私计算技术发展。谢谢大家!
🌟 关注「隐语Secretflow」B 站, 获取更多演讲回顾及相关资讯。
🏠 隐语社区:
👇 欢迎关注:
公众号:隐语小剧场
B站:隐语secretflow
邮箱:secretflow-contact@service.alipay.com


















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









